
Quick Answer
Start by defining real-time reporting platform finance metrics as controls, not dashboard KPIs: give each metric a responsible owner, intervention trigger, and first-response task. Track four latency clocks (event, ledger posting, reconciliation, and payout status), then block high-impact automation when freshness fields are missing. Run release checks in sequence: collection state, ledger posting, settlement confirmation, then compliance gate.
Real-time reporting is a control problem, not a dashboard problem#
Treat real-time reporting as an internal control problem, not a dashboard shopping project. For platform finance teams, the goal is timely control over reporting quality and payment operations. You need issues detected, routed, and acted on before they turn into misstatements or payment errors.
Internal control is a management process tied to operations, reporting, and compliance objectives. In practice, a metric matters only if it helps your team detect a problem in time, route it through clear reporting lines, and start remediation with assigned authority.
Build for action, not visibility#
This article focuses on a control-room metric set where each metric has:
- An owner for first-response accountability
- A trigger that defines when to intervene
- A first action that starts diagnosis or containment
If one of those is missing, the metric usually adds visibility without adding control.
Timeliness is the standard#
Timeliness is the control test. A control deficiency exists when design or operation does not allow timely prevention or detection of misstatements, so "we saw it later" is not enough. Before you act on a metric, confirm the feed is current and complete enough for the decision. If not, treat it as low confidence and escalate through established lines.
Scope matters#
The examples here assume platform finance teams operating across payout rails and programs where rail and institution coverage can vary by setup.
When U.S. rails are referenced, treat them as examples, not defaults. FedNow is a U.S. instant payments service for depository institutions and is designed for 24x7x365 processing. Participant coverage still needs to be verified because the Federal Reserve list is updated irregularly and is not fully complete at any given time, including the file posted as of 3/23/26. RTP is also U.S.-specific, and institution participation still must be confirmed even though eligibility is broad.
Use that as a working rule throughout the article. Do not standardize thresholds, payout promises, or escalation paths until rail availability, institution support, and program constraints are confirmed for your operating footprint.
If you want a deeper dive, read Real-Time Payment Use Cases for Gig Platforms: When Instant Actually Matters.
Define real-time in platform finance terms#
In platform finance, "real-time" should mean control, not just fast display. Real-time visibility is rapid status updates. Real-time controllability is your ability to intervene before ledger drift, reconciliation failures, or payout issues compound.
Define four latency clocks up front, and assign a timestamp to each in your data model:
| Latency clock | Definition |
|---|---|
| Event latency | When the business event occurred vs when your platform received it |
| Ledger posting latency | When the event reached the ledger and posted to the correct accounts |
| Reconciliation latency | When internal and external records were matched and confirmed equal |
| Payout status latency | When rail or provider status changed vs when your team saw that change |
These clocks often do not move together. FedNow is described as near real-time and designed for 24x7x365 processing, and RTP is described as always-on with final and irrevocable settlement for credit transfers. That still does not mean your internal payout status is current, and a posted payout status does not always mean funds are already available to the recipient.
Keep the ledger as your financial source of truth. It supports statutory reporting. BI tools like Power BI and Tableau are operational reporting surfaces. Power BI dashboard tiles are snapshots, and Tableau can cache query results. Tableau Cloud refreshes cached data every 12 hours by default, so a dashboard can look current while reconciliation or settlement operations are stale.
Before acting on a dashboard, verify four fields: source update time, ledger posted-at time, last successful reconciliation run, and latest payout-status timestamp by rail. If any is missing, treat the view as low confidence and avoid automated decisions until that clock is explained.
Related: FedNow vs. RTP: What Real-Time Payment Rails Mean for Gig Platforms and Contractor Payouts.
Build the minimum metric stack by workflow#
Start with a small control stack tied to intervention, not a broad dashboard. If a metric has no named owner, trigger, and first action, keep it in background reporting rather than your control room.
Payment operations often span multiple systems and teams, which makes ownerless metrics easy to ignore. One survey reports that 49% of companies use five or more systems to manage payments, and 13% use ten or more.
| Workflow stage | Must-have metric | Trigger condition | Owner | First action |
|---|---|---|---|---|
| Ledger integrity | Out-of-balance amount and unposted event count | Any unexplained mismatch between business-event totals and posted ledger totals, or missing posted-at timestamps | Accounting ops or ledger owner | Stop reliance on the affected slice, inspect posting queue and journal entries, isolate duplicate or missing events |
| Reconciliation health | Unreconciled item count and time since last successful reconciliation | Last successful run is missing or stale, or unmatched items start accumulating | Reconciliation lead | Match internal ledger or ERP records to bank statement activity, then bucket breaks into missing, duplicate, or amount mismatch |
| Settlement variance | Expected vs actual money movement | Expected settlement from internal records does not match actual deposit or bank movement | Treasury or settlements owner | Verify provider settlement file, bank activity, and timing assumptions before releasing dependent actions |
| Payout execution | Success rate, failure rate, and return rate by rail/provider/code | Failure or return patterns worsen, or API/webhook status updates stall | Payments ops | Split failures by rail, provider, and code; pause blind retries and inspect newest failures first |
| Exception management | Exception queue aging and backlog growth | Items exceed your internal SLA or queue growth outpaces clearance | Ops manager | Triage oldest and highest-value items, assign owners, and escalate clustered blockers |
| Cash position | Available cash vs scheduled payout obligations | Cash on hand or expected inflows no longer cover planned disbursements | Treasury or finance ops | Recheck same-day obligations, confirm inbound collections and settlement timing, and sequence releases accordingly |
What each metric is protecting#
Each metric protects a different control point. Ledger integrity checks whether events became correct accounting entries. Reconciliation health checks whether internal records match external sources of truth. Settlement variance checks whether expected money movement became actual money movement. Payout execution checks whether disbursement paths are operating. Exception aging checks whether breaks are clearing. Cash position checks whether you can keep paying.
Do not collapse these into one "payments healthy" score. A platform can show strong payout success while reconciliation is stale, settlement files are incomplete, or exceptions are aging in queue.
Cash reconciliation is a core checkpoint. Compare expected money movement from internal ledger or ERP records with actual bank movement. If that match fails, lower confidence in downstream payout and reporting decisions until the gap is explained. At scale, the standard is whether you can account for every dollar at any point in time.
GAAP evidence is not the same as triage evidence#
Use two evidence layers because they solve different problems. For GAAP reporting, support needs to hold up for recognition, measurement, presentation, and disclosure. In U.S. reporting, the FASB Accounting Standards Codification is the authoritative nongovernmental GAAP source, so the evidence behind a metric should trace to accounting records, not just dashboard views.
For operator triage, you need evidence current enough to act on: API or webhook timestamps, bank statement lines, and latest reconciliation results. For GAAP support, keep a durable package: journal entries, reconciliation output, settlement files or bank confirmations, and a reproducible export explaining the amount.
Dashboard screenshots can help detect issues, but they are not sufficient evidence on their own. Use dashboards for detection. Use ledger records, bank matches, and reconciliation artifacts for substantiation.
Where NRR and DSO help, and where they do not#
NRR and DSO help with executive context, not payout control. Net Revenue Retention measures recurring revenue retained from existing customers over a period, including expansion and churn effects, so it belongs in executive and investor reporting. It does not directly show whether today's payouts posted correctly, whether a return file landed, or whether settlement matched expectation.
Days Sales Outstanding measures average collection time after credit sales. It can matter for liquidity planning when receivables timing affects available cash. But DSO is a collections metric, not a payout-control metric, and it does not directly surface stale status feeds, unmatched deposits, or ledger posting failures in real time.
Keep NRR and DSO in executive reporting and cash-planning context. For daily payout operations, prioritize reconciliation health, settlement variance, and cash position.
Design the control-room dashboard your team can run daily#
Run one control room with three role-specific views, not one blended dashboard. Finance close, intraday payout operations, and incident command need different latency assumptions, evidence, and next actions.
A blended board makes it easy to miss root cause. Ops can see failures rising while finance is looking at older reconciled totals, and no one notices a stale source feed.
Separate the views by decision type#
Use each view for a distinct decision:
| View | Decision type | Primary focus |
|---|---|---|
| Finance close view | Finance close | Prioritize ledger integrity, reconciliation status, settlement variance, and evidence availability |
| Intraday operations view | Intraday payout operations | Prioritize payout success and failure rates, returns, queue aging, and source freshness so operators can answer what is breaking now and what to handle first |
| Incident commander view | Incident command | Prioritize cross-system status, blast radius, top failure codes, retry state, and oldest unresolved exceptions to isolate whether the break is in ingestion, posting, reconciliation, provider status, or reporting |
Put freshness and completeness on the face of the dashboard#
Show freshness by source system on the same tiles as the metrics it affects. A generic "last updated" stamp is not enough.
For each source, display:
- Last source event time
- Last successful ingest or refresh time
- Completeness status for required fields, for example non-null coverage
Use source-specific mechanics where available:
Dynamics 365: entity-store refresh options includeEvery hour,Twice a day,Once a day, andOnce a week.QuickBooks OnlineandXero: webhook events are useful change indicators, but not a guaranteed freshness SLA.BigQuery: streaming supports minimal-latency reads; committed streams with offsets support exactly-once write patterns.
Set an explicit operating rule: if freshness is unknown, treat metric confidence as low and require manual verification before high-impact automated escalation. Continue manual triage while source timeliness is being verified.
Build the exception panel for bottlenecks, not volume vanity#
The exception panel should show where work is stuck, not just how much failed. Include aging, top failure codes, retry state, and owner or queue segment.
Group failure codes into action-oriented buckets. Decline codes and related failure categories help teams separate issuer declines, blocked payments, invalid requests, and other status issues so they can reroute, fix data, or stop retries.
Retry state is mandatory context. Fifty first-attempt items are not the same as 50 items cycling repeatedly without new evidence. If you use Amazon SQS, metrics like ApproximateAgeOfOldestMessage directly support queue-aging visibility.
| Dashboard component | Power BI | Tableau | Google Looker Studio | OneStream |
|---|---|---|---|---|
| Intraday ops view | Strong for ops dashboards, but "real-time" is near real-time with latency; Microsoft recommends Fabric Real-Time Intelligence for new streaming scenarios, with real-time streaming sunsetting beginning October 31, 2024 | Good fit for interactive ops views; workbook-level freshness policy is available, and Tableau Cloud cache refresh is 12 hours by default unless changed | Good for lightweight operational views; most source types support freshness settings, but extracted sources do not and need scheduled auto-update | Better when the view depends on governed finance data and structured components, not fast-changing stream behavior |
| Per-view freshness handling | Works well when source timestamps are exposed in the model | Strong workbook-level freshness control | Usable for many live sources; extracted sources do not have a normal freshness option | No supported evidence here for native per-widget freshness indicators, so surface freshness from source metadata |
| Exception monitoring | Supports queue and failure-code panels when modeled well | Presents queue aging and code splits clearly | Works for simpler monitoring; watch extract limits and schedules | Better for controlled finance review than live queue triage |
| Close and certification view | Works if audit evidence is maintained outside the dashboard | Works for review with deliberate freshness policy settings | Better for lighter reporting than governed close | Strong fit for close-oriented views: component-based dashboards plus workflow support for quality and audited data collection |
Choose tools based on fit, not labels. Tableau gives explicit workbook-level freshness control. Looker Studio can work, but extracted sources require scheduled updates and cap at 750,000 rows. OneStream is a strong fit for certification and audited collection. Power BI remains broadly useful, but avoid designs that depend on retired streaming assumptions.
Set incident tiers and trigger rules before failures happen#
Set incident tiers before the next spike, then tie each tier to financial risk, customer impact, a named owner, an escalation channel, and a response clock your team can actually meet.
Do not start with generic Sev1/Sev2 labels. Start with the impact dimensions that matter in finance ops: payout execution impairment, confidence in reporting or ledger integrity, and recoverability without manual intervention. That keeps thresholds tied to your own rails and operating tolerance.
What each tier needs#
For every tier, lock these fields now so nobody invents process during an incident:
- Trigger condition: exact metric move or event state that opens the incident, for example a burst of failed payouts or a material jump in settlement lag.
- Owner: one accountable responder plus backup coverage.
- Escalation channel: who gets notified, and in what order.
- Response SLA: time to acknowledge and time to first containment action.
- First evidence pack: provider reference, payout event payload, ledger posting ID, settlement status, and source freshness stamp.
Dashboards are only the surface. Responders still need transaction-level evidence to separate provider failure, destination-data issues, and potentially stale upstream feeds.
Use decision rules as house rules, not universal truths#
Use practical rules, but treat them as team-tested starting points. One useful house rule is this: if payout failures rise while settlement lag is stable, check routing, destination data, and rail execution first. If failures and settlement lag rise together, widen triage to ingestion, posting, or reconciliation breaks.
Validate quickly. Sample recent failed items, confirm explicit failure events, and compare settlement timestamps with ledger postings. If failures cluster by provider or return reason, routing or destination data is a reasonable first lane. If failures cut across providers and ledger movement is stale or missing, treat it as a broader pipeline risk candidate.
Timing windows matter too. FedNow uses a 20-second timeout clock, and a receiver institution can reserve up to five seconds. Requests sitting well beyond those windows without a final state should be treated as potential intervene-now signals and checked against provider-specific behavior.
Match first actions to failure shape#
First actions should contain harm. Typical options are pausing payouts, routing to a backup path where supported, or holding payout release for policy checks. These are not universal defaults across all providers.
Put destination-data validation near the top of the tree for returned or failed payouts. Incorrect destination information is a common return cause, and returned payouts are typically back in 2-3 business days, sometimes longer. Also, do not close on posted status alone. Posted can still require monitoring before recipient funds are actually available.
Draw a hard line between monitor and intervene#
Write the monitor-versus-intervene boundary in plain language. Ops should know when to keep watching and when to stop normal payout actions. Finance should know when noise is contained versus when ledger confidence, settlement timing, or reporting trust is at risk.
A practical boundary:
- Monitor when volume is low, source freshness is verified, and failures are isolated with known causes.
- Intervene now when freshness is uncertain, failures are spreading, settlement movement is affected, or you must pause payouts or change routing.
If your program has formal notice obligations, define those clocks and owners in advance. In some regulated contexts, notification starts within 1 hour of identification and updates continue at least once per calendar day until recovery.
Handle reconciliation breaks with explicit failure taxonomy#
Use a fixed failure taxonomy so reconciliation breaks are fast to classify and fast to triage. If everything is labeled as a generic recon issue, teams lose time, retry the wrong action, and weaken reporting trust. A practical approach is to define repeatable buckets, then assign one detecting metric and one first artifact for each.
Treat this six-bucket set as a house taxonomy, not a universal standard: missing event, duplicate event, amount mismatch, stale status, unmatched deposit, and policy-gated hold.
| Failure bucket | First detecting metric | First artifact to inspect | What usually goes wrong first |
|---|---|---|---|
| Missing event | Event arrival gap or expected-to-received count variance | Webhook trace or provider event log for the provider reference | Upstream event never arrived, arrived late, or was filtered out |
| Duplicate event | Duplicate event ID count or repeat processing attempts on the same object | Processed event IDs log | A retry replays the same event and triggers second handling |
| Amount mismatch | Reconciliation exception count for amount variance | Journal entry and provider settlement/export amount | Reference matches, but amount is outside tolerance |
| Stale status | Aging count of items stuck in pending/open state | Provider status payload, such as RTP pacs.002 or FedNow status request/response messages | Status stops advancing while lifecycle activity continues |
| Unmatched deposit | Unmatched bank statement or settlement line count | Bank statement line and settlement export pack | Funds arrive but cannot be matched to an application transaction |
| Policy-gated hold | Hold queue volume or payout-enabled failure count | Account verification record or hold reason code | Payout is blocked by missing capability or verification information |
Start with the artifact that can disprove your first guess#
Start with the artifact most likely to falsify your first assumption. For unmatched deposit, begin with the bank or settlement line because reconciliation exceptions occur when auto-match cannot find an application transaction for a bank statement line. For amount mismatch, compare the journal entry to the provider export early because amount variance is a defined reconciliation exception category.
For stale status, do not rely on dashboard labels alone. Check the status artifact directly, pacs.002 on RTP or the status request/response flow for pending FedNow items, before deciding whether to wait, retry, or intervene.
Treat duplicate handling as an idempotency control check#
Duplicate webhook events are expected, so duplicate does not mean ignore. It means verify replay safety.
Check the processed event ID and, where applicable, the idempotency key used for the original action. Same-key retries should return the same result, including errors, instead of causing duplicate side effects. A common break is provider-safe retry behavior paired with non-idempotent internal posting logic.
Connect break handling to reporting trust#
For teams tracking real-time reporting metrics in platform finance, reconciliation break rate and time-to-resolution can serve as practical operational warning signals. Rising break volume can indicate declining match confidence. Slower recovery, often tracked with MTTR, can mean exceptions are aging into close risk.
This is a controls problem, not just an ops problem. Internal controls support reliable reporting and timely error detection, and faster reconciliation helps teams correct errors earlier. If you tighten only one control this quarter, tighten the first-artifact rule for each bucket.
Run settlement and payout checkpoints in order#
Run payout release as a gated sequence for your program, not a speed race: verify collection state, validate ledger posting, confirm settlement state, then run the compliance gate before release.
Use a fixed release sequence#
Payout scheduling is not proof of funds readiness. It controls when you attempt payout, not when pending funds become available, and some programs require your balance to cover payout total and fees before initiation.
| Checkpoint | What you verify | If it fails | First artifact |
|---|---|---|---|
| Collection state | Funds are collected or available for the program | Stop payout initiation | Funding balance view, collection reference, or provider balance record |
| Ledger posting | Collection posted once to the correct account and amount | Hold release and fix ledger drift | Journal entry, posting timestamp, idempotency key |
| Settlement state | Payment/transfer reached settled state | Keep item in pending queue | Rail status response, settlement export, or transaction-level settlement report |
| Compliance gate and payout release | No sanctions, policy, or account-verification block before execution | Record a formal hold or rejection | Hold reason code, case record, reviewer, disposition |
Before any outbound release, confirm the ledger entry exists, the amount matches, and replay handling did not create a duplicate posting.
Treat FedNow, RTP, and async status feeds differently#
Use rail-specific evidence at the settlement checkpoint. FedNow runs 24x7x365 and still provides end-of-day balances on Federal Reserve accounting records, which is a practical signoff anchor. RTP settlement is final and irrevocable, with recipients receiving payment within seconds, so a correctly settled RTP item should not be handled as reversible pending.
Do not assume network maximums are your operating limits. FedNow has participant-configurable limits, with a $100,000 default and higher maximum settings where enabled. RTP's network limit increase to $10 million does not remove participant-level variation.
For asynchronous provider updates, treat silence as unknown. Webhook events can be resent for up to three days. Process replayed events chronologically and keep duplicate prevention active so replays do not create second ledger movements or second payouts.
Log compliance blocks as finance evidence#
A blocked or rejected payout can be a reporting event, not just an ops note. Store a structured hold record with reference number, account number, amount, date, customer or counterparty identifier, reason code, reviewer, and disposition so finance and audit teams can trace the decision path.
Where U.S. sanctions blocking rules apply, initial reports can be due within 10 business days, so unresolved holds should be aged against a deadline.
Run two cadences on purpose#
Use intraday checkpoints for incident-prone queues: pending settlement, webhook retry backlog, stale statuses, and policy-gated holds. Then run a separate end-of-day signoff against settlement and reconciliation artifacts, including rail outputs and transaction-level settlement reports tying settled items to payouts.
If an item has not passed settlement confirmation by cutoff, keep it on hold, log the reason, and release it in the next confirmed cycle.
If you are formalizing checkpoint order, retry rules, and provider routing, map this sequence to your execution flow in Gruv Payouts.
Protect auditability with governed data lineage#
If a payout, balance, or exception metric cannot be traced end to end, it is not ready for finance signoff. Set a minimum standard: every reported number should resolve through a clear evidence chain from the originating request to the exact export that was reviewed.
Build the five-link chain first#
Use one chain across teams and tools: request -> provider reference -> ledger posting -> reporting model -> export artifact.
| Chain link | Kept evidence or mapping |
|---|---|
| Request | Provider request identifier tied to the transaction action |
| Provider reference | Provider funds-movement record linked to the same transaction key; status-change event evidence on the same key |
| Ledger posting | Journal entry, posting timestamp, account, and amount |
| Reporting model | Ledgered data tied to the reporting model that produced the metric |
| Export artifact | Reviewed export with version and date context |
At the request layer, keep the provider request identifier tied to the transaction action, and keep the provider funds-movement record linked to the same transaction key. When status changes arrive asynchronously, keep that event evidence on the same key as well. The first checkpoint is simple: from a dashboard row, can you reach the original request and provider-side movement without guesswork?
Next, anchor that provider reference to the exact ledger posting: journal entry, posting timestamp, account, and amount. If that mapping is weak, duplicate handling, reversals, and late corrections become hard to defend.
Then tie ledgered data to the reporting model that produced the metric, and finally to the export artifact used in review. Keep the reviewed export with version and date context, not just a dashboard view.
Do not confuse tool visibility with governed lineage#
"Single source of truth" positioning is not the same as governed lineage. A unified platform can help, but auditability still depends on controls and retained evidence.
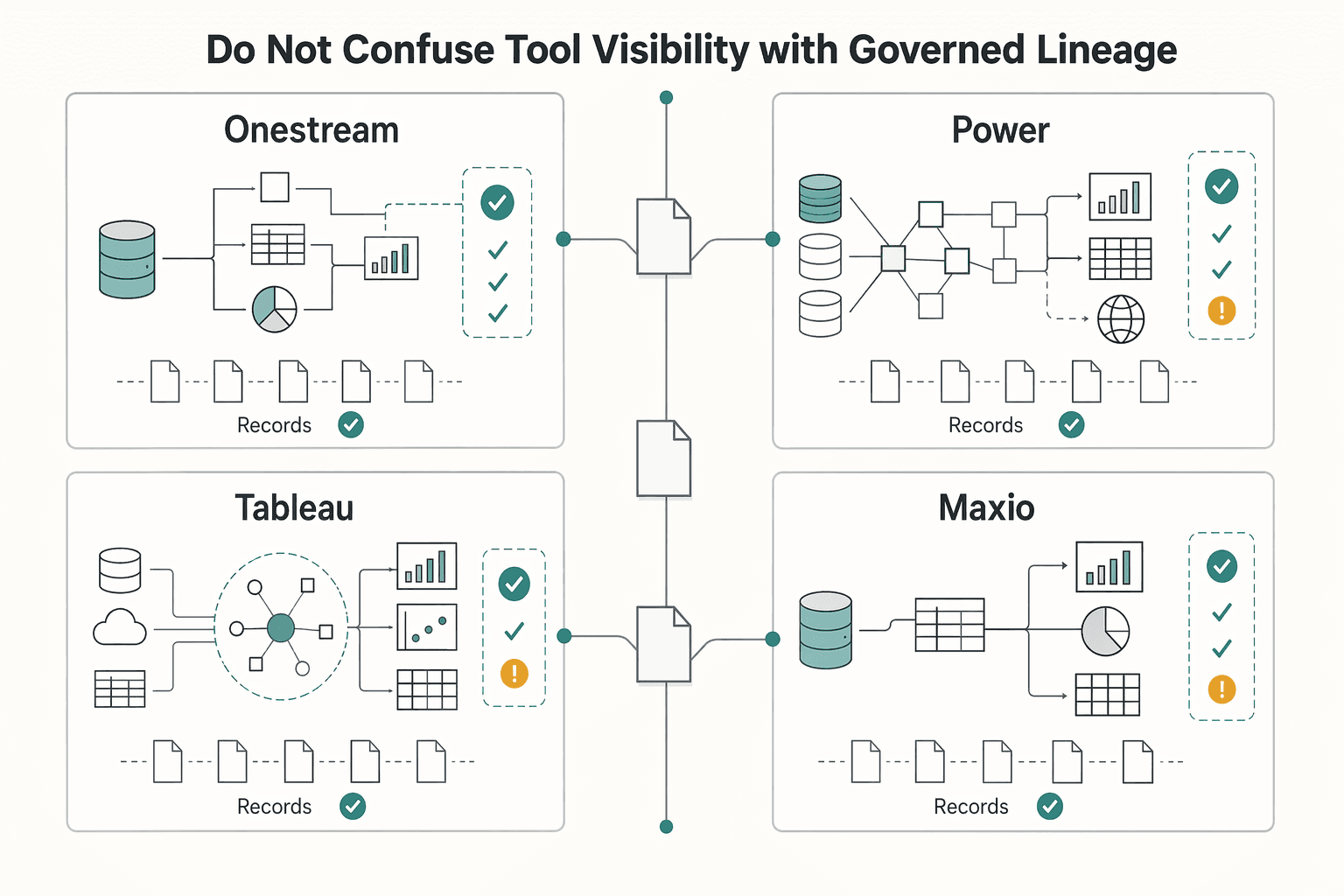
Power BI and Tableau make that distinction clear. Power BI lineage view shows relationships across workspace artifacts and external dependencies, and Tableau lineage shows upstream and downstream dependencies around a selected lineage anchor. That is useful for impact analysis, but not enough to prove review, approval, or reproducible exports.
| Tool | What it can show or export | What you still need to govern |
|---|---|---|
| OneStream | Unified finance and operational data environment | Ownership, change approval, and evidence of reviewed outputs |
| Power BI | Lineage across artifacts and external dependencies | Metric definition control, access control, and retained export packs |
| Tableau | Dependency tracing around a selected asset | Clear asset ownership, revision discipline, and review evidence |
| Maxio | CSV exports of Subscription, Customer, and Transaction data; reports used to verify GL amounts | Mapping from operational exports to ledger and approved reporting logic |
Maxio is a good example. Exportable data and GL-verification reporting support audits only when you preserve the exact export and document how it ties back to accounting.
Add the controls ICFR and SOX reviews typically test#
For ICFR, the standard is a supervised process designed to provide reasonable assurance over reliable financial reporting. For teams preparing for SOX in SEC-reporting contexts, prioritize four controls:
- Change logs for model logic, source mappings, calculations, and access changes.
- Named ownership and review evidence for each metric, model, and export.
- Override approvals for manual edits, forced reclasses, and signoff exceptions.
- Reproducible exports and retention so the same source slice and logic can be regenerated later, with records preserved for required retention periods.
Use a simple rule: if someone can change a reported number without a change record, reviewer, and retained artifact, keep it out of finance signoff. Speed only helps if the evidence trail survives inspection.
You might also find this useful: ICFR (Internal Control Over Financial Reporting) for Platforms: SOX Compliance Without a Big Finance Team.
Choose tooling by operating constraints, not marketing claims#
Choose the stack based on time-to-detect and time-to-resolution requirements, not just time-to-visualization.
A lower-cost BI layer can still be viable if you build reconciliation, lineage, and exception controls outside the dashboard layer. For example, Google Looker Studio is positioned as a no-cost option, but freshness is connector-dependent. Pro auto refresh is disabled by default, reload intervals are every 5, 10, 15, or 30 minutes, and extracted data sources cap at 750,000 rows.
| Tool | Grounded strength | What to verify before finance signoff |
|---|---|---|
| Power BI | Scheduled refresh is license-dependent: Pro is up to 8 refreshes/day, with higher-tier capacity up to 48 | Does refresh cadence match your incident window, and could inactivity pause scheduled refresh after two months? |
| Tableau | Extract refresh can be scheduled; on-prem and WDC extract refresh is managed via Tableau Bridge | Can your team operate Bridge reliably, and is refresh priority configured correctly in queueing? |
| Google Looker Studio | Connector-level freshness controls, scheduled PDF delivery, optional Pro auto refresh | Is auto refresh enabled where needed, and are extracted sources hitting truncation limits? |
| OneStream | Audit logs can retain source spreadsheet copies; security audit reports are exportable | Can reviewers retrieve the exact reviewed artifact without manual reconstruction? |
For integration breadth, vendor claims are directional. Klipfolio advertises 100+ connectors. Lucid Financials cites QuickBooks, Xero, and payroll integrations. Maxio states integration with critical cash-to-revenue systems. Docyt says key statements update in real time. HubiFi markets audit-trail and lineage coverage from report to record. Treat those as starting points, not proof of exception-handling depth.
Use one practical test in vendor review: ask for a live walkthrough of a failed refresh, a broken reconciliation item, and the retained export pack used for review. If ownership, retry state, and evidence retention are unclear in that workflow, the tool may improve visibility while slowing resolution.
Execute a 90-day rollout with measurable checkpoints#
Use 90 days as an operating cadence if it fits your program, not a compliance standard. Move only when each phase has a clear exit test.
Phase 1#
Baseline the current profile before designing the target profile. Document the outcomes you achieve today: feed timeliness, recurring exceptions, unassigned break age, and what evidence you can export when finance asks what happened.
Lock metric definitions early. For each metric, record owner, trigger, first action, source system, and freshness expectation so different teams get the same count from the same data.
Treat freshness as timeliness plus completeness, not timestamp alone. Check last successful load time, expected load interval, record counts, and obvious integrity breaks.
Phase 2#
Launch the minimum operating view for incident handling, not the full reporting vision. Start with source freshness, break queue volume, aging, failure categories, retry state, and hold or exception queues so teams can triage and escalate quickly.
Define incident tiers before enabling alerts. The flow should be consistent every time: triage and validate, categorize and prioritize, then escalate when criteria are met. A simple severity model is enough if it is repeatable.
Run dry runs on historical incidents or through a tabletop exercise. Use cases like a failed refresh, reconciliation mismatch, and backlog in held items help here. Confirm the team can answer: who owns it, what evidence proves it, what action happens first, and who is notified next.
Phase 3#
Harden production by tuning alerts for actionability. If no one can act when an alert fires, remove it or downgrade it to monitoring to avoid alert fatigue.
Run escalation drills after tuning. Validate clean handoffs, clear incident explanations, and evidence-pack export without manual reconstruction, for example source timestamp, reference IDs, status, owner, and export time.
Include control reviews in the rollout rhythm. Monthly reviews can work operationally, but keep quarter-end and fiscal-year-end control evaluation as the timing anchors when ownership, control logic, or evidence retention changes.
Operator checklist#
- Freshness verified, including completeness checks by source
- Break queue triaged and validated
- Aged items assigned to a named owner
- Material holds or exceptions explained with a reason finance can review
- Evidence pack exportable without manual stitching
Confirm country and program constraints before standardizing metrics#
Do not standardize operating thresholds across countries or programs by default. Standardize metric names globally, then localize trigger points, actions, and escalation thresholds before rollout.
Rail coverage is the first place global assumptions fail. FedNow and RTP are U.S.-scoped payment infrastructures, and SEPA scope is framed by countries and legal framework, with scheme-specific behavior for SEPA Instant. Keep dashboard wording explicit: "where supported," "when enabled," and "coverage varies by market/program."
Compliance gates also vary by program. Requirements can differ across flows, and legal-entity onboarding can require beneficial-owner identification at account opening. If policy gates can hold or delay payout, include that in the metric definition and exception taxonomy, and do not copy payout-release SLAs or auto-escalation thresholds across programs without signoff.
Retention and reporting obligations are also local. EU DAC7 sets annual seller-reporting duties to a Member State tax authority, and cross-border platform reporting depends on partner-jurisdiction participation and exchange arrangements. In the U.S., BSA recordkeeping generally requires many records to be retained for at least five years, and those duties can stack with other laws. GDPR-style storage limitation requires personal data to be kept no longer than necessary for its purpose, so one global retention window is a risk.
Before you change any metric, alert, or evidence export, run a formal verification step:
- Confirm rail availability assumptions for the target market.
- Confirm policy gates and reporting obligations with legal and compliance owners.
- Confirm retention handling for the evidence pack and any control-relevant exports.
If any answer is unclear, standardize the metric name only and keep the local threshold unchanged.
Build for controllability first and visibility second#
Build control before coverage. The useful version of real-time reporting metrics in platform finance is not the one with the most charts. It is the one where each metric has a trigger, a named owner, and a first action that starts when the trigger is hit.
Teams often stop at visibility. A dashboard can look current while reconciliation is stale, incomplete, or blocked by unresolved exceptions. If a metric shows something is wrong but does not make clear who acts next and what they do first, you have monitoring, not control.
Make each metric executable#
A metric is operational when these four elements are defined:
- Trigger
The condition that matters, and how long it must persist before action.
- Owner
One role or person accountable for first response.
- First action
The first concrete check or containment step.
- Escalation path
Where it goes if first response does not clear it.
Two practical checkpoints help. First, when an alert fires, can the owner reach the exact queue, records, or evidence they need quickly? Second, before freezing retries, holding payouts, or escalating exceptions, confirm the source data is current enough to trust.
Prefer traceability over surface area#
Broad dashboard coverage helps, but traceability makes numbers defensible. Provenance and data lineage let you explain where a number came from, how it changed, and which records support it.
For teams operating with strict control expectations, the standard is not "we can see it," but "we can trace it." In practice, that means following a figure through request, provider reference, ledger posting, reporting model, and export artifact. If that chain breaks, treat the figure as low confidence until repaired.
Reconciliation controls follow the same rule: owner, aging visibility, correction deadline, and proof of resolution. Keep evidence simple and consistent: source event ID, provider reference, ledger entry ID, timestamps, retry state, reconciliation result, and manual override approval when applicable.
Test the path, not just the chart#
Tested escalation paths beat passive visibility. A clear incident response plan defines who does what, and a named incident manager keeps ownership from diffusing when multiple signals fail at once.
Next step:
- Pick your current top five failure modes from real incidents.
- For each, map the detecting metric, trigger, owner, first action, escalation path, and required evidence.
- Run one incident drill with current data, real channels, and actual owners, then fix what slowed detection, blurred ownership, or broke traceability.
When you are ready to implement this control model with API/webhook workflows and traceable records, start in the Gruv docs.
Frequently Asked Questions
Which real-time finance metrics matter most for platform operations?
Start with signals that show whether money movement and records still agree. In practice, this can include reconciliation exception volume and aging, settlement mismatches, payout success and failure behavior, payout-status latency, and ledger timeliness. Reconciliation is central because it verifies transaction accuracy and record integrity, not just reporting output.
What should be on the minimum dashboard for ledger, reconciliation, settlement, and payouts?
There is no universal minimum field list across platforms, so treat this as a design choice, not a standard template. Keep the dashboard to one-page highlights for monitoring, then use detail views for triage. A practical baseline is to make current health visible across ledger, reconciliation exceptions, settlement mismatches, payout flow, and data freshness so teams do not act on stale signals.
How should teams set thresholds that trigger immediate action versus monitoring?
Define two parameters for each alert: the violation threshold and how long the breach is allowed to persist. That separates brief noise from sustained failures that need intervention. Before escalating, confirm the underlying data feed is current enough to trust the signal.
How do we prioritize incidents when multiple metrics break at once?
Prioritize by impact and urgency, then map that to response priority. Issues that risk duplicate financial operations or record-integrity breaks should outrank slower reporting-only degradation. That keeps triage tied to operational risk, not chart volatility.
What are the most common failure patterns, and which metric catches each one first?
Timing differences, errors, and potential fraud can surface as reconciliation discrepancies. Duplicate-retry risk is why idempotent request handling matters in payment flows. With idempotency keys, repeated calls with the same key should return the same result rather than create a second operation.
Can executive metrics like NRR and DSO replace operational payout and reconciliation metrics?
No. NRR measures recurring-revenue retention in existing customers, and DSO measures how long credit sales take to convert to cash. Both are useful executive lenses, but operational payout and reconciliation controls still need their own metrics.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
- cisa.gov/federal-incident-notification-guidelinestrusted
- ecfr.gov/current/title-17/chapter-II/part-240/subpart...trusted
- ecfr.gov/current/title-31/subtitle-B/chapter-V/part-5...trusted
- fedramp.gov/docs/20x/incident-communications-procedurestrusted
- irs.gov/newsroom/irs-issues-faqs-on-form-1099-k-thre...trusted
- sec.gov/rules-regulations/2003/03/managements-report...trusted
- sec.gov/newsroom/speeches-statements/munter-statemen...trusted
Educational content only. Not legal, tax, or financial advice.
Related Posts

The Freelance Payment Penalty: A Modeled Audit of Platform Fees, FX Spreads, and Payout Delays
The money rarely disappears through a single, easy-to-spot fee. The real loss is stacked. A marketplace takes its commission, a processor adds a charge for international cards, a bank or payment company converts the currency at a spread, a platform holds the funds before release, and a wire sheds a little to intermediaries on the way in. Each layer looks defensible on its own, but the worker feels the combined result as a smaller deposit and a later payday.

How to Respond to a Subpoena for Business Records
Move fast, but do not produce records on instinct. If you need to **respond to a subpoena for business records**, your immediate job is to control deadlines, preserve records, and make any later production defensible.

A US Expat's Guide to Investing in UCITS ETFs to Avoid PFIC Issues
The real problem is a two-system conflict. U.S. tax treatment can punish the wrong fund choice, while local product-access constraints can block the funds you want to buy in the first place. For **us expat ucits etfs**, the practical question is not "Which product is best?" It is "What can I access, report, and keep doing every year without guessing?" Use this four-part filter before any trade: