
Quick Answer
Use a seven-stage status taxonomy - submitted, pending review, in transit, paid, failed, held, and returned - and attach a timestamp plus next action to each state. Treat paid as valid only after provider completion and internal ledger posting both succeed, and route held or returned payouts to named owners with SLA clocks. Keep review details internal, but give recipients clear escalation paths when a status stalls.
Why Payout Visibility Builds Contractor Trust#
A payout tracker can help build trust when recipients can see what is happening, what happens next, and whether they need to act, without opening a support ticket. When payout status is vague, routine questions can turn into tickets, calls, and escalations. When status is clear, timestamped, and action-oriented, recipients can self-serve and support teams may spend less time chasing updates.
Treat visibility as a trust and service issue#
Do not treat visibility as just a UI feature. CFMA describes payment transparency as clear visibility into the payment pipeline and warns that poor transparency costs trust. That risk can be sharper when a subcontractor or lower-tier recipient is waiting on cash and cannot tell whether a payout is submitted, delayed, under review, or sent.
Use industry data as context, not as your benchmark. Levelset's 2022 Construction Cash Flow & Payment Report surveyed more than 500 construction companies. It found that less than 40% were paid within 30 days on average, and less than one-tenth were always paid on time for completed work. Read that as evidence that payment uncertainty is common, not as a target for your own recipient base.
Design for self-service and measure support impact#
Design for self-service first, then check whether support load actually changes. Zendesk defines ticket deflection as shifting routine questions to self-service, and notes that agents benefit when customers can resolve minor issues independently. Your tracker should answer the questions that usually drive the queue:
- Where is my money?
- What is happening now?
- What do I need to do next?
Set a baseline before launch. Pull payment-inquiry tags, then capture backlog and SLA views in your support tooling so you can compare before and after. If you cannot measure payment inquiry volume, queue aging, and time to resolution now, it will be hard to tell whether better visibility improved outcomes later.
Keep compliance gates in the design from day one#
Build the compliance gates in from day one. Transparency should give recipients clear status, but it should not expose sensitive internal review logic. The goal is clarity without creating legal, fraud, or operational risk.
If a payout can pause for risk or compliance review, include a neutral, customer-safe status and assign a clear internal owner for that state. Where AML obligations apply, these controls are mandatory. For money services businesses, 31 CFR 1022.210 requires an effective AML program that is commensurate with risk. That does not apply to every contractor platform, but if your business is in scope, your status model has to respect those review gates.
That is the frame for the rest of the guide. Build a tracker that gives recipients reliable self-service answers, supports internal status tracking, and keeps sensitive review mechanics appropriately controlled. Related reading: How to Build a Payment Sandbox for Testing Before Going Live.
What payment transparency must actually deliver#
Payment transparency is only credible when it works for both sides. Recipients need to see the current payout state, and finance needs to verify that state through audit and reconciliation records.
Define success as recipient clarity plus operator control#
Success means recipient clarity plus operator control. For recipients, show a current payout status and a timing signal. For finance, keep a chronological audit log and a payout reconciliation view that links bank payouts to the underlying transaction batches.
Use one practical test: can finance open a payout, inspect the related transactions, and confirm that the amount and state match what the recipient saw? If not, you have a status display, not a trustworthy tracker.
Set a concrete trust promise#
Set a concrete trust promise for U.S. contractors and subcontractors: each payout view should show current status, a timestamp, and clarify next steps when action is needed. Keep timing language program-specific, not universal.
In federal construction contexts, one clause uses 7 days after receipt of payment, while a DOT DBE rule uses 30 days. Your tracker should make timing visible without implying a single deadline across all contexts.
Use Levelset as context, not proof#
Use Levelset as context, not proof. Its 2022 report surveyed 519 U.S. construction companies. Related reporting links low visibility with trust erosion, but that does not validate your product outcomes by itself.
Set your own evidence standard before rollout, then measure it before and after launch. Good examples are payment-status inquiry volume, resolution speed for payout questions, and reconciliation mismatches between the recipient view and finance records.
To reduce payout friction without losing compliance controls, see Invisible Payouts: How to Remove Payment Friction for Contractors Without Sacrificing Compliance.
What to prepare before you build#
Do the data and ownership work before you design screens. Otherwise the tracker can look clear and still break down on exceptions, failed payouts, and finance reconciliation.
Gather the minimum baseline inputs#
Gather these four inputs first, even if they are messy:
- current payout state events or timeline records
- historical payout records with transfer dates and outcomes
- support ticket tags for payout questions
- existing service-level agreement (SLA) targets, if any
This is the minimum baseline for recipient trust and operator control. Your event data should capture traceable fields: when the transfer was initiated, destination of funds, estimated delivery date, if available, and a transfer identifier. If those fields are inconsistent, fix that gap before debating status labels.
Build one evidence pack from recent payout and support operations#
Build one evidence pack from recent payout and support operations. It should show top inquiry reasons, exception queue aging, failed payout causes, and where reconciliation becomes unreliable.
Start with support tags so payout questions are grouped by issue type, not dumped into one generic queue. Then check whether those tagged groups map to first-reply or resolution times. If they do not, you can count volume, but it is harder to tie problem types to response-time impact.
Next, pull payout history with both normal and exception outcomes. Provider taxonomies differ, but your pack should include terminal and problem states such as processing, posted, failed, returned, or canceled. Do not treat posted as guaranteed recipient receipt, because bank release delays can still happen.
Document where system truth breaks before UI work starts#
Review sample payouts and mark reconciliation breakpoints, such as missing provider references, missing status transitions in your internal ledger, or returned payouts that drop the return reason. Preserve explicit return reasons when available. Labels like account closed or no account are more useful than a generic failed state, especially since payouts are typically returned within 2-3 business days.
Set one engineering verification rule: for a sample payout, reconstruct the full payout state timeline from request through final outcome using historical records only. If that is not possible, the tracker will drift from finance reality.
Align ownership across finance ops, product, and engineering#
Align ownership across finance ops, product, and engineering early.
Define two things in writing: first, what support must be able to answer from the tracker without finance escalation; second, what recipients can see versus what stays internal, including exception approvals. Keep this operational and specific.
Set SLA basics up front: service scope, metrics, roles, and remedies when targets are missed. At minimum, define time-to-resolve goals by work type and working hours, and assign owners for each exception queue. Also define retry safety before build. Undelivered events can be resent for up to three days, so duplicate-processing controls and idempotency handling are prerequisites.
The target output of prep is simple: one evidence pack, one owner map, and one shared definition of payout truth before recipient-facing polish begins. Related: Payment Scheduling for Platforms: How to Build Flexible Payout Calendars for Contractors.
Choose a status taxonomy recipients can act on#
Keep the recipient-facing status model small, plain, and action-oriented. Provider systems may expose many statuses and sub-statuses, but recipients should only see states that change what they need to understand or do.
Start with a seven-stage working model#
One practical seven-stage model is: submitted, pending review, scheduled or in transit, paid, failed, held, returned. Treat this as a working product taxonomy, not a universal standard, because provider labels and lifecycle rules vary. For example, at least one major platform merged "In Transit" into "Scheduled" on January 29, 2025.
Use one filter for every label: if it does not change recipient understanding or action, merge it. Keep provider-specific detail in internal metadata. Your top-level status should answer one question fast: "What is happening to my payout right now?"
Write one meaning line and one next-step line per status#
For each visible status, write one short "what this means" line and one short "what to do next" line.
| Status | What this means | What to do next |
|---|---|---|
| Submitted | We received your payout request and are preparing it for processing. | No action needed unless we contact you for more information. |
| Pending review | Your payout is being checked before it can move forward. | Please wait. If this status does not change by your support window, contact support. |
| Scheduled or in transit | Your payout is scheduled or has been sent and is moving through the payment network. | Watch for deposit confirmation. Bank processing can still take 1-3 business days after some systems mark a payout paid. |
| Paid | The payout is complete on our side. | Check your receiving account. If funds are still missing after the stated bank window, contact support with the payout ID. |
| Failed | The payout could not be completed. | Follow the prompt in your payout dashboard or contact support to retry. |
| Held | Your payout is paused during review. | No immediate action unless we request information. Contact support if the hold exceeds the published review window. |
| Returned | The payout was sent but came back after a post-send issue or non-claim. | Review payout details and contact support before resubmission. |
Keep two distinctions clear: paid does not always mean instant bank availability, and returned is different from failed because it happens after send.
Show action text only when action is required#
Apply one rule consistently. If a status implies recipient action, show explicit action text. If it reflects an internal-only review, show a neutral waiting message plus an escalation path.
For review states like pending review and held, neutral language builds trust without exposing internal triggers. For failed and returned, show concrete next steps because recipients need a clear recovery path.
Use PayQuicker and Flashtract as pattern checks, not lists to copy. PayQuicker emphasizes status visibility plus support access in one place, while Flashtract shows how transparency improves control in lower-tier payment tracking. In both cases, the principle is the same: fewer, clearer statuses tied to the next obvious move.
Map events from request to final payout confirmation#
Map every recipient-visible status to a recorded system event, or do not show it yet. When the timeline, audit log, and historical payout records diverge, trust drops and reconciliation gets harder.
Define one canonical event chain before UI mapping#
Define one canonical event chain before UI mapping: payout request accepted, provider request submitted, provider response recorded, internal ledger posted, async provider update received, recipient notification sent. Provider labels can vary, but each handoff needs one internal event so you can reconstruct history later.
Make events immutable and store dispute-critical fields each time: payout ID, recipient ID, provider reference, timestamp, request payload hash or version, and retry token. Keep the exact idempotency key, or equivalent, on the event. Same-key retries should resolve to the same logical payout, not create a second-looking attempt in your records. For PayPal batch payouts, treat sender_batch_id the same way: reuse it for retry safety and avoid duplicate-request rejection in the 30-day window.
Bind each visible status to a triggering event and a verification check#
Bind each visible status to one triggering event and one verification check so product language stays anchored to system truth.
| Visible status | Triggering event | Verification before display |
|---|---|---|
| Submitted | Your platform persisted the payout request and generated the payout ID | Confirm request write succeeded before showing anything |
| Pending review | Internal review flag recorded, or a provider on-hold/review state recorded | Verify this is an actual review state, not a transient delay |
| In transit | Provider accepted the payout request or batch and returned a provider reference | Confirm provider reference is stored in the audit log |
| Paid | Provider completion confirmation recorded and your ledger posting completed | Confirm both provider-side completion and internal ledger write exist |
| Held | Provider or internal review explicitly marked the payout on hold | Auto-create an exception queue item with owner and timer |
| Failed | Final failure response recorded, or retries are marked exhausted in your system | Confirm this is not a retryable transport failure |
| Returned | Provider return event recorded or transaction log shows funds returned | Route automatically to reissue or recipient-update handling |
A status should be reproducible from stored events, not reconstructed from support notes or spreadsheets.
Confirm completion before moving a payout to paid#
Do not move a payout to paid on webhook receipt alone. Webhooks are a standard update path, but they still need confirmation logic.
Handle two conditions explicitly: undelivered webhook events can be resent for up to three days, and snapshot payloads can be stale by the time you process them. Deduplicate already processed events, and when payload freshness is uncertain, fetch the latest provider state before advancing status. If you replay missed events, process them in created order.
At minimum, require all three checks for paid: the event has not already been processed, the latest provider state still supports completion, and the internal ledger posting succeeded. If any check fails, keep the prior safe status, typically in transit, and open internal review.
Do not treat missing search records as proof of no payout activity. PayPal transaction search can lag by up to three hours, so during that window, prefer direct provider events and stored provider references.
Automate the held and returned branches#
Automate the held and returned branches so ownership starts the moment the state changes.
For held, create the queue item on event receipt with payout ID, provider reference, recipient, reason code, if present, and the last successful pre-hold event. For returned, attach both the original send event and the return event, then route directly to the team that can collect updated payout details or resubmit.
Treat these as expected lifecycle outcomes, not edge cases. The operating goal is simple: every payout is traceable end to end, every visible status has evidence, and every exception has an owner as soon as it appears.
Design two views that stay consistent#
Use two interfaces, but one event history. Your recipient timeline and ops reconciliation view should read from the same payout events so disputes, support, and month-end close can reconcile to the same payout-linked records.
Build both views from one payout spine#
Build both views from one payout spine: payout ID, transaction-level records, provider reference, and recorded state changes. Recipient labels can be simpler, but each label should map back to the internal event that triggered it. In ops, keep investigation fields visible, including provider references, transfer-status webhook events, and exception queue routing.
| View | Primary goal | Must show |
|---|---|---|
| Recipient timeline | Clarity and confidence | current status, timestamp, next action, ETA window when available |
| Ops reconciliation view | Investigation and close | provider reference, transfer-status updates, exception type/queue destination, reconciliation state |
| Export records | Audit and month-end support | historical payout records, settlement-batch links, processing details, status history |
Use one verification checkpoint: sample recent payouts and confirm the recipient status, ops status, and export rows all point to the same underlying event timestamps.
Design the recipient view around the next practical question#
Design the recipient view around the next practical question: where is this payout, what should I do, and what happens next. If you have an estimated arrival timestamp, present it as an estimate, not a guarantee. When delivery is uncertain, show a clear next action, such as asking the recipient to check their PayPal account, or state explicitly that no action is needed yet.
Do not mark a payout as paid just because it was sent. Keep a status like in transit until your completion checks confirm it.
Design the ops view for reconciliation first#
Design the ops view for reconciliation first. Show the provider-level details needed to investigate quickly: provider reference, transfer status updates, exception type, queue destination, and links to payout reconciliation artifacts. Apply one rule consistently: if a field helps dispute resolution or close, show it in ops even if it is hidden from recipients.
Route exceptions by type into the right queue instead of relying on manual triage. Keep payout history and exports ready for audit and close, and retain records to match your retention obligations, including at least four years where employment tax recordkeeping applies.
Set exception ownership and response SLAs#
Do not launch recipient-facing exception statuses until each exception class has three things: a named owner, a defined SLA clock, and a prewritten message. Without clear ownership for failed, held, returned, and review states, a tracker creates confusion instead of trust.
Assign one owner to each exception class#
Define classes from provider states you can verify, then map one accountable owner to each class. Stripe separates failed and returned payouts. Keep that distinction in your queue. Failed payouts void the pending transaction and return funds to you, while returned payouts come back as a separate return transaction and are typically returned within 2-3 business days. Adyen also documents an under-review path where manual review can freeze funds and block external payout.
Use a simple ownership rule: one active owner at a time, plus an escalation path that keeps routing until someone acknowledges. Avoid collapsing held, paused, and under review into one bucket, because missing requirements and manual review freezes call for different actions and different recipient messages.
Tier your service-level agreement by payout risk#
Set SLA targets by priority tier, not by status label alone. That lets you treat the same status differently when business risk is different.
Publish explicit timers per tier:
- acknowledgment timer
- investigation timer
- escalation timer
Severity-based models often use first-response targets like 4-hour or 1-hour, and some business-critical cases use 30-minute or 15-minute targets. You do not need to copy those exact thresholds, but you should define your own and auto-escalate when acknowledgment does not happen on time.
Add recipient macros that match the real state#
Create one approved macro per exception state so recipients get consistent, event-based updates. Each message should state what happened, what comes next, and whether the recipient needs to act.
Use provider-backed timing only where available. For returned payouts, say the transfer did not arrive and funds are being returned, with the note that returns are often visible within 2-3 business days. For paused payouts tied to missing tax information or other requirements, state what must be completed. Also say that payouts may unpause within two business days after required tax forms are submitted if no other requirements remain. For under-review states, keep the language neutral and avoid details you cannot confirm.
Extend escalation design to subcontractor chains#
If you support construction payout flows, include downstream subcontractors in the escalation design, not just the primary payee. Lower-tier participants can carry more payment risk, so a blocked primary payout can raise downstream payment risk.
Flag exceptions where primary payee status can delay subcontractor or second-tier subcontractor payment. Where contracts include defined payment windows, treat approaching deadlines as priority triggers. For DOT-assisted contract contexts, guidance cites payment to subcontractors no later than 30 days after the contractor receives payment. Use that as a risk signal where applicable, and escalate earlier when a hold threatens downstream timing.
Decide what to show and what to withhold#
Use a compliance-first visibility rule: show recipients what changed, what happens next, and what they should do, while withholding signals that expose internal risk controls.
Apply a visibility filter before writing recipient copy#
For each payout status, sort fields into show, internal-only, and never disclose.
| Category | Includes | Handling |
|---|---|---|
| Show | current status, timestamp, next step, support path | Show recipients a neutral state like "under review" when needed |
| Internal-only | investigator notes, internal risk codes, compensation-review handling notes | Keep these fields out of recipient copy |
| Never disclose | bank-side suspicious activity reporting signals | Keep SAR confidentiality explicit in policy and copy design |
If your flow touches bank-regulated review, keep SAR confidentiality explicit in policy and copy design. Recipients can see a neutral state like "under review," but not whether a SAR exists.
Separate live obligations from proposal noise#
Do not design messaging as if FAR Case 2023-021 is active. It was issued as a proposed rule on January 30, 2024, and withdrawn as of January 8, 2025.
If you set pay inquiry or transparency rules in your own policy, keep scope precise. OFCCP says EO 11246 was revoked, while Section 503 and VEVRAA remain in effect, and 41 CFR 60-1.35 addresses compensation-disclosure nondiscrimination obligations with an essential-job-functions defense. Do not assume those employee or applicant provisions automatically apply to independent contractor payout recipients.
Use plainspoken copy when details must be withheld#
When you cannot disclose the reason, keep the message clear and conspicuous: what changed, whether action is needed, when the next update is expected, and where support starts.
Use approved macros in both the tracker UI and support tickets, where available, so agents do not improvise sensitive explanations. The standard is practical: give recipients useful transparency while keeping risk-review logic internal.
Link transparency choices to margin and support cost#
Treat transparency as an economics decision: ship the status and history details most likely to reduce support load and reconciliation friction first, then expand.
Measure the economics at the payout level#
Track four metrics from day one: inquiry rate per payout, full resolution time, exception queue backlog, and cost-to-serve by status group.
| Metric | Definition | Measurement note |
|---|---|---|
| Inquiry rate per payout | Payment-related inquiries per consistent payout denominator | Use a consistent denominator such as completed payout attempts or total payouts in period |
| Full resolution time | Median elapsed time from ticket creation to final solve | Keep the definition stable before and after launch |
| Exception queue backlog | End-of-day unsolved tickets in exception queues | Use dated end-of-day unsolved-ticket snapshots, not a live queue view |
| Cost-to-serve by status group | Support cost joined to payout outcomes by status group | Join support demand to payout outcomes by status group |
Keep metric definitions stable. For support speed, use full resolution time, meaning median elapsed time from ticket creation to final solve. For backlog, use dated end-of-day unsolved-ticket snapshots, not a live queue view, so comparisons across weeks or cohorts stay valid.
Use a consistent denominator before and after launch, such as completed payout attempts or total payouts in period. If you change denominator definitions midstream, you will not be able to tell whether added visibility actually reduced inquiry pressure.
Join support data to payout statuses and reconciliation records#
Build one joined view that connects support demand to payout outcomes. In practice, map ticket reasons or tags to payout status groups, and attach payout IDs and provider references where available.
Use payout reconciliation reporting to split effort by outcome, especially failed payouts. A practical check is to sample a day and confirm the recipient timeline, internal reconciliation view, and ticket reason all point to the same payout event. If they do not, your cost analysis will be noisy. Tag early. If categorization happens late in the ticket lifecycle, resolution-time-by-status becomes unreliable.
Compare before and after the first two transparency features#
When you launch real-time payout tracking or expose historical payout records, use a straight before-and-after read on the same metrics.
Prioritize features that answer common recipient questions without agent help. Status visibility is often first because many payout providers expose status changes through events or webhooks, which lets your tracker reflect lifecycle changes. Historical records often come next because they can reduce repeat payment-history questions and reconciliation requests.
If a new detail does not lower inquiry rate, shorten resolution time, or reduce backlog, leave it for later.
Segment by operating model before you expand#
Do not evaluate all traffic as one pool. Cut results by operating model so you can see where transparency affects margin and service cost.
For example, a property-management portal may combine payment-status visibility and compliance-document workflows in one recipient surface. Contractor-heavy payout automation flows should be analyzed separately, especially in large batch operations where exception handling can scale quickly.
Use a simple decision rule. Ship the transparency elements that prevent repeat "what happened?" contacts first. Then add richer detail only after core status groups show lower support cost and less reconciliation friction.
Roll out in phases with hard verification gates#
Do not release transparency features to everyone at once. Roll out progressively: for example, start with a recipient cohort, expand rail by rail, and move to full coverage only after each gate passes.
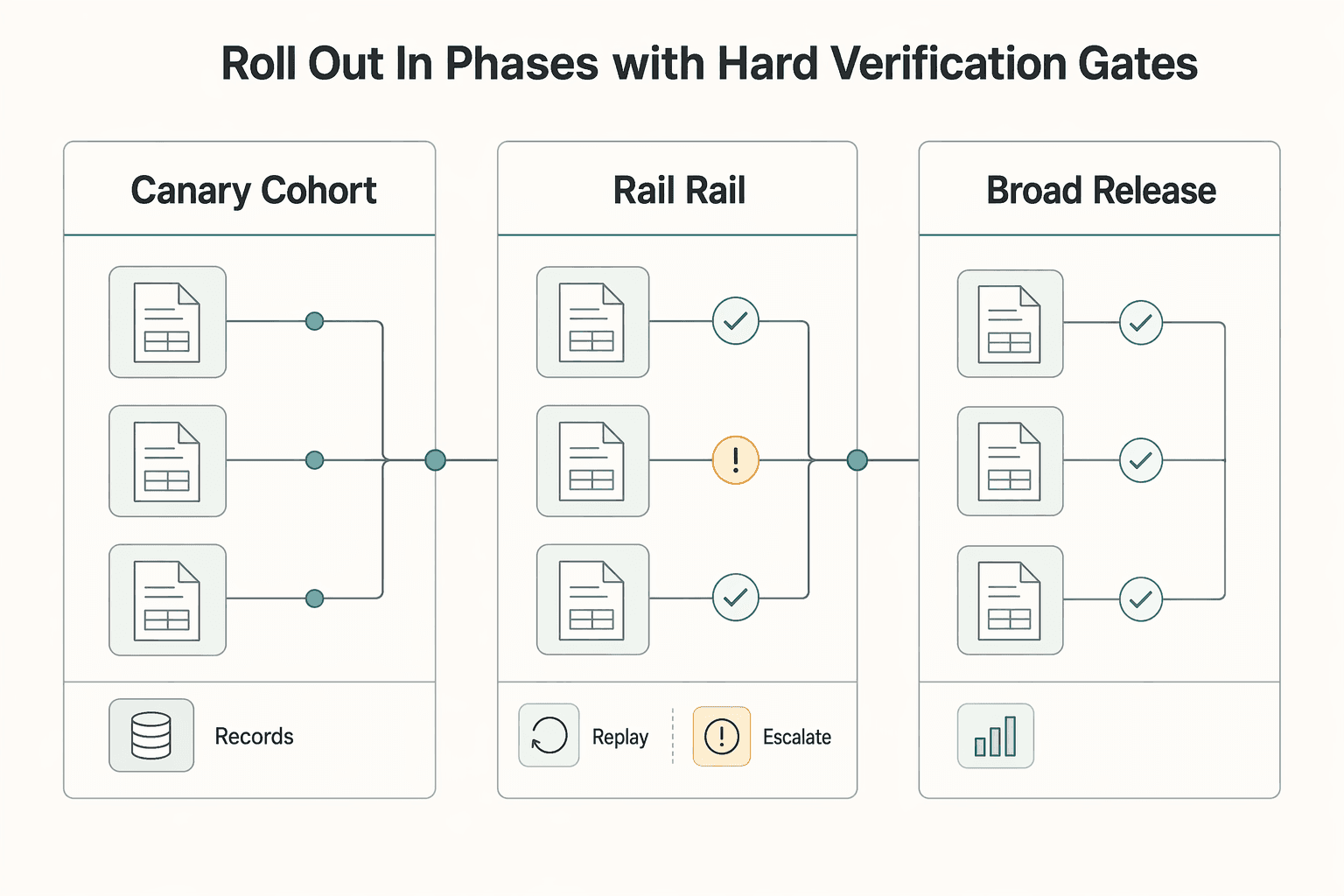
| Phase | Scope | Gate |
|---|---|---|
| Canary cohort | Start with one stable account-based or user-based cohort; a 10% step on 10,000 eligible contexts exposes about 1,000 | For sample payouts, confirm the recipient timeline, state-change record, and internal reconciliation view all match |
| Rail-by-rail expansion | Expand one payout rail at a time | Verify reconciliation view accuracy against the payout reconciliation report and verify exception-queue handling for failed webhook paths |
| Broad release | Move to full coverage only after each gate passes | Export event history in CSV or JSON tied to the same payout records used in reconciliation; require finance ops sign-off if export quality fails any checkpoint |
Start with a canary cohort#
Start with one stable canary cohort so you can validate behavior before broad exposure. Cohorts can be account-based or user-based, and progressive rollouts keep those buckets consistent. For example, if you had 10,000 eligible contexts, a 10% step would expose about 1,000.
Gate this phase on status-event consistency. For a sample of payouts, confirm the recipient timeline, the state-change record, and the internal reconciliation view all match. If the recipient sees a final status while event history shows an intermediate state, pause expansion and fix that mismatch first.
Expand rail by rail#
After the cohort passes, expand one payout rail at a time. Payout behavior can differ by payment method and operating context, so a clean result on one rail does not prove another rail is ready.
Use two gates per rail. First, verify reconciliation view accuracy against the payout reconciliation report, since reconciliation is organized around settlement batches. Second, verify exception-queue handling for failed webhook paths. Retries can run for up to 30 days, so queue aging and response ownership need to stay within your internal targets.
Hold broad release until finance ops signs off#
Before full coverage, confirm audit logs are exportable evidence, not just something visible in a console. Finance ops should be able to export event history in CSV or JSON and tie it to the same payout records used in reconciliation.
If export quality fails any checkpoint, require finance ops sign-off before wider release. Missing key audit details or event gaps weaken control evidence and make disputes and period close harder.
Before expanding coverage, align your verification gates to real payout state transitions by reviewing Payouts and mapping each status to an auditable event.
Common mistakes and how to recover fast#
Even after a gated rollout, trust can break in four common places: too many statuses, mismatched timelines, unowned exceptions, and legalistic recipient copy. The fix is usually straightforward: simplify the model, enforce one event record, assign escalation ownership, and rewrite messages for first-read clarity.
Collapse the status taxonomy#
If recipients cannot tell whether to wait, update details, or contact support, the status model is doing too much. A compact status model is feasible in real systems, so keep only statuses that change recipient understanding or operator handling, and remove labels that do neither.
For each remaining status, define two fields: what this means and what to do next. Also avoid treating a posted or paid-style status as guaranteed receipt, because banks can still delay fund release. Before relaunch, make sure every final-looking status includes a clear bank-delay recovery path.
Enforce one event source and repair historical payout records#
When recipient and ops timelines disagree, stop patching both views separately. Use one state-change record as the shared reference, and have both views read from it.
Webhook-driven status updates can serve as that primary event source. You can automate reconciliation by matching provider events to internal records with a correlation ID across webhooks, API responses, dashboard searches, and reconciliation exports. Revalidate historical records so the recipient view, ops view, and exports show the same timestamps and state order. If trace IDs are part of support, investigate before the 10-day unsupported window.
Assign owners and escalation timers before expanding access#
A clearer UI will not help if exception queues have no accountable owner. Assign named responders by exception type and configure escalation timeout minutes for every rule before broader rollout.
Escalation policies are designed to notify one target at a time until someone acknowledges. Use that structure to prevent aging items from drifting without action. For returned payouts, set recipient expectations around the typical 2-3 business day return window, then route to manual review when the window is exceeded.
Rewrite compliance copy into plain language#
Recipient-facing compliance text should explain status and next action, not mirror internal legal drafting. Use wording people can understand on first read, with everyday language unless a technical term is necessary.
Keep policy detail in internal docs, and keep tracker copy focused on the basics: current status, what it means, what happens next, and when to contact support. If a sentence reads like legal review text, move it behind the curtain.
For a step-by-step walkthrough, see How to Build a Trust and Safety Program for Your Contractor Marketplace.
Conclusion and copy paste checklist#
Trust comes from making each payout legible, not from adding more screens. A tracker people trust shows a current status, timestamp, owner for exceptions, and next action tied to a verifiable event.
Define a small status taxonomy before you build UI#
Define a small status taxonomy and plain-language action text before you build UI. Keep recipient statuses action-oriented and provider-safe: pending, under review, paid, failed, and canceled, plus held or returned only when that rail supports them.
Check each status with two one-sentence tests: "what does this mean?" and "what should I do now?" Do not leak internal processing labels into recipient copy. PayPal explicitly includes an under-review On Hold state, while Stripe payout status filtering includes pending, paid, failed, and canceled.
Map every visible status to a verifiable event and retry rule#
Map every visible status to a verifiable event and retry rule. If you show paid, you should be able to point to the event that triggered it, not just a request your app sent.
For Stripe connected payouts, that typically means payout.created, payout.updated, payout.paid, and payout.failed, with provider references stored alongside your internal record. Use idempotency keys on retries so repeated requests do not create duplicate operations. Also keep expectations realistic: payout event notifications can span multiple days.
Set exception ownership and SLA timers before rollout#
Set exception ownership and SLA timers before rollout. Each exception class needs a named owner, start time, and escalation path.
At minimum, assign ownership for failed and under-review/on-hold payouts, and add held/returned queues only where your provider supports those states. Stripe also notes a failed payout can block further payouts to the same external account until details are updated, so unresolved failures can spread beyond one payout.
Split recipient and ops views, but keep one event source#
Split recipient and ops views, but keep one event source. Recipients should see the timeline, timestamp, and next action. Operators should see provider references, retry history, failure codes, where available, and audit event records showing who changed what and when.
Use payout reconciliation as a hard gate: finance should be able to match bank-received payouts to the transaction batches they settle. If reconciliation and the recipient timeline disagree, treat that mismatch as an incident.
Launch in phases and expand only with proof#
Launch in phases and expand only with proof. Canary and percentage rollout patterns reduce risk by letting you validate metrics before full exposure.
Start with a small subset, then expand only if status-event consistency, exception queue aging, audit-log completeness, and reconciliation accuracy pass your gates. Roll back when they do not.
Use this copy-paste checklist:
- Define your status taxonomy and action text for each state.
- Map each visible status to a verifiable event and retry rule.
- Stand up exception queue ownership and SLA timers.
- Split recipient and ops views on one event source.
- Launch in phases with verification gates before full rollout.
When your checklist is complete, use Docs to implement webhook-driven status tracking, idempotency keys, and reconciliation-ready exports in production.
Frequently Asked Questions
What is payment transparency for contractor payouts in practical terms?
Payment transparency means the people involved can see where a payout is in the pipeline with less reliance on back-and-forth support updates. In practice, a practical minimum is clear status visibility, when that status was recorded, and what happens next. That gives recipients clarity and gives support and finance one shared reference point.
What minimum fields should a contractor payment-status tracker include?
Include the fields needed to find, explain, and verify a payout: payout identifier, status, amount, currency, and timestamp. If you use PayPal Payouts, use payout_batch_id for status lookup and keep timestamps in ISO 8601 format. For operations, keep provider references, processing timestamps, and a linkable record tied to your transaction log or payout reconciliation report.
How does real-time payout tracking reduce inbound support volume?
It can reduce avoidable “where is my payout?” contacts by giving recipients enough detail to self-serve first. Stripe explicitly notes that exposing Trace IDs can help minimize support requests for late or missing payouts. When a payout is delayed, your tracker should show the Trace ID and explain what to do if funds have not arrived after 10 business days.
What status stages are most useful for recipients versus internal teams?
Recipients need a short, action-oriented view, while internal teams need deeper operational detail. A useful recipient set is pending, under review or on hold, in transit, paid or completed, failed, held, and returned or unclaimed, with plain next steps. Keep retries, provider responses, processing logs, and reconciliation detail in internal views unless they change recipient action.
How do we balance transparency requirements with compliance constraints?
Be transparent about status and next step, but do not expose protected internal reasoning. In regulated contexts, SAR-related confidentiality can limit what you can disclose about review activity. If you cannot share the reason, state that processing is paused, what happens next, and when the recipient should contact support.
How should we handle failed, held, returned, and under-review payouts?
Treat each as a separate exception flow with a clear owner, recipient message, and escalation timing. For failed payouts, confirm whether funds were deducted before promising a resend; PayPal states failed payouts are not deducted from the sender’s account. For held or under-review payouts, communicate that processing is paused without exposing internal triggers. For returned or unclaimed payouts, state the recovery path clearly, including PayPal’s 30-day auto-cancel behavior for unclaimed transactions.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
- consumerfinance.gov/rules-policy/regulations/1005/31trusted
- csrc.nist.gov/glossary/term/audit_logtrusted
- dol.gov/agencies/ofccptrusted
- ecfr.gov/current/title-48/chapter-1/subchapter-H/part...trusted
- ecfr.gov/current/title-31/subtitle-B/chapter-X/part-1...trusted
- federalregister.gov/documents/2024/01/30/2024-01343/office-of-fe...trusted
- federalregister.gov/documents/2025/01/08/2025-00118/office-of-fe...trusted
- informationliteracy.gov/resources/plainlanguagegovtrusted
Educational content only. Not legal, tax, or financial advice.
Related Posts

Invisible Payouts: How to Remove Payment Friction for Contractors Without Sacrificing Compliance
Invisible payouts should make life easier for contractors without hiding the controls your team needs. Contractors should get a predictable, low-friction flow, while internal teams can still enforce and document payout decisions when needed. If you run contractor payouts at scale, you need both outcomes at once. We recommend treating every easy payout as a controlled release path your team can replay later.

Payment Scheduling for Platforms: How to Build Flexible Payout Calendars for Contractors
**Treat payout calendar design as an operating policy, not a booking feature.** A lot of payment content focuses on booking and checkout flows. That is a different problem from deciding when contractors become eligible for payout, what can block release, and how finance closes each cycle without surprises.

How to Show Fee Transparency to Contractors: Building a Clear Payment Breakdown UI
Your payment breakdown UI should answer two questions at a glance. Contractors should be able to see how an invoice turns into a net payout. Finance should be able to close the payout without manual cleanup. If the recipient view cannot be traced back to approval and accounting records, it is not transparent enough to run.