
Quick Answer
Payment platforms should vet and monitor vendors with a tiered, lifecycle-based process that sets ownership before onboarding, collects checkable evidence, blocks go-live when high-impact gaps remain, and tracks live vendors with KRIs. Third-Party Risk Management works best when scope, approvals, contract obligations, monitoring, and escalation paths are all recorded in one auditable vendor record.
Why payment vendor risk needs active management#
Payment-vendor risk is easier to control when ownership, evidence, and escalation are explicit from the start.
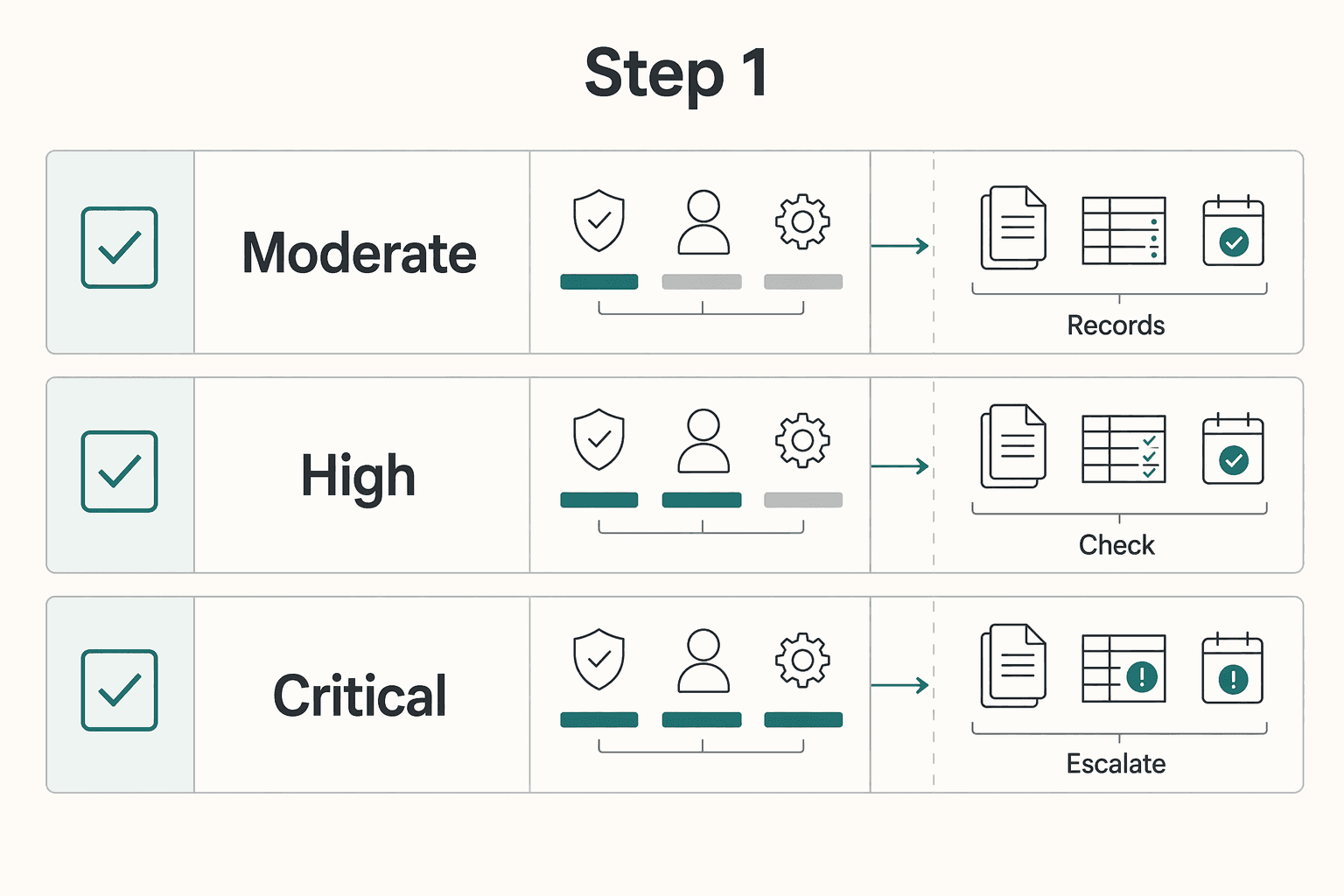
Step 1 Put accountability in place before onboarding#
Third-Party Risk Management, or TPRM, is the practice of identifying, assessing, and controlling risks introduced by external partners that can access your data. For payment platforms, that is an operating issue, not a theoretical one. Vendors can sit close to user information, and your organization still owns the compliance outcome when that data is involved.
Before review starts, document who can:
- approve go-live
- reject go-live
- escalate issues after launch
If those owners are not clear in writing, your review process is probably not reliable yet.
Step 2 Treat vendor risk as a lifecycle, not a questionnaire#
A one-time onboarding check is not enough. Third-party relationships can expand capability, but they also increase exposure to breach, noncompliance, and hidden data flows. One weak link can create security, regulatory, and reputational impact.
Use a continuous lifecycle: Identify, Assess, Mitigate, Monitor, Respond. In practice, that means re-checking evidence over time, watching for deterioration, and escalating when conditions change.
Step 3 Start with a defensible baseline and go deeper where impact justifies it#
A practical goal is a consistent baseline for all vendors, with deeper review where vendor impact warrants it.
For payment-related vendors, confirm whether processors are PCI DSS compliant and can demonstrate strong security controls. For cloud or infrastructure providers, verify the quality of contract protections, including whether service level agreements give you enough protection.
Do not substitute reputation for proof. If evidence is not checkable, pause and escalate based on impact.
Related: Expired Card Management at Scale: How Platforms Automatically Refresh Payment Credentials.
Define payment vendor risk by money movement stage#
Define vendor risk by functional impact on money movement, not by brand reputation. If a vendor can affect funds availability or handle sensitive data, scope it for closer review until evidence supports a narrower scope.
Step 1 Map the vendor to the stages it actually touches#
Start in pre-acquisition planning, before onboarding, and carry it into post-acquisition monitoring. Use the money-movement stages your product actually runs, then tie each touched stage to a third-party risk assessment scope.
For each vendor, keep one scannable record that states:
- stages touched
- data handled
- how the dependency could interrupt funds movement
Step 2 Separate risk types before review begins#
Keep these lenses separate from the start: regulatory non-adherence, operational failure, data breaches, and supply chain attacks. If they collapse into one generic security review, decision quality drops.
A single incident can span more than one lens, so assign at least one review question and one owner to each risk type, even when the same team covers more than one.
Step 3 Escalate by function and dependency level, not reputation#
Review depth should rise with risk, relationship complexity, and dependency impact. A well-known vendor may still need deeper review when the dependency is close to payout execution or sensitive data handling.
Check the dependency at supplier, product, and service levels. If failure at any level can disrupt payout operations, consider escalating review depth and controls.
Step 4 Record market and program coverage before onboarding#
Coverage and review requirements vary by context and regulatory guidance, so document scope before go-live. Record scope details such as market, program, legal entity, and excluded use cases.
Confirm compliance, legal, and operations are working from the same coverage record so regional limits surface during scoping, not during an incident.
For a step-by-step walkthrough, see Working Capital Management for Payment Platforms: How to Optimize Cash Between Collection and Disbursement.
Set risk tiers before you evaluate tools or vendors#
Set risk tiers before procurement compares tools or pricing. If you tier later, the evidence bar can drift under commercial pressure and the review turns into vendor-specific negotiation instead of a repeatable decision.
Step 1 Write tier entry criteria that combine business impact and compliance exposure#
Use internal tiers, for example low, medium, and high, with entry criteria that are explicit enough for two reviewers to place the same vendor in the same tier from the intake record alone. Because TPRM is broader than cyber review, include operational disruption, noncompliance exposure, unexpected cost, and data risk, not just security controls.
Keep intake scope broad enough to match real dependency risk. Suppliers, vendors, service providers, and contractors can all belong in scope when they affect payment operations or regulated data handling. A vendor that does not move funds directly can still require a higher tier if it can materially disrupt critical payment operations.
Run a consistency check by having compliance and operations tier the same intake independently. If outcomes differ because criteria rely on reputation or vague labels, tighten the trigger language until the deciding facts are obvious.
Step 2 Map controls and evidence to obligations, not preferences#
Define baseline versus enhanced controls through compliance framework mapping and your GRC evidence model, not internal habit. The test is simple: every requested artifact should answer a defined risk question in scope.
When cardholder data is involved, map evidence requests to relevant PCI SSC control areas for your use case. When card-not-present authentication is in scope, include EMVCo 3-D Secure relevance in the review. If neither applies, avoid expanding the checklist with unrelated requests.
In your GRC record, tie each artifact to the risk type it addresses and the review owner. If an item cannot be tied to a risk question or obligation, make it optional or remove it.
Step 3 Add automatic escalation triggers for enhanced due diligence#
Do not leave enhanced review to case-by-case debate. Define internal triggers in advance, such as dependencies tied to higher-risk payment flows or other critical controls in your environment.
Treat this as your governance rule, not a universal legal standard across all jurisdictions or business models. The value is consistency. Known triggers reduce pressure to lower review depth after a vendor is already preferred.
Ask for operational proof where the risk justifies it. Static-rule approaches can fail to keep pace with changing attack tactics, and over-weighting fraud blocking can hurt approval performance for legitimate transactions. For medium and high tiers, require evidence of how detection, review, and tuning work in practice, not just feature claims.
Step 4 Publish the tier artifact table and enforce the gate#
Publish a tier table that shows minimum evidence requirements before tool comparison starts. Exact documents vary by product and market, but the structure should be explicit in both policy and GRC.
| Tier | Onboarding artifacts to define in policy | Control evidence focus | Monitoring cadence in policy | Escalation owner |
|---|---|---|---|---|
| Low | Service description, business owner, data handled, dependency summary, legal entity details | Baseline evidence mapped to in-scope risks only | Periodic review plus event-driven updates | Business owner with procurement support |
| Medium | Low-tier artifacts plus data flow, subcontractor disclosure, governance contacts, incident contact path | Control documentation and sample monitoring outputs mapped in GRC | More frequent review than low tier, plus issue follow-up | Shared business owner and compliance review |
| High | Medium-tier artifacts plus enhanced review package for dependencies your policy flags as critical | Attestations, resilience evidence, remediation history, and framework-relevant proof, for example PCI SSC or EMVCo 3-D Secure where applicable | Highest-frequency review in your program plus immediate review on material change or incident | Compliance and legal, with executive escalation path |
Apply a hard internal gate: if a vendor cannot meet the minimum evidence set for its assigned tier, do not launch a pilot. That is a governance choice to prevent temporary exceptions from becoming permanent production dependencies.
Treat delay language as a live gap. If artifacts are promised only after contract signature, pilot launch, or later scale, record that as unresolved evidence risk and hold escalation decisions to the same standard.
For a practical look at ongoing payment controls, see A Guide to Transaction Monitoring for High-Risk Payments.
Prepare the onboarding evidence pack before vendor review starts#
Start with one internal review package before the onboarding review opens. If required evidence is missing, treat it as unresolved risk, not admin cleanup.
Step 1 Require a standard package before any review meeting#
Use the risk tier from the previous section to set the minimum package, but keep the structure consistent across vendors. Include control documentation and a short description of the data activity in scope; add incident history or summaries, subcontractor disclosures, and governance contacts when they are available and relevant to your risk review. Every new integration creates new data flows and new exposure points, so the package should show where that exposure begins.
Use a simple readiness check: can legal, compliance, and finance answer the same core questions from the same folder without requesting a second version? If not, intake is not ready.
Step 2 Ask for operational proof, not statements of intent#
If a vendor claims continuous monitoring, ask for proof that it is active. Useful evidence includes sample monitoring outputs, remediation tracking, issue-status reports, or a redacted example showing how an alert moved from detection to closure.
Focus on whether monitoring is real, reviewed, and tied to response. Post-deployment monitoring is necessary, and monitoring methods are still uneven, so do not accept broad claims without review ownership, update cadence, and documented failure handling. If dashboards or reports are only promised after contract signature or pilot launch, log that as a current evidence gap.
Step 3 Map each artifact into your GRC record and, if relevant, SOC expectations#
Treat the package as an indexed evidence set, not a document dump. Map each artifact to the TPRM lifecycle checkpoints you need at onboarding: Identify, Assess, Mitigate, Monitor, Respond.
If your internal process uses SOC-oriented criteria, request artifacts you can cross-map to those expectations, but do not treat a single attestation as sufficient on its own. In your GRC record, capture artifact owner, document date, review owner, and the risk or control supported so later revalidation is straightforward.
If EU cybersecurity obligations are in scope for your markets, keep a mapping note for NIS2-related technical and methodological cybersecurity risk-management measures. Keep this as traceability, not a universal requirement.
Step 4 Build one intake folder so every function reviews the same evidence#
Create one intake folder structure for your team before requests go out, and require all submissions to follow it. One practical internal structure is: 01 scope and service description, 02 controls and security, 03 incidents and remediation, 04 subcontractors, 05 governance and audit responses, 06 contracts and approvals. Maintain one index with document name, version date, vendor owner, and internal reviewer.
The goal is consistent review: the same evidence, the same visible gaps, and the same version history across legal, compliance, and finance.
For more on keeping vendor records, contracts, and payment terms in one place, see Procurement Data Management for Platforms: How to Centralize Vendor Contracts and Payment Terms.
Run due diligence with clear go or no-go checkpoints#
Once intake is complete, make the checkpoint decision and treat high-impact evidence gaps as launch blockers until remediation is verified. In TPRM, this review is part of risk control, not post-decision paperwork, and the lifecycle still applies: Identify, Assess, Mitigate, Monitor, Respond.
Step 1 Score the vendor against four decision checkpoints#
A practical way to run the go or no-go call is to use four checkpoints: control sufficiency, legal fit, operational resilience, and escalation readiness.
| Checkpoint | What to verify |
|---|---|
| Control sufficiency | Evidence shows required controls are real, current, and owned. |
| Legal fit | Service model, subcontractor use, and data handling fit your contractual and compliance boundaries. |
| Operational resilience | The vendor can continue or recover during disruptions that affect payments or data handling. |
| Escalation readiness | Both sides can identify who acts, who decides, and what evidence is produced during incidents. |
For key artifacts, verify document date, vendor owner, internal reviewer, and the control or risk supported. If ownership or currency is unclear, treat it as an evidence gap.
Step 2 Treat high-impact evidence gaps as launch blockers#
Use a strict rule for high-impact controls: do not launch based on promises. A statement like "report available after signature" or "process exists but is undocumented" is not closure for high-impact items.
When third parties handle user information, your organization remains accountable for compliance. Approval records should therefore capture the evidence reviewed, residual risk, and why any exception is acceptable.
Step 3 Run scenario tests before you approve#
Scenario tests are where the paperwork meets reality. Run them before approval to confirm the vendor's operating response matches the submitted evidence.
| Scenario | Confirm |
|---|---|
| Vendor outage on payout day | Detection, communications, fallback, and recovery evidence. |
| Compliance-control failure | Identification, containment, review ownership, and transaction handling. |
| Delayed offboarding | Revocation of access and credentials, data return, and subcontractor touchpoints. |
| Unresolved data exposure | Escalation triggers, scoping method, response owner, and investigation or closure artifacts. |
The key red flag is mismatch. If the vendor claims continuous monitoring but cannot show practical evidence of alerts, issue tracking, or review ownership, assume the process is weaker than described.
If you operate in an EU financial context, resilience review may need to reflect expectations around ICT provider resilience. Treat that as a context signal for scrutiny, not a universal checklist.
Step 4 Record the outcome with sign-offs and RACI ownership#
Use this as an internal governance template for auditable decisions. Sign-off titles and RACI structure should match your own program requirements.
| Outcome | When to use it | Suggested sign-offs | RACI ownership to record |
|---|---|---|---|
| Go | High-impact controls evidenced, legal fit confirmed, escalation contacts named, no material open gaps | Accountable business owner plus legal, compliance, and risk reviewers as applicable | R for vendor owner and reviewer leads, A for final decision owner, C for finance or ops as needed, I for affected stakeholders |
| Conditional go | Only lower-impact gaps remain, remediation dates assigned, residual risk accepted in writing | Same as above, plus explicit exception approval | Same RACI, plus each open item, target date, and closure verifier |
| No go or pause | High-impact control gap, unresolved legal issue, weak resilience response, or unclear escalation path | Final decision owner and control-function reviewers acknowledge pause | Record remediation owner, re-review owner, and restart approver |
Final check: one record should let an auditor, executive, or incident responder understand exactly why the vendor was approved, conditionally approved, or paused.
Related reading: Liquidity Management for Payment Platforms With Funds Ready to Pay.
Need an implementation reference for evidence capture, payout controls, and audit-ready records? Review the Gruv docs.
Negotiate contract terms that preserve control after go-live#
If a risk finding can affect approval, it should be reflected in enforceable contract language before launch. Do not let the evidence review live only in notes while the signed agreement defaults to generic vendor terms.
Step 1 Convert due diligence findings into clause requests#
Turn each material finding from the approval record into a contract ask. This is how the assessment becomes ongoing control, especially when vendors can access your systems, data, and customers and your organization remains accountable for compliant third-party handling.
For high-impact vendors, use a short negotiation matrix with four columns: risk finding, required clause, business owner, and fallback position. Use it to align legal, compliance, and procurement when language is negotiated around contractual accountability, incident communication, remediation responsibilities, or termination rights. Verify that every open risk in the go or conditional-go record maps to either signed contract text or a written, approved exception. If it does not map, treat it as a control gap.
Avoid vague language for launch-critical issues. If a control was not clearly evidenced in review, do not accept wording that makes post-go-live remediation optional.
Step 2 Lock in continuous monitoring and change visibility#
The contract should support continuous monitoring and reevaluation after onboarding. Require access to the information your team needs to reassess risk as conditions change, including material changes in service, controls, ownership, security posture, or subcontractor use.
Define what the vendor must provide so monitoring is operational: current control artifacts when reasonably requested, notice of material service or control changes, and visibility into subcontractors involved in the service when relevant. Vendors can change ownership or experience cybersecurity incidents over time, so change-notice terms are part of maintaining control, not optional overhead.
Before signature, confirm the contract preserves the same monitoring signals you reviewed during onboarding.
Step 3 Make offboarding enforceable, not assumed#
Offboarding obligations should be explicit in the contract. Where offboarding is relevant, data return or deletion, credential revocation, access removal, and transition support can be written as duties so expectations are clear.
Do not rely on goodwill for unwind steps. If responsibilities are not written, oversight gaps can increase contractual and legal risk. Cross-check offboarding language against your delayed-offboarding scenario from review. If the clause does not support that scenario, treat the draft as incomplete.
Step 4 Align notice paths with your internal operating model#
Notice paths for breaches and service failures should fit your internal operating model so alerts reach the right owners quickly. The contract should identify who must be notified and which events trigger notice.
Use your operating model as the test. If compliance, legal, and operations have different incident responsibilities, the contract routing should support that split instead of funneling everything through one commercial contact. Missing formal process can fail audits or regulatory reviews, and oversight gaps can lead to contractual violations or legal liability. The signed agreement should mirror how your team will actually respond when something breaks.
Monitor live vendors with KRIs that trigger action#
After go-live, control should include ongoing post-acquisition monitoring, not just the onboarding review. Keep monitoring scoped, tied to concrete signals, and documented in the same vendor risk record used for onboarding decisions.
This also lines up with lifecycle guidance: the April 2025 GSA C-SCRM Acquisition Guide describes assessment activity across the acquisition lifecycle and explicitly includes post-acquisition monitoring. It also frames scope across suppliers, products, and services, which is a useful reminder to monitor what is actually live in each market, not just what was approved at contract signature.
Set your monitoring cadence and scope based on your internal vendor tiering, then confirm the owner can reliably access each data source. If a metric depends on ad hoc vendor exports, it is less likely to hold up during incidents or rapid change.
Use a compact KRI register so each signal has an owner and a defined response path:
| KRI definition | Owner | Data source | Review frequency | Tolerance | Corrective action |
|---|---|---|---|---|---|
| Documented, evidence-based signal | Named function owner | System or report of record | Set by risk tier | Agreed internal limit | Pre-agreed escalation and remediation step |
Treat scope changes as monitoring events. If a vendor expands from one country to additional markets or adds new services, reassess KRIs and controls for the newly live footprint before you treat the relationship as unchanged.
When a KRI breaches tolerance, move from reporting to action: log the breach, assign remediation ownership and target dates, and track status until closure in the vendor risk record. That is what makes continuous monitoring defensible in audits and practical in operations.
Escalate fast when thresholds are crossed#
Treat a KRI breach as a potential escalation event when it changes risk posture, not just dashboard color. If one incident combines regulatory non-adherence and operational disruption, route it through compliance and legal in the same reporting cycle and keep one record in your vendor risk file.
Step 1#
Start with a severity matrix so the same facts lead to the same decision path. Use three lenses together: compliance impact, customer impact, and operational disruption.
| Severity | What qualifies | Immediate internal action | Evidence to preserve |
|---|---|---|---|
| Moderate | Isolated control failure, limited customer effect, contained operational issue | Tighten controls for the affected process, increase review frequency, assign remediation owner | Incident summary, KRI breach record, affected market or process, owner assignment |
| High | Clear regulatory non-adherence or broader customer impact, with service degradation or repeated exceptions | Escalate to compliance and legal, evaluate temporary control or use restrictions, notify executives through your internal chain | Legal and compliance assessment notes, vendor response, decision log, contract clause referenced |
| Critical | Compliance breach plus material operational disruption affecting live payment activity or multiple markets | Immediate joint compliance and legal escalation, executive decision on continued use, external review where law or contract requires it | Full chronology, approvals, communications, remediation demands, contingency actions, board pack materials |
Verification point: test the matrix on a recent incident. If two reviewers land on different severities, tighten the category definitions.
Step 2#
Map each severity to actions your team can execute immediately. Third-party relationship risk management is risk-based, and the June 6, 2023 interagency guidance is explicit that programs should scale to risk, complexity, and organizational profile.
For payment vendors, your internal playbook can include temporary control tightening, contractual review, governance escalation, and external review when obligations require it. For each action, define the owner, approval path, and system of record.
Step 3#
Handle compliance breach plus operational disruption as one joint event by default. Have compliance and legal review the same incident package in the same reporting cycle to avoid split decisions and mixed instructions to the vendor.
Include the KRI trigger, customer or transaction impact, affected jurisdictions, vendor explanation, contractual rights, and any open remediation from earlier monitoring. This single package supports later audit, board, or partner review.
Step 4#
Tie escalation outcomes to your offboarding framework before you need it. Because lifecycle guidance covers all stages of third-party relationships, escalation paths should connect remediation decisions with replacement or termination review when issues persist.
Document serious issues with formal governance discipline: clear issue statement, management response, accountable owner, and evidence of executive or board acknowledgment. The FDIC examination framework is a useful reference point here because it includes explicit governance artifacts such as MRBA and director or trustee signatures.
Assign ownership and reporting so decisions stay auditable#
Use one ownership map and one reporting trail for vendor decisions, or your audit record can fragment. When compliance, legal, finance, and operations each track decisions separately, unresolved gaps can hide behind an "approved" status.
Step 1#
Create one ownership grid, for example a RACI, for the full vendor lifecycle: onboarding, monitoring, escalation, and offboarding. Keep it at the decision level, not the task level, and assign one named accountable owner for each decision, for example evidence closure, temporary exception acceptance, heightened review, and offboarding start.
Treat unclear shared accountability as a risk signal. If an exception is owned by two groups together, due dates, approval basis, and closure evidence can slip, which can contribute to reporting errors or sanctions-screening gaps.
Step 2#
Set an operating and senior-review cadence from the same source record, for example monthly and quarterly. In both views, combine key risk indicators with unresolved remediation items so open fixes are reviewed as part of current risk posture.
Use a consistent set of fields across both views, such as current tier, KRI status, open remediation items, accountable owner, due date, decision taken, and evidence link. As a verification check, pick one vendor escalated last quarter and confirm the summary ties back to system evidence showing what was checked and when, including timestamped history.
Step 3#
Keep board-facing reporting concise, but traceable to full GRC evidence. Each summary statement should map back to the underlying incident package and decision log.
For exceptions, assign one accountable owner by person, not department, and define a clear closure condition. If closure language is vague, exceptions can roll across review cycles and become normalized.
Common mistakes that create avoidable regulatory surprises#
Avoidable surprises usually come from process drift, not obscure rules: treating review as one-time onboarding, letting inventory fragment, accepting partial review, and approving vendors on security checks alone.
| Mistake | Grounded alternative |
|---|---|
| Treating review as one-time onboarding | Treat third-party risk assessment as a recurring control and keep a current record of last review date, next revalidation date, KPI status, and one accountable owner. |
| Letting inventory fragment | Use a centralized vendor inventory and confirm procurement contracts, finance records, and onboarding files are consolidated in one repository and kept current by one accountable function. |
| Accepting partial review | For high-impact vendors, treat the decision as pending closure rather than approved with follow-up, and require a named owner, due date, and closure proof for any exception. |
| Approving vendors on security checks alone | Review security alongside procurement and compliance inputs, and include onboarding and offboarding in the same control scope. |
Step 1#
Treat third-party risk assessment as a recurring control, not a launch gate. For each live high-impact vendor, keep a current record of last review date, next revalidation date, KPI status, and one accountable owner.
This is a common gap: one cited split shows 41% vs 14% between organizations that view continuous monitoring as key and procurement professionals who use it to assess suppliers. If revalidation is not scheduled and tracked, continuous monitoring is not operating in practice.
Step 2#
Use vendor tools to organize inputs, not to set your standards. Tools can support the process, but your decision criteria should still come from your control requirements.
Use a centralized vendor inventory as the checkpoint: confirm procurement contracts, finance records, and onboarding files are consolidated in one repository and kept current by one accountable function. Separate lists across teams create duplicate records and weaker oversight. 86% of surveyed professionals reported silos hurting risk management.
Step 3#
Do not accept partial review for high-impact vendors because of launch pressure. If required evidence is missing, treat the decision as pending closure rather than approved with follow-up.
For any exception, require a named owner, due date, and closure proof. Without those three fields, temporary exceptions are harder to close and can persist past the original urgency.
Step 4#
Do not run security-only reviews. Security is necessary, but it should be reviewed alongside procurement and compliance inputs so key risk signals are not missed.
Include onboarding and offboarding in the same control scope. Weak onboarding and offboarding practices can leave exposure after the contract ends.
Copy and paste checklist for your first 30 days#
Use the first 30 days to lock in five controls: inventory, evidence, approval, monitoring, and expansion guardrails. If a vendor cannot meet the evidence needed for review, treat that as a hold, not a launch-speed exception.
Step 1 List every payment vendor and set the initial tier#
Start with a complete inventory of every third party involved in payment activity, including payment processors and adjacent services your flows depend on. For each vendor, record the service, internal owner, systems or data involved, and the scope of the third-party risk assessment.
Classify vendors into your risk-tiered process using consistent, simple logic. Two practical checks are whether the vendor can access sensitive customer data and whether failure would disrupt a critical payment activity. If those answers are unclear, pause tiering until they are clear.
Step 2 Collect baseline Due Diligence and map it into one record#
Build one baseline review pack and store it in a central record shared across compliance, legal, finance, and operations. Capture control evidence, ownership, data-access scope, and whether the vendor appears compliant with obligations such as GDPR or CCPA where relevant.
Map evidence into one risk record as you collect it. If card-related scope is involved, note whether PCI DSS 4.0 applies, effective March 2025. Verification check: each mapped control has either attached evidence or a clearly logged gap. Avoid spreadsheet-and-email tracking that creates stale records and weak visibility.
Step 3 Gate go-live with tier-specific checkpoints and documented ownership#
Approve go-live only when tier-specific checks are complete and the decision is explicit. The record should show what evidence was reviewed, who made the decision, and when it was made.
If a high-impact control is unverified, hold launch. Future remediation is not the same as completed review. Verification check: one record shows pass, hold, or approved-with-exception status, with decision ownership and supporting evidence.
Step 4 Launch Continuous Monitoring with named KRIs#
After go-live, shift from one-time review to continuous monitoring so changes in vendor risk are caught as they happen. Use a small KRI set your team can actually review, assign owners, and define escalation actions for meaningful risk changes.
Practical KRIs include changes in data access, compliance status changes, and service issues affecting payment activity. Verification check: each KRI has a data source and escalation path documented before expansion.
Step 5 Recheck risk before expansion#
Before expanding a vendor to more markets, products, or exposure, run a scoped re-review and update the same central risk record. Focus on what changed in data access, compliance exposure, and operational dependency.
At minimum, document what changed, what controls were rechecked, and whether expansion is approved or held. If expansion is moving faster than review and monitoring updates, stop expansion first.
If you are still building your vendor evaluation process, see How to Find Vendors for Your Platform and Vet Third-Party Providers at Scale.
Conclusion#
The goal is not more controls. It is better control fit by vendor criticality, backed by clear records and clear escalation.
Step 1 Match control depth to real vendor criticality#
A lean program can still be a serious one when tier logic is consistent and documented. Vendors with continuity-critical impact or meaningful data access often need deeper review and tighter monitoring than low-impact tools. A breakdown at one point in the chain can ripple into operational disruption and trust damage, so focused scrutiny belongs here.
Use a simple defensibility test: in one record, can you show why Vendor A received baseline review and Vendor B received enhanced review? If you cannot show service scope, business impact, data-access profile, and internal owner, tiering is probably intuitive rather than defensible.
Step 2 Keep evidence closure visible, not implied#
A defensible program is one you can prove without rebuilding the story from email threads. The key artifact is a current record that ties together the third-party risk assessment, reviewed evidence, open gaps, approval status, and the named owner for follow-up.
For a high-impact vendor, that record should show tier logic, review closure, recent continuous monitoring results, key obligations, and ownership in one place. If those elements are split across systems, visibility is weak even when the work was completed.
A common failure mode is partial closure during onboarding that never returns to a clear pass, hold, or exception state. Without a formal process, organizations can fall short in audits or regulatory reviews, and legal exposure is harder to manage when the evidence trail is weak.
Step 3 Use monitoring signals and contracts to make post-go-live control real#
Programs drift when assessment is treated as one-and-done. Risk-aware review includes continuous monitoring and reevaluation because risk changes after launch.
Monitoring signals only help when they trigger action. When risk signals worsen, your program should drive a defined response, including heightened review or constrained expansion where appropriate. Documented obligations and ownership are what make those responses workable after go-live.
As a final check, map your program to the lifecycle: Identify, Assess, Mitigate, Monitor, Respond. Keep expanding only when risk justifies it and evidence still supports the decision. If market-specific obligations are unclear, get specialist legal or compliance advice before widening scope.
If you want to pressure-test tiering, monitoring triggers, and escalation paths for your markets, talk to Gruv.
Frequently Asked Questions
What is third-party risk management for payment platforms in practical terms?
In practical terms, third-party risk management for payment platforms is the process of identifying, assessing, and controlling risks introduced by external partners that can access your data or affect money movement. The article frames it as a lifecycle: Identify, Assess, Mitigate, Monitor, Respond, with clear ownership, evidence, and escalation from the start.
How do we vet a payment vendor before onboarding without slowing launch timelines?
Set accountability and risk tiers before procurement compares tools or pricing, then require a standard evidence package before any review meeting. Keep one intake folder and one scannable record so legal, compliance, finance, and operations review the same evidence. If required evidence is missing, treat it as unresolved risk and hold go-live for high-impact gaps.
What should we monitor monthly vs quarterly after a vendor goes live?
The article says review cadence should follow your internal vendor tiering rather than one fixed schedule for every vendor. Use the same source record for operating and senior review, for example monthly and quarterly, and include current tier, KRI status, open remediation items, accountable owner, due date, decision taken, and evidence link. Reassess when scope changes, such as new markets, services, or material changes in controls or subcontractor use.
When should a payment vendor incident be escalated to legal leadership?
Escalate to legal leadership when an incident reaches high or critical severity, especially when there is clear regulatory non-adherence, broader customer impact, service degradation, repeated exceptions, or material operational disruption. The article also says to treat compliance breach plus operational disruption as one joint event by default and route it through compliance and legal in the same reporting cycle. Preserve the incident package, vendor response, decision log, contractual rights, and remediation status in one record.
How do we avoid overbuilding controls for low-impact vendors?
Avoid overbuilding controls by setting risk tiers before review and using a consistent baseline for all vendors, with deeper review only where impact warrants it. Map every requested artifact to a defined risk question or obligation, not internal preference. If a request is not tied to the risk in scope, make it optional or remove it.
Who should own final vendor risk decisions across compliance, legal, finance, and ops?
Final vendor risk decisions should have one named accountable owner, supported by a single RACI that covers onboarding, monitoring, escalation, and offboarding. The article suggests recording R for vendor owner and reviewer leads, A for the final decision owner, and C or I for other stakeholders as needed. Sign-offs can include the accountable business owner plus legal, compliance, and risk reviewers as applicable.
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
- acquisition.gov/far/2.101trusted
- buy.gsa.gov/api/system/files/documents/c-scrm-acquisitio...trusted
- department.va.gov/privacy/wp-content/uploads/sites/5/2024/08/F...trusted
- department.va.gov/procurement-acquisition-and-logistics/nation...trusted
- fdic.gov/resources/supervision-and-examinations/exami...trusted
- fdic.gov/news/press-releases/2023/pr23047a.pdftrusted
- federalregister.gov/documents/2023/06/09/2023-12340/interagency-...trusted
- federalreserve.gov/SECRS/2019/November/20191118/OP-1670/OP-1670...trusted
Educational content only. Not legal, tax, or financial advice.
Related Posts

The Freelance Payment Penalty: A Modeled Audit of Platform Fees, FX Spreads, and Payout Delays
The money rarely disappears through a single, easy-to-spot fee. The real loss is stacked. A marketplace takes its commission, a processor adds a charge for international cards, a bank or payment company converts the currency at a spread, a platform holds the funds before release, and a wire sheds a little to intermediaries on the way in. Each layer looks defensible on its own, but the worker feels the combined result as a smaller deposit and a later payday.

How to Respond to a Subpoena for Business Records
Move fast, but do not produce records on instinct. If you need to **respond to a subpoena for business records**, your immediate job is to control deadlines, preserve records, and make any later production defensible.

A US Expat's Guide to Investing in UCITS ETFs to Avoid PFIC Issues
The real problem is a two-system conflict. U.S. tax treatment can punish the wrong fund choice, while local product-access constraints can block the funds you want to buy in the first place. For **us expat ucits etfs**, the practical question is not "Which product is best?" It is "What can I access, report, and keep doing every year without guessing?" Use this four-part filter before any trade: