
Quick Answer
Build one internal transfer record first, then initiate ACH debit and ACH credit through that record using an idempotency key on every create call. Track outcomes from the provider reference plus webhook events, and expect initiation to precede final settlement on a batch rail that can take 1-3 business days. Auto-retry only uncertain delivery failures, send business-rule failures to review, and require finance evidence such as a journal link or export mapping before marking a transfer complete.
What an ACH API Integration Needs to Handle#
Step 1 Set the scope#
Treat this as an architecture guide, not an ACH 101. An ACH API lets your platform initiate, send, and track ACH payments. The harder part is often not the first create-transfer call. It is deciding where transfer intent lives, how asynchronous status updates enter your application, and which records you keep when finance or support asks what happened to a specific payment.
If your team is still choosing between API-native initiation and manual spreadsheet, CSV, or bank-portal uploads, make that call early. ACH APIs are meant to replace those manual steps with automated, API-first payment handling. That changes more than integration style. It changes ownership, state design, retries, record matching, and how much operational work lands on engineering later.
A common risk is treating ACH as just another endpoint and discovering too late that the hard problems start after submission.
Step 2 Define the outcome#
Do not aim for generic ACH support. Aim to programmatically create ACH debit and ACH credit transfers, track each one through provider responses and later events, and close the loop with finance matching and an audit trail that operations and finance can actually use.
Every transfer needs a durable internal record that ties together the original request, the provider reference, later status changes, and the finance-side posting or journal entry. A good checkpoint at design time is simple. Pick one test transfer and ask whether you can trace it from initiation to final accounting evidence without hopping across disconnected tools or guessing which event changed its state.
If the answer is no, your integration may process payments, but it will still fail under investigation, close, or incident review.
Provider and market differences can matter, especially around initiation shape, event delivery, batch handoffs, and what data is available for finance matching. Some ACH implementations are built for fully automated collection and disbursement at scale, including recurring payment use cases. Depending on the provider, important edges like exports, exception handling, or status mapping may still sit with your team.
Use this guide as a decision structure: how you initiate, how you observe changes, how you match outcomes, and how you retain evidence. The red flag is an integration that makes transfer creation look easy but gives you weak visibility once money movement becomes asynchronous.
If you cannot point to the exact records you will keep for each ACH debit or ACH credit, including the provider reference and the artifacts finance needs later, pause there before writing more code.
If you want a deeper dive, read Invoice API Integration: How to Programmatically Generate Invoices for Your Platform.
What to prepare before you write a line of code#
Before implementation, lock down what transfer types you will send through the ACH API and what must be true before any transfer is initiated. If you skip this, the rework usually shows up later in onboarding, exception handling, and finance matching.
Step 1 Define the transfer types you will support#
Treat each transfer type as a separate product decision: one-off ACH debits, one-off ACH credits, and recurring ACH payments. If your provider offers multiple ACH speed or processing options, model those as explicit choices instead of a single generic "bank transfer."
A quick checkpoint is to draft one sample record per type and confirm you can identify direction, initiator, and the provider reference or downstream event you expect to track.
Step 2 Confirm onboarding and access gates#
Map bank account linking and bank account verification before you design initiation calls. Then mark where KYC or KYB must be complete; if your compliance process includes AML review, define that gate explicitly so onboarding issues are not misrouted as payment failures.
Also set expectations on network access early: direct participation in payment networks is tied to financial-institution status, so most platforms integrate through a provider or bank partner.
Step 3 Pick one source of truth and test failure paths#
Choose one authoritative internal record for money movement and keep initiation, status changes, and reconciliation tied to it. Then stand up sandbox tests that include failed verification, failed linking, duplicate submissions, and delayed status updates, not just happy-path transfers.
As a final readiness check, confirm your provider exposes the core developer surface you need: documentation, API status visibility, and sandbox access.
Related: ERP Integration Architecture for Payment Platforms: Webhooks APIs and Event-Driven Sync Patterns.
Choose your ACH initiation path without future rework#
If you need transfer-level control and clearer status handling, use an API-first path. If your team already runs stable scheduled file operations, batch processing can be a practical starting point, but define your migration trigger up front.
ACH is still a batch-processed rail, so initiation and settlement are different moments. In practice, an API call can return success before funds appear in the recipient account, and ACH settlement can still run on a 1-3 business day cycle.
Compare options by operating fit, not launch speed#
| Option | Integration speed | Transfer-level control | Operational visibility | Async reality |
|---|---|---|---|---|
| REST ACH API | Often a strong fit for modern app workflows | High | High, when your provider exposes usable status and tracking signals | API success can arrive before bank-account funds reflect |
| SOAP ACH API | Viable in enterprise environments | Medium to high | Medium to high | Same ACH batch-cycle behavior after initiation |
| ACH Payment SDK | Can speed initial integration when it fits your stack/provider | Depends on SDK surface | Depends on SDK surface | Still follows ACH's asynchronous settlement behavior |
| Batch processing | Fastest when scheduled file ops already exist | Lower at per-transfer level after handoff | Lower between submission and later outcomes | Built around scheduled batch timing, not real-time completion |
Decide based on exception handling#
Choose API-first when you need granular retries, clearer status mapping, and product-level orchestration across different payment flows. Choose batch-first when your immediate goal is reducing manual CSV uploads to bank portals and your transfer patterns are stable.
Set migration criteria before batch hardens into debt#
If you start with batch, define migration criteria now. Typical triggers are needing transfer-level retries, earlier and clearer status visibility, and reliable mapping from each initiation record to later outcomes.
Also avoid assuming initiation alone solves scale. A basic ACH API can help, but by itself it is not enough without solid outcome matching and internal state handling.
For a step-by-step walkthrough, see How to Manually Track Your Physical Presence Days for the FEIE.
Design the transfer state model before integrating endpoints#
Before you integrate endpoints, decide that your platform is the system of record for transfer state. Provider responses, webhooks, and bank-side updates are inputs, but your internal history should be deterministic and auditable from stored evidence.
Step 1 Define the platform states you will own#
Use a short, stable internal set: requested, submitted, pending network, settled, returned, failed, and reversed. Treat these as product states, not universal provider labels, so external status wording does not control your logic.
Step 2 Attach evidence to every transition#
Store a consistent evidence object for each state change: provider reference, webhook event (or payload record), internal event timestamp, and ledger journal link.
| State | Minimum evidence to persist |
|---|---|
requested | Internal transfer record showing accepted intent |
submitted | Provider reference tied to the transfer |
pending network | Correlated webhook/polling update after submission |
settled | Evidence used to confirm final ledger effect |
returned / failed / reversed | Exception outcome plus linked ledger impact/adjustment trail |
This is what keeps reconciliation from turning into a manual, ambiguous process later.
Step 3 Separate provider truth from platform truth#
API-first platforms can expose payments and payouts as programmable building blocks, including webhook- and idempotency-driven flows. Your platform still needs explicit transition rules for what evidence is sufficient to move a transfer forward.
If an incoming webhook cannot be correlated to a known transfer and provider reference, do not advance state automatically. Route it to an explicit exception branch with clear reconciliation ownership so return and failure paths do not sit in limbo.
Implement initiation endpoints with idempotent retries#
Make transfer creation idempotent before optimizing anything else: one idempotency key for one transfer intent should map to one outcome, even when calls are retried.
Step 1 Require and enforce an idempotency contract#
Require a client-supplied idempotency key on every create call, persist it on first receipt, and apply the same replay behavior in your API and worker layers. In a REST-based interface that returns JSON with standard HTTP methods and status codes, this prevents duplicate creation when a timeout or server error leaves the caller unsure whether the request completed.
Step 2 Validate intent and readiness before submission#
Validate transfer intent and platform readiness checks before provider submission, including your bank account verification status and compliance flags (AML/KYC). If prerequisites are incomplete, keep the transfer in a review path instead of submitting and retrying. If your integration uses OAuth 2.0, plus separate sandbox and production environments and credentials, confirm the environment at initiation time to avoid cross-environment errors.
Step 3 Retry only uncertain failures and keep immutable evidence#
Set a narrow automatic retry rule for uncertain delivery failures (for example, transport failures or timeouts), and route business-rule failures to manual review. For every create call, persist an immutable request snapshot, idempotency key, response mapping, and timestamps so the same record can support both audit and incident debugging.
This pairs well with our guide on How to Choose API Testing Tools by Cost, Compliance, and CI/CD Fit.
Build event handling and tracking your ops team can trust#
Trust in this layer comes from explicit mapping, not from webhook payloads alone. Treat each webhook as an input to your state model, define what it can change, and make that logic visible to both engineering and payments ops.
| Incoming event example | Internal transition | Retry policy | Alert severity | Escalation owner |
|---|---|---|---|---|
| Link session completion webhook | Mark onboarding attempt complete; queue public_token exchange | Retry only when processing failed before persistence | Set by policy | Set by policy |
ITEM_ADD_RESULT | Update onboarding result; move forward on success or set blocked reason on failure | Do not blindly retry business outcomes; route to review when needed | Set by policy | Set by policy |
| Hosted-session event notification | Append session timeline; no automatic money-state change by default | Retry transport/timeouts only | Set by policy | Set by policy |
Notification with notification type and Reason Codes | Map to internal status or review queue; store raw values with mapped state | Retry uncertain processing failures, not repeated business outcomes | Set by policy | Set by policy |
Handle duplicates and ordering as first-class concerns. Correlate on provider event ID when available, tie back to your internal object, and keep creation-time correlation data such as your idempotency key context. Design for out-of-order delivery so older events do not overwrite newer internal state unless you explicitly allow that transition.
Add verification checkpoints outside the handler path. Keep a queue for unmatched events, sweep for stale pending states, and run status-drift checks between provider-facing status and your internal Ledger state so webhook acceptance is not mistaken for operational completion.
Give ops a single tracking view that answers "what now?": current state, last event, blocked reason, next action, owner, and reconciliation status in one place, with raw notification type or reason code available for investigation.
You might also find this useful: How to Build a Partner API for Your Payment Platform: Enabling Third-Party Integrations.
Reconcile ACH outcomes to your ledger and reporting#
Reconcile in one direction: initiated transfer, settled outcome, returns or adjustments, then finance export tied to Ledger journals. Starting from exports or dashboard totals makes breaks harder to explain and harder to close.
| Stage | Rule | Handling |
|---|---|---|
| Initiated transfers | Build the match set from what you initiated, with internal transfer ID, provider reference, creation timestamp, amount, direction, counterparty or account reference, and the expected journal path | Keep pending items in this set until they settle, fail, or are explicitly canceled under your state rules |
| Settled outcomes | Match them back to the initiated set using internal transfer ID plus provider reference | Process returns and adjustments in a separate pass after this match |
| Returns or adjustments | Run them as a second pass | Hold them out of downstream reporting and route them for review if they cannot be traced to a clean initiation record and event history |
| Exports | Tie each exported line to journal evidence | A report is close-ready only when each exported line maps to journal evidence |
Step 1 Reconcile initiated transfers first. Build your match set from what you initiated, not from what was later reported back. For each transfer, keep one immutable creation record with your internal transfer ID, provider reference, creation timestamp, amount, direction, counterparty or account reference, and the expected journal path.
Keep pending items in this set until they settle, fail, or are explicitly canceled under your state rules.
Step 2 Match settled outcomes, then process returns or adjustments in a separate pass. Match settled outcomes back to the initiated set using internal transfer ID plus provider reference. After that, run returns and adjustments as a second pass so finance can clearly see whether a posted item needs a compensating journal, a status correction, or both.
If a return or adjustment cannot be traced to a clean initiation record and event history, hold it out of downstream reporting and route it for review.
Step 3 Tie exports to journal evidence, not status labels. A report is close-ready only when each exported line maps to journal evidence. Where your finance stack exposes journal runs by API, use that object as the shared reconciliation anchor. For example, Zuora's v1 API includes listing summary journal entries in a journal run.
For each exported line, keep a compact evidence pack: transfer ID, provider reference, internal status, journal or journal-run ID, export batch ID, and immutable event-history links.
Step 4 Run daily break controls and define handoffs. Before downstream reporting, check for:
- initiated transfers with no matched settlement or terminal outcome
- duplicate journal postings for the same transfer reference
- unresolved returns or adjustments with no finance treatment
Then document handoffs with ERP/reporting: who owns status mapping, who owns journal exceptions, when an export is final, and where the shared reconciliation status lives. If platform says settled but finance has no journal evidence, treat reporting as incomplete.
Automating settlement and reporting through APIs can speed reconciliation and reduce manual work when platform and finance review the same records.
Related reading: How to Set and Track KPIs for Your Freelance Business.
Handle compliance gates and risk controls without blocking good transfers#
Anchor compliance decisions to the same transfer record you reconcile, and run gates at fixed checkpoints so only genuinely risky items pause for review.
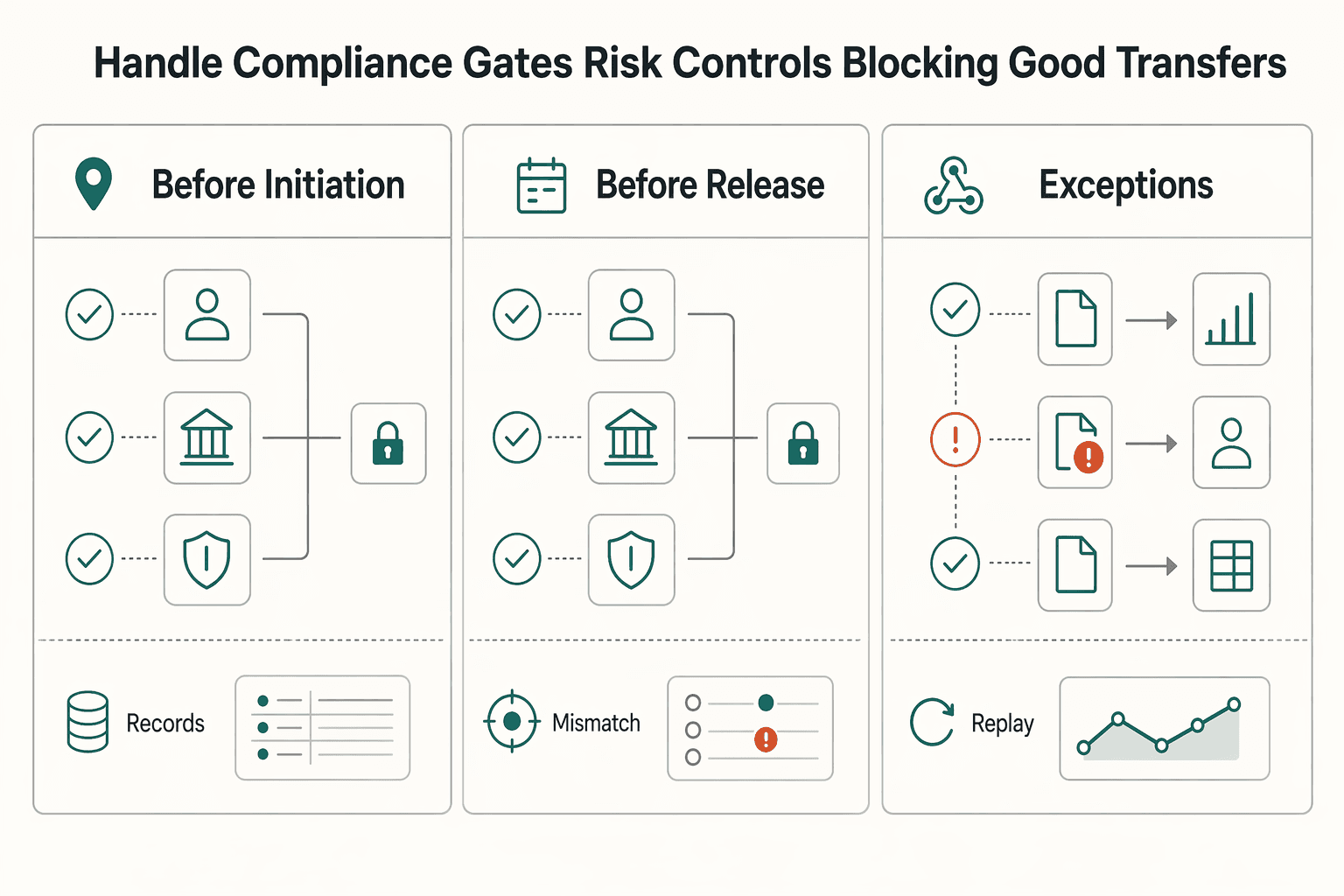
| Checkpoint | Evaluate | Record |
|---|---|---|
| Before initiation | KYC, KYB, and AML | Gate name, decision, policy version, and timestamp |
| Before release | Re-check KYC, KYB, and AML | Gate name, decision, policy version, and timestamp |
| Post-event exception review | Webhook updates as they arrive | Gate name, decision, policy version, and timestamp |
Step 1 Place checks at fixed checkpoints. Evaluate KYC, KYB, and AML before initiation, re-check before release, and run post-event exception review as webhook updates arrive. Keep each decision tied to the transfer with the gate name, decision, policy version, and timestamp so the control history is auditable.
Step 2 Use policy-based gating, not blanket holds. Payment APIs can abstract onboarding, fraud, compliance, and settlement, but your platform still needs explicit decision policy. Let transfers proceed when required checks pass, and pause higher-risk items with a clear blocked_reason, named owner, and required remediation evidence. Avoid a generic "pending compliance" state that hides ownership and blocks good transfers.
Step 3 Minimize sensitive data and keep controls consistent across rails. In logs and events, keep only what is needed for investigations and audit trail integrity, and avoid storing full identity payloads by default. Where supported, apply the same gating model to virtual accounts and payout controls so risk handling stays consistent.
Need the full breakdown? Read How to Secure a REST API: Prevention, BOLA Protection, Detection, and Response.
Final checklist to ship without platform debt#
Launch only when engineering, payments ops, and finance can all reference the same transfer record, evidence trail, and owner when something breaks.
| Launch check | Verification |
|---|---|
| Document the chosen integration path and migration trigger | One approved design note exists with the current path, key dependency, and a named migration trigger |
| Validate operational evidence capture before go-live | Sample records include request details, reference IDs, timestamps, current state, and assigned owner |
| Define control gates and exception handling clearly | Exception records consistently show reason, timestamp, actor, and next action |
| Rehearse close with finance-facing outputs | No missing or duplicate records, and finance can trace from transfer ID to exported line item without manual reconstruction |
| Assign ownership and freeze launch artifacts | Escalation ownership is clear before the first live transaction |
- Document the chosen integration path and migration trigger.
State the path you are shipping now, why it is acceptable for launch, and the explicit condition that would trigger a migration later. Verification: one approved design note exists with the current path, key dependency, and a named migration trigger.
- Validate operational evidence capture before go-live.
Confirm your team can trace each transfer from request through status updates to final outcome in one place. Verification: sample records include request details, reference IDs, timestamps, current state, and assigned owner.
- Define control gates and exception handling clearly.
Set where checks can stop or route a transfer, and what evidence must be recorded for review. Verification: exception records consistently show reason, timestamp, actor, and next action.
- Rehearse close with finance-facing outputs.
Run a dry close to confirm transfer outcomes map cleanly into the records finance uses for reconciliation. Verification: no missing or duplicate records, and finance can trace from transfer ID to exported line item without manual reconstruction.
- Assign ownership and freeze launch artifacts.
Name responders across engineering, payments ops, and finance, and store the launch pack in a durable location. External references can become unavailable, as shown by one Oracle document returning 404 and one Cybersource capture being blocked by a client extension. Verification: escalation ownership is clear before the first live transaction.
Frequently Asked Questions
How do I programmatically initiate and track ACH transfers from my platform end to end?
A practical pattern is to keep one transfer record in your platform and attach related initiation requests, provider references, events, and matching results to it. An ACH API lets you initiate, process, and track bank payments through software rather than bank portals or CSV uploads. In a sandbox, verify that one transfer view can show what was requested, what was sent, what came back, and the latest known outcome before you trust the live flow.
What transfer statuses should every ACH integration include to avoid ambiguous states?
Use your provider's documented statuses, and make each state unambiguous by attaching clear evidence and next-action ownership.
How do `Idempotency key` strategies prevent duplicate ACH transfers across retries and webhook replays?
Define your duplicate-prevention approach with your provider, and validate it in sandbox so retries or replayed events do not create unintended duplicate transfers.
When should we auto-retry a failed transfer versus send it to manual review?
Set those rules in your own risk and operations policy, and document why each transfer was retried or held.
How do `Webhooks` and scheduled reconciliation jobs work together without creating status conflicts?
Keep the focus on consistent status visibility and reconciliation so delayed or missed updates are detected and resolved.
Should we start with `Batch processing` or a `REST ACH API` for a new platform integration?
API-first workflows can replace manual file operations and improve payment status visibility, so choose based on your operating model and provider capabilities.
How do we map ACH outcomes into a `Ledger` without breaking finance reporting?
ACH automation supports reconciliation, so define ledger handling rules with finance based on your controls and provider documentation.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
Includes 7 external sources outside the trusted-domain allowlist.
- docs.wise.com/api-referencetrusted
- agilepayments.com/ach-apiexternal
- airwallex.com/docs/global-treasury/use-cases/vendor-payout...external
- developer.cybersource.com/docs/cybs/en-us/unified-checkout/developer/a...external
- developer.cybersource.com/docs/cybs/en-us/sa/developer/all/sa-checkout...external
- developer.zuora.com/v1-api-reference/api/summary-journal-entries...external
- dwolla.com/updates/what-is-ach-automationexternal
- explore.fednow.org/resources/customer-readiness-guide.pdfexternal
Educational content only. Not legal, tax, or financial advice.
Related Posts

Invoice API Integration for Programmatic Generation on Your Platform
For teams implementing invoice APIs and programmatic invoice generation, the hard part is usually not the create-invoice call. The real work is making invoice creation line up with payment collection, ERP posting, and the checks finance needs so nobody is rebuilding the trail later. If your team can generate an invoice but cannot trace it to a payment reference and an export-ready accounting record, you have a demo, not a production setup.

ERP Sync Architecture for Payment Platforms Using Webhooks, APIs, and Event-Driven Patterns
If you run payouts into an ERP, "just use an API and a webhook" is not enough. The design has to survive retries, late events, and finance scrutiny without creating duplicate payouts or broken reconciliation. The real question is not which transport looks modern. It is which pattern keeps postings correct, traceable, and recoverable when delivery gets messy.
How to Build a Partner API for Your Payment Platform: Enabling Third-Party Integrations
Treat payment partner work as an architecture decision, not a quick integration ticket. If provider-specific objects, statuses, and errors leak into your public API, switching providers later can force client-facing changes.