
Quick Answer
A bank code is not the same as a routing number or a sort code. Bank code is an umbrella label, while a routing number is a U.S. institution identifier and a sort code is a UK routing identifier. For payouts, collect the code required by the destination country and rail, pair it with the right account identifier, and validate each code family separately before submission.
How to use this payout reference guide#
Treating bank code, routing number, and sort code as one generic field creates avoidable payout failures. Teams often discover the mismatch only after submission, when the provider cannot process the transfer.
These terms are not interchangeable. A U.S. Routing Transit Number (RTN) is a financial-institution identifier assigned by the American Bankers Association. UK domestic payments use the sort code for routing and settlement, including Bacs, FPS, and ICS. BIC/SWIFT identifiers identify financial institutions in international transfer contexts. Incorrect values can stop processing and add fees.
This guide turns that terminology into an operator-ready reference you can build against. We use it as a practical checkpoint when you need to design intake fields, map data correctly, and catch bad routing data before submission.
There is no universal field set for every payout corridor. Requirements vary by destination country, rail, provider, and program coverage. Stripe notes required bank details differ by bank location, and payout availability varies by industry and country. Goldman Sachs notes some countries require external clearing codes. Adyen documents that local and cross-border payouts on the same bank account can require separate transfer instruments.
The cost of getting this wrong is operational and financial. ABA states that inaccurate, incomplete, or missing RTN data can cost organizations thousands of dollars per month. Stripe warns incorrect BIC/SWIFT entries can block transfers and trigger fees.
This guide gives you:
- An at-a-glance comparison of key payout reference types
- Country-and-rail decision rules
- An implementation sequence from intake through submission
- A launch checklist for enabling new payout corridors
At-a-glance comparison of payout reference types#
Use a corridor-specific reference and collect it with the account identifier your payout path requires. You usually see failures when one institution code stands in for complete bank details.
| Reference type | Where used | Domestic vs cross-border fit | External clearing code may be needed? | Collect with | Common failure when missing or wrong |
|---|---|---|---|---|---|
| ABA routing transit number / Routing number | United States | Primarily U.S. domestic rails (FedACH, Fedwire contexts) | Sometimes for cross-border flows into the U.S.; not a universal domestic requirement | Beneficiary account identifier required by the rail/provider | U.S. payout can fail to route correctly, or be rejected because the 9-digit routing value does not match the intended bank/rail |
| Sort code | United Kingdom | Primarily UK domestic payments | Sometimes in cross-border setups; not typically the core domestic UK requirement | UK account number | UK payout can fail because only one field was collected, or the sort code is wrong even when the account number is present |
| IBAN | European Union and other SEPA countries | Used for domestic and international euro payments across SEPA countries | Sometimes, depending on country and provider rules | Often centered on IBAN for SEPA intake; some corridors also request BIC/SWIFT | Payment can be delayed or rejected because required corridor fields are incomplete or inconsistent |
| SWIFT/BIC | Global financial messaging context | Mostly cross-border; not a substitute for every domestic bank reference | May be needed alongside country-specific clearing data in some countries | Usually with account number or IBAN, depending on corridor | Transfer can stall because the BIC is wrong, or because the BIC provided is not the routing BIC for that payment path |
| CLABE | Mexico | Strong fit for domestic Mexico transfers (such as SPEI) | Sometimes for cross-border initiation into Mexico | CLABE identifies the destination account in the cited transfer flow | Mexico transfer can fail to initiate because CLABE is missing, or the 18-digit value is invalid |
| IFSC | India | Strong fit for domestic India branch routing (such as NEFT) | Sometimes for cross-border setups into India | Beneficiary account identifier required by the rail/provider | Payment cannot be routed to the beneficiary branch because IFSC is mandatory in the cited NEFT flow |
| BSB code | Australia | Primarily Australian domestic routing | Sometimes for cross-border payouts into Australia | Beneficiary account identifier required by the rail/provider | Payout can be rejected or misrouted because the BSB is missing or does not match the receiving branch |
| Zengin Code | Japan | Domestic customer transfer context in Japan | Sometimes for cross-border initiation into Japan | Japanese account details, as required by provider or bank | Domestic Japan transfer can fail because the routing reference set is incomplete or mapped to the wrong field family |
What this should change in your intake design#
Do not ship one generic bank code field. These references do different jobs, and their formats differ. U.S. RTN is 9 digits. UK sort code is 6 digits. CLABE is 18 digits. IFSC is 11. BSB is 6 digits in XXX-XXX format.
Do not assume cross-border means just collect SWIFT. BIC is standardized, but the account-holding BIC and the payment-routing BIC can differ. A valid BIC can still be the wrong one for the route.
Pairing rules worth hardcoding#
Hardcode institution-plus-account pairings so your users do not have to guess. We recommend corridor-specific defaults, and you should confirm provider requirements:
| Context | Baseline fields |
|---|---|
| United States | Routing number + beneficiary account identifier required by the rail/provider |
| United Kingdom | Sort code + account number |
| India | IFSC + beneficiary account identifier required by the rail/provider |
| Australia | BSB + beneficiary account identifier required by the rail/provider |
| SEPA corridors | Center intake on IBAN; add BIC or an external clearing code only when the country, provider, or rail requires it |
IBAN is different: teams use it as an account identifier for domestic and international euro payments across SEPA countries. In SEPA corridors, center your intake on IBAN, then add BIC or an external clearing code only when the country, provider, or rail requires it.
Verification details that prevent cleanup work#
Validate each code family before first live use. For U.S. routing data, check against the Federal Reserve routing directory used for Fedwire and FedACH contexts. For UK intake, enforce format constraints: sort code is 6 digits, and account number is 6 to 8 digits.
| Item | Check | Detail |
|---|---|---|
| U.S. routing data | Check against the Federal Reserve routing directory | Fedwire and FedACH contexts |
| UK intake | Enforce format constraints | Sort code is 6 digits; account number is 6 to 8 digits |
| Australia | Use a BSB lookup | Before submission |
| Mexico | Enforce CLABE length | 18 digits |
For Australia, use a BSB lookup before submission. For Mexico, enforce CLABE at 18 digits. Keep a corridor matrix with country, rail, required fields, whether an external clearing code may be required, and one accepted provider payload so launch rules do not live only in tribal knowledge.
The operating rule is simple: model each reference as a distinct type, pair it with its account identifier, and treat IBAN and BIC as corridor-specific tools, not universal replacements.
For payout troubleshooting on the payment side, see Payment Decline Reason Codes: A Complete Reference for Platform Engineers.
What each code actually identifies and what it does not#
Treat these references as distinct field types, not synonyms. Some identify an institution or branch for routing, and others identify the beneficiary account.
| Term | What it identifies | What it does not identify | Usually collected with |
|---|---|---|---|
| Bank code | Context-dependent label that may refer to an institution identifier | No single globally standardized field type | Country- and rail-specific account details |
| Routing number / ABA RTN | The U.S. paying financial institution in a payment transaction | The customer's U.S. account number | U.S. account number |
| Sort code | The UK bank for routing purposes | The customer's UK account number | UK account number |
| IBAN | The bank account identifier under ISO 13616 | A universal substitute for every routing field | Sometimes BIC/SWIFT, depending on flow |
| SWIFT code / BIC | A business identifier used in financial messaging and routing | The beneficiary bank account itself | IBAN or other account identifier, depending on flow |
Bank code is an umbrella label. It may mean a routing number in the United States, a sort code in the United Kingdom, or another domestic institution code elsewhere. That is why a single bank_code intake field can create mapping errors across jurisdictions.
Keep institution fields and account fields separate in your data model. An ABA routing number is a unique 9 digit institution identifier, while the account number identifies the customer account. In the UK, the sort code is 6 digits and identifies the bank, while the account number is stored separately.
IBAN and SWIFT/BIC are often requested together in cross-border contexts, but they are not interchangeable. IBAN is an account identifier standard under ISO 13616. BIC, under ISO 9362, identifies a payment service provider and can be branch-specific.
To prevent terminology drift across vendors, keep one internal glossary and map provider labels into it. If a provider says "SWIFT," store bic; if it says "bank code," resolve and store the specific type, such as aba_rtn or sort_code, before validation and submission.
Related: What Is an ABA Routing Number? A Platform Operator's Guide to US Bank Routing.
Which references to collect by country and rail#
Start with country + rail, not a generic bank code field. That is the practical way to request what the route actually needs and reduce corridor-level mismatches.
| Rail | Destination context | Common baseline fields to request | Verify before submit |
|---|---|---|---|
| ACH | United States domestic | Account number + routing number | Keep routing number as its own field and validate it as a 9-digit U.S. identifier |
| UK domestic rails | United Kingdom domestic | Account number + sort code (baseline) | Confirm the sort code can receive the rail you plan to use (for example Faster Payments, Bacs Direct Credits, or CHAPS) |
| SEPA | SEPA scheme countries | IBAN, plus BIC/SWIFT where required for that flow | Check provider- and flow-level requirements; do not assume one universal SEPA rule |
| Wire transfer | Cross-border corridors (and wire use cases more broadly) | Beneficiary account details + routing-path details (SWIFT/BIC or domestic routing coordinates); some implementations also require recipient address + wire routing number | Run corridor checks before submission because wire-required data can vary by destination and setup |
If the destination is United States domestic, prioritize routing number with account number for ACH-related setup. If it is United Kingdom domestic, prioritize sort code with account number, then verify rail operability. For cross-border payouts across multiple markets, expect SWIFT/BIC or domestic routing coordinates plus country-specific fields, not one global template.
Country examples help prevent a US- and UK-centric design. Build the model so these corridors fit naturally too:
- Mexico (SPEI context): request CLABE (18 digits).
- India: model IFSC and MICR Code as distinct field types when required by corridor or provider. Avoid hardcoded format assumptions not confirmed in your specs.
- Australia: request BSB as its own field (6-digit
XXX-XXXformat).
Hardcode the core branching logic, but do not hardcode every provider requirement. Corridor-level exceptions are real, including cases where an additional external clearing code may be required, and provider coverage can vary by location.
The payout data model your engineering team should lock first#
Lock a typed, context-aware payout schema early. Separate editable recipient data from payout-time snapshots, and store provider references for reconciliation. When country and rail are explicit on each reference, validation and incident review are more reliable.
Compare the records you actually need#
| Record | Purpose | Editable after creation | Must include | Main failure if omitted |
|---|---|---|---|---|
| Beneficiary profile | Current recipient details for future payouts | Yes | Beneficiary ID, country, account-linked details, contact data as needed | Updates overwrite history, so change tracking is weak |
| Payment reference record | Canonical routing/clearing identifier with typed validation | Sometimes, with version history | code_type, value, country, rail, verification_status | Wrong code family gets reused because everything is treated as generic "bank code" |
| Payout instruction snapshot | Fields captured for one submitted payout | Prefer no edits after submission | Submitted beneficiary fields, amount/currency context, rail-specific routing details | You cannot reliably reconstruct why a payout was rejected or returned after profile edits |
| Provider reference record | External IDs and references for reconciliation | Yes, as updates arrive | Provider payout ID, payment reference, payout date, amount, currency, type | Internal records cannot be cleanly matched to provider reports or bank events |
Your payment reference object should be strict and predictable: normalized code_type, raw value, country, rail, verification_status, timestamps, and provenance. Keep code_type controlled, not free text, so external clearing codes and domestic code families are stored as distinct types when corridor rules differ.
Make validation rules follow code type, country, and rail#
Do not use one regex for all routing fields. Validation should be code-type specific, then constrained by country and rail context. Use per-type rules for:
- allowed character set
- exact or bounded length
- normalization rules
- compatible countries and rails
- required companion fields
Use the actual format rules in code, not just in docs. U.S. routing numbers use a 9-digit form. UK domestic sort code is 6 digits in one provider spec. IFSC is 11 alphanumeric characters in that same spec. CLABE is 18 digits. Also model rail-level requirements explicitly, since local-network and wire flows can require different field combinations. Reject values that are valid in format but invalid for the selected country + rail.
Keep auditability and reconciliation first-class#
Design for this deliberately. Keep recipient profiles editable, and capture payout instructions at submission so you preserve the submitted field set. That split lets you answer both "what is current now" and "what did we actually send then." We use this checkpoint because it also helps when verification takes a few business days and when downstream events arrive after recipient edits.
Store provider references alongside internal payout records: external payout ID, any bank-assigned payment reference, payout date, type, amount, and currency. These are common reconciliation fields used to match payouts to settled transaction batches, and external references may arrive later than submission. In some provider reporting, refresh cadence is approximately every two hours, so reconciliation should tolerate delayed updates.
For logging, keep reconstructable trails without overexposing sensitive data. Log object IDs, code type, country, rail, verification outcomes, and masked values where needed.
Related reading: How State Variations in the Uniform Trust Code Affect Your Trust.
Validation order from onboarding to payout submission#
A workable sequence is intake validation, corridor eligibility, compliance and policy gates, pre-submit verification, then execution with idempotent retries. This catches structural and route-fit issues before submission and reduces avoidable late-stage failures.
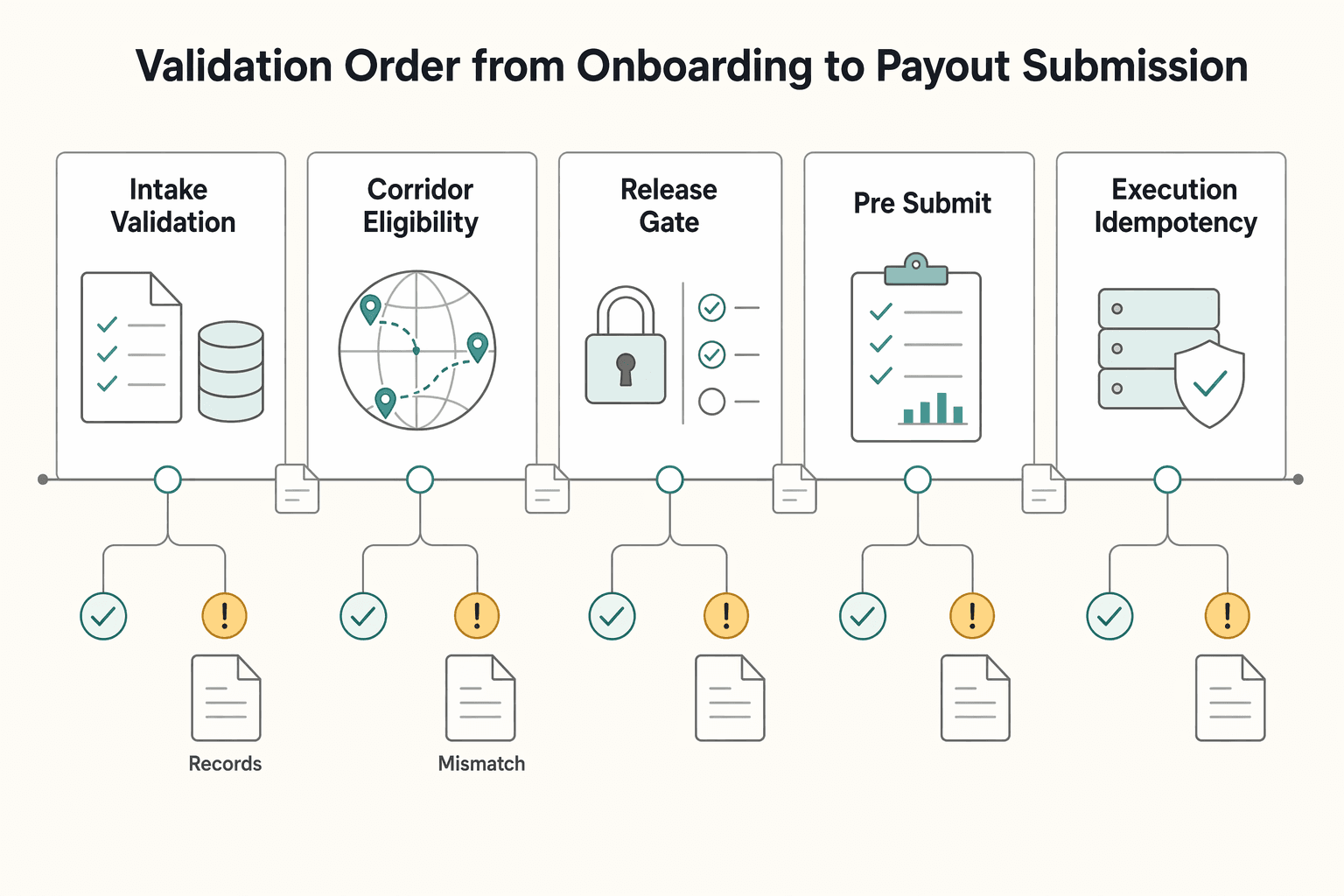
At each stage, ask a different question: Is the data valid? Is the route available? Is release approved internally? Is the submission still correct now? Is retry behavior duplicate-safe?
| Stage | What you verify | Example operator check | Main failure if skipped |
|---|---|---|---|
| Intake validation | Field format and required companions | U.S. local bank setup requires account + routing number; IBAN can be up to 34 alphanumeric characters; SWIFT/BIC is 8 or 11 | Bad or incomplete recipient records are stored and reused |
| Corridor eligibility check | Country and rail are actually available | Confirm the recipient country supports the chosen payout method; local and wire networks are different paths | You collect valid-looking data for a route you cannot send |
| Compliance and policy gates | Internal approval and restricted scenarios | Apply your compliance, risk, or payout-policy holds before submission | Payouts are stopped late, after prep or batching |
| Pre-submit verification | Current route data and pair-field rules | Recheck country + rail compatibility, sort-code capability data, and whether IBAN + SWIFT/BIC should be included for IBAN-registry destinations | Preventable rejects, returns, or delays |
| Execution with idempotency | Safe retry behavior | Retry with the same request identifier when upstream status is delayed | Duplicate payouts from replayed POSTs |
Preflight checks that actually catch problems#
Be strict at pre-submit. Confirm three things together: the code is valid for its type, the type is valid for the selected country and rail, and required pair fields are present.
That matters because a value can be valid on its own but still be wrong for the route. A UK sort code helps route and settle UK payments, but route availability still depends on the selected country and rail. For IBAN-registry destinations, missing IBAN details can cause returns, and including both IBAN and SWIFT/BIC is advised for those international payments. If your intake model only supports one generic bank-code field, this is where failures surface.
Keep route and capability reference data fresh on a schedule, not just at launch. Sort-code capability datasets can change on weekly cadences, and stale data can delay or block processing.
Retries should not create second payouts#
Idempotency is what makes timeout retries safe instead of duplicative. Supported APIs can return the prior status for repeated identifiers; missing idempotency identifiers can create duplicates.
Keep the rule simple: if the original submission may have reached the provider, retry with the same request identifier and the same payload.
Corridor launch checkpoints#
Before you enable a new corridor in production, require an internal evidence pack, not just a demo. At minimum, consider including:
- sample beneficiary records with the exact required reference pairs
- test submissions showing how invalid records are rejected before execution, when supported
- duplicate-submission tests proving retries return prior status instead of creating a second payout
- reconciliation fields captured after submission
Consider holding release until finance can reconcile a test batch and ops can explain the expected failure path for a malformed record.
For more on that distinction, read What is an IBAN and How is it Different from a SWIFT Code?.
Failure modes that cause avoidable payout delays#
Many avoidable payout delays start when route-specific reference errors are allowed to reach submission. A practical default is to reject records when country, rail, and reference type are clearly incompatible, and hold only when the instruction might still be valid but needs external evidence to resolve.
ACH relies on the receiving institution's routing number, UK domestic payments rely on sort code information for routing and settlement, and some countries require an External clearing code. If those references are treated as one generic field, failures move from intake to post-submission, where recovery is slower and more expensive.
| Failure mode | What it usually looks like | Why it delays payout | Best first action |
|---|---|---|---|
| Wrong code family for corridor | UK sort code captured for US ACH, or a 9-digit US ABA routing number treated as a UK code | Value can look valid in isolation but is unusable on the selected rail | Reject fast when country + rail + code_type are incompatible |
| Mismatched country and rail | Domestic-looking details are present, but submission path requires different references | Provider or clearing rejection can happen after submission | Reject when route rules are known; do not silently infer fallback rails |
Missing External clearing code | Account details are present but a required country-specific clearing code is absent | Instruction can stall for correction or be rejected downstream | Reject when the rule is known; hold only when corridor requirements are incomplete internally |
| Stale beneficiary details | Account is nonexistent, closed, or now invalid | Failure appears late and triggers support and resubmission work | Fail and require account refresh; hold if recipient disputes and evidence is pending |
The four failures worth treating as recurring risks#
Wrong code family points to a data-design or mapping issue, not just provider processing. A US ABA routing number is 9 digits and a UK domestic sort code is 6 digits, but format checks alone are not enough. A numeric value can still be the wrong reference for the selected rail.
Country-rail mismatch is another common break point. Data collected for one route may be submitted on another later, which can lead to downstream rejects for incorrect instruction or unverified recipient instead of a clean intake rejection.
Missing External clearing code is the same underlying problem in a quieter form. Some countries require it in payment instructions, so missing schema support can create avoidable manual chasing.
Stale beneficiary details pass structural checks and then fail late. Common post-submission failures include nonexistent, closed, or invalid accounts, and outdated routing data increases failed payments, exceptions, cost, and customer impact. Routing-reference updates should be an ongoing control, not a one-time setup.
Why late rejection hurts status tracking and reconciliation#
Late rejection creates status ambiguity, not just a failed payout. Providers may return a high-level status plus sub-status detail, and SEPA exceptions are structured, for example rejects and returns. If your internal systems collapse this into one generic failed state, teams lose the reason data needed to decide whether to retry, correct data, or wait.
Reconciliation gets harder too. You need to match a submitted payout to later rejection or return events, retain return reasons, and explain timeline gaps to recipients. For missing-funds cases, follow-up may require trace metadata like a Payout Trace ID, and bank tracing may not start until after 5 business days.
A practical exception routing model#
Use this default: reject fast when data is clearly wrong, and hold when resolution needs evidence outside your records. Route the case by owner:
| Owner | Handles | Examples |
|---|---|---|
| Ops | Beneficiary-data exceptions | Missing External clearing code; stale account details; recipient confirmation |
| Engineering | Mapping defects | Wrong code_type for a corridor; incorrect country-rail validation rules |
| Finance | Sent-but-not-received investigations | Trace handling; reconciliation with provider events |
For evidence, require the minimum package that closes the case: submitted instruction snapshot, provider return reason or sub-status, and corridor metadata at submission. If a recipient disputes a failed bank-account result, require written confirmation from their bank before escalation.
Short post-incident template#
Use the template below as a baseline, and do not stop at the individual record. If you skip the guardrail, the same delay pattern will return.
- Root cause category: wrong code family, country-rail mismatch, missing clearing code, stale beneficiary data, or internal mapping defect
- Affected rail: e.g.,
ACH,SEPA, orWire transfer - Escape point: intake, corridor eligibility, pre-submit, or provider post-submit reject
- Prevention fix: form change, validation rule, route-capability update, or beneficiary refresh control
- Release guardrail: test case added, required field enforced, reject reason surfaced in dashboards, or finance sign-off added before corridor launch
For a workflow-automation example, see How to Use Zapier to Automate Subscriber Workflows on Your Platform Without Code.
Scenario recommendations for platform teams#
Design for the corridors you actually run, not a generic "bank details" object. If your volume is concentrated in one market, go deep on that market's controls. If you span regions, move to a country-and-rail matrix before scale exposes the gaps.
| Scenario | Priority | First-class fields | Verification checkpoint | Red flag |
|---|---|---|---|---|
High-volume domestic payouts in the United States | Fast pre-submit rejection and routing-data freshness | Routing number plus account number | Refresh routing validation tables at least monthly; reject route-incompatible records before submission | Legitimate payouts fail because new routing data is not recognized |
Mixed corridors across United Kingdom and European Union | Matrix-driven intake, not manual branching | Sort code for UK domestic flows; IBAN and BIC where the rail and provider require them | Validate destination country, selected rail, and required field pairings at intake and pre-submit | UK domestic details are later reused for SEPA or cross-border flows without required identifiers |
Expansion into India, Mexico, or Australia | Country modules with native identifiers in schema | IFSC plus beneficiary account attributes for India, CLABE for Mexico, BSB code plus account details for Australia | Validate code family and length by country before launch | Country-specific identifiers live in notes/free text, so validation and mapping are unreliable |
If you are launching in the United States, prefer hard rejection early. ABA routing numbers are distinct nine-digit identifiers used with account numbers, and bad routing data creates real operating cost. For ACH-heavy lanes, format checks alone may not be enough. Table freshness is a core control.
If you cover the United Kingdom and European Union, use the matrix model. UK domestic payments use sort code data for routing and settlement, while SEPA operates with harmonized standards and uses references that include IBAN and BIC. Keep country, rail, and code_type separate so you can enforce valid combinations before submit.
If you are expanding into India, Mexico, or Australia, model native identifiers as first-class fields from day one. India NEFT beneficiary setup uses IFSC with account attributes. IFSC is 11 characters, and the first four are letters. Mexico CLABE is 18 digits. Australia BSB code is six digits in XXX-XXX format. Also keep room for an External clearing code, since some countries may require one.
Roll out one corridor at a time#
Use a phased rollout: launch one corridor, run controlled volume, inspect reject reasons, and confirm your ops team can distinguish wrong-code-family errors from missing-data cases before expanding. Widen coverage only when reject patterns are understood and reconciliation is reliable.
For a step-by-step walkthrough, see How to Hedge FX Risk on a Global Payout Platform.
Non-obvious tradeoffs teams miss until scale#
At low volume, permissive intake can feel faster. At scale, it pushes cost into payout exceptions, manual ops, and reconciliation work. If you plan to run multiple rails or regions, add corridor-aware field requirements earlier than feels comfortable.
| Tradeoff | Early upside | Cost that shows up later | Practical recommendation |
|---|---|---|---|
| Speed vs certainty | Fewer required fields can speed onboarding and launch | More payment exceptions from incorrect payee details or missing information, followed by manual investigations | Make corridor-defining fields mandatory at intake and re-check them before submit |
| Flexibility vs maintainability | Market-specific exceptions can improve short-term submit rates | Can create schema drift, branching logic, and weaker test coverage over time | Keep one canonical model (country, rail, code_type, verification status), then layer corridor rules on top |
| Coverage vs operational clarity | A generic "bank code" field is quick to ship | Harder triage when required code types vary by corridor and country | Store an instruction snapshot and label each reference by its actual type |
Speed versus certainty#
Permissive intake is not always wrong, but the cost shows up later, when fixes are slower. Payment exceptions often start with incorrect or missing instruction data, and investigation messages can move sequentially bank by bank once a payment is in flight. That is a meaningful scale risk: about 5% of cross-border payments encounter friction, and manual interventions tied to these cases cost the industry upwards of $2 billion per year.
Use a simple rule: when a field determines routing for the selected corridor, reject fast if it is missing or mismatched. Enforce required field pairings at both intake and pre-submit, not just one or the other.
Flexibility versus maintainability#
Short-term patches help you ship, but they compound quickly. If country and rail requirements are hidden behind generic text inputs, your logic becomes harder to test, reason about, and audit.
This gets more important as harmonised ISO 20022 requirements roll out. On 17 October 2023, global participants were encouraged to align on a common minimum messaging data set, with alignment expected by end-2027. Benefits still depend on broad adoption, and inconsistent implementation still creates cross-border inefficiencies. Standards help, but they do not resolve internal schema inconsistencies on their own.
Before you enable a corridor, confirm the same required reference set is enforced in onboarding, API schema, and pre-submit checks. If those layers accept different combinations, you increase the risk of future exceptions.
Hidden cost centers#
A major cost center is the follow-on work after an exception: triage, delayed investigation communication, and reconciliation when items fail to auto-match. Straight-through processing reduces manual intervention and streamlines reconciliation, but it works best when instruction data stays consistently structured across the payment lifecycle.
For each exception, keep the operational record complete: instruction snapshot, provider reject or response detail, and transaction-level reconciliation evidence for status and fee impact. If items cannot be auto-matched, they move to manual reconciliation. Complete, continuous, and precise reconciliation is a core operating requirement.
The practical call is to choose slightly more structure than launch instincts suggest. Expanding later is usually easier than cleaning inconsistent reference data after volume arrives.
Decision checklist before you enable a new payout corridor#
Treat corridor launch as a release gate. If you cannot verify required identifiers, state handling, and retry behavior end to end, do not enable it yet.
Confirm minimum identifiers by both country and rail before go-live. For U.S. ACH onboarding, collect the 9-digit ABA routing number and account number together. For UK domestic payouts, expect the 6-digit sort code with account number. Note that payee checks commonly validate name, sort code, and account number together. In EU cross-border contexts, confirm whether your provider expects IBAN and BIC together. We recommend that you also decide explicitly whether an external clearing code is required for the destination corridor.
| Launch check | What to verify before go-live | Red flag if missing |
|---|---|---|
| Reference minimums | Required identifiers by country and rail, such as routing number, sort code, IBAN, SWIFT/BIC, or external clearing code where applicable | Generic bank code field with no typed code family |
| Schema alignment | Onboarding forms, API schema, and canonical stored fields use the same definitions | Intake accepts values the submit layer rejects |
| State and audit mapping | Policy gates are mapped to payout states and exception outcomes | You cannot explain why a payout was blocked, retried, rejected, or released |
| Release controls | Controlled non-production payout tests, idempotency keys on create/update calls, and webhook events wired to ops and reconciliation | Duplicate submissions, poor rejection visibility, or weak reconciliation evidence |
Test local-bank rails and wire rails separately when your provider configures them separately, for example ACH/FPS vs. Fedwire/SWIFT. Shared beneficiary data does not mean shared failure modes. Review and update corridor onboarding requirements regularly after launch to reduce avoidable payout failures.
Before rollout, map your required identifier fields, retry keys, and rejection states to Gruv payout workflows in the Payouts module.
Conclusion#
Stop treating payout references as one generic bank-details field. The reliable unit is the corridor: country, rail, and scheme, plus any provider-specific requirement.
Once you model it that way, implementation choices get simpler. U.S. ACH and direct-deposit style onboarding typically requires routing number plus account number together. UK domestic routing depends on sort code across UK payment systems, and sort code should be handled as a 6-digit field. SEPA is standards- and rulebook-driven, so validation logic should stay rail- and corridor-specific. Use this production pattern:
- Build a comparison matrix so product, ops, finance, and engineering align on required references by corridor.
- Lock schema fields so you store code type, value, country, rail, and verification state explicitly.
- Run validation in sequence: intake checks, then corridor and eligibility checks, then pre-submit verification, then funds release.
- Roll out in phases with measurable checkpoints, one corridor at a time.
A CLABE (18 digits), a UK sort code (6 digits), and an Australian BSB (XXX-XXX) are different identifiers with different routing meaning, not formatting variants of one field.
Before scaling volume, make freshness a control, not an assumption. U.S. Fedwire and FedACH routing data is synchronized daily. UK sort-code capability data is updated weekly. If pre-submit checks are not tied to current directory or scheme data, teams can accept values that look valid but still fail on the rail used. Apply the same rule when a provider requires an external clearing code in certain countries.
Pick one active corridor this week and run the checklist end to end. Confirm your required references, schema coverage, validation order, and current pre-submit data sources. Fix the intake-validation gaps you find before you increase payout volume. If you want a corridor-by-corridor readiness review before scaling volume, contact Gruv.
Frequently Asked Questions
Is a bank code the same as a routing number?
No. Bank code is an umbrella label for institution-routing identifiers, while a routing number is a U.S. identifier used in domestic transfers. If a form only says bank code, capture the code family and country so users do not submit the wrong identifier for that corridor.
What is the practical difference between a routing number and a sort code?
A routing number is a U.S. bank identifier and uses a 9-digit form in U.S. processing. A sort code is the UK routing and settlement identifier and is 6 digits. They serve similar purposes in different systems, so they are not interchangeable and should not share one validation rule.
What payout reference details are typically needed for United States vs United Kingdom payouts?
For U.S. domestic payouts, routing number plus account number is a common reference pair. For UK domestic payouts, sort code plus account number is a common reference pair, with a 6-digit sort code and account number often validated at 6 to 8 digits. Validate by both country and rail before submission.
When do you need SWIFT/BIC in addition to domestic bank codes?
You may need SWIFT/BIC for international flows, but not as a universal rule in every destination. Some provider flows require domestic-style routing and account details plus SWIFT, national ID, or IBAN. Validate BIC separately as 8 or 11 characters.
Can IBAN replace all other payout references?
No. IBAN is used to identify accounts for cross-border payments, but it does not replace UK sort code and account number for domestic UK references. In some corridors, providers also require BIC with IBAN.
What is an external clearing code and when is it required?
An external clearing code is a country-dependent clearing identifier that may be required for certain payment corridors. Treat it as a structured coded value from published clearing-code lists, not free text. If a corridor requires it, include it before submission.
What should we do when provider and country rules conflict with our current payout form?
Change the form to match the rule set you must submit. Add provider-required fields explicitly and render country-specific fields based on the selected country instead of forcing one global field set. Keep form fields and submission payload aligned so intake and submission expect the same identifiers.
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
Includes 3 external sources outside the trusted-domain allowlist.
- bis.org/press/p231017.htmtrusted
- bis.org/cpmi/publ/d218.htmtrusted
- ecfr.gov/current/title-12/chapter-II/subchapter-A/par...trusted
- federalreserve.gov/frrs/regulations/appendix-a-routing-number-g...trusted
- ffiec.gov/npwtrusted
- cheatsheetseries.owasp.org/cheatsheets/Logging_Cheat_Sheet.htmlexternal
- committee.iso.org/sites/tc68/home/articles/content-left-area/a...external
- developer.gs.com/docs/services/transaction-banking/routing-codesexternal
Educational content only. Not legal, tax, or financial advice.
Related Posts

The Freelance Payment Penalty: A Modeled Audit of Platform Fees, FX Spreads, and Payout Delays
The money rarely disappears through a single, easy-to-spot fee. The real loss is stacked. A marketplace takes its commission, a processor adds a charge for international cards, a bank or payment company converts the currency at a spread, a platform holds the funds before release, and a wire sheds a little to intermediaries on the way in. Each layer looks defensible on its own, but the worker feels the combined result as a smaller deposit and a later payday.

How to Respond to a Subpoena for Business Records
Move fast, but do not produce records on instinct. If you need to **respond to a subpoena for business records**, your immediate job is to control deadlines, preserve records, and make any later production defensible.

A US Expat's Guide to Investing in UCITS ETFs to Avoid PFIC Issues
The real problem is a two-system conflict. U.S. tax treatment can punish the wrong fund choice, while local product-access constraints can block the funds you want to buy in the first place. For **us expat ucits etfs**, the practical question is not "Which product is best?" It is "What can I access, report, and keep doing every year without guessing?" Use this four-part filter before any trade: