
Quick Answer
Start by separating involuntary churn from voluntary churn, then run payment-failure recovery as an owned operating system rather than a billing setting. Build a baseline from failed invoices, retry outcomes, and decline causes, and apply segment-specific actions instead of one global cadence. Use Smart Retries defaults like 8 tries within 2 weeks only as a starting point, define stop rules for hard declines, and verify each change against recovered revenue, retained MRR, and customer friction.
Why payment-failure churn is a monetization problem, not just a billing bug#
Treat payment-failure churn as a monetization issue first. Many failed payments are recoverable, so what looks like churn is often revenue collection leakage rather than clear product rejection.
Step 1 Separate recoverable revenue from true retention loss#
Involuntary churn happens when customers stop paying unintentionally, usually because of payment friction rather than a decision to leave. That is different from voluntary churn, and the split matters because both affect recurring revenue for different reasons.
When failed renewals and deliberate cancellations sit in the same retention bucket, teams misread the problem. Some losses do point to product or pricing issues, but payment-failure churn is often addressed through recovery actions like retries and dunning.
Use a simple operating test. If you cannot report voluntary churn separately from failed-payment churn, you cannot tell whether you have a demand problem or a collection problem.
Step 2 Put ownership and economics around recovery#
Once you frame failed payments as a monetization issue, the next question is simple: how much recurring revenue is recoverable, and who owns that recovery process?
This guide focuses on clear ownership, explicit decision rules, and measurable outcomes. The goal is not just more successful retries. It is better customer unit economics, measured against what it costs to acquire and keep the customer.
Automated retries can reduce involuntary churn, but one blanket retry policy is not a strategy. Recovery should be managed with segment-level rules and clear tradeoffs.
Step 3 Bound the scope to subscription billing controls#
This playbook is limited to subscription billing workflows where recurring charges fail and can still be recovered. That includes invoice failures after the first attempt and the related controls around dunning, retry policy, customer messaging, and payment settings.
Retry design is one concrete lever. Smart Retries uses AI to choose reattempt timing and reduce involuntary churn. One documented default is 8 tries within 2 weeks, with configurable windows from 1 week to 2 months. Treat defaults as a starting point, not as a rule you copy unchanged.
The key decision is segmentation. Both dunning strategy and retry policy can be set by customer group instead of forcing every account through one collection path. That is how payment-failure churn becomes an actively managed monetization system instead of a passive billing outcome.
Track involuntary and voluntary churn separately so recovery gains are visible. See Involuntary vs. Voluntary Churn on Platforms: How to Measure and Attack Both Separately.
What to prepare before you change anything#
Before you change retry timing or Dunning management, get to a baseline you trust. This is churn-reduction work. If the starting point is fuzzy, you will not know what actually improved.
| Prep area | What to gather | Examples |
|---|---|---|
| Baseline evidence | Failed payments, recovery outcomes, and current dunning rules | Pull a consistent recent window |
| Raw event evidence | invoice.payment_failed webhook events, payment-method-update events, and final outcome events | Trace failures and retry attempts |
| Flow and owners | The full Payment failure recovery flow and who can change each step | Initial decline through retries, payment-method update, cancellation, and reactivation |
| Live settings and decline data | Payment gateway settings and logs, active Smart Retries window, and decline-cause data | 8 tries within 2 weeks, or 1 week, 2 weeks, 3 weeks, 1 month, or 2 months |
| Success definition and update path | Success criteria and the payment-method-update path end to end | Confirm customers can update the right subscription and pay outstanding invoices cleanly |
Step 1 Build the minimum evidence pack#
Pull a consistent recent window of Failed payments, recovery outcomes, and current dunning rules. Your baseline should show both the payment failure rate and how effective current recovery is before you change policy.
Include raw event evidence, not just dashboards. If Stripe is part of your stack, include invoice.payment_failed webhook events so you can trace failures and retry attempts, then connect those to payment-method-update and final outcome events.
Step 2 Confirm the map and the owners#
Map the full Payment failure recovery flow from initial decline through retries, payment-method update, cancellation, and any reactivation. Then document who can change each step.
If ownership is split across finance, product, and payments operations, assign a clear decision owner before you tune policy so tradeoffs can be resolved quickly.
Step 3 Gather live vendor settings and decline-cause data#
Export current Payment gateway settings and logs from live configuration. If you use Stripe Smart Retries, record the active window, including whether you are using the recommended default 8 tries within 2 weeks or another configured window such as 1 week, 2 weeks, 3 weeks, 1 month, or 2 months.
Review decline-cause data before you touch retry logic. Use Stripe decline codes to classify failure reasons, and if you use Adyen, map raw acquirer responses to refusal reasons and result codes.
Step 4 Define success before you tune#
Define success criteria up front for recovery effectiveness and involuntary churn reduction. Keep those definitions fixed while you test so the results stay comparable.
Also verify the payment-method-update path end to end. If customers cannot update the right subscription and pay outstanding invoices cleanly, retry tuning will not remove the real bottleneck.
A deterministic ledger makes it easier to measure recovered revenue, retries, and write-offs cleanly. See How to Build a Deterministic Ledger for a Payment Platform.
Set ownership and decision rights before touching retry logic#
Set decision rights first. Retry settings, dunning messages, and stop rules are safer to change when ownership is clear and one approver is designated.
Step 1 Name one accountable owner and one approver#
Assign one accountable owner for Payment failure recovery performance and one approver for customer-facing Dunning management changes. The owner prepares the evidence, proposes changes, and reports outcomes. The approver has final go or no-go authority.
If you cannot clearly identify who approves changes in Stripe under Billing > Revenue recovery > Retries, decision rights are not clear yet.
Step 2 Separate decision areas and document who controls each#
Treat retries, messaging, and stop rules as separate decision areas, even if one group reviews them together.
| Decision area | Accountable owner | Approver | Evidence before change |
|---|---|---|---|
| Retry timing and attempt limits | Payments or billing owner | Revenue or product approver | Current settings, decline-cause mix, baseline recovery outcomes |
| Failed-payment emails and reminder copy | Lifecycle marketing or product owner | Customer-impact approver | Current templates and timing, support feedback patterns |
| Stop rules for payment-method update or cancellation | Product or revenue owner | Functional approver | Current cancellation path, update-flow outcomes |
Keep this as a living record with the exact setting location, edit access, and required approval. If your stack includes custom recovery automations or orchestration retries, document those change paths too so edits stay controlled.
Step 3 Run one recurring cross-functional review with one shared record#
Run one recurring review across product, finance, and ops, and keep one shared Revenue recovery playbook record so retries and messaging are evaluated together. Track proposed changes, current Failed payments and recovery outcomes, messaging updates, and explicit approve, reject, or defer decisions.
That matters because recovery outcomes are shaped by both retries and failed-payment emails, not by retry logic alone.
Avoid overlapping major retry edits when tie-break authority is unclear. If ownership is split and tie-break authority is unclear, sequence major Smart Retries and dunning-flow changes instead of launching them together. Finalize who owns retries, who owns recovery emails, and who approves stop rules, then tune from a clear baseline.
Related: Revenue Recovery Playbook for Platforms: From Failed Payment to Recovered Subscriber in 7 Steps.
Step 1 map your churn leakage and baseline economics#
Once ownership is clear, map the leakage before you try to fix it. Separate voluntary churn from involuntary churn first, or your recovery decisions may target the wrong problem.
Stripe's definitions are a practical baseline: involuntary churn happens for reasons outside the customer's control, typically payment or banking issues, while voluntary churn is a customer choosing to cancel. Treat that split as required reporting, not optional. Chargebee's churn reporting uses the same distinction because it changes how you analyze revenue loss.
Step 1 separate involuntary churn from voluntary churn#
Create two loss buckets in subscription reporting: intentional cancellation and failed-payment loss. Keep failed-payment loss visible through retries and dunning until it ends in recovery, cancellation or lapse, or reactivation. Kinde defines dunning as communication after a failed transaction, which is a useful boundary for this tracking.
Do not let a final cancellation event become the only truth. Some accounts cancel after repeated failures, but the economic path can start with payment failure. As one founder put it, "we found that 30% of this churn wasn't people consciously cancelling." Use that as a prompt to inspect your own data, not as a benchmark.
Verification check: for any period, each churned subscription should land in one primary bucket only. If finance, product, and billing report different churn totals, reconcile that before changing retries.
Step 2 build a stage baseline for failed-payment leakage#
After the churn split is clean, map the failed-payment path end to end and refresh it on a regular cadence. Stripe recommends tracking payment failure rates, recovery rates, and recent failed payments for top customers. Chargebee's lifecycle framing of first failure, retries, dunning, and post-dunning supports a stage-based baseline.
| Stage | What to measure | Verification check |
|---|---|---|
| Initial decline | Failed invoices or renewal attempts, plus attached MRR or invoice value | Match gateway or billing failure logs for the same period |
| Retry attempts | Retry attempts per failed-invoice episode | Use one episode ID per invoice so retries are not counted as new failures |
| Successful recovery | Failed invoices later paid inside your recovery window | Tie recovered revenue to the original failed invoice |
| Cancellation or lapse | Subscriptions ending after a failed-payment sequence | Separate user-initiated cancellation from non-payment termination where possible |
| Reactivation | Accounts returning after payment-failure cancellation or lapse | Track separately so immediate recovery is not overstated |
Keep the focus on two anchors: revenue at risk at first decline and revenue recovered during the sequence. If you only track retry success counts, leakage can stay hidden.
Avoid mixing invoice-level and subscription-level metrics in one line item. Use one unit per metric and label it clearly. If you need both, split them into separate sections.
Step 3 cut cohorts by plan type and tenure#
Do not run this analysis on blended averages. Glenbrook recommends involuntary-churn tracking by cohort or funnel before making changes. At minimum, use a consistent cohort split, for example by plan type and tenure.
Those cuts change the economics of recovery effort. A low-price self-serve tier and a higher-value annual plan should not be managed the same way. A first-renewal failure and a long-tenure customer with a temporary card issue are different signals.
Use the cohort table to decide tradeoffs. If higher-value cohorts recover well after outreach, extra manual attention may pay back. If short-tenure, low-value cohorts show many failures with weak recovery, test whether additional retry density adds return or just noise.
If the data is split across tools, bring in payments, analytics, and product early. Glenbrook notes this work may require cross-functional participation, and in practice that can be necessary to connect gateway failures, subscription states, and cancellation reasons.
Step 4 use outside numbers as context, not targets#
Use external benchmarks to confirm the problem is material, not to set goals. Claims vary. Slicker says "20% more" failed-payment recovery, RecoverPayments cites "20-40%" churn reduction, and Glenbrook cites a 1.39% average involuntary-churn impact from Recurly-reported data. Treat those as directional context only. Your targets should come from your own stage baseline, cohort cuts, and unit economics.
Checkpoint before moving on. You should be able to explain, on one page, how much revenue enters the failed-payment path, how much is recovered, where drop-off occurs, and which plan and tenure cohorts drive the loss. If you cannot, keep working the baseline before tuning recovery policy.
For a step-by-step walkthrough, see How to Reduce Subscriber Churn on Your Platform Without Sacrificing Margin.
Step 2 segment failures and accounts before choosing actions#
Do not use one global retry cadence. Start with failure cause, then layer in customer value tier so the action fits both the decline pattern and the account economics.
At-risk customer segmentation is a practical starting point. Group accounts by payment behavior and reasons for missed payments. A temporary issuer issue, a hard decline, and a high-value account should not be handled the same way.
Read decline signals from the gateway#
Start with the payment gateway decline response. Gateway responses carry the decline reason, and the hard-versus-soft split should drive handling. Soft declines can be retry candidates. Hard declines should follow a different path.
If the issuer returns a hard decline code, Stripe Smart Retries does not automatically reattempt payment. If available, include issuer or network guidance such as Merchant Advice Code in your classification logic, since it is meant to help determine whether to retry.
Before you tune timing, run a simple quality check:
- What share of failures has a usable gateway decline category?
- What share still sits in an internal
unknownbucket?
If classification is still noisy, fix the mapping before you go deeper on retry optimization.
Define action tiers by segment#
Start with simple action tiers, then refine them as your data improves.
| Segment | Usual action | Why it fits |
|---|---|---|
| Soft decline, standard-value account | Immediate retry path, then delayed retries | Temporary issues may clear, and later spacing avoids dense fixed retries |
| Hard decline or issuer guidance not to retry | Pause automated retries and prompt payment-method update | Reattempts may conflict with issuer/network intent |
| Recoverable signal on a high-value account | Delayed retry path plus manual outreach when economics justify it | Segment-specific policies let you match effort to revenue at risk |
For delayed retries, use Exponential backoff so wait times increase between attempts up to a limit instead of repeating a dense fixed cadence.
Treat Smart Retries as a layer, not the strategy. Smart Retries uses dynamic, time-dependent signals, and Stripe's recommended default is 8 tries within 2 weeks. Use that as a timing layer inside your segmentation model, not as a substitute for segmentation.
Before moving on, define for each segment the trigger, maximum attempt window, exit condition, and exception owner. Then monitor early for two avoidable errors: repeated retries on hard declines, and manual outreach on low-value accounts without clear recovery upside.
Step 3 design retry cadence and stop rules that protect trust and margin#
Use segment-specific retry timing with clear stop rules. Blanket daily retries can ignore decline type, add compliance cost, and keep contacting customers after the practical recovery window.
Set timing by segment, not by habit#
After segmentation, define each segment's retry window and attempt spacing. Stripe supports both Smart Retries and custom retry schedules for failed subscription and invoice payments, and Stripe says Smart Retries are more effective than fixed schedules. For many soft-decline segments, Smart Retries are a strong default timing layer.
A practical starting point is 8 tries within 2 weeks. Treat that as a baseline, not a universal rule. Stripe also allows 1 week, 2 weeks, 3 weeks, 1 month, or 2 months, so you can shorten or extend windows based on segment economics.
If you are not fully delegating timing to Smart Retries, use Exponential backoff so attempts spread out over time instead of repeating on a dense fixed cadence.
| Segment | Retry approach | Stop rule | Next action |
|---|---|---|---|
| Soft decline with valid payment method | Smart Retries or custom spaced retries within a defined window (for example, 1-2 weeks) | End of segment window or max attempts | Send update reminder, then final recovery notice |
| Hard decline | No auto retries | Immediate stop | Require payment method update |
| No payment method on file | No auto retries | Immediate stop | Send update link and rescue message |
| High-value recoverable account | Longer window, potentially up to 8 times within 2 months, plus optional 7 days grace for manual outreach | End of grace period or owner decision | Manual outreach, then terminal action if still unpaid |
Protect the hard-decline path first. Stripe does not retry when there is no payment method or a hard decline, and PayPal's Visa summary states Category 1 hard declines allow no reattempts.
Write stop rules before launch#
Before you launch, do not rely on attempt count alone. For each segment, define:
- When retries pause.
- When payment-method update becomes mandatory.
- When the account exits collection retries and moves to post-collection messaging.
For soft declines, stop usually means end of window. For hard declines or missing payment method, stop is immediate and the path becomes update-focused. For high-value accounts, Stripe's automation recipe supports an additional 7-day grace period before a terminal action.
Align dunning with real retry windows#
Your dunning setup should match your actual retry logic. Recurly supports different dunning cycles and schedules, and Stripe supports automated emails for failed payments, expiring cards, and payment-method updates.
Use a simple sequence:
- Immediate failure notice with a payment-method update link.
- Reminders during the retry window when customer action can still help recovery.
- Final notice at the end of the window, or at grace-period start if you use one.
If Smart Retries controls exact timing, do not promise a fixed next retry date in customer messages.
Reduce attempt density when trust signals worsen#
If recoveries flatten while complaints rise, reduce attempt density and tighten segment rules, starting with low-value or noisy segments. More retries can lift retry-success counts while still hurting net results through added operational load and fee exposure. PayPal also notes non-compliant retries can incur fees, including a $0.10 USD domestic retry fee example.
Verify each policy change against revenue and unit economics#
Judge policy changes by recovered revenue and net unit economics, not by retry-success count alone. Use Stripe recovery analytics, or the equivalent in your stack, to compare failure rates, recovery rates, and recent failed-payment patterns using the same segment definitions. Record each change, including segment, window, max attempts, stop condition, and communication schedule, and roll it back if it does not beat baseline on revenue and margin.
If your retry policy is changing every week, lock the decision rules in one operating spec your teams can execute consistently. Use the Gruv docs as your implementation reference.
Step 4 orchestrate dunning journeys and payment method updates#
Once retry windows are set, the next job is making the customer path clear. Keep each retry state to one clear message and one clear next action.
Connect each retry state to one customer ask#
Make the first sentence in each message explicit: payment failed, here is what to do now, and here is what happens if no action is taken. Stripe can automatically email customers after each failed subscription payment, and that flow is designed to prompt payment-method updates.
Keep the copy narrow and practical. If Smart Retries controls exact timing, do not promise a fixed retry timestamp. State that the invoice is unpaid and ask for a payment-method update now so retries can continue inside your collection window.
Recurly supports targeted dunning campaigns by plan or account, with up to 50 campaigns for eligible merchants. Use segmentation only where it changes the action or tone in a way your team can explain.
Shorten the path from email click to saved payment method#
Reduce the steps between the failed-payment email and a completed payment-method update. Stripe supports sending customers to either a Stripe-hosted Customer Portal or your own subscription management page. Use the route with the least friction.
Be explicit on hard declines. Chargebee documents that hard declines are not retried until payment details are updated, so your message and destination should say that clearly and ask for an updated method directly.
Validate the full path after each change: click from the failed-payment message, complete the update, and confirm the account and invoice return to the intended recovery flow.
Branch recovery effort by account value and signal quality#
Do not force every failed payment into the same recovery path. Stripe supports segment-specific retry policies, and Stripe automations can notify your team when high-value invoices are overdue.
| Account segment | Recovery path |
|---|---|
| High-value overdue accounts | Assisted recovery with an internal alert plus human follow-up |
| Standard recoverable segments | Smart Retries plus update reminders |
| Hard declines | Update-focused messaging until payment details are changed |
This helps focus manual effort on accounts that warrant assisted recovery.
Keep vendor outcome claims conservative and auditable. Keep outcome claims vendor-labeled and evidence-based. Chargebee documents retry and failed-payment messaging mechanics. Slicker publishes outcomes such as 70-85% recovery and 2-4x better recovery, but those are vendor-reported results, not an industry baseline or a guaranteed forecast.
For internal decisions, document segment message copy, destination path, retry-policy mapping, and before-and-after recovery by segment. If you cite vendor numbers, label them directional and compare them against your own recent performance before setting targets.
Step 5 harden your payment stack before scaling retries#
Fix routing fragility before you increase retry volume. Retries can recover many failed payments, but they cannot repair a weak gateway, processor, or acquirer path.
The point is simple. If a customer updates their card but the next attempt still runs through the same weak route, the customer action changed but acceptance may not. Start with routing and response quality, then tune Smart Retries.
Audit the payment path before you tune retry volume#
First, determine whether failures are mostly customer-level or concentrated in one Payment gateway path. Payment failover exists to reroute transactions when part of the chain breaks so payment can still complete.
Confirm that you can see, for each failed recurring charge:
- gateway or processor used
- issuer or network response code
- retry-eligibility signals, including Mastercard Merchant Advice Code when present
- whether the attempt used a backup route or only the primary route
- final outcome after retry or payment-method update
If your data only says "failed" and "retried," you cannot tell whether retries are recovering payments or just repeating the same broken path.
Respect network instructions in retry policy. Visa says retries should not be attempted after a Do Not Try Again instruction, and merchants are not permitted to reattempt Visa Category 1 declines. Mastercard decline metadata can also inform retry decisions. If those signals are missing or unmapped, fix that before adding retry complexity.
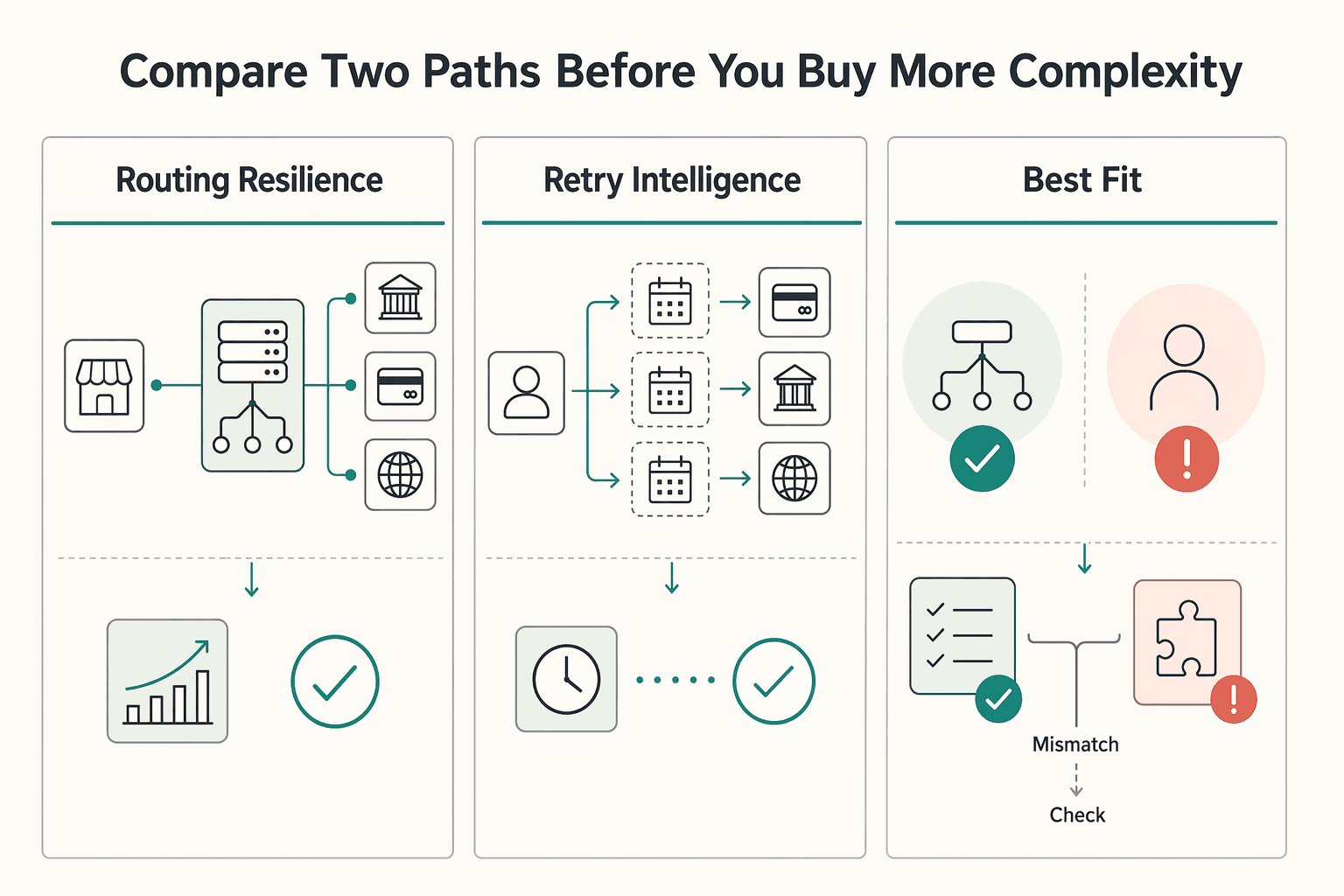
Compare the two paths before you buy more complexity#
| Decision area | Keep current gateway-only flow | Add orchestration or failover features |
|---|---|---|
| Routing resilience | One primary route with higher single-point risk if it degrades | Supports backup routing or route selection using rules and real-time data |
| Retry intelligence inputs | Limited to what the current gateway and billing stack expose | Can combine gateway, processor, acquirer, segment, payment method, fraud-risk, and currency rules |
| Best fit | Stable acceptance, low route concentration, clean decline data | Gateway-specific failure concentration or clear need to route by segment, currency, or risk |
Payment orchestration is not automatically the right move. It centralizes gateways, processors, acquirers, and related providers so routing can follow predefined rules plus real-time data. That helps when failures are routing-driven. It helps less when the core issue is customer-level decline behavior rather than route fragility.
Add machine learning only after the basics are clean#
Use Machine learning for retry timing only after your labels and routing data are trustworthy. If your team cannot clearly explain why recent failed payments were retried, stopped, or rerouted, keep improving data quality first.
Run controlled pre-live testing before rollout. Stripe test environments let you simulate transactions to catch integration defects before live payments. Pair that with regular failure testing and a small resiliency scorecard: failures by route, reroute success, retry success by decline class, and cases blocked by network rules.
Use one decision rule to keep the team honest. If failures are concentrated in one gateway path, fix routing and acceptance before you expand intelligent retries. Add failover, improve route selection, or reduce dependence on a single processor path first.
If failures are not gateway-specific and decline data is clean, then increase Smart Retry complexity second. This order keeps you from treating infrastructure fragility as a churn-optimization problem.
If you need a more advanced recovery layer, see How to Use Machine Learning to Reduce Payment Failures on Your Subscription Platform.
Step 6 run the weekly operating cadence and verification loop#
This is the verification loop. Hold changes steady for a consistent review window, for example a week, then check whether recovery actions improved retained revenue without adding customer friction or accidental churn.
Review one shared dashboard#
Run one shared dashboard across finance, product, and payments ops so decisions are based on the same definitions. Track the core signals: Failed payments, recovery rate, retained MRR or a GRR view, and the churn split between Involuntary churn and Voluntary churn.
That split should stay explicit. Involuntary churn is not the same as voluntary cancellation behavior, and combining them can hide whether payment recovery is working or simply masking a separate retention issue.
| Metric | What to verify | Why it matters |
|---|---|---|
| Failed payments | Whether volume is rising, flat, or concentrated in recent high-priority accounts | Shows whether the issue is broad or isolated |
| Recovery rate | Whether recovered payments improved after the last policy change | Shows whether retry or dunning changes are working |
| Retained MRR or GRR view | Whether recovered invoices meaningfully improve retained revenue from existing subscribers | Avoids celebrating saves that do not move revenue |
| Churn split | Involuntary churn versus Voluntary churn | Keeps payment-failure work separate from true cancellation behavior |
Before you call a win, verify movement in recovery rate against recent failed-payment records and confirm the saves came from actual recovered invoices.
Score experiments with pass/fail outcomes#
Treat each test as a decision, not as a dashboard trend. Define a hypothesis, a primary outcome, and guardrail metrics, then close it explicitly as validated, invalidated, or inconclusive.
Compare variables that are actually testable in this work, such as Smart Retries versus fixed retry timing, or one dunning window versus a longer one. Longer dunning windows can improve recovery in some contexts, but that is a test variable, not a rule to copy.
Be careful with timing effects after policy edits. Changes to a dunning campaign do not apply to invoices already in dunning, so separate newly entered invoices from in-flight ones before you interpret results.
Keep an exceptions log and a short decision record. Maintain an exceptions log for cases where Dunning management or retry behavior creates unintended outcomes, including unintended cancellations. Use account-level activity exports where available to verify which campaign and communications a customer actually received.
Close each review cycle with a short decision record. Record what changed, what happened to the four metrics, whether the hypothesis was validated, invalidated, or inconclusive, key exceptions, and one decision for the next cycle. That keeps your Revenue recovery playbook evidence-based instead of memory-based.
Related reading: What Is Negative Churn? How Platform Operators Achieve Revenue Expansion Without New Customers.
Common mistakes that sink recovery programs and how to recover fast#
The usual failure modes are copied defaults, metric confusion, and unsegmented retries. Treat retry and dunning settings as local policy decisions that you validate, not as vendor truth.
Step 1 test vendor defaults before you trust them#
Vendor defaults are starting points, not evidence for your mix of subscribers, gateways, and decline reasons. Defaults also vary by platform. Stripe documents a recommended Smart Retries default of 8 tries within 2 weeks, while Paddle describes up to 7 retries over 30 days in some flows.
Test before rollout instead of assuming defaults will transfer. Recurly explicitly recommends evaluating dunning campaign effectiveness through testing. Run a controlled test window against your current baseline and score it on recovered invoices, retained MRR, churn split, and customer-friction exceptions.
Step 2 optimize for economics, not retry hit rate#
More successful retries do not automatically mean a healthier recovery program. The goal is lower involuntary churn and better overall economics, not just a higher count of eventual authorizations.
Keep explicit stop rules for non-retryable cases. Stripe notes that when a failure returns a hard decline code, invoice payment cannot be retried without a new payment method. Also watch fraud-like exception patterns: excessive retries can resemble card testing. Stripe support notes Visa excessive-retry fee enforcement since April 1, 2021, with a ceiling of 15 retries in 30 calendar days for a single payment series.
Step 3 enforce segment rules and stop conditions#
Broad retry logic across all accounts can underperform. Major platforms support different retry policies and collection strategies by customer segment and gateway response code, and Stripe documents segment-specific retry policies through automations.
Use that capability to define segment-specific paths and clear stop conditions, then verify execution weekly. The minimum evidence pack is segment definitions, decline-code mapping, stop rules, and account-level activity exports showing which retry and dunning path each customer actually received.
Segment recovery by payment behavior, customer value, and risk, not just by plan tier. See How to Use Subscriber Segmentation to Reduce Churn on Your Platform.
Takeaway and copy/paste 30-day checklist#
Keep the first 30 days tight: separate the problem, assign clear ownership, run segment-based recovery rules, and judge changes against recovery outcomes and unit economics, not retry volume.
| Week | Focus | Actions |
|---|---|---|
| Week 1 | Baseline and ownership | Baseline Involuntary churn, Voluntary churn, and Failed payments in one shared view, and assign one owner for Payment failure recovery |
| Week 2 | Segmentation and retry rules | Implement customer segmentation and publish retry and stop rules; treat 8 tries within 2 weeks as a starting point, not policy; use Exponential backoff where retries continue |
| Week 3 | Dunning and experiment setup | Align Dunning management with payment-method update flows so failed-payment messages clearly direct customers to fix details and re-enter recovery; launch one controlled experiment |
| Week 4 | Review and next tests | Review lift versus baseline using payment-failure rate, recovery rate, and churn split; check Unit economics; document decisions and next tests in the Revenue recovery playbook |
- Week 1: Baseline Involuntary churn, Voluntary churn, and Failed payments in one shared view, and assign one owner for Payment failure recovery.
- Week 2: Implement customer segmentation and publish retry and stop rules. If you use Smart Retries, treat defaults like 8 tries within 2 weeks as a starting point, not policy. Use Exponential backoff where retries continue so attempts do not become overly dense.
- Week 3: Align Dunning management with payment-method update flows so failed-payment messages clearly direct customers to fix details and re-enter recovery. Launch one controlled experiment, for example on timing or message clarity.
- Week 4: Review lift versus baseline using payment-failure rate, recovery rate, and churn split, then check Unit economics before scaling effort by segment. Document decisions and next tests in your Revenue recovery playbook.
Keep the operating principle simple: fewer assumptions, tighter decision rights, and evidence-backed iteration beat generic retry volume. When you want to validate this kind of 30-day recovery plan against your own money-flow and controls, talk to Gruv.
Frequently Asked Questions
What is the difference between involuntary churn and voluntary churn in a subscription business?
Involuntary churn is customer loss caused by payment failure or banking issues, not an active cancellation decision. Voluntary churn is when the customer chooses to cancel. You should separate them in reporting because tactics for cancellation behavior usually do not fix payment-method or decline-path failures.
What are the minimum components of a reliable payment-failure recovery system?
The minimum stack is coordinated, not just retries: retry logic, customer failure notifications, and a clear path for payment-method updates. Automatic card updates should also be enabled where your provider supports them, so reissued cards do not break continuity by default. Add segment-level rules so different customer groups are not forced into one universal collection path.
How should retry cadence work in practice when failure causes differ?
Use different logic for soft and hard declines. Soft declines are temporary and can be retried later, while hard declines should not continue retrying until payment details change. Platform defaults are useful baselines, but validate them against your own segments and decline mix before you treat them as policy.
When should we stop retrying and ask for a payment method update?
Stop retrying when you receive a hard decline. In that state, successful collection is not expected without a new payment method. If your logs do not clearly distinguish hard versus soft declines, fix that first because cadence tuning without that split is less reliable.
What results should operators realistically expect from dunning and retry optimization?
Expect improvement in recovered revenue, not total elimination of involuntary churn. Many failed payments are recoverable, but some causes remain outside your control. Judge results against your baseline using recovered invoices and movement in involuntary versus voluntary churn.
What should founders and revenue leaders do first in the first 30 days?
Start by enabling and validating failed-payment retries, since retries are one of the most effective recovery levers. In parallel, confirm your flow covers failure notifications, payment-method updates, and hard or soft decline handling. In the first 30 days, aim to trace each failed invoice through its assigned recovery path and see where recovery is breaking.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
- csrc.nist.gov/glossary/term/configuration_control_boardtrusted
- docs.stripe.com/billing/revenue-recovery/smart-retriestrusted
- docs.stripe.com/billing/revenue-recoverytrusted
- hbs.edu/faculty/Pages/item.aspxtrusted
- hbsp.harvard.edu/product/523050-PDF-ENGtrusted
- paypal.com/us/brc/article/avoid-excessive-retries-penal...trusted
- stripe.com/resources/more/involuntary-churn-101-what-it...trusted
- stripe.com/resources/more/subscription-churn-101trusted
Educational content only. Not legal, tax, or financial advice.
Related Posts

The Freelance Payment Penalty: A Modeled Audit of Platform Fees, FX Spreads, and Payout Delays
The money rarely disappears through a single, easy-to-spot fee. The real loss is stacked. A marketplace takes its commission, a processor adds a charge for international cards, a bank or payment company converts the currency at a spread, a platform holds the funds before release, and a wire sheds a little to intermediaries on the way in. Each layer looks defensible on its own, but the worker feels the combined result as a smaller deposit and a later payday.

How to Respond to a Subpoena for Business Records
Move fast, but do not produce records on instinct. If you need to **respond to a subpoena for business records**, your immediate job is to control deadlines, preserve records, and make any later production defensible.

A US Expat's Guide to Investing in UCITS ETFs to Avoid PFIC Issues
The real problem is a two-system conflict. U.S. tax treatment can punish the wrong fund choice, while local product-access constraints can block the funds you want to buy in the first place. For **us expat ucits etfs**, the practical question is not "Which product is best?" It is "What can I access, report, and keep doing every year without guessing?" Use this four-part filter before any trade: