
Quick Answer
Split churn into two lanes and run different fixes. Track involuntary loss with failed payments, dunning recovery, and failed transaction reason codes; track voluntary loss with cancellation events, segment behavior, and value signals. Then prioritize by CLV/CAC exposure, not by one blended retention number. Use an account-level checkpoint before calling any recovery successful: failed charge, customer message, retry attempt, and final status should all reconcile in sequence.
Separate Voluntary and Involuntary Churn First#
Measure voluntary and involuntary churn separately. Treating churn as one number can fund the wrong fix. In a subscription business, Voluntary churn and Involuntary churn are different failures. One is a customer choosing to leave because price or value no longer works. The other is a customer dropping unintentionally because of a payment failure or technical issue.
That split matters because the economics are different. A payment failure can put revenue at risk even when the customer still wants the product. A cancellation for value reasons often points to a product, pricing, or onboarding problem. If you blend both into one headline retention KPI, the dashboard gets simpler, but the diagnosis gets weaker.
A practical starting point is this table:
| Lens | Voluntary churn | Involuntary churn |
|---|---|---|
| What happened | The customer actively cancels | The customer leaves unintentionally |
| Typical root cause | Price, value mismatch, poor fit, weak onboarding | Payment failure or technical issue |
| First checkpoint | Cancellation reason and recent product usage | Failed payment history and billing event trail |
| Risk if mislabeled | You discount instead of fixing value delivery | You blame product when billing caused the loss |
This article takes a two-lane view for founders, revenue leaders, product teams, and finance operators who care about margin, not just a prettier retention line. The goal is not more reporting for its own sake. It is to separate measurement, assign ownership, and decide where effort should go based on likely impact on Customer lifetime value (CLV).
One verification detail matters early. Each churned account should be tagged by exit type from evidence you can inspect, not from guesswork. For a voluntary exit, that usually means an explicit cancellation event or stated reason. For the payment-related lane, you want a visible billing trail showing failed charges or a technical break before the account lapsed. If that evidence is weak, your churn discussion will turn into opinion fast.
A common failure mode is trying to "reduce churn" with one broad initiative. Teams push win-back messages or discount offers while payment failures are quietly climbing. Or they invest in billing recovery while users are actually leaving because they never reached value. Either way, time and budget can go to the wrong problem.
Some benchmarks are directional, not universal. For example, one cited range suggests involuntary churn can account for 20 to 40% of total SaaS churn, but that is not a constant across every model or stage.
For the rest of this piece, keep one executive view if you need it, but run two lanes underneath it. That is a reliable way to improve retention without confusing product problems with billing problems, or lifting CLV in one place while creating waste somewhere else.
If you want a deeper dive, read eLearning Subscription Retention: How EdTech Platforms Reduce Churn with Cohort-Based Billing.
Voluntary churn and involuntary churn compared at a glance#
Separate these lanes early. Voluntary churn is a customer choosing to cancel, while involuntary churn is a customer being lost for reasons outside their control, most often payment-related.
| View | Best for seeing | Misses on its own |
|---|---|---|
| Gross churn | How much customer or recurring revenue is being lost over time | Whether people wanted to leave or were lost through payment failure |
| Voluntary lane | Customer preference shifts | Payment issues |
| Involuntary lane | Payment issues | Customer preference shifts |
| Criteria | Voluntary churn | Involuntary churn |
|---|---|---|
| Primary trigger | Customer actively cancels | Customer is removed after non-payment or related payment friction |
| What it signals | Change in preference, fit, or satisfaction | Payment-side failure rather than an intentional exit |
| Evidence to verify | Recorded cancellation event or explicit customer action | Failed-payment or delinquency trail tied to account loss |
| First metric to inspect | Cancellation rate and stated exit reasons | Failed-payment and delinquent-removal trends |
| Strategy implication | Diagnose why customers chose to leave | Diagnose why willing customers could not continue paying |
| Benchmark example (not universal) | 2.41% in Recurly benchmark content | 0.86% in Recurly benchmark content |
This split is operational, not semantic. Recurly's framing is the key baseline: voluntary churn reflects customer preference shifts, while involuntary churn points to payment issues, and each requires a different response.
Use gross churn as the executive summary, then run two operator views underneath it. Gross churn tells you how much customer or recurring revenue is being lost over time, but not whether people wanted to leave or were lost through payment failure. If you cannot answer those two questions separately, you are still managing churn at headline level only. Related: Involuntary Churn: How Failed Payments Silently Kill Subscription Revenue.
Build a KPI hierarchy that separates diagnosis from decisions#
Once you split churn lanes, build a KPI hierarchy so each metric has one job: outcome, diagnosis, or prioritization. A metric tree helps you connect movement to cause and effect so the team can decide what to do next, not just report a blended churn number.
Keep the lanes side by side in reporting, but separate in operations.
| KPI layer | Involuntary lane | Voluntary lane | Decision it should drive |
|---|---|---|---|
| Outcome | Involuntary churn rate | Voluntary churn rate | Which lane gets attention first |
| Operating driver | Payment failure rate, retry recovery in Dunning | Cancellation rate by segment | Whether to focus on billing recovery or customer choice |
| Diagnostic detail | Failed transaction reason codes | Stated cancellation reasons, usage or cohort patterns | What to fix first inside the lane |
| Economic filter | CLV and CAC of affected accounts | CLV and CAC of affected segments | Whether the intervention is worth budget and effort |
For the diagnostic layer, do not stop at decline volume. Use failed-transaction reason codes to separate payment-friction signals, for example issuer or card-data issues, from behavior that looks more like a product-value exit. The point is practical routing: avoid sending product teams after a billing problem, or billing teams after exits that were intentional.
Tie each lane to money, not just rate movement. With CAC pressure rising over the past five years, losing hard-won accounts costs more, so lane-level CLV and CAC should shape priority and budget.
Set a strict operating rule: no weekly churn meeting without a lane split, reason-code trend, and one action owner per metric.
Assign ownership so churn work does not stall between teams#
Treat Voluntary churn and Involuntary churn as separate workstreams with separate owners; a single blended owner usually slows action. A practical operating split is to have billing and engineering lead the involuntary lane, product and revenue lead the voluntary lane, and finance prioritize where intervention has the strongest economic impact.
| Lane | Primary owner | What to monitor first | What to verify |
|---|---|---|---|
| Involuntary churn | Billing, payments ops, engineering | Payment failures, retry outcomes, authorization patterns | Failed-payment trail, retry history, and final removal event |
| Voluntary churn | Product and revenue | Cancellation events, activation and value-realization signals, segment/cohort patterns | Recorded cancellation reason plus segment or cohort context |
| Prioritization | Finance | Relative CLV/CAC exposure by lane | Which funded action is most likely to prevent meaningful loss |
Use one shared churn-incident log so teams can connect symptoms to root causes quickly instead of debating from partial data across separate tools.
For a step-by-step walkthrough, see How to Calculate and Manage Churn for a Subscription Business.
Execute the involuntary lane in the right order#
Run the involuntary lane in order: establish recoverability basics first, then inspect payment plumbing, then add card-data resilience, and keep audit traceability in place throughout.
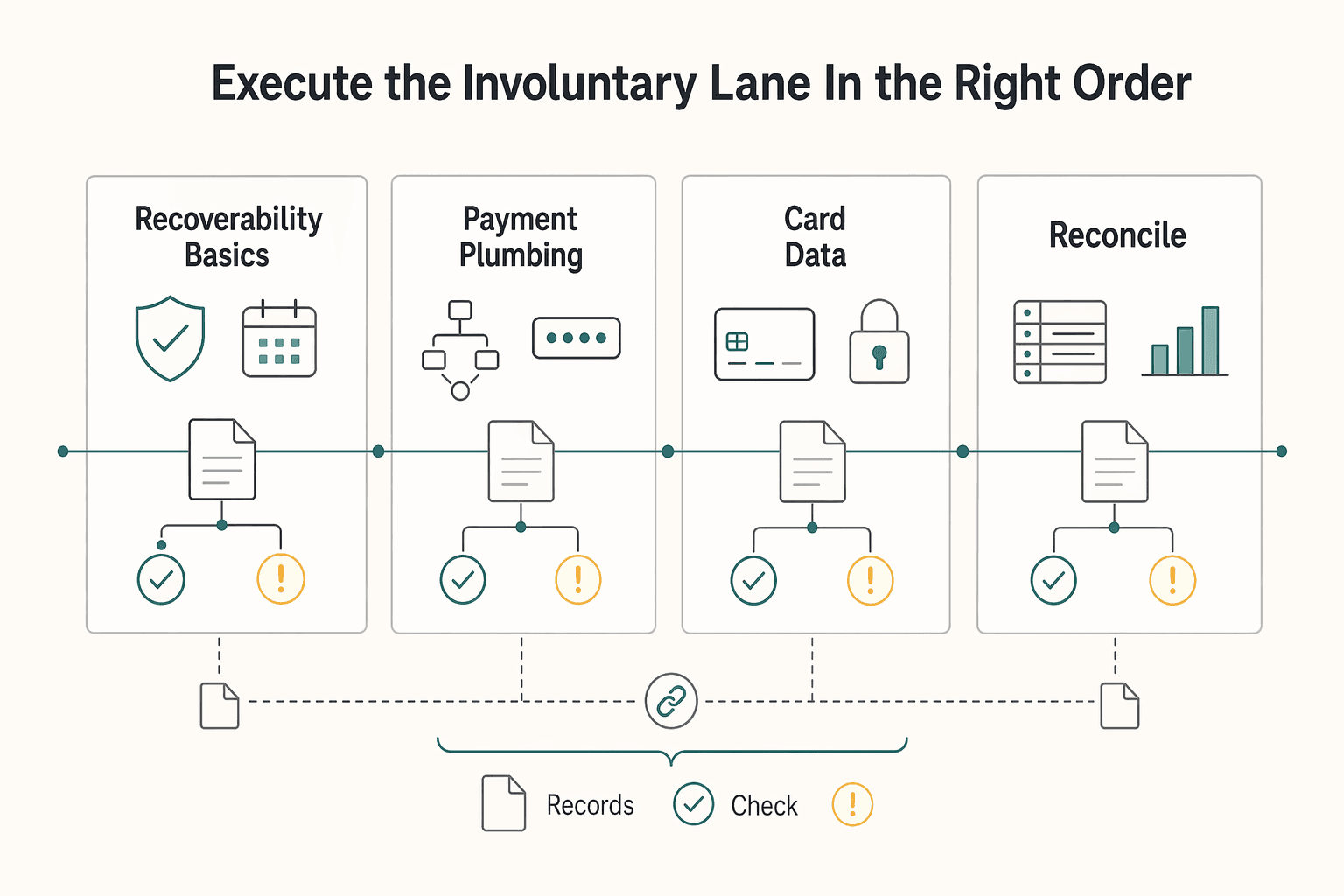
| Stage | What to implement | What to verify before moving on |
|---|---|---|
| Recoverability basics | Pre-dunning emails, In-app notifications, clean retry logic | Failed payments, customer prompts, and retry attempts are visible per account and tied to the same invoice or renewal event |
| Payment plumbing | Payment gateway routing review (including Stripe/Braintree where used), Payment authorization tracking by method | Authorization outcomes are segmented by method and processor path, not blended into one failure bucket |
| Card-data resilience | Payment Method Updater, monitoring for expired credit cards, Hard decline reason-code breakouts | You can separate stale-card patterns from other decline patterns |
| Audit and reconciliation | Idempotent retries, ledger/audit-trail checks | Retry history and final account status can be traced and reconciled account by account |
Start with what your team can actually observe. If support and ops cannot show the failure-message-retry sequence for one account, you are not ready for deeper optimization.
Keep diagnosis clean by separating involuntary churn from voluntary churn. A failed renewal belongs in the payment-recovery lane first; only then should you treat the loss as a product or value decision.
After that, inspect the payment path in detail. Track outcomes by payment method and processor path so you can see where failures concentrate instead of treating all declines as one problem.
Then run the card-data pass. Expired credit cards are a known churn cause, so review updater performance and hard-decline patterns directly rather than burying them in a generic failed-payment queue.
Use this companion guide for implementation depth: How to Reduce Involuntary Churn: A Platform Operator Playbook for Payment Failure Recovery.
We covered adjacent billing mechanics in Subscription Billing Platforms for Plans, Add-Ons, Coupons, and Dunning.
Reduce voluntary churn without masking product-value problems#
Keep voluntary and involuntary churn separate from the start. If a Payment failure happened before cancellation, do not classify that account as pure Voluntary churn until you confirm the billing recovery path was real and the customer still chose to leave.
| Observed signal | Test first |
|---|---|
| Customers report slow time-to-value | Test onboarding |
| Engaged users show price friction | Test packaging or pricing |
| Inputs are too vague to act on | Improve cancellation reason capture |
| Exit pattern | Assign first | Verify | First move |
|---|---|---|---|
| Failed renewal, customer billing touchpoint, then cancellation | Billing-related (not pure voluntary) | Renewal/invoice timeline, failure event, customer notifications, retry outcome, cancel event | Validate billing recovery before using this account in product-churn analysis |
| Cancellation with no recent billing issue and declining usage | Voluntary | Usage trend, cancellation reason, segment, tenure | Investigate value delivery, onboarding, packaging, or pricing |
| Cancellations concentrated in one onboarding stage | Voluntary, activation-related | Stage completion by cohort, time-to-value, cancellation reasons | Fix value delivery in that stage before expanding discounts |
Keep the classification evidence account-level and inspectable. Your team should be able to show the sequence from failed attempt to customer message to cancellation. If that chain is unclear, the churn label is weak.
Once labels are clean, prioritize by value at risk: high-CLV segments first, then segments with faster CAC payback risk. Replacing churned customers can cost much more than retention, and gross churn is most useful when tied back to segment economics and root cause.
Use cancellation intelligence to test specific hypotheses, not generic win-back copy. Test onboarding when customers report slow time-to-value; test packaging or pricing when engaged users show price friction; improve cancellation reason capture when inputs are too vague to act on.
Decision rule: if voluntary exits cluster in one onboarding stage, fix product value delivery there before scaling discount tactics. Discounts can create short-term saves while hiding the actual leak.
You might also find this useful: How to Use a Community to Reduce Churn and Increase LTV.
Hidden tradeoffs competitors underplay#
Billing-side recovery can improve outcomes, but it is not free upside. Treat each churn tactic as a test that needs clear ownership and account-level evidence before you scale it.
| Choice | What vendors emphasize | What to validate in your own data |
|---|---|---|
| More aggressive recovery on failed renewals | Higher recovered revenue | The exact sequence per account: failed renewal, customer touchpoints, retry path, and final outcome |
| More tools and more Payment gateway connections | More coverage and resilience | Who owns routing, monitoring, and reconciliation when results differ across systems |
| Vendor case studies as decision input | Proof that focused payments work | Whether your billing cadence, payment mix, customer tenure, and support model match the case context |
Zuora's framing is useful here: voluntary and involuntary churn are different lanes, and a meaningful share of churn can be involuntary. In the Seattle Times example cited by Zuora, 62% of churn was involuntary and retention reportedly improved by 25% after payments-focused changes. Use that as a signal that billing operations can matter, not as a guarantee you can simply carry over to your own model.
A practical bar: if you cannot reconstruct an account's full path from failed payment to final status, your measurement is not strong enough to support broad claims about save rates.
So optimize the billing lane, but do it with explicit ownership, tighter proof standards, and fewer assumptions than competitor pages suggest.
Use this 30-day decision checklist to attack both lanes#
Treat this month as a lane-split operating cycle: measure voluntary and involuntary churn separately, run fixes separately, then reallocate budget with explicit rules.
| Week | Primary focus | What to publish or change | What to verify before moving on | Common miss |
|---|---|---|---|---|
| Week 1 | Measurement split | Publish a two-lane scorecard for Voluntary churn, Involuntary churn, failed transaction reason codes, and a CLV/CAC tie-out | Definitions are fixed, formulas are documented, and finance agrees the CLV/CAC view matches the board version | One blended churn number drives debate instead of action |
| Week 2 | Baseline payment-failure controls | Review or deploy baseline controls already in your stack (for example: pre-dunning emails, in-app notifications, retry policy in Dunning, updater status checks) | Each touchpoint is timestamped, outcomes can be traced at account level, and support can see what the customer saw | Activity exists in tools, but support and finance cannot audit impact |
| Week 3 | Root-cause work by lane | Run one voluntary sprint by segment and one involuntary sprint by reason-code cluster | Each sprint ends with a ranked cause list, a named owner, and one change to ship or stop | Anecdotes pile up, but no clear segment or reason-code signal guides spend |
| Week 4 | Economic reallocation | Set if-then budget rules for the next month | Owners accept the rules before month-end, and action logs show what changed | Budget follows internal noise, not the clearer economic signal |
Week 1 is the foundation: Custify separates voluntary and involuntary churn, and your scorecard should do the same. Publish formulas with the scorecard so numerator, denominator, and date range stay stable week to week.
Week 2 should prioritize auditability over ambition. Do not count controls as wins unless you can reconstruct the account path from failed charge to customer touch to retry outcome.
Week 3 is where the lanes should intentionally diverge. For voluntary churn, investigate one meaningful segment; for involuntary churn, investigate failed-transaction reason-code clusters and act on the strongest pattern.
Week 4 is the decision gate. Sparkco is directionally right that automation and churn prevention are now imperative in subscription contexts, but your exit criteria should stay practical: named owner per lane, weekly KPI movement, and an auditable action log. Related reading: How EOR Platforms Use FX Spreads to Make Money.
Conclusion#
Treat churn as two jobs, not one metric. Voluntary churn is a customer deciding to leave. Involuntary churn is a customer losing service because payment or technical issues got in the way, often without the customer realizing it at first. Those are different failures, so they need different owners, different evidence, and different fixes.
| Final check | What to verify |
|---|---|
| Recovered account | Failed payment, customer message sent, retry attempt, and final payment all line up in the account history |
| A "voluntary" cancellation | There was no unresolved payment failure right before the exit |
| Directional benchmarks | Use them only after your own definitions are fixed and your payment-failure data can be reconciled account by account |
The practical mistake is blending them into one retention number and then debating it in the abstract. If a customer cancels after expired payment details were never recovered, that is not pure product rejection. If payment recovery is stable but cancellations are rising, billing fixes alone may not solve a value problem. You get better decisions when you separate diagnosis first, then evaluate each lane against the same business impact criteria.
That is the operating standard worth keeping. Your voluntary lane should be measured through cancellation behavior and signs of dissatisfaction in the journey. The billing lane should be measured through payment-failure patterns, expired payment details, and recovery outcomes. Shared prioritization matters, but shared measurement does not.
A good final check is whether your evidence is auditable, not just plausible. Pick one recovered account and verify the sequence end to end: failed payment, customer message sent, retry attempt, and final payment all line up in the account history. Then pick one "voluntary" cancellation and confirm there was no unresolved payment failure right before the exit. That can catch a common failure mode: teams call a billing problem a product problem and spend on the wrong fix.
Benchmarks deserve restraint. Some sources say involuntary churn can represent 20 to 40% of overall churn in subscription contexts and expose up to 30% of turnover in recurring-billing businesses if left unmanaged. Those figures are directional, not your target. Use them only after your own definitions are fixed and your payment-failure data can be reconciled account by account.
If you want one rule to keep after reading this, use it as a heuristic: when payment failures rise and engagement is steady, prioritize the billing lane first. When cancellations rise and payment recovery stays steady, prioritize the voluntary lane first. Managing involuntary churn can also help preserve trust and reduce later active cancellations. Keep the work concrete: measurable lanes, explicit owners, and auditable execution.
Frequently Asked Questions
What is the practical difference between Voluntary churn and Involuntary churn on a platform?
Voluntary churn happens when a customer actively decides to cancel. Involuntary churn happens when a legitimate payment is declined because of a payment problem, not because the customer chose to leave. In practice, that means different evidence: cancellation intent for one lane, payment-failure traces for the other.
How much churn is usually involuntary, and when should we trust that benchmark?
Treat published benchmarks as directional, not as your operating target. Butter cites more than $440 billion in annual industry loss and says subscription companies lose an average of 10% of top-line revenue to involuntary churn. Treat those as source-specific estimates, not universal planning numbers. Trust a benchmark only after your own definitions are fixed and you can reconcile failed charges, retries, and final outcomes at the account level.
Which metrics should we track first if we can only launch a minimal churn dashboard?
Start with a small set: voluntary churn rate, involuntary churn rate, payment-failure rate in recurring payments, and recovery rate from dunning. Then add failed-transaction reason codes, because a single “payment failed” bucket hides what to fix. If finance cannot tie a “recovered” payment back to the ledger and the account history, do not treat the dashboard as decision-grade yet.
What should we implement first to reduce involuntary churn in Recurring payments?
Begin with the basics you can audit: automated payment-failure notifications and dunning management with retry logic you can trace. Stripe highlights both as prevention levers, which is a practical starting order. Your verification check is simple: pick one recovered account and confirm the failed charge, message send, retry attempt, and final payment all line up in sequence.
How do Pre-dunning emails and In-app notifications work together without annoying customers?
No single best channel sequence is established. A practical baseline is to send one clear notification with the next action and retry timing, then add a second channel only if the issue is still unresolved.
When should we invest in Payment Method Updater versus improving Payment authorization and retry logic?
Improve failure diagnosis and retry logic first if you still cannot explain why charges are failing. A Payment Method Updater can help when expired cards or stale payment details are a repeated cause, but it will not replace disciplined decline handling and dunning execution. If your reason-code review is still blurry, fix diagnosis before adding more recovery tooling.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
- compsci.sites.tjhsst.edu/cspilot/lab621.txttrusted
- cs.arizona.edu/~mercer/Projects/BoggleWordstrusted
- cs.unc.edu/~weiss/COMP114/dictS05.txttrusted
- cs.unc.edu/~weiss/COMP114/scramDict.txttrusted
- dspace.mit.edu/bitstream/handle/1721.1/162934/Agrawal-shree...trusted
- federalregister.gov/documents/2024/11/15/2024-25534/negative-opt...trusted
- irs.gov/pub/irs-access/p2104_accessible.pdftrusted
- leg.colorado.gov/initiative_files/3308/downloadtrusted
Educational content only. Not legal, tax, or financial advice.
Related Posts

Reducing Involuntary Churn with a Payment Failure Recovery Playbook
Treat payment-failure churn as a monetization issue first. Many failed payments are recoverable, so what looks like churn is often revenue collection leakage rather than clear product rejection.

How EdTech Platforms Reduce Churn With Cohort-Based Billing
This is not really a pricing-page decision. It is a billing and measurement decision you need to explain, measure, and operate without mixing up product churn, billing churn, and reporting noise. That is the real job behind **elearning subscription retention cohort billing**, especially once finance asks why retention moved and ops has to prove the answer.

Involuntary Churn From Failed Renewals in Subscriptions
This is a billing operations problem, not a customer-intent problem. When renewals fail because charges do not go through and retries do not recover them, you can measure that path, triage it, and reduce it.