
Quick Answer
Yes. Build the payout support ticket cost calculator around payout-linked evidence, not generic queue totals: include only tickets tied to a payout ID, status change, reconciliation case, or settlement exception record. Then calculate fully-loaded cost with direct handling labor plus management, tooling, and training overhead. Break results by failure point so you can see which delayed-disbursement categories are driving repeat work and which fix should be prioritized first.
Delayed disbursement tickets are not always just a queue problem#
Delayed disbursement tickets are not always just a queue problem. In many teams, one customer contact triggers additional internal follow-up, so visible ticket counts can understate total operating effort.
That is why a payout support ticket cost calculator works best as an operating tool, not just a finance exercise. Per-ticket costing is a common management method in support. Outsourced help desk pricing often uses it, and published ranges can run from $6 to $40 per ticket depending on L1 to L2 support and monthly ticket volume. That is useful context, but it is not a payout benchmark. It does not, by itself, tell you what a delayed-disbursement case costs in your operation.
A workable model needs to do three things. First, it should calculate fully-loaded cost per ticket rather than stopping at agent time or salary-only estimates. Second, it should group tickets by the failure point that created the contact so you can see whether the expensive problem is, for example, status visibility, provider routing, ledger posting, reconciliation close, or a true exception. Third, it should turn that analysis into a decision about what to fix before you hire more people or push more volume through the same weak spot.
One early checkpoint matters. If your support data cannot reliably tie a ticket to a real payout event, a payout status change, or a known exception path, the numbers may look precise but still fall apart in review with finance or ops. The same goes for cost inputs. You need a baseline that includes direct handling labor and overhead such as management, tooling, and training. Treating cost per ticket as a salary-division exercise can understate the true burden, especially when low first-contact resolution creates follow-up drag and pushes work into other teams.
The goal of this article is simple: build a calculator you can defend in a monthly review and use to make changes you can verify. You should come away able to quantify fully-loaded cost, spot the highest-cost payout failure points, and connect each one to a concrete fix that can be checked against outcomes, not just intentions. If the model is doing its job, it will answer a more useful question than "How busy is support?" It will show which payout problems are expensive enough, and repeatable enough, to deserve immediate operational attention.
Related: Publisher Payment Thresholds: How to Set Minimum Payout Limits That Reduce Cost Per Transaction.
Define the calculator and the decision it must drive#
A payout support ticket cost calculator should be treated as a payout-operations model, not a generic support-cost tool. Its purpose is to show what payout-related contacts actually cost after handling, investigation, reconciliation work, and exception follow-up are counted together.
Use strict scope so the number stays defensible:
| Include in model | Exclude from model |
|---|---|
| Delayed disbursements | Account access issues |
| Reconciliation breaks | Profile edits |
| Settlement exceptions | Promos and marketing contacts |
| Payout status investigations | Onboarding contacts not tied to payout flow |
Apply one inclusion rule: only model tickets that can be traced to a payout artifact, for example, a payout ID, status change, reconciliation case, or settlement exception record. If a ticket cannot be tied to a real payout event, keep it out of optimization analysis until tagging is corrected.
The calculator should produce two outputs:
- fully-loaded cost per ticket by failure type
- monthly loss exposure by failure type
Set one operating rule so the model drives action: if the top failure categories show rising cost per ticket for two review cycles, fix instrumentation before adding headcount. Rising unit cost usually signals weak failure tagging, poor status visibility, or unresolved exception paths that force support into manual investigation.
For a step-by-step walkthrough, see Employee Cost by Country Calculator for Total Burden Across 40+ Markets.
Tag every payout ticket by failure point before doing any math#
Do not trust the model until every payout ticket has one primary failure-point tag. Without that, you end up pricing symptoms instead of operational breakdowns, and the same issue gets counted across multiple labels.
Tags are operational, not cosmetic. They add context and support tracked workflows and business-rule handling. Use one field for the primary failure point, then separate tags for the customer-facing symptom. A subject like "where is my money" is a symptom; your team still needs a grounded failure-point label supported by payout records.
Use conditional ticket fields to keep this consistent. Start with a top-level payout issue field, then reveal narrower options so agents select structured values instead of free-typing vague labels. This matters for reporting because tickets can carry multiple tags. If you do not enforce one primary failure-point field, category counts and cost-per-ticket views will drift.
| Failure point | Support symptom | Required evidence | Owning team |
|---|---|---|---|
| Initiation | Payout not visible as created | Payout ID or missing creation record, request timestamp | Payout product or operations |
| Provider routing | Sent but not progressing through the external rail | Provider reference, routing result, status history | Payments operations |
| Status update | "Where is my money" with unclear state | Payout status (pending, paid, failed, or canceled) and event timestamps | Product and support operations |
| Ledger posting | Mismatch after payout movement | Ledger entry plus internal-to-external record comparison | Finance ops or ledger team |
| Reconciliation close | Batch or settlement does not tie out | Reconciliation case, transaction history, settlement report, or exception record | Finance ops |
Keep symptom handling and root-cause tagging separate. Incident response answers the user now; root-cause tagging helps prevent repeats. If an agent cannot support a root-cause label with payout evidence, keep the ticket in symptom triage until the record is complete.
Set a hard internal checkpoint: any ticket without a valid primary failure-point tag is excluded from optimization analysis. That prevents unsupported savings claims and quickly shows where field design, training, or payout instrumentation still needs work.
For retention impact, see Bad Payouts Are Costing You Supply: How Payout Quality Drives Contractor Retention.
Build the fully-loaded baseline cost model#
Start with one number: fully-loaded cost per ticket. If you only count agent salary, you will understate what payout delays and exceptions actually cost.
Use a simple baseline formula: total monthly support spend / monthly ticket volume. Keep both numerator and denominator to the same month and the same in-scope payout tickets so finance, support, and product read the number the same way.
Define the numerator before you trust it#
Include both direct and indirect costs. Direct costs cover agent compensation and handling labor. Indirect costs cover management time, QA, tools, training, and other overhead needed to run support.
| Cost component | Share of total support cost |
|---|---|
| Agent salaries and benefits | 60-80% |
| Software, tools, and infrastructure | 10-25% |
| Overhead, facilities, and training | 10-15% |
Use an explicit overhead multiplier or a clearly stated indirect-cost allocation. One benchmark breakdown attributes 60-80% of total support cost to agent salaries and benefits, 10-25% to software/tools/infrastructure, and 10-15% to overhead/facilities/training. Do not treat those percentages as a target; use them as a check against salary-only models.
Define each input so it is auditable#
| Field name | Owner | Source system | Refresh cadence | Common data-quality failure mode |
|---|---|---|---|---|
| Monthly payout ticket volume | Support operations | Ticketing export filtered to payout failure-point tags | Monthly | In-scope and out-of-scope tickets mixed |
| Agent compensation and handling labor | Finance or support leadership | Payroll, invoices, staffing roster | Monthly | Shared staffing allocated incorrectly |
| Management and QA allocation | Support leadership | Roster, allocation sheet, budget mapping | Monthly | Lead/QA effort omitted |
| Tooling and infrastructure cost | Finance or IT owner | Billing records and invoices | Monthly | Platform-wide tooling misallocated |
| Training and enablement cost | Support leadership or enablement owner | Training logs and budget lines | Monthly or quarterly | Onboarding or retraining spend excluded |
Where possible, tie these inputs back to payout operations records, for example, support logs, ledger events, reconciliation reports, and payout status history, so the model stays anchored to real work.
Set one checkpoint before modeling savings: have finance and support leads confirm the baseline reflects true fully-loaded cost, not salary-only estimates.
You might also find this useful: Platform Payout Cost Estimator for Wire, ACH, and Local Rails.
Model follow-up drag and channel economics#
Low first-contact resolution (FCR) usually raises support effort because unresolved issues create follow-up work. In this model, treat FCR as a case-level operating metric and define it up front: what counts as "resolved on first meaningful response," and what follow-up window you will use. Without that definition, monthly comparisons become hard to trust.
Scenario the drag, not just ticket count#
Run two scenarios side by side for each high-volume failure tag:
| Scenario | Hold constant | Change | Compare |
|---|---|---|---|
| Current state | Weekly case volume, observed channel mix | Actual FCR | Carry-forward work into next week |
| Improved FCR state | Weekly case volume, observed channel mix | Higher FCR tied to a specific fix | Carry-forward work into next week |
If reopen data is incomplete, use a clearly labeled proxy and keep it consistent. The goal is not a perfect forecast. It is an explainable one.
Use a regular reporting cadence (daily or weekly) so slowdowns show up early instead of appearing late as hidden workload.
Break out channel mix before prescribing fixes#
Model channel mix by failure tag using your own records, and reconcile help desk, chat, and phone data before you draw conclusions. Disconnected systems can produce conflicting counts, which distorts follow-up drag and hides true effort.
If a category is both phone-heavy and low-FCR, prioritize root-cause fixes and clearer status visibility before chatbot deflection. That sequence is easier to explain in ops review and usually reduces repeat-contact pressure first. See Payout Status Page Design: How Platforms Reduce Where-Is-My-Money Support Tickets.
Document assumptions for each scenario: FCR definition, follow-up window, channel assignment rules, carry-forward logic, and data sources. We covered this in detail in Multi-Currency FX Calculator for Platform Payout Controls.
Prioritize fixes by cost driver, not by loudest queue#
Prioritize each expensive failure tag by root cause and assign one primary fix per tag. If you bundle product changes, status messaging, process controls, and ticket deflection together, you will not know what actually reduced cost per ticket or improved first-contact resolution.
Start from why the ticket exists, not which queue it hit. In triage, requests are assessed, categorized, prioritized, and routed, so your fix logic should follow that same path: is the issue mostly status confusion, a real operational exception, routine repeat questions, or bad routing?
| Cost driver pattern | Primary intervention | Verification checkpoint | Accountability rule |
|---|---|---|---|
| Users keep asking for updates because payout state is unclear | Status visibility | Fewer repeat contacts and reopens for the same payout-status stage within your follow-up window | One named owner |
| Tickets reflect a real payout break or exception that needs investigation | Process control | Fewer aging exception cases and faster closure of exception-handling workflows | One named owner |
| Requests are routine and answerable from known policy or status rules | Ticket deflection via self-service knowledge base or chatbot | Deflected issues do not come back as agent-handled contacts in the same issue window | One named owner |
| Cases arrive with the wrong team or missing required detail | Intake and routing fix | Lower reassignment rate and fewer bounce-backs between teams | One named owner |
Use a strict if-then rule. If repeated contacts come from unclear status, improve payout status communication first. If repeated contacts come from real breaks, fix reconciliation and exception handling first.
Be explicit about tradeoffs. Chatbots and self-service content can reduce repetitive volume, but they do not replace controls for true settlement exceptions.
Before funding more automation, test for misrouting. One cited support benchmark reports that about 30% of tickets in traditional systems require reassignment, with roughly 15 minutes added per reassignment. If your high-cost category also has high reassignment, fix intake first. Guided intake forms with conditional questions can collect the details needed to route tickets correctly and reduce ticket bouncing.
Keep ownership singular even when execution is cross-functional: assign one accountable function per intervention, and make supporting roles explicit.
Need the full breakdown? Read Unit Economics for Payment Platforms: How to Calculate True Cost Per Payout.
Implement with an operator checklist and monthly checkpoints#
Use a three-phase implementation: baseline, targeted pilot, then broader rollout only after verification passes.
Lock the checklist before you pilot#
Before any team changes queues, content, or payout status surfaces, confirm:
- taxonomy is finalized and failure-point tags are used consistently
- input fields are validated, including cost inputs and fields used for monthly ticket volume
- baseline is approved so pilot results are compared to a stable starting point
- scenario assumptions are logged in plain language (what changed, what stayed fixed, and what is in scope)
- one owner and one measurement reviewer are assigned
- monthly review cadence is set before rollout starts
If a ticket cannot be tied to a valid failure point and known cost input, exclude it from optimization analysis until corrected.
Review one evidence pack every month#
Use one system of record for supporting documentation so support, product, and finance review the same inputs each cycle.
| Evidence item | What to include |
|---|---|
| Monthly ticket volume | Updated monthly ticket volume |
| Cost inputs | Updated cost inputs |
| First-contact resolution | First-contact resolution trend |
| Channel distribution | Channel distribution |
| Failure-point changes | Top failure-point changes since the prior review |
| Assumption changes | Any material assumption change logged next to the numbers |
Include updated monthly ticket volume, cost inputs, first-contact resolution trend, channel distribution, and top failure-point changes since the prior review. Log any material assumption change next to the numbers.
Use one gate before wider rollout#
Do not scale an intervention unless it lowers cost per ticket without worsening unresolved payout backlog.
Keep the rollout order strict: baseline first, then targeted pilots, then broader rollout after each category clears the checkpoint. If one metric improves while backlog health worsens, stop and correct before scaling. Related reading: Contractor Payout Speed Calculator by Rail and Country.
Account for market and program variance before rollout#
Do not scale a pilot across markets or programs until local variance is explicitly scoped. Treat each segment as in-scope only when the payout execution path, policy gating, and provider operating pattern are known well enough for a like-for-like comparison.
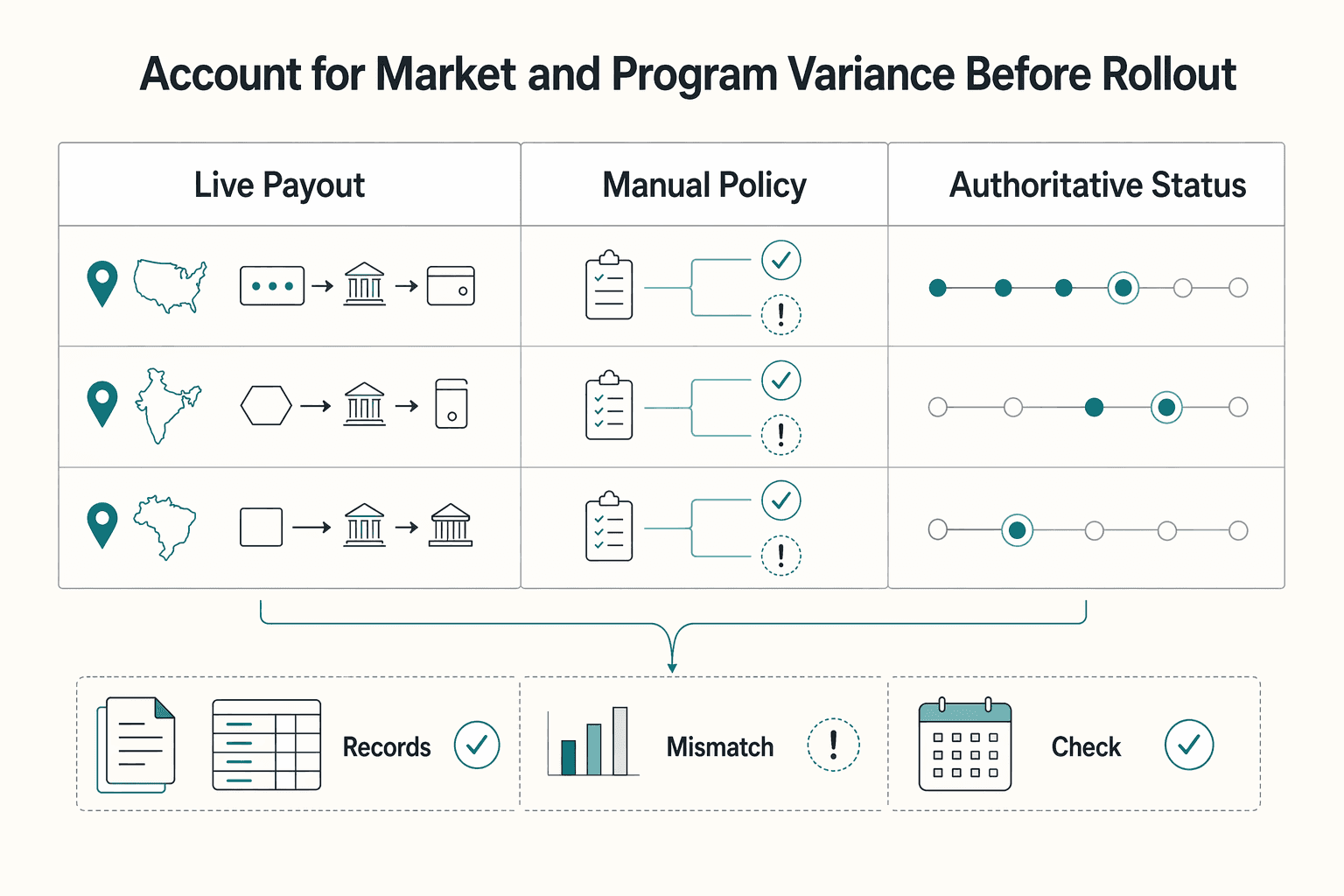
| Variance check | Record before launch |
|---|---|
| Live payout path | The live payout path for every market and program in the sample |
| Manual or policy review | Whether manual or policy review can pause disbursement |
| Authoritative status timestamps | Which status timestamps are treated as authoritative for support decisions |
Add a simple variance check to the monthly evidence pack before launch. For every market and program in the sample, record the live payout path, whether manual or policy review can pause disbursement, and which status timestamps are treated as authoritative for support decisions. If those inputs are unclear, keep that segment out of rollout until they are clarified.
Use the ledger as the shared source of truth when diagnosing delayed disbursement tickets. Before launch, confirm support, ops, and finance are not mixing ledger events with derived projections or copied status fields, and spot-check recent delay tickets against ledger event history so calculator inputs stay aligned.
Keep this stage conservative when evidence is incomplete. Label unknowns directly, avoid synthetic benchmarks, and do not track exceptions only in ad hoc spreadsheets, where manual errors, version drift, stale data, and weak audit trails can obscure real variance.
This pairs well with our guide on Spend Analytics for Platforms That Turns Payout Data Into Cost Decisions.
Conclusion#
A useful payout support ticket cost calculator is only worth keeping if it changes what your team does next. The value is not in a single blended cost-per-ticket number. It is in linking fully-loaded cost to the exact place where payout execution, ledger handling, or reconciliation is creating repeat work.
Keep the baseline simple and defensible. A standard support cost-per-ticket approach starts with total operating costs divided by resolved tickets, and that is a solid first anchor here. What makes it decision-useful is the payout layer you added throughout this model: valid failure-point tags, channel mix, repeat-contact drag, and evidence that the ticket matches ledger truth. If finance and support cannot sign off on those inputs, do not treat the result as precise enough to justify staffing changes.
This is also where many teams get misled. Generic support articles often frame cost per ticket as the main formula, and some float targets like $20 or less per ticket or note that wages can make up 60 to 70% of total costs. Those figures can be useful context for broad support operations, but they are not payout-platform standards. If you import them as targets without checking your own delayed-disbursement categories, you risk optimizing to a benchmark that has little to do with your actual failure modes.
Your best next move is narrow, not broad. Run a time-boxed pilot on the highest-cost delayed-disbursement category, then require measurable improvement before you expand automation, headcount, or self-service. The checkpoint should be explicit:
- lower fully-loaded cost per ticket for that category
- no worsening in unresolved payout backlog
- sampled tickets still align with ledger events and reconciliation outcomes
If one of those three conditions does not hold, pause and inspect the intervention before scaling it.
A practical red flag is relying on stale or weak guidance when you make that call. Some public guidance pages are explicitly archived and warn that continued reliance is not advised, so freshness matters. Apply the same standard internally. If your status definitions, ticket tags, or reconciliation reports are outdated, the model may look clean while your decisions get worse.
Treat this as an operating discipline. Baseline with direct costs, indirect costs, and an explicit overhead multiplier. Prioritize the highest-cost failure point, not the loudest queue. Verify outcomes with a small evidence pack, then scale only after the result holds for a full review cycle. If your biggest ticket driver is status confusion rather than a true payout break, a clearer status experience may be the better next fix than more agents or more automation.
Frequently Asked Questions
What is a payout support ticket cost calculator, and how is it different from a generic support cost calculator?
A payout support ticket cost calculator is a scoped support-cost model where you measure tickets your team classifies as payout-related. A generic support cost calculator usually starts with team size, agent cost, and monthly ticket volume. That is useful for a baseline, but you still need clear internal ticket categorization to make the payout view reliable.
Which inputs matter most for a reliable payout ticket cost per ticket calculation?
Start with monthly ticket volume, average agent cost, and team size because those are common baseline inputs in generic calculators. Then add your own category definitions and channel mix so the model reflects how tickets are actually handled. If repeat contacts are not consistently linked to the original case, your cost per ticket is still directional rather than decision-grade.
How do we calculate a fast baseline without overengineering the model?
Use total monthly support spend divided by monthly payout-related ticket volume, and document exactly what spend is included. Keep the first pass simple: direct handling labor plus indirect costs such as management, tooling, and training. A practical checkpoint is finance and support sign-off on the baseline before comparing interventions.
Why do first-contact resolution and follow-up tickets change true support cost so much?
Because one “ticket” can require multiple touches and extra investigation time. Support workflows often ask for screenshots and page links, and more detail can speed diagnosis. The common failure mode is counting only the first case while ignoring repeat contacts and follow-up workload.
When should we use ticket deflection versus fixing payout operations and reconciliation controls?
Use deflection for repetitive status questions when issues are mainly informational. Prioritize process fixes when your own ticket data shows recurring unresolved issues that keep generating human follow-up. If a category remains phone-heavy or repeatedly reopens, review the underlying workflow instead of relying only on FAQ or bot coverage.
What are the biggest gaps in generic SERP calculators for payout-heavy platforms?
They often present broad support benchmarks such as $8 to $15 per human-handled ticket or $6 to $40 by support level and volume, but those are context benchmarks rather than a universal cost-per-ticket number. They can also miss repeat-contact effects and channel differences, including cases where portal access is 24/7 but human support capacity differs by channel. Use benchmark ranges as context, not as your target number.
How often should finance, support, and product teams recalculate and review results?
Review monthly at minimum, because ticket volume and channel mix can change quickly. Recalculate sooner after major workflow, tooling, or policy changes. The monthly pack should include ticket volume, cost inputs, repeat-contact trend, and a spot-check that ticket categorization is still consistent.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
- acquisition.gov/far/part-31trusted
- azmag.gov/Portals/0/Documents/MagContent/2021_MAG_Unif...trusted
- catalog.greatbay.edu/sites/default/files/20232024-catalog-3-13-24...trusted
- comptroller.war.gov/Portals/45/documents/fmr/Volume_10.pdftrusted
- docs.cpuc.ca.gov/PublishedDocs/SupDoc/A2106021/5195/492387843...trusted
- dot.ny.gov/main/business-center/contractors/constructio...trusted
- federalregister.gov/documents/2024/04/16/2024-06563/improvements...trusted
- gao.gov/assets/gao-20-195g.pdftrusted
Educational content only. Not legal, tax, or financial advice.
Related Posts

Payout Status Page Design That Reduces Where-Is-My-Money Tickets
Many examples of **payout status page design** focus on visual inspiration instead of operating guidance. Layout ideas can help, but they do not answer the question your finance or support team asks most: where is the money, who owns the next step, and what proof do we have?

Bad Payouts Are Costing Your Supply in Two-Sided Platforms
Payout issues are not just an accounts payable cleanup task if you run a two-sided marketplace. They shape supply-side trust, repeat participation, and fill reliability. They can also blur the revenue and margin signals teams rely on.

Set Publisher Payment Thresholds Without Delaying Recipient Payouts
Set payout minimums to manage transaction costs, but only if recipients can still predict when they will be paid. If thresholds are unclear or scoped poorly, you may lower fee drag while increasing rollover balances and "where is my payout?" pressure on operations.