
Quick Answer
For payment platforms, keep money-critical reads and writes on a relational core with ACID transactions, and scale only the paths that can tolerate delay. Use read replicas for reporting and visibility, consider sharding when write growth becomes the bottleneck, and evaluate Distributed SQL when you need SQL and ACID at higher scale without owning manual shard operations.
Why database architecture matters for payment platforms#
For platform payments, your first database decision is boundary-setting. Decide which paths in your system must stay exact and current in the relational core, and which can tolerate delay through read replicas, sharding, or distributed options. If you let money-critical reads and writes drift from the source of truth, risk rises fast.
A practical rule keeps this simple: keep transaction-critical state on a relational core, then scale non-critical access with the least risky pattern. If you own payout approvals or balance-affecting writes, you should treat database choice as a control decision before it becomes a scale decision. Database choice shapes scalability, reliability, security, and operating cost, and payment workloads make those tradeoffs harder. Relational systems remain a dependable source of truth for financial state because ACID guarantees fit multi-step updates.
- Keep money state on the relational core
Transaction records and writes that change financial state should stay on the relational core path. ACID helps prevent partial outcomes in multi-step financial updates. A practical test is simple: if stale or incorrect data here could change a money decision, keep it on the core.
- Scale reads only where stale data is acceptable
Use secondary read patterns for reporting and visibility where delayed data is acceptable. Any screen or workflow that can influence a financial action needs careful read-path validation before moving off the primary path.
- Treat sharding and distributed writes as boundary choices, not automatic upgrades
Sharding and distributed designs address scale in different ways, but they do not fix weak boundaries around transaction-critical data. They change how data is organized and operated under load. The real question is whether your correctness rules still hold after you distribute the system.
This guide is about reducing architecture debt caused by weak boundaries. Relational modeling also gives you explicit integrity links between entities, which supports transaction-critical workflows. The decision rule for the rest of the article is straightforward: start with correctness, then scale. If you are classifying a read or write that can change financial state, anchor it to the relational core path first. If it serves non-blocking reporting or visibility, that is where replicas, sharding, or distributed options belong.
Choose the architecture by risk first and scale second#
For payment systems, database choice is a risk-control decision before it is a scaling decision. If your team owns payments, onboarding, reporting, or payout infrastructure where compliance or approval gates can block or release funds, correctness and failover behavior should lead the decision.
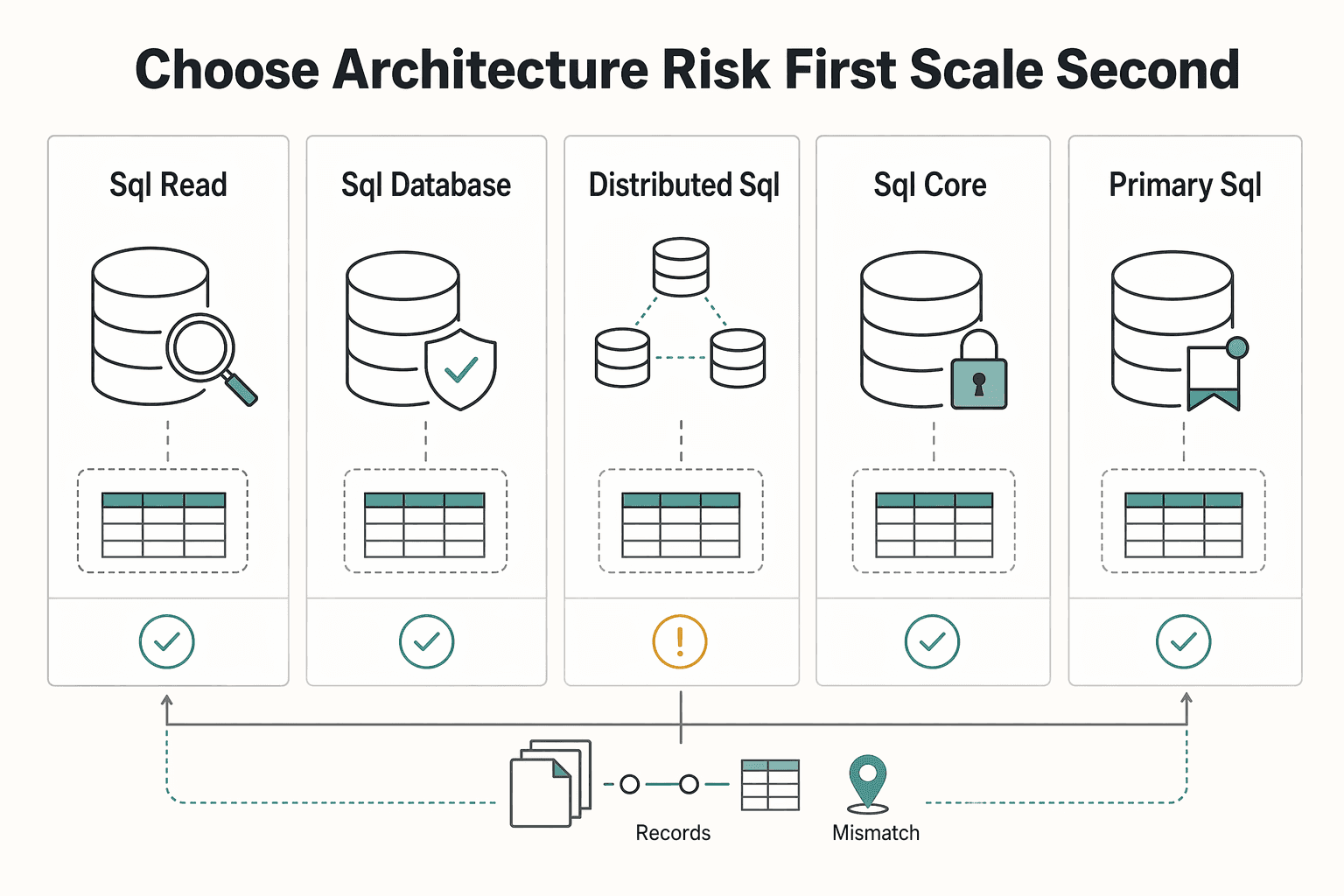
| Pattern | Best fit | Main risk |
|---|---|---|
| SQL with read replicas | One authoritative writer still handles state changes and the main pressure is rising read volume | Critical decisions can become a control problem if teams cannot prove they use authoritative state when required |
| SQL with database sharding | Read replicas are already scaling reads, but writes and data growth are still the bottleneck | Manual sharding and custom failover scripts can become operationally fragile |
| Distributed SQL | Teams need SQL and ACID transactions at higher scale across multiple machines | Distributed coordination and lock contention can add overhead when transactions span multiple machines |
| SQL core plus NoSQL projections | Keep correctness-critical records on SQL and use NoSQL for read-heavy views built around specific access patterns | System roles must stay explicit, and single-node MySQL can struggle at higher scale |
- For teams with financial-state risk
Use a relational core for balance-affecting writes, payout-state transitions, and other decision-critical paths. Structured tables plus primary and foreign keys provide explicit integrity controls, and ACID supports reliable multi-step updates. The key test is whether money-related writes still meet ACID requirements.
- Not for low-consequence apps
If stale reads or duplicate events are mostly operational noise, payout-grade controls may be unnecessary. If incorrect data can affect money movement or create audit-evidence gaps, raise the bar and treat database choice as a risk-control decision.
- Compare options in this order
Start with money-movement correctness: which reads and writes require ACID. Then separate read growth from write growth. Next, review failover behavior under stress, including dependence on custom routing or failover logic. Finally, assess operator burden, because manual sharding and custom failover scripts can become fragile.
- Use this first-pass filter
This table is for elimination, not for picking a universal winner.
| Option | Guarantees on critical paths | Operational complexity | Failure blast radius | Migration difficulty |
|---|---|---|---|---|
| Primary SQL plus read replicas | Full ACID on the primary writer; keep decision-critical transactions on the primary path | Read routing and failover procedures still need disciplined operations | Depends on replica routing and failover design | Can be incremental when a relational core already exists |
| SQL with manual sharding | Guarantees depend on sharding and routing design decisions | Manual sharding adds shard-key, routing, rebalancing, and failover overhead | Custom routing and failover logic can increase fragility | Can require application and data-model changes to become shard-aware |
| Distributed SQL | Keeps SQL semantics and ACID transactions while partitioning data horizontally; many systems use consensus replication for consistent writes and predictable failover | More partitioning and failover behavior moves into the database layer, so cluster operations and query tuning matter | Reduces app-level routing risk, but cluster behavior still matters | Requires careful migration planning and testing on critical money paths |
Before you commit, inventory every endpoint, job, and admin action that can approve, reject, hold, settle, or release funds. For each one, record the read source, write boundary, and expected audit evidence. If those are not clear, you are still optimizing for scale too early.
For a related breakdown, read FATCA and W-8 Tax Compliance for Platforms: When to Release, Hold, or Withhold Foreign Payouts.
Best for early and mid-scale platforms using SQL with read replicas#
If a single-writer SQL setup still meets your needs, keep that shape while you evaluate scaling options. It preserves familiar SQL and ACID transaction semantics and avoids introducing application-level sharding logic too early.
- Best fit
Use this pattern when one authoritative writer still handles state changes and the main pressure is rising read volume. The key check is whether your team can clearly separate correctness-critical reads from informational views and validate that split in your own environment.
- Why it works
The main advantage is operational simplicity on the write side: one transaction boundary and fewer moving parts in the application. It also buys time before harder scale choices, such as distributed SQL systems that scale horizontally without manual sharding while still presenting a single SQL interface.
- Main risk
The risk is unclear read-path governance, not the pattern itself. If teams cannot prove that critical decisions use authoritative state when required, a scale optimization can become a control problem.
- Recommended split
Keep correctness-sensitive decision flows on the authoritative data path. Use additional read capacity for informational workloads such as analytics, historical reporting, and bulk exports only after explicit risk review.
- Verification to require
Validate with real traffic, not diagrams. For high-impact endpoints and tools, document which data path they use, the impact of stale or delayed views, and the escalation or fallback procedure.
Related: ERP Integration Architecture for Payment Platforms: Webhooks APIs and Event-Driven Sync Patterns.
Best for write-heavy growth using SQL with database sharding#
Sharding is typically a next step when read replicas are already scaling reads and a single primary is still the write and data-growth bottleneck. The goal is to spread write load horizontally without giving up SQL and ACID behavior for critical state.
- Best fit
Choose this after the primary-plus-read-replica pattern has done what it can. In that shape, replicas scale reads, but writes still go to one primary, so write pressure remains concentrated. If writes and data growth are still the bottleneck, one-writer SQL is likely a scaling boundary rather than a simple tuning issue.
- Why it works
Sharding changes where writes land by distributing data across partitions instead of forcing every hot path through one primary. In distributed SQL systems, that horizontal partitioning is paired with SQL semantics and ACID transactions for critical state.
- Main risk
A major risk is operational fragility when teams depend on manual sharding and custom failover scripts.
- Recommended cut
Prefer architectures that handle horizontal partitioning and replication as built-in behavior, rather than making manual shard routing the default.
- Verification to require
Confirm read replicas are actually absorbing read load while write traffic remains concentrated on one primary, then verify failover behavior is predictable in your replication approach. Treat ad hoc shard routing paired with custom failover scripts as high-risk unless ownership and testing are clearly defined.
Related reading: FATCA Compliance for Marketplace Platforms: Identifying and Reporting Foreign Account Holders.
Best for high-scale SQL without owning manual shard operations#
Distributed SQL is worth serious evaluation when you need SQL and ACID transactions at higher scale across multiple machines.
- Best fit
This fits teams that need to scale writes and data volume beyond a single machine. You keep a relational model while scaling across multiple machines. Scaling out is often described as cheaper for large transactional applications than scaling up a single high-end server.
- Why teams choose it
The main benefit is preserving ACID guarantees for sensitive transactional paths while expanding capacity beyond one machine.
- What the real cost looks like
Distributed execution makes coordination more expensive, not free. When a transaction spans multiple machines, commit requires distributed coordination such as two-phase commit, which adds overhead like a couple of extra network round trips. For lightweight OLTP-style work, that overhead can dominate the actual business-logic time.
Isolation can also become a bottleneck. If locks are held for the full commit-protocol duration, lock contention can rise sharply under concurrency. Evaluate contention behavior under realistic concurrency, not just simple throughput demos.
- How to evaluate it safely
Treat this as an operating-model decision, not just a database switch. Before committing, check how often critical transactions span more than one node and how latency and contention behave when those distributed transactions are common.
If your pain is write concentration and single-node limits, this pattern may fit. If routine money flows still depend on wide cross-node transactions, distributed coordination overhead remains a core constraint.
For a step-by-step walkthrough, see OFAC Compliance for Payment Platforms: How to Screen Every Payout Against the Sanctions List.
Best for mixed workloads using SQL core plus NoSQL projections#
For mixed workloads, a common split is to keep correctness-critical writes on SQL and use projections for read shapes that do not fit relational queries cleanly. This gives you strict integrity controls where it matters and more flexible read views where some delay is acceptable.
- Best fit
Keep one authoritative SQL write path for correctness-critical records, and use NoSQL for read-heavy views built around specific access patterns. Running both SQL and NoSQL in production is a common pattern in 2026.
- Why teams choose it
SQL gives you ACID guarantees and database-level constraints like unique keys, foreign keys, and check constraints for integrity-sensitive data. NoSQL models are typically optimized for specific access patterns rather than general-purpose querying. The split can reduce compromise when one datastore has to serve very different workloads.
- What you must keep explicit
Make system roles explicit: SQL holds correctness-critical state, while NoSQL serves read paths that can tolerate delay.
- Where teams get hurt
The main risk is assuming single-instance ACID behavior will scale without architectural changes. At higher scale, single-node MySQL can struggle to provide strong consistency, high availability, and horizontal scalability at the same time.
- Concrete use-case
A practical pattern is to keep transactional records in SQL and serve high-volume read views from NoSQL based on specific access patterns. For mixed workloads at larger scale, hybrid sharding is presented as a way to balance tradeoffs, but that sharding evidence is from a non-peer-reviewed study.
Set consistency boundaries before you scale#
Define these tiers before you add replicas, shards, or another datastore. Paths that change transactional state should read and write through the authoritative store, while observational paths can use delayed reads.
1. Put transactional decisions on the authoritative path#
If a path changes or confirms transactional state, it should read from the same authority that commits writes. Use delayed reads for reporting and other non-blocking views so heavy analytics traffic does not burden OLTP systems.
| Path type | Read/write expectation | Preferred read source |
|---|---|---|
| Transactional state changes and verification | Strong | Authoritative transactional SQL path |
| Reporting, BI, and non-blocking dashboards | Eventual | Replica, warehouse, or projection store |
2. Make the boundary explicit in design review#
Do not leave this boundary implied. If you are reviewing a feature, document its required tier, allowed data source, and failure behavior when that source is unavailable. That keeps "faster read" shortcuts from quietly moving eventual reads into transactional paths.
A practical review lens is still partitioning, replication, concurrency control, and consistency guarantees. It forces teams to decide not just whether a feature scales, but whether its read and write path matches the guarantees it needs.
3. Treat retries and traceability as part of the boundary#
Retries are part of the boundary, not an afterthought. Document how retries are handled, what request identity fields are used, and how operators check prior outcomes during incident response. Keep these rules easy to trace in specs and runbooks. For deeper record-design context, see Audit-trail design patterns for payment platforms.
4. Escalate cross-boundary features#
Features that read from an eventual source and can trigger a transactional write need explicit review. Include failure scenarios for stale reads and source unavailability. If you are evaluating distributed SQL, be clear about where SQL semantics, ACID transactions, horizontal partitioning, and consensus replication can reduce operational burden, and where they do not remove the need for clear boundaries.
Before locking read-routing rules, map each critical path to strong vs. eventual consistency and validate retry handling against Gruv's developer docs.
Prevent the failure modes competitors skip#
The failure to prevent is not just scale trouble. It is architectural ambiguity: when teams add replicas, partitions, or extra stores, they need to restate authority, read guarantees, and transaction boundaries. ACID still applies to transaction properties, but surrounding read paths and multi-store flows need explicit rules.
1. Treat consistency scope as a design decision, not an implementation default#
Before scaling read paths, define which features require stronger consistency and which can tolerate eventual results. Keep that mapping visible in design review so performance optimizations do not quietly change decision-critical behavior.
2. Reduce single-store dependency without creating unclear authority#
Reliance on a single cloud-based data store is a documented risk, and using different stores can improve availability, response time, and cost efficiency. For each workflow, document which store is authoritative, which stores are derivative, and what happens if a dependent store is unavailable.
3. Validate data-dispersion choices against real usage, not only lab assumptions#
Data-dispersion decisions should be reviewed as an operational risk, not a one-time schema choice. Use the same architecture lens during rollout and review: data model, data dispersion, data consistency, data transaction service, and data management cost.
4. Decide detection and rollback evidence before cutover#
Mixed-store architectures can improve availability, response time, and cost efficiency, but they also expand verification work. Define what evidence confirms drift, what action contains it, and what records prove recovery. Consider your rollback evidence before cutover so decisions are based on facts, not assumptions.
| Symptom | User impact | Detection signal | Containment action | Post-incident evidence |
|---|---|---|---|---|
| Read expectation does not match read path | Incorrect or conflicting user-visible state | Design-review mismatch between feature and assigned consistency scope | Move the feature to its defined authoritative path | Review artifact showing corrected boundary |
| Authority is unclear across stores | Conflicting outcomes between systems | Workflow map cannot identify one authoritative store per action | Pause affected action until authority is explicit | Updated authority map and incident decision log |
| Data dispersion no longer matches traffic shape | Uneven performance or operational overhead | Periodic review shows dispersion or cost imbalance | Revisit dispersion plan before peak changes | Before and after architecture review notes |
| Transaction guarantees are assumed beyond scope | Overconfidence in non-transaction paths | Missing documented boundary between ACID transaction scope and surrounding reads | Re-document transaction boundary and dependent paths | Published boundary definition used in runbooks |
Explain compliance claims without overpromising#
Use precise language here. ACID describes transaction behavior inside a database, not full compliance. Keep your compliance wording aligned to your architecture boundaries so reviews stay clear about what is and is not guaranteed.
| Topic | Guidance | Reference |
|---|---|---|
| ACID and compliance | ACID describes transaction behavior and does not by itself prove PCI DSS, SOC 2, or broader control coverage | Database design deliverables: 2.5.13; Program Controls: 2.5.13.1.5 |
| Constraints evidence | Focus on design artifacts that show intent and enforcement | 2.5.13.4.2.4 Develop a List of Constraints |
| Policy decisions and financial records | Model policy decisions as distinct records and link them to financial effects | 2.5.13.4.3.7 Verify Data Model |
| Future-change boundaries | Document workflows likely to change independently from core financial records | 2.5.13.4.2.5 Develop a List of Potential Future Changes |
- ACID is a database property, not a compliance badge.
Keep claims narrow and testable. ACID describes transaction behavior. It does not, by itself, prove PCI DSS, SOC 2, or broader control coverage. The IRM structure is a useful reminder: database design deliverables are grouped under 2.5.13, while Program Controls appears separately in 2.5.13.1.5.
- Design for evidence quality, not compliance slogans.
Focus on design artifacts that show intent and enforcement. Use 2.5.13.4.2.4 Develop a List of Constraints to document key constraints, then keep them maintained as the model evolves.
- Separate policy decisions from financial history.
When policy decisions affect financial actions, model those decisions as distinct records and link them to financial effects. During 2.5.13.4.3.7 Verify Data Model, confirm the model clearly separates decision state from financial records and keeps links between them explicit.
- Capture future-change boundaries early.
Use 2.5.13.4.2.5 Develop a List of Potential Future Changes to document workflows likely to change independently from core financial records, and keep those boundaries explicit in the model.
If you keep one rule, use this: state exactly what the database guarantees, then separately state what policy, controls, and evidence processes guarantee.
Roll out in sequence so you do not rebuild six months later#
A safer rollout is phased. If you are still on a single writer, keep the simplest architecture that still protects money-critical behavior, and add complexity only when evidence shows the current phase is the bottleneck.
| Phase | Focus | Verification checkpoint |
|---|---|---|
| Phase 1 | Define explicit transaction-consistency checkpoints and make the tradeoff between data integrity and always-on availability explicit early | Require a clear readiness-to-commit step and a separate commit step; confirm commit state is recorded only after participants approve; document tradeoffs and residual risk |
| Phase 2 | Add scale mechanisms only when measured evidence shows the current design is insufficient | Test whether consistency behavior still matches requirements as scale complexity increases, and capture any guarantee changes before moving on |
| Phase 3 | Evaluate Distributed SQL as an operating-model decision, not a marketing decision | Validate how isolation and durability are defined; if the system uses 2PC, confirm the readiness phase and commit phase behavior under fault conditions |
Phase 1#
Start by defining explicit transaction-consistency checkpoints. In financial systems, data integrity and always-on availability can compete, so make the tradeoff explicit early.
Verification checkpoint: require a clear readiness-to-commit step and a separate commit step for critical transactions. Confirm commit state is recorded only after participants approve, and document tradeoffs and residual risk before moving on.
Phase 2#
Add scale mechanisms only when measured evidence shows the current design is insufficient. Treat scale claims as hypotheses to verify, not assumptions.
Verification checkpoint: test whether consistency behavior still matches requirements as scale complexity increases, and capture any guarantee changes before moving on.
Phase 3#
Evaluate Distributed SQL as an operating-model decision, not a marketing decision. Keep ACID claims narrow and testable during evaluation.
Verification checkpoint: validate how isolation and durability are defined in the target system, since implementations can vary and still be labeled ACID. If the system uses 2PC, confirm the readiness phase and commit phase behavior under fault conditions.
Conclusion#
The core decision is straightforward: keep money-critical updates inside ACID transaction boundaries, then scale with the least risky next step.
- Protect correctness first.
For multi-step money movement updates, keep them inside ACID transaction boundaries. Anchor those paths in a relational core with a defined schema and enforced primary and foreign key relationships, not loose application logic.
- Classify before you scale.
Map each payment read and write by required consistency and performance, then choose scaling patterns from that map. Before adding new layers, validate behavior during failover and compare user and reporting outputs against relational records.
- Treat architecture as a tradeoff, not a maturity badge.
Database choices affect scalability, reliability, security, and operational cost. They can also affect compliance and disaster recovery outcomes. If deep database operations are not a team strength, managed options can reduce operational burden as you scale.
- Take one concrete next step this week.
Build a short decision sheet with payment path, required read/write guarantee, and failure-mode check, then check your payout approvals, balance-affecting writes, reporting exports, and support views against it.
- If Gruv is in scope, confirm coverage early.
For compliance-gated payout flows, review the docs or talk to sales to confirm market and program coverage before locking architecture decisions.
If you want a design sanity check on payout gating, ledger traceability, and rollout sequencing for your markets, talk to Gruv.
Frequently Asked Questions
Sharding vs read replicas for payment platforms, which comes first?
There is no fixed sequence in the article. Start with the measured bottleneck and separate read growth from write growth. Use read replicas when one authoritative writer still handles state changes and the main pressure is read volume. Consider sharding when replicas are already scaling reads and a single primary is still the write or data-growth bottleneck.
Does ACID compliance mean we are compliant with PCI DSS or SOC 2?
No. The article says ACID describes transaction behavior inside the database, not full compliance. Keep claims narrow and separate database guarantees from policy, controls, and evidence processes.
Can we serve wallet and balance checks from read replicas safely?
Not by default. Any screen or workflow that can influence a financial action needs careful read-path validation before moving off the primary path. If stale or incorrect data could change a money decision, keep it on the relational core.
When should we choose Distributed SQL over manual sharding?
Choose Distributed SQL when you need SQL and ACID transactions at higher scale across multiple machines and do not want manual shard routing to be the default. The article also says to test how often critical transactions span more than one node and how latency, contention, and failover behave under realistic conditions. Treat it as an operating-model decision, not just a database switch.
What is the biggest architecture mistake teams make in payment databases?
The biggest mistake described here is architectural ambiguity. Teams add replicas, partitions, or extra stores without restating authority, read guarantees, and transaction boundaries. That can turn scale optimizations into control problems on money-critical paths.
How do idempotency keys interact with ledger writes during retries?
The article does not define a universal pattern. It says retries belong inside the architecture boundary, so you should document request identity fields, retry handling, and how operators check prior outcomes during incidents. This interaction needs system-specific design and testing rather than assumptions.
What should stay on strongly consistent SQL versus move to NoSQL projections?
Keep correctness-critical state, balance-affecting writes, payout-state transitions, and other decision-critical paths on the authoritative SQL path. Move read-heavy views built around specific access patterns to NoSQL only when some delay is acceptable. Keep system roles explicit so SQL remains the source of truth and NoSQL serves derivative read paths.
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
Includes 1 external source outside the trusted-domain allowlist.
- digitalcommons.georgiasouthern.edu/cgi/viewcontent.cgitrusted
- drum.lib.umd.edu/bitstreams/9f17a28c-6940-4693-bb54-6ea5529c0...trusted
- irs.gov/irm/part2/irm_02-005-013trusted
- ntrs.nasa.gov/api/citations/19830007077/downloads/19830007...trusted
- reports-archive.adm.cs.cmu.edu/anon/2024/CMU-CS-24-107.pdftrusted
- sites.cs.ucsb.edu/~mikec/cs16/misc/demos/savitch10pgms/Chapter...trusted
- snap.berkeley.edu/project/10053261trusted
- algomaster.io/learn/system-design/relational-databasesexternal
Educational content only. Not legal, tax, or financial advice.
Related Posts

The Freelance Payment Penalty: A Modeled Audit of Platform Fees, FX Spreads, and Payout Delays
The money rarely disappears through a single, easy-to-spot fee. The real loss is stacked. A marketplace takes its commission, a processor adds a charge for international cards, a bank or payment company converts the currency at a spread, a platform holds the funds before release, and a wire sheds a little to intermediaries on the way in. Each layer looks defensible on its own, but the worker feels the combined result as a smaller deposit and a later payday.

How to Respond to a Subpoena for Business Records
Move fast, but do not produce records on instinct. If you need to **respond to a subpoena for business records**, your immediate job is to control deadlines, preserve records, and make any later production defensible.

A US Expat's Guide to Investing in UCITS ETFs to Avoid PFIC Issues
The real problem is a two-system conflict. U.S. tax treatment can punish the wrong fund choice, while local product-access constraints can block the funds you want to buy in the first place. For **us expat ucits etfs**, the practical question is not "Which product is best?" It is "What can I access, report, and keep doing every year without guessing?" Use this four-part filter before any trade: