
Quick Answer
Build a payout SLA by defining scope, start and stop events, pause rules, ownership, KPI formulas, and remedies before you publish any timing promise. Use records your team can reproduce consistently, keep payment terms separate from internal operating targets, and pilot one narrow cohort before rollout. If a target cannot be measured from source records, leave it out.
What a payout SLA should cover#
Start by defining terms. The available reference material is useful, but it is not complete. The New York State procurement acronym page says its definitions are "for reference only" and "not inclusive of every acronym, word, or phrase," so treat outside glossaries as inputs, not as the controlling source for your payout document.
Before you start#
Step 1. Start with a terms table, not clause drafting. Use a structured terms table before you draft promises into a technology vendor contract. A practical model is Acronym | Term | Definition. You can extend that with fields like owner and evidence source, but keep the core discipline intact: one shared meaning per term.
Step 2. Mark unknowns before you promise timing. From the evidence provided, core payout SLA specifics are still undefined, including clock start and stop events, completion criteria, pause rules, breach thresholds, ownership model, and KPI formulas. Treat those as explicit gaps to resolve in your own operating document before you make external commitments.
Step 3. Keep wording concrete where a term is known. If you reference ACH, use the specific term and definition: ACH is "a nationwide electronic network for the transfer of funds from one bank account to an account in another bank." That level of precision reduces ambiguity when teams review timing language later.
That is the approach for the rest of this guide: define what you can defend, and label what is still undefined so expectations stay clear.
What a payout SLA covers and what it does not#
Before you set metrics, decide exactly what the SLA is meant to govern.
- Set scope before metrics.
A Service Level Agreement defines expected service levels, how performance is measured, and what remedies apply if targets are missed. Start with one scope sentence that names the services included. If something is not named, keep it out of scope until you add it.
- Keep external commitments separate from internal targets.
Payment terms and internal AP or operations processing targets can sit in different layers, and documenting them separately improves clarity. For example, you might publish a payment term such as Net 45 while tracking tighter internal handoff and completion targets to support delivery. Keeping those layers distinct helps reduce misalignment between service delivery and expectations.
- Use the SLA as a contract component, not a replacement.
Treat the SLA as part of the outsourcing or technology vendor contract structure, not as a substitute for it. In practice, the SLA can consolidate service and reliability expectations into one operating document, while incentives and penalties still need to fit the contract type. If you are still sourcing, include the expected service levels in the RFP because they can change supplier pricing and responses.
- Define one reporting rule for "paid."
Pick one internal completion definition and use it consistently in reporting. If you adopt an internal "paid" definition, label it clearly as your operating definition rather than a universal legal standard. The exact phrasing matters less than using the same definition every time.
If you want a deeper dive, read Contractor Payout SLAs: How to Promise and Deliver Payment Speed Guarantees.
What to prepare before you draft#
Do not draft payout timing promises until you can define the service levels you expect, how performance will be measured, and what happens if targets are missed. This prep work is what turns a payment term into something you can actually measure and enforce.
Step 1 Gather the evidence pack you will draft from#
Build the draft from documented service expectations, not memory. Pull together all contracted services and their expected reliability in one working document before you finalize commitments.
Use a simple checkpoint: every proposed timing target should have a clear metric, responsibility, and measurement method. If a target cannot be measured consistently, leave it out of the draft for now.
Step 2 Define responsibilities, expectations, and remedies up front#
Document who owns each service level, what the expectation is, and what remedy applies if that level is missed. Keep terms explicit so neither party can reasonably misread the agreement later.
Treat this as legal and operational preparation. Any significant contract without an associated SLA reviewed by legal counsel is more vulnerable to misinterpretation.
Step 3 Align objectives before you negotiate numbers#
Before you write a headline promise, confirm the SLA objectives align with your business and technology goals.
This is where overpromising usually starts. Misalignment can hurt pricing, service delivery quality, and customer experience.
Step 4 Set your negotiation baseline early#
Many providers start from prewritten SLA templates with different service levels and prices. Review and modify those terms with legal counsel instead of accepting defaults unchanged.
If you are still in sourcing, carry service-level expectations into the request process. That preparation can change supplier offerings, pricing, and willingness to respond.
Related: Invisible Payouts: How to Remove Payment Friction for Contractors Without Sacrificing Compliance.
Map the payout clock and define start and stop events#
If the clock is ambiguous, the rest of the SLA will be too. Define one official clock start and one official clock stop, and tie both to records your team can retrieve consistently.
Use a timing table with your own event labels, but make each label unambiguous. Where possible, map each event to a durable record rather than a memory-based status description so operations, finance, and reporting teams measure the same thing.
Keep contract timing artifacts and operational clock definitions aligned, but separate. Contract summaries can carry timing fields such as payment terms and delivery timeframe, for example Net 45; your SLA clock still needs internally defined start and stop events for measurement in your environment.
Version your clock definitions when terms change. Formal amendments and effective dates can occur in contract operations, so update the start and stop definitions by effective date instead of silently changing how performance is measured midstream.
For pause handling, confirm payout pause triggers and payout-event mechanics with your platform or payment provider. Treat pause conditions, entry events, and exit events as internal policy, and keep them clearly separate from sourced contract timing artifacts.
For a step-by-step walkthrough, see QuickBooks Online + Payout Platform Integration: How to Automate Contractor Payment Reconciliation.
Set tiered timing commitments contractors can trust#
A single payout promise sounds clean, but it can create avoidable interpretation and delivery risk. If service paths or review states behave differently in practice, your commitment model should reflect that.
Step 1#
Choose a commitment model your data and contract structure can defend. In an SLA, you are defining the expected service level and how it will be measured, so the model should match operational reality.
| Commitment model | What you promise | Where it works | Main tradeoff |
|---|---|---|---|
| Uniform single-window promise | One timing term for all in-scope payouts | Low-variation programs | Simple to explain, but can hide meaningful variation |
| Tiered by documented eligibility state | Different timing bands based on documented eligibility states | Programs where eligibility states affect release timing | More realistic, but only if status assignment is auditable |
| Tiered by service path | Timing bands by service path or higher-review path | Programs with multiple processing paths | More accurate, but harder to maintain and explain |
If supplier coverage and pricing differ by service level, your timing commitments should reflect that instead of forcing one global promise.
Step 2#
Assignment rules need to be explicit. Do not leave banding to ad hoc interpretation.
Write if-then rules tied to states your systems can prove at clock start:
- If a payout meets your documented eligibility state, assign the corresponding faster band.
- If required checks are still pending, assign the slower band or no speed commitment until prerequisites clear.
- If a payout is outside faster-support coverage, assign only the published baseline band for that path.
- If a payout enters a higher-review path, assign that path's published band.
Store the assigned band at release time so disputes and reporting use the same historical record.
Step 3#
Remedies should match both your contract posture and your measurement maturity. SLAs should state what happens when service levels are missed, but that does not mean every miss has to start with money.
A workable ladder is:
- documented escalation and corrective action
service creditfor repeated or material missespenalty clauseonly where contract and procurement posture support it
Also define the document hierarchy for conflicts. If timing language appears in multiple contract artifacts, set an order of precedence so interpretation stays consistent.
Step 4#
Publish timing bands as "where supported," with scope labels that make the limits obvious. For each band, state the applicable service-path or cohort conditions so contractors see the real commitment, not an aspirational average.
Before you publish, check one evidence pack: historical completion timing by path, exception logs, current provider coverage and pricing terms, and unsupported paths. If a path is unstable, keep it on a separate band instead of forcing uniform timing.
Define pause rules for compliance and documentation gaps#
Pause rules are one of the first places a payout SLA becomes either defensible or useless. If a pause reason is not predefined, backed by evidence, and logged, it should not stop the SLA clock.
| Pause rule item | What to document | Section step |
|---|---|---|
| Allowed pause triggers | Controlled list of allowed pause triggers and the proof required for each one | Step 1 |
| Pause start record | Event name used in operations and reporting; evidence that starts the pause | Step 1 |
| Pause end record | Evidence that ends the pause | Step 1 |
| Cause code | Store the cause code at pause start | Step 2 |
| Resume rule | Conditions checkpoint, waiver or exception path, and official restart time | Step 3 |
| Long-pause threshold | Policy threshold that triggers early communication and internal escalation | Step 4 |
Step 1#
Define a controlled list of allowed pause triggers, and document the proof required for each one. Avoid broad labels that cannot be audited later.
For every trigger, record:
- the event name used in operations and reporting
- the evidence that starts the pause
- the evidence that ends the pause
Step 2#
Record the pause state when it starts so later review is based on what was known at that checkpoint, not on dispute cleanup.
Store the cause code at pause start, and keep review states specific enough that pause history stays interpretable in reporting.
Step 3#
Every pause needs a resume rule with a named checkpoint and restart timestamp. A practical pattern is: conditions checkpoint, waiver or exception path, and a named closing time.
For each pause, answer these points in writing:
- What must clear before processing resumes?
- What evidence proves it cleared?
- Is there an approved exception or waiver path?
- Which timestamp is the official restart time?
Step 4#
Set a policy threshold for long pauses that triggers early communication and internal escalation. The threshold value is a policy choice, but the response should be automatic and consistent.
The notice should state the current pause reason, what is needed to resume, and the next required action. The escalation path should be defined before the case drifts into a silent paused state.
Assign ownership and escalation paths across teams#
Once the pause rules are in place, assign ownership. Otherwise an issue can drift across teams with no named decision-maker.
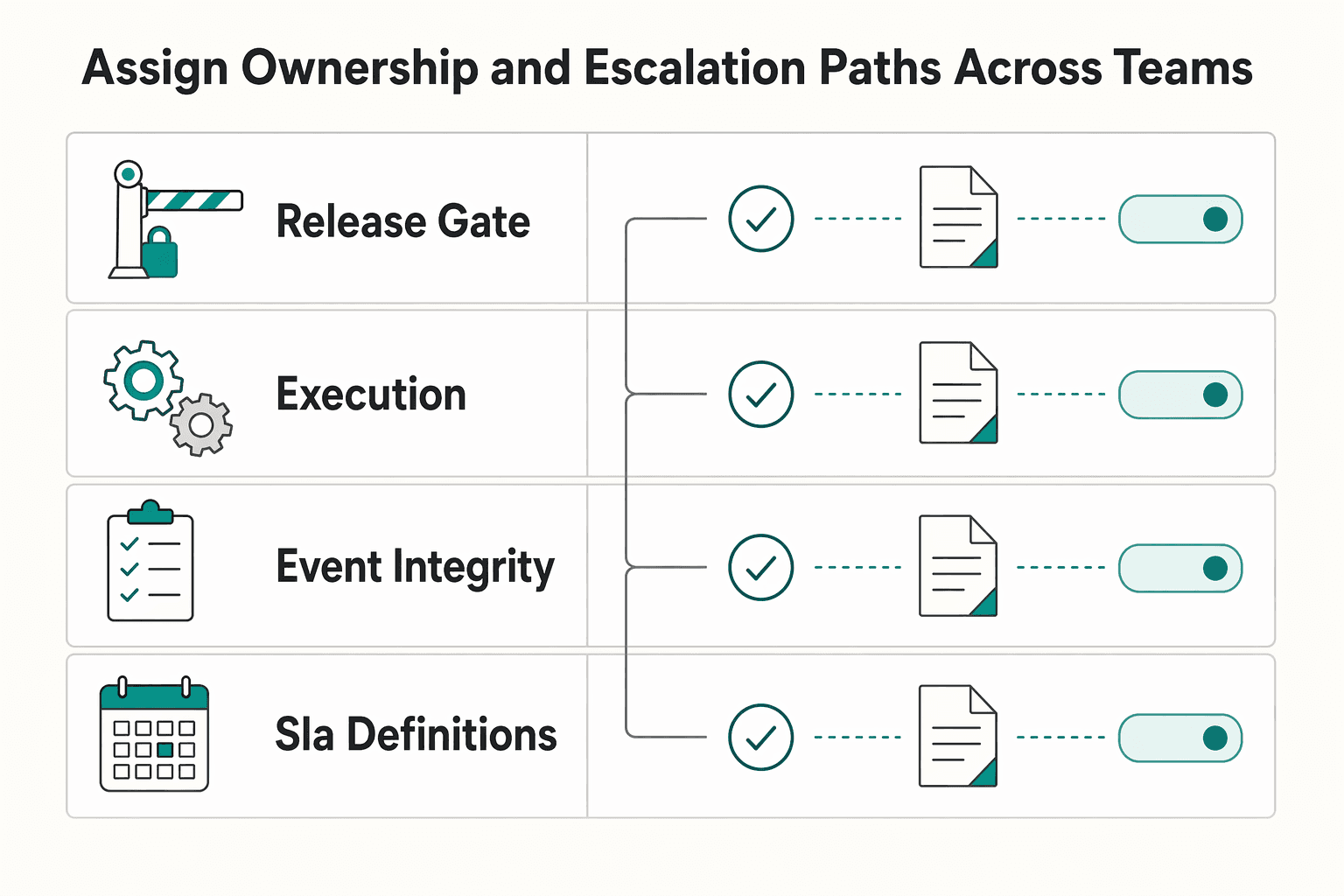
| Ownership area | What to assign | Control |
|---|---|---|
| Approval | A named owner | Visible in one ticket or audit record |
| Execution | A named owner | Visible in one ticket or audit record |
| Event integrity | A named owner | Visible in one ticket or audit record |
| SLA definitions | One accountable owner controls start and stop events, pause logic, and breach attribution | Treat owner changes as formal change control with a dated update, itemized amendments, and an effective date |
| Monthly reconciliation and reporting sign-off | A separate accountable owner signs off the reconciliation package and records open discrepancies before reporting is finalized | Treat owner changes as formal change control with a dated update, itemized amendments, and an effective date |
Step 1#
Build a RACI-style map around decisions, not departments. In your org context, make sure approval, execution, and event integrity each have a named owner.
Pressure-test the map with one delayed payout: who approved it, who released it, who confirmed the event trail, and who handled follow-up risk. If those answers are not visible in one ticket or audit record, ownership is still too abstract.
Step 2#
Define an escalation ladder before a breach happens, and separate the stages so the response changes as risk increases. If it helps in your environment, label stages as at-risk, breached, repeated breach, and systemic breach.
For each stage, document the trigger, the decision authority, and the expected response. As risk escalates, route issues from functional intervention to accountable owners and, when needed, cross-functional review for provider dependencies, logging gaps, or contract mismatch.
Step 3#
Assign one accountable owner for SLA definitions and a separate accountable owner for monthly reconciliation and reporting sign-off. Name specific people, not only team names.
The definitions owner controls start and stop events, pause logic, and breach attribution. The reporting owner signs off the reconciliation package and records open discrepancies before reporting is finalized. If either owner changes, treat it as formal change control with a dated update, itemized amendments, and an effective date.
Step 4#
When payout SLA language affects contract or RFP obligations, route updates through formal contract governance and involve legal or procurement review where needed. Keep core clause definitions aligned across operating documents, vendor agreements, and implementation sign-off artifacts.
A clean update pack includes revised clause text, effective date, named contract administration contacts, and the event definitions used for reporting. Resolve definition mismatches early to reduce later dispute and reconciliation risk.
Draft enforceable terms and remedies#
This is where the document either becomes operational or stays aspirational. Write the terms so a breach can be measured, reviewed, and resolved from records, not interpretation.
Step 1#
Draft one SLA clause set that clearly defines scope, timing start and stop points, pause logic, breach definition, remedy ladder, and dispute process.
Keep those terms tied to the governing contract documents. If you are still in procurement, include the expected service levels in the RFP up front because they influence supplier offerings and pricing. Before sign-off, confirm that legal, operations, and the vendor read the same start, stop, and pause events the same way.
Step 2#
Tie each incentive and penalty term to measurable service metrics and auditable events.
Avoid subjective phrasing. If a trigger cannot be traced in system records and used in breach reporting, it is too weak for enforcement. A practical test is to run one delayed-service scenario end to end and confirm the breach outcome can be calculated from the record.
Step 3#
Use a remedy ladder: corrective action first, then financial remedies for repeat breaches.
For an initial miss, require service response and root-cause correction. For repeated breaches in the agreed reporting period, apply a service credit or fee adjustment defined in the contract. Keep each trigger explicit so escalation is tied to counted breaches, not opinion.
Step 4#
Define exclusions and dispute handling with the same precision as the promise.
State when the provider is or is not liable, including circumstances outside the provider's control and any exclusions already defined in the governing contract. Define who can raise a dispute, what evidence is required, and which record controls when reports conflict. Broad exclusions that conflict with published service terms create avoidable breach disputes later.
Build measurement, reporting, and audit evidence#
If SLA results cannot be recreated from underlying records, they are easier to dispute and harder to enforce. The measurement section should make that recreation possible.
Step 1#
Define each KPI as a formula in the SLA artifact, not just a label. Lock the numerator, denominator, clock start and stop events, exclusions, and reporting period so legal, operations, and finance calculate the same result.
| KPI example | What to define explicitly |
|---|---|
| On-time payout rate | In-scope population, committed window, and completion event |
| Median completion time | Start/stop events, treatment of paused time, and in-scope population |
| Paused-time share | Valid pause reasons, pause evidence, and duration basis |
| Breach count | Unit of breach (for example, per payout or per reporting result) and reporting period |
| Repeat-breach rate | Lookback window and what qualifies as repeat |
Use the same start and stop events across all formulas and reports. If teams use different completion events, breach outcomes can drift.
Step 2#
Define a recurring evidence pack in the contract so every reported KPI can be traced to source records. Treat it as a named contract artifact, not a slide summary.
For example, include:
- Event export needed to rebuild the payout clock
- Exception log for excluded cases and exclusion reasons
- Breach log tying each breach to underlying records and remedy status
ledger-to-settlementreconciliation file showing matched and unmatched items
Set an order-of-precedence rule for conflicts between dashboards, exports, and reconciliation records. If you are still in procurement, include these reporting expectations in the RFP so suppliers scope and price correctly before signature.
Step 3#
Validate that SLA metrics align with business objectives before launch. Misalignment can hurt pricing, service quality, and customer experience.
Document responsibilities and expectations in the same SLA artifact so teams work from one shared definition of success.
Step 4#
Publish two reporting views with different purposes: internal operations and stakeholder clarity.
The internal view should support diagnosis and remediation. The stakeholder-facing summary should present updates in plain language. Both views should map to the same underlying records so trust does not break between what different audiences see.
You might also find this useful: Payment Transparency for Contractors: How to Build a Payout Tracker Your Recipients Trust.
Common failure modes and recovery actions#
An SLA should not stop at measurement. When payout operations slip, the document should already define what happens next.
| Failure mode | What happens | Recovery action |
|---|---|---|
| SLA ambiguity | Teams can report different outcomes from the same period | Define measurable service levels and clear ownership in the SLA |
| Objective misalignment | Breach reporting can drift from lived experience | Document how service is measured and keep that definition consistent across reporting and operations |
| Supplier-default SLA language | Unmodified terms can shift risk during service degradation | Review and negotiate contract and SLA language with legal counsel |
| Undefined remedies | SLA reporting becomes informational instead of corrective | Predefine remedies in the SLA, including financial adjustments tied to breach magnitude |
Step 1#
SLA ambiguity becomes a bottleneck when metrics, responsibilities, and expectations are unclear. Teams can report different outcomes from the same period, and that can still damage service quality and customer experience.
Define measurable service levels and clear ownership in the SLA so both parties share the same understanding of performance and obligations.
Step 2#
Objective misalignment creates silent failures even when activity looks normal. If customer and supplier are not aligned on what is being measured, breach reporting can drift from lived experience.
Document how service is measured and keep that definition consistent across reporting and operations, with an explicit review path when conditions change.
Step 3#
Supplier-default SLA language can leave recovery obligations vague. Standard provider SLAs are often slanted toward the supplier, so unmodified terms can shift risk during service degradation.
Review and negotiate contract and SLA language with legal counsel, and avoid significant contracts that lack an associated, legally reviewed SLA to reduce misinterpretation risk.
Step 4#
Undefined remedies weaken enforcement after a miss. If breach consequences are unclear, SLA reporting becomes informational instead of corrective.
Predefine remedies in the SLA, including financial adjustments such as payment reductions tied to breach magnitude, and revisit terms to confirm both parties are still measuring the same service levels and outcomes.
Pilot with one payout cohort before full rollout#
Roll out in phases. Start with a small pilot cohort, validate the results, and expand only when your success criteria are met.
Step 1#
Choose a narrow pilot cohort so you can inspect outcomes closely, for example one country-method combination or one contractor segment in one program. That keeps testing controlled while payout timing can still vary by method, configuration, and country.
Step 2#
Run a side-by-side period where legacy tracking and new payout tracking operate concurrently for the same payout population. Reconcile the outputs and review disagreements before expanding scope.
If possible, include at least one month end in the parallel run. Also keep payout schedule, funds availability, and settlement timing as separate states in reporting.
Step 3#
Define scale-up criteria before the pilot starts, and use those criteria to make the go or no-go decision for expansion. Move forward when pilot results meet those criteria and records reconcile across systems.
If issues remain, keep the scope contained and refine the process before widening rollout.
This pairs well with our guide on Bank-Rejected Contractor Payout Recovery for Platform Teams.
Copy and paste payout SLA implementation checklist#
Use this checklist only for items you can prove in a contract, report, or audit trail. If a timing point or remedy cannot be evidenced, leave it out until it can.
Step 1#
Define the service in one place: scope, start and stop events, completion evidence, owners, and data sources. Keep metrics, responsibilities, and expectations together so they are not split across notes or email. If operations can describe a stop event but logs cannot prove it, the definition is not ready.
Step 2#
Document approved pause categories and entry and exit evidence before launch. Use exact internal labels, clear ownership, and explicit clearance conditions for each category. If your records cannot separate external delay from internal delay, breach handling will break down.
Step 3#
Finalize the remedy ladder before rollout and get legal review in contract templates, RFP language, and vendor paper where relevant. Define escalation first, then when service credit applies, then when a penalty clause is appropriate. Do not ship commercial promises that are not mapped to measurable events.
Step 4#
Stand up KPI reporting on trusted operational records and audit trail data. Keep a single source of truth and require every reported breach to trace to source events. If reports do not reconcile to underlying records, pause SLA reporting until the mismatch is resolved.
Step 5#
Pilot one cohort first, review every breach root cause, and scale only after stable performance. Expand when reporting is consistent and remedies can be administered as written. If a payout segment keeps failing, contain scope and fix it before widening rollout.
Turn this checklist into your rollout spec, then map statuses, retries, and audit outputs in the Gruv docs.
Build promises your team can keep at scale#
The strongest payout SLA is not the one with the fastest headline promise. It is the one your team can measure consistently and enforce clearly as volume grows. A strong Service Level Agreement defines the expected service level, the metrics used to measure it, and what happens if targets are missed.
Step 1#
Anchor the promise to records your team can reproduce the same way every month. If your team cannot produce one consistent reading of when service is complete, do not publish a tighter timing commitment yet.
Use a practical check: two operators should be able to calculate the same on-time result from the same report without subjective interpretation. If they cannot, the SLA language is still too loose for an external commitment.
Step 2#
Keep the SLA as one operating document that ties service scope, measurement logic, responsibilities, and remedies together. That is what reduces ambiguity when issues happen, because the metrics, expectations, and owners sit in one place.
If a payout partner is involved, do not accept template language as-is. Provider templates are often supplier-favored, so review and revise the terms with legal counsel before they are finalized in contract documents.
Step 3#
Start with narrow commitments and expand only where measurement stays consistent as volume grows. Keep broader terms where reporting is still inconsistent, then tighten only after the same measurement approach holds up over time.
If measurement quality drops as volume rises, pause expansion and fix the records first. Misaligned service levels can hurt deal pricing, delivery quality, and customer experience even when the promise sounds attractive.
Step 4#
Set service-level expectations early in the RFP, not only in late contract edits. Early expectations affect supplier offerings, pricing, and whether suppliers choose to bid.
Sanity-check alignment across the RFP language, vendor response, and final contract terms. If those documents describe different service expectations, scaling risk is already built in.
Step 5#
Treat faster commitments as something you earn through consistent evidence. Expand only when your metrics, ownership model, and remedy path remain clear as volume grows.
Operationally, the rule is simple: publish what your records and contracts can support today. Significant contracts without a clear SLA are open to misinterpretation, so widen the promise as the proof gets stronger.
Related reading: Build a Fair Internal Contractor Payment Dispute Process.
Before publishing payout speed commitments, confirm market coverage and compliance gates for your programs by contacting Gruv.
Frequently Asked Questions
What should a contractor payout SLA include at minimum?
At minimum, include the expected service level, how performance is measured, who owns each responsibility, and what remedies apply if service levels are missed. If a vendor or payout partner is in scope, carry those expectations into the RFP and the contract, not just internal notes.
When should the payout clock start and stop?
Use one official start event and one official stop event that both sides can verify from stable records. Tie each timing point to logs, reports, or another durable system of record so enforcement does not depend on interpretation.
What exceptions are valid reasons to pause SLA timing?
Valid pause reasons should be explicitly defined in the SLA and backed by entry and exit evidence. The record should show when the pause started, why it started, who owned it, and when timing resumed. If a pause reason is not predefined, evidenced, and logged, it should not stop the SLA clock.
Is `Net 30` enough for contractor payment expectations?
No. Net 30 is a payment term, but it does not replace SLA definitions for measurement, responsibilities, and remedies. Pair payment terms with explicit service-level definitions so expectations are operationally clear.
What happens operationally and contractually when an SLA is breached?
First confirm the breach against the agreed metric and source records, then follow the remedy path defined in the contract. A practical ladder is corrective action first, then service credits or fee adjustments for repeated breaches, with penalty clauses only where the contract posture supports them. Poorly designed incentives or penalties can create monetary loss and trust problems instead of improving performance.
How do we separate contractor-caused delays from internal processing failures?
Treat attribution as a design choice you define in advance. Set clear categories, ownership, and evidence requirements before launch so each delay is classified consistently. If a delay cannot be supported by records, classify it as uncertain rather than forcing a confident label.
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
- archives.obm.ohio.gov/Files/Major_Project_Governance/Resources/Res...trusted
- capitol.tn.gov/Archives/Joint/committees/fiscal-review/cont...trusted
- comptroller.nyc.gov/wp-content/uploads/documents/RFP_NYC-Comptro...trusted
- das.nebraska.gov/materiel/purchasing/109035/109035%20O3%20FDG...trusted
- fdic.gov/system/files/2024-06/2020-request-for-info-s...trusted
- gsa.gov/buy-through-us/purchasing-programs/multiple-...trusted
- hcpf.colorado.gov/sites/hcpf/files/Sandata%20EVV%20Contract%20...trusted
- hcpf.colorado.gov/sites/hcpf/files/Conduent%20EDW%20Contract.pdftrusted
Educational content only. Not legal, tax, or financial advice.
Related Posts

The Freelance Payment Penalty: A Modeled Audit of Platform Fees, FX Spreads, and Payout Delays
The money rarely disappears through a single, easy-to-spot fee. The real loss is stacked. A marketplace takes its commission, a processor adds a charge for international cards, a bank or payment company converts the currency at a spread, a platform holds the funds before release, and a wire sheds a little to intermediaries on the way in. Each layer looks defensible on its own, but the worker feels the combined result as a smaller deposit and a later payday.

How to Respond to a Subpoena for Business Records
Move fast, but do not produce records on instinct. If you need to **respond to a subpoena for business records**, your immediate job is to control deadlines, preserve records, and make any later production defensible.

A US Expat's Guide to Investing in UCITS ETFs to Avoid PFIC Issues
The real problem is a two-system conflict. U.S. tax treatment can punish the wrong fund choice, while local product-access constraints can block the funds you want to buy in the first place. For **us expat ucits etfs**, the practical question is not "Which product is best?" It is "What can I access, report, and keep doing every year without guessing?" Use this four-part filter before any trade: