
Quick Answer
Assume AI agent payment liability starts with the party closest to execution, then gets reallocated through contracts and evidence. In most incidents, the merchant or PSP must handle refunds, reversals, or dispute responses first, while recovery from vendors or partners happens later. The practical fix is to define first-loss ownership pre-launch, map who can freeze records, and keep proof of authority, limits, and execution state ready for review.
The real question is where AI agent payment liability lands first#
The practical question is often who absorbs the first operational loss, not whether "the AI pays." In practice, the party closest to the transaction flow may have to act first. Liability is sorted out later through contracts, evidence, and local legal rules.
In agentic commerce, a single payment can involve an autonomous agent, a platform operator, a merchant, and a PSP. The outcome often turns on three things: who took the initial hit, who can prove what happened, and what the governing agreements and local rules say.
That framing matters because the first painful moment is rarely a courtroom question. It is usually a live operational one. A customer disputes a charge. A merchant asks why an order was placed. A PSP wants a response. Or an internal finance team wants to know whether funds need to be returned now. If your team cannot answer those questions quickly, the practical burden tends to land where execution happened, even if the deeper cause sits elsewhere.
Why is first loss usually operational, not final?#
Agent-initiated payments do not replace existing payment-chain obligations, and compliance duties still apply even when a human is not clicking pay. Traditional card flows describe defined obligations across participants. One industry description of an OpenAI-linked payment approach states that settlement, refunds, chargebacks, and compliance remain with the merchant and PSP.
So the first question is practical, not theoretical: which entity in your stack will have to refund, reverse, investigate, or absorb the issue before fault is fully resolved?
The answer should be documented before launch, not inferred after an incident. In the first hours of a disputed payment, someone has to do at least four things:
- decide whether the transaction should be refunded, reversed, or left in place while facts are checked
- preserve records before logs rotate, tools update, or context changes
- coordinate with the PSP or merchant on the customer-facing response
- start an internal reconstruction of what the agent was allowed to do and what it actually did
If no one owns that sequence, you do not have a usable liability model. It also helps to separate customer remediation from internal recovery. The party facing the customer or the bank may have to act immediately, while contract claims against a platform, vendor, or partner can take much longer.
Teams get into trouble when they assume those timelines are the same. Usually they are not. The operational loss arrives first.
More autonomy creates more ways to be wrong#
Agentic systems can initiate actions, make decisions, and interact with third parties on their own. That creates failure modes where a payment can be authenticated, within scope, and still commercially wrong.
One cited scenario makes the point. A scoped credential allowed up to $1,200 for flights, checks passed, and the outcome was still wrong because the agent relied on a policy document that was eighteen months old. Access control alone is not enough.
Compared with more deterministic automation, an agent can appear to follow instructions and still produce a bad commercial outcome when it relies on stale or misread context. In practice, "authorized" and "acceptable" can diverge.
A useful way to pressure-test this before launch is to ask your team to walk through the exact chain of decisions:
- Who granted the authority?
- What mission was the agent actually given?
- Which limits were machine-enforced, and which were only stated in policy?
- What data or documents shaped the choice?
- If the result is challenged later, what proof shows the action stayed inside the allowed scope at the time?
Before launch, require an evidence chain that shows:
- who authorized the agent
- what mission scope was allowed
- what limits applied
- what records prove execution stayed in scope
In practice, that evidence chain is stronger when it is assembled as a packet rather than scattered across systems. Your team should be able to pull the authorization record, policy version, execution logs, timestamps, and decision trace without depending on memory or informal screenshots. If the proof depends on a person remembering which dashboard to check, your position may be weaker during a real dispute.
Verifiable intent can strengthen proof of authorization, but it does not guarantee correct reasoning or a correct outcome. That distinction matters during review. Verifiable intent may show that a user or company approved a category of spend or a defined task. It does not prove that the agent used the right source, interpreted the policy correctly, or selected the commercially appropriate transaction. Disputes can turn on that gap.
Use a decision model before you turn it on#
Before enabling autonomous execution for a 2026 launch, map the risk for each country, PSP setup, and vertical. Your goal is to know what can go wrong before you argue about who pays.
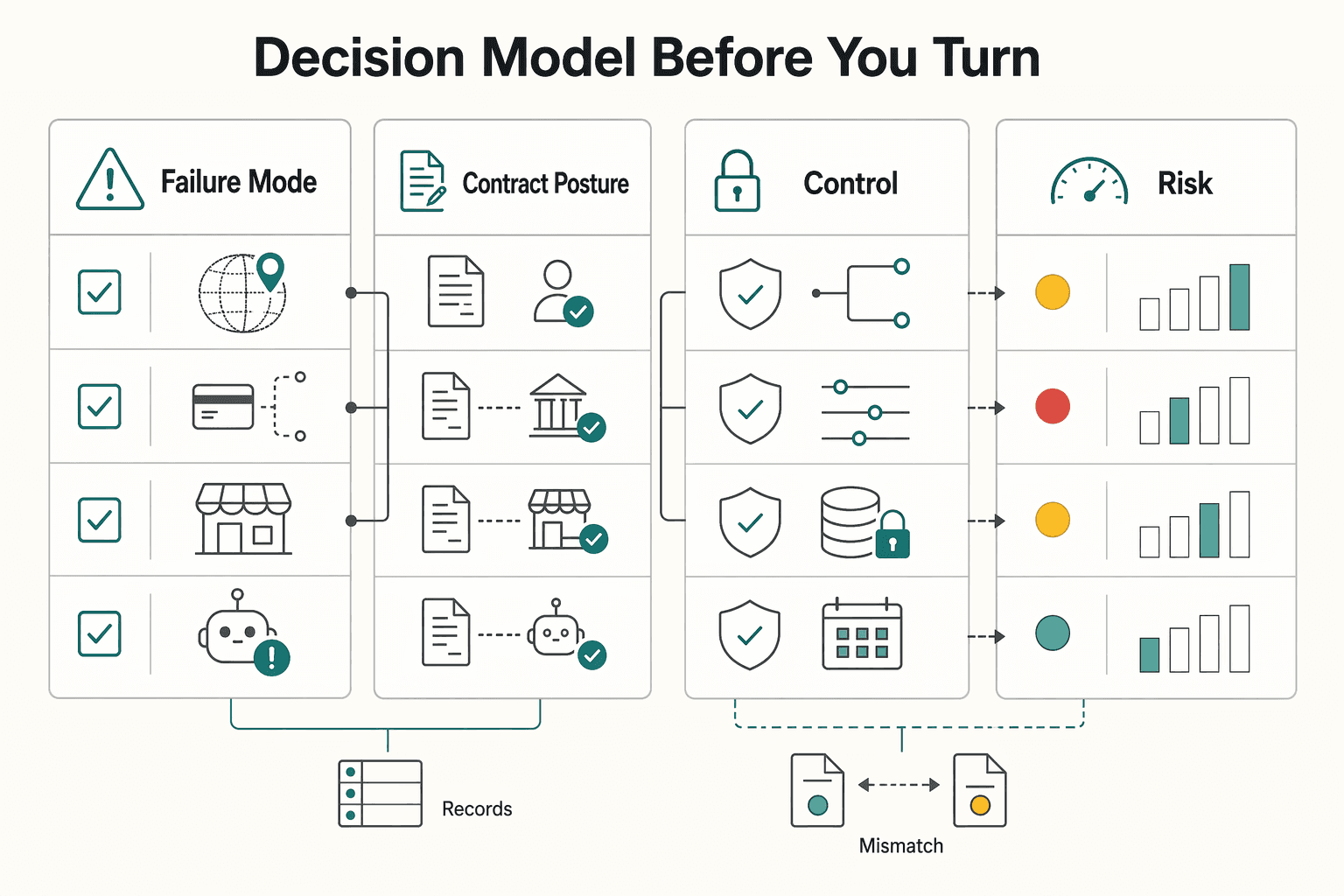
Focus on four things:
- Failure mode: what "wrong but permitted" looks like in your flow
- Contract posture: which agreements govern refunds, disputes, cooperation, audit access, and recovery rights
- Control design: mission scoping, approvals, logs, and whether limits are visible to third parties
- Rollout risk: where jurisdiction, program rules, insurance terms, or partner requirements change outcomes
That exercise works better as an operating review, not a theoretical legal memo. For each live flow, write down the exact transaction path, the systems involved, the records produced, and the fallback when something goes wrong.
Then assign an owner for each part. Decide who freezes evidence, who responds to the PSP, who handles the customer message, who decides whether the event is a policy defect or a processing problem, and who owns any vendor escalation.
Set legal expectations early. Under Australian common-law framing in the source material, an agent acting within authority can bind the principal, and private internal limits may not protect the principal unless communicated to third parties. Treat that as jurisdiction-specific, not universal.
That point creates a practical design question: are your limits only internal, or are they reflected in the actual payment or merchant-facing setup? If a restriction exists only in your own workflow but is not visible where the transaction is accepted, you should not assume that restriction will help you later.
Do not switch on autonomous payment execution until you have written confirmation from your PSP or acquiring partner, counsel, insurer, and local operating partners on how these flows are handled. If a 2025 pilot memo or sandbox approval is the only written sign-off, do not assume it covers a 2026 production flow.
Written confirmation matters because informal alignment may not hold in a dispute. If a partner says a flow is acceptable, ask them to confirm the exact setup they reviewed, the controls they expect, and the records they would need if a payment is later challenged. If those answers stay vague, treat that vagueness itself as a risk signal.
If you want a deeper dive, read Chargebacks in Agentic Commerce: Evidence Liability and Recovery Workflows for Platforms.
Start with the right liability model#
Treat AI agent payment liability as two decisions, not one: who absorbs the immediate operational loss, and who in the end bears legal responsibility after review. Keeping those separate makes risk, controls, and ownership clearer.
Here, the term means responsibility for compliance and loss handling when an autonomous payment agent initiates, routes, or approves a transaction that later proves wrong. The agent does not "pay." An organization in the online marketplace payments stack still has to refund, reverse, investigate, and document what happened, and compliance obligations do not disappear because a human did not click pay.
That definition helps because teams often collapse unlike outcomes into one vague category. A refund, a chargeback, an internal write-off, a contractual recovery claim, and a compliance issue do not always land on the same party at the same time. If you treat them as one combined question, accountability gets muddy fast.
First loss and final liability are different#
In practice, first loss is often operational. In the cited payment-protocol framing, settlement, refunds, chargebacks, and compliance remain with the merchant and PSP at the point of execution, even if recovery is later pursued through contracts or disputes.
| Stage | Owner focus |
|---|---|
| Operational owner | handles customer or payment-chain remediation |
| Investigation owner | classifies the failure and preserves evidence |
| Recovery owner | manages any contractual, partner, or vendor claim |
A useful checkpoint is simple: if a payment had to be unwound today, can your team name who handles the refund or dispute before fault is resolved? If not, your liability model is not ready.
A second checkpoint is just as important: can your team name what evidence would be needed to move the loss elsewhere later? Many organizations can answer the first question and not the second. They know who would refund the payment, but not what records would support a later recovery claim. That is how first loss turns into final loss by default.
Document those stages separately, even if one company owns all three. Otherwise the same incident gets handled three different ways by three different teams, with no single version of events.
What changes when you move from traditional automation to agentic execution?#
In traditional card payments, liability roles are treated as settled doctrine. In agentic commerce, responsibility assignment is harder.
A common operational gap is weak identity separation and weak logging. The controls you would expect in internal controls for accounts payable platforms are a useful analog here. If you cannot prove who authorized the action, what limits applied, and what the agent actually did, liability analysis and compliance handling get much harder.
That gap often shows up in mundane places. A company may have a record that a user enabled autopay behavior, but not a record of the exact scope that was granted at execution time. It may retain payment processor references, but not the decision trace showing why the agent acted when it did. It may log the payment event, but not the tool sequence that produced it. In a dispute, each missing link makes the reconstruction less credible.
Traditional automation often centers on a narrow question: did the system follow the rule? Agentic systems require a wider one: what rule, context, and objective was the system operating under when it acted? If your logs cannot answer that, root-cause analysis can quickly turn into opinion.
Preserve enough detail to reconstruct four layers:
- the human or system authorization that enabled the agent
- the policy and mission scope active at the time
- the external and internal data the agent relied on
- the execution path from decision to payment submission
If one of those layers is missing, expect disagreement later about whether the problem was policy, data, model, access, or infrastructure.
Do protocols improve handoffs without changing liability?#
Protocols can improve how instructions move between systems. They do not automatically reassign contract or payment-network liability. If a partner says protocol use covers the risk, require explicit contract language for refunds, disputes, cooperation duties, and compliance ownership.
Be direct here. "The protocol handled it" is not a liability answer. It is, at best, an integration answer. The operational and legal questions still remain:
- Who accepted the transaction?
- Who must answer the dispute first?
- Who holds the records?
- Who must cooperate in an investigation?
- Who can seek recovery, and under what contract language?
If the agreement does not say, assume the protocol alone will not rescue you. Better handoffs may reduce confusion, but they do not replace allocation terms. That is why the operational documents, the merchant structure, and the vendor agreements all need to line up before launch.
For a step-by-step walkthrough of the payment stack, see Global Payment Processing Platforms: Complete Infrastructure Guide.
Map the failure before you assign the bill#
Do not start with blame. Start by classifying the failure. If you cannot separate policy, access, infrastructure, model, and coordination failures, you may mis-assign responsibility and weaken later recovery efforts.
One practical mistake is trying to answer "who pays?" before answering "what failed?" In the first stage of an incident, freeze evidence first. Then classify. If teams jump straight to a liability position, they can contaminate the record with assumptions and miss the actual break point.
Use a cleaner sequence:
- preserve the execution record
- identify the exact transaction or transactions at issue
- map the tool and system path involved
- classify the likely failure family
- only then start liability and recovery analysis
| Failure mode | Common trigger | Who may absorb first loss initially | Who may be liable later | Evidence that matters most |
|---|---|---|---|---|
| Policy defects | Wrong merchant rules, approval thresholds, or category permissions | Varies by contract and flow; often the party that must unwind the payment | Often the team that set or approved the policy | Policy versions, approval records, change history, execution-time timestamps |
| Credential compromises | Token misuse, stolen credentials, inherited higher-privilege permissions | Varies; often the party handling the customer dispute and remediation | Depends on where access control failed across operator, platform, or vendor | Access logs, token scope, privilege changes, approval records |
| Infrastructure failures | Duplicate submits, stale data, malformed fields, outages | Varies; often the party reversing or correcting the transaction | Platform, integration, or processing counterpart tied to the break | Request and provider references, retry history, transaction timeline, incident records |
| Model errors | Wrong merchant choice, bad intent interpretation, stale context used as current | Varies; often the commercial party that executed the payment | Depends on whether cause is model behavior, data pipeline, or interface layer | Prompt/context snapshot, model version, retrieval output, data snapshot, override logs |
| Emergent coordination failures | Multiple agents/tools interact and produce an unintended outcome | Often unclear at incident start; frequently the party closest to funds movement and customer remediation | Hard to reallocate without a reconstructable decision chain | End-to-end event trail, tool handoff logs, version map, human escalation history |
That table is most useful when you apply it to a real event record rather than a hypothetical. For each disputed transaction, force the team to point to the specific evidence that supports one category over another. A vendor risk assessment for third-party payment risk is useful here because it forces the team to separate counterparties before a live dispute blurs the record. If the answer is "a bit of everything," keep separating the layers until you can identify the primary operational break and any secondary contributors.
Policy defects can be hard to push outward#
If your team configured the rules, start by assuming you own the problem unless the evidence shows otherwise. These cases can be hard to shift because the defect sits in your decision layer, not only in downstream processing.
Policy defects also tend to look reasonable in hindsight until you line up the timestamps. A threshold may have been approved, a merchant category may have been enabled, or a fallback rule may have been left active longer than intended. None of that necessarily looks like a dramatic failure in isolation. But if the wrong policy was in force when the agent acted, the case may point back to whoever set or approved that policy.
This is why version discipline matters. Keep a record of who changed the rule, when it became active, and whether the agent execution clearly tied to that version. If you cannot match the transaction to the exact policy state in force at the time, later arguments about what the rule "should have been" will not help much.
Credential compromises change the core question#
When spend authority is misused, the issue is often less about reasoning quality and more about who let access escape its controls. One cited incident narrative reports inherited higher-privilege permissions and references a two-person production-change checkpoint. Treat that as a cautionary pattern, not a universal template.
In these cases, teams often lose time debating whether the agent made a bad choice, when the real issue is that the agent or related system should never have had that level of authority. Start by asking:
- what credential or token was used
- what scope it had at the time
- whether that scope was intentionally granted
- whether privilege changed before execution
- whether any approval record supports that change
If the authority itself was wrong, model quality may be a side issue. The liability center of gravity can shift toward access control, change management, and approval discipline.
Infrastructure and model mistakes need different diagnosis#
Do not collapse every failure into "AI error." A grounded source makes the split clear: hallucination points to model behavior, while stale data can implicate the data pipeline. Keep enough records to test both paths, or later attribution will stay weak.
That distinction matters operationally because the fixes differ. If the model misread valid context, you may need to revisit prompt structure, retrieval boundaries, or review gates. If the model was fed stale or malformed data, the root issue may sit in synchronization, transformation, or upstream storage. Calling both of those "AI mistakes" can make remediation slower and vendor conversations less precise.
Use one simple diagnostic habit. Ask two separate questions:
- If the same model had better data, would the outcome likely have changed?
- If the same data had been handled by a simpler rules-based path, would the outcome likely still have failed?
Those questions will not solve every dispute, but they help separate model behavior from data and infrastructure defects.
Emergent coordination failures are the hardest to recover#
The toughest cases involve interactions across multiple agents and tools, where root-cause narratives can conflict. If you cannot reconstruct the full decision chain, your position in disputes and vendor claims can be weaker.
These failures are difficult because each component may appear locally reasonable. One tool may pass back stale context, another may interpret that context too confidently, and a third may execute payment as if the upstream signals were reliable. No single step may look clearly broken when viewed alone. The bad outcome appears only when the chain is reconstructed end to end.
That is why handoff logs matter so much. You need to know which system passed what information, in what order, with what version state, and whether any human review point was skipped or satisfied. Without that sequence, each party can describe the event from its own narrow viewpoint and still miss the real failure.
If you are designing incident evidence and payment controls, use the developer docs to map status events and audit-ready records into your launch checklist.
Who can be on the hook in a disputed agent transaction#
In a disputed agent transaction, the immediate burden often sits in the commercial and payment stack, not only with the model vendor. Depending on the setup, parties can include the platform operator, model vendor, merchant or Merchant of Record (MoR), payment service provider (PSP), and end customer.
| Actor | What they usually control | Where exposure often shows up first | What to verify now |
|---|---|---|---|
| Platform operator | User experience, transaction policy, routing logic (when they control checkout) | Confirm with the relevant authority | Policy approvals, payment-routing ownership, and whether logs can reconstruct decisions |
| Model vendor | Model behavior and sometimes tool calls | The excerpts do not show model vendors reimbursing chargebacks by default | Whether terms cover payment accuracy, dispute support, or only general service commitments |
| Merchant or MoR | Transaction acceptance, fulfillment, customer-facing sale | Chargeback reimbursement can land here first, including cases where the shopper never visited the merchant site directly | Who is merchant of record, who receives disputes, and who reimburses the bank |
| PSP | Processing access and dispute-process framework | Confirm with the relevant authority | Contract terms for dispute handling, fees, and evidence obligations |
| End customer | Payment authorization and dispute initiation | Card disputes and refund requests can start here; recovery depends on the payment rail | Evidence of consent, account control, and delivery |
In the examples cited here, merchants are often the party reimbursing banks for chargebacks, including cases where the shopper never visited the merchant site directly. A valid payment token can support authorization, but it does not remove later dispute exposure on its own.
Some payment methods can shift formal chargeback liability to a digital wallet provider, while the merchant may still absorb indirect fraud costs.
Use this internal rule: if your company controls the user experience, sets transaction policy, and routes payment, treat that as a likely exposure point unless contracts clearly reallocate it.
That rule helps because technical distance is not a reliable shield by itself. In these examples, even when authorization data looks valid, downstream disputes can still return to the commercial side.
A common mistake is treating rail availability as liability acceptance.
The same caution applies to model vendors. Their systems may influence the outcome, but the excerpts do not show them as the default party carrying refunds, chargebacks, or customer remediation.
Consumer protection can also vary by rail: card flows include a dispute path, while stablecoin payments may be irreversible.
Before launch, run one disputed-payment scenario from each actor's viewpoint:
- What would the customer ask for first?
- Which party would the bank or PSP contact?
- Who can actually produce the evidence?
- Who can pause, refund, or reverse?
- Who has a contract path to recover loss later?
If the answers point to different parties for different steps, document that clearly. That is normal. What is dangerous is leaving those handoffs undefined.
Legacy SaaS terms are where many platforms lose before the incident starts#
Exposure often starts before any incident, when the contract was written for classic SaaS rather than AI workflows that can influence live transactions. If the paper does not match the operating risk, remediation gets harder when something goes wrong.
A traditional Software as a Service (SaaS) model is subscription-based and multi-tenant. That structure is often framed around availability and support commitments. Agentic AI workflows can coordinate multi-step actions, so risk is not only about uptime. It can also involve security, bias, and network lock-in concerns.
The problem is not that old SaaS terms are useless. It is that they may emphasize service levels without clearly describing how an incident will actually be investigated. In an agentic payment dispute, teams may still need to establish what happened inside the service, what records can be accessed, and how quickly incident details can be reconstructed.
How should you read the contract like a loss map?#
Treat contract review as a pre-incident control. For each model-vendor and orchestration agreement, check what is explicitly stated about:
- payment accuracy expectations
- security obligations
- dispute cooperation workflows
- loss allocation language for transaction failures
- records you can access when investigating disputed events
If those points are missing or vague, treat recovery outcomes as uncertain and plan your rollout, reserves, and operating controls accordingly.
Reading the contract like a loss map means following the likely incident path line by line. If a transaction is challenged, which clause tells you whether logs are preserved? Which clause tells you whether investigation support is available? Which clause addresses security events tied to credentials or access? Which clause, if any, speaks to payment-related failures rather than only generic service interruptions?
If you cannot point to those terms, do not assume they exist by implication. In practice, silence can leave responsibilities unclear when losses are being debated.
Why old SaaS assumptions break here#
The mismatch is operational. Deterministic, control-heavy systems are described as more resilient, while probabilistic use cases are described as more exposed. When AI output can affect money movement or trigger multi-party fulfillment, the real question is not just whether service stayed up. It is whether you can reconstruct what happened, when it happened, and who controlled the final decision path.
That is why uptime credits alone may not resolve a transaction dispute. If evidence-access and cooperation terms are thin, remediation can become slower and more uncertain while responsibility is still being debated.
Another way to see the mismatch is to compare what each model assumes after a failure. Traditional SaaS contracting may focus on service restoration or a limited credit. Agentic payment incidents can require additional operational detail: prompt preservation, context reconstruction, tool-call history, version visibility, and coordinated explanation across multiple parties. If the agreement does not support those tasks, it may not match the real operating risk.
This is also where internal procurement habits can create avoidable exposure. If negotiations focus only on price, term length, and uptime, the company may lose bargaining room on clauses that matter during an incident. By the time a disputed payment happens, those missing rights can become expensive.
Clauses worth pushing for#
When negotiating, push on terms tied to real failure handling, not only generic service commitments. Areas to clarify include:
| Clause area | Clarify |
|---|---|
| Incident notice | events affecting transaction integrity or security |
| Audit logs | access, retention, and export rights |
| Model/version visibility | for disputed actions |
| Security commitments | credentials, access control, and subcontracting |
| Liability limits | how they apply to payment-related events |
| Failure-type allocation | so different failure modes are not collapsed into one vague category |
Before launch, test whether the agreement supports a real investigation. If your team cannot quickly obtain a usable event record, your recovery position may be weak too.
That test should be concrete. Ask: if a payment executed wrongly this week, how would we get the relevant logs, version details, and execution history? Who would we contact? What format would the records arrive in? How long would it take? If those answers depend on goodwill rather than contractual duty, treat that as a material weakness.
One final warning sign is a negotiation focused only on price, term, and uptime. In agentic commerce, the contract needs to reflect how transaction failures actually happen and how they will be resolved.
It is also worth checking whether the contract uses broad language that groups all failures together. A policy defect, a credential issue, and a model behavior issue are not operationally the same. If the paper treats them as one undifferentiated category, later recovery efforts may become harder because the agreement never anticipated the distinctions your incident team will care about most.
Compliance duties still apply in agentic payments#
Letting an agent initiate or complete a payment does not remove compliance duties. For a 2026 rollout, PCI DSS 4.0 and AML obligations still apply, so this is not only a vendor-contract issue. The same is true for KYC controls on payment platforms when the agent changes who submits or routes the transaction.
A useful baseline is to separate the payment channel from the transaction obligation. AML obligations are transaction-level, not channel-level, and PCI DSS 4.0 is still in effect.
That means the compliance question is not "was an agent involved?" It is "what facts did the agent change?" Did autonomy affect who initiated the transaction, whether explicit approval or preset limits were in place, what trigger logic executed, or what records exist? Those are the facts that can change the operating burden.
Autonomy changes the facts, not the duty#
Map your risk before launch using two practical tiers. The spend-control policy playbook for virtual cards is a useful analog when you are translating preset authority into machine-enforced limits. In assisted e-commerce, the user gives explicit approval before payment execution. In semi-agentic setups, the agent can execute with minimal or no extra input once preset conditions are met.
As autonomy increases, the line between human- and machine-initiated transactions gets less clear. That makes evidence quality more important. Approval events or preset limits, trigger logic, and execution records should be clear enough for both compliance review and dispute handling.
The operational difference between the two tiers is often the quality and timing of proof. In assisted flows, teams should be able to show the approval event tied closely to the payment event. In semi-agentic flows, teams should be able to show the preset authority, the conditions under which it could be used, and the record that those conditions were met when execution happened.
If either of those records is thin, the problem is not only dispute handling. It can also make internal control review harder, because the company cannot demonstrate how autonomy was bounded at the point of use.
A practical standard here is consistency. Whatever approval or preset-limit model you use, the evidence should be captured the same way every time, stored where it can be retrieved, and tied to the exact execution record. Inconsistent evidence packs create avoidable doubt.
Why does the jurisdiction picture change?#
Jurisdiction changes the operating burden even when the payment flow looks similar. In the European Union, payment questions can sit inside a wider compliance stack. Teams may need to assess the EU AI Act alongside other EU digital-law and data obligations, and that overlap can make implementation more complex.
Across markets, treat 2026 exposure as a partner-and-contract execution question from day one. Confirm how partner rules and your agreements apply to the exact agent flow you plan to run.
The main operational takeaway is not that one region is simple and another is not. It is that the same product behavior can create different review paths depending on where you deploy it and which counterparties support it. A flow your PSP is comfortable with in one market may require different confirmation, records, or restrictions in another. That is why country-by-country and partner-by-partner mapping matters before rollout.
This is also where local operating partners become important. They can surface issues that are easy to miss in a centralized design review, especially around customer-facing records, merchant structure, and incident response expectations. If the local view conflicts with the product view, resolve that before go-live.
A confirmation sequence worth using before launch#
Before rollout, work through the counterparties in the order that will matter during an incident:
| Step | What to confirm |
|---|---|
| Start with your PSP or acquiring partner | Describe the exact flow, including assisted vs semi-agentic behavior, and confirm required controls and records |
| Confirm the Merchant of Record structure | Define who handles refunds, chargebacks, and customer-facing records in each market |
| Lock the evidence pack before rollout | Keep approval or preset-limit records, predefined trigger logic, timestamps, and clear execution records |
Use that order because it follows the real incident path. The PSP or acquirer will matter immediately if a payment is challenged. The merchant or MoR structure will determine who faces the customer and who handles chargeback mechanics. The evidence pack will determine whether you can explain the event coherently once questions start coming in.
When you lock the evidence pack, make sure it is usable by more than one team. Compliance, payments, legal, and operations should all be able to work from the same record set rather than separate screenshots or email threads.
For a 2026 go-live, that pack should include the current PSP approval, the merchant or MoR map for each market, the policy version in force, the execution trace, and the escalation contacts that will matter during a dispute. If a 2025 pilot memo or sandbox approval is the only written sign-off, refresh it before launch.
Treat the pack as a living control. Re-run the confirmation sequence whenever merchant routing, model permissions, spend limits, or partner terms change in 2026. If we cannot reconstruct the exact execution state from our records on the same day, we should assume the flow is not ready for broader rollout.
Frequently Asked Questions
Why is first loss usually operational, not final?
Because the party closest to customer remediation or payment execution often has to refund, reverse, or investigate first, while later recovery depends on contracts, records, and jurisdiction-specific rules.
What changes when you move from traditional automation to agentic execution?
The analysis shifts from whether a fixed rule fired correctly to what authority, context, data, and execution path were active when the agent acted.
Do protocols improve handoffs without changing liability?
Yes. Protocols can make system handoffs cleaner, but they do not on their own reassign refund, dispute, compliance, or cooperation duties.
How should you read the contract like a loss map?
Follow the likely incident path and confirm who must preserve logs, provide investigation support, address security events, and respond to payment-related failures.
Why does the jurisdiction picture change?
The same agent flow can trigger different review paths by market, depending on local law, PSP expectations, merchant structure, and incident-response requirements.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
Includes 3 external sources outside the trusted-domain allowlist.
- digital-strategy.ec.europa.eu/en/policies/regulatory-framework-aitrusted
- europarl.europa.eu/RegData/etudes/STUD/2025/778575/ECTI_STU(202...trusted
- ir.lawnet.fordham.edu/cgi/viewcontent.cgitrusted
- sec.gov/Archives/edgar/data/2003292/0002003292260000...trusted
- sec.gov/Archives/edgar/data/1321655/0001321655250000...trusted
- a16zcrypto.com/posts/article/agentic-commerce-wont-kill-cardsexternal
- ari.us/wp-content/uploads/2025/08/AI-Liability-Repo...external
- finextra.com/blogposting/30917/when-ai-agents-pay-who-own...external
Educational content only. Not legal, tax, or financial advice.
Related Posts

Chargebacks in Agentic Commerce: Evidence Liability and Recovery Workflows for Platforms
For platform founders, the hard call is no longer just how to stop fraud. You also have to handle disputes where the payment was authorized, but the buyer later says the result was not what they meant to approve. That gap between "authorized" and "wanted" is where much of the new risk sits. It gets wider when an AI agent can browse, compare options, fill carts, and complete purchases on a customer's behalf.

How OTAs Should Structure Payments for Hotels, Hosts, and Agents
Travel payment operations are not standard ecommerce operations. In travel, you often deal with deposits, chargebacks, and high-ticket bookings that may not be fulfilled for months. Much of the complexity sits in the gap between charge, fulfillment, and payout, where finance exceptions and reconciliation issues surface.

Agentic Commerce for Platform Operators: How to Prepare Your Payment Infrastructure for AI Agents
Move now, but do not launch on hype alone. Agentic commerce is moving from concept into practical implementation. Your payment risk still comes down to the same core controls: who authorized the transaction, what the agent was allowed to do, and who is accountable when a transaction is fraudulent or incorrect.