
Quick Answer
Platforms detect fraud without blocking legitimate payments by starting with a small set of high-signal controls, mapping the full money flow, and routing alerts by risk tier and payout impact. Add friction only when evidence is mixed, keep traceable case records, and tune rules against two scoreboards: fraud-risk reduction and customer-impact reduction.
Why platforms struggle to stop fraud without blocking good payments#
Step 1. Name the tradeoff before you buy or tune anything#
The job is to catch fraud without choking legitimate payouts. If your controls stop more fraud by freezing every unusual payout, the loss shows up somewhere else: false declines, delays, and avoidable friction for real contractors and sellers.
That is why platform monitoring is harder than most demos suggest. You are trying to catch payment fraud and identity-related abuse while still clearing good payouts on time. False positives are expensive, so aggressive rules can damage approval outcomes quickly.
Monitoring is also often reactive. Alerts may fire after a fraud attempt is already underway, and some signals are weak on their own because advanced attackers can spoof them. A single device, identity, or transaction anomaly is rarely enough to justify a confident decision.
Verification point: before moving on, state in one sentence what matters more in your environment when there is a conflict: stopping a risky payout immediately or allowing a borderline payout to preserve speed and trust.
Step 2. Put the right owners in the room#
This is an operating-model decision, not just a software decision. Compliance, legal, finance, and risk owners need to agree on what can be delayed, what must be reviewed, what can be blocked, and what evidence is required before funds are held or released.
Detection alone does not solve much. A fraud detection system only helps when it leads to a defensible action, such as delaying or blocking a high-risk payment or adding extra authentication only for borderline cases. Risk-based authentication is usually the practical middle ground. Add friction where the evidence is mixed, not on every payment.
A broad rule rollout without clear decision ownership can fail in practice. Teams may discover too late that no one agreed on holds, overrides, or recordkeeping duties. If ownership is unclear, avoid broad enforcement. Monitoring without an owner creates noise. Enforcement without an owner can create customer harm.
Step 3. Commit to control checkpoints and evidence you can defend#
You need controls you can explain under pressure, not a feature matrix. The minimum standard is a set of checkpoints, escalation triggers, and reporting artifacts that still make sense in sensitive or audit-facing cases.
For multi-market monitoring, traceability is an important checkpoint. You should be able to reconstruct the path from trigger to final action, including why a payout was allowed, challenged, delayed, or blocked. Without retained transaction documentation and a clear case timeline, decisions are hard to defend later.
That reporting layer is also operationally necessary where audit-facing obligations apply, including recordkeeping and suspicious activity reporting processes such as SAR or CTR. With that foundation in place, the rest of this article focuses on operator decisions you can apply now: where checks belong, when escalation starts, what artifacts to retain, and how to reduce fraud risk without turning legitimate payouts into avoidable incidents.
If you want a deeper dive, read A Guide to Transaction Monitoring for High-Risk Payments.
Define success before you tune a single rule#
Once ownership and evidence are clear, define success in writing before you change thresholds. One metric is not enough. Track two lanes in parallel: fraud-risk reduction and customer-impact reduction.
Step 1. Set two scoreboards#
Keep Transaction Fraud Monitoring outcomes separate from customer outcomes so one noisy metric does not hide the other. One lane should show whether risky behavior is being caught more effectively. The second should show whether legitimate payouts are being disrupted through false blocks, extra reviews, or avoidable delays.
This matters because rule-based logic depends on predefined thresholds and static conditions. A rule like "more than a set amount within 24 hours" may catch abuse, but it can also create alert noise when normal behavior changes. Legacy rule-based systems can overwhelm review teams when alert noise is left untuned.
Verification point: before launch, answer both questions for each rule: what fraud pattern should it reduce, and what legitimate behavior might it interrupt?
Step 2. Name the tradeoff owner#
When Alert Prioritization conflicts with payout speed, assign one clear approver for that tradeoff. The approver does not need to be the rule author. Ownership does have to be explicit so analysts know who can accept tighter controls or faster payouts when those goals conflict.
A key failure mode is alert noise overwhelming teams and letting true threats slip through. Put the approver, fallback approver, and escalation trigger in the same rollout decision note.
Step 3. Write acceptance criteria before rollout#
Do not deploy new Rule-Based Detection logic without clear pass conditions. Define, at minimum:
- what counts as an unacceptable false block
- expected review turnaround for flagged payouts
- which alert types must always have escalation coverage
- what evidence must be present before a hold or release decision
If confidence is low, start with simulation or shadow rules before full enforcement. Rules are not set-and-forget, and static thresholds can be evaded over time. Keep an evidence pack with the rule purpose, owner, expected customer impact, test results, and an explicit rollback trigger if alert noise spikes.
You might also find this useful: Subscription Billing Platforms for Plans, Add-Ons, Coupons, and Dunning.
Map your money flow and fraud exposure points end to end#
A stage map is usually more useful than adding more thresholds. If you cannot show where money changes state, who acted, and what audit record remains, alerts can drift away from the real exposure.
Step 1. Draw the full path, not just the happy path#
Map the flow you actually operate, including exception paths. Document each stage your platform uses from initiation through settlement. For each one, record the start event, confirmation event, decision owner, and whether intervention is still possible before settlement.
Include asynchronous and manual paths too. If controls are tuned only on the first event while state changes later, blind spots can appear and intervention windows can be missed. The expected outcome is one stage map where each movement has an event name, owner, state change, and intervention point.
Step 2. Tag each stage with abuse patterns and the control expected to fire#
Use that map to tag likely abuse, then assign the control in your transaction monitoring software. Keep the labels simple, such as identity inconsistencies, unusual behavior versus account history, or other patterns that need review.
| Stage (example) | Abuse focus | Control to assign | Audit checkpoint |
|---|---|---|---|
| Entry stage | Identity inconsistency, unusual first-use activity | Rules plus scenario checks across transaction, account, and device signals | Is there an auditable record of the signal, decision, and action taken? |
| Account activity stage | Behavior inconsistent with prior usage | Behavior-based alerting with explainable risk scoring | Can you show which signal fired, who handled it, and what happened next? |
| Value movement stage | Rapid value movement inconsistent with normal pattern | Scenario monitoring on amount, frequency, and history | Can you explain why it was flagged and what control outcome followed? |
| Funding stage | Unusual funding pattern | Correlation checks across transaction and account data | Can you trace the alert and follow-on decision in your audit trail? |
| Payout stage | Cash-out abuse or high-risk anomalies | Real-time monitoring before settlement plus case escalation | Can you show pre-settlement intervention decisions and case follow-up records? |
Static rules still help, but mark the stages where rule-only logic is likely weak. If a stage ignores available transaction, account, device, network, or OSINT inputs, log that gap before rollout.
Step 3. Align controls to timing and traceability#
Timing and traceability need to be part of the control design. For each stage, capture when a decision was made, which control or version produced it, and the audit-trail records tied to the outcome.
Use one verification question across every stage: can your team explain the decision path and resulting action from the available audit trail? If that trace is incomplete, fix traceability before tightening thresholds.
One common failure to watch for is inconsistent state handling across systems, which can create conflicting records and weak auditability. For a related example, see Device Fingerprinting and Fraud Detection: How Platforms Identify Bad Actors.
Gather prerequisites and evidence before implementation#
Once your stage map exists, resist the urge to tune alerts right away. First confirm that your data, policy gates, and evidence are usable, or monitoring can generate noise reviewers cannot act on.
Step 1. Assemble the minimum data for context intelligence#
Context intelligence works when you can connect signals to the same customer, entity, and event. Start with transaction history, account behavior, and device or identity signals. The goal is context across time, channels, devices, identities, locations, and behavior, not maximum data collection.
For each data source, document the source record, join key, refresh timing, and owner. If key signals cannot be joined reliably, missed links and false alerts can increase.
Step 2. Confirm the policy dependencies before any hold logic goes live#
A risk-based monitoring program should rest on customer due diligence and ongoing monitoring, not on rules alone. If your CDD and AML gates do not define what information must exist before transactions proceed, hold and escalation decisions are hard to defend.
| Dependency | What to define |
|---|---|
| Customer and business information | What customer and business information must be present for review, including risk-based record updates and beneficial ownership details for legal entities where applicable |
| Industry, region, and risk appetite | How industry, region, and risk appetite shape rule parameters for screening, review, or intervention |
| Hold authority | Who can place, extend, and release holds |
Set those three dependencies before launch.
Step 3. Build a practical evidence pack before rollout#
Before rollout, build a baseline evidence pack, such as a control catalog, ownership map, escalation matrix, and sample case files. The objective is accountability: each control should have a named owner, defined inputs, a decision path, and an escalation route.
Each sample case file should show the alert reason, timeline, analyst actions, hold or release decision, unresolved questions, provider reference, and final ledger outcome. If an informed reviewer cannot reconstruct what happened end to end, your controls are not audit-ready.
For a step-by-step walkthrough, see A Guide to Stripe Radar for Fraud Protection.
Choose your detection stack with explicit tradeoffs#
Choose the lightest stack your team can run and defend in real casework. If you are early-stage or under-resourced, start with high-signal rules plus focused alert prioritization, then add ML after you can tune consistently and explain decisions.
Step 1. Compare options by operating tradeoffs#
Rules are clear and practical, but they can become rigid and expensive to maintain as fraud patterns change. ML can improve prediction, but ML-only setups often stop at risk labels unless you also support investigation and evidence handling. Agentic orchestration is most useful when risk signals and evidence stay linked across systems.
| Approach | Explainability | Speed to deploy | Maintenance and drift | Use now | Pilot next | Defer |
|---|---|---|---|---|---|---|
| Rule-Based Detection | High when alert logic is visible | Usually fastest | Can become rigid as patterns evolve | High-signal rules your analysts can already review and defend | Expand only after review outcomes are stable | Low-value rules that add noise |
| Machine Learning | Varies by how clearly outputs are exposed | Slower if labeling and tuning discipline is weak | Input and model drift are ongoing risks | Queue ranking or score-assisted review | Hold or block decisions from score alone | |
| Orchestration (Agentic AI) | Depends on how clearly actions and reasons are logged | Medium, depends on integrations | Detection logic can decay over time and needs retuning | Connect existing risk signals to investigation workflows | Broader automation after case quality is proven | Automations you cannot justify, trace, or maintain |
Step 2. Keep timing aligned to intervention needs#
If a decision has to happen before funds move, use real-time checks for that event path. Delayed batch review hours or days later can miss the intervention window on fast-moving fraud. Keep the first release small enough that reviewers can inspect serious alerts end to end.
Step 3. Confirm integration checkpoints before rollout#
A useful stack does more than score risk. It should preserve context from intake through investigation. Verify integration with transaction monitoring and authorization feeds, and confirm that alerts flow into the case management platform your fraud team uses.
In an end-to-end test, confirm:
- customer, entity, and event identifiers survive each handoff
- alert reason is visible to the analyst
- the final case links back to the original transaction and disposition outcome
Step 4. Treat vendor claims as inputs, not proof#
For any vendor you shortlist, ask for operating evidence that matches your workflow, not just feature lists. Ask for:
- a sample alert from a transaction or authorization feed with a clear reason
- a sample case showing analyst actions, timeline, open questions, and disposition
- an example of how stale logic, retuning, and drift are handled over time
Be careful with headline metrics alone. Reported results can differ by model and dataset, and selection depends on your application requirements. The right stack is the one your team can explain, test, and maintain without overbuilding.
This pairs well with our guide on Best Platforms for Creator Brand Deals by Model and Fit.
Before you lock your rule-vs-ML roadmap, map each control to webhook timing, idempotency, and audit-trail requirements in the Gruv docs.
Build risk tiers and alert queues that protect approval rates#
If approval rates matter, queue design matters too. You want the highest-risk, time-sensitive events at the front of the line while legitimate payouts keep moving when the context supports them.
Step 1. Sort alerts by risk and payout impact#
Tier alerts by both risk and payout consequence, not by alert volume alone. A low-impact anomaly that can be monitored after release should not sit in the same queue as a high-value payout with multiple warning signals.
| Tier | Definition |
|---|---|
| Immediate hold candidates | Funds can still be stopped and context is thin or conflicting |
| Fast-review anomalies | Unusual events with enough trust history for rapid human review |
| Monitor-only items | Low-impact outliers logged for repeat-pattern tracking |
This only works if analysts can review connected context in one place. Fraud.net's February 11, 2026 evidence highlights a common failure mode: underwriting data, velocity alerts, and beneficial ownership records remain disconnected, creating "a fragmented, incomplete view of risk." If reviewers have to bridge tools manually, prioritization quality degrades before thresholds do.
Step 2. Define clear if-then routing before threshold tuning#
Write routing logic in plain language before you tune it. Define clear pause-for-review and allow-with-monitoring paths so analysts are not making ad hoc routing decisions.
Keep routing aligned to intervention timing. If funds can move before review, the relevant alerts have to be generated in real time for that path. A queue that updates only after release supports retrospective casework, not prevention.
Use model scores to rank review order, not to replace explainable routing decisions. Weekly sampling of paused and allowed-with-monitoring outcomes should confirm that each case file shows the signals, trust context, and decision rationale.
Step 3. Tie Alert Prioritization to real analyst capacity#
Prioritization breaks down when queue inflow exceeds what analysts can clear inside the intervention window. Backlog pressure usually pushes teams toward two bad outcomes: rubber-stamping or blanket holds. One raises loss risk. The other increases false declines and frustrates legitimate users.
Assign ownership and review windows by tier, then track queue aging daily. If high-priority alerts age past the point of useful intervention, treat that as a control issue, not normal backlog. Reduce low-value alert volume, move borderline items to monitoring, or narrow manual-review triggers.
Daily queue health checks should include:
- incoming volume by tier
- oldest alert age
- disposition mix
- count of alerts blocked by missing context
If too many alerts require extra tool-hopping to resolve, data silos are already weakening your decisions.
Step 4. Review queue health, tune weekly, and sample monthly#
Run queue operations like a living control set. Review health frequently, tune thresholds weekly from real outcomes, and sample decisions monthly across your monitoring setup.
Monthly sampling should test for:
- false blocks on legitimate payouts
- missed escalations from delayed or siloed signals
- inconsistent analyst decisions on similar cases
Fraud.net's evidence on delayed and siloed signals creating blind spots is the practical warning here: escalation quality drops when context arrives late or fragmented.
Keep a durable audit trail for material queue changes: queue definition, threshold change note, owner approval, sampled alerts, and decision rationale. That is what supports a continuous, auditable view of risk when compliance or leadership reviews approval-rate tradeoffs.
Set escalation triggers and ownership boundaries#
Set ownership as an explicit internal policy before alert volume grows. Define who handles routine reviews, who can approve holds, releases, and routing exceptions, and who reviews cases that may require regulatory reporting.
Step 1. Assign decision rights by customer impact#
Document who can make which decision and at what impact level. Assign routine alert handling, hold and release authority, and potential SAR-to-FIU escalation paths with full AML audit-trail expectations. For every disposition, record the acting role, decision time, and reason code. This helps prevent customer-visible payment delays when release authority is unclear.
Step 2. Define escalation triggers before edge cases pile up#
Escalate when fraud indicators conflict with the available KYC and transaction-monitoring context, or when activity no longer looks normal for that customer or business. If a case cannot be resolved from the current file, escalate instead of forcing a routine closure.
Escalate when reporting responsibility is unclear or when the investigation requires additional documents from the customer or business. Unclear ownership can create avoidable delay.
Step 3. Require a complete case pack before escalation#
Escalate with a complete package, not a summary note:
- alert context and why it fired
- timeline from trigger to current payout status
- actions already taken, including hold or release, outreach, and document requests
- unresolved questions for the receiving team
Include the KYC profile, linked transaction history, and any documents already requested from the customer or business. The receiving owner should be able to decide next steps without re-running first-pass investigation.
Need the full breakdown? Read Choosing Between Subscription and Transaction Fees for Your Revenue Model.
Implement controls in Gruv with traceability first#
Roll out fraud controls in stages, and make traceability a go-live requirement before broad blocking. A control that flags payment fraud or identity-theft risk is only useful if your team can explain how the decision was made.
Step 1. Start in monitoring-only mode#
Begin by observing alerts without changing payout outcomes. This gives you a baseline for how often manual rules, behavioral analysis, or AI-powered checks fire before those signals affect real payments.
Keep the scope narrow at first. Use a limited set of payout paths. Log the suggested action, and confirm that operators can reconstruct the event input, the signal that fired, and the recommended outcome from the case record.
Step 2. Move to controlled enforcement on selected paths#
After monitoring output is stable, enforce only on low-ambiguity cases. Start with targeted holds or reviews, not broad blocking across all payout flows.
For each case, record the same decision trail every time. At minimum, keep a clear record of the input event, the signal that fired, the decision taken, and the operator-visible outcome.
Step 3. Define repeat-event handling before expansion#
Do not expand enforcement until repeat-event handling is stable. The same fraud signal should not create conflicting actions or repeated tickets because of retries or replays.
Use a consistent deduplication approach across alert intake, decisioning, and payout action, and persist decision state so replays append evidence instead of triggering a brand-new action.
Step 4. Require explainability before full coverage#
Move to full coverage only when held or blocked cases are explainable end to end. Your record should show the original event, the detection signal, the decision, and the final resolution in one trail.
This matters even more when AI checks are involved. Real-time analysis and historical behavioral patterns can help detect anomalies and reduce false positives, but they do not replace decision accountability.
Run vendor due diligence with proof requests you can verify#
Use the same traceability standard from go-live to decide vendor eligibility. If a provider cannot show sample alert output, rule-change evidence, and a clear incident path for your use case, treat that as a fail before procurement.
Some Transaction Monitoring Software products are marketed as broad platforms, but your real risk sits in operator detail. You need proof that your team can integrate the system, explain decisions, tune controls, and defend outcomes to compliance and audit.
Step 1. Build a side-by-side checklist before demos#
Standardize the evaluation format first. Send one checklist to every vendor and require the same proof set so you can compare integration fit, explainability, support model, scalability, and rule governance on equal terms.
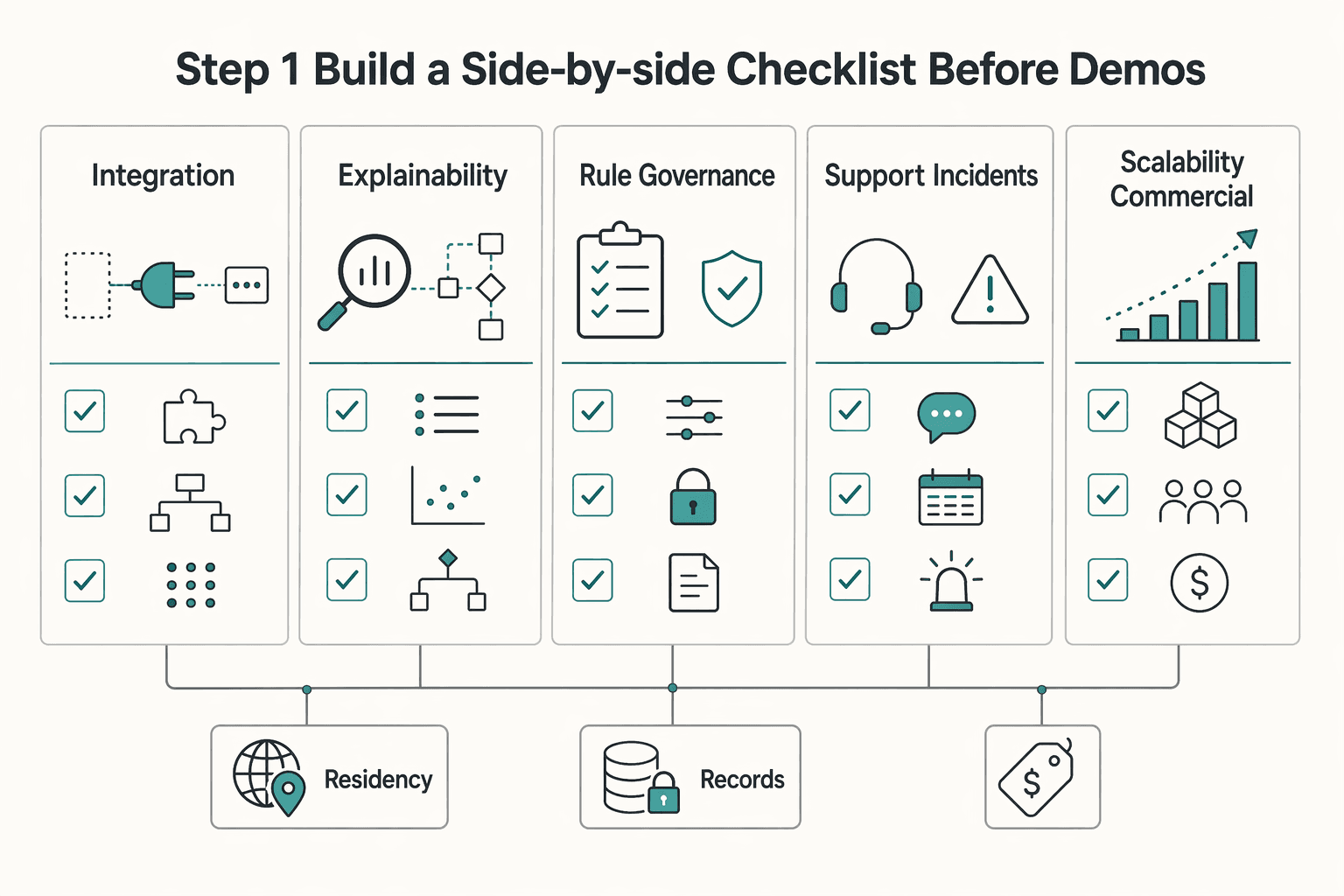
| Area | Proof to request | What you verify |
|---|---|---|
| Integration fit | API docs, sample payloads, event model, implementation assumptions | Whether payout, ledger, webhook, and case data can flow without hidden custom work |
| Explainability | Sample alerts, analyst case view, reason codes, audit trail export | Whether an operator can reconstruct why an alert fired and what changed after review |
| Rule governance | Rule version history, approval path, tuning workflow, rollback method | Whether rule changes are controlled and reversible |
| Support and incidents | Incident response process, escalation path, ownership boundaries | Whether response ownership is clear when alerts misfire or queues stall |
| Scalability and commercial fit | Test conditions, volume assumptions, pricing model, data residency position | Whether claims match your conditions and expose regional or usage-based pricing risks |
Keep one baseline check on every scorecard: API integration, data residency compliance, and transparent usage-based pricing. Fraudio's own selection guidance highlights these checks, so treat them as practical procurement controls rather than optional extras.
Step 2. Require proof for Machine Learning and Alert Prioritization claims#
Treat ML and prioritization claims as unproven until you can inspect outputs and workflows. Terms like "explainable AI," "full audit transparency," and "unified control" are only useful if the evidence holds up in your operating flow.
Request one package with three parts:
- sample outputs: raw alert, decision factors, queue placement, and post-review case history
- tuning workflow: who can change thresholds or rules, what approval is logged, how changes are tested, and how rollback works
- incident process: what happens if the model floods queues, suppresses expected alerts, or creates actions your team cannot explain
Use vendor claims as proof prompts, not conclusions. Ask to see your event configured, changed, and rolled back with audit history visible, and request a case export that shows alert creation, review notes, disposition, and follow-on action.
Step 3. Normalize every outcome claim or mark it non-comparable#
Accept outcome claims only when test conditions are explicit. "Reduced false positives" or "better prioritization" is not comparable without the tested data profile, transaction context, review model, and tuning period.
Capture at least:
- tested use case
- transaction volume band
- production versus pilot context
- analyst review model
- what remained manual
If those conditions are missing, mark the claim as unknown or non-comparable. Public rankings, vendor roundups, and marketplace ratings can conflict, and they do not prove audit readiness or regulatory adequacy for your flow.
Step 4. Apply a pass fail gate before procurement#
Use pass-fail gates for control-critical requirements, and reserve weighted scoring for non-critical differences. This prevents buying broad Fraud Detection Software that demos well but fails under real case operations.
Fail before procurement if any of these remain unproven:
- no usable audit trail for alert creation, analyst action, and final disposition
- no demonstrable rule governance, including version history and rollback
- no evidence of API fit for core events and payout states
- no clear position on data residency for required regions
- no documented incident response process for alert floods, outages, or misfires
By commercial review, you should be comparing only vendors that already met operator-critical controls.
Related reading: Best Merch Platforms for Creators Who Want Control and Compliance.
Common implementation mistakes and how to recover quickly#
Many implementation failures come from operating gaps, not missing features. If alert queues are already noisy, recovery often starts by narrowing scope and making decisions easier to explain.
Step 1. Cut rule volume before you tune Rule-Based Detection#
Launching too many rules at once can increase false positives. Overly broad rule sets can flag normal behavior as suspicious, which drains investigation capacity and can damage customer relationships.
Reduce to a small set of high-signal controls tied to clear risk patterns, then tune from there. Document your decisioning score threshold as a risk-appetite choice, including who approved the cutoff and the tradeoff accepted. Re-expand only after reporting shows alert volume, disposition mix, and which alerts were legitimate activity.
Step 2. Put analyst guidance around Machine Learning before trusting outputs#
Use Machine Learning for prioritization, not as an unreviewed decision source. One cited stacking-model study reported strong detection metrics while also noting computing cost and delay challenges.
Set review criteria before model outputs influence investigation prioritization or escalation. Define when analysts accept a recommendation, escalate, or override it, and require those decisions in case records. If a case file shows only a score and final disposition, treat that as a control gap.
Step 3. Assign clear ownership for escalations and edge cases#
Unclear ownership is a fast way to mishandle alerts. If no team clearly owns triage, escalation, and final-disposition decisions, reviews can stall or move forward without enough context.
Publish an escalation matrix for routine alerts, urgent cases, and ambiguous cases. Make roles explicit for triage, escalation, and final disposition, including after-hours handling. Test the process against recent cases to confirm that owner, escalation path, and final decision timing are visible.
Step 4. Standardize case files so every alert has a traceable decision path#
Poor evidence hygiene can weaken otherwise sound decisions. If investigators record different levels of detail, consistency is hard to defend in compliance or audit reviews.
Standardize one case-file format and one audit-pack format for every alert. Include timeline, trigger, supporting data points, analyst actions, escalation record, and final disposition. Case-management workflows plus reporting and analytics help teams keep decisions reconstructible from input to final action, and support refining thresholds, investigation processes, and model performance with additional data points.
For related reading, see How EOR Platforms Use FX Spreads to Make Money.
Your next step is a 90-day execution checklist#
Treat the next 90 days as a control build, not a vendor hunt. Tighten ownership, alert handling, and case records first. Adding more detection logic before that usually adds noise.
| Timing | Focus | Key actions |
|---|---|---|
| Week 1 to 2 | Map flow, outcomes, and ownership | Map your end-to-end transaction flow, define fraud-loss reduction and customer-impact reduction, and assign who can place a hold, who can release it, who approves exceptions, and who owns compliance escalation |
| Week 3 to 4 | Launch baseline rules and risk-tiered alerts | Deploy a small baseline of Rule-Based Detection, route alerts by risk tier with explicit escalation triggers, and use real-time monitoring where inline decisions are required and batch review where delayed review is acceptable |
| Month 2 | Tune thresholds and document exception logic | Tune thresholds using analyst feedback, document exceptions for Payment Fraud, Synthetic Identity Risk, and Account Takeover, and define what evidence is required to release, what justifies longer holds, and when escalation moves beyond routine fraud review |
| Month 3 | Pressure-test vendors and publish the reporting pack | Run proof checks on vendor claims using sample alert outputs, explainability detail, override logs, case-management records, and transaction linkage, then publish a pack with a control catalog, ownership map, escalation matrix, threshold-change log, sample case files, open evidence gaps, and leadership reporting on queue health and disposition trends |
Step 1 (Week 1 to 2). Map flow, outcomes, and ownership#
Map your end-to-end transaction flow and name decision owners for each intervention point in Transaction Fraud Monitoring. Define two outcome lanes before writing rules: fraud-loss reduction and customer-impact reduction. Assign who can place a hold, who can release it, who approves exceptions, and who owns compliance escalation.
Verification point: confirm you can reconstruct each case from transaction event to decision to final disposition.
Step 2 (Week 3 to 4). Launch baseline rules and risk-tiered alerts#
Deploy a small baseline of Rule-Based Detection tied to real payout decisions, then route alerts by risk tier with explicit escalation triggers. Use real-time monitoring where inline decisions are required, and batch review where delayed review is acceptable. That is a speed-versus-review tradeoff, not a maturity signal.
Verification point: every alert should show trigger, queue, analyst action, and outcome.
Step 3 (Month 2). Tune thresholds and document exception logic#
Tune thresholds using analyst feedback, and document exceptions separately for your main fraud scenarios (for example, Payment Fraud, Synthetic Identity Risk, and Account Takeover). Define what evidence is required to release, what justifies longer holds, and when escalation moves beyond routine fraud review.
If your program includes SAR filings, define what repeated suspicious activity changes operationally. FinCEN's October 2009 outreach report describes examples where a second SAR led to closer monitoring and possible closure, but it does not imply FinCEN approval or a required template.
Step 4 (Month 3). Pressure-test vendors and publish the reporting pack#
Run proof checks on vendor claims using inspectable artifacts: sample alert outputs, explainability detail, override logs, case-management records, and transaction linkage. Treat performance claims about alert speed or decision latency as product-specific until validated in your environment.
Publish an audit-ready pack with: control catalog, ownership map, escalation matrix, threshold-change log, sample case files, open evidence gaps, and leadership reporting on queue health and disposition trends.
After your 90-day checklist is drafted, pressure-test your payout controls and ownership model with a Gruv implementation review.
Frequently Asked Questions
What should platforms prioritize first in transaction monitoring to reduce fraud quickly?
Start with a small set of high-signal controls tied to your highest-risk payment decisions. Keep screening and monitoring separate, and reduce rule volume if queues are noisy. Every hold decision should be traceable from trigger to analyst action to final disposition.
Is `Rule-Based Detection` or `Machine Learning` better for platform fraud detection?
Neither is automatically better on its own. Use rules as the control baseline and use models for prioritization until analyst guidance, escalation criteria, and case records are consistently reliable. Static rules can miss complex patterns, and model outputs should not replace reviewed decisions.
How can we cut fraud losses without blocking legitimate payouts?
Use risk-tiered decisions instead of applying the same hold logic to every anomaly. High-risk signals with weak context can pause for review, while lower-risk anomalies with stronger account context can proceed under continued monitoring. Validate the balance in your own environment.
What evidence should we request from `Transaction Monitoring Software` vendors before signing?
Ask for inspectable evidence, not feature claims. Request explainability outputs, audit-trail support, privacy safeguards, and sample case artifacts that show how alerts are generated, reviewed, and overridden. In a broker-dealer context, also confirm support for Rule 3310-related controls such as written AML procedures, named AML responsibility, senior-management approval, and independent testing expectations.
How should we use `Open-Source Intelligence (OSINT)` and `Contextual Intelligence` without overreaching?
Use OSINT only for case-focused questions and only from publicly available sources. The goal is to assess a specific customer or incident context, not broad surveillance. Record what source was checked, when, why it mattered, and how it informed the decision.
What remains unknown when vendor pages show features but not independent benchmarks?
Independent performance and control effectiveness remain uncertain. Feature pages do not prove fraud-loss impact, false-positive behavior, operational workload, or market-specific reliability on their own. Treat breadth claims as vendor claims until you validate source quality, relevance, and decision usefulness in your own environment.
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
Includes 6 external sources outside the trusted-domain allowlist.
- bsaaml.ffiec.gov/manual/AssessingComplianceWithBSARegulatoryR...trusted
- fincen.gov/system/files/shared/Bank_Report.pdftrusted
- alloy.com/blog/5-ways-ai-fraud-detection-helps-financi...external
- apptad.com/blogs/implementing-context-intelligence-to-c...external
- b2b.mastercard.com/media/d1onse0r/impact-study-eight-steps-to-e...external
- coredo.eu/transaction-monitoring-common-scenarios-that...external
- craftingsoftware.com/real-time-fraud-monitoring-for-enterprise-fi...external
- finra.org/rules-guidance/key-topics/aml/faqexternal
Educational content only. Not legal, tax, or financial advice.
Related Posts

The Freelance Payment Penalty: A Modeled Audit of Platform Fees, FX Spreads, and Payout Delays
The money rarely disappears through a single, easy-to-spot fee. The real loss is stacked. A marketplace takes its commission, a processor adds a charge for international cards, a bank or payment company converts the currency at a spread, a platform holds the funds before release, and a wire sheds a little to intermediaries on the way in. Each layer looks defensible on its own, but the worker feels the combined result as a smaller deposit and a later payday.

How to Respond to a Subpoena for Business Records
Move fast, but do not produce records on instinct. If you need to **respond to a subpoena for business records**, your immediate job is to control deadlines, preserve records, and make any later production defensible.

A US Expat's Guide to Investing in UCITS ETFs to Avoid PFIC Issues
The real problem is a two-system conflict. U.S. tax treatment can punish the wrong fund choice, while local product-access constraints can block the funds you want to buy in the first place. For **us expat ucits etfs**, the practical question is not "Which product is best?" It is "What can I access, report, and keep doing every year without guessing?" Use this four-part filter before any trade: