
Quick Answer
Define `Idempotency-Key` scope per operation and treat a retry as replay, not new execution. On `POST /payments`, a key hit should return the original `HTTP` result, while a key miss executes once and stores a canonical response envelope. Claim ownership before any charge or payout mutation so parallel workers cannot post twice. Apply the same guard to asynchronous paths by deduping `webhook` deliveries and queue redelivery before writing `ledger journal` entries, then block rollout until failure tests show one intent yields one financial outcome.
Why idempotency matters in payment operations#
Treat duplicate money movement as a distributed retry problem, not a single HTTP bug. The goal is simple: the same customer intent should produce one financial result.
Duplicate charges often come from normal failure recovery, not one dramatic outage. A customer retries after a connection issue while your backend also retries after a timeout. If POST /payments creates a new payment record on every call, one intent becomes two financial writes, with immediate downstream costs in refunds, support load, and trust.
Start with the failure model#
In payments, failure is routine. That is why idempotent behavior matters. Repeating the same request should have the same effect as making it once, without extra side effects.
The baseline control is a request key on write operations, paired with reliability patterns like message queues. The key makes repeated attempts safe, and queues help retries survive partial failure without turning into duplicate execution. If your duplicate-payment review is still framed mostly as "double-clicks," widen the scope before you ship fixes.
Define the outcome before implementation#
Keep one lens throughout this guide: one intent, one financial result. We will apply it to POST /payments, then to adjacent money flows, and finally to the checks that keep finance and engineering aligned.
Use this practical checkpoint: repeat the same logical request on a known write path such as POST /payments and confirm you do not get multiple payment records or multiple charges for that single intent. If repeated calls still create new records, the duplicate-execution risk is still there.
The rest of the guide follows a production sequence: choose scope, design retry behavior, control concurrency, extend the pattern to adjacent flows, and verify under failure.
Where duplicate money movement actually starts#
Duplicate money movement usually starts at retry boundaries and async redelivery, not one broken HTTP call. In a distributed system, if your team cannot name the retry owner at each hop, assume duplicate side effects are already possible and fix that ownership before you scale.
Map every retry hop#
Trace one write intent end to end: client submit, API timeout retry, backend worker retry, downstream provider retry behavior, and webhook delivery and consumption. The common failure pattern is retries, timeouts, worker restarts, and concurrent handling of the same request, not a simple calculation error.
Treat timeouts as ambiguous signals. A timeout means "no confirmation yet," not "it definitely did not happen," so retry paths can execute the same business logic twice if they are not idempotent.
Separate charge risk from payout risk#
Charge-side and payout-side duplicates can look similar in logs, but they can fail in different places. Use that split when you review evidence and assign controls.
| Flow | Common duplicate entry point | Typical bad outcome |
|---|---|---|
| Charge path | Repeated user submits after a stalled experience, plus retry paths that create new attempts | One order can be charged twice (for example, $100 becoming $200) |
| Payout path | Retried workers or repeated payout execution in async processing | Funds can be resent, and dropped webhook events can drift ledger state |
Verify ownership with evidence#
For each hop, document three things: who retries, what signal triggers the retry, and what record proves prior execution. Use concrete evidence for the same intent, such as durable workflow history or state, a provider-side reference, and a consumed webhook record.
For one payment example and one payout example, trace the full chain. If you cannot show that chain, do not assume a request key by itself is protecting the flow.
Related: ERP Sync Architecture for Payment Platforms Using Webhooks, APIs, and Event-Driven Patterns.
What to prepare before you change production behavior#
Before you change production money movement, lock down two decisions. First, decide how you identify the same intent on retries. Second, decide which record is authoritative for prior-attempt checks and final outcomes. Without that baseline, retries can still create duplicate outcomes.
Define request identity before changing handlers#
Define one consistent Idempotency-Key approach for each write flow, and document who generates it. The rule is simple: the same intent should keep the same key across retries, and a new intent should get a new key.
For each in-scope endpoint, document:
- where the key is created
- where prior attempts are recorded
- how replay records are retained for that operation class
Run a retry test and verify the same key survives end to end, including downstream calls where supported. If a retry path drops it, the next system can treat the request as new work and repeat a charge ($100 becoming $200).
Document the records that decide truth#
Write down the source-of-truth records you already rely on for duplicate prevention and final outcomes. This is a decision map, not a schema redesign.
For one money-movement flow, you should be able to trace:
- incoming request identity
- prior-attempt record lookup
- downstream reference, if present
- final posting outcome
If that chain is not clear, replay behavior is not ready for production changes.
Assemble a minimum rollout evidence pack#
Keep the approval pack small, but concrete. Include:
| Evidence item | What it covers |
|---|---|
| Retry matrix | Who retries at each hop, including concurrency risk |
| Replay contract draft | Repeated key, timeout, validation failure, and unknown-processing states |
| Reconciliation outputs | Finance ops can verify |
| Prior-attempt check proof | A prior-attempt check, such as a flag or read check, runs before any charge or posting logic |
Also include proof that a prior-attempt check, such as a flag or read check, runs before any charge or posting logic. For finance-side validation context, keep account reconciliation guidance in scope.
Set rollout boundaries before implementation#
Do not start with "all write endpoints." Name the first boundary and what stays out of scope for wave one.
Any endpoint that can move money and can be retried should have:
- a documented identity rule
- a named authoritative record for prior execution
That is the minimum baseline before you change production behavior.
Step 1 Set idempotency scope and key ownership#
Set one clear key strategy and one clear scope per logical operation before you change handlers. If scope is ambiguous, retries can be treated as new execution.
Idempotency is a caller-service contract. Repeated requests with the same identifier should produce the same observable outcome. That only works when your team agrees, per operation, how the identifier is generated and how repeats are recognized.
Assign one key strategy per operation#
For each operation class, use a stable idempotency-key strategy and apply that rule consistently for the same logical action.
If one intent can end up with multiple keys, replay becomes unreliable. Keep one dedupe key for execution, and treat any secondary IDs as trace metadata.
Scope keys to operation boundaries#
A raw key value is not enough. Define where that key is valid. One key should map to one logical operation type, not multiple unrelated writes.
Your lookup behavior should follow a simple pattern:
- key hit: return the stored outcome
- key miss: execute once, persist key plus outcome, then return
Plan for concurrent arrivals here as well, so simultaneous requests do not race into duplicate processing.
Separate retries from legitimate repeats#
Use one hard rule everywhere: same intent uses the same key, new intent uses a new key. Apply this at API boundaries and message-processing boundaries, since at-least-once delivery can redeliver the same work.
For each in-scope operation, document:
| Document item | What to define |
|---|---|
| Key generation | How the key is generated |
| Same intent rule | What counts as the same intent |
| Storage | Where key and prior outcome are stored |
| Expiry | When keys expire or age out |
| Late retries | How late retries are handled after expiry |
Keep expiry explicit. Keys need lifecycle controls to avoid unbounded growth.
Step 2 Design replay semantics before coding handlers#
Define replay behavior before you write handler code. For the same request key, return the prior outcome instead of re-executing the financial operation.
Define replay in HTTP terms#
Write the contract from the caller's point of view. A key hit should replay a consistent prior outcome for that same logical request.
Idempotency here is about the business operation, not just transport dedupe. The goal is one intended outcome when retries happen. As a practical guardrail, store replay records with composite ownership boundaries, such as (user_id + idempotency_key) in a multi-tenant model, to reduce cross-user collisions.
Specify write-path sequencing#
Spell out one explicit path so retries always have a single replay source. One workable pattern is:
- Scope the idempotency key to the business operation and owner.
- Execute the operation when no prior result exists for that key.
- Persist one canonical result for that key.
- On retry, return that stored result instead of re-executing.
The requirement is consistency. The same key should resolve to one stored result, not open a second execution path because of timing.
Compare response behavior by outcome class#
| Outcome type | First handling expectation | Retry with same key |
|---|---|---|
| Success | Complete the logical operation and store a canonical result | Replay the stored success outcome |
| Validation failure | Return a stable failure outcome for that request | Replay the same failure outcome |
| Downstream timeout with known non-completion | Return a stable non-success outcome once non-completion is verified | Replay that same outcome for the key |
| Unknown-processing state | Mark result as ambiguous when completion cannot be proven | Return a stable ambiguous or in-progress outcome tied to the same key |
Set a decision rule for ambiguity#
Ambiguous state is where duplicate writes can slip in. If completion cannot be proven, keep responses stable under the same key and do not create a second financial write.
Retries and ambiguous timeouts are normal in at-least-once systems. Your replay contract should treat them as expected behavior, not exceptions. Use "one intended outcome per logical request" as the operating promise instead of assuming universal exactly-once execution across distributed flows.
Step 3 Control concurrency across workers and queues#
Once replay semantics are defined, concurrency control prevents duplicate money movement under load. In distributed systems, duplicate attempts are normal, and parallel workers can see the same key, so on write paths like POST /payments and payouts, enforce single ownership even if it adds some latency.
Claim the key before any money movement#
Process same-key requests only once at the server so one worker executes a given logical request. If a worker cannot verify ownership for that key, it should not create a charge, payout, or ledger journal entry; it should replay the stored result or return a stable in-progress response for that key.
One safe sequence is: claim first, mutate money state second, persist the canonical response third. Keep ownership boundaries visible in storage, such as key plus tenant or user scope, so same-key handling cannot cross accounts.
Dedupe queue consumers and webhook handlers#
API-layer idempotency is not enough. message queue redelivery and duplicate webhook delivery are normal in distributed systems, so consumers also need dedupe checks before they apply downstream side effects.
Use the same rule as the API path: if a delivery for that business operation was already applied, skip or replay instead of posting again. This is especially important during redelivery windows after retries or failures.
Pair retries with a circuit breaker#
Retries can increase duplicate-attempt pressure during dependency failures. If you use a circuit breaker, keep idempotency behavior consistent so each key maps to one stable outcome class: replayed failure, retriable response, or in-progress state.
For deeper breaker design, see How to Implement Circuit Breakers in Payment APIs: Preventing Cascade Failures.
High contention is not a reason to relax money-movement controls. In payment flows, prioritize correctness first, then optimize throughput.
For a step-by-step walkthrough, see Xero Multi-Currency for Payment Platforms: How to Reconcile Foreign Currency Payouts.
Step 4 Extend idempotency to payouts and ledger posting#
Do not stop at card charges. Apply the same replay contract to other financial writes so retries and duplicate-delivery attempts resolve to one stable outcome instead of repeated financial side effects. Specific payout endpoint behavior should be confirmed in your provider docs.
Apply the same replay pattern to payout-side writes#
Treat payout-side mutations as idempotent write paths, not "admin-only" exceptions. If your API already uses a request key and replays a stored prior response on retries, carry that same pattern into other payout operations that change state where your integration supports it.
The core rule does not change: reuse the same key for the same business intent, and issue a new key for a genuinely new intent. Without that boundary, retries and new requests are hard to distinguish reliably.
For financial operations, keep the idempotency record and business mutation in the same primary-database transaction when possible. Storing dedupe state only in fast cache can fail on restart or eviction, which brings duplicate-execution risk back.
Dedupe asynchronous inputs before any ledger journal write#
At-least-once delivery means the same message can arrive more than once. If you process asynchronous provider inputs, check dedupe status before writing a ledger journal entry.
Use a stable external event identity, or a defensible composite identity, plus account or tenant scope. Then link the first accepted delivery to its posting result. Later duplicates should no-op or replay the stored processing result instead of posting again. Treat this as a control objective, since provider-specific webhook dedupe mechanics are not established in the provided excerpts.
Keep request-to-ledger traceability explicit#
The ledger is your system of record, and General Ledger Entry records sit at the accounting boundary. Keep an auditable mapping from request or event identity to internal posting result so operators can verify whether an origin was already applied.
A practical minimum is: request or event identity, scope, payout or account reference, resulting journal or posting ID, stored response or processing outcome, and applied timestamps. If your OLTP model is normalized, for example 3NF or higher, keep this mapping in that model rather than scattering it across hard-to-reconcile side paths.
Step 5 Keep compliance gates replay-safe#
Compliance decisions can create duplicate operational work just as easily as money movement. Keep them replay-safe under the same request key so the same business intent returns the same allow, block, or review outcome, plus the same decision reference.
Make policy decisions deterministic per key#
A retry should not open a new compliance case or produce a different result just because the request was replayed. Use one rule: same key and same submitted facts should replay the same decision. Changed facts or a materially different policy version should be treated as a new intent.
This is especially important for date-sensitive checks. For FEIE-related handling, the IRS physical presence test uses 330 full days during any period of 12 consecutive months, and those days do not need to be consecutive. Snapshot the evaluation date and input window used on first decision so retries do not drift.
Dedupe compliance document workflows#
Apply the same dedupe discipline to compliance document requests as you do to financial writes. Retries should not create duplicate collection flows for FEIE or FBAR-related steps.
For FEIE workflows, keep the decision trail explicit and replayable. A practical checkpoint sequence is: determine presence in a foreign country, count qualifying days, then determine excludable FEIE. If your first pass referenced a Form 2555 or 2555-EZ path, replay that reference instead of opening a second request. Treat that IRS practice-unit sequence as operator guidance, not binding legal authority.
For FBAR-related reminders or holds, preserve the notice context used at decision time. FinCEN posts filing-date and event-based extension notices, including an additional extension notice dated 10/11/2024, so avoid replay behavior that assumes one permanent date.
Store decision context with the idempotency record#
Do not store only the HTTP response. Store the compliance context with the idempotent entry as well. At minimum, persist:
| Context item | Stored value |
|---|---|
| Decision reference | Decision reference or case ID |
| Outcome | Replayed outcome (allow, block, or review) |
| Policy version | Policy or ruleset version used |
| Document requests | Document request IDs already created, if any |
| Evaluation context | Evaluation date and relevant notice reference |
| Feature flags | Feature-state flags used at decision time |
That gives audit and ops one trail to explain why a retry was allowed or blocked, and it makes duplicate document creation easier to catch early.
Step 6 Verify with failure injection and reconciliation checks#
Do not expand endpoint coverage until failure tests prove your core consistency invariants. Happy-path success is not enough in a distributed system. You can compute the right result and still get different runtime behavior under retries, concurrency, or partial failure.
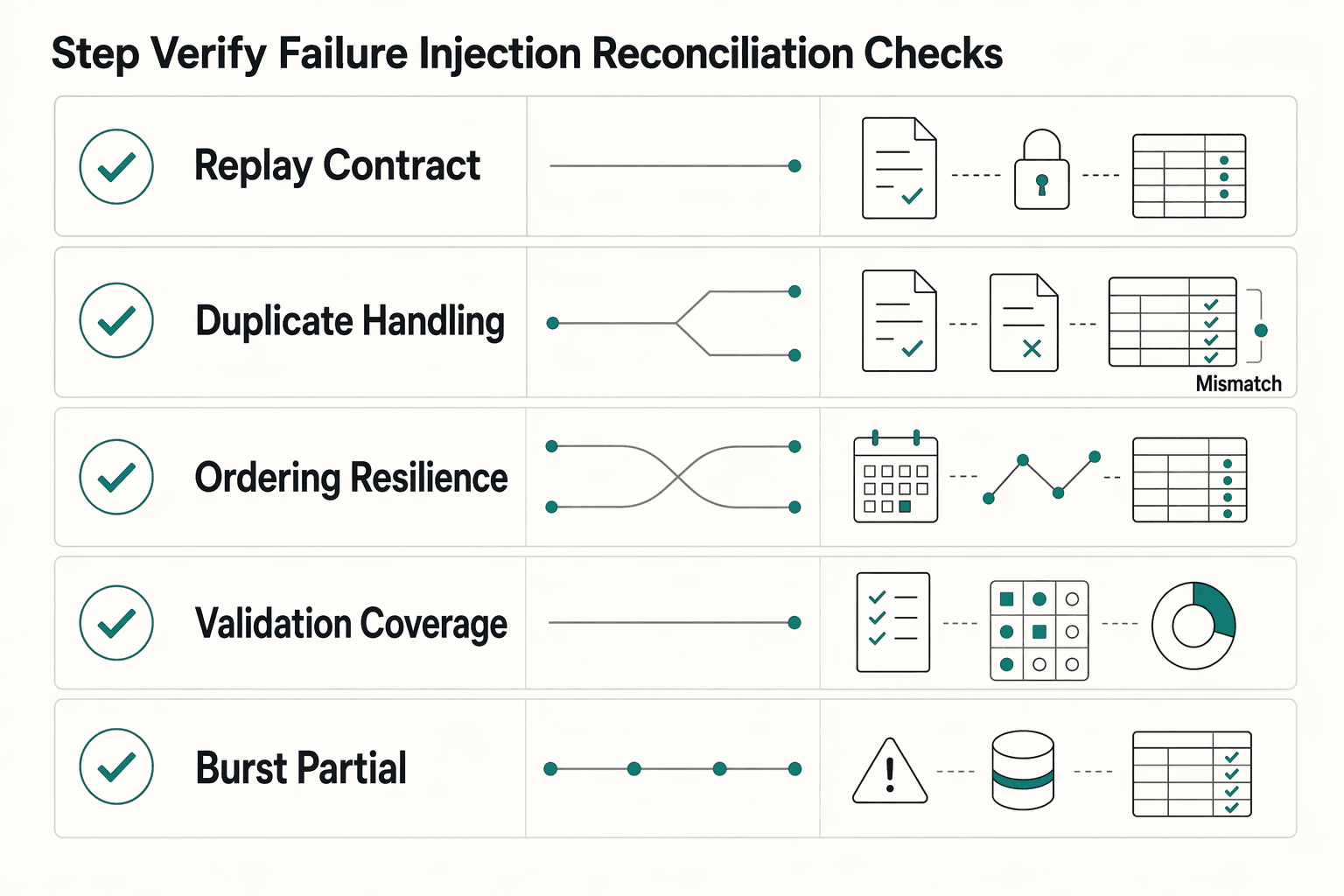
Define the invariants before you script failures. Write the invariants first so engineering and finance judge outcomes against the same rules:
- the same business intent should resolve to a consistent outcome on replay
- retries or duplicate submissions should not create duplicate side effects
- delayed or reordered events should still satisfy your consistency rules
- acceptable drift should be explicit through a staleness budget
A fast check is to compare the first outcome with replay outcomes for the same intent. If outcomes change for the same intent, treat it as a go-live blocker.
Inject the failures production actually produces. Build the test matrix around common failure conditions, not lab-only edge cases:
- retries after partial failure
- duplicate submits for the same intent, including near-simultaneous submits
- delayed or reordered async delivery
- traffic bursts or partition-like conditions that expose drift
For each case, keep one validation evidence pack across tests, metrics, and runbooks. This catches the common gap where API behavior looks stable but runtime behavior still diverges.
Verify operational outputs, not only API responses. Do not stop at the API surface. A retry-safe API can still fail operationally if retries create duplicate outcomes or drift that breaks downstream matching in accounting flows.
Focus on stability: one intent should map to one consistent record set across attempts. If accounting sync is in scope for rollout, validate those assumptions in your own integration and process; one example workflow is Xero + Global Payouts: How to Sync International Contractor Payments into Your Accounting System.
Publish go-live criteria before adding endpoints. Make go-live criteria explicit and enforce them:
| Area | Required pass signal | Blocker signal |
|---|---|---|
| Replay contract | Same intent replay remains consistent with declared invariants | Replay outcome changes across retries |
| Duplicate handling | Duplicate submissions/redelivery do not create extra side effects | Extra side effects appear after retries/redelivery |
| Ordering resilience | Delayed/reordered events stay within invariants and staleness budget | Reordering causes invariant violations or unbounded drift |
| Validation coverage | Tests, metrics, and runbooks detect and explain failures | Failures occur without reliable detection or diagnosis |
| Burst/partial-failure behavior | Consistency holds during traffic bursts and partial failures | Bursts/partial failures create inconsistent behavior |
If any row fails, pause rollout to additional endpoints, fix that invariant, and rerun the same matrix before scaling volume. For teams running large payout batches, Bulk Payment Processing Platforms for Thousands of Payouts covers batch execution in more detail.
Turn your go-live matrix into concrete integration tests and operational checks with Gruv API docs.
Common mistakes and how to recover without data drift#
A common way to create drift is to patch retries while leaving idempotency gaps in place. Recover from stored outcomes instead of re-running side effects.
When Idempotency-Key scope is too broad or too narrow. If the same key maps to different business intent, reject it as misuse rather than guessing. If retries miss the original operation, tighten scope boundaries and enforce payload consistency so one key always means one intent. For historical collisions, avoid executing ambiguous retries as if they were new intent.
When replay returns a different HTTP result than the first response. A different replay body means your replay contract is broken. Persist one canonical completion envelope for completed requests and make that stored envelope the replay source. Do not rebuild replay responses from current mutable state.
When the API is idempotent, but queue consumers are not. Stable edge behavior does not protect you if redelivery or restart still triggers duplicate side effects downstream. Add consumer-side dedupe and gate execution with explicit lifecycle state, for example received and in-progress, to block concurrent duplicates.
When vendor examples are treated as plug-and-play. Vendor patterns help, but they do not encode your exact flow. Validate examples against your own path: where intent is created, where concurrency appears, where delivery can repeat, and where replay rules are enforced. Reliability comes from storage semantics, locking behavior, and replay rules across the full money path, not header parsing alone.
Related reading: How Payment Platforms Should Structure Affiliate Payouts.
Final takeaway and launch checklist#
Preventing duplicate charges and payouts is a contract, not a header toggle. Treat idempotency as one end-to-end system across HTTP handlers, async workers, message queue consumers, webhook receivers, and reconciliation, with proof that one intent produces one financial outcome.
Launch on the highest-risk write paths first. Start with the writes where duplicate effects cost the most, especially money movement and ledger-impacting operations. Because POST is not idempotent by default, design for the common failure case: the first request succeeds, the response is lost, and the retry arrives.
Before rollout, define Idempotency-Key scope per endpoint, including what counts as a true retry versus a new intent. Then verify that the same key executes once and retries return the stored result from durable records, not a fresh financial write.
Prove replay correctness and concurrency control. Next, prove that the replay contract survives concurrency. Define replay behavior for the HTTP outcomes you support, then verify concurrency controls in both app workers and message queue consumers. Duplicate requests can come from client retries, queue redelivery, and webhook delivery retries.
Use an idempotency store that keeps the key and response fields with creation metadata. If the same key can return a different status or body, or if downstream consumers can still post duplicate ledger journal entries, treat that as a launch blocker.
Expand only when operations can verify end-to-end outcomes. Expand coverage in controlled waves only after replay and concurrency are stable on the first paths. For the flows you support, confirm finance traceability end to end.
The go-live check is practical: can you trace a payout from onboarding approval to settlement, then back to ledger and reporting records without manual reconstruction? Pause expansion if queues, returns, or ledger breaks get worse.
Copy and use this launch checklist.
-
Idempotency-Keyscope rules defined per endpoint - Replay contract documented for all target
HTTPoutcomes - Concurrency controls active in app workers and
message queueconsumers -
webhookdedupe verified against duplicate delivery tests - Checks for duplicate
ledger/ledger journalpostings are in place and passing - Reconciliation outputs validated for finance tooling and payout operations
If every line is backed by observed evidence, you can scale safely without creating hidden duplicate-payment cleanup later.
If you want a design review for payout idempotency, replay semantics, and reconciliation controls in your target markets, contact Gruv.
Frequently Asked Questions
How do `Idempotency-Key` values prevent both duplicate charges and duplicate payouts in practice?
A request key gives each mutating call one stable identity. When that same key is retried, the API should return the previously stored outcome instead of running the money movement again. This protects you when retries come from multiple directions, such as user re-submits plus backend retries; the same pattern can also reduce duplicate payout effects when the payout flow enforces the same key-and-replay contract.
What should an API return on a retry with the same key when the first attempt already succeeded?
Return the stored result from the first completed attempt. In practice, that means replaying the cached status and body, and ideally the same full HTTP response envelope. The test is consistency: same key, same response, one financial outcome.
What should an API return when the first attempt is still in an unknown or processing state?
Do not treat the retry as a new permission to execute the financial write again. Return a consistent response tied to that same key until the original attempt resolves. In distributed systems, uncertain state is normal, so the retry contract should keep callers anchored to the in-flight operation.
Is idempotency enough on its own, or do we still need `message queue` controls and `circuit breaker` policies?
Idempotency is necessary, but not sufficient on its own. It handles request identity at the API edge, while queue redelivery and downstream retries still need queue-level controls. Circuit breaker policy details are architecture-specific and are not defined by idempotency alone. For related failure patterns, see How to Implement Circuit Breakers in Payment APIs: Preventing Cascade Failures.
What are the most common implementation mistakes that still lead to duplicates?
A common failure is not honoring replay behavior: the same key should return the same stored outcome, not trigger a second execution. Another frequent gap is making only the edge API idempotent while downstream retry paths can still execute duplicates. These issues can reintroduce duplicate effects even when the header exists.
Where should we store replay records so finance and engineering can both audit outcomes from request to `ledger journal`?
At minimum, store enough prior result data to replay identical responses for repeated keys (status and body, and ideally the full HTTP response). Cache-only retention windows (for example, 24 h) can be useful for retries, but they are implementation choices rather than a universal requirement. How that maps into finance audit trails, including ledger journal links, depends on your system design.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
Includes 3 external sources outside the trusted-domain allowlist.
- fincen.gov/report-foreign-bank-and-financial-accountstrusted
- irs.gov/individuals/international-taxpayers/foreign-...trusted
- irs.gov/individuals/international-taxpayers/figuring...trusted
- roc.cs.berkeley.edu/papers/brown-dissertation-TR.pdftrusted
- sites.cc.gatech.edu/systems/papers/HotOS8.pdftrusted
- blog.bytedoodle.com/idempotency-in-distributed-transaction-systemsexternal
- codingdroplets.com/idempotency-keys-in-aspnet-core-preventing-d...external
- dataopsschool.com/blog/idempotencyexternal
Educational content only. Not legal, tax, or financial advice.
Related Posts

The Freelance Payment Penalty: A Modeled Audit of Platform Fees, FX Spreads, and Payout Delays
The money rarely disappears through a single, easy-to-spot fee. The real loss is stacked. A marketplace takes its commission, a processor adds a charge for international cards, a bank or payment company converts the currency at a spread, a platform holds the funds before release, and a wire sheds a little to intermediaries on the way in. Each layer looks defensible on its own, but the worker feels the combined result as a smaller deposit and a later payday.

How to Respond to a Subpoena for Business Records
Move fast, but do not produce records on instinct. If you need to **respond to a subpoena for business records**, your immediate job is to control deadlines, preserve records, and make any later production defensible.

A US Expat's Guide to Investing in UCITS ETFs to Avoid PFIC Issues
The real problem is a two-system conflict. U.S. tax treatment can punish the wrong fund choice, while local product-access constraints can block the funds you want to buy in the first place. For **us expat ucits etfs**, the practical question is not "Which product is best?" It is "What can I access, report, and keep doing every year without guessing?" Use this four-part filter before any trade: