
Quick Answer
Start by treating trust and safety contractor marketplace design as an operating and margin decision, not a policy document. Set business targets first, prepare an evidence pack and data-boundary map, then split in-house versus vendor ownership across moderation, policy, and compliance work. Implement controls in sequence from onboarding checks to ongoing monitoring and escalation. Use monthly checkpoints on review cost, abuse loss, conversion, and retention so controls are tightened or relaxed by segment.
Build trust and safety as a margin decision from day one#
Step 1. Treat trust and safety as an operating choice#
Start by deciding that your Trust and Safety program exists to protect users and business performance at the same time. In a contractor marketplace, weak controls do not stay contained as policy issues. They show up as operational losses, higher support burden, and slower growth when teams are forced to clean up preventable damage.
Trust and Safety is the set of tools and business practices a marketplace uses to protect users and its own integrity. That makes it a business-owned problem, not a legal-only one. Founders, product, revenue, and finance should agree on who owns risk decisions, who approves spend, and which losses count against margin. Without shared ownership, policy, product, and finance can drift apart.
Use one simple checkpoint. Name one accountable owner and write down the business outcomes they are expected to improve. If nobody can say who owns abuse loss, review cost, and conversion impact together, you do not have a real operating decision yet.
Step 2. Define success in business terms first#
Set success measures before you buy tools or hand work to vendors. Early targets can include fewer failed transactions and fewer abuse losses. Next comes predictable operating load, so review queues and escalations do not spike every time volume rises or a new feature goes live. The third target is a defensible regulatory compliance posture.
That last point is no longer background work. Trust and safety is increasingly treated as a normal business function as regulatory pressure grows. If you operate in the UK, Ofcom's online safety regulatory documents page is a concrete example of regulators spelling out duties and the steps service providers need to take. That page was published on 23 October 2025 and updated on 15 December 2025. Software may help, but it does not transfer your responsibility to follow those duties.
Make this practical by listing the four numbers you will review every month. One workable set is failed transaction rate, abuse loss rate, review volume, and compliance or enforcement exceptions. If none of those are currently visible, your team is still operating on intuition.
Step 3. Phase scope by market and monetization risk#
Do not design for every country, every abuse type, and every edge case on day one. Coverage varies by market, expectations differ, and implementation gaps still exist across platforms. The OECD's 2021 survey covered 28 countries and 15 platform businesses, which is a useful reminder that there is no universal trust rulebook you can copy into your marketplace.
Phase controls by risk profile and revenue exposure instead. If you are early and concentrated in one market, start with the harms most likely to block completed transactions or create direct loss. If you are moving into new regions or higher-risk categories, add stronger controls in stages and document why each control exists. That written rationale becomes part of your evidence pack when a partner, auditor, or regulator asks how decisions were made.
There is a clear tradeoff here. Large marketplaces may need always-on capacity, but most teams should not staff or buy for 24/7 coverage on day one. Upwork has described a 24/7 operation backed by a large dedicated team, which is a scale marker, not a starting requirement for everyone. Build to your current risk, verify what is actually hurting margin, and expand from there.
For a step-by-step walkthrough, see How to Compare Freelance Hiring Paths by Trust, Evidence, and Control in 2026.
Set your operating target before you buy tools or vendors#
Set the operating target before tool selection, or you will buy coverage that does not match the harms affecting your contractor marketplace. A single platform-wide risk statement is usually too vague to run day to day. Define harm classes, assign owners, and decide where friction belongs in the flow.
Step 1. Name the harms that can actually move margin#
Start with the abuse lanes most likely to hurt users or completed transactions: fraud, harassment, listing abuse, and payment abuse. Map each lane to one control owner who can approve rule changes when that lane worsens.
Use a strict prioritization rule: if one abuse class can materially reduce take rate or transaction completion, fix it before expanding feature breadth. Marketplace risk includes both financial crime and non-financial abuse, and unresolved abuse can push users to leave. Before shopping vendors, document each harm with one recent example, user impact, business impact, and named owner.
Step 2. Write risk appetite by flow stage#
Write risk appetite by flow stage, not as one global statement. Set expectations separately for signup, profile or listing creation, messaging, booking, and payout.
Place onboarding checks at entry points, then use in-product monitoring where abuse appears later in the lifecycle. Friction tolerance should vary by stage; many teams can justify more friction at payout than at profile creation. Avoid concentrating controls only at onboarding while leaving messaging or payment abuse under-monitored.
Step 3. Turn policy into enforceable targets#
Convert community guidelines into operating targets your team can execute: response-time goals, false-positive tolerance, and escalation triggers. Set response targets by severity instead of using one SLA for every case.
For urgent violations, action may need to happen within minutes; lower-risk reports can run through slower queues. Track false positives by review lane so you do not reduce abuse at the cost of legitimate contractor conversion and higher support load.
Prepare the minimum inputs your team needs before implementation#
Before implementation, lock three inputs: a starter evidence pack, a data-boundary map, and a baseline metric set. If any of these are weak, you risk shipping policy gaps and compliance mistakes into version one.
Step 1. Build a starter evidence pack#
Build a working pack that gives product, ops, policy, and legal the same factual starting point. Include:
- Abuse taxonomy
- Current community standards
- Recent incident examples
- Policy gaps those incidents exposed
For each incident, capture what happened, which rule applied (or failed), who decided, and business impact. If you cannot point to a specific standards gap or enforcement gap, you are not ready to configure tooling. Ownership should also be explicit across legal, policy, product, and ops; if rule-change ownership is unclear, pause and fix that first.
Step 2. Document data boundaries before you collect more#
Run an information audit or data-mapping exercise before you add new checks. Your record should document the source of personal data, where and how it is stored, who can process or view it, who it is shared with, and retention period.
Use data minimisation as the operating rule: collect only what is necessary for a stated purpose. If a vendor requests extra personal data without a clear use case, treat it as a red flag. You should be able to explain why each field exists, which workflow needs it, and when access should end or the data should be deleted. If you need a deeper treatment, see GDPR for Marketplace Platforms: How to Handle Contractor and Seller Personal Data Compliantly.
Step 3. Capture baseline metrics you can compare later#
Freeze a baseline before implementation changes behavior. Track the same definitions across three areas:
| Area | Metrics | Notes |
|---|---|---|
| Identity verification | Pass/fail counts by flow; false match and false non-match rates when available | Freeze a baseline before implementation changes behavior |
| Content moderation | Queue volume, aging, and major decision buckets | Confirm you can reproduce the same metrics one month later using the same definitions |
| Payments | Dispute activity and dispute rate | Cardholders can dispute up to 120 days after payment; Stripe cites dispute activity above 0.75% as excessive as a reference point, not a universal benchmark |
For disputes, use both metrics together. Cardholders can dispute up to 120 days after payment, so very recent data is incomplete. Stripe cites dispute activity above 0.75% as excessive, which is a reference point, not a universal benchmark.
Final check: confirm you can reproduce the same metrics one month later using the same definitions. If not, fix measurement before buying additional controls.
Split ownership across the trust and safety stack with explicit buy vs build rules#
Use your evidence pack, data map, and baseline metrics to set ownership rules before you scale vendors. A practical default is to keep policy interpretation, exception handling, and final enforcement judgment with your internal team, and outsource repetitive lanes only where quality controls are measurable and auditable.
Step 1. Keep policy judgment and final decisions close to the business#
Third-party providers now operate across the trust and safety stack, not only moderation. The network spans moderation, policy/community standards support, tooling, and regulatory-compliance support, so governance can drift if one vendor is shaping rules, applying them, and reporting outcomes without strong internal oversight.
Keep internal ownership of the decisions that express risk appetite: policy interpretation, escalation criteria, and hard enforcement calls. You can still use external support for execution, but assign a named internal owner to approve policy changes and resolve edge cases.
If ambiguous cases are handled outside that internal path, enforcement consistency usually drifts before the trend is visible. Define a written escalation route for every exception lane.
Step 2. Outsource repetitive review lanes only when QA is measurable#
Outsourced moderation is most defensible in high-volume lanes with clear labels and narrow escalation rules. Human moderation quality needs active monitoring, so do not outsource a queue unless you can measure consistency, fairness, and accuracy against your own standards.
Before go-live, test vendor performance on a holdout set from your own incidents and compare decisions using one shared metric dictionary. This matters because cross-industry moderation metrics are not standardized, and names and definitions vary.
Tooling and compliance support can still be useful, but governance depends on traceability. Require decision records that can flow into your existing ops data with policy version, timestamp, and evidence references intact.
Step 3. Score vendors on governance fit, not just queue coverage#
Do not treat public search results as proof of cross-vendor pricing or performance. Public comparisons are limited, pricing is usually customized, and performance claims are hard to compare when metric definitions differ.
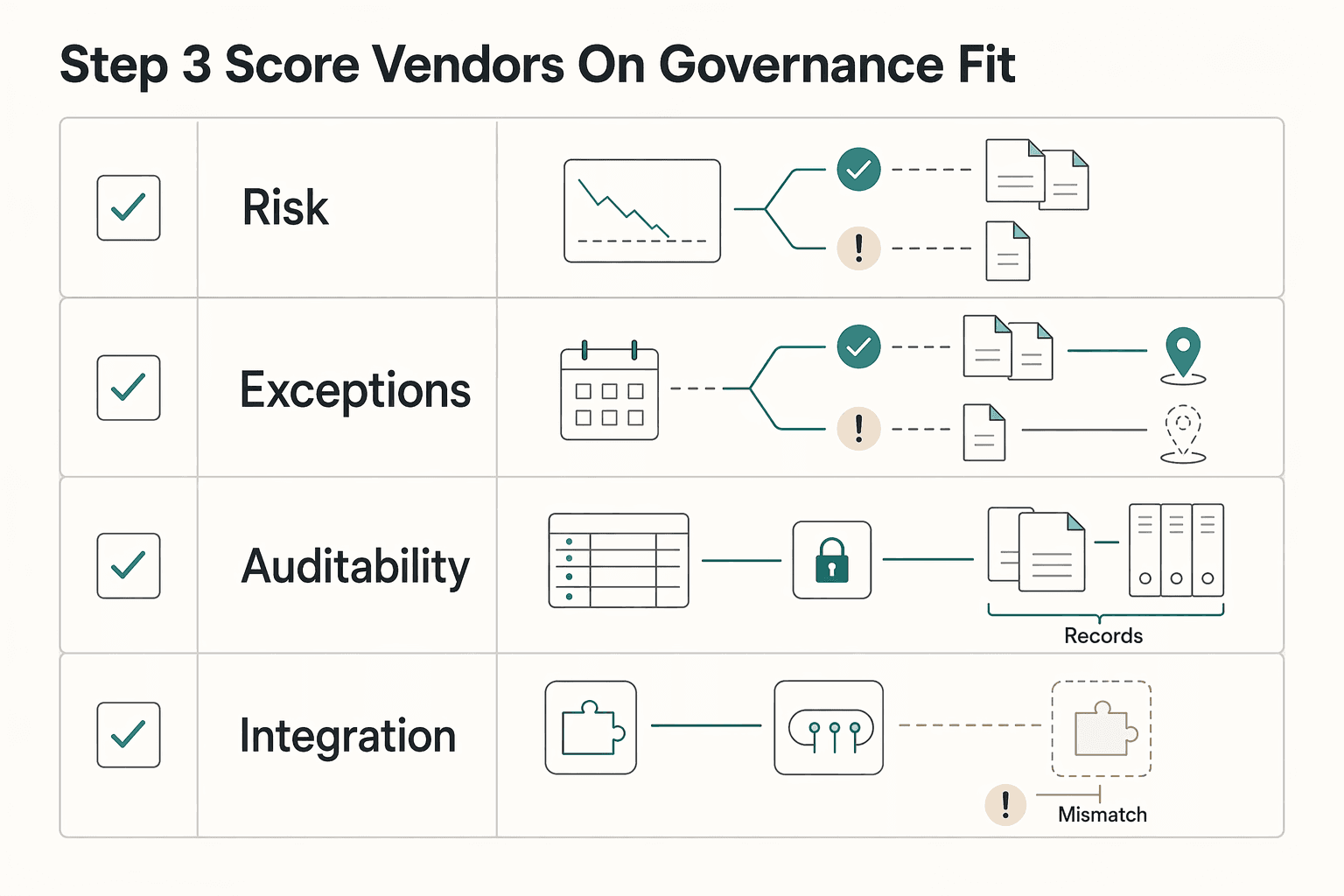
| Selection criterion | What good looks like | Red flag |
|---|---|---|
| Quality drift risk | Documented QA method, calibration process, and a clear path for policy updates to reach reviewer decisions | One headline quality number with no rubric, no sampled reviews, and no disagreement method |
| Escalation transparency | Edge cases route to your internal policy owner with clear reason codes and visible queue status | Gray-area cases are resolved inside the vendor team and you only see final outcomes |
| Auditability | Exportable case ID, reviewer decision, policy version, timestamp, and evidence reference per case | You cannot reconstruct why a decision was made or which policy version applied |
| Integration burden | Decision data syncs into existing ops records without manual copy steps | A separate console creates duplicate records and weakens your audit trail |
If this visibility is missing, keep scope narrow. Start with one lane, one metric dictionary, and one escalation path, then expand only after you can verify governance and quality in your own operating context. Related: The Best Software for Trust and Estate Administration.
Implement controls in sequence across onboarding and ongoing activity#
Start with account integrity, then add suspicious-activity controls, then run continuous enforcement. This sequence reduces avoidable abuse earlier instead of pushing preventable cases into moderation queues.
Step 1. Add onboarding checks before you scale transaction volume#
Put onboarding checks, identity verification, and two-factor authentication at the front door. Verification confirms that people are who they claim to be, and MFA materially lowers account-compromise risk, so this is the right place to protect both signup and account access.
Keep ownership explicit. The relying party should be authoritative on whether reauthentication requirements are met, so your system should clearly define what is checked, what triggers a challenge, who can override failures, and what evidence is stored.
Step 2. Trigger reverification when behavior changes, not on a fixed calendar#
Use reverification when risk signals change, and use link analysis to identify potentially related accounts or network abuse patterns. Link analysis should inform investigation, not act as a complete detector by itself.
If you use risk scoring, define what routes to review and what blocks automatically. One production example uses 65 for elevated risk and 75 for high risk; treat that as a reference point and tune against your own incident history.
Keep a clean audit trail for each reverification event: trigger, initiating rule or reviewer, and final outcome.
Step 3. Run continuous enforcement through queues tied to community guidelines#
After front-door and midstream controls are live, run queue-based content moderation aligned to community guidelines and incident severity. Use automated detection for clear-cut violations, and route harder cases to human review.
Make manual review an explicit lane, and include user reports as an input signal. Launch high-confidence blocks first, add manual review for borderline cases, then tune thresholds after incident retrospectives show where you are missing abuse or over-blocking legitimate users.
Build enforcement and escalation that can survive real incident load#
Consistency is what usually fails first under incident load, so your enforcement ladder needs to map directly to your community standards.
Step 1. Define an escalation ladder by violation severity#
Write the ladder in plain operator language, with actions that increase by severity: warning, content removal, temporary suspension, account restriction, permanent removal. Front-line reviewers should know what they can decide directly, what must escalate to policy owners, and what needs legal or compliance input.
Tie each decision to the rule, not reviewer instinct. For each major standard, document the triggering behavior, the default action, and the escalation condition. If automation flags or removes content first, define when moderator confirmation is required before the restriction is final.
Step 2. Pre-plan failure modes before queues spike#
Set explicit handling for the three failure modes that create inconsistent outcomes:
- False-positive lockouts: give users a clear path to challenge major restrictions, with a priority lane for account-access mistakes.
- Backlog spikes: define what can be auto-actioned, what can wait, and what must escalate immediately.
- Policy edge cases: route novel abuse patterns to rapid policy review so reviewers do not create ad hoc precedent.
If backlog pressure starts changing outcomes, policy is no longer driving enforcement.
Step 3. Make major actions auditable and calibrate outsourced review quality#
Every major enforcement action should leave an auditable trail: case ID, violated standard, evidence reviewed, action taken, triggering actor or rule, user notification, and appeal or reversal outcome. That supports postmortems and compliance record-keeping, including retained records of risk assessments and compliance measures under Online Safety Act 2023 guidance, and clear statements of reasons for content restrictions in DSA Article 17 scope.
If you outsource moderation, do not rely only on vendor QA scores. Run recurring calibration between internal policy owners and external reviewers on sampled decisions, especially reversals, edge cases, and high-severity actions, to keep decisions correct and consistent.
Connect trust and safety decisions to pricing, conversion, and margin#
Trust and safety controls should earn their place in your P&L. Stricter onboarding checks and reverification can reduce abuse, but they can also reduce activation and completed transactions if friction lands in the wrong places or legitimate users get blocked.
That tradeoff is measurable. Payment and fraud controls can create false positives, and legitimate users may abandon when valid transactions are declined. Treat each added check as a priced business decision with both upside and drag.
Step 1. Segment where you add friction#
Use risk bands instead of applying the same onboarding burden to every flow. Low-risk flows should stay light; higher-risk flows should get stronger checks and a path to manual review.
| Segment | Typical control posture | When to escalate | Main metric to watch |
|---|---|---|---|
| Low-risk signup or browsing | Minimal onboarding checks, passive monitoring, no manual review by default | If behavior changes or linked abuse signals appear | Activation rate and first-session dropoff |
| First monetized transaction or payout setup | Identity verification, authentication step, targeted reverification if signals change | Manual review for mismatched identity, suspicious account changes, or payment anomalies | Completed transaction rate, review cost per transaction |
| High-risk or high-impact flow | Strong checks plus manual review before key action completes | Immediate escalation for repeat abuse signals, high-value activity, or linked accounts | Fraud loss avoided, false-positive rate, retention after review |
A practical rule: keep lighter controls where abuse impact is low and review cost is high; add earlier friction where potential loss is materially higher.
Step 2. Tie each control to unit economics#
Evaluate every control against the same four questions: cost per transaction, loss prevented, conversion impact, and retention effect. Finance and cross-functional leadership increasingly expect measurable outcomes like revenue lift, cost reduction, customer base growth, and retention impact, not just a larger trust and safety budget.
Use a monthly scorecard with:
- review cost per completed transaction
- fraud or abuse loss avoided
- activation-to-first-transaction conversion
- reversal or appeal rate on manual decisions
- 30-day retention for users who passed, failed, or were stepped up
Then test by segment. If a low-risk cohort gets frequent step-ups with little abuse reduction, you are adding cost without enough return. If a high-risk cohort keeps strong completion while loss rises, controls are likely too soft or too late.
Step 3. Review trust and safety as a controllable margin lever#
Treat trust and safety spend as a controllable, COGS-like operating lever in planning, while keeping formal accounting treatment separate. Review it monthly with revenue and finance so pricing, promotion strategy, and control settings stay aligned.
Do not use fraud reduction alone as the success metric. The joint EBA-ECB report says strong customer authentication contributed to reducing fraud levels, but broader friction can still lose legitimate users through false declines or unnecessary reverification. The goal is stronger contribution margin, not only fewer incidents.
Market scope also matters. The UK Online Safety Act passed into law on 26 October 2023, and duties are described as proportionate to risk of harm and provider size and capacity. Ofcom also notes that if a service fits multiple regulated categories, associated legal requirements can stack. So control design may need to vary by market, product surface, and regulatory obligations rather than stay globally uniform. If UK scope is relevant, keep a separate control map and legal review path. For a deeper treatment, see Online Safety Act UK: What Marketplace and Platform Operators Must Do to Comply.
Fix common mistakes before they lock in cost and risk#
The costly pattern is treating trust and safety as a one-time setup instead of a system you review and enforce continuously. Fix four habits early so cost, appeals, and compliance risk do not compound later.
- Onboarding-only controls
Onboarding is not enough on its own. Keep trust and safety active after signup with regular review of live activity, account changes, and moderation outcomes, because abuse pressure shifts downstream if controls stop at the front door.
- Outsourced decisions without internal governance
You can outsource execution capacity, but not accountability. Under UK GDPR Article 28, the controller still has to select processors with sufficient guarantees, so your team should retain policy ownership and final escalation authority.
- Policy text without operator instructions
High-level prohibitions are not operational guidance. Your terms and community rules should include enforceable restrictions plus the moderation procedures, measures, and tools your team applies, including where automated and human review are used, so decisions stay diligent, objective, and proportionate.
- Compliance sprawl across disconnected docs
Do not split obligations across scattered notes and threads. Maintain one current control map that ties controls to owners, records, and evidence, including Article 30 ROPA duties and, where in scope, Online Safety Act 2023 Section 23 record-keeping and regular compliance review duties.
Related reading: California Meal and Rest Break Laws and Contractor Misclassification Risk.
Use this checklist to launch and scale without hidden trust costs#
To launch and scale without hidden trust costs, turn trust and safety into explicit operating gates before case volume grows.
- Confirm scope: Document the top abuse types, target outcomes, and risk appetite for your contractor marketplace, with clear escalation triggers in writing.
- Confirm ownership: Define the internal vs vendor split across your trust and safety stack, and keep policy interpretation, exception handling, and final enforcement authority with your team.
- Confirm controls: Deploy identity verification and two-factor authentication early on higher-risk lanes, then add reverification triggers and content moderation in sequence as live patterns emerge. CISA reports that MFA makes accounts 99% less likely to be hacked, and NIST includes periodic reauthentication (with a maximum overall timeout of 12 hours at AAL3).
- Confirm governance: Run an update loop for community standards, moderation QA, and incident postmortems. Keep auditable records for major actions; if your UK service may be in Online Safety Act scope, document risk assessments and compliance measures and review them regularly.
- Confirm economics: Review trust cost, fraud impact, conversion impact, and retention impact monthly with finance and revenue leaders, and judge tradeoffs by segment rather than one blended platform number.
Map your current controls to this checklist, then confirm where Gruv modules and compliance gates fit your market coverage.
Frequently Asked Questions
What is the minimum Trust and Safety program a contractor marketplace needs to launch credibly?
Start with a documented risk-reduction program: clear moderation and escalation rules, onboarding checks on the highest-risk entry points, and an auditable record of what happened in each major decision. If your UK service may be in scope of the Online Safety Act 2023, the minimum credible bar also includes an illegal-content risk assessment. Ofcom says services the Act applies to have three months after launch to complete that assessment. A good test is whether you can reconstruct why a listing, account, or message was approved, restricted, or escalated.
What should we keep in-house versus assign to the third-party vendor network?
Keep policy interpretation, exception handling, and final enforcement authority inside your team. Use vendors for repeatable review lanes or specialist capabilities that help detect, prevent, or remove harmful accounts, behaviors, content, and transactions. If a vendor cannot show escalation transparency or how policy updates reach reviewers, that is a governance risk, not just an ops detail.
When does outsourced content moderation improve outcomes, and when does it create more risk?
It can help in higher-volume, repeatable lanes when your written guidance is stable enough for quality checks. Risk is higher when work is heavy on edge cases, when incorrect decisions could seriously harm people, or when moderation relies on personal data without strong controls. A common failure mode is drift: reviewers follow stale instructions, appeals rise, and consistency drops.
How do onboarding checks affect conversion and revenue in practice?
There is no single conversion or revenue rule that applies universally. Treat it as a measurement problem: track pass rate, manual-review rate, completed transaction rate, and downstream abuse or dispute loss by segment. If your own data shows a low-risk cohort with strong completion and low loss, lighten checks there before loosening controls everywhere.
How often should we run reverification and link analysis without overloading operations?
There is no universal cadence that fits every marketplace. A practical starting point is trigger-based reverification when behavior or account details change, then expanding only where those reviews actually catch meaningful abuse. Watch backlog, reviewer yield, and false-positive lockouts. If volume rises faster than decision value, your triggers are too broad.
What is still unknown when comparing trust and safety vendors?
A lot of the market is still hard to compare cleanly because there is no clear industry standard for how trust and safety teams are organized. That means cross-vendor pricing and performance comparisons are often not apples-to-apples. Ask for lane-level QA methods, escalation paths, and sample audit evidence, not just accuracy claims or branded dashboards.
How do GDPR and Online Safety Act UK obligations change program design for cross-border marketplaces?
First, do not assume every marketplace is in scope of the Act. If your service is in scope, Ofcom says providers can still be legally responsible for UK users' safety even if they are based outside the UK. As of 17 March 2025, platforms have a legal duty to protect users from illegal content online. At the same time, UK GDPR data minimisation means you should collect and hold only the personal data you need. So your moderation design has to separate necessary evidence from nice-to-have data and document both the illegal-content risk assessment and the data handling choices together.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
Includes 4 external sources outside the trusted-domain allowlist.
- digital-strategy.ec.europa.eu/en/faqs/dsa-transparency-database-questions-...trusted
- eba.europa.eu/publications-and-media/press-releases/joint-...trusted
- legislation.gov.uk/eur/2016/679/article/28trusted
- gov.uk/government/publications/online-safety-act-ex...external
- gov.uk/government/collections/online-safety-actexternal
- ico.org.uk/for-organisations/uk-gdpr-guidance-and-resou...external
- ofcom.org.uk/siteassets/resources/documents/online-safety...external
Educational content only. Not legal, tax, or financial advice.
Related Posts

GDPR for Marketplace Platforms: How to Handle Contractor and Seller Personal Data Compliantly
Treat this as an operating decision, not a policy exercise. If you own compliance, legal, finance, or risk for a platform, your job is to decide who owns each GDPR duty. You also need to define what evidence must exist, what your team reviews on a recurring basis, and which issues need escalation before a launch or vendor change goes live.

UK Online Safety Act Compliance for Marketplace and Platform Operators
Treat the UK Online Safety Act as operating work now, not a policy debate. The most practical way to reduce uncertainty is to run an auditable implementation plan: make an initial scope call, stand up baseline controls, assign owners, and keep records you can defend if Ofcom asks questions.

How to Handle Auto-Reminders and Dunning for a Contractor Marketplace
If you are building an automated reminder flow for a contractor marketplace, make one decision first: treat collections as receivables operations, not as a messaging feature. Dunning belongs inside your accounts receivable process, so reminder logic has to follow the same financial truth your team uses to decide whether an invoice is unpaid or resolved.