
Quick Answer
Classify each failed payout first, then choose retry, reroute, or stop based on that class. A payout retry strategy should separate soft decline, hard decline, issuer timeout, insufficient funds (NSF), and do not honor, then apply rail-specific timing and stop rules. Keep every replay under the same idempotency key, and only queue the next attempt after webhook evidence and ledger journal state match. This reduces duplicate-side-effect risk while preserving recoverable disbursements.
Classify payout failures before retrying#
This guide is about handling failed payment attempts with clearer retry decisions. A declined payment is not a single problem type, and treating every failure the same creates avoidable risk.
The core rule is simple: do not treat every failure the same. The decision is whether to retry or stop, and that choice should start with failure type. Failure types are not interchangeable, and retry guidance consistently flags the same challenge: some failures are temporary, and some are effectively final. Simple retries are not enough.
That is why this guide keeps failure class at the center. A soft decline usually points to a temporary issue, such as insufficient funds or a network timeout. A hard decline points to a more permanent issue, such as a closed account or another condition that should not be blindly replayed. If your team cannot say which class triggered the next action, you are not making a controlled retry decision. You are just resubmitting and hoping.
Execution discipline matters just as much as classification. Once you choose the next action, make each attempt controlled and explainable later. Keep a clear record of what failed, what changed, and why another attempt was allowed.
The reason to be this strict is practical, not theoretical. The cost of a declined transaction extends beyond immediate revenue loss, and weak retry handling can quickly create extra operational drag. Throughout this guide, you will build concrete artifacts your team can use: an eligibility table by failure class, an action policy, a retry decision matrix, ops checkpoints, and a copy-and-paste launch checklist. The goal is not to retry more. It is to make each next action defensible, observable, and safe.
If you want a deeper dive, read Two-Sided Marketplace Dynamics: How Platform Supply and Demand Affect Payout Strategy. For a quick next step on payout retry strategy, try the free invoice generator.
Set the payout retry scope and success target#
Set scope before logic: decide what the policy controls, what success looks like, and what should never stay automated.
-
Define the control unit first. Decide whether decisions are made per single payout or per payout batch, then set where policy attaches: per payee, per corridor, or per disbursement rail. A practical default is single-payout eligibility, with the batch used for release and monitoring. For any failed item, you should be able to identify one retry state, one owner, and one rail-specific rule set.
-
Set success targets before timing rules. Choose the outcomes you will evaluate before tuning schedules: recovery on retryable failures, duplicate risk, manual ticket volume, and reconciliation export quality. This keeps the team from optimizing for "more retries sent" instead of better payout handling. If those outcomes are not visible together in one report, you are tuning blind.
-
Use replay safety as the launch gate. If a retry cannot be replayed with an idempotency key, keep it out of production. Providers such as GoCardless explicitly document idempotency keys, and your operator check should be simple: can the next attempt be traced as the same business intent as the original attempt? If not, treat it as duplicate risk, not a normal retry.
-
Write a one-line escalation boundary. Keep automation for cases that match your approved retry rules and have intact replay evidence, and route all other cases to Payments Ops. If that line is too vague to paste into queue rules, tighten it before launch.
Related: Push Notification Strategy for Payment Platforms: How to Alert Contractors About Payouts.
Prepare prerequisites and evidence before you change retry rules#
Before you change retry rules, build a small evidence pack and confirm filing readiness so you do not treat unreleasable payouts as retryable recovery.
| Check | What to confirm | Key detail |
|---|---|---|
| Evidence pack | Failure-code distribution, prior retry outcomes, provider references from webhook events, and matching ledger journal traces | Use one date range and one payout population; if lineage is incomplete, pause automation changes |
| Compliance-status visibility | Whether a payout is technically failed or held for compliance review at the same decision level | If those states are mixed, retries add noise instead of recovery |
| Tax validation status | W-8, W-9, Form 1099, and VAT validation status in the operator flow | Keep it visible even if remediation happens in another system |
| US filing path | Businesses filing 10 or more information returns must file electronically, and electronic filing requires a Transmitter Control Code (TCC) | If an original return had to be filed electronically, corrected returns must also be electronic |
| IRIS timing | If you use IRIS, plan for filing season 2027 as the IRIS-only target | Submit the IR Application for TCC by November 1st and allow 45 business days for processing |
| Routing baseline | Bank transfer, card rail, and stablecoin rail where supported, plus current failure volume and retry usage | Record whether compliance and beneficiary status is visible at decision time |
Step 1. Gather the minimum evidence pack for recent failed payouts. Use one date range and one payout population, then pull four items together: failure-code distribution, prior retry outcomes, provider references from webhook events, and matching ledger journal traces. Your operator check is simple: which failures repeat, and can each failed attempt be traced from original attempt to provider event to journaled state without gaps? If that lineage is incomplete, pause automation changes. Separate hard declines from soft declines before you tune recovery logic.
Step 2. Confirm compliance-status visibility before marking anything retry-eligible. At the same decision level you set earlier (single payout, with payee/corridor/rail context), verify that operators can see whether a payout is technically failed or held for compliance review. Keep this as a visibility and triage check, not a policy rewrite. If those states are mixed, retries add noise instead of recovery.
Step 3. Validate tax and beneficiary readiness where reporting applies. Make W-8, W-9, Form 1099, and VAT validation status visible in the operator flow, even if remediation happens in another system. For US information returns, businesses filing 10 or more information returns must file electronically, and electronic filing requires a Transmitter Control Code (TCC). If an original return had to be filed electronically, corrected returns must also be electronic. If you use IRIS, plan for filing season 2027 as the IRIS-only target, submit the IR Application for TCC by November 1st, and allow 45 business days for processing.
Step 4. Baseline current routing before you compare post-change results. Record the rails you currently run (bank transfer, card rail, and stablecoin rail where supported), plus current failure volume, retry usage, and whether compliance/beneficiary status is visible at decision time. This gives you a defensible before/after baseline instead of relying on memory.
You might also find this useful: Retry Logic for Failed Payouts: Exponential Backoff and Error Classification Strategies.
Build the retry eligibility table by failure class#
Turn your evidence pack into one operator-facing table so each failure class resolves to a single next action, with clear stop conditions and an evidence gate before any new attempt is queued.
Map provider codes into the classes you already use#
Start by mapping provider-specific codes into your existing five classes: Soft decline, Hard decline, Issuer timeout, Insufficient funds (NSF), and Do not honor. Treat these as internal routing buckets, not universal definitions.
Because distributed payment flows can degrade partially instead of failing in a clean binary way, design each row to handle delayed or incomplete signals rather than assuming every failure is final on first read.
| Failure class | Default action to encode | Compliance stop condition | Evidence gate before requeue |
|---|---|---|---|
| Soft decline | Choose one: auto-retry, manual review, or immediate fail + beneficiary update request | Record any policy hold that blocks release | Define the minimum attempt-level evidence required in your system |
| Hard decline | Choose one: auto-retry, manual review, or immediate fail + beneficiary update request | Record any policy hold that blocks release | Define the minimum attempt-level evidence required in your system |
| Issuer timeout | Choose one: auto-retry, manual review, or immediate fail + beneficiary update request | Record any policy hold that blocks release | Define the minimum attempt-level evidence required in your system |
| Insufficient funds (NSF) | Choose one: auto-retry, manual review, or immediate fail + beneficiary update request | Record any policy hold that blocks release | Define the minimum attempt-level evidence required in your system |
Do not honor | Choose one: auto-retry, manual review, or immediate fail + beneficiary update request | Record any policy hold that blocks release | Define the minimum attempt-level evidence required in your system |
Write the action in plain language#
Use plain, fixed actions in the policy column: auto-retry allowed, manual review required, or immediate fail and beneficiary update request. Avoid soft wording that leaves room for interpretation at queue time.
If your program uses compliance holds (for example KYC/KYB/AML states), place that stop logic directly in the same row so operators and automation evaluate the same rule path.
Attach the evidence gate before automation runs#
Define evidence gates per row before automation is enabled. A practical pattern is to require attempt-level records that let you trace one failure path end to end (for example webhook signal, provider reference, and ledger state) before another attempt can be queued.
If that lineage is incomplete, route the case to manual review. This keeps retries policy-driven and evidence-driven instead of optimism-driven.
For a step-by-step walkthrough, see Build a Payout Error Rate Dashboard to Reduce Failed Disbursements.
Set timing cadence and stop rules by rail#
Set cadence by disbursement rail and failure reason, not one global schedule. Use retries where recovery is still likely, and stop when repeated attempts mostly add processing cost, duplicate risk, and operational noise.
Build a timing matrix by rail and failure type#
Reason-aware retry rules are the core control here: soft declines and transient technical failures can justify spaced retries, while hard declines and unresolved review states should move to stop or manual handling sooner. Keep the matrix market-aware, since retry performance can vary by region and timing.
| Disbursement rail + failure pattern | Retry cadence direction | Stop rule | Reconcile before next attempt | Customer comms trigger |
|---|---|---|---|---|
| Any rail + transient technical/timeout signal | Retry in a controlled window with spacing that fits that rail and market behavior | Stop when repeated attempts no longer improve recovery | Reconcile if status is delayed, inconsistent, or ambiguous | Notify only when payout timing changes materially |
| Any rail + soft decline pattern | Retry with wider spacing and tighter monitoring | Stop or escalate if the same pattern repeats without signal improvement | Reconcile before each additional attempt once outcomes become noisy | Notify when recipient action may be needed |
| Any rail + hard decline or unresolved review/compliance state | Do not continue automatic retries | Move to manual resolution and beneficiary update flow | Reconcile first, then close or reroute | Notify with a clear next step, not generic failure alerts |
This keeps timing from becoming a blunt instrument: retry where the failure context supports it, and stop where it does not. Tie every stop path to a clear recipient communication trigger so support volume does not spike from avoidable confusion.
Need the full breakdown? Read How to Hedge FX Risk on a Global Payout Platform.
Decide when to retry the same rail and when to reroute#
After timing is set, make routing evidence-first: retry the same rail for clearly transient failures, and reroute when repeated failures show the same pattern on the original path. That keeps your payout retry strategy focused on recovery odds instead of channel hopping.
Build a routing matrix before you switch rails#
Use one qualitative matrix per rail unless your own history supports hard thresholds. The goal is simple: decide whether one more same-rail attempt is more likely to recover than a switch.
| Rail | Retry same rail first when | Switch rail sooner when | Cost check | Speed check | Failure-risk check |
|---|---|---|---|---|---|
| Bank transfer | Failure appears temporary and the prior attempt is confirmed as not later successful | Repeated failures keep appearing on the same provider or corridor, and an alternate rail is already available | Compare incremental retry cost vs switch and handling cost using your own data | Use observed settlement and exception timelines | Pause if prior status is still ambiguous to avoid duplicate side effects |
| Card rail | Signal looks soft or timing-related, not permanent | The same issuer/provider pattern repeats instead of resolving | Compare retry-fee exposure vs switch cost | Use recent issuer behavior, not a fixed every 3, 6, or 9 days rhythm | Treat hard-decline behavior as stop-or-switch, not repeat |
| Stablecoin rail (if enabled) | Recipient route is already enabled and failure appears operational | Original rail keeps failing and the stablecoin route is already available for that recipient | Include network and operational handling cost from your own corridor data | Check actual release speed in production, not assumptions | Do not switch while required recipient-route data is unresolved |
Reroute on patterns, not impatience#
Reroute because the pattern says the current path is unlikely to recover, not because attempts are taking too long. Failure reasons are not all "try again later," and one global schedule is a poor fit across rails and markets. Keep the same rail for transient cases; move earlier when repeated failures concentrate on the same issuer, provider, or corridor attributes.
Some failure volume is unavoidable, so your objective is controlled recovery, not endless retries.
Check recipient readiness before any rail switch#
Switch rails only when the recipient can actually be paid on the alternate route with the data and checks your system already requires. If those requirements are incomplete, do not auto-switch.
Keep attempt lineage intact across the original attempt, retries, and reroute actions, and enforce idempotency controls at each step. That is what prevents retries from multiplying into duplicate payouts and downstream record conflicts.
This pairs well with our guide on How Platforms Verify Bank Details Before Payout Release.
Implement idempotent execution and ledger-first state control#
Treat every retry and reroute as the same logical payout, or you will eventually create duplicate financial side effects. Keep one immutable idempotency key from the original attempt through every replay, and only let state advance from journaled evidence.
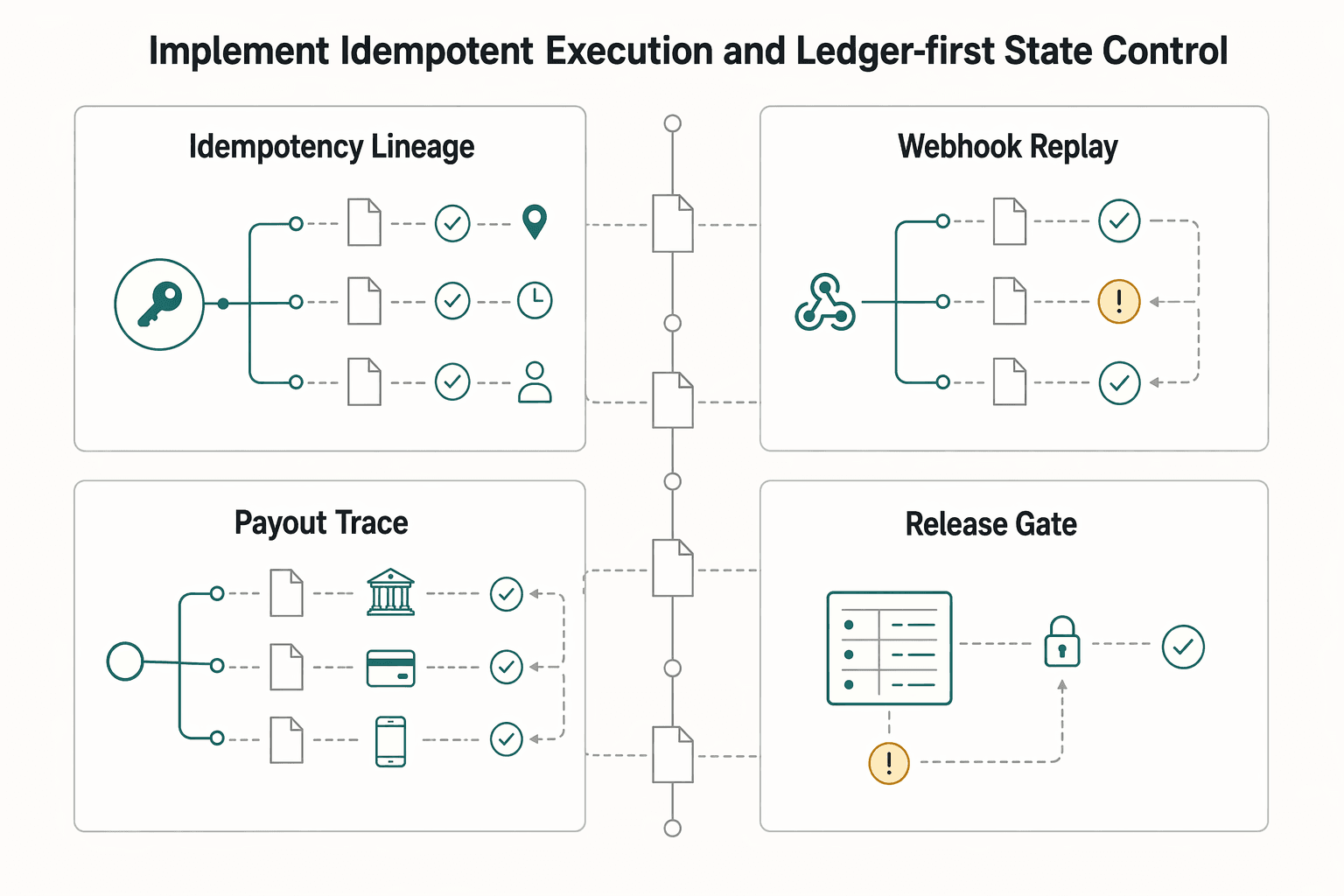
| Control | Rule | Key check |
|---|---|---|
| Idempotency lineage | Keep one immutable idempotency key from the original attempt through every replay | Verify the original idempotency key is still attached and the action is recorded in the same payout lineage, not as a new payout object |
| Webhook handling | Process webhooks as asynchronous, replayable inputs | Compare each incoming webhook event against current journaled state before allowing a transition |
| Ledger authority | Use provider callbacks as inputs, not as the source of truth | Journal first, then project status from verified journal entries |
| Release gate | Do not advance a retry or reroute until prior state is reconciled | Confirm the reconciliation export shows no unresolved delta for that payout |
Step 1: Keep one idempotency lineage Do not replace the payout identity after a timeout, queue retry, or manual action. Idempotency means multiple attempts of the same logical operation should produce the same external outcome as one run. Before sending any new attempt, verify the original idempotency key is still attached and the action is recorded in the same payout lineage, not as a new payout object.
Step 2: Process webhooks as asynchronous, replayable inputs Assume at-least-once delivery behavior: events can arrive late or more than once. Compare each incoming webhook event against current journaled state before allowing a transition. This is the control that protects you from the timeout trap where the first call succeeded but was not yet observed, and a retry succeeds again.
Step 3: Make the ledger journal authoritative Use provider callbacks as inputs, not as the source of truth. Payment state is more than success or failure, so derive payout and wallet status from verified journal entries. Journal first, then project status from that record to keep audit history, visible state, and retry decisions aligned.
Step 4: Add a release gate before every next attempt Do not advance a retry or reroute until prior state is reconciled and the reconciliation export shows no unresolved delta for that payout. If status is still ambiguous, pause automation until the record is clean.
Related reading: How to Migrate Contractors from Check to Digital Payout with Clear Go/No-Go Gates.
Prevent common payout retry failures and recover fast#
When retries misbehave, do not tune timing first. Contain risk first: pause automation, classify failures by evidence, then restart in controlled cohorts.
| Scenario | Immediate action | Restart condition |
|---|---|---|
| Generic backoff across mixed outcomes | Pause any queue running generic backoff across mixed outcomes and re-enable by failure-code cohort | Queued items in each cohort show the same failure class, a provider reference when available, and a matching ledger journal state |
| Duplicates from weak replay controls | Freeze the affected payout batch and reconcile ledger journal entries against provider references | Do not reissue until lineage is clear under one idempotency key |
| Blocked disbursements with policy uncertainty | Re-check KYC, KYB, and AML status and keep automation off | Restart only when policy state is explicit; if status is missing, stale, or under review, route to manual handling |
| Cross-border backlog restart | Verify W-8/W-9 and Form 1099 workflow status before release, especially when restarting a backlog | Hold restart decisions until the tax workflow can support that correction path |
Step 1 Pause any queue running generic backoff across mixed outcomes. Timeouts, hard declines, and policy blocks should not share one retry path. Re-enable by failure-code cohort, and use soft-versus-hard decline classification to avoid wasted attempts and extra fees.
Before unpausing, spot-check that queued items in each cohort show the same failure class, a provider reference when available, and a matching ledger journal state. If those do not align, keep the queue paused.
Step 2 If replay controls were weak and duplicates occurred, freeze the affected payout batch immediately. Reconcile ledger journal entries against provider references to identify where one logical payout may have been sent more than once, or where a timeout masked a completed release. Do not reissue until lineage is clear under one idempotency key.
Step 3 Re-check KYC, KYB, and AML status before restarting blocked disbursements. A retry can be technically possible but still policy-ineligible. Keep automation off until policy state is explicit; if status is missing, stale, or under review, route to manual handling.
Step 4 For cross-border recipients, verify W-8/W-9 and Form 1099 workflow status before release, especially when restarting a backlog. If you will submit 10 or more information returns, IRS rules require e-filing, and if the original return was required to be e-filed, corrected returns must also be e-filed. If your tax workflow cannot support that correction path, hold restart decisions until it can.
We covered the broader operating context in How Platforms Reduce Cross-Border Payout Costs.
Conclusion#
The right move is not to retry more. It is to retry when your failure-class policy, timing, and data indicate the next attempt is likely to recover payment without adding customer or network-rule risk.
Frequently Asked Questions
What is a payout retry strategy, and how is it different from card payment retry logic?
The reliable guidance on payment retries is to decide whether a failed payment should be retried now, retried later, or not retried at all. Classifying failures as soft declines or hard declines is a key part of that decision.
Should every failed payout be retried automatically?
No. Some failed payments should never be retried, while others may succeed if resubmitted. Auto-retry only when the failure appears transient and the previous attempt is still unresolved.
How long should we wait before retrying a failed payout?
Use the failure class, not one global timer. For clearly technical faults or issuer timeouts, retrying immediately or within minutes can make sense. For insufficient-funds-style failures, waiting at least 3 to 5 days before the first retry is a better starting point. If you cannot clearly classify the failure, pause automation and review before retrying.
How many payout retry attempts are too many?
There is no universal maximum supported by the evidence here. A practical approach is to set a defined stop rule and avoid random repeated retries, since uncontrolled retrying can hurt outcomes.
When should we switch rails instead of retrying the same rail?
Use a defined retry strategy instead of random retries, and stop attempts that are unlikely to recover.
Which metrics prove a retry policy is actually working?
Start with Payment Retry Success Rate, which measures the percentage of failed attempts recovered through retries. Then compare before-and-after trends to confirm the strategy is improving recovery, not just increasing retry volume.
How do we prevent duplicate payouts when retries and webhooks arrive out of order?
The provided evidence does not cover webhook-ordering controls or idempotency-key implementation details. At minimum, reduce duplicate risk by avoiding random retries and only retrying failures that are likely to succeed on a later attempt.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
Includes 2 external sources outside the trusted-domain allowlist.
- cisa.gov/news-events/bulletins/sb25-013trusted
- irs.gov/pub/irs-pdf/p1220.pdftrusted
- jud.ct.gov/LegalResources/Docs/LJDocs/Appellate/2021/32...trusted
- ncua.gov/files/publications/CE%20Guide%20For%20NCUA%2...trusted
- pmc.ncbi.nlm.nih.gov/articles/PMC12611161trusted
- stripe.com/resources/more/payment-retries-101-how-busin...trusted
- chargeblast.com/blog/payment-retry-logic-when-and-how-to-ret...external
- count.co/metric/payment-retry-success-rateexternal
Educational content only. Not legal, tax, or financial advice.
Related Posts

How Supply and Demand Dynamics Should Set Your Marketplace Payout Strategy
In a two-sided marketplace, payout strategy is not back-office plumbing. It can shape whether sellers stay active, whether transactions complete reliably, and whether buyers can find supply that is ready to transact.

Push Notification Strategy for Payment Platform Payouts
**Payout alerts fail when your message language gets ahead of a verified payout state.** If you want notifications your contractors can trust, optimize for what you can prove in your payout lifecycle. Do not optimize only for send speed or open rate.

Retry Logic for Failed Payouts with Exponential Backoff and Error Classification
For failed payouts, the sequence is simple: classify the failure, decide whether it is safe to retry, then control the pace with backoff. That is the practical core of **retry logic failed payouts exponential backoff error classification**.