
Quick Answer
In 2026, finance leaders are using AI mainly for controlled, reviewable tasks rather than finance-wide automation. Most teams are still experimenting or running limited production, so the practical focus is on approved narrative drafting, reporting analysis, accounts payable support, contract validation, reconciliation support, and tentative forecasting, with human approval, traceable source data, and rollback paths before scaling across countries or core close processes.
Where AI Is Proving Useful for Finance Teams#
AI is a priority for finance in 2026, but most teams are still in early-stage adoption rather than finance-wide deployment. The gap is straightforward. Interest is high, pilots are common, and production discipline is often limited, especially in multi-country operations with sensitive data and money movement.
Start from the actual gap.
If you run a platform, separate demand from readiness first. Deloitte's Q4 2025 CFO Signals release on 13 Jan 2026 says 87% of CFOs expect AI to be extremely or very important to finance operations in 2026. It also says 50% of North American CFOs rank digital transformation of finance as their top priority.
Execution still trails that intent. EY's December 2025 roundtable findings show 78% are still experimenting, 22% have AI in production in one to three finance processes, and 0% are scaling AI across finance. EY also captures the mood directly: finance teams are cautious. Gartner points to the same pattern. Many AI pilots never reach production or fail to scale. For finance leaders, that pilot-to-production gap is the operating problem.
Choose for control, not demo quality.
This guide is for that gap. It is not trying to persuade you to use AI. It is meant to help you decide where AI belongs, in what order, and under which controls, so a pilot can survive close, audit, approvals, and country rollout.
Every recommendation ties to a verification point. Before a use case moves past testing, you should be able to name four things: the source data it relies on, the human owner approving the output, the system of record confirming what happened, and the rollback path if quality drops. If you cannot name those four items, treat the use case as exploration, not production.
Use the same standard for evidence. Directional signals help with prioritization, but decision-grade choices need more than broad market claims. A finance AI proposal should include a compact evidence pack: the task changing, the data touched, the control checks required, and what failure looks like in practice. "Faster board narrative drafting" and "fewer reconciliation exceptions" should not be judged the same way.
Limit scope to finance decisions that match market reality.
Keep the scope on finance leadership decisions, not generic productivity tips. The useful questions are shaped by market constraints, data control, compliance expectations, and money movement operations.
That framing lines up with current guidance. OECD guidance on AI in finance emphasizes quality data, sound governance, privacy, and ethics before broader deployment. Gartner highlights four fundamentals: model governance, value maintenance, data management, and skills development. Those are operating conditions for usable output, not abstract principles.
For platform finance teams, cross-border expansion raises the bar. The Bank for International Settlements notes there is no single, complete international standard for cross-border payment services, so jurisdictions apply different approaches. That is why this guide treats market rollout as an upfront operating constraint, not a legal step bolted on later. If compliance coverage or document handling is unclear in a target market, keep AI in analysis support and require human approval for execution decisions.
The rest of this article follows that sequence. Choose the right AI layer, put minimum controls in place, rank use cases by risk and impact, and scale only where the evidence holds.
What the 2026 evidence says before you pick any tool#
Use 2026 evidence in two tiers: directional signals for priority, and decision-grade evidence for buying and rollout decisions. Across these primary sources, the pattern is similar: interest is high, but production maturity is uneven.
Anchor on primary evidence first.
Start with the original report or release page. CFO Connect's State of AI in Finance 2025, published March 20, 2025, gives a clear baseline: 85% of CFOs see value in AI, but 39% have implemented it. The same source points to practical blockers: time, skills, and clear ROI.
That is an execution constraint, not just a tooling gap. Before you use any claim, confirm that you can see the original source page, publication date, and exact wording.
Treat sentiment as directional, not operating proof.
Deloitte CFO Signals is useful for direction. Its Q4 2025 release says 87% of surveyed North American CFOs expect AI to be extremely or very important to finance operations in 2026. Deloitte describes CFO Signals as a quarterly barometer of sentiment and forward-looking strategy.
That is useful direction, not proof of scaled operations. Deloitte Finance Trends 2026 reports 63% fully deployed AI solutions and 14% fully integrated AI agents. Do not compare those figures directly with CFO Connect or EY without aligning scope, definitions, and sampling.
Mark unknowns before tool shortlisting.
The public CFO Connect State of AI in Finance 2026 landing page is useful context, but the visible copy does not provide methodology or sample metrics. Treat it as a pointer, not decision-grade evidence.
EY's roundtable framing helps explain why some pilots stall before core adoption. "I'd be surprised if anyone in finance is mature in AI - we're a cautious group." That caution, plus weak short-term ROI in some cases, is why you should not treat repeated search-result claims as settled fact.
Before you shortlist tools, capture four fields for each claim: original source URL, publication date, geography, and whether it reflects sentiment, experimentation, or live operational use. For related benchmark context, see State of Subscriptions 2026 Benchmarks for Platform Operators.
Choose the right AI layer for each finance job#
Pick the AI layer by error cost and traceability, not by demo quality. General assistants can fit low-risk narrative work. Finance specialist and ERP-native tools can fit work that needs traceability to source records.
Sort the job by traceability before vendors.
Start with a simple question: can a reviewer trace this answer to a named source? EY reports that 78% of CFOs are still experimenting through proofs of concept, so narrow, reviewable use cases are still a practical starting point.
Before testing tools, define three fields for each job: source of truth, reviewer, and failure cost. If the source is an approved deck, policy file, or exported report, a general assistant can fit. If the source is live transaction data, close status, or reconciliation evidence, start with tighter controls and clearer audit paths.
Match the job to the lane.
| Lane | Typical tools | Good first-fit jobs | What a CFO can verify | Main tradeoff | Do not start here |
|---|---|---|---|---|---|
| General assistants | ChatGPT Enterprise, Microsoft Copilot | Memo drafts, policy summaries, meeting prep, first-pass commentary on approved extracts | OpenAI says business data is not used for training by default. Microsoft says Copilot prompts, responses, and Graph data are not used to train foundation models, and Copilot inherits permissions, labels, retention, and supports audit. | Fast to pilot for broad teams, but quality and traceability depend on source-pack discipline. | Close judgments, journal support, or reconciliation decisions that cannot be traced to source records |
| Finance specialists | Numeric, Drivetrain, Dust | Close workflows, variance explanation, planning across ERP and adjacent systems, governed agent workflows | Numeric says it pulls every ERP transaction line. Drivetrain markets connectors and APIs across ERP, CRM, HRIS, databases, warehouses, Sheets, and 800+ systems. Dust positions governed agents and says customer data is never used to train models. | Finance-oriented workflows, with integration and ownership effort that varies by implementation. Mapping and connector hygiene drive quality. | Use cases where mappings, dimensions, or connected sources are still unstable |
| ERP-native | Oracle NetSuite | Reconciliation support, period-end close controls, transaction-history checks in ERP | NetSuite says close tasks can be accelerated with automation and embedded controls. NetSuite Transaction Audit Trail shows transaction history, including who changed a transaction and when. | Strong ERP-native traceability, but narrower coverage for cross-functional analysis outside ERP. Releases are on a twice-a-year cadence. | Cross-functional summaries that require CRM, HRIS, or warehouse data outside ERP |
Apply explicit decision rules.
If the task is narrative-heavy and low-risk, consider starting with ChatGPT Enterprise or Copilot in Microsoft 365-heavy environments. Keep a reviewable record of the prompt run.
If the task affects close or reconciliation decisions, consider specialist or ERP-native control paths such as Numeric or Oracle NetSuite, and require reviewer checks back to source records.
If the task spans ERP, CRM, HRIS, warehouse, and spreadsheet data, evaluate a specialist lane such as Drivetrain instead of forcing ERP-only coverage. If your need is governed multi-agent orchestration across internal knowledge and tools, Dust may be a better fit.
Use one reproducible review test before scaling.
Before you scale anything, ask one question: can a second reviewer reproduce the output from the same inputs? For narrative work, retain the prompt, attached files, version date, and reviewer notes. For close-related work, require at least one spot check back to a transaction line, reconciliation item, or NetSuite audit-trail entry.
If an answer cannot be traced to a source record, do not put that use case into production. Related: How Finance Can Future-Proof for a Recession: A Platform CFO's Resilience Playbook.
Prepare the prerequisites before your first production use case#
Before you move a finance AI use case into production, make sure a written control pack exists and named owners have signed it. A practical minimum package is an owner map, approval gates, a data-handling policy, and a rollback path.
Map ownership before you test output quality.
Ownership comes first. If no one can tell you who approves, who handles exceptions, and who can shut the use case off, output quality does not matter yet. NIST's AI governance guidance is clear that roles and communication lines should be clear, and that executive leadership is responsible for AI deployment risk decisions.
Your minimum owner map should name:
- a finance owner for business accuracy
- an ops owner for process execution
- a product or technical owner for tool behavior and access
- an executive approver, typically the CFO or delegate, for go-live and rollback
Use one practical check: can a second reviewer tell, from the document alone, who approves normal cases, who handles exceptions, and who disables the use case if quality drops? If not, keep it in pilot mode.
Define approval gates and rollback before launch.
Set approval logic before production. Ramp's control-first framing is useful here: approve when safe, escalate when not. At minimum, define:
- one condition where the tool can assist without extra signoff
- one condition where output must escalate to a human reviewer
- one rollback trigger
- one manual fallback process
- one evidence pack to reconstruct prior decisions
NIST also calls for safe decommissioning and phase-out processes, so rollback cannot stay implicit.
Lock data boundaries before scope expansion.
Your data policy should be tighter than technical access. The data minimisation standard is a strong operating rule: keep processing limited to what is necessary for the stated purpose.
For a first production use case, define:
- allowed files and fields
- retention boundaries
- disallowed sensitive data categories for that workflow
Spendesk's 12 March 2026 guidance supports starting with process mapping, pain-point identification, and data assessment. The practical warning is the same: avoid over-broad first deployments.
Run market-readiness checks for cross-border work.
For finance teams expanding across countries, readiness checks should be jurisdiction-specific. Stripe states that country requirements differ for payouts and also warns that Stripe verification does not replace your own independent legal KYC obligations.
Before you launch, include a country-by-country check for payout readiness, required identity evidence, and document-review ownership. If the workflow touches cross-border payment messaging, assess FATF Recommendation 16 requirements, including the USD/EUR 1,000 peer-to-peer cross-border threshold context. If U.S.-source payments to foreign persons are in scope, assess whether NRA withholding may apply at the default 30% rate and whether documentation (such as W-8BEN) is needed for your process.
Set one hard internal gate for your program: no production use case moves forward until finance, ops, and product owners sign off on controls, country assumptions, and rollback steps. This helps avoid preventable rework after launch.
For a practical next step on invoice workflows, see How to Make the Case for AP Automation to Your CFO: A Platform Finance Team Playbook.
Prioritize use cases with a risk-to-impact sequence#
Sequence use cases by control strength and business impact, not by demo quality. Gartner's warning is practical: opportunistic AI pilot selection in finance can drive inconsistent outcomes, so use a simple portfolio method that ranks value, feasibility, and scalability.
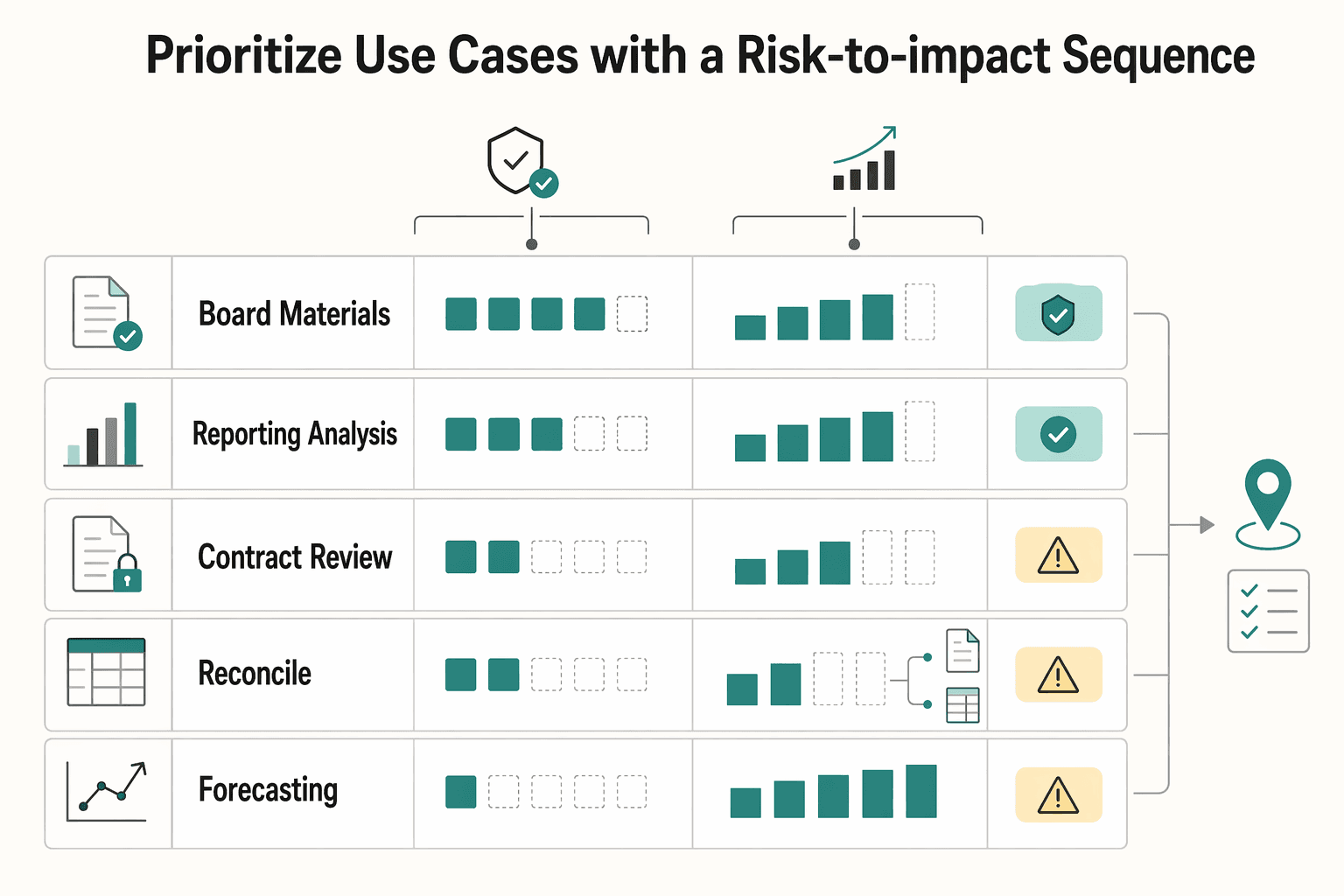
Score the portfolio before approving builds.
Score each candidate from 1 to 5 across four factors: business impact, error cost, data sensitivity, and integration load with Oracle NetSuite or adjacent finance tools. For first production releases, favor meaningful impact with lower error cost and lighter integration. Keep high-impact, high-risk items queued for a later wave unless they address core data quality.
| Use case | Business impact | Error cost | Data sensitivity | Integration load | Starting recommendation |
|---|---|---|---|---|---|
| Board materials | 3 | 3 | 3 | 2 | Good quick win if inputs already come from approved reporting packs |
| Reporting analysis | 4 | 3 | 3 | 3 | Strong first-wave candidate when source reports are stable |
| Contract review | 3 | 4 | 4 | 2 | Keep human approval in place; use for review support, not final judgment |
| Reconciliation | 5 | 5 | 4 | 4 | Structural win; prioritize early to improve downstream trust |
| Forecasting | 5 | 4 | 4 | 4 | High value; promote when actuals and variance data are dependable |
This keeps you from polishing presentation before you improve the underlying finance truth.
Separate quick wins from structural wins.
Run one quick win and one structural win in your first set. Quick wins can cover summarizing or analyzing approved data, often board materials and reporting analysis. Structural wins improve record quality and confidence in the numbers, with reconciliation as the clearest example.
Microsoft's finance scenarios include budgeting, forecasting, and financial analysis, but those scenarios are demonstrative and still require your own fit check against business process, regulatory needs, and responsible-AI controls. Oracle NetSuite's February 11, 2026 announcement grouped AI across close, reconciliation, and narrative workflows, and tied close monitoring to data integrity. A practical sequence is to strengthen the record first, then scale narrative automation where controls hold.
Use an internal gate for forecasting narratives.
If reconciliation quality is unstable, keep forecasting narratives in assist mode. Forecasting is a valid use case, but polished narrative on weak actuals can create false confidence.
Before promoting forecast narrative automation, verify that key inputs reconcile across core source systems and that variance explanations trace to approved data. If that checkpoint fails:
- strengthen close and reconciliation inputs first, including Numeric close workflows and Drivetrain NetSuite-connected budget-versus-actual and budget-versus-forecast inputs
- keep forecast commentary draft-only until reviewers can map each statement to reconciled source packs
Require a clear reviewer evidence pack.
Promote a use case only when a reviewer can quickly inspect the evidence behind suspect output. If you cannot name that evidence in one sentence, the use case is not ready.
The pack should be explicit by workflow. For board and reporting tasks, keep approved variance reports and exports. For contract review, keep clause source, redline history, and the named approver. For forecasting, keep actuals extracts, the approved planning version, and reconciliation exceptions together. To move beyond pilot mode, pick fewer use cases, score them rigorously, and sequence them so confidence in numbers rises before confidence in prose.
Set country and compliance constraints before scaling#
Country rollout is an operating constraint, not a later legal cleanup. Finance is not working from one global rulebook, and FATF is explicit that countries have different legal, administrative, and operational frameworks. The same AI-assisted finance task will not have the same compliance shape in every market.
Treat each country as its own approval decision.
Make rollout decisions market by market before scaling any workflow. Use a simple matrix: country, money movement involved, customer type, tax-document path, and named compliance reviewer.
Use FATF status as a risk input, not a shortcut. The 13 February 2026 update confirms that jurisdictions under increased monitoring have committed to resolve strategic deficiencies. FATF also states this status does not automatically require enhanced due diligence. Apply a risk-based approach, not automatic approval or automatic rejection.
Verification point: for each country, a reviewer can name the exact evidence pack for onboarding, payment, or tax handling in one sentence.
Map vendor privacy controls to finance-data handling.
Treat enterprise AI privacy controls as necessary but not sufficient. For Microsoft 365 Copilot, verify the documented boundary that prompts, responses, and Microsoft Graph data are not used to train foundation LLMs.
For Gemini in Google Workspace, verify the parallel boundary that content is not human reviewed or used for model training outside your domain without permission. Then confirm the admin retention setting. Google states prompts and responses can be retained from 90 days to indefinite, and that setting affects auditability and sensitive-data exposure.
The standard is simple: vendor controls must match your own access controls, retention choice, and reviewer approval step.
Verify the cross-border evidence pack before automation touches decisions.
Use a minimum pack across markets, then add country-specific items:
- KYC: if your operation is a covered financial institution, confirm written procedures to identify and verify beneficial owners of legal entity customers under 31 CFR 1010.230. Use AI for organization and gap detection, not final verification.
- AML: check current FATF country status and record the reviewer's risk rationale.
- Tax documents: confirm CRS self-certification captures all tax residencies, track IRS Form W-8 validity through the last day of the third succeeding calendar year, and handle applicable backup withholding at 24 percent in applicable situations.
- Audit trail: retain prompt, source document name or ID, reviewer, approval timestamp, and final action.
Limit unclear markets to analysis support.
If local compliance coverage is unclear, limit AI to analysis support and keep execution decisions human-approved. Use AI to summarize documents, flag missing beneficial-owner fields, compare tax-residency statements, and draft reviewer questions, but keep onboarding approvals, tax-status changes, and fund-release decisions with human approvers.
That boundary lets you move faster across countries without pretending unresolved compliance work is complete.
Connect AI decisions to the money lifecycle and ledger truth#
Once country controls are set, anchor AI to money events, not above them. Approve AI use only where you can check outputs against a payment record, payout artifact, or ledger entry your ops team can pull on demand.
Map your real money flow before adding AI.
Start with your actual operating sequence, for example: collect, hold, convert where needed, pay out, then reconcile. Use this as a working map, not a universal template, so finance can see exactly where value changes hands and where proof is required.
For each stage, name the source of truth first:
- collect: payment request, authorization, or transaction event
- hold: platform or provider balance state
- convert: FX conversion event or balance change by currency
- pay out: payout object, bank transfer, or settlement event
- reconcile: report, export, API record, and ledger posting
Verification point: your team can identify one export or API object for each stage.
Use AI at specific review decisions.
Use AI where humans already review exceptions, summaries, or mismatches. It can classify payout breaks, draft reserve-change explanations, compare transaction batches to expected settlement totals, and flag missing data before close, but it should not be the only explanation for cash movement.
Payout review is a practical example. Stripe exposes concrete touchpoints in the Dashboard, downloadable payout reconciliation reports, and the API. In Stripe, each funds movement in or out of your account creates a BalanceTransaction. Keep AI outputs tied to those records, not free-form text.
If you use multi-currency settlement, add an explicit check for whether the balance was accrued in the original currency or converted before payout.
Require rerunnable evidence for every AI-assisted decision.
Tie each AI output to artifacts your ops team can reproduce. Oracle describes a multi-day path from checkout to settlement to payout and points finance to verifiable touchpoints in reporting, exports, and BI API access, so your review should follow those artifacts, not the assistant interface.
A minimum evidence pack includes source export name, report date, payout or transaction ID, reviewer, approval timestamp, and final ledger action. If the result cannot be recreated from the same export tomorrow, it is not ready for production.
Avoid demo logic that skips ledger proof.
Fast demos can hide control gaps. OpenAI states model outputs can be incorrect or misleading, so treat generated finance text as draft support for review, not as ledger truth.
If you use manual payouts, keep tighter controls because reconciliation responsibility sits with the operator. Limit AI to exception triage and explanation drafting until you can verify the chain from transaction event to payout record to ledger entry. In early launches, remember Stripe may schedule the initial payout in about 7 to 14 days after the first successful live payment.
Related reading: Real-Time Reporting Metrics Platform Finance Teams Can Actually Control.
Execute a 30 90 365 rollout with pass fail checkpoints#
Once AI is tied to ledger-verifiable decisions, the next risk is scaling on enthusiasm instead of evidence. Treat 30, 90, and 365 days as stage gates with pass/fail checks, not maturity labels. That matters in 2026 because signals are mixed. EY reports many finance teams are still experimenting, while Deloitte reports broader deployment in its surveyed sample. Your rollout should move only when your own controls and outcomes hold.
Set a 30 day gate around one controlled use case.
Use the State of AI in Finance 2026 material as high-level context, not as a rollout template. In the first 30 days, run one finance task with clear source data and an existing human approver, such as payout exception triage, reconciliation commentary, or forecast variance summaries.
| Phase | Required outcome | Pass checks | No go trigger |
|---|---|---|---|
| 30 days | One controlled use case in live review | Source data is stable, approval path is followed, evidence pack is rerunnable from the same export | Source records are missing or inconsistent, approval is bypassed, result is not reproducible |
| 90 days | Cross-functional adoption in the same use case family | Finance, ops, and data owners use the same rules, governance controls are active, benefit is visible in close or planning work | Hand-offs break, policy exceptions grow, teams disagree on what "approved" means |
| 365 days | Embedded in a core finance activity | Process is part of normal close or planning cadence, ownership is named, control reviews continue | Usage stays ad hoc, output still needs heavy manual rework, no owner can defend the process |
Your 30-day pass check is simple: can the team rerun the result tomorrow from the same export, report date, and approval log? If not, stop. EY states that effective data management is a prerequisite, so unstable report logic or changing field definitions are launch blockers, not cleanup items.
Expand to 90 days only after leadership and controls align.
At 90 days, the goal is not more prompts. It is repeatable, cross-functional execution for a finance decision. Finance, operations, and the data or admin owner should follow the same approval path and evidence standard.
Make one leadership go or no-go check explicit. Gartner reports only 46% of CFOs have had explicit conversations with finance leadership about AI ambition. If that conversation has not happened, do not widen scope.
Use approval adherence as the operating proof point. Microsoft guidance emphasizes governance, management, and security operations, and calls out approvals and DLP controls during rollout. In practice, you should be able to show who approved output, where that approval happened, and whether sensitive finance data stayed in approved environments.
Earn the 365 day embed with measurable finance improvement.
A 365-day target is earned only when AI is part of a core close or planning activity and the finance team can show measurable improvement. Keep the measure concrete: shorter review time, fewer reconciliation exceptions carried forward, faster variance analysis, or a cleaner planning cycle.
Add a resourcing checkpoint before expanding scope. Name the operational owner, approval owner, and data upkeep owner before adding countries, entities, or use cases. COSO's warning is direct: rapid AI adoption without robust internal controls can undermine reporting and compliance integrity. If ownership is still "shared," treat it as a no-go for expansion.
Common mistakes that keep finance teams stuck in pilot mode#
Teams get stuck in pilot mode when they scale before they prove control. Treat these as stop signs, not cleanup items.
Reconcile AI output to source records before anyone acts on it.
Do not treat ChatGPT output as decision-ready just because it sounds plausible. OpenAI says it can produce incorrect answers and recommends accuracy checks, so the minimum bar is traceability to the same export, report date, and transaction set your team would use without AI.
For close and cash work, verify against the ledger or reconciliation system, not memory. In Oracle NetSuite, Intelligent Transaction Matching uses rules to match imported lines to transactions, with manual exception handling when records do not align. Use that pattern: match, review exceptions, approve. If output cannot be traced to source records, it is commentary, not evidence.
Choose for control fit, not demo quality.
A strong demo is not enough if you cannot explain data boundaries, approvals, and prompt and response handling. During selection, ask a blunt question: what control do we gain or lose by using this product for this finance task?
Microsoft documents that prompts, responses, and Microsoft Graph data in Copilot are not used to train foundation models, and Enterprise Data Protection applies contractual protections to prompts and responses. Google's enterprise guidance makes the same governance point: evaluating infrastructure, data governance, and security controls for sensitive data is mandatory. If those answers are unclear, do not buy on polish.
Align country policy gates before cross-border rollout.
A use case that works in one country is not automatically ready for several. FATF says implementation should be adapted to each country's legal and operational context, and EU rules require safeguards when personal data is transferred outside the EEA.
Before rollout, document the approved data path, local owner, approval step, and any required transfer safeguard or policy note for each country set. One common failure mode is standardizing the process first, then discovering that documentation and data-handling requirements diverge by market.
Measure operational change, not activity.
Adoption metrics alone do not prove value. EY reports many finance teams are still in early-stage experimentation, so usage counts by themselves are weak evidence of progress.
Track outcome measures tied to core finance work: faster review cycles, fewer reconciliation exceptions carried forward, or less manual rework in variance analysis. Microsoft's business-impact reporting is explicitly framed around linking usage to business outcomes. If you cannot show before-and-after change in a controlled finance task, you are still in pilot mode.
How to recover when a pilot fails quality or control checks#
When a pilot fails, pause expansion and run a controlled recovery cycle. First identify whether the failure came from data quality, governance and process, or tooling controls, then retest at a smaller scope with clear evidence.
Classify the failure before you touch the tool.
Start by classifying the failure. Use three triage buckets as a working model, not a universal standard.
- Data issue: source data was stale, incomplete, or mis-mapped.
- Process/governance issue: approvals were skipped, reviewers acted on draft output, or exception ownership was unclear.
- Tooling/infrastructure issue: the product could not stay within your control boundary, lacked usable logs, or produced output that could not be traced to source material.
Before you rerun, confirm you can show the dataset, report date, prompt or request, reviewer, and approval action for the failed cycle.
Contain scope and tighten approvals.
Do not widen the retry on the first pass. Rerun with a smaller blast radius: one team, one report, one country, or one decision type. Keep the real finance task, but remove cross-entity and multi-path complexity.
At the same time, require named reviewer approval before output is shared outside finance or used in an operating decision. Define one measurable outcome and one control checkpoint so pass or fail stays clear.
For Microsoft Copilot, confirm auditing is enabled so interactions are logged. For Gemini Enterprise, confirm admins can query Gemini log events before rerun. If the interaction trail is missing, post-failure review is harder to verify.
Rebuild the evidence pack.
Rebuild evidence from scratch, not memory. Include the source export, report timestamp, prompt or task instruction, raw output, reviewer comments, approval record, and final disposition: accepted, corrected, or rejected.
Document the assumed data-use boundary as well. Microsoft states Copilot prompts, responses, and Microsoft Graph-accessed data are not used to train foundation models. Google states Gemini enterprise content stays within the organization and is not used for model training outside the domain without permission.
Keep quality review and privacy review separate so each failure stays diagnosable.
Rerun small, then apply a decision rule.
Rerun only the narrowed use case and test it against the same checkpoint that failed. Treat this as an iterative risk process across the lifecycle: govern, map, measure, and manage.
Set an internal stop rule to prevent forced rollout. Example: if the same checkpoint fails in two consecutive cycles, pause expansion and re-rank the use case. This is an internal discipline choice, not an industry mandate.
Record the rollback so the next review is factual.
Document each rollback so another team can review it without a meeting: what failed, what was rolled back, who approved the pause, what controls were added, and what must be true before retest.
That record keeps communication with finance, product, and compliance grounded in evidence instead of opinion.
For a step-by-step walkthrough, see IndieHacker Platform Guide: How to Add Revenue Share Payments Without a Finance Team.
Copy and paste checklist for the next finance AI decision cycle#
If your team cannot complete all four lines before launch, pause the cycle. This checklist keeps decisions tied to evidence, tool fit, and controls instead of momentum.
Confirm evidence quality.
Paste this into the decision doc: Known facts come from CFO Connect directional evidence plus internal source data; unknowns are listed explicitly. CFO Connect's published 2025 page shows a pilot-to-implementation gap, with 85% seeing value and 39% reporting implementation. That is useful context, but not proof for your specific workflow.
Verification check: attach the internal export, report date, owner, and unresolved assumptions. If a claim depends on "the model will infer it," keep it in unknowns.
Confirm tool fit.
Paste this line: Selected lane: ChatGPT Enterprise, Numeric, Drivetrain, or Oracle NetSuite, with tradeoffs stated. Then document why this lane fits the task and what you give up versus the other options.
Use product claims as fit signals, not universal rankings. ChatGPT Enterprise states business data is not used for model training by default and supports SAML SSO. Numeric emphasizes timestamped audit trail records for close work. Drivetrain describes NetSuite integration for consolidated reporting and real-time variance tracking. NetSuite documentation highlights Audit Trail visibility into who changed what and when.
Confirm controls before launch.
Paste this line: Owner, approval path, audit trail, and recovery trigger are defined before launch. Name the operator, reviewer, approver, and the system log you will use for review.
Set one recovery trigger before you start. Example: if the same control checkpoint fails twice, pause expansion and rerank the use case.
Confirm success criteria.
Paste this line: One business metric and one control metric are approved by the CFO. Treat this as an operating rule, not an industry standard, to keep scope and accountability clear.
Make both metrics specific before launch. Business metric examples: forecast cycle time, reporting turnaround, variance review throughput. Control metric examples: approval adherence, audit-trail completeness, or share of outputs reconciled to source records.
For a broader operating model view, read Lean Finance and the Modern CFO: How Payment Platform Leaders Evolve from Cost Center to Strategic Driver.
Before the next planning cycle, align your owner map, approval gates, and reconciliation checkpoints against the implementation surfaces in the Gruv docs.
Conclusion#
The practical move is not broad AI adoption. It is controlled adoption tied to measurable finance outcomes, risk constraints, and governance. Current evidence supports that stance: in BCG's survey of over 280 finance executives, median ROI was 10%, and only 45% could quantify ROI.
Use fewer use cases and scale them in sequence with strict checkpoints. Set pass-or-fail criteria before spend increases, tied to measurable business outcomes and governance controls. That matches the pattern across BCG, Gartner, and Deloitte: stronger results come from focused choices, explicit success conditions, and measurable outcomes, not adoption breadth.
Expand only after early controls and outcomes are demonstrated. WEF's framing is practical here: responsible AI investment can build confidence, but cybersecurity, regulatory, and workforce risks remain part of the operating reality. The next step is simple: run one constrained decision cycle this quarter, document the baseline and results, and expand only where the evidence is clear.
If you want to validate market coverage and control requirements before scaling, talk with Gruv.
Frequently Asked Questions
How are finance leaders using AI in 2026 in day-to-day operations?
Day-to-day use is concentrated in targeted automation, analytics, and risk management rather than broad transformation. Early production work includes accounts payable support, contract validation, internal chatbots, approved narrative drafting, reporting analysis, and tentative forecasting. These use cases still need human review and traceable source data.
What is the biggest blocker for CFO adoption right now?
The biggest blocker is turning pilot interest into a finance-grade business case that can survive control, cybersecurity, and regulatory review. Many teams are still experimenting, and weak short-term ROI can block approval. If ownership, evidence, and rollback steps are unclear, the use case is not ready for production.
Which AI tools are finance teams actually using most often?
There is no supported global winner by product name. The article groups tools into general assistants, finance specialists, and ERP-native tools, and says teams should choose by job fit, traceability, data boundaries, and audit needs. If a tool cannot show clear data-use terms and verified feature availability, it should not be treated as production-ready.
What does moving beyond pilot mode look like in measurable terms?
A practical sign is live production use in one to three finance processes rather than only proofs of concept. Beyond usage counts, the article looks for named ownership, approval adherence, rerunnable evidence packs, and outputs that trace back to source records. If the result cannot be reproduced from the same export or record set, it is still pilot work.
What should a 30 90 365 rollout include for finance teams?
At 30 days, run one controlled use case with stable source data, an existing human approver, and a rerunnable evidence pack. At 90 days, expand only if finance, ops, and data owners follow the same approval path and controls under real volume. By 365 days, the use case should be embedded in close, reporting, or planning with named ownership, ongoing control reviews, and measurable finance improvement.
Which finance processes should be automated first and which should wait?
Start with repetitive, document-heavy, reviewable tasks such as accounts payable support, contract validation, approved reporting analysis, board materials, internal finance chatbots, and tentative forecasting. Reconciliation is a structural win worth prioritizing early, but only with tight controls and source-record checks. Forecast narratives and other higher-risk decisions should stay in assist mode until data quality, approvals, and reconciliation inputs are dependable.
How should platform CFOs evaluate AI tools across different markets?
Begin with contractual and admin controls, then confirm regional availability before rollout. Privacy controls are necessary but not sufficient, so platform CFOs should also verify retention settings, access boundaries, approval steps, and whether the workflow fits each country's payout, tax-document, and compliance requirements. Keep a verification pack with contract terms, admin settings, region checks, and the named reviewer for each market.
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
- airc.nist.gov/airmf-resources/playbook/governtrusted
- airc.nist.gov/airmf-resources/airmf/5-sec-coretrusted
- bis.org/fsi/fsisummaries/exsum_23901.htmtrusted
- ecfr.gov/current/title-31/subtitle-B/chapter-X/part-1...trusted
- irs.gov/individuals/international-taxpayers/nra-with...trusted
- irs.gov/forms-pubs/about-form-w-8-bentrusted
- nist.gov/itl/ai-risk-management-frameworktrusted
- oecd.org/en/topics/sub-issues/digital-finance/artific...trusted
Educational content only. Not legal, tax, or financial advice.
Related Posts

The Freelance Payment Penalty: A Modeled Audit of Platform Fees, FX Spreads, and Payout Delays
The money rarely disappears through a single, easy-to-spot fee. The real loss is stacked. A marketplace takes its commission, a processor adds a charge for international cards, a bank or payment company converts the currency at a spread, a platform holds the funds before release, and a wire sheds a little to intermediaries on the way in. Each layer looks defensible on its own, but the worker feels the combined result as a smaller deposit and a later payday.

How to Respond to a Subpoena for Business Records
Move fast, but do not produce records on instinct. If you need to **respond to a subpoena for business records**, your immediate job is to control deadlines, preserve records, and make any later production defensible.

A US Expat's Guide to Investing in UCITS ETFs to Avoid PFIC Issues
The real problem is a two-system conflict. U.S. tax treatment can punish the wrong fund choice, while local product-access constraints can block the funds you want to buy in the first place. For **us expat ucits etfs**, the practical question is not "Which product is best?" It is "What can I access, report, and keep doing every year without guessing?" Use this four-part filter before any trade: