
Quick Answer
A new payment platform should build the smallest set of capabilities that unlock the first measurable business outcome and make the first live money movement flow safe to operate. In practice, that means sequencing Now items around blockers, core reliability controls, policy and audit trail gates, and clear ownership across product, engineering, and finance ops, while deferring expansion work that adds complexity without improving launch readiness.
What to Build First#
For platform payments, build order is a core launch decision. This article gives you a clear way to define what belongs in Now, what should wait, and which decision gates need to clear before you scale.
The scope is intentionally narrow. It is for founders, product leaders, finance ops, and engineering teams building embedded payments or marketplace payouts. This is not a generic roadmap guide for broad discovery or feature ideation. In money movement, sequencing mistakes create operational risk.
A product roadmap is a high-level plan for where the product is going and how it gets there. Used well, it communicates direction, priorities, and progress. Used poorly, it turns into a dated feature list. In this context, that distinction matters because dependencies are real, and some work should not move until a decision gate confirms readiness.
The bias throughout is simple: prioritize explicit priorities, dependencies, and governance gates over shipping the maximum number of features. Expect a focus on sequencing, visible blockers, and proof points. If a launch feature adds more operational exposure than business value, it likely does not belong in Now.
A practical roadmap should stay strategic and not collapse into a task tracker. Now / Next / Later is usually enough structure to keep sequencing clear without pretending every detail is knowable. For each Now item, make three points explicit:
- why it matters now
- what has to come first
- which review or decision gate confirms readiness
This is where teams often break down. Without governance and decision gates, sequencing slips under pressure. Many teams review the roadmap once per quarter and ignore it in between. That can hide blockers and push work forward out of order.
So the goal of this piece is not more process for its own sake. It is better build order. Use the roadmap as a communication and decision tool, not a guaranteed schedule, so product, finance ops, and engineering can rank work by shared logic instead of feature-by-feature debate.
Build a shared sequencing model before you pick features#
Start with shared sequencing logic, not feature debate. If product, engineering, and ops use different priority definitions, the roadmap can turn into a request pile.
Use a small set of working definitions and keep them stable across teams:
- Vision: the destination and outcomes the product is trying to achieve.
- Prioritized initiatives: the ranked bets that move you toward that destination.
- Scoped initiatives: the subset you plan to deliver in the current planning window.
Treat this as strategy, not intake. Start by stating what is true now, including key constraints and dependencies, then set a small number of strategic themes so ranking decisions stay tied to outcomes. If an item does not clearly support a theme, it likely does not belong in Now.
Keep the sequencing framework simple and explicit: vision to prioritized initiatives to scoped initiatives to backlog to release checkpoints. Rank bets first, scope what fits now, then break only that scoped set into backlog items. For each item, make checkpoints explicit: owner, metric, review date, and what must happen first.
Keep your Backlog and Feedback loop visible in one shared place for all owners. That visibility helps keep roadmap changes deliberate instead of reactive. If an item jumps the queue because it is loud or urgent but has no clear outcome or sequencing logic, treat that as a red flag and reprioritize in the open on a regular review rhythm.
Set your first 90-day build order and prove it with a table#
A 90-day Now / Next / Later table is a practical way to sequence launch work. It helps the team rank work by prerequisite order, operational risk, and time-to-market impact instead of treating everything as equally urgent. Use the timing below as a benchmark, not a universal rule.
| Phase | Timing | Prerequisite test | Operational risk test | Launch impact test | Pass/fail checkpoint |
|---|---|---|---|---|---|
Now | Day 1-30 | Removes a blocking prerequisite or confirms an architectural decision | Makes the first live flow observable and owned across product, engineering, and ops | Enables the first end-to-end launch path | Pass if the blocker map and owners are explicit, and the first flow can be reviewed end to end |
Next | Day 31-60 | Relies on a stable foundation from Now | Improves exception handling and day-to-day operating readiness | Supports controlled growth after the first path is working | Pass if a defined test phase is completed and unresolved exceptions have clear owners and decisions |
Later | Day 61-90 | No longer blocks launch readiness | Expands resilience or reporting after live feedback exists | Adds scale or optional expansion without delaying initial launch | Pass if post-launch findings are documented and reprioritized into the next cycle |
Use explicit defer rules so Now stays small. If a feature adds operational complexity without clearly improving launch readiness, move it to Later. Then pressure-test each candidate with three questions:
- Does it remove a launch blocker?
- Does it reduce risk on the first live flow?
- Does it support near-term launch goals instead of optionality?
If the answers are mostly no, it is not a Now item. This is where sequencing matters more than speed. Rushing early strategy and foundational decisions is a common launch failure pattern, and the failure mode is often organizational, not purely technical.
Related reading: How to Build a Deterministic Ledger for a Payment Platform.
Match capability order to your business model#
Capability order should follow the business outcome your model has to protect first, not a generic payments feature list. A marketplace payout flow, a recurring billing platform, and an omnichannel PSP can use similar components, but their sequencing should be validated with evidence rather than assumed from the model label.
Start by choosing 2 to 3 outcomes for the next quarter. Then test candidate capabilities against those outcomes and place them in Now, Next, or Later based on confidence and dependencies.
| Business model lens | Outcome to protect first | Now decision test | Common failure mode |
|---|---|---|---|
| Marketplace payouts | Define the highest-priority near-term outcome for this implementation | The item has a clear blocker, a named owner, a dependency review, and a checkpoint you can review end to end | Copying a fixed build order without model-specific evidence |
| Recurring billing platform | Define the near-term outcome with the clearest business reason | The item supports one near-term outcome, includes dependency review, and can be validated with operating evidence | Treating the roadmap as a feature list instead of an outcome plan |
| Omnichannel PSP | Define the near-term outcome that best aligns teams on current scope | The item maps to one near-term outcome, has an owner, and includes a review checkpoint | Committing to exact dates a year out |
Use this as a decision aid, not dogma. The same model label can hide different constraints, so lock sequencing only after product, engineering, and ops can point to the same evidence.
For each Now item, keep a compact evidence pack with:
- the outcome being protected
- the blocker making it urgent
- one dependency check and one operational checkpoint
- one named failure mode with an owner
Tie each call back to a clear business reason. If a proposed item cannot map to one near-term outcome and one clear reason, it should not displace an existing Now priority.
If cross-border payouts are part of the plan, Digital Nomad Payment Infrastructure for Platform Teams: How to Build Traceable Cross-Border Payouts goes deeper on building traceable payout flows.
Put compliance and policy gates in front of scale#
If a control decision can block delivery, it belongs in the delivery sequence from the start. After you set capability order for your model, bring compliance and policy gates into ownership, review, and release decisions instead of treating them as cleanup work after build.
| Gate | Checks | Release use |
|---|---|---|
| Policy decisions | Which policy decisions are in scope for this release; who owns each decision and exception path; where the decision is reviewed and measured before launch | Keep the decision point traceable in product behavior and visible in operating forums |
| Audit trail review pack | Events the team must be able to trace end to end; records used to connect decisions, status changes, and downstream outputs; who can apply overrides and how those actions are captured; one checkpoint proving teams can follow the flow without escalation | Treat traceability as a go/no-go control before launch |
| Provider confirmation | Confirm what the initial flow supports; record that decision with release artifacts; treat unclear support as a sequencing risk | Use a formal checkpoint before launch scope is locked |
Make policy decisions explicit in delivery#
Policy controls need to be visible, owned, and reviewable in the same operating forums as roadmap priorities. If a team can allow, restrict, or delay a critical flow, that decision point should be traceable in product behavior and not split across ad hoc steps.
Before launch, confirm:
- which policy decisions are in scope for this release
- who owns each decision and exception path
- where the decision is reviewed and measured before launch
That is how the roadmap stays a living governance tool instead of a static artifact.
Treat the audit trail as a go/no-go control#
Traceability should be treated as a release control, not a reporting extra. Compliance pressure is an operating-model constraint, so key processes should be standardized and traceable before scale.
Define a minimum review pack before launch:
- the events your team must be able to trace end to end
- the records used to connect decisions, status changes, and downstream outputs
- who can apply overrides and how those actions are captured
- one checkpoint proving teams can follow the flow without escalation
If you want a deeper reference point, What Is an Audit Trail? How Payment Platforms Build Tamper-Proof Transaction Logs for Compliance pairs well with this section.
Add a provider confirmation checkpoint before launch#
Assumptions create bad sequencing. If launch scope depends on a provider, include a formal provider confirmation checkpoint before you lock launch scope. Confirm what your initial flow supports, record that decision with release artifacts, and treat unclear support as a sequencing risk rather than a launch assumption.
The tradeoff can be worth it: ship a narrower scope with explicit gates and traceable controls before you expand volume or complexity.
If compliance operations are starting to slow the roadmap, How to Build a Compliance Operations Team for a Scaling Payment Platform lays out the team design in more detail.
Sequence integrations by dependency risk, not partner pressure#
Integration order should prioritize upstream dependency risk and readiness, then weigh commercial urgency. Once policy gates are set, your roadmap should show what must come first and why, not just what is easiest to sell or easiest to build.
Rank integrations by operational consequence#
Not every integration carries the same consequence if it slips or fails. Use a simple relative order and ask:
- Does this affect core money movement outcomes?
- How wide is the operational impact if it fails?
- Is there a viable fallback if it is delayed or unavailable?
You do not need a numeric score. You need a clear order that makes dependencies and priorities explicit before lower-impact expansion work.
This matters because integration failures are often planning and governance failures, not just technical limits. When sequencing is weak, teams can lose priority clarity, ship lower-impact work first, and turn manageable work into long delays.
Pull no-fallback dependencies into earlier validation#
A prerequisite with no viable fallback is a strong signal to validate earlier, even if the implementation itself looks straightforward. The risk is often not API difficulty; it is limited recovery options if an upstream dependency fails late.
Before implementation, run a concrete checkpoint on launch-critical items:
- data integrity across records you create, receive, and reconcile
- security protocols and access boundaries
- architecture readiness for expected scale and failure states
- fallback position if provider output is delayed or unusable
That keeps readiness evidence-based instead of assumption-based.
Keep partner pressure visible, and make tradeoffs explicit#
Commercial demand still matters, but it should not silently reorder critical prerequisite work. Keep demand inputs visible and require an explicit tradeoff when they change sequencing.
A workable review rule is simple: consider accelerating a partner-driven item when the roadmap tradeoff is explicit against dependency risk. If it does not reduce a known upstream risk, record the tradeoff and sequence it deliberately.
Treat acquisitions and major expansions as explicit tradeoffs#
Acquisitions and large expansions can change sequencing, but they are not automatic priority signals on their own.
Use a simple test: does this move reduce a current launch risk, or mostly add new dependencies and coordination load? Make that decision explicit in the roadmap so build order stays credible under pressure.
Engineer reliability surfaces from day one#
Reliability work is not later-stage polish. Build replay-safe money movement paths before you add volume. If an API or payout integration can create a new side effect on retry, it is high risk to launch.
| Control | Key requirement | Review check |
|---|---|---|
| Idempotency | Require an idempotency key for any endpoint that creates or changes money movement; pair it with a deterministic request fingerprint tied to business intent | Valid retries return the stored outcome, and critical APIs and integrations are tested for in-progress dedupe, completed replay, mismatch rejection, and expiry handling |
| Failure states | Separate temporary uncertainty, permanent failure, and duplicate or mismatched retry attempts; define what is automated versus what routes to people; keep timeouts, retries with backoff, and circuit breakers in the baseline | Each state has an owner and procedure before launch |
| Audit trail transitions | Trace every critical status change from first request through reconciliation | Include the original API request, idempotency key, request fingerprint, stored replay response, and status transitions, and verify that the records map to reconciliation output |
Duplicate payment incidents often come from retries, timeouts, and reconnect behavior hitting non-idempotent endpoints. Without an idempotency policy, every retry can become a financial event, and the visible symptom is simple: one customer, two charges.
Make idempotency non-negotiable#
For any endpoint that creates or changes money movement, require an idempotency key as part of the API contract. On a valid retry, return the stored outcome instead of re-running business logic.
Pair the idempotency key with a deterministic request fingerprint tied to business intent so you can separate a true retry from a changed request that reused the same key. Before launch, test these lifecycle cases across critical APIs and integrations:
- in-progress dedupe
- completed replay
- mismatch rejection
- expiry handling
A common failure mode is when a provider accepts a request but times out before your side gets a clear outcome. The caller retries. Without a persisted outcome to replay, you can create a second instruction. Idempotency keys do not guarantee exactly-once behavior across every distributed component, but they do help prevent your own platform from turning normal network uncertainty into duplicate money movement.
Standardize failure states before scale#
If you do not define failure states early, support and reconciliation pressure can end up defining them for you. At minimum, separate temporary uncertainty, permanent failure, and duplicate or mismatched retry attempts, then define what is automated versus what routes to people.
Timeouts, retries with backoff, and circuit breakers belong in the baseline. Each state also needs an owner and procedure. Support messaging, finance ops handling, and engineering escalation should be explicit before launch.
Be cautious about adding more payment methods or channel variants until this status model exists across core integrations. More methods add settlement timelines, exception handling, and refund and support edge cases.
Tie every critical transition to the audit trail#
Every critical status change should be traceable from first request through reconciliation. Each transition should let the team answer three questions: what was requested, what changed, and how that maps to final financial output.
For launch review, require an evidence pack, not just passing tests. Include the original API request, idempotency key, request fingerprint, stored replay response, and status transitions in the audit trail, then verify that the records map to reconciliation output. If any link is missing, the roadmap is ahead of operating reality.
You can harden these reliability surfaces over time from maturity level 0 to 3, but basic controls should not be deferred.
Define who decides what across product, finance ops, and engineering#
Once reliability controls are in place, decision drift can become the next risk. Set decision rights before you expand the roadmap, or priorities can move through side conversations instead of explicit tradeoffs.
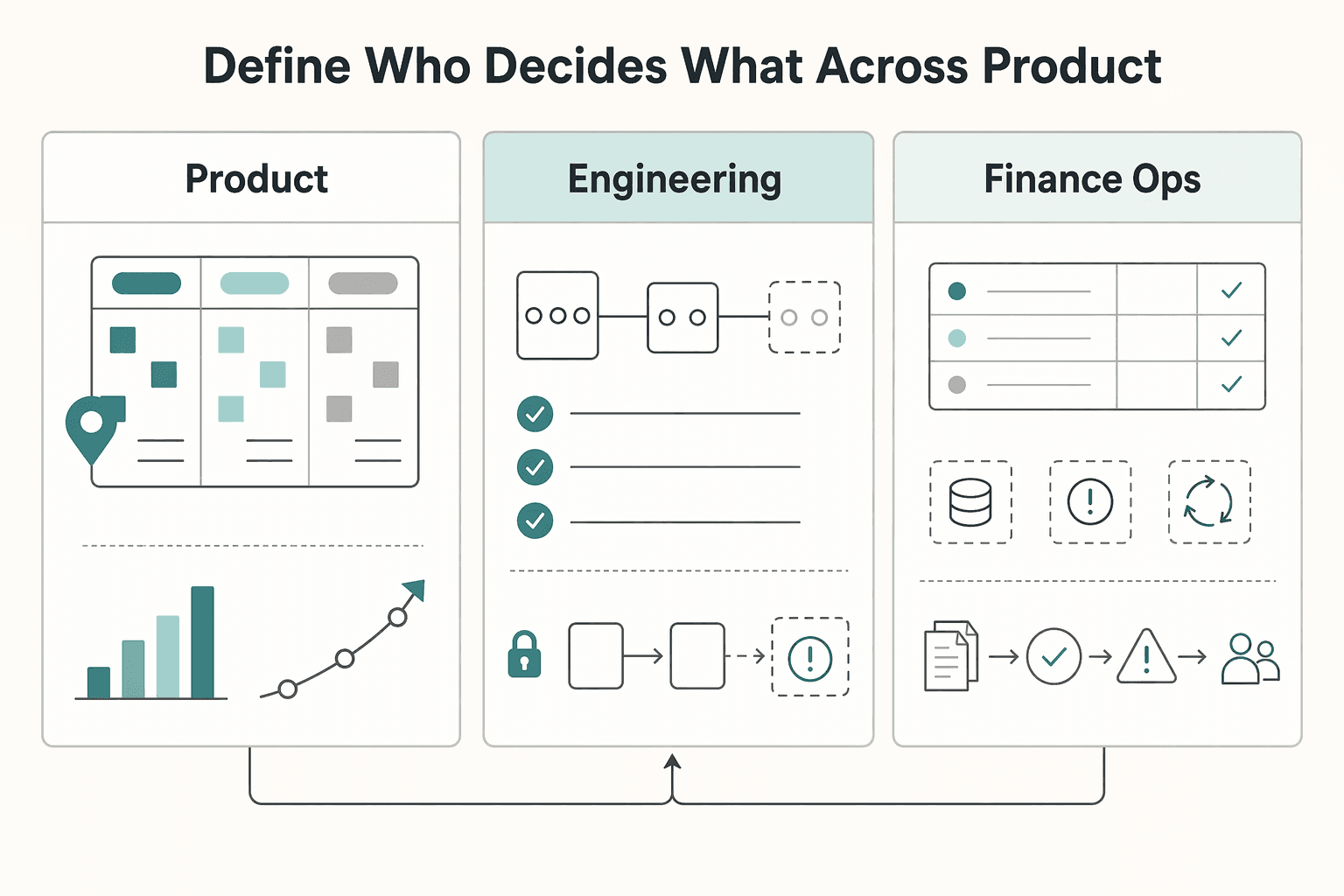
Use one clear working split tied to roadmap decisions. One practical split to test is: Product leads sequencing intent for Prioritized initiatives (Now, Next, Later) and how that sequence supports the vision; Engineering leads technical prerequisites and dependency risk; Finance ops leads reconciliation and exception readiness checks so changes do not create stuck cash, exception chasing, or customer trust loss.
| Function | Owns | Must bring to review |
|---|---|---|
| Product | sequencing intent for prioritized initiatives | ranking rationale, customer or business reason, change note if an item moved |
| Engineering | technical prerequisites and dependency risk | blocker status, launch blockers, failure modes, verification result |
| Finance ops | reconciliation and exception readiness checks | exception impact, reporting effect, payout handling implications, evidence needed for review |
Keep this in one lightweight decision matrix, not separate team trackers. For each candidate in the Backlog, record four items: why it is prioritized, which blocker could stop it, what finance ops must verify, and who has final sign-off if tradeoffs appear. That helps the roadmap stay an alignment tool instead of turning into a fixed feature list with unchangeable deadlines.
Use one shared review rhythm for Backlog changes and Feedback loop updates so reprioritization stays visible. Ask for evidence when items move, such as incident learnings, support patterns, reconciliation findings, or upstream changes. If an initiative jumps the queue without that record, treat it as hidden reprioritization and challenge it.
Document an escalation path for blockers that threaten compliance, payouts, or reporting integrity. If a launch item could break payout continuity, compromise reporting, or bypass a control, take it out of normal prioritization and route it through a named cross-functional go/no-go review.
For a step-by-step walkthrough, see What Is a Payment Facilitator (PayFac)? And Should Your Platform Become One.
Use a decision table to choose Now, Next, and Later items#
If you want Now, Next, and Later to hold up under pressure, use one shared decision table. Keep it in your single planning source so tradeoffs, blockers, dependencies, and reprioritization stay visible.
Score with simple labels#
Use High / Medium / Low labels as a discussion aid, not a weighted formula, across a shared set of columns:
- Customer impact: expected effect on meaningful customer or business outcomes.
- Operational risk: likelihood of added delivery or support strain if the item is rushed or underbuilt.
- Prerequisite load: how much must land first before the item is launch-ready.
- Coordination sensitivity: how much cross-team alignment is required to execute cleanly.
| Initiative | Customer impact | Operational risk | Prerequisite load | Coordination sensitivity | Working bucket |
|---|---|---|---|---|---|
| Baseline reliability work | Set in review | Set in review | Set in review | Set in review | Now / Next / Later |
| Payments orchestration | Set in review | Set in review | Set in review | Set in review | Now / Next / Later |
| Multi-gateway strategy | Set in review | Set in review | Set in review | Set in review | Now / Next / Later |
| Expansion integrations | Set in review | Set in review | Set in review | Set in review | Now / Next / Later |
Treat this as a decision aid, not a fixed formula. The point is to expose tradeoffs clearly, especially where one choice consumes capacity that cannot be used elsewhere.
Apply one focus rule#
When a Later item is proposed for Now, compare it directly against current Now items in the same review on expected impact, dependencies, and readiness. Keep blocker status and operational ownership explicit before reordering.
Keep the ranking trust-first#
Final ordering should reflect the Trust-first product roadmap principle. Growth can move up when readiness and dependencies are clear, without obscuring reliability tradeoffs.
Fix the sequencing mistakes that burn quarters#
Most sequencing failures come from treating the roadmap like a feature queue instead of a goal-linked plan that gets reviewed and corrected as evidence changes.
Stop treating the Product roadmap like a feature list#
A product roadmap is an alignment tool, not a request dump. Every Now item should connect to a clear business outcome and evidence that the work is ready to execute.
If that connection is unclear, keep the item in Next or Later as directional work. This also helps avoid overpromising exact long-range dates that are likely to shift as assumptions change.
Keep the plan anchored to a short vision and a small quarterly outcome set. A practical constraint is 2 to 3 outcomes per quarter. If an item does not advance one of them, it should not displace committed work.
Do not mistake visible expansion for readiness#
Expansion can be commercially attractive, but visibility is not proof of readiness. Move expansion up only when you can show evidence that the current scope is working and supports committed outcomes across teams.
Use simple evidence checks in the same review: what changed, what worked, and what still needs clarity. If that evidence is thin, keep the work directional until readiness is demonstrated.
Separate core priorities from ad hoc asks#
Ad hoc demand can distort build order when it bypasses the same decision rules as planned work. Keep these requests separate from roadmap items already tied to committed outcomes, then evaluate both against the same quarterly outcomes.
If a request does not materially advance a committed outcome, it should not enter Now. That keeps prioritization tied to strategy, not side-channel pressure.
Make the feedback loop explicit#
A roadmap that is not reviewed often becomes static fiction. Keep Now / Next / Later honest by recording what changed and why.
If a priority change cannot point to new evidence, it is usually reshuffling, not sequencing.
Run a launch-readiness checklist before you scale volume#
Before you scale volume, run a repeatable go/no-go checklist. Failures can surface in development or commercialization, and some trace back to early-stage decisions, so this review should catch gaps before volume hides them.
| Review area | Checks | Record or action |
|---|---|---|
| Sequence integrity | Who owns the launch decision and post-launch follow-up; what result indicates success; what is the response if it fails on day one | Keep one short evidence record with owner, success criteria, blocker, failure-response note, and rollback trigger |
| Controls evidence | Which gate or approval applies; what trace record is expected; what review artifact operations should check | Mark each required artifact as pass, fail, or unclear before the decision meeting |
| Observed platform behavior | Verify that failure paths are exercised and that operating instructions match real status transitions; run a cross-functional walkthrough with engineering, support, and operations using real states and handoffs | If the documented steps do not match platform states, treat that as a launch blocker |
| Commercial promises | Confirm that customer-facing promises match what is enabled in production now | Add one timestamped checkpoint row per review with the decision, open risks, and owner for each unresolved item |
Treat this as a phased checkpoint, not a one-time signoff. Product work is rarely linear, and speed pressure can outrun tradeoff clarity if you do not re-check Now scope as it changes.
Check sequence integrity first#
A Now item is not launch-ready until ownership, success criteria, and failure response are explicit in one place. Use a simple three-question test for each Scoped initiative:
- Who owns the launch decision and post-launch follow-up?
- What result indicates success?
- What is the response if it fails on day one?
If those answers are scattered, the item is still underdefined. Keep one short evidence record per item: owner, success criteria, blocker, failure-response note, and rollback trigger.
Verify controls with reviewable evidence#
Check controls as reviewable evidence, not intent. For critical events, confirm which gate or approval applies, what trace record is expected, and what review artifact operations should check.
Mark each required artifact as pass, fail, or unclear before the decision meeting. If traceability is unclear, keep scope bounded until it is clear. If you want a deeper refresher on traceability expectations, What Is an Audit Trail? How Payment Platforms Build Tamper-Proof Transaction Logs for Compliance is the relevant companion piece.
Confirm actual platform behavior, not intended behavior#
Readiness should be based on observed behavior, not intended behavior. For key flows, verify that failure paths are exercised and that operating instructions match real status transitions.
Run a short cross-functional walkthrough with engineering, support, and operations using real states and handoffs. If the documented steps do not match platform states, treat that as a launch blocker.
Make commercial promises pass the same test#
Commercial commitments should match what is enabled in production now. Apply the same readiness standard to customer-facing promises as you apply to delivery scope.
If a promised capability is still marked unclear in the checklist, narrow the promise or narrow the launch. Add one timestamped checkpoint row per review with the decision, open risks, and owner for each unresolved item.
If your checklist is passing but implementation details are still fragmented, use the Gruv docs to review currently documented API behavior, webhooks, and operational status handling where enabled before launch.
Conclusion#
Good sequencing is usually simpler than the debate. Establish core controls first, then expand capabilities once core money movement is stable enough to operate and review. For platform payments, your roadmap should decide what must be true for launch and what can wait.
A strong roadmap is a decision system, not a feature wish list. Set clear direction, turn it into prioritized initiatives, and keep backlog and feedback visible so changes are deliberate. Treat the roadmap as a high-level hypothesis about direction and why, not as the backlog and not as a fixed commitment.
Use Now / Next / Later to force ordering without pretending uncertainty is gone. Keep Now small and explicit, and attach clear evidence to each item before you call it ready. If priorities change because of bugs or immediate operational needs, update the roadmap visibly and document the tradeoff.
Next step: build your Now / Next / Later table and review every Now item against the first measurable outcome before committing scale targets. If an item does not support that outcome or is less ready than the current Now work, move it out.
When you are ready to pressure-test your roadmap against real payout and compliance constraints, talk with Gruv.
Frequently Asked Questions
What should a new payment platform build first?
Build the prerequisites that directly unlock the first business outcome and the first end-to-end live flow. Start with a short vision, then keep only the Now items that remove blockers, reduce risk, or support near-term launch goals. If an item does not support that outcome now, move it out of Now.
How do we sequence compliance and payouts without slowing launch?
Keep compliance and payouts in one shared roadmap decision path when either can block launch. Make dependencies, ownership, and decision rationale visible in the same roadmap record instead of splitting them across separate tracks. Confirm market- and program-specific details before assigning dates.
Which criteria should rank payment roadmap items when teams disagree?
Rank items by objective fit, prerequisite load, and capacity cost. Keep the ranking in one shared source of truth so blocker status, dependencies, and tradeoffs stay visible. That helps teams align without letting decisions drift across separate tools and conversations.
What can safely wait until post-launch without creating major risk?
Work that does not unlock the first measurable outcome is usually the best candidate for Later. Expansion scope and polish can wait if they do not hide critical blockers. If an item seems optional but can block launch readiness, treat it as Now and decide explicitly.
How should product, finance ops, and engineering split ownership by phase?
A workable split is Product for sequencing intent, Engineering for technical prerequisites and dependency risk, and Finance ops for reconciliation and exception readiness. There is no universal split, so assign ownership per item and document one escalation path. If ownership is unclear, resolve that before the item enters Now.
When should a platform add payments orchestration or a multi-gateway strategy?
There is no universal trigger here for adding payments orchestration or a multi-gateway strategy. Evaluate it against the current objective, expected benefit, and explicit capacity tradeoffs. If the case is still abstract, keep it out of Now.
How do country and program differences change sequencing decisions?
They can change both scope and order. Keep the roadmap adaptable and avoid turning timeline columns into fixed promises. Before assigning work to Q2 / Q3 / Q4, verify what is actually supported in each target market and program.
What is the biggest mistake in payment product roadmap sequencing what to build first new platform?
The biggest mistake is treating the roadmap like a dated release list instead of a strategic decision tool. When teams skip objective, blocker, and tradeoff clarity, capacity gets pulled toward noise instead of outcomes. Keep the roadmap tied to goals, dependencies, and evidence.
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
Includes 6 external sources outside the trusted-domain allowlist.
- congress.gov/116/plaws/publ94/PLAW-116publ94.htmtrusted
- sei.cmu.edu/documents/1601/2020_011_001_650224.pdftrusted
- aakashg.com/what-is-a-product-roadmapexternal
- alphapoint.com/blog/stablecoin-payment-integration-for-bank...external
- blazonagency.com/post/product-launch-timelineexternal
- blog.roadmap.one/posts/blog16-how-to-build-product-roadmapexternal
- codingdroplets.com/idempotency-keys-in-aspnet-core-preventing-d...external
- craft.io/guide/product-roadmaps-a-detailed-introducti...external
Educational content only. Not legal, tax, or financial advice.
Related Posts

The Freelance Payment Penalty: A Modeled Audit of Platform Fees, FX Spreads, and Payout Delays
The money rarely disappears through a single, easy-to-spot fee. The real loss is stacked. A marketplace takes its commission, a processor adds a charge for international cards, a bank or payment company converts the currency at a spread, a platform holds the funds before release, and a wire sheds a little to intermediaries on the way in. Each layer looks defensible on its own, but the worker feels the combined result as a smaller deposit and a later payday.

How to Respond to a Subpoena for Business Records
Move fast, but do not produce records on instinct. If you need to **respond to a subpoena for business records**, your immediate job is to control deadlines, preserve records, and make any later production defensible.

A US Expat's Guide to Investing in UCITS ETFs to Avoid PFIC Issues
The real problem is a two-system conflict. U.S. tax treatment can punish the wrong fund choice, while local product-access constraints can block the funds you want to buy in the first place. For **us expat ucits etfs**, the practical question is not "Which product is best?" It is "What can I access, report, and keep doing every year without guessing?" Use this four-part filter before any trade: