
Quick Answer
Start by reconciling each payout batch across three records: provider outcome, ledger journals, and the general ledger. Use stable identifiers, replay-safe checks with an idempotency key, and a named owner for every exception queue. Then require closure evidence for each mismatch so support, finance, and engineering can prove what happened. For payout reconciliation at scale, the key is early detection and traceable resolution, not batch totals that only look close enough.
Payout Reconciliation as an Operating Control#
Step 1 Reframe reconciliation as an operating control#
Treat payout reconciliation at scale as an operating control, not a back-office tidy-up after money has already moved. Once you pay through one or more PSPs, a mismatch is no longer just a finance nuisance. It can delay settlements and create downstream accounting work.
That shift matters earlier than most teams expect. Reconciliation is often described as matching PSP payout records to internal records, but at scale it reaches beyond bookkeeping. Timely, accurate checks are part of how you run the business, especially when small mismatches can turn into meaningful exposure and create reporting, settlement, and audit problems downstream.
Step 2 Define the match you actually need#
Start with a simple objective: catch gaps between your payout batches, the provider outcome, and the general ledger early. If your records only agree at a batch total, the control may still be weak. You need enough traceability to explain what was intended, what the PSP says happened, and what accounting recorded for that same payout.
Use a simple checkpoint for any payout batch under review. You should be able to show whether each payout has a corresponding provider record and a corresponding ledger outcome, not just whether the batch sum looks close enough. If you cannot do that, unreconciled transactions can linger and create downstream accounting and audit cleanup.
Watch one common tradeoff. A high auto-match rate can look healthy while unresolved exceptions remain. The better test is whether mismatches surface early enough to resolve before they distort reporting or delay settlements.
Step 3 Set scope and ownership before you design#
This guide is for founders, finance, ops, and engineering owners who need a practical way to build traceable, exception-driven reconciliation with clear accountability. If ownership is blurred, automation can make the problem harder to resolve. Finance may see a posting issue, ops may see a payout failure, and engineering may see an asynchronous provider event. Someone still has to decide who closes which exception and what evidence counts.
The examples assume higher-volume payout operations where reconciliation decisions affect multiple teams. That matters because the right control is rarely "reconcile monthly and move on." Many businesses do reconcile monthly. Higher-volume or multi-channel operations often need weekly or daily checks to keep cash flow tight. The rest of this guide shows how to choose that level of control without overbuilding too soon. You might also find this useful: How to Scale an Airbnb Business.
What payout reconciliation at scale actually covers#
At scale, reconciliation is an operating control across the full payout chain, not a check between one PSP file and one bank total. You are matching records across three or more sources, and any mismatch is a discrepancy that needs investigation.
Step 1 Map the whole payout chain#
Start by defining the full path: payout request, Payment Service Provider (PSP) execution result, settlement arrival, ledger journals, Enterprise Resource Planning (ERP) posting, and close. A transaction is reconciled only when the relevant records agree across your internal system, processor, and bank. Use a traceability check on a recent payout to confirm you can follow it end to end with stable references.
Step 2 Set a clear accounting anchor#
Set one accounting anchor for posted outcomes, then reconcile operational and reporting views back to it. This keeps teams aligned when different systems show different states during normal processing. Without that anchor, finance and operations can interpret the same payout differently and leave discrepancies unresolved.
Step 3 Reconcile at transaction level and measure the right outcome#
Keep transaction-level links even when providers send aggregated settlements. If expected and settled amounts differ because of fees, FX conversions, chargebacks, or timing differences, aggregate-only matching slows root cause analysis and can turn dispute work into hours instead of minutes.
Do not treat auto-match rate as the only success metric. The stronger test is whether exceptions are identified quickly, resolved cleanly, and supported by an audit trail that shows what was requested, processed, settled, and recorded. If you want a deeper dive, read How to Scale Global Payout Infrastructure: Lessons from Growing 100 to 10000 Payments Per Month.
What to prepare before you change your process#
Before you change reconciliation, lock ownership and evidence first. Otherwise, automation will move ambiguity faster and make exception queues harder to close.
| Prep area | Items | Note |
|---|---|---|
| Sources and owners | payout engine; PSP; bank or settlement feed; ERP; data warehouse | Each exception queue needs a named closer |
| Identifiers and evidence fields | internal payout ID; provider reference; idempotency key; timestamp standard; status history | If any source drops one of these, treat it as a design gap |
| Eligibility gates | KYC; KYB; AML; bank-account verification statuses | Preserve gate-related transitions so exceptions are classified correctly |
| Closure evidence pack | mismatch reason codes; replay logs; relevant timestamps; provider response details; audit-trail exports | Closure record should show what happened and why the outcome was accepted |
Step 1 Inventory sources and assign closure owners. List every payout record source your team relies on: payout engine, PSP, bank or settlement feed, ERP, and data warehouse. Reconciliation should match records across three or more sources, so each exception queue needs a named closer. Keep separation of duties clear so the person resolving a mismatch is not the only person deciding it is resolved.
Step 2 Freeze the identifiers and evidence fields you trust. Define the minimum fields required in every handoff and export: internal payout ID, provider reference, idempotency key, timestamp standard, and status history. If any source drops one of these, treat it as a design gap. Run a quick trace test on one recent payout and confirm you can follow the same reference chain across payout engine, PSP output, ERP posting, and support view.
Step 3 Confirm payout-eligibility policy gates. Document which upstream checkpoints can block release, including KYC, KYB, AML, and bank-account verification statuses. You do not need to redefine those controls here; you do need status history that preserves gate-related transitions so exceptions are classified correctly.
Step 4 Define the evidence pack before new rules ship. Standardize what finance and support need to close cases: mismatch reason codes, replay logs, relevant timestamps, provider response details, and audit-trail exports. The closure record should show what happened and why the outcome was accepted.
If ownership is still unclear, pause rollout and assign an exception SLA before adding more matching rules.
Map your end-to-end payout chain and choose the source of truth#
Once owners and evidence are set, decide what counts as truth. Reconcile on immutable ledger journals and your general ledger, not on a PSP or internal UI status label. If one payout cannot be traced across request, provider activity, accounting, and export, your control is not reliable yet.
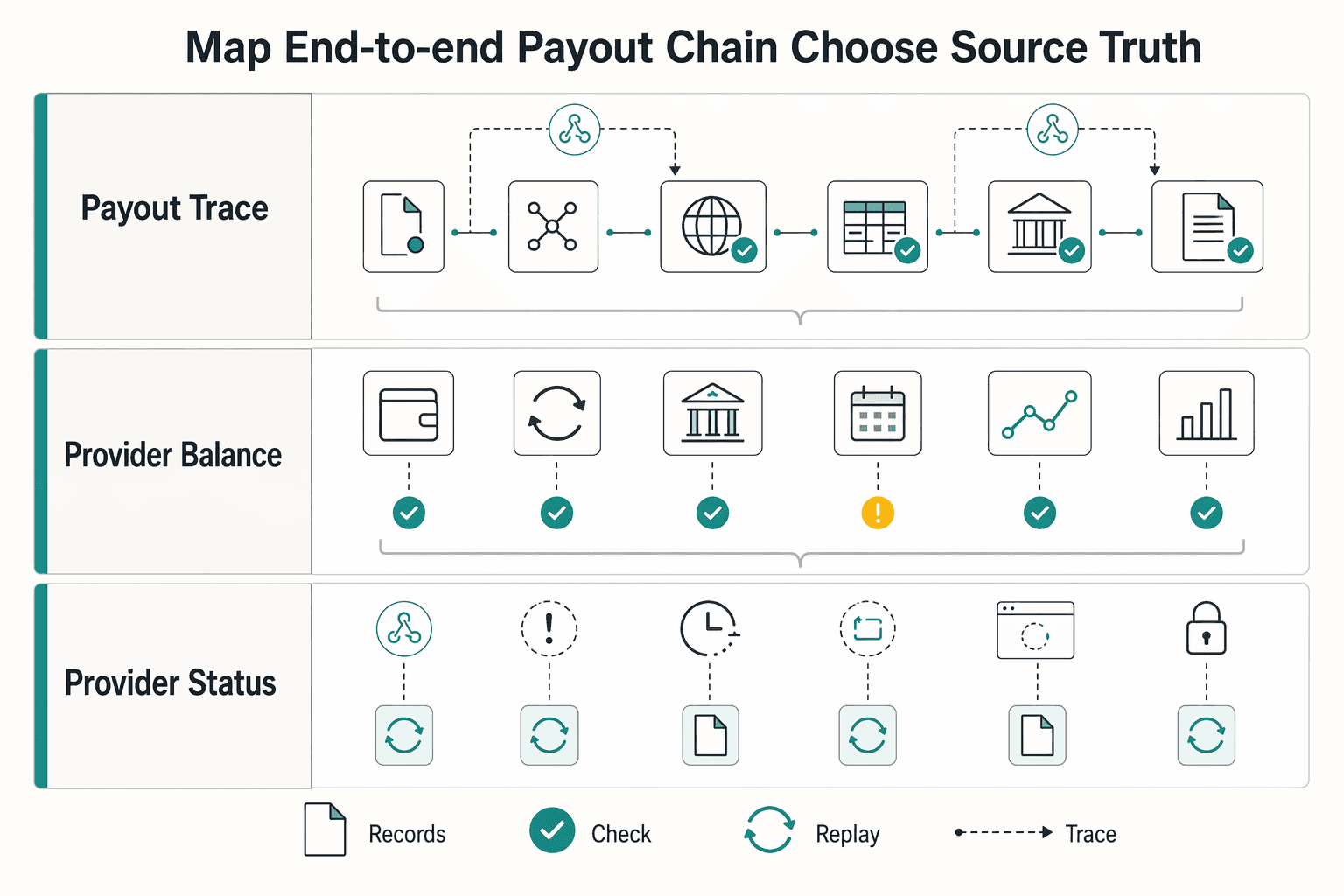
| Record type | Use | Note |
|---|---|---|
| ledger journals | Anchor on immutable internal records | Reconcile on immutable ledger journals, not on a PSP or internal UI status label |
| general ledger | Use as part of the durable accounting record | Every payout in a batch should be traceable request -> provider reference -> ledger entry -> general ledger export |
| provider balance activity | Use in the three-way match | Reconciliation decisions should anchor to provider balance activity, internal ledger journals, and the GL side of posting |
| bank or settlement outcome | Use to tie payout totals to settlement | A practical control is a three-way match across provider balance activity, the general ledger, and the bank or settlement outcome |
| provider status fields | Use for triage only | status values such as pending and available indicate where funds sit in the settlement pipeline |
Step 1. Draw one sequence for each payout rail, not one blended diagram. Map the chain from payout request to PSP execution, settlement confirmation, ledger write, ERP posting, and general ledger export. Include webhooks, retry paths, manual replays, and delayed finance handoffs. A single happy-path diagram usually hides where exceptions are actually created.
If you use Merchant of Record (MoR) or Virtual Accounts structures, explicitly mark where your team records funds movement, where the provider reports movement, and where accounting events are created.
Step 2. Mark every write boundary where duplicates can happen. Duplicates usually appear at retries and asynchronous updates, not at initial approval. Mark each boundary that writes or mutates money state: payout creation, webhook consumer, ledger posting, ERP sync, and batch export. At each boundary, enforce replay-safe checks using your idempotency key or equivalent request identifier before writing again.
A common failure pattern is one provider execution with two internal postings, or one successful payout with a duplicated ERP post after replay. Without replay logs and preserved identifiers, teams debate symptoms instead of proving what happened.
Step 3. Separate decision states from display states. Use provider status fields for triage, not as accounting truth. In a documented Stripe workflow, status values such as pending and available indicate where funds sit in the settlement pipeline. Reconciliation decisions should anchor to durable records: provider balance activity, internal ledger journals, and the GL side of posting.
A practical control is a three-way match across provider balance activity, the general ledger, and the bank or settlement outcome. In the same Stripe example, the provider balance record links to the underlying object through source, and teams then tie payout totals to the bank statement. Your stack may differ, but the control principle is the same.
Use this as the verification checkpoint: every payout in a batch should be traceable request -> provider reference -> ledger entry -> general ledger export. If any link is missing, pause new matching rules and fix traceability first. That is how you produce audit-ready evidence and avoid approved-but-unreconciled flows becoming uncontrolled payments. Related: Affiliate Network Payouts: How to Pay Publishers and Partners Automatically at Scale.
Standardize data before matching or your exception queue will explode#
Once you know which records are authoritative, do not jump straight into match rules. Reconciliation depends on matching and verifying data across internal ledgers and external networks, and poor normalization creates false mismatches faster than rule logic can clear them.
Normalize records before you compare them#
Step 1. Normalize at transaction level across PSP, bank, and ERP feeds. Translate incoming records into one consistent structure before matching. Standardize IDs, currencies, event labels, and other core fields first so your matching logic compares like with like.
If feeds use different labels for the same movement, your exception queue will mostly reflect taxonomy conflicts, not real breaks. Keep source references attached through normalization so you can still trace each transformed record back to its original input.
Step 2. Decide where normalization lives before connector count grows. Choose the architecture your team can maintain and audit reliably.
| Approach | Latency | Maintainability | Auditability |
|---|---|---|---|
| In-ERP mapping | Fewer moving parts after data lands in ERP | Strong when finance owns mappings in ERP | Strong when mapping and posting evidence live together |
| Middleware layer | Adds a handoff before ERP | Useful when many feeds need shared normalization | Depends on preserving raw and transformed records |
| Dedicated reconciliation service | Depends on connector and ingest setup | Useful when reconciliation logic changes frequently | Strong only when inputs, transforms, and match decisions are retained |
If your team already operates deeply in NetSuite, an in-ERP path such as SuiteBilling can avoid separate-system sync overhead. Third-party platforms integrated with NetSuite can add flexibility, but they also add another transformation boundary to monitor.
Decompose aggregated settlements before you trust totals#
Step 3. Break aggregated settlements into attributable payout lines. Net settlement totals are not enough when they bundle multiple components. Decompose those totals so each part can be tied back to the relevant payout record or batch line.
A clean net match can still hide attribution errors if component-level mapping is missing. Preserve the raw settlement line, decomposed components, and linkage references for review.
Add sequencing carefully and pull back fast when noise rises#
Step 4. Match on reference hierarchy before amount-only fallback. Start with the strongest references, then use amount/date checks as supporting signals. Keep amount-only matching narrow so you do not auto-match the wrong records under load.
Step 5. Roll back to narrower rules if a new connector floods the queue. If exceptions spike after a new feed, treat normalization quality as the first suspect. Pull back to strict reference-based rules, fix mapping quality, then reprocess from raw inputs before widening logic again.
We covered this in detail in How to Connect Wise to QuickBooks for Automatic Reconciliation.
Set matching rules and ownership that finance and engineering both trust#
After normalization, make every match decision traceable: define the rule tier, assign an owner, and store closure evidence. Without that structure, similar exceptions get resolved inconsistently and the audit trail becomes hard to defend.
Define rule tiers before you automate more#
Set rule tiers before you expand automation so matching stays consistent and explainable. Automated reconciliation is strongest when configurable, rules-based logic drives decisions, not when teams chase auto-match rate alone.
For each tier, document:
- acceptance criteria
- who can approve or clear it
- required closure evidence
- your internal exception-handling target
| Rule tier | When it should pass | Who approves the logic | Minimum evidence kept |
|---|---|---|---|
| Exact match | Core references align to the source of truth, and currency, event type, and amount agree | Assigned rule owner(s) | Source records, matched identifiers, rule version, timestamp |
| Conditional match | Primary reference is incomplete or timing differs, but documented secondary checks support the match | Assigned policy owner(s) | Reason code, supporting fields used, reviewer or auto-decision record |
| Manual review | Core evidence is missing, conflicting, or outside approved conditions | Named queue owner | Investigation notes, source documents, closure decision, user and timestamp |
A useful test: each rule should be explainable in one sentence. If it is vague, tighten it before automating it.
Split responsibility based on how the work actually breaks#
Define ownership by failure mode and write it down in a responsibility matrix your teams can follow. The key is separating who defines accounting acceptance from who maintains rule integrity and who executes queue operations.
Your matrix should make clear:
- who owns accounting acceptance decisions
- who owns queue execution and evidence collection
- who owns rule versioning, data consistency, and replay safety
This prevents ad hoc decisions in tickets or chat and keeps exception handling repeatable.
Use a quick control check: sample ten recently closed exceptions and verify a reviewer can reconstruct each decision from the stored record alone.
Route by decision rules, not ad hoc judgment#
Route exceptions with explicit decision rules, not individual judgment. In practice, routing works better when teams distinguish data-integrity breaks from accounting-interpretation breaks and assign each path to its documented owner.
Use a compact root-cause taxonomy so routing is consistent, for example:
- missing identifier
- duplicate record
- timing gap
- unmatched fee component
- settlement aggregation issue
- posting gap
- manual override required
Define escalation triggers for pattern risk, such as repeated root causes across batches or sudden growth in manual-review volume.
For closure, keep a complete audit trail for every resolved case:
- raw provider or bank record
- normalized record
- matched ledger journals
- rule version or reason code
- user who closed the case
- replay or reprocess log, if used
Related reading: Deel vs Remote for Freelancers Who Need a Clear First-Payout Decision.
Decide cadence and controls by risk not habit#
Set reconciliation cadence by exposure and exception risk, not by inherited calendar habits. A fixed weekly routine can look orderly while discrepancies age, and manual handoffs across inboxes or spreadsheets reduce visibility.
Map exposure before you pick a review rhythm#
Start by mapping each payout lane by observable risk: volume, process complexity, and how often exceptions appear. As volume rises, manual matching becomes unsustainable and errors or delays are more likely, so higher-risk lanes often need tighter review cycles. Lower-risk lanes may tolerate weekly checks only when open exceptions stay controlled and records remain easy to reconstruct with a clear audit trail.
Use a quick lane-by-lane check:
- Are discrepancies handled immediately when found?
- Is documentation organized enough for traceable review?
- Are exceptions aging beyond what your team can resolve confidently before close?
If these controls are not holding, shorten the cadence.
Tie frequency to operating outcomes, not team preference#
Choose frequency based on control outcomes: earlier discrepancy detection, lower exception age, and cleaner close readiness. Regular scheduling, organized records, and immediate discrepancy handling are the baseline. Without those, more frequent runs are just activity.
Manual handoffs are a warning signal. When work bounces between inboxes and spreadsheets, delays stack up, visibility drops, and liquidity risk increases.
Apply stronger controls where funds are most exposed#
Increase control rigor in lanes with the most exposure or rising disputes. Tighten exception-aging limits, require stronger closure evidence, and escalate repeating root causes sooner.
When dispute volume increases, adjust cadence and control limits first, then decide whether more automation is necessary. Keep separation of duties intact as you scale: controls are stronger when review, execution, and system integrity do not collapse into one owner.
Build dispute prevention and recovery paths for inevitable failures#
Failures are inevitable, so dispute prevention starts with a pre-defined recovery path. Because money movement can complete quickly while reconciliation can take days and fail quietly, your first action should be containment and evidence collection, not a fast retry.
| Failure case | Initial check | Response |
|---|---|---|
| duplicate-payout suspicion | Check whether the same internal payout ID or provider reference appears more than once across request logs, PSP responses, and ledger journals | Pause manual resends |
| missing settlement confirmation | Review settlement timing and formats for the rail and provider | Do not mark a payout as failed based only on missing webhooks |
| stale status after webhooks | Compare webhook history, immutable ledger journals, and current provider-side references | If the ledger advanced but the status view did not, correct display state while preserving the audit trail |
| ERP posting delayed | Confirm funds movement and settlement | Treat it as an accounting lag until funds movement and settlement are confirmed |
Classify the failure before anyone retries or rebooks#
Classify the break before anyone retries or rebooks. For duplicate-payout suspicion, pause manual resends and check whether the same internal payout ID or provider reference appears more than once across request logs, PSP responses, and ledger journals. For missing settlement confirmation, do not mark a payout as failed based only on missing webhooks: settlement timing and formats vary by rail and provider.
Use one verification checkpoint: can you trace a payout from request to provider reference to prior-state ledger entry without relying on mutable UI status? If not, treat it as a data-integrity gap first, not a payout-outcome decision.
Recover from the break with an evidence pack#
Recover with documented evidence, not memory. For stale status after webhooks, compare webhook history, immutable ledger journals, and current provider-side references. If the ledger advanced but the status view did not, correct display state while preserving the audit trail. If ERP posting is delayed, treat it as an accounting lag until funds movement and settlement are confirmed.
A practical evidence pack includes request/response logs, provider references, webhook history when available, and prior journal state before correction. That discipline matters because disputes carry an evidentiary burden, and unsupported fixes are harder to defend.
Keep support and finance aligned during the investigation#
Pre-wire support and finance communications so payees get one consistent status while the investigation is in progress. Use shared status labels, required identifiers, and one escalation path. Mixed messages like "paid" from support while finance is still validating delayed ERP posting create avoidable trust damage.
For a step-by-step walkthrough, see Build a Freelance Referral Program Without Payout Disputes.
Final checklist to launch without surprises#
Launch only when these controls are clear and repeatable. Reconciliation is central to a reliable close, and unmatched transactions can hide duplicate payments, hidden fees, or fraud risk, so treat this as an operating check, not a last-minute cleanup.
- Lock identifiers and replay controls.
Define the fields you will carry end to end (for example, internal payout ID, provider reference, and idempotency key) and verify they persist across payout records, provider events, and finance review outputs. If a key reference drops at any handoff, fix that before broad rollout.
- Confirm transaction-level normalization before wider auto-matching.
Pull internal and external records, then align IDs, currencies, timestamps, and status labels before expanding rule coverage. If records are compared at different layers (for example, net settlement against gross payout data), exception volume will usually rise, not fall.
- Set ownership, exception handling, and escalation rules.
Name owners for accounting decisions, queue operations, and data-integrity fixes, and document your exception SLA and escalation triggers. Include who approved adjustments and where supporting paperwork is stored so case closure is auditable.
- Prove end-to-end traceability on a real payout.
Walk one live payout from request through provider and accounting evidence, using records such as webhooks, ledger journals, and general ledger outputs where those systems are in scope. If success status cannot be explained with a clear evidence trail, treat it as a launch blocker.
- Reflect compliance gates in payout and exception logic.
If your workflow uses KYC/KYB, sanctions checks, or wallet verification controls, ensure those states drive payout eligibility and routing so teams investigate the right issue first. If you need a deeper view on the verification side, see Payee Verification at Scale: How Platforms Validate Bank Accounts Before Sending Mass Payouts.
Need the full breakdown? Read Connect Wise to Xero Without Reconciliation Surprises.
Frequently Asked Questions
What is payout reconciliation at scale in practical terms for a platform team?
It is the day-to-day control of matching payouts across records so you can prove what happened. In practice, it means checking internal payout records, PSP results, settlement data, and accounting postings, often across three or more sources. If you cannot trace a payout from internal ID to provider reference to accounting entry, your close process is not yet reliable.
Why do mismatches increase when we add more PSPs and payment rails?
Adding more PSPs and rails usually means more data sources and formats to align. That raises the odds of comparing unlike records, especially net versus gross amounts, which is a common mismatch driver. If exception volume jumps after a new connector goes live, review normalization and layer mapping before adding more matching rules.
What is the minimum architecture required for reliable reconciliation?
For a reliable baseline, use consistent internal and provider identifiers, a clear accounting source of truth, and reconciliation data from at least three places: your payout records, PSP data, and accounting records. The core requirement is traceability across those systems when a discrepancy appears.
How often should payout reconciliation run for multi-PSP operations?
There is no single right cadence for every platform. Many businesses reconcile monthly, while higher-volume or multi-channel teams often move to weekly or daily checks because problems compound faster. For multi-PSP operations, weekly or daily checks are often a better starting point than monthly-only reviews.
Can payout reconciliation be fully automated without manual review?
No, not in a credible way. Matching can be highly automated, but discrepancies still need investigation, especially when records disagree about the same funds movement. A practical rule is to automate exact matches and route unresolved cases into manual review with key identifiers and provider references attached.
What should finance own versus engineering own in exception handling?
There is no universal split, so define one explicitly before volume rises. A practical split is to keep accounting-acceptance decisions with finance, and data integrity, ingestion reliability, and identifier traceability with engineering. If an exception lacks a provider reference or traceable event history, route it to engineering first.
What usually causes mismatches between PSP settlements and ERP records?
The most common cause is comparing the wrong layer, especially net settlement totals against gross payout records. When records disagree, verify the PSP settlement record, the internal payout record, and the accounting entry for the same identifier before booking a manual adjustment.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
- elibrary.imf.org/view/journals/063/2025/009/article-A001-en.xmltrusted
- lackawanna.edu/wp-content/uploads/2024/01/Catalog_CourseDes...trusted
- michigan.gov/dtmb/-/media/Project/Websites/dtmb/Procureme...trusted
- nerp.ornl.gov/publicationstrusted
- occ.gov/publications-and-resources/publications/comp...trusted
- regent.edu/wp-content/uploads/2025/01/Regent-Research-R...trusted
- sec.gov/Archives/edgar/data/2044725/0001193125260939...trusted
- sec.gov/files/ctf-written-payments-settlement-operat...trusted
Educational content only. Not legal, tax, or financial advice.
Related Posts

How Platforms Validate Bank Accounts Before Mass Payouts
For mass payouts, the real question is not whether to verify payees. It is how much verification you require before release, who can override it, and what evidence you can produce later. If you cannot show that evidence on demand, your release rule is weaker than it looks.

Scaling a Global Payout Platform from 100 to 10000 Monthly Payments
Scaling a global payout platform is rarely just a vendor problem. More often, it is an infrastructure and operating-discipline problem, because cross-border payments still carry persistent issues around cost, speed, access, and transparency. If growth is framed as "one more provider" or "higher API throughput," breakpoints can show up in finance, support, compliance, and reconciliation.

Automating Affiliate Network Payouts for Publishers and Partners at Scale
Automating affiliate payouts is worth doing, but only after you decide what has to stay controlled. As programs grow, payouts become a real operational burden, and payout reliability affects whether partners stay engaged. If you automate the payment motion before you clean up approvals, tax data, and reconciliation, you usually do not remove work. You just move it into exceptions that are harder to unwind.