
Quick Answer
Platform operators should prepare for AI agents by treating launch as a control design decision, not a channel decision. Define what the agent can do, retain proof of user authority, assign accountability for errors or fraud, verify primary and fallback rails, choose the integration model before engineering starts, and launch only with a complete evidence pack, clear ownership, and live fallback paths.
Move now, but do not launch on hype alone#
Move now, but do not launch on hype alone. Agentic commerce is moving from concept into practical implementation. Your payment risk still comes down to the same core controls: who authorized the transaction, what the agent was allowed to do, and who is accountable when a transaction is fraudulent or incorrect.
Before you start, anchor the risk. Kearney describes agentic commerce as shopping and payment experiences where AI agents act autonomously for users. It projects that AI shopping agents could account for roughly $10 trillion to $12 trillion in annual online sales by 2030. Forecasts at that scale can push roadmap decisions ahead of clear control ownership.
At the same time, current payment systems generally assume a human is directly clicking buy. In agent-led flows, the core question is more specific: what proof do you have that a user authorized this purchase, and who owns the outcome if a transaction is fraudulent or incorrect?
Step 1. Define the decision as a control question#
Treat launch as a control design decision, not a channel decision. Before go-live, write down:
- What the agent is allowed to do
- What proof of user authority you will retain
- Who owns accountability if a transaction is fraudulent or incorrect
If you cannot trace a request from user intent to payment initiation with clear authorization evidence, treat that as a no-go.
Step 2. Sequence the work before engineering commits#
Use a deliberate order: market selection, integration model, control ownership, authorization and fraud boundaries, evidence requirements, then expanded autonomy. This helps keep execution from outrunning governance. If timelines are tight, start with narrower scopes and expand only after controls are working as designed.
Step 3. Use measurable readiness checks, not narrative milestones#
Use observable checks early. Stripe's field guidance highlights two practical baselines for nonhuman traffic patterns:
- Set rate limits to prevent agentic bursts
- Cache read-heavy API endpoints to prevent time-outs
Also plan for a fragmented network. Google's AP2 announcement presents AP2 as an open protocol for secure agent-led payment initiation and as a way to reduce interoperability risk in a fragmented market. Related work such as A2A, plus AP2 requirements like Verifiable Digital Credentials, shows where controls are heading. None of that replaces your own authorization model, accountability map, and go or no-go criteria.
The sections that follow stay focused on operator decisions: where to launch first, how to compare integration paths, which controls must exist before go-live, and when to scale autonomy.
For a step-by-step walkthrough, see How Platform Operators Triage Late B2B Payments Before Market Entry.
Anchor the definitions before you commit roadmap#
If a customer still has to approve the payment at checkout, label that flow agent-assisted in roadmap and risk documents. Reserve autonomous execution for flows where software can execute within documented limits, because the label determines the control evidence you need before launch.
Step 1. Use execution as the boundary, not the presence of AI#
Use a strict line: the shift is from decision support to autonomous execution. AI agents can act on instructions without human input at every step, but assisted checkout is still assisted checkout when a person approves the payment.
Step 2. Standardize language before it enters planning#
Do not let teams use one term for different behaviors. Keep a shared taxonomy page for product, payments, risk, and compliance, and use only two labels:
- Agent-assisted: software helps, the customer still approves payment
- Autonomous execution: software can initiate within documented limits
Verification checkpoint: if product, risk, and payments ops do not assign the same label to the same flow, pause and fix definitions before engineering starts.
Step 3. Tie each label to control evidence#
Do not accept autonomy claims based on naming alone. Use authentication, authorization, and verification as the baseline. Then define boundaries such as allowing agent refunds up to a set limit and requiring human approval above that threshold.
Before launch, require artifacts that show those controls work in practice, including dry runs and cryptographic trails. If an agent acts under the wrong identity or outside its boundary, the result can be fraud losses, compliance failures, and customer churn.
Once the labels are fixed, you can decide where the controls are strong enough to launch. For accounting-system payment intake, read How Platform Operators Accept Payments Through QuickBooks.
Pick your first launch markets with a gating matrix#
Choose first-wave markets by operational readiness, not headline demand. If a row does not yet have a verified primary rail and fallback rail on day one, keep that row as unknown instead of launch-ready.
Step 1. Build rows at the country-vertical level#
Build the matrix around country-vertical pairs so payments, risk, and compliance are scoring the same operating context. Keep Open Banking and A2A payments as separate rails when they are in scope, and mark any unverified rail claim as unknown.
| Matrix column | What to confirm before green |
|---|---|
| Primary rail fit | Named provider, supported flow, settlement path |
| Fallback rail fit | Alternate rail or provider, failover path |
| Fraud exposure | Owner for disputes and abuse, plus review path |
| Compliance and reporting readiness | Named owner, review checklist, entity review |
| Operational readiness | Acquiring status, payout reliability check, support coverage |
Step 2. Add a real compliance-readiness gate#
If cross-border money movement is in scope, treat compliance readiness as a launch gate, not a placeholder. Name the owner for entity review, provider and rail policy checks, reporting review, and escalation before a row turns green.
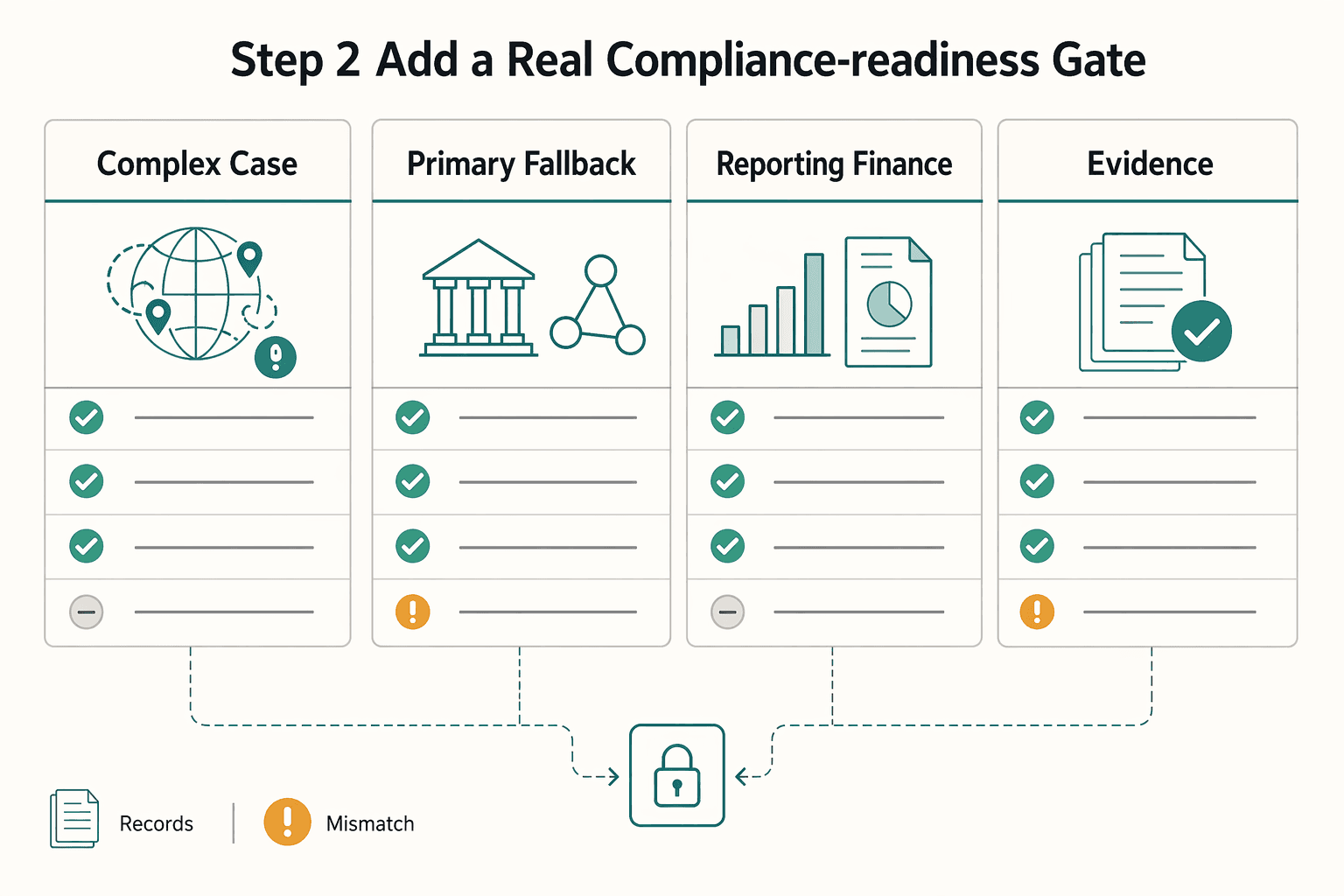
| Compliance item | When to review | Key note |
|---|---|---|
| Entity and market scope | Before a row turns green | Confirm which operating entity, merchant model, and provider contract actually apply |
| Primary and fallback rail coverage | Before launch and after routing changes | Verify the settlement path, failover path, and named exception owner |
| Reporting and finance ownership | When cross-border money movement or payouts are in scope | Keep reporting, withholding, and escalation ownership explicit rather than implied |
| Evidence retention | Before live traffic | Keep approval records, event trails, and reconciliation evidence retrievable |
Capture edge cases in notes, not assumptions. Requirements can change by entity structure, provider setup, rail, and market, so route unresolved finance or legal questions before you mark a row green.
Use the same matrix rule for adjacent reporting flows: if a row introduces a new payout structure or cross-border money movement, readiness is not complete until reporting ownership and escalation are explicit.
If the owner is unclear or the review status lives only in chat threads, the row is not ready for a first-wave launch.
Step 3. Score readiness with evidence, then rank by resilience#
Score each row on confirmed operability: local acquiring path, dispute handling readiness, payout reliability, and support ownership for exceptions. If any of those checks are unverified, keep that row as unknown and score it down automatically.
When demand looks similar across rows, pick the one with stronger redundancy and fewer unresolved compliance questions. The rule is simple: no first-wave market should be marked launch-ready without a verified primary rail, a verified fallback rail, and clear ownership for compliance and exception handling. After you know where you can launch, decide how much payments maintenance you want to own.
For A2A and open-banking payment options, read Open Banking for Platform Operators: A2A Payments.
Choose your integration model before engineering starts#
Choose your model based on maintenance ownership first, then price. Stripe Connect frames the core tradeoff directly: you can offload payments maintenance to Stripe or keep full control and ownership of payments.
Step 1. Price the maintenance decision, not just the transaction fee#
A centralized path through Stripe can reduce how much payments maintenance your team carries. A more self-managed path gives you more control, but your team also keeps more integration ownership.
| Fee item | Amount | Note |
|---|---|---|
| Successful domestic card transaction | 2.9% + 30¢ | Per successful domestic card transaction |
| Managed Payments fee | 3.5% | Additive to standard processing fees |
| Monthly active account | $2 | Connect self-pricing; active means a month when payouts are sent to a user's bank account or debit card |
| Payout sent | 0.25% + 25¢ | Connect self-pricing per payout sent |
Model the full fee picture before build starts. Stripe pricing lists 2.9% + 30¢ per successful domestic card transaction, and Managed Payments pricing notes the 3.5% Managed Payments fee is additive to standard processing fees. For Connect self-pricing, Stripe lists $2 per monthly active account and 0.25% + 25¢ per payout sent. "Active" means a month when payouts are sent to a user's bank account or debit card.
| Decision area | More centralized via Stripe | More self-managed |
|---|---|---|
| Maintenance ownership | More offloaded | More retained in-house |
| Custom control | Lower | Higher |
| Cost model focus | Processing fees plus any additive managed fees | Processor fees plus internal engineering and support load |
| Ongoing operations | Fewer integrations to maintain directly | More direct integration maintenance and testing |
Gateway fees can materially affect profitability, so treat speed and margin as one decision.
Step 2. Verify the prep work your model creates#
Whichever model you choose, confirm the readiness basics before approval. These checks help verify the design is ready for live agent traffic:
- Deploy a product feed
- Confirm file and firewall settings welcome agents
- Set rate limits to prevent agentic bursts
- Cache read-heavy endpoints to reduce timeout risk
Step 3. Commit to an explicit support posture#
Approve the model only when ownership is named and operating checks are documented. Keep a short evidence pack with your chosen model, fee assumptions, integration owners, feed owner, incident triage owner, rate-limit settings, and cache plan. That keeps the decision operational, not just architectural. Once the model is chosen, make the operating boundaries explicit.
For benchmark context on platform payment operations, read State of Platform Payments: Benchmark Report for B2B Marketplace Operators.
Define your payment control plane and ownership map#
Define the control plane before pilot work starts: set an internal rule that every payment mutation has one owner, one trace, and one alert destination. Without that, launches drift into cross-tool debugging instead of controlled operations.
Step 1. Map the full path, not just the charge#
Put the end-to-end flow on one page: request intake, decisioning, payment initiation, settlement events, ledger posting, and exception handling. If you use a payment provider, show what runs through provider APIs, what is reviewed in provider dashboards, and what remains in internal ops tools.
Keep the merchant-control boundary explicit. The Checkout API pattern is useful because it is merchant-run, stateful, and returns the latest authoritative checkout state on each call. That gives you a clear ownership anchor for cart state, fulfillment choices, and payment initiation.
A practical test is whether someone outside engineering can point to one artifact and answer where the request entered, where money movement was initiated, and where exceptions are escalated.
Step 2. Assign named owners at each control point#
Assign people, not just teams, to each control point. In practice, one workable split is named ownership across product, payments ops, risk, compliance, and engineering escalation, even if one person covers multiple areas early on. Prioritize decision authority over org-chart purity:
- Product: intended user behavior and approval paths
- Payments ops: transaction handling and exceptions
- Risk: review and block decisions
- Compliance: recordkeeping and policy interpretation
- Engineering: failures that require code, config, or integration changes
If ownership is shared or implicit, exceptions usually end up in manual cross-system reconciliation, which is a known source of delay and operational strain.
Step 3. Require idempotency and replay rules at every mutation#
Document retry behavior at every mutation point. Use Idempotency-Key where retries could otherwise create duplicate processing, and require Request-Id for request-level tracing and debugging. Keep API-Version explicit with a YYYY-MM-DD date, for example 2026-01-30, so you can identify the active contract during incidents.
Your map should define behavior for timeouts, duplicate submissions, and late settlement events. You should be able to prove from logs and audit trails whether a retry was a safe replay or a new instruction.
Step 4. Gate the pilot with an evidence check#
Use a clear go-live gate. A practical internal bar is to confirm each control point has a named owner, an audit artifact, and an alert destination. The artifact can be a dashboard view, event log, ticket trail, or reconciliation record, as long as it supports exception escalation with full audit trails.
Verify these baseline controls before launch so provider dashboards, provider APIs, and internal tooling function as one controllable plane instead of disconnected systems:
- Bearer-token validation is checked on every request
- Endpoints use HTTPS and JSON
- Session creation rejects malformed checkout requests, including requests without at least 1 item
With ownership mapped, set the line between user intent and payment authority.
For labor-market payment trends that shape rollout priorities, read Gig Economy Payment Trends 2026 for Platform Operators.
Lock down authorization, fraud, and liability boundaries#
Set a hard boundary: customer intent is not payment authorization. If you blur the two, you can increase dispute risk, weaken fraud review, and create liability confusion when an agent acts beyond what the user expected.
Step 1. Separate intent capture from payment authorization#
Treat prompts, chat messages, and agent goals as intent signals only. In current market reality, checkout remains the main trust checkpoint, so require an explicit authorization event at checkout or another clearly defined approval surface before payment initiation.
Name the exact artifact that converts intent into authorization, such as a confirmed checkout state, an approval click, or another retrievable consent record. Then verify that you can show, in order, the agent request, user approval artifact, payment initiation event, and resulting ledger entry.
Step 2. Define fraud controls by rail and channel#
Use fraud controls by rail and by channel, not one blended profile. In agent-driven server-side flows, some human-centric signals can be thinner, so your checks should reflect that.
Include extra review triggers for assistant-originated transactions based on your own risk posture and evidence quality, not assumed industry-mandated rules. For each rail and channel, define:
- Required proof of user approval before authorization
- Events that trigger step-up review, hold, or rejection
- Evidence retained for disputes, reversals, and abuse investigations
Step 3. Document liability assumptions before launch#
Do not assume the historical four-party model cleanly covers agentic flows. A common framing is a "fifth participant" layer, where the agent sits between cardholder and merchant and complicates first-loss expectations.
Write down, for each transaction type, who handles first-line operational response and remediation across platform, processor, and merchant counterparties when consent is disputed, authorization fails, or post-settlement disputes appear. If that allocation is vague, minor incidents quickly turn into loss-allocation fights.
Step 4. Block silent escalation from assisted to autonomous execution#
Do not let an agent move from assisted actions to autonomous execution without explicit policy approval and a fresh authorization condition. Fully autonomous buying is not yet market standard, and moving too aggressively can mean giving up control too early.
Reject hidden upgrades. That includes reused approvals for broader spend authority, retries that create new payment attempts without renewed consent, and channel handoffs where browsing behavior turns into payment initiation without a clear user-state change.
Once those boundaries are set, collect the proof you will need when something goes wrong.
For B2B settlement between marketplace operators, use Platform-to-Platform Payments: How to Build B2B Settlement Between Two Marketplace Operators.
Prepare the prerequisite evidence pack before launch#
Launch only when your evidence pack can answer one operating question across ops, risk, and finance from the same file set, with operational control artifacts kept separate from market-specific legal or reporting trackers.
Step 1. Build the core launch file#
Collect the documents you will use during reviews: a responsibility matrix with named owners, current approval language, an escalation guide, and current endpoint contract tests for the payment surfaces in scope.
Your readiness check is simple: for one in-scope payment flow, you can retrieve the current approval language, current endpoint contract, current reconciliation owner, and escalation path without cross-team guesswork.
Step 2. Add cross-border reporting trackers only where they apply#
If your rollout spans multiple entities, markets, or payout structures, add a separate finance and legal sub-pack only where it actually applies. Tie each obligation to the operating entity, launch market, payment rail, named owner, and review cadence.
Do not treat one market's answer as universal. Requirements change by entity structure, provider model, rail, and geography, so keep the decision record with the row instead of relying on memory or inherited assumptions.
The practical bar is simple: when someone asks whether a row can launch, you can show the owner, the current status, and the escalation path without reconstructing it from Slack or email.
Step 3. Pre-stage operational failure scenarios#
Before launch, pre-stage scenarios for stale tokens, duplicate events, timeout retries, and partial-settlement or reconciliation mismatches. For each scenario, store the test input, expected payment result, expected ledger result, and expected escalation path.
Step 4. Require one traceable event trail per critical flow#
Before launch, require one retrievable trail per critical flow: request, approval artifact, payment event, ledger entry, and reconciliation export. If any part of that chain is missing, treat it as a launch blocker rather than a post-launch cleanup task.
Once the pack is complete, you can roll out in phases without guessing what to do when the first exception hits. For benchmark context on subscription payment operations, read Subscription Benchmark Report for Platform Operators: Churn Trials Payment Declines and LTV.
Before pilot sign-off, map your control artifacts and ownership handoffs against your implementation surfaces in the Gruv docs.
Roll out in phases and keep fallback paths live#
One practical rollout pattern is to phase agent-led payments and keep fallback checkout plus manual intervention available as scope expands. That helps limit blast radius while you validate live transaction outcomes in production.
| Phase | Agent scope | What stays live | Gate to expand |
|---|---|---|---|
| Phase 1 | Discovery, comparison, carting, handoff to checkout | Standard checkout, manual intervention path, non-agent channel | Structured API data remains reliable for comparison, inventory checks, and pricing validation on assisted flows |
| Phase 2 | Constrained payment initiation inside a defined checkout contract | Same fallback checkout and intervention path | Contract inputs/outputs are consistently valid, reliability holds, and latency stays acceptable |
| Phase 3 | Expanded autonomy for approved merchant coverage and policy conditions | Fallback paths remain active | Reliability and latency stay stable as coverage widens, and fraud-related cancellation risk remains contained |
Step 1. Start with agent-assisted discovery and carting#
Start where the agent helps without owning the highest-risk action. Focus on discovery, inventory checks, price comparison, and cart assembly, while conventional checkout still completes payment.
This aligns with agent-led commerce as a mix of human-assisted and autonomous interactions. It also helps you surface an early known failure mode: cross-storefront complexity that can force human-in-the-loop fulfillment or narrower merchant coverage.
Step 2. Add constrained payment initiation#
Move to payment initiation only after you can validate a clear checkout contract end to end. The checkpoint is explicit inputs and outputs: PDP URL, buyer identity, and tokenized payment method in, confirmed merchant order and status out.
Keep this phase constrained so you can verify performance under live traffic. Gate expansion on operational signals, not narrative milestones: checkout reliability, checkout latency, and safe fallback usage.
Step 3. Expand autonomy only after metrics hold#
Expand autonomy only when the Phase 2 signals remain stable after scope increases. If reliability drops, latency rises, or fraud-related cancellations increase as coverage widens, reduce scope before expanding again. The tradeoff is straightforward: faster autonomy expansion increases coverage speed, but it also increases operational complexity and incident blast radius.
Step 4. Keep fallback paths genuinely usable#
Fallbacks are only real if they are active, staffed, and tested. Keep non-agent channels and manual intervention operational while agent and non-agent paths run in parallel.
Re-test fallback execution against layout-change and cross-storefront failure cases you see most in production. If a failed order cannot be traced from checkout request to merchant order status, pause expansion and restore control first.
Track the metrics that should stop or scale rollout#
Blended conversion and revenue can hide risk, so split channel reporting first, then evaluate payment performance and operational control together before adding a market.
Step 1. Separate channel reporting at the event level#
Track ChatGPT, Perplexity, and direct web flows as separate channels from first request through final ledger entry. Do not roll agent traffic into a generic "AI" bucket or mix it with standard web checkout in headline metrics.
This separation matters because completion paths are mixed: some orders finish in merchant checkout, some in retailer apps, and some in in-ChatGPT app flows. For every paid order, you should be able to identify the channel, the completion path, and a complete event trail without manual reconstruction.
Step 2. Pair payment metrics with ops signals#
Treat payment and control signals as one operating set, including measures like auth success, disputes, manual review load, settlement delays, and ledger-reconciliation breaks. A channel can look strong on clicks or carts while increasing manual handling, slowing settlement, or breaking downstream posting.
A common failure mode is stale or inconsistent commerce data. If product, pricing, availability, taxes, shipping, or fulfillment details are not accurate and timely for agent channels, issues can appear in support and finance before top-line dashboards do. Check merchant logs for early signals, then confirm the order data used by agent channels is the same data finance reconciles later.
Step 3. Define pause triggers before launch#
Set internal pause triggers before launch, with thresholds defined by market and risk profile. The key is pre-commitment: when a trigger is crossed, it routes to named owners across payments ops, risk, engineering, and finance instead of becoming an incident-time debate.
Use an escalation table that maps each metric to an owner and a first review artifact. If a reconciliation break cannot be traced to a specific channel and completion path, pause expansion and fix observability first.
Step 4. Use clean reporting cycles before expansion#
A practical internal guardrail is to wait for two consecutive reporting cycles that meet your quality and control targets before opening the next market. This is an internal policy choice, not a universal rule, but it helps avoid scaling on one good week.
This matters because payment rails vary by region, and early momentum does not prove stable conversion. The fastest-growing channel is not always the safest one to expand first. Stable controls should beat noisy growth.
Fix common operator mistakes before they become expensive#
After you set pause triggers and rollout gates, remove the avoidable mistakes that make those triggers fire. Treat market momentum as context, not readiness, and do not scale agent-led payments until ownership, fallback, and evidence are already operating.
Step 1. Re-run your market matrix without vendor momentum baked in#
A launch announcement is not a control. If your team is combining category framing and market optimism into one maturity score, split them and score launch readiness on controls you can run now.
Use separate columns for market narrative and live control readiness: named owners, fallback checkout, reconciliation traceability, and documented handling when agent actions are wrong or non-consensual. The practical check is simple: if a provider surface changed or disappeared next quarter, would order flow, ledger traceability, and exception handling still hold?
A new vendor surface or pilot can be useful input, but it is not a control baseline. Treat announcements and early merchant examples as provisional until your own fallback, reconciliation, and exception handling still work when that surface changes.
Step 2. Assign protocol ownership before incident response is needed#
Protocol ownership must be explicit before expansion. If you support agent-facing standards, assign one accountable team for standards tracking, version compatibility testing, and release signoff.
Keep ownership concrete: a named owner, a test cadence, and documented version assumptions in release artifacts. If you are evaluating newer intent standards, stay precise: a published spec or reference implementation is not the same as live commerce or payment-stack integration.
This matters because delegated checkout moves purchase actions into background API calls, and that challenges legacy human-present intent assumptions in payments. Without clear ownership, retries, authorization evidence, and dispute handling tend to drift together.
Step 3. Add secondary rails and a real manual fallback#
Do not depend on one provider surface for cash movement. Add a secondary payment rail and keep a tested manual fallback for exceptions.
Tested is the key requirement. A fallback that exists only in planning documents often fails when the primary path stalls or an agent request is malformed. Run live drills that confirm ops can move orders without losing event trails, customer-intent records, or reconciliation links.
Set this up early because liability allocation is still unsettled in agent scenarios. CBA notes that EFTA unauthorized-transaction protections may not map cleanly when agents are involved and that consumers may absorb losses in some cases, while other commentary describes scenarios where merchants absorb losses.
Step 4. Enforce an evidence pack before opening the next market#
Weak documentation hygiene turns normal exceptions into expensive support and finance work. Require a standard evidence pack for incidents, reversals, and reconciliation breaks before approving expansion.
| Evidence item | Must include |
|---|---|
| Incident timeline | Channel, completion path, and owner actions |
| Authorization artifact or customer-intent record | Used for the transaction |
| Payment event trail | Request through settlement and ledger posting |
| Reversal or refund records | Timestamps and linked order IDs |
| Reconciliation notes | Resolution or escalation path |
If a market cannot produce this pack within one review cycle, pause expansion. For a forward-looking subscription commerce view, read Future Subscription Commerce Predictions for Platform Operators Through 2027.
Map Gruv modules to your target architecture#
If your team requires an evidence pack, the architecture decision gets simpler: map Gruv to the control point that is already creating operational drag, not to every layer at once.
Before you start, document the current path. Write down your flow from request intake to final posting as a step sequence. For each step, note the input event, decision owner, output artifact, and fallback path. If those steps are unclear today, add that clarity before introducing a new control layer.
Step 1. Trace the current flow before placing any module#
Treat the architecture map as an execution path, not a logo diagram. It should show how work moves when things go right and what happens when they do not.
Use one successful transaction and one failed or retried transaction as your checkpoint. If you cannot trace both from request source to your current reporting destination, fix the map first.
Step 2. Attach Gruv to the bottleneck, not the whole stack#
Start where the pain is highest. If exceptions dominate, begin with the Gruv module that addresses that lane first. If visibility is the issue, begin with the control and reporting surface you need to tighten.
Keep evaluation narrow with a one-page fit note per module: what problem it addresses, what event it consumes, what artifact it must produce, and what fallback applies if it is unavailable. If those four points are not clear, the module is still in evaluation.
Step 3. Keep orchestration and controls separable by default#
If your channel-facing orchestration is currently stable, keep it stable and add Gruv controls in a separate step. That keeps change scope smaller and makes failure isolation easier.
When you test, require one evidence pack per case with event IDs, owner actions, and outcome notes. That keeps architecture decisions tied to observable behavior, not assumptions.
Conclusion and copy/paste launch checklist#
Do not scale autonomy just because the channel exists. Launch only when each item below is documented with an owner and a verification point.
- Label the current flow honestly as agent-assisted or autonomous.
If a person still reviews or approves payment, keep the flow labeled agent-assisted across product, risk, support, and finance. That keeps control design aligned with reality while shopping bots continue to advance faster than autonomous payment execution.
- Select first-launch markets with a scored matrix, not demand alone.
Score operational readiness across market options. Confirm you can normalize and syndicate catalog data and run fast availability checks. If those fail, agent flows can break early. Treat single-provider paths without a tested fallback as a launch risk.
- Choose the integration model and document tradeoffs before engineering starts.
There is no universal winner, but there must be an explicit choice. Record lock-in, control, and migration conditions up front, and define how scoped or shared payment tokens and payment handlers will be governed.
- Assign control owners and define pause/scale triggers before launch.
Every control point should have a named owner, an audit artifact, and a clear alert path. If you cannot show who responds and what evidence proves a control fired, you are not ready to scale.
- Complete the evidence pack, test scenarios, and reconciliation checkpoints.
Finish these before launch, not after: policy matrix, escalation and operating documents, API contract tests, and failure scenarios. The key checkpoint is a traceable event path from request through financial records and reconciliation output.
- Roll out in phases, keep fallback paths live, and scale only after live metrics hold.
Start narrow and keep non-agent fallback paths active while you validate operations. Multi-provider fallbacks matter in practice. Incident analysis across 215+ services reported a median resolution time of about 90 minutes, with frequent short AI API incidents and rarer high-blast-radius cloud failures. Use tight timeouts, caching, and circuit breakers so a dependency wobble does not become a full stop.
If every box is not checked yet, the next task is control readiness, not broader autonomy. If you want a market-by-market readiness review for controls, payouts, and compliance gates, talk to Gruv.
Frequently Asked Questions
Are agentic payments real today?
Yes, but most live examples still look constrained or assisted rather than broadly autonomous. Infrastructure providers, payment networks, and commerce platforms are actively building support, but that momentum is not proof of mature cross-market operations.
What is table-stakes for platform operators right now?
Table-stakes are controls that make agent interactions reliable and observable. A practical baseline is machine-consumable catalog data plus API protections such as rate limits for burst traffic and caching for read-heavy endpoints to reduce timeouts. If those basics are weak, scaling agent-driven payment flows can add operational risk before it adds value.
Should we use one integration layer or integrate each agent directly?
There is no universal best choice in the available evidence. Choose based on your operating constraints and decide maintenance ownership before price alone. Revisit the choice as protocols and partner requirements evolve.
What blocks scaling most often?
Unresolved liability and weak control posture are recurring blockers. The article also highlights a pattern where teams either over-block agent transactions or allow them with weak controls. When exception paths are unclear, edge cases can become risk and support incidents.
How do we plan when forecasts conflict?
Plan with phased rollout gates tied to live operating evidence, not headline forecasts. Keep scope narrow, measure real failure patterns, and keep fallback paths live while you learn. If signals conflict, fix the failing control point before expanding autonomy or reach.
Where do Open Banking and A2A payments fit?
This article does not provide enough evidence to make market-fit conclusions on Open Banking or A2A payments in that section. Treat them as rails to evaluate separately by market and operating model, not as automatic replacements for cards. Decide only after you have evidence for your specific countries, channels, and control requirements.
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
Includes 3 external sources outside the trusted-domain allowlist.
- stripe.com/guides/how-to-prepare-for-agentic-commerce-t...trusted
- stripe.com/connect/pricingtrusted
- support.stripe.com/questions/managed-payments-pricingtrusted
- checkout.com/blog/agentic-commerce-questions-answeredexternal
- cloud.google.com/blog/products/ai-machine-learning/announcing...external
- kearney.com/industry/financial-services/article/agentic-...external
Educational content only. Not legal, tax, or financial advice.
Related Posts

The Freelance Payment Penalty: A Modeled Audit of Platform Fees, FX Spreads, and Payout Delays
The money rarely disappears through a single, easy-to-spot fee. The real loss is stacked. A marketplace takes its commission, a processor adds a charge for international cards, a bank or payment company converts the currency at a spread, a platform holds the funds before release, and a wire sheds a little to intermediaries on the way in. Each layer looks defensible on its own, but the worker feels the combined result as a smaller deposit and a later payday.

How to Respond to a Subpoena for Business Records
Move fast, but do not produce records on instinct. If you need to **respond to a subpoena for business records**, your immediate job is to control deadlines, preserve records, and make any later production defensible.

A US Expat's Guide to Investing in UCITS ETFs to Avoid PFIC Issues
The real problem is a two-system conflict. U.S. tax treatment can punish the wrong fund choice, while local product-access constraints can block the funds you want to buy in the first place. For **us expat ucits etfs**, the practical question is not "Which product is best?" It is "What can I access, report, and keep doing every year without guessing?" Use this four-part filter before any trade: