
Quick Answer
Start by enforcing idempotency on side-effecting POST calls, then route 429 responses through Retry-After-aware pacing and route 500-class faults through a tighter bounded retry branch. For payout and onboarding operations, treat the first API response as provisional and confirm completion through webhooks plus reconciliation records. This is the core of api rate limiting error handling that avoids duplicate writes, queue amplification, and hard-to-debug status drift.
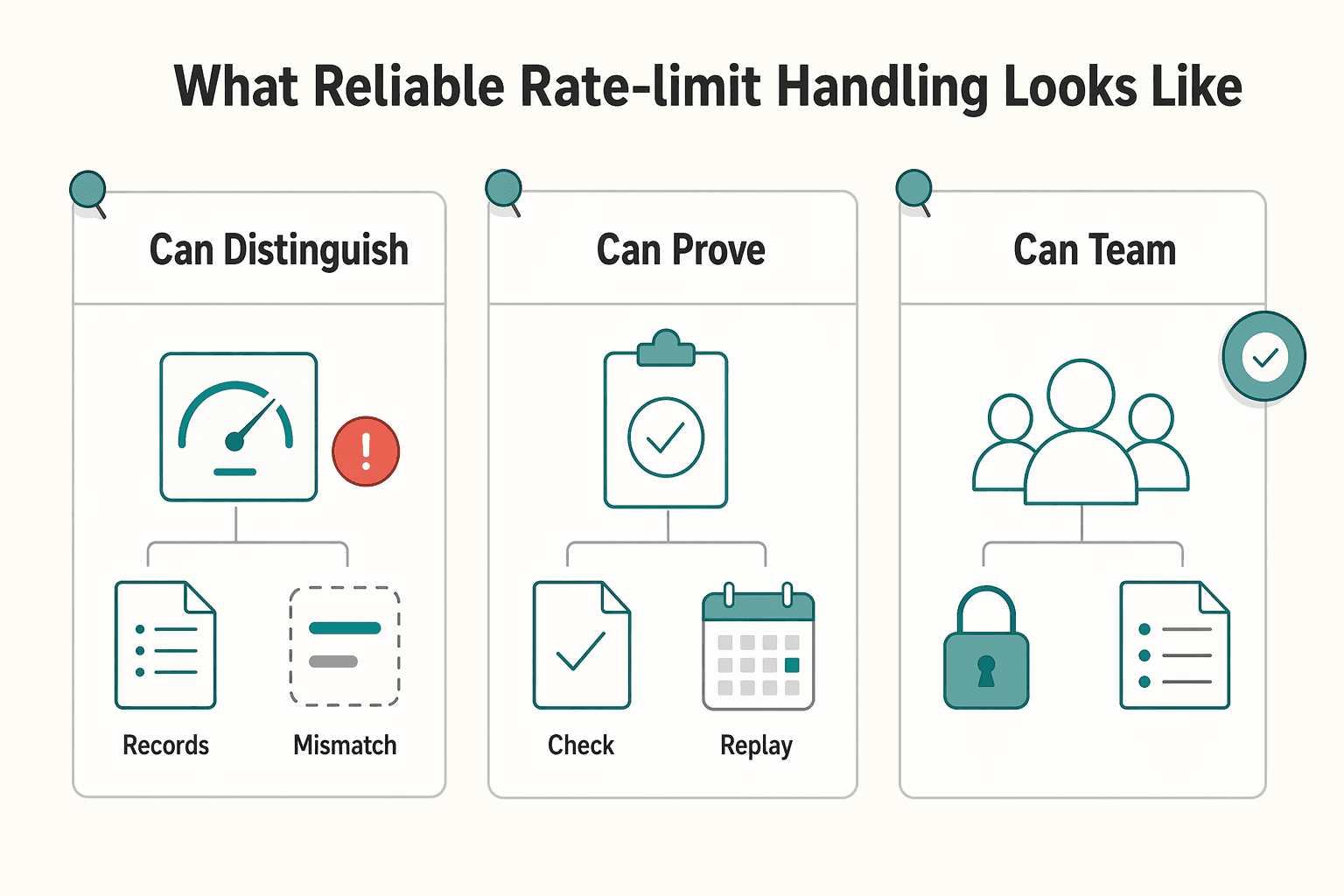
What Reliable Rate-Limit Handling Looks Like#
If your team is integrating a Payouts API, onboarding flow, or reporting endpoint, a lone setTimeout is rarely a real answer once HTTP 429 Too Many Requests starts showing up. It may quiet the immediate error. It does not tell you whether you hit a provider limit, whether you should wait for Retry-After, or whether the final outcome will arrive later through webhooks instead of the original response.
The gap is operational. In HTTP, 429 means the client sent too many requests in a given time window, and the response can include Retry-After, which tells you how long to wait before trying again. That matters because fixed-delay retries treat every failure as the same kind of problem. In production, they are not. A rate-limit response needs one control path, a transient HTTP 500 Internal Server Error needs another, and asynchronous completion needs its own check against webhook or downstream status before you decide an operation is done.
This is a best-of decision guide for teams making architecture choices, not just patching a noisy endpoint. The goal is to help you choose patterns that hold up over time and avoid the ones that only hide the problem for a sprint or two. If you cannot explain what happens after the first failed request, after the retry, and after the eventual status update, you probably do not have production-ready api rate limiting error handling yet.
A useful way to read the list is to judge each pattern against three operator questions. The sections that follow rank patterns by that standard, starting with the ones that prevent the most expensive mistakes.
- Can it distinguish throttling from other failures?
429 has a specific meaning: too many requests in a time window. A credible handler checks for that status explicitly and honors Retry-After when it is present. A red flag is any retry policy that lumps 429, timeouts, and 500 responses into one generic delay loop.
- Can it prove the final state of a money movement or onboarding action?
For payout and reporting flows, the request log is not enough. Many providers use webhook events for asynchronous updates, so your checkpoint is whether the operation can be verified against the later event stream and, where relevant, a downstream accounting or reconciliation record rather than the first API response alone.
- Can your team operate it under pressure?
Exponential backoff with jitter is a recommended pattern for 429 handling, but even a good retry policy can fail if you cannot see retry counts, stop conditions, or duplicate-write risk. The practical test is simple: during an incident, can someone tell which calls are waiting, which were abandoned, and which still need reconciliation?
Who This Best-Of List Helps and the Selection Criteria#
This list is for teams where a bad retry can do more than waste calls. If your integration touches payouts, onboarding, or reporting tied to downstream accounting, you need handling that survives partial failure and still leaves a clean audit trail. The test is straightforward: can someone trace one request from the first API call to the final status update without guessing?
- Payment and payout teams
Best fit: teams shipping money movement or account onboarding where 429 and 500 have very different consequences. A HTTP 429 Too Many Requests response means you sent too many requests in a time window, and it may include Retry-After; HTTP 500 Internal Server Error is a generic server-side failure. The key differentiator is failure isolation. If your handler treats both as the same problem, you will mask root cause and create ugly reconciliation work later.
- Not aimed at low-stakes, low-volume integrations
If an occasional throttle can be reviewed by a human and there is no downstream posting, you may not need every pattern in this ranking on day one. The deciding factor is blast radius. Once a retry can create duplicate payout attempts, duplicate internal records, or delayed customer status, the bar changes quickly.
- Every pattern must prove replay safety
We score patterns on idempotency first, because safe retrying means not performing the same operation twice. A real checkpoint is whether you can show the idempotency key, the original request, and the resulting single business outcome. Red flag: any design that adds more retries before defining duplicate-write protection.
- Operational visibility and compliance count as part of error handling
We also rank patterns on webhooks and auditability across KYC, AML, and customer due diligence controls. Receiving webhook events helps with asynchronous outcomes, but only if you can match the event back to the original request and the final status or accounting state. If a pattern cannot be explained from request to resulting status update and reconciliation record, do not call it production-ready.
Related: Payment API Rate Limiting: How to Design Throttling Policies That Do Not Break Integrations.
Best API Rate Limiting and Error Handling Patterns at a Glance#
If you need one quick judgment, start here: put strict idempotency in place, separate 429 from 500, and treat payout completion as asynchronous. Everything else helps, but those three controls do most of the work when retries meet money movement.
The table below uses relative implementation cost, not benchmarked effort. That matters because the pattern that costs more to build is not always the one that costs more to operate.
| Pattern | Best for | Key pros | Key cons | Primary failure mode addressed | Implementation cost |
|---|---|---|---|---|---|
Client-side throttling | Bursty reads, batch submission pacing, and status polling | Smooths bursts before they hit provider limits, can be tuned per endpoint | Can delay legitimate traffic, easy to get wrong if one global limit covers everything | Self-inflicted 429 spikes from your own traffic bursts | Medium |
| Server-side rate limiting | Multi-tenant APIs, webhook receivers, and internal services protecting critical routes | Fairness by identity scope such as API key or user ID, isolates noisy tenants | Coarse policies can starve critical payout or webhook paths | One tenant or route consuming shared capacity and degrading others | Medium |
Retry-After handling | Direct responses with HTTP 429 Too Many Requests on payout, reporting, or status endpoints | Uses the provider's own wait signal instead of guessing, reduces unnecessary retries | Header may be absent, so you still need fallback behavior | Hammering an endpoint during the throttle window | Low to medium |
Capped exponential backoff | Retryable transient failures and overload conditions after 429 or selected 500 responses | Spreads retries over time, caps worst-case delay, reduces retry storms | Slower completion, needs explicit cap and retry budget | Tight retry loops that amplify outages | Medium |
Strict idempotency | Payout writes and any write with financial side effects | Safe retrying without duplicating the operation, cleaner reconciliation | Requires key scope, storage, and request matching discipline | Duplicate payouts or duplicate write side effects during retries | High |
| Webhook-first completion handling | Asynchronous payout status changes and any endpoint where the final result arrives later | Tracks eventual outcome through webhooks, reduces fragile polling assumptions | Requires deduplication, ordering checks, and replay handling | Treating an initial API response as the final business outcome | Medium to high |
Compliance-aware degrade mode for Payouts API | High-risk payout writes when verification checks are stale, unavailable, or delayed | Can preserve some low-risk visibility while holding higher-risk writes, depending on program rules | More product logic, more operator messaging, more evidence retention | Processing or paying out funds before required verification gates are satisfied | High |
| Anti-pattern: global retries without idempotency | Nothing production-critical | Fast to code | Creates duplicate side effects and ugly reconciliation work | Prevents none, can create duplicate writes | Low build, high incident cost |
Anti-pattern: treating all 500 like 429 | Nothing production-critical | Simpler branch logic | Mixes server faults with quota throttling, hides root cause | Prevents none, can grow queues while the real fault persists | Low build, high ops risk |
Anti-pattern: relying on setTimeout as the only control | Manual scripts and prototypes at most | Trivial to add | No per-tenant fairness, no Retry-After awareness, no retry cap, no audit trail | Prevents none, often causes bursty retry behavior | Low build, high fragility |
The fit usually becomes obvious once you map the flow. Read-heavy routes benefit from client-side throttling and tenant-aware server limits. Payout writes and other side-effecting calls need strict idempotency before you add more retries, because a delayed response and a repeated write are not the same problem. For asynchronous webhooks, the control is not "retry more." It is "wait for the outcome channel you trust and dedupe what arrives."
Use one verification checkpoint across all of this. For any retried payout request, you should be able to show the idempotency key, the original request, the returned 429 or 500, any applied Retry-After delay, any later webhook event where applicable, and the single final business outcome. If you cannot reconstruct that chain, your controls may look fine in tests but fail during reconciliation.
The most common failure mode is policy flattening. Teams collapse every error into one retry path, then wonder why a quota event becomes a retry storm or why a transient 500 gets treated like a scheduling hint. If you are sequencing the work, implement idempotency first, honor Retry-After on 429, cap backoff for retryable failures, and only then tune endpoint or tenant limits around high-volume routes and webhook ingestion.
For scaling patterns, see Rate Limiting and Throttling for High-Volume Payout APIs.
Best Practice 1 Use Idempotency Before You Add More Retries#
On writes, this is the first control that matters. Put idempotency in front of every Payouts API POST before you add more retry logic, because retries handle transport noise while idempotency prevents duplicate side effects such as a second payout or a second write.
This is the right starting point for payout creation and payout lifecycle updates where a timeout or HTTP 500 Internal Server Error can leave you unsure whether the provider processed the write. Stripe's documented behavior is a useful benchmark here: all POST requests accept idempotency keys, and subsequent requests with the same key return the same prior result, including 500 errors. That lets your client retry the same operation without accidentally minting a second object, but only if the request is truly the same operation.
The decision rule is simple. If payout creation times out or returns a retryable 500, resend the same request with the same idempotency key. If anything in the business intent or request parameters changes, use a new key and treat it as a new write, because reusing a key with different parameters is explicitly unsafe and can be rejected.
Three operator details matter more than most teams expect:
- Scope the key to one business action. One key should represent one payout creation, not a whole batch job, not a user session, and not a generic retry token shared across services.
- Persist the original request next to the key. At minimum, keep the key, request parameters, first response, timestamps, and the final payout or internal outcome so you can prove one write led to one business result.
- Know the provider window. Stripe documents keys up to 255 characters and notes keys may be pruned after 24 hours. Adyen documents keys up to 64 characters and a minimum validity period of 7 days. Do not assume one provider's retention window or key format applies to another.
The payoff shows up quickly under load. Stripe's Create Payout API is limited to 15 requests per second and 30 concurrent requests per business, so a burst of retries after a transient fault can quickly collide with rate or concurrency pressure. Idempotency lets you retry one intended payout safely instead of turning one uncertain write into several competing writes.
One red flag is easy to miss: do not treat 429 as if it had the same replay semantics as a completed idempotent POST. It does not. Stripe notes that a request rate limited with 429 can produce a different result with the same idempotency key, so throttling still needs its own handling path, which the next section covers.
Before release, use one checkpoint for any retried payout. Record which idempotency key was used, what exact POST body it protected, whether the first attempt timed out or returned 500, and which single payout or internal record survived reconciliation in the end. If you cannot show that chain, you are not ready to add more retries.
For authentication tradeoffs that affect retries and webhook security, see Choosing OAuth 2.0, JWT, or API Keys for Production APIs.
Best Practice 2 Split 429 and 500 Handling Into Different Control Paths#
Once idempotency is protecting your writes, stop treating every failure as the same retry problem. A 429 is the provider telling you to slow down in a specific time window; an HTTP 500 Internal Server Error means the server hit an unexpected condition. If you send both down one generic retry branch, you usually get the worst of both outcomes: more throttling on one side and silent queue growth on the other.
| Response | Meaning | Handling |
|---|---|---|
| 429 | Too many requests in a given time window | Honor Retry-After when present, then use bounded exponential backoff |
| 500 | Unexpected server condition; execution may be uncertain | Retry only idempotent operations and keep caps explicit and bounded |
| 502 | Included in the AWS retry class cited here | Retry only when the operation is idempotent and still within budget |
| 503 | Included in the AWS retry class cited here | Retry only when the operation is idempotent and still within budget |
| 504 | Included in the AWS retry class cited here | Retry only when the operation is idempotent and still within budget |
Stripe's low-level error guidance is a useful anchor here: each error type needs a different approach and different idempotency semantics. That matters because a request rate limited with 429 can produce a different result with the same idempotency key, so you cannot assume the same replay behavior you rely on after a completed idempotent POST.
Treat 429 as a pacing signal#
HTTP 429 Too Many Requests means the client sent too many requests in a given amount of time. Your first move should not be an immediate retry, and it definitely should not be a fixed setTimeout pasted into every caller. If the response includes Retry-After, honor that value first, because that header tells the client how long to wait before making a new request.
After that wait, use bounded exponential backoff if the endpoint is still under pressure. The key difference in this branch is that you are cooperating with provider throttling, not trying to out-retry it. A fixed sleep can cause many delayed requests to wake up together and hit the same rate window again.
For incident handling, log three fields on every 429: the Retry-After value, the next scheduled attempt time, and the request class or endpoint being retried. If you cannot inspect those fields during an incident, you will struggle to tell the difference between true provider throttling and your own client burst behavior.
Treat 500 as uncertain execution#
A 500 is different. MDN defines it as an unexpected server condition that prevented the request from being fulfilled. That means the provider may have failed before doing the work, during the work, or after the work but before returning a clean response. This branch therefore needs stricter rules: retry only idempotent operations, and keep the caps explicit and bounded.
The rule is straightforward. If the operation is a read, or a write protected by idempotency, a small retry budget is reasonable. If the operation is not idempotent, do not automatically retry because documented guidance warns that retrying non-idempotent requests can create race conditions and conflicts.
For a concrete cap, AWS standard retry behavior is a good reference point. It uses 2 maximum retries, for 3 total attempts, with exponential backoff by a base factor of 2 and a maximum backoff time of 20 seconds. AWS also explicitly includes 500, 502, 503, and 504 in that retry class. You do not need to copy those exact numbers, but you do need explicit limits, because unbounded 5xx retries are how transient instability turns into a backlog that outlives the original outage.
What matters most here is evidence. For every retried write after a 500, keep the idempotency key, request fingerprint, first error response, retry count, and final object or downstream outcome. That is the only way to prove later that one business action still resulted in one financial effect.
Put the stop conditions in writing#
This pattern costs more than a single generic retry helper because it adds branching logic and more tests. It is still worth it because the stop conditions become explicit instead of accidental.
Use these decision rules in your client:
- If the response is
429, wait forRetry-Afterwhen present, then apply bounded backoff. - If the response is
500,502,503, or504, retry only when the operation is idempotent and still within budget. - If the request is non-idempotent or the retry budget is exhausted, stop and escalate rather than feeding the queue forever.
In practice, this is where rate-limit and failure handling stops being a retry habit and becomes an operational control. You are no longer asking, "Should we try again?" You are asking, "What exactly failed, what evidence do we have, and what is the cheapest safe next action?"
For a step-by-step walkthrough, see ACH API Integration to Programmatically Initiate and Track Transfers in Your Platform.
Best Practice 3 Throttle by Endpoint and Tenant Instead of One Global Limit#
Once you have separate 429 and 5xx branches, decide who gets to consume the retry budget. If onboarding, reporting, payout status checks, and batch jobs all share one global bucket, one noisy route or tenant can starve the paths you actually need to keep alive. For platforms with mixed traffic, endpoint and tenant-scoped throttling is often a safer step up from a single global cap.
| Scope | Use | Risk addressed |
|---|---|---|
| Global limit | Outer guardrail for total platform pressure | Acts as a backstop for overall traffic pressure |
| Endpoint or method limits | High-volume routes such as reporting, reconciliation pulls, or batch submission endpoints | One route should not starve the paths you need to keep alive |
| Per-tenant limits | Traffic by tenant identity or API key | One heavy caller should not consume the whole shared budget |
A global limit is still useful as a backstop. The problem is that real APIs already distinguish between global and endpoint failure modes. Stripe, for example, documents both global-rate and endpoint-rate, and notes a live mode global baseline of 100 operations plus a default per endpoint limit of 25 requests per second. That is the practical signal: one number rarely reflects how different routes behave under load.
Scope the limit to the thing that can cause damage#
The cleanest pattern is layered control. Keep one broad global ceiling, then add narrower limits by API method or route, and by tenant identity. AWS API Gateway explicitly supports throttling at the API or API method level, and usage plans identify clients with API keys. Kong documents the same idea from a different angle with service, route, and consumer-scoped rate limits.
That matters because the failure you are trying to avoid is not just "too much traffic." It is the noisy neighbor problem. Microsoft's architecture guidance is blunt: if one tenant consumes a disproportionate share of resources, overall performance can degrade. In payment and payout contexts, that can mean a reporting export storm slows down payout status polling or delays webhook processing enough to create operational confusion.
Use a layered policy, not a single bucket#
A workable decision rule looks like this:
- Keep a global limit as an outer guardrail for total platform pressure.
- Add endpoint or method limits for high-volume routes such as reporting, reconciliation pulls, or batch submission endpoints.
- Add per-tenant limits so one heavy caller cannot consume the whole shared budget.
If you are implementing this, the most important detail is the limit key. You should be able to inspect every throttled event by at least tenant or API key, route or method, and scope hit such as global vs endpoint. If your logs only show "rate limit exceeded," you will not know whether you have a bad tenant, a bad route, or a bad policy.
The tradeoff is tuning effort. Different route types often peak differently, so policy values that protect payout writes may feel too strict for reporting jobs, or too loose for status endpoints. Start simple, but once multiple high-volume routes are competing regularly, move past one global bucket. A layered model costs more to tune, yet it narrows the blast radius and gives you much better evidence when HTTP 429 Too Many Requests starts clustering.
Best Practice 4 Treat Webhooks and Ledger Reconciliation as Part of Error Handling#
In asynchronous payment flows, the first API response is often only an acknowledgment that work started, not proof that money movement finished. Once you have separate retry paths and scoped throttles, the next decision is what actually closes the loop. In most payout and virtual account flows, that should be the webhook plus the reconciliation record in your accounting or ledger system, not the original request log.
| Signal | Role | Caution |
|---|---|---|
| Initial API response | Intent or submission acceptance | Do not treat it as proof that money movement finished |
| Webhook | Provider's state update | Payloads can be outdated, partial, or arrive in the wrong order |
| Reconciliation record | Confirms the transaction record matches the accounting record before marking final | Do not let an old event push recorded state back without reconciliation evidence |
Providers explicitly use webhooks to deliver final outcomes after the initial API interaction. Stripe notes that webhook events help you respond when a bank confirms a payment, and Adyen describes webhooks as the message that arrives with the final outcome as soon as it is available. That matters because virtual account events can evolve after the first deposit notification. Bridge, for example, documents both a new deposit received event and later status changes such as funds delivered or refund issued.
A practical rule set looks like this:
- Treat the initial API response as intent or submission acceptance.
- Treat the webhook as the provider's state update.
- Treat reconciliation as the control step that confirms your transaction record matches the accounting record before you mark the record final.
That last step is the differentiator. Payment reconciliation is not just another status check. It is the act of matching transaction records against accounting records to confirm the payment is accurate. If a deposit was first marked as received and a later webhook indicates a refund issued, do not let a retry of the earlier request or an old event push your recorded state back to an earlier state. Only change it if you have reconciliation evidence that supports it.
The main risk is that webhook payloads are not always neat or ordered. Stripe's developer guidance is clear that webhook payloads can be outdated, partial, or arrive in the wrong order. Your handler therefore needs two safeguards: idempotent processing and ordering checks. In plain terms, processing the same webhook twice should leave the same result as processing it once, and an older event should not overwrite a newer reconciled state.
For each accepted state change, keep an evidence pack. Record the provider event reference, the related deposit or transaction identifier, the event receipt time, and the ledger or accounting record you matched against before posting the change. If you cannot show why a state transition was accepted, you will struggle to unwind duplicate or regressive updates during an incident.
One more failure mode is easy to miss: every webhook can trigger a read storm if you always fetch the latest object before deciding anything. Stripe notes that 429 responses may begin at typically 100 read requests per second. If your webhook consumer responds to each event with an immediate read call, you can create a second rate-limit problem inside your own error handling. Consider re-fetching only when the webhook payload lacks the fields you need to reconcile or validate the state change, and route mismatches for controlled review instead of letting blind retries keep rewriting state.
Best Practice 5 Add Compliance-Aware Degrade Modes for High-Risk Operations#
When compliance dependencies go stale, do not treat payouts and onboarding the same way you treat ordinary reads. One practical pattern is to degrade by risk: where program rules allow, keep some visibility features available while pausing new money movement and other high-impact writes until required verification, AML, or VAT checks are current again.
This follows how providers already gate regulated activity. Stripe explicitly notes that charges or payouts can be temporarily paused if required information is not provided or verified according to its thresholds. For AML, the stronger design principle is proportionality, not blanket shutdowns. FATF's current direction puts more emphasis on risk-based controls and simplified measures for lower-risk cases, so your degraded mode should reflect that distinction instead of failing every endpoint alike.
A useful decision split can look like this, depending on your program rules:
- Keep some lower-risk reads available such as payout status, onboarding status, and document visibility when the last good compliance result is still traceable.
- Pause new payout writes and new account activations when the gating check is unavailable, expired under your policy, or missing required evidence.
- Route borderline cases to manual review rather than auto-retrying into a non-compliant state.
What matters most here is the evidence pack behind each unblock decision. Keep the last successful check result, its timestamp, the source used, and the exact artifact tied to the account. That can include a Form W-9 for TIN collection, Form W-8 BEN when requested by the payer or withholding agent, and reporting records linked to FinCEN Form 114, Form 2555, or Form 1099-NEC where your product supports those flows. For EU cross-border VAT validation, record the VIES lookup result and country context. One easy failure mode is assuming UK GB VAT numbers still validate in VIES. That service ceased for GB numbers on 01/01/2021, so your fallback logic needs a different path.
Conclusion#
Reliable api rate limiting error handling is a sequence of control paths, not a single retry helper. Start with idempotency so a replay cannot duplicate a write. Split 429 from 5xx so throttling honors Retry-After and transient server faults stay bounded. Treat webhooks as part of completion, not as optional extras. And when money movement is compliance-gated, keep degraded behavior risk-based and tied to current verification evidence.
That does not make every failure disappear. It does give your team a clearer way to decide when to wait, when to retry, when to stop, and what record proves the final outcome.
Frequently Asked Questions
What should happen right after `HTTP 429 Too Many Requests`?
Stop sending the same request immediately and check for the Retry-After header first. If it is present, wait that long before the next attempt, because a 429 is a rate-limit signal, not a generic failure. If the header is missing, fall back to your bounded backoff path rather than guessing with instant retries.
When should you retry after `HTTP 500 Internal Server Error`, and when should you fail fast?
Retry only when the failure looks transient and the operation is safe to replay, which usually means the request is idempotent. Fail fast when the error is clearly non-transient or diagnosable, such as a bad configuration or authorization issue, because repeated attempts will not fix the cause. A common mistake is treating every 5xx like a 429 and letting queues grow while nothing improves.
What is the practical difference between `throttling` and `exponential backoff`?
Throttling is the limit you enforce on request volume once a threshold is reached. Exponential backoff is the delay pattern you use after a retryable failure, where each new attempt waits longer than the last. Put simply, throttling shapes traffic before it crosses a limit, while backoff spaces out retries after a failure. You often need both: throttling to reduce self-inflicted 429s, and backoff to space out retry attempts after transient failures.
Do idempotency keys remove the need for webhooks?
No. Idempotency stabilizes retries by reusing the first result for the same key, but webhooks are still needed when the final outcome arrives asynchronously after the initial request path. Use idempotency on the write path and webhook-driven handling on the completion path.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
- bsaaml.ffiec.gov/manual/BSAAMLRiskAssessment/01trusted
- docs.stripe.com/api/idempotent_requeststrusted
- docs.stripe.com/webhookstrusted
- federalregister.gov/documents/2024/07/03/2024-14414/anti-money-l...trusted
- govinfo.gov/content/pkg/FR-2024-07-03/pdf/2024-14414.pdftrusted
- irs.gov/forms-pubs/about-form-w-9trusted
- irs.gov/forms-pubs/about-form-w-8-bentrusted
- occ.treas.gov/topics/supervision-and-examination/bsa/bsa-a...trusted
Educational content only. Not legal, tax, or financial advice.
Related Posts

Rate Limiting and Throttling for High-Volume Payout APIs
High-volume payouts do not always fail in one obvious, dramatic way. Failures often show up in the seams. A burst of legitimate traffic slows the API, retries pile up, one integration can eat shared capacity, and what looked like a small tuning issue turns into reconciliation pain and duplicate risk later. If you treat rate limiting and request throttling as something to sort out after launch, you can bake debt into the part of the integration you least want to revisit.

Payment API Rate Limiting: How to Design Throttling Policies That Do Not Break Integrations
---

Tax-Loss Harvesting for U.S. Expats Living Abroad
Before you sell anything, settle one question: which country may tax the sale, and which records will support the filing. If residency is clear, move on. If you see dual-residency signals or treaty uncertainty, stop and sort that out before you trade.