
Quick Answer
Start by classifying each failed payout, then retry only recoverable cases with exponential backoff and jitter under a fixed retry budget. For terminal classes, stop automated attempts and hand off with a reason code, owner, and full attempt history. Keep idempotency keys consistent across retries, queue hops, and webhook handling so replays do not create duplicate outcomes. The practical target is traceability: one record that shows what failed, what decision was made, and who owns the next action.
Set Retry Rules by Failure Type#
For failed payouts, the sequence is simple: classify the failure, decide whether it is safe to retry, then control the pace with backoff. That is the practical core of retry logic failed payouts exponential backoff error classification.
These are not ordinary API errors you can hide behind a retry loop. A bad retry decision can create downstream operational work. The real question is always the same: what failed, should you try again, and how long should you wait?
A useful mental model is that failures have two dimensions: where they happen and when. A timeout before you get a provider response is not the same as a hard validation error. A failure during a traffic spike should not be handled the same way as one that keeps showing up hours later. If you do not classify first, retry behavior becomes guesswork.
Both extremes are risky. Missing retry logic can turn transient API errors into permanent failures. Going the other way and hammering the same failing operation on a short interval is not resilience either. Under load, the condition causing the failure may not have cleared by the time the next retry arrives. In payout delivery, that is your signal to slow down, not speed up.
First, classify the error. Then decide whether it is retryable, non-retryable, or unclear. If it is retryable, apply exponential backoff so retries spread out instead of bunching together. If recovery still looks unlikely, stop cleanly and escalate with enough evidence for an operator to act.
Two habits make this work in real systems. First, keep a traceable event record for every retry attempt, including the payout identifier, the failure signal, the attempt count, and the provider response or lack of response. Second, never let the queue become an opaque holding area where items keep cycling without a visible owner or stop condition.
A concrete example is HTTP 429, the standard "Too Many Requests" or RateLimitError response. That often indicates a pacing problem, not a data-quality problem, so your first move should be to back off and reduce pressure. By contrast, if the signal says the request itself is malformed, retrying usually just delays the real fix.
The goal here is implementation clarity. You want recovery where recovery is plausible, restraint where retries would amplify failure, and escalation paths that leave a readable trail instead of mystery failures.
Build the payout retry mental model before writing code#
Start with one rule: classify each failure as recoverable or terminal before you write retry code. That keeps your retry logic tied to a clear decision path instead of guesswork.
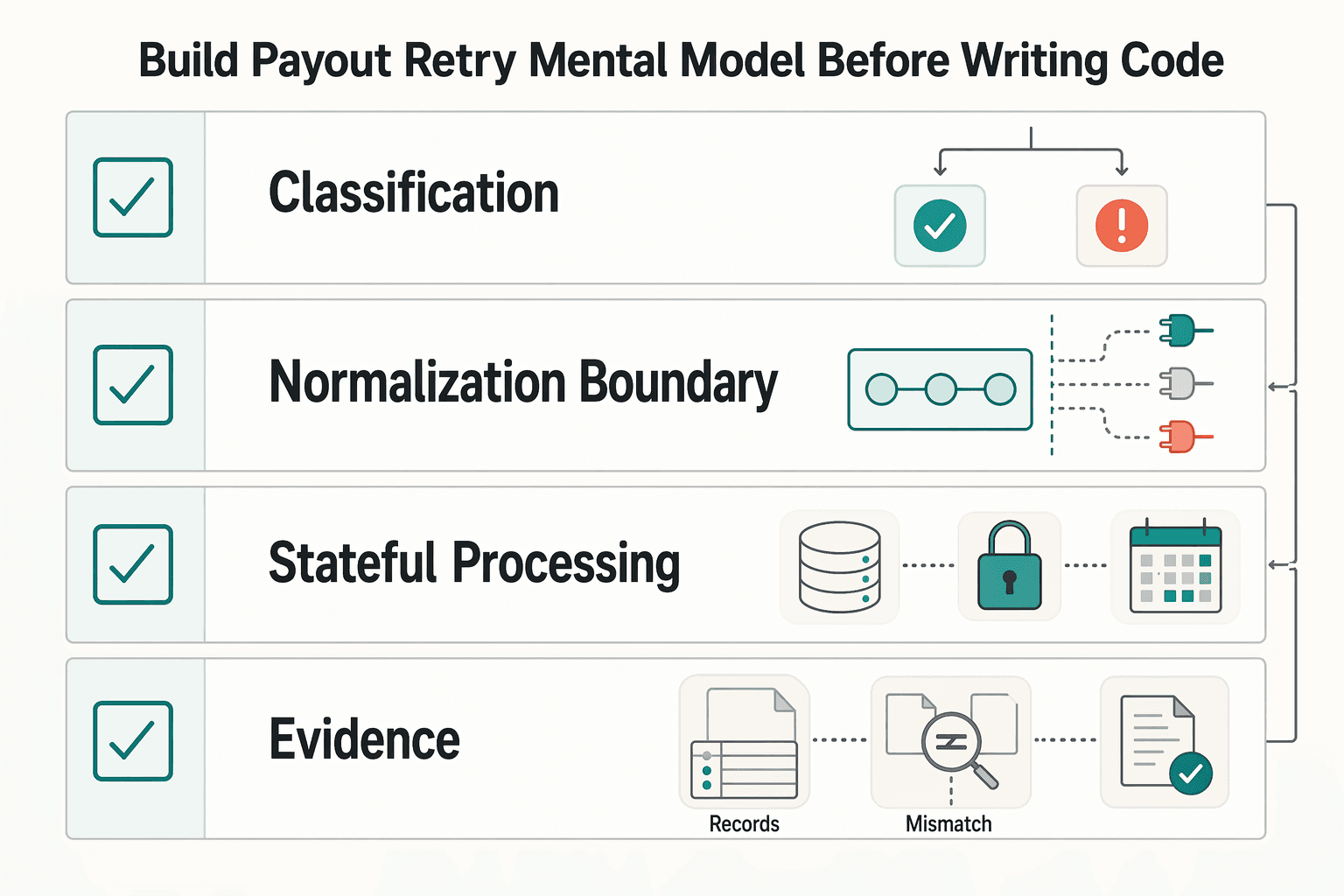
| Area | Action | Effect |
|---|---|---|
| Classification | Classify each failure as recoverable or terminal before you write retry code | A clear decision path instead of guesswork |
| Normalization boundary | Translate provider-specific behavior into one internal payout model first | Retries close gaps without creating duplicate outcomes |
| Stateful processing | Reuse the same payout identity, keep a decision history, and respect an explicit retry budget | Handles retries after partial progress |
| Ownership and evidence | Give each terminal path and reconciliation outcome a named owner and an evidence trail | Failures do not end in ambiguous states |
Build that logic behind a normalization boundary so provider-specific behavior is translated into one internal payout model first. Then apply idempotent, persistent retry against that model, so retries close gaps without creating duplicate outcomes.
Treat payout processing as stateful work, not a stateless call loop. Retries can happen after partial progress, so every attempt should reuse the same payout identity, keep a decision history, and respect an explicit retry budget you define up front.
Set ownership before you tune backoff. Each terminal path and reconciliation outcome should have a named owner and an evidence trail, so failures do not end in ambiguous states.
For a step-by-step walkthrough, see API Rate Limiting Error Handling for Payout and Webhook Integrations.
Classify payout failures with explicit stop and retry rules#
Use a decision table so every failure signal maps to one class, one retry path, one owner, and one evidence set. If your team still has to ask "is this retryable?" or "who owns this?" during incident handling, the classification is not operational yet.
Make three control points explicit: where the task goes next, what context moves with it, and how the payout exits the flow. Without that, teams duplicate work, contradict each other, and lose context at handoffs.
Use an operable decision table#
| Failure signal | Class | Retry path | Escalation owner | Evidence required |
|---|---|---|---|---|
| Signal is clearly recoverable in your internal policy | Retryable, non-final | Retry within a constrained retry budget | Engineering | Normalized payout ID, prior attempt history, provider response/event trail |
| Signal is clearly terminal in your internal policy | Non-retryable, final | Stop automated retries and route to manual resolution | Operations/compliance/support (as defined internally) | Final reason code, decision history, required next action |
| Signal is ambiguous or incomplete | Non-final, pending triage | Apply limited retries, then escalate with full history | Engineering first, then designated ops owner | Full event timeline and ownership handoff record |
Default to conservative handling when semantics are unclear#
When provider semantics are unclear, treat the state as non-final, use a limited retry budget, and escalate with complete evidence. That may slow some resolutions, but it reduces contradictory handling and context loss during handoffs.
Make terminal routing actionable#
When automated recovery stops, use explicit reason codes and named operator actions instead of a generic failed label. The handoff should tell the next owner what to do next without re-reading raw logs.
For a broader look at failed payment handling across methods and regions, see How to Handle Failed Payments Across Multiple Payment Methods and Regions.
Set Exponential Backoff policy by payout risk not by engineering habit#
Set retry pacing as explicit contract behavior, not as an SDK default. Define how Exponential Backoff and Jitter are applied, when retries must stop, and when work is handed to a person or a Dead Letter Queue (DLQ).
For rate-limit signals, slower and less synchronized retries are the safer default. A 429: 'Too Many Requests' or RateLimitError indicates calls are exceeding API rate limits, so widening retry spacing and adding jitter helps avoid making the condition worse.
| Failure signal | Retry stance | Stop rule |
|---|---|---|
429 / RateLimitError | Increase spacing between attempts and add jitter | Stop when retry budget is exhausted, then escalate with full event history |
Classed Non-Retryable Error | Do not auto-retry | Route directly to remediation |
| Ambiguous non-final state | Use only remaining retry budget with controlled spacing | Escalate once budget is consumed |
Keep your Retry Budget visible by error class, provider, and flow type. That makes it clear whether automated recovery is resolving retryable cases or just masking upstream issues.
Choose queue-based retries when durability and observability matter#
Use a Queue-Based Exponential Backoff Pattern when failed payouts must survive crashes, restarts, and worker churn. Avoid relying on setTimeout for this path.
| Pattern | What changes in production |
|---|---|
setTimeout / in-process scheduler | Traditional in-process retries have production limits, and retries can be lost if the process crashes or restarts. |
Message Queue Retry Pattern (Delayed Requeue Pattern) | Retry state lives in the queue, delay can be applied with native features (for example Amazon SQS DelaySeconds), and non-retryable or max-attempt cases can be routed to DLQ. |
For distributed payout services, keep retries in the queue layer instead of per-worker timer logic. Where supported, Amazon SNS-style fan-out can distribute the same payout event to separate consumers without each service inventing its own retry loop.
Keep implementation order strict so behavior stays consistent across workers:
- Enqueue the event.
- Classify the failure.
- Compute the delay.
- Requeue, or route to
DLQwhen non-retryable or out of budget. - Commit final status with
Ledger Journalcorrelation.
This design adds operational overhead, but for money movement it usually gives you better failure transparency and control than in-process retries.
Prevent duplicate payouts with idempotency and state guards#
Preventing duplicates starts with idempotency: the same payout instruction should produce the same result when replayed, not a second side effect. In practice, make Idempotency Key required at creation and reuse that exact key across retries, queue hops, and Webhook handling.
| Control | Requirement | Result |
|---|---|---|
Idempotency Key | Make it required at creation and reuse the exact key across retries, queue hops, and Webhook handling | The same payout instruction should produce the same result when replayed |
| Idempotent operation | Running it multiple times should yield the same result as running it once | Retrying paid calls without idempotency can lead to double payment |
| Current state verification | Verify current state before mutating data | Avoid duplicate financial effects |
| Replayed event handling | Handle replayed events in a way that avoids rewriting already-completed outcomes | Keep already-completed outcomes from being rewritten |
| Write sequence testing | Test the enforced write sequence under timeout, crash, and duplicate-delivery scenarios | Retries should recover safely without creating duplicate financial effects |
An idempotent operation is one where running it multiple times yields the same result as running it once. That matters because retries that look harmless in testing can still create duplicate side effects in production, and retrying paid calls without idempotency can lead to double payment.
Keep the implementation checks strict and consistent in your own state model. A retry path should verify current state before mutating data, and replayed events should be handled in a way that avoids rewriting already-completed outcomes.
If you enforce a write sequence (for example: external result, internal status, then Ledger Journal linkage), test it under timeout, crash, and duplicate-delivery scenarios. The exact order is system-specific, but the bar is the same: retries should recover safely without creating duplicate financial effects.
Handle compliance gates and program variance without breaking retry logic#
Treat compliance-gated failures as a separate path from retryable failures. Retries are for transient, short-lived issues, so when a failure indicates policy or compliance review, move it into an explicit compliance-resolution state instead of routing it through Exponential Backoff.
| Scenario | Meaning | Handling |
|---|---|---|
| Transient, short-lived issue | Retries are for transient, short-lived issues | retry_later means automated recovery may work |
| Policy or compliance review | Something must change before resubmission | Move it into an explicit compliance-resolution state instead of routing it through Exponential Backoff |
| Market and program context | Part of classification at the time of failure | Store the payout context you need for routing decisions up front |
| Compliance-held payout | The hold has not been cleared | Verify the case record shows the failure reason and ownership, and confirm automated retry is off until the hold is cleared |
This split keeps operations honest: retry_later means automated recovery may work, while a compliance state means something must change before resubmission. If those paths are merged, teams can misread blocked payouts as technical delays, and repeated retries can escalate into a retry storm that will not clear without intervention.
Make market and program context part of classification at the time of failure, not an afterthought. Store the payout context you need for routing decisions up front, then classify each failure against that context so retry logic and compliance handling stay distinct.
A practical check is simple: for any compliance-held payout, verify that the case record shows the failure reason and ownership for resolution, and confirm automated retry is off until the hold is cleared.
Related: Smart Dunning Strategies: How to Sequence Retry Logic for Maximum Recovery.
Use an implementation checklist that teams can ship against#
Treat this as a release checklist, not a loose set of ideas: define classification first, then execution behavior. If your team cannot consistently classify failures, backoff tuning is premature.
Start with an explicit order of operations:
- Finalize the error taxonomy.
- Map each class to a decision table action.
- Implement retry behavior from that table.
- Define how non-retryable failures exit the flow.
- Add observability that shows each decision path.
- Set rollout gates only after those pieces are in place.
Keep the taxonomy practical. AccessDenied and ThrottlingException should not land in the same path, because they imply different fixes. That matches a basic production constraint: requests that miss identity, permission, configuration, quota, or validation expectations are rejected for different reasons.
For go-live, require a compact evidence pack that lets operators trace real failed attempts end to end in your own stack. At minimum, each sample should clearly show the identifier, classification result, reason, chosen action, and final owner so incidents are diagnosable without guesswork.
Roll out by blast radius. Start with a narrow slice, review behavior, then expand only after the same checklist still passes.
If some failures trace back to invalid European bank details, see What Is an IBAN Number? How Platforms Use IBANs to Send Error-Free European Payouts.
Conclusion#
From the limited evidence reflected here, the safest conclusion is narrow: retry behavior needs clear policy decisions, and exponential backoff with jitter is explicitly requested in at least one open feature issue.
That point matters more than many retry discussions admit. Headline-level or metadata-level guidance can be useful context, but it does not replace your own rules for which failures are retryable, when automation must stop, and what an operator needs to see before taking action.
So the practical recommendation is simple: do not make your retry loop more aggressive until your evidence trail is stronger. For payout retry logic, the real checkpoint is whether one person can trace a single failed request from first attempt to latest state without opening multiple unrelated tools or guessing which attempt was last. If that trace is broken, faster retries will mostly create noise.
A good final review before rollout should answer a few plain questions:
- Can you show a stable request ID, attempt history, error/response details, timestamps, and current state in one place?
- Do ambiguous errors stay non-final for a bounded retry window instead of being mislabeled as permanent failures too early?
- When retries stop, does the record move to a clear review state with a reason code and an owner?
The most common failure mode is not "we forgot exponential backoff." It is "we cannot explain why this request is still retrying" or "we cannot prove what changed state last." Those are observability and state-control problems first, and they deserve attention before policy tuning.
If your current design cannot explain each failed request from first submission to current state, fix that path first. Then tighten your stop rules, then validate your classification logic, and only then adjust backoff behavior. That order is slower at the start, but it gives you something more valuable than a busy retry engine: a process you can inspect, defend, and operate under pressure.
Related reading: How Platform Operators Recover Failed Payouts Without Duplicate Risk.
Frequently Asked Questions
When should failed payouts be retried versus stopped immediately?
Retry when signals match transient overload or temporary API unavailability, including a 429 resource-exhaustion error. The approved sources do not define exact payout-specific stop rules, so treat unclear non-transient failures as manual-review cases and attach verifiable evidence to the decision.
How do we classify payout failures when provider error messages are vague?
Do not treat a vague label as automatically terminal. A public report shows an “Unknown Error” that failed to trigger retry and was tied to throttling identification issues, so ambiguous errors should be reviewed with verifiable error evidence before final classification.
What is a practical Exponential Backoff and Jitter policy for payout systems?
Keep the policy explicit: waits should increase after each retry when overload or temporary unavailability is suspected. Define specific retry counts, delay caps, and jitter formulas internally and document them clearly.
Why is queue-based retry usually better than `setTimeout` for payout reliability?
Treat the choice between queue-based retry and setTimeout as an implementation decision to validate in your own environment.
What should happen after max retries are exhausted in a `Dead Letter Queue (DLQ)` path?
Avoid prescribing a specific terminal workflow without evidence from your own system. Keep final DLQ decisions evidence-based.
How do `Idempotency Key` design and `Webhook` replay handling work together?
Any coupling rules for Idempotency Key design and Webhook replay handling should come from your internal system requirements.
How should `KYC` and `AML` holds be modeled in payout retry logic?
KYC/AML hold handling is out of scope here, so do not define compliance-hold retry rules from this section alone.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
Includes 6 external sources outside the trusted-domain allowlist.
- sec.gov/files/ctf-written-input-daniel-bruno-corvelo...trusted
- www2.eecs.berkeley.edu/Pubs/TechRpts/1997/CSD-97-945.pdftrusted
- cloud.google.com/blog/products/ai-machine-learning/learn-how-...external
- dev.to/andreparis/queue-based-exponential-backoff-a...external
- dev.to/aws/5-common-aws-errors-new-developers-hit-a...external
- developers.openai.com/cookbook/examples/how_to_handle_rate_limitsexternal
- docs.aws.amazon.com/bedrock/latest/userguide/troubleshooting-api...external
- docs.aws.amazon.com/neptune/latest/userguide/best-practices-open...external
Educational content only. Not legal, tax, or financial advice.
Related Posts

How to Handle Failed Payments Across Multiple Payment Methods and Regions
Treat **failed payment retry logic** as a revenue recovery decision, not a billing toggle. The job is to recover valid revenue while controlling processing cost, customer friction, and compliance or security risk.

Smart Dunning Strategies to Sequence Retry Logic for Maximum Recovery
If you treat retry logic as a billing setting, you may get some upside and still create hidden operational gaps. A better starting point is shared ownership across teams. Product decides customer treatment. Engineering controls retry execution and event integrity. Finance ops owns reconciliation and audit-trail review.

What Is an IBAN Number? How Platforms Use IBANs to Send Error-Free European Payouts
If you are evaluating **iban number platforms european payouts**, skip the glossary. The real decision is which payout setup will keep money moving, exceptions visible, and reconciliation manageable as volume grows. This guide is for platform founders, finance ops leads, and engineering owners who need to ship reliable European payouts, not for readers looking for a basic banking explainer.