
Quick Answer
Hidden AP inefficiencies are recurring breaks across approvals, exceptions, retries, and handoffs that quietly slow cycle time and weaken cash-flow visibility. Spot them by baselining cost per invoice, first-time error-free disbursements, and cycle time, then tracing one invoice or payout end to end with approval logs, payout status history, webhook delivery records, and posting evidence to find waits, duplicate touches, and missing ownership.
Where Hidden AP Inefficiencies Start#
Hidden AP inefficiencies are often a pattern problem, not a single-event problem. Small repeats across approvals, exceptions, and handoffs can quietly erode cycle-time control and cash-flow visibility.
Recognize the real unit of failure#
Start by tracking repetition, not drama. Accounts payable (AP) is the short-term debt a business owes suppliers or vendors for goods or services already received, and AP management is part of internal control and cash-flow management. In teams where AP work intersects with payout operations and product or engineering handoffs, recurring small breaks can compound fast.
Treat isolated misses as signals, not exceptions to ignore. A delayed approval on an invoice due in 30 or 60 days, a manual status check, or a repeated rework touch may look minor on its own. In aggregate, those patterns can create real operating drag.
A simple checkpoint: can you trace one invoice or payment from receipt to approval to payment transmission, including where it waited, who touched it, and what record exists at each step? If that trace depends on memory or manual exports, you already have enough signal to investigate.
Use diagnostics that can survive scrutiny#
Use measurable operating signals, not vague "best-in-class" language. AP benchmarking commonly uses:
- total cost per invoice processed
- percentage of disbursements that are first-time error free
- cycle time from invoice receipt to payment transmitted
You do not need a perfect benchmark on day one. You need a baseline that is clear enough to show whether the problem is mainly cost, error, or delay.
Value Stream Mapping (VSM) helps because it documents each process step and makes waste visible across both the work itself and the information needed to move it forward. If the current path is not clear, automation can hide friction instead of removing it.
Keep the scope tight enough to act#
This article focuses on operational decisions in platform finance teams. It is most useful where AP, payout execution, and engineering dependencies can create hidden drag, and where that drag can be diagnosed with traceable evidence. It does not assume one benchmark or one tool choice guarantees improvement.
Cross-industry and aggregate payments benchmarks are useful for orientation, but they are not an operating playbook for your team. Your results still depend on approval logic, exception handling, payment paths, and ownership when work stalls.
Start with facts you can verify. If you can measure cycle time, first-time accuracy, and wait states, you can prioritize fixes. If you cannot, your first job is to make waste visible enough that finance, ops, and engineering are working from the same picture.
For a step-by-step walkthrough, see IndieHacker Platform Guide: How to Add Revenue Share Payments Without a Finance Team.
What silent killers look like in platform finance operations#
Once you have a baseline, the next job is to name the breaks that hide inside routine work. Silent killers are recurring D.R.O.P.S. breaks that look minor in one queue but create real drag across AP, payout execution, and record visibility: delays, redundancies, overlaps, poor integration, and siloed communication.
Name the D.R.O.P.S. pattern#
In platform workflows, delays are not just late approvals. They also show up as approved items waiting on payout release, webhook-driven status updates arriving late, or reconciliation stalling because a status change never makes it back into finance records.
Redundancies show up when AP, ops, or support re-enter data that already exists somewhere else. Overlaps show up when multiple teams can change the same exception, but nobody clearly owns the final outcome.
Poor integration can emerge in embedded finance setups, where financial services are integrated into a nonfinancial product across multiple systems. Siloed communication is the human-side failure mode. One team may see "paid," another sees "pending review," and no shared record resolves the mismatch.
Anchor examples in platform paths#
These problems become visible when you trace a real platform path, not a generic AP checklist. A payout can look complete in a provider view while still missing from your records, leaving AP with unresolved month-end questions. The same issue appears in payout batches, where a batch can be released even though a subset fails or retries outside the main flow.
Use one checkpoint: trace a recent invoice or payout through approval, transmission, batch inclusion, and posting visibility. If that trace depends on chat messages, spreadsheet notes, or memory, you are looking at hidden operational debt.
Check why it stays invisible#
These problems can stay hidden when teams optimize local KPIs without shared end-to-end evidence. AP can hit approval targets, ops can hit release timing, and engineering can confirm event receipt while audit-trail gaps and reconciliation friction build across tools.
Treat missing chronology as a red flag. An audit log should show who did what and when. In webhook-driven flows, delivery can lag, and failed events can be resent for up to 3 days. Retry handling has to prevent the same event from being processed more than once. If you cannot prove status changes, retries, and final posting impact from the audit trail, treat the issue as systemic.
Related: Finance Operations Priorities for Payment Platform CFOs.
What to prepare before you start diagnosing#
Before you chase root causes, build an evidence set that can survive disagreement. If finance says "held," ops says "sent," and engineering says "delivered," you need artifacts that let one timeline win.
Collect the minimum evidence set#
Start with four exports from the same recent period:
- your reconciliation export (or internal equivalent)
- AP approval logs
- payout status history
- event timelines
The point is time alignment. A payout reconciliation report ties the bank payout to the batch of transactions it settles, and AP approval history can verify each recorded invoice action.
For the transaction view, pull history that reconstructs movement across charges, refunds, and payouts. For one sample invoice or payout, line up approval time, payout release time, bank payout reference, and final posting impact without asking anyone to search chat history.
A common operational failure mode is mismatched date windows. If AP exports by calendar month but payouts settle on a different cadence, you can end up diagnosing timing noise instead of defects.
Verify the technical surfaces before reading the data#
Check the delivery layer before you treat duplicate or missing events as proof of a broken process. Start with webhook delivery logs, retry behavior, and idempotency handling.
If you are working in Stripe, undelivered webhook events are queryable. Automatic retries can continue for up to three days, and recovery views are limited to events from the last 30 days. Export logs early when an issue is older or recurring. For retry safety, confirm create or update requests use idempotency keys and that those keys are stored somewhere inspectable.
A practical checkpoint is to pick one event that looks duplicated and prove whether it came from a legitimate retry path or from separate submissions. If you cannot see idempotency-key or delivery history, the diagnosis is still guesswork.
Pull policy context before labeling a queue "stuck"#
Policy checks can affect processing outcomes, so pull KYC/AML and VAT-validation context before you label a delay as waste.
For identity controls, keep the point precise: CIP under AML rules is risk-based, and legal-entity onboarding can require beneficial ownership verification. For VAT, keep scope exact: VIES checks apply to EU cross-border VAT registration status.
A red flag is when teams cannot distinguish policy holds from processing failures in their own records. If records show a payout paused for verification, your evidence set should make that visible.
Assign a small decision group with authority#
Use a small cross-functional group with enough authority to resolve tradeoffs quickly, for example finance, ops, and engineering owners.
Give that group only three decisions: what counts as a true defect, what is policy-driven delay, and what needs a permanent fix versus monitoring. After the first review, each recurring issue should have one decision owner and one missing-artifact list. If you end with competing narratives and no owner, close the evidence gaps before you expand the diagnosis.
Map your money path and handoffs end to end#
Once the evidence pack is in place, map the current state before you debate fixes. If money movement, status movement, and ownership are not visible on the same path, teams can mislabel expected async delay as AP failure or blame policy and engineering holds on the wrong function.
Draw the real path, not the intended one#
Trace one transaction family from invoice intake to payout settlement using the path your team follows today, including manual checkpoints and exception branches. Use a baseline path like this:
- invoice received
- invoice reviewed
- AP approved
- payment or payout instruction created
- provider acknowledgment received
- webhook update received
- posting completed
- payout batch assigned (if relevant)
- bank settlement confirmed
Branch the map where your model can change responsibility, for example merchant of record, and where virtual accounts can change routing or reconciliation artifacts.
A practical check is to prove one artifact per stage for one sample invoice: approval record, outbound instruction, webhook event, posting entry, and payout reference. If one is missing, the handoff is still unclear.
Observe the work with VSM and Gemba Walks#
Do not stop at the diagram. Use Value Stream Mapping to capture both kinds of flow: the movement of money and the information needed for the next decision. Then run Gemba Walks on that same path to observe real waits, re-entry, and unclear ownership across AP, ops, and engineering.
For each step, ask:
- what artifact do you trust?
- what makes you stop?
This is often where hidden queues show up. A task marked "finance pending" may actually be sitting in an engineering retry queue, and an "ops delay" may be an asynchronous provider update. Webhook-driven updates are often asynchronous, so some lag is normal. The job is to separate expected waiting from unlabeled internal waiting. Record touch time and wait state in plain language for each step.
Build a handoff table your triad can use#
Reduce each boundary to a row so evidence and ownership are explicit. Write recovery actions clearly enough that someone can execute from the row alone.
| Handoff | System of record | Required artifact | Common failure mode | Recovery owner |
|---|---|---|---|---|
| Invoice intake to AP queue | AP tool or intake inbox | Received invoice record with timestamp and vendor/payee details | Missing fields, duplicate submission, manual re-entry from email | AP owner |
| AP approval to payment instruction | AP approval log | Approved status plus outbound instruction/request ID | Approved item never sent, wrong payee selected, retry creates duplicate without idempotency key | Finance ops or engineering owner |
| Provider update to internal status via Webhooks | Webhook delivery logs | Event ID, delivery attempt history, mapped internal status | Event delayed, not consumed, replayed without dedupe | Engineering owner |
| Internal status to posting | Event timeline or posting system | Posting entry tied to transaction or payout reference | Status changed but posting not completed, wrong amount or timing | Finance systems or engineering owner |
| Payout Batch to bank settlement | Payout status history or bank payout report | Batch ID and settlement reference | Batch closed later than assumed, item omitted from batch, settlement reference missing | Treasury or payout ops owner |
Mark expected async behavior versus true failure#
Classify each boundary as one of three types:
- immediate
- async but expected
- exception-only
For async steps, look for proof-of-progress artifacts such as a request ID, webhook delivery attempt, pending posting entry, batch assignment, or settlement reference. Do not treat a stale read by itself as failure. Eventual consistency can make recent writes temporarily invisible, and payout batches can add planned interval latency.
Escalate when there is no next artifact, no owner, and no retry path. When retries are needed for create or update calls, confirm idempotency keys are used so a temporary consistency window does not create duplicate side effects.
We covered this in detail in Real-Time Reporting Metrics Platform Finance Teams Can Actually Control.
Spot early warning signs before margin impact becomes obvious#
The point of diagnosis is to catch repeat signal clusters early, because single incidents often do not tell you whether margin risk is building. Focus on patterns that recur across AP, ops, and engineering, not isolated late payouts or one-off tickets.
Track symptom clusters, not isolated incidents#
Track four signals together: AP aging drift, repeat exceptions, duplicate-touch tickets, and reconciliation lag in Reconciliation Pack outputs. One signal can be noise. When two or three move together, treat that as a cue to check for either an operating defect or a policy bottleneck.
Use your Payables Invoice Aging Report to compare overdue amounts and how long installments have been due by supplier. Do not force generic 30/60/90 thresholds. Compare current aging against your own recent baseline and flag items that sit longer without a new artifact or named owner.
For each cluster, validate one sample item across three records where available: AP status, Reconciliation Pack output, and payout or event history. If one system shows pending and another shows posted, treat that mismatch as an investigation signal rather than assuming it is a normal queue effect.
Tag policy-gated delays separately from broken paths#
Separate expected policy holds from broken integration paths before you escalate. If KYC requirements are not fulfilled, payout blocking is expected and should not be handled like a failed integration.
Use at least two incident tags: policy gate and integration path. Put verification-related holds in the first bucket. Put missing webhook delivery or processing evidence, unmapped provider status, or status changes without downstream posting in the second.
Use payout status context before escalating. pending or in_transit can be normal states, so latency alone is not enough. Escalate when the next expected artifact is missing, such as no provider event, no internal status progression, or no posting follow-through.
Run RCA only on repeats and require evidence#
Run Root Cause Analysis on repeat incident classes, not one-offs. If an exception type recurs, the corrective action should remove the cause and prevent recurrence, not just clear one case.
Require evidence before assigning blame: audit trail records and webhook delivery records. The audit trail should reconstruct the sequence of events, and webhook delivery records should show whether events were delivered, failed, or still within a retry window.
Timebox the investigation to documented windows. Undelivered webhook events can be retried for up to three days, and event retrieval guidance covers the last 30 days, so delayed triage can hide the evidence you need.
Flag manual work that is hiding product debt#
Repeated manual fixes usually point to system debt, not just extra effort. Watch for recurring invoice recoding after intake and payout retries handled by people instead of stable retry controls.
When payout create or update calls are retried, verify idempotency keys are used so repeats do not create duplicate operations. If people have to manually confirm whether a retry already ran, treat that as a control gap.
Use the same test for invoice coding. If AP keeps correcting the same fields before approval, that may indicate a weak intake contract and labor masking the underlying defect.
This pairs well with our guide on Catching Payout Errors Early in High-Volume Platform Operations.
Prioritize fixes by impact and controllability#
Once repeat issues are evidenced, stop treating every defect as equal. Rank the next 30 days on two axes, margin risk and execution controllability, and as a default, move record-integrity issues ahead of pure speed work.
Score margin risk and controllability separately#
Use a simple 1-5 score for each issue and keep the scale stable for the month.
For margin risk, score both likelihood and consequences, then set consequence levels using your risk appetite and tolerance. Issues tied to duplicate or erroneous disbursement risk, reconciliation breaks, or reporting mismatches will often rank above delays that do not affect downstream posting.
For controllability, score what your team can land and verify within 30 days. High-controllability issues usually have one clear owner, one queue, a known failure mode, and enough evidence in operating records. Low-controllability issues usually span teams, systems, or unclear ownership. If two items tie on effort saved, keep the higher-risk item ahead.
Put Ledger and Audit Trail defects ahead of speed work by default#
If an issue affects record integrity or Audit Trail completeness, treat it as a control issue before you tune throughput.
The reason is practical. Records need to reflect transactions accurately, and the trail needs to be strong enough to reconstruct event sequence and trace from source transaction to reporting and back. If you cannot trace one affected transaction end to end, the evidence is already weak.
Use a strict check. For one transaction, confirm the source event, status changes, posting outcome, and reportable result without manual reconstruction. Missing hops belong in the top priority band.
Ship tactical fixes when the defect is contained#
When a repeated defect is contained to one queue, has a clear owner, and has lower control impact, ship the tactical fix now and defer the larger redesign.
Good tactical candidates are isolated mapping gaps, retry-control defects, or intake validation issues that repeatedly create manual AP rework. Validate them in normal operations by checking first-time quality, fewer duplicate or erroneous disbursements, and fewer exceptions in that same queue.
If the same failure pattern appears across multiple payment and posting surfaces, treat the local patch as containment, not closure.
Compare payment paths with a decision table#
Use one decision table so path choices stay measurable. Compare AP effort saved, failure-rate reduction, and risk exposure.
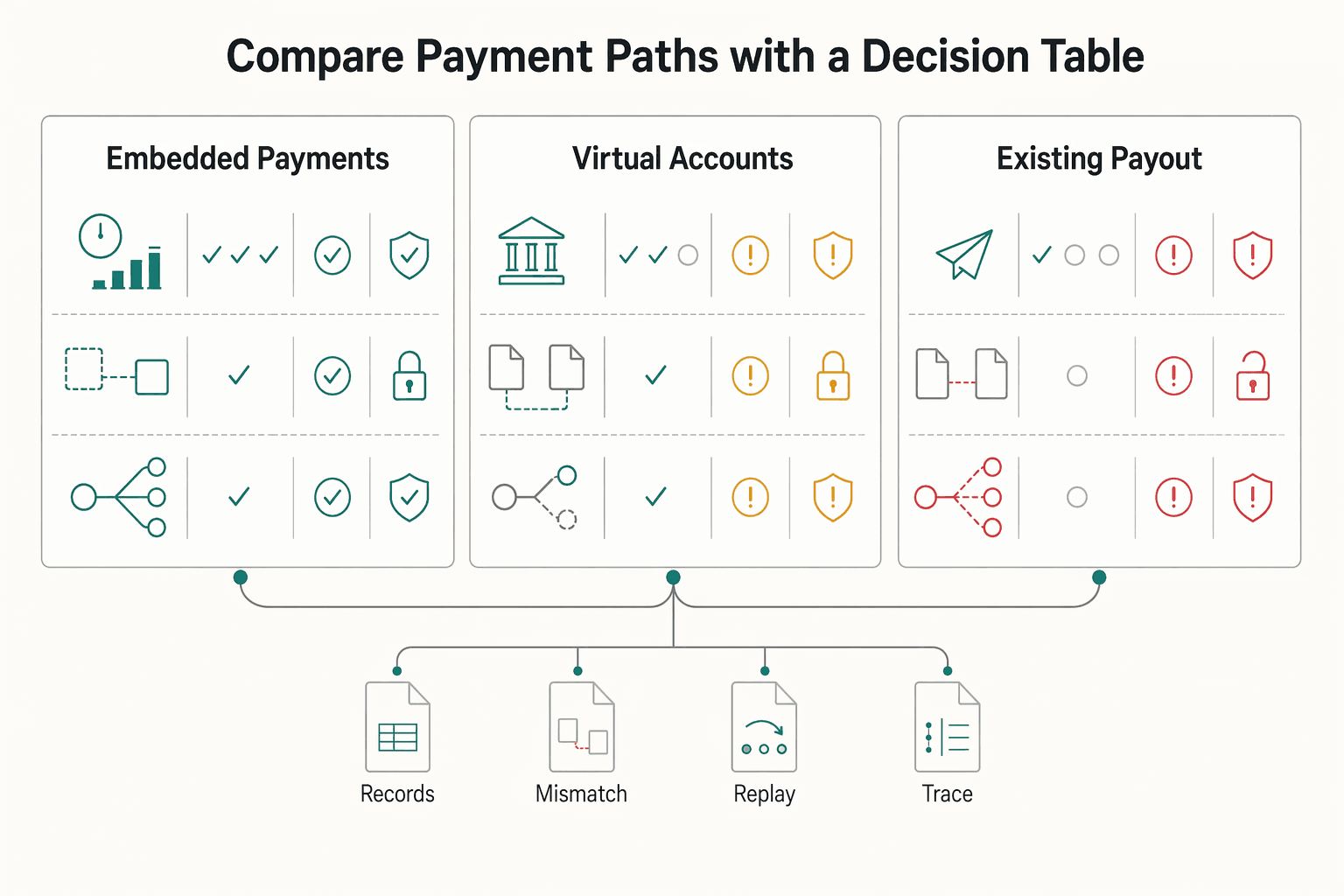
| Path | AP effort saved | Failure-rate reduction potential | Risk exposure to review first |
|---|---|---|---|
| Embedded Payments | Can improve where API-driven events reduce manual status chasing | Can improve when first-time quality improves and duplicate payment handling is tightened | Review architecture and control complexity across API connectivity, status mapping, retries, and downstream posting |
| Virtual Accounts | Can reduce reconciliation effort in reconciliation-heavy flows when virtual account structures are used | Can improve when unmatched receipts and reconciliation exceptions are the primary defect class | Validate sub-ledger-to-ledger traceability and exception handling before scaling |
| Existing payout paths | Can deliver near-term queue-level gains from targeted fixes | Can be strong for isolated defects such as duplicate retries, unmapped updates, or stuck states | Scope may be narrower with single-owner control, but still verify audit-trail completeness and posting follow-through |
For the next 30 days, pair one contained tactical fix with one control-critical fix so you reduce operational drag without compounding record-layer risk. Related reading: Choosing Embedded Finance for Freelance Platforms With an Operations-First Scorecard.
If your impact-versus-controllability scoring points to status and retry gaps, align your rollout with implementation details for webhooks, idempotency, and reconciliation workflows: Review the docs.
Fix cross-team handoffs that create repeat AP rework#
After prioritization, stop letting defects bounce between AP, ops, and engineering. A reliable way to cut repeat rework is to make the handoff contract explicit, assign one accountable owner per exception class, and require evidence at each boundary before work moves forward.
Standardize the intake contract#
Start with the handoff that creates the most AP reopen tickets. Define one intake contract for Webhooks and retry-driven events: required fields, allowed status values, and what a retry is allowed to do.
At minimum, specify the durable identifier, the fields AP needs in order to act without re-escalating, and how duplicate deliveries are handled. Webhook endpoints can receive the same event more than once, so use a dedupe control such as logging processed event IDs and skipping events that were already processed.
Keep status meanings strict across teams. If you use HTTP-style intake responses, treat 202 (Accepted) as receipt or queue acknowledgment, not posting or payout completion. For webhook consumers, return 2xx quickly before heavy downstream logic, then complete complex processing asynchronously.
A practical check is to review five recent retry cases and confirm the same event ID did not create duplicate AP work, duplicate payout handling, or duplicate posting updates.
Assign one accountable owner per exception class#
Shared ownership can create drift. For each recurring exception class, assign one accountable team for triage and resolution coordination, with a named escalation path for payout mismatches and posting mismatches.
This keeps control clear without collapsing segregation of duties. Approval and review can stay separate, while one team remains accountable for the exception until resolution or a formal evidence-backed handoff.
Watch for taxonomy drift. If AP marks an item "failed," engineering marks it "retrying," and ops marks it "pending provider update," you lose control context. Use one shared status vocabulary across queues, notes, and reporting.
Add proof at boundary states#
Use three boundary checkpoints and require audit-trail evidence for each:
| State | What it should mean | Minimum evidence to capture |
|---|---|---|
| accepted | Event or request was received and queued or acknowledged | timestamp, source event ID, receiving endpoint or queue result |
| posted | The accounting entry updated the posting record | posting timestamp, journal or posting reference, related transaction ID |
| reconciled | Transaction records matched against books or statements | reconciliation timestamp, matched record references, exception note if unmatched |
Do not advance handoffs on verbal confirmation or dashboard color alone. If you cannot reconstruct who accepted, who posted, and who reconciled a transaction from timestamped records, the handoff is still weak.
Also verify undelivered-event and reprocessing behavior. In providers with retry behavior like Stripe, undelivered events may be resent for up to three days, so reprocessing logic should explicitly prevent the same event from being processed more than once.
Align leaders on one operating standard#
Bring finance, ops, and engineering together around one artifact: the handoff contract, the ownership map, and the boundary-state evidence requirements. That prevents parallel local standards. For broader alignment, use The Payment Operations Maturity Model: How to Benchmark Your Platform Finance Team.
Choose automation versus process redesign with clear rules#
Use one rule: automate only steps that already run as standard work, and redesign first when root-cause analysis points to unclear ownership, policy ambiguity, or repeated judgment calls.
Automate first when inputs and controls are stable. Approval criteria and control ownership should be explicit. Compliance gating should be risk-tiered. Retry paths should be idempotent so the same request can be safely repeated without duplicate side effects.
Redesign first when teams are compensating for unclear ownership or inconsistent VAT-validation handling. Variation at those points is a process problem, and automating it usually preserves rework instead of removing it.
Document the tradeoff before you choose speed. Faster cycle time does not replace preventive controls, audit-trail evidence, or clear control ownership.
Implement controls without slowing payouts#
Controls should protect release decisions, not turn every payout into a review queue. Use hard stops only for checks that change whether funds can legally or safely move. If a control does not affect that decision, keep it out of the payout path and monitor it through events, exception routing, and reconciliation review.
Gate only release-critical checks#
Start with three pre-release questions: is the counterparty cleared for payout, is the payout eligible, and is the tax profile complete where your program requires it. In practice, that usually means identity/AML status, required legal-entity verification for that program, payout eligibility rules, and Form W-9 or Form W-8BEN collection when that route is enabled.
Keep the scope tight. CIP and beneficial-ownership checks are risk-based, but they should only be mapped into release logic where they apply to your operating model and jurisdiction. A common failure mode is requesting every document from every seller or contractor and collapsing payout speed.
Verification point: sample ten recently released payouts and confirm each has a clear pass/fail record for identity status, eligibility, and tax-profile completeness.
Move monitoring off the critical path#
Use server-side webhooks for confirmation and post-event supervision. Webhooks are asynchronous and a reliable confirmation path for payment events, so they work well for detecting holds, reversals, missing data, and downstream mismatches without blocking clean payouts.
Route only exceptions to humans. Let normal events pass, then send unusual cases to an owned queue for reconciliation checks. Stripe retries undelivered webhook events for up to three days, so monitoring can stay non-blocking, but your consumer still needs duplicate-safe handling. Also design retries with the 24-hour idempotency-key pruning window in mind.
Verification point: review webhook delivery logs and compare undelivered events from the last 30 days against your exception queue and posting records.
Validate tax artifacts only on applicable paths#
Do not treat FEIE, FBAR, and 1099 handling as universal payout gates. These checks apply only to specific taxpayer and account situations, so route them only on supported paths.
For example, FEIE physical presence uses 330 full days in 12 consecutive months abroad. FBAR is triggered when qualifying U.S. persons exceed $10,000 aggregate foreign-account value at any point in the year, with an April 15 due date and automatic extension to October 15. For 1099 handling, collect the required tax form and TIN where needed, and confirm current IRS rules before hardcoding thresholds.
Verification point: for each tax-related hold code, attach the underlying document or rule reference to the case record.
Make every control traceable back to money movement#
Every held or released payout should trace directly to the transaction event and audit log record. Each control should write a timestamp, reason code, actor or service, source artifact, and final release decision so finance can verify outcomes without stitching records together by hand.
This is where hidden slowdown often appears. A dashboard can show "released," but if that status cannot be traced to a posted entry and audit evidence, you have speed without proof. Keep controls observable with minimal context switching for operators, then verify approved actions match posted outcomes in reconciliation checks.
Verification point: weekly, trace a sample from dashboard status to the posting event to the audit log record, and fix any break before adding new controls.
Common mistakes and how to recover fast#
Fast recoveries usually come from fixing structural causes first, not pushing teams to "be more careful."
Map the delay before coaching the team#
Mistake: treating repeat AP or payout delays as a discipline issue. Recovery: run Value Stream Mapping on the real intake-to-posting path, then run Root Cause Analysis on repeat failure classes so you isolate system and process causes.
Use D.R.O.P.S. as a practical sorting aid, not a formal standard: delays, redundancies, overlaps, poor integration, and siloed communication. Start with one recurring exception and trace where it waited, where data changed hands, and who could unblock it.
Verification point: for three recent delayed items, produce one current-state map with each handoff, each status change, and total wait time between steps.
Freeze automation when status and retry logic are still wrong#
Mistake: automating broken steps. Recovery: pause new automation until ownership, status definitions, and duplicate-safe retry handling are explicit.
Idempotency is required, but it is not enough on its own. Webhook events can arrive more than once, and failed deliveries can retry over long windows. Adyen can retry three times immediately and then continue from queue for up to 30 days. If retries are treated as new business events, duplicate AP work and duplicate payout actions can follow.
Verification point: for one event type, document the single exception owner, the exact status meanings, and the idempotency or deduplication rule.
Split compliance holds from real processing failures#
Mistake: counting every hold as an operations defect. Recovery: separate compliance-required holds from true processing failures in incident reporting.
If required customer due diligence cannot be completed, the transaction should not proceed. Ongoing AML monitoring and OFAC-related blocks can also be legally required outcomes, not workflow defects. Keep these separate from failures like missing ingestion, bad status transitions, or posting mismatches.
Verification point: classify recent holds as either compliance-required hold or processing failure, then confirm each case has one clear reason.
Require before-and-after evidence for every fix#
Mistake: shipping fixes without proof of outcome. Recovery: require before-and-after evidence in audit trails and reconciliation outputs.
Use a compact evidence set: triggering event log, status history before release, the same case after release, and one reconciliation output showing settlement behavior. If you cannot trace system and user activity for the same case end to end, keep the fix open.
Verification point: for each production fix, attach one before sample and one after sample, and confirm traceability from event receipt to final reconciliation.
30-day execution checklist teams can copy#
Keep the first 30 days narrow and evidence-led. The goal is to prove which fixes reduce repeat AP work before you expand scope.
Gather the baseline and publish the current state#
Collect the baseline artifacts you already trust, such as AP queue exports, transaction timelines, webhook delivery logs, and reconciliation output. Then publish one current-state map of how work actually flows today, since Value Stream Mapping starts from the current state.
Use a cross-functional group, but keep the map simple enough that finance, ops, and engineering can challenge it. Verification point: for at least one recurring exception path, show each handoff, system of record, wait state, and owner. A red flag is when webhook evidence does not show retry behavior, because late asynchronous events can then be misread as fresh failures.
Observe the work and run RCA on repeats#
In week 2, observe the work directly and run Root Cause Analysis on recurring exceptions. Gemba Walks keep the team grounded in real flow before action, and RCA gives you a structured way to define causes and corrective actions.
Pick the top recurring failure classes and assign one clear owner to each. That ownership model is operational, not a legal requirement. Verification point: for every failure class, document the root cause, corrective action, and named owner. If the team cannot show the triggering event, status history, and recovery path, treat the cause statement as incomplete.
Ship only the top two fixes and prove they worked#
By week 3, rank fixes by impact and controllability, then ship the top two so validation stays clear. Require evidence, not narrative.
Set pass criteria in this order: audit-trail completeness first, fewer manual touches second. If a change speeds processing but leaves gaps in recorded activity, keep it open. Verification point: attach one before sample and one after sample, and confirm the same case is traceable from event receipt to reconciliation.
Review risks, separate compliance gates, and set the next cycle#
Use week 4 to review unresolved risks and confirm CDD, KYB, and AML gates are behaving as intended. Keep compliance-required holds separate from true processing failures such as broken status transitions or missing postings.
As a practical check, review recent webhook and event history over the last up to 30 days where available, especially when live-mode delivery retries can continue for up to 3 days. Close with one finance-ops-engineering decision meeting: what stays open, what moves next, and what needs a policy decision instead of another patch.
Conclusion#
Winning teams do not start with generic automation. They fix the highest-risk handoff first, assign one accountable owner, and prove the fix in records before scaling.
Prioritize the highest-risk handoff first#
Start with the handoff that can weaken record reliability, break audit trail completeness, or trigger duplicate money movement. Risk should set the response order, and clear responsibility is a control requirement, not optional process hygiene.
Use a simple gate: if your team cannot name the recovery owner for one exception class, do not automate that path yet. Ownership split across finance, ops, and engineering can create local progress, but not reliable end-to-end improvement.
Run a 30-day checklist and verify gains in records, not meetings#
Use the 30-day plan to compare before and after on the exact path you changed. Proof should show up in the transaction timeline, audit trail, and exception queue, not just in fewer Slack messages.
For the failure class you fixed, you should be able to reconstruct timing and status from intake through posting and reconciliation. If you cannot, the process still depends on tribal knowledge. Centralized logs also make unusual activity easier to detect and easier to audit later.
Keep one operator detail in view: webhook retries are expected behavior, not automatic provider failure. Retries can continue for up to three days, and manual event recovery may only cover the last 30 days. Without idempotent handling and retry-log checks, late or repeated events can look like new failures and create false RCA.
Scale deliberately only after the evidence holds#
Once one handoff is stable, move to the next highest-risk queue instead of trying to clean up everything at once. Preventive fixes should stay ahead of throughput tweaks, because faster flow on weak controls can push cost downstream into reconciliation, exceptions, and audit support.
As volume grows, keep definitions, logs, and ownership consistent. If a fix reduced manual touches but left status ambiguity, treat it as partial progress and close that gap before expanding automation.
Validate market and module coverage before rollout#
Check market and module coverage before rollout. Do not assume a payment path, country, currency, or connected-account setup is supported just because it works in one context. Eligibility can vary by geography, currency, and account type.
If you need certainty for specific markets or modules, talk to Gruv to confirm what is supported now and what must be enabled first. That small check can help prevent expensive rework later.
Before rolling changes across markets or modules, validate coverage and compliance gating assumptions so your next 30-day plan stays realistic: Talk to Gruv.
Frequently Asked Questions
What are silent killers in platform finance operations, and how are they different from normal AP backlog?
Silent killers are recurring process failures hidden inside routine AP work, not just visible queue volume. They show up as repeated rework, unclear ownership, retry-related duplicates, incomplete audit trails, and handoff delays across finance, ops, and engineering. A normal backlog is mainly visible work in queue.
What are the first signs that hidden AP inefficiencies are becoming a margin problem?
Early signs include cycle-time drift, repeat exceptions, and rising manual intervention on cases that should clear cleanly. Duplicate or erroneous disbursements are a core warning signal. If rework and duplicate-payment risk rise before queue volume does, margin pressure may already be building.
How can a team diagnose hidden inefficiencies quickly without a full transformation project?
Start with one money flow and map the current state with Value Stream Mapping, direct observation through Gemba, and Root Cause Analysis on recurring failures only. Use a minimum evidence pack: AP queue exports, status history, audit-trail records, and webhook delivery logs. For one repeated failure class, prove the trigger, each handoff, and the recovery owner. If retry or idempotency evidence is missing, duplicate actions can be misread as separate failures.
Should we automate AP steps immediately or fix process design first?
Automate stable steps, but fix process design first when ownership, status definitions, or policy interpretation are inconsistent. Automation can accelerate flawed flow if the underlying decision logic is unclear. If teams do not agree on when a case is accepted, posted, or reconciled, resolve that first.
What happens if we ignore small cross-team delays for another quarter?
Small delays can compound into longer waits, more manual touches, and more friction across teams. Teams can still hit local targets while end-to-end performance deteriorates. Not every delay is a defect, because some holds are expected compliance outcomes. The real risk is mixing required holds with broken integrations or unclear ownership.
What should leaders do first when finance, ops, and engineering disagree on the root cause?
Start with shared case evidence, not separate opinions. Review the same event timestamps, status history, audit trail, and webhook or retry logs for one case. Then assign one decision owner for that failure class so definitions and decision rights are clear.
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
- cms.gov/Medicare/Provider-Enrollment-and-Certificati...trusted
- csrc.nist.gov/glossary/term/audit_logtrusted
- csrc.nist.gov/glossary/term/audit_trailtrusted
- ecfr.gov/current/title-31/subtitle-B/chapter-X/part-1...trusted
- ecfr.gov/current/title-31/subtitle-B/chapter-X/part-1...trusted
- federalreserve.gov/paymentsystems.htmtrusted
- federalreserve.gov/paymentsystems/files/psr_policy.pdftrusted
- gao.gov/products/gao-25-107721trusted
Educational content only. Not legal, tax, or financial advice.
Related Posts

The Freelance Payment Penalty: A Modeled Audit of Platform Fees, FX Spreads, and Payout Delays
The money rarely disappears through a single, easy-to-spot fee. The real loss is stacked. A marketplace takes its commission, a processor adds a charge for international cards, a bank or payment company converts the currency at a spread, a platform holds the funds before release, and a wire sheds a little to intermediaries on the way in. Each layer looks defensible on its own, but the worker feels the combined result as a smaller deposit and a later payday.

How to Respond to a Subpoena for Business Records
Move fast, but do not produce records on instinct. If you need to **respond to a subpoena for business records**, your immediate job is to control deadlines, preserve records, and make any later production defensible.

A US Expat's Guide to Investing in UCITS ETFs to Avoid PFIC Issues
The real problem is a two-system conflict. U.S. tax treatment can punish the wrong fund choice, while local product-access constraints can block the funds you want to buy in the first place. For **us expat ucits etfs**, the practical question is not "Which product is best?" It is "What can I access, report, and keep doing every year without guessing?" Use this four-part filter before any trade: