
Quick Answer
Use payout failure root cause analysis by separating failures into bank, user, or processor paths, then validating that label against transaction-time evidence before locking a cause. Start from the last confirmed state transition, run a short triage window for containment and evidence capture, and only then choose retry, reroute, or stop actions. The method works when teams track owner accountability, compare before-and-after incident patterns, and require recurrence reduction plus reconciliation improvement before calling a fix complete.
Separate root causes before choosing a recovery path#
Payout failure root cause analysis works best when you separate likely causes early instead of treating every failure as the same kind of incident. Issues at different points in the payout flow can all surface as "payout failed," but they may not have the same owner or the same fix.
That is why RCA needs to be evidence-first. Root Cause Analysis, or RCA, is the process of finding underlying causes so teams can choose the right corrective action. Restoring one failed payout addresses a symptom. Removing the condition that keeps creating that failure pattern is what helps prevent recurrence. If teams stop at symptom handling, repeat exceptions are more likely.
In payout operations, one incident can also have more than one root cause. The goal is not to pick a single explanation quickly. The goal is to group failures into useful categories early and review evidence close to transaction time, when the event trail is usually easier to verify.
This article focuses on production payout operations for platform finance, operations, and product teams. It is not generic AP or AR guidance, even if some RCA habits overlap. The emphasis here is operational separation across likely failure points, such as bank behavior, user-provided data, processor behavior, or internal handling.
A practical starting rule is to begin with confirmed facts, not blame. If your event history and internal records do not agree, you are still collecting evidence, not analyzing cause.
Failure patterns are not one-size-fits-all, and they can vary by institution and program. By the end, you should have practical outputs for live operations: a working classification approach for likely causes, an incident checklist for initial containment, and clear criteria for next-step handling based on evidence. Related reading: How HR Platforms Scale Employee Recognition Payout Disbursements.
Define Payout RCA So Teams Stop Fixing Symptoms#
The core rule is simple: Root Cause Analysis (RCA) means finding the condition that created the failure, not just restoring one failed event. The alert is a symptom. Symptoms help you triage, but by themselves they do not explain the cause.
Treating symptoms still has value for short-term stabilization, but it is not a full fix. If teams stop there, the same problem can come back. RCA is meant to prevent recurrence by addressing causes at the source, and it works better when you assume an incident may have more than one root cause.
You should name the cause only after you connect the observed failure signal to supporting operational data.
A practical checkpoint is this: if observed signals and operational data do not align, you are still in evidence collection. Until those signals connect, you have not reached root cause.
This distinction affects control quality, not just incident closure. Unresolved causes show up as repeat exceptions, and RCA can also support compliance by surfacing issues tied to potential noncompliance before they repeat. For a step-by-step walkthrough, see Account Takeover in Payout Platforms and How to Stop Payee Hijacks.
Map the Payout Lifecycle Before You Analyze Any Failure#
Start with location, not explanation. Good RCA starts by confirming the last verified state and the first failed state in your workflow. Without that boundary, you can fix the visible symptom and miss the actual break.
Map the lifecycle as it really runs in your operation, including each state change and handoff where failures can be introduced. Use that map to trace the disruption backward to its base issue instead of stopping at the incident signal. Keep containment separate from root-cause conclusions until the sequence is clear. Steps that look like one failure label on a dashboard may still represent different break points.
Before you open RCA, verify three basics:
- the observed sequence is complete enough to reconstruct what changed
- verified facts are separated from assumptions
- evidence gaps are documented before conclusions are finalized
This keeps short-term containment separate from root-cause work and makes it more likely that your fix prevents recurrence instead of shifting the problem downstream.
A simple working habit helps: write the sequence in plain language before you debate cause. If two reviewers cannot agree on what happened first, what changed next, and which state is actually verified, the incident is not ready for causal analysis. We covered this in detail in Building a Payout Ledger with Double-Entry Bookkeeping for Platform Financial Records.
Classify Failures by Owner With a Bank User Processor Matrix#
Assign a provisional owner as soon as you identify the first failed state. At triage, the point is not perfect diagnosis. It is to start the right containment step, with clear accountability and evidence.
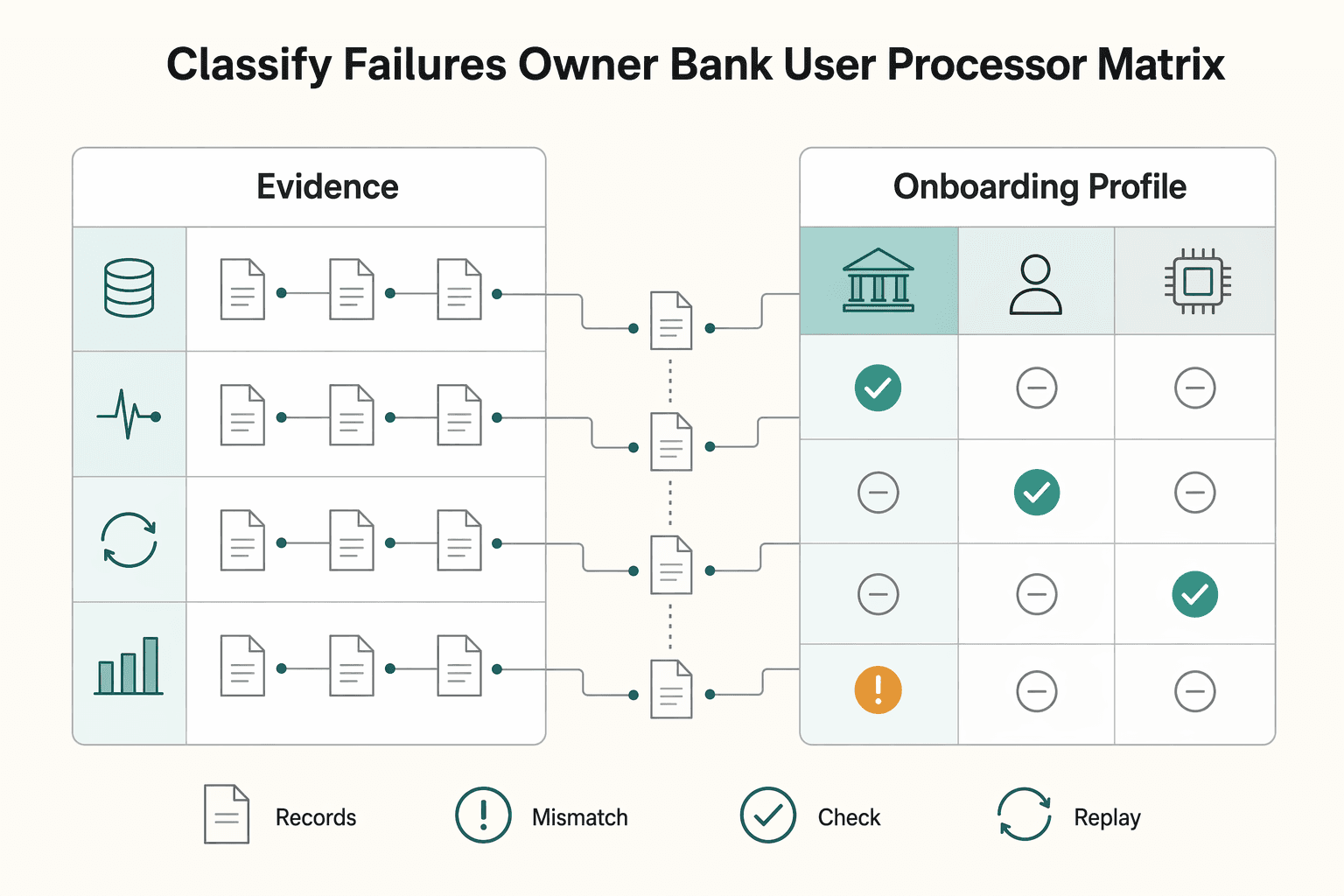
Keep a one-screen matrix with these columns:
| Observed signal | Likely cause bucket | Primary owner | First containment action | Escalation trigger |
|---|---|---|---|---|
| Documented return reason from the bank/rail after submission | Bank or processor path (provisional) | Payments ops / bank-relationship owner (provisional) | Pause blind retries and capture provider reason text, route, and timestamps | Reason cannot be matched to current provider docs, or repeats cluster on one route |
| Onboarding or profile state does not satisfy your current policy checks | User or policy-control path (provisional) | Onboarding ops / compliance owner (provisional) | Hold payout and route through your approved review path | Stored profile/doc state conflicts with policy decision, or review backlog grows |
| Execution state is inconsistent across timeout/retry/callback records | Processor or integration-control path (provisional) | Engineering / integrations owner (provisional) | Freeze automated replay and reconcile request vs execution evidence | Request, processing, and callback records do not reconcile |
Build rows from observed signals, not assumptions. If required fields are missing, for example payout ID, provider reference, state transition, or timestamps, keep the bucket marked as provisional.
Do not classify from the surface symptom alone. One layer can report a failure generated by another. When that happens, keep ownership provisional until the evidence shows where the blocking condition started. Assign primary ownership to the team that can make the first durable correction.
That last point matters operationally. A failure signal can surface downstream of the condition that actually started the problem. The matrix is useful because it forces you to ask who can stop recurrence, not only who first noticed the problem.
The matrix should also hold up in governance review. The OCC Payment Systems handbook, Version 1.0, October 2021, separates risk into operational, fraud, strategic, credit, liquidity, and compliance categories. It also emphasizes controls such as policies, internal controls, risk assessment, and management and board reporting. OCC merchant-processing guidance also treats processing as distinct from card issuing and describes a high-volume, low-margin model where contingent liabilities may result in losses. Your matrix should feed those controls, not sit outside them.
Use your existing incident cadence to prioritize recurring buckets that create the most repeat work or operational impact first. Related: How Streaming Gaming Platforms Scale with Monetization and Payout Infrastructure.
Run a 30 Minute Triage Checklist Before Deep RCA#
Use the first triage window for containment and evidence capture, not certainty. Early conclusions should stay provisional until the evidence is internally consistent. If you do not yet have an official Root Cause Analysis (RCA), treat any root-cause conclusion as unverified.
Work the incident in a fixed order#
Start by capturing concrete checkpoints so everyone frames the same incident:
- incident date
- duration
- scope
- impact
Then build your working record from explicit evidence inputs, including official status updates and your incident-response framework. That keeps the investigation grounded in observable facts.
Capture minimum evidence before theorizing#
Maintain a timestamped record of confirmed facts, open questions, and hypotheses. If the records do not tell one coherent story yet, keep technical explanations provisional.
Without verified internal detail, this stage is forensic reconstruction, not final causation.
Use simple containment rules#
Keep containment actions narrow, reversible, and documented during triage. Avoid overlapping changes that blur the timeline and weaken later analysis.
Containment first, cure second#
Keep containment and cure separate. Immediate recovery is about limiting impact and preserving evidence. Full Root Cause Analysis (RCA) comes after verification.
Build the Evidence Pack Needed for 5 Whys to Work#
A 5 Whys session is only as good as the incident record behind it. Before you ask why, align on one consistent record and verify key facts directly so the team is not debating assumptions.
Standardize one dossier format#
Use the same dossier shape every time so teams do not have to rebuild context mid-incident.
| Dossier element | Capture | Why it matters |
|---|---|---|
| Incident timeline | What happened, in order, and when impact was observed | Keeps the team anchored to a shared sequence of events |
| Direct verification notes | What was checked at the source ("go and see") | Reduces secondhand interpretations |
| Why-chain log | Each "why" step and the evidence behind it | Helps reach root cause instead of stopping at symptoms |
| Fix decision | Workaround or permanent fix selected | Connects analysis to action and recurrence prevention |
If records conflict, resolve those conflicts before locking in a causal story. Keep raw artifacts alongside summarized fields so another reviewer can validate the conclusion later.
Join records across systems before interpretation#
Treat this as an end-to-end state check, not a single-screen review. Use direct verification against source records, not only summarized status labels or retellings.
The point is to move past superficial explanations and produce a fix path you can defend.
Add compliance context when relevant#
The available sources do not define a payout-specific compliance checklist for 5 Whys evidence. If compliance context may matter, document what is known and avoid assuming mandatory fields that are not confirmed.
Set a pre-Whys quality gate#
A practical readiness check is:
| Pre-Whys check | Requirement |
|---|---|
| Shared incident narrative and impact statement | One shared incident narrative and impact statement |
| Key facts | Verified from source records |
| Why-chain | Traceable why-chain that supports root-cause reasoning |
| Fix path | Clear path to a workaround or permanent fix |
Use 5 Whys Fishbone and Pareto Without Falling Into Generic RCA#
Use this sequence as an operating method. The available evidence does not validate payout-specific RCA methods; it shows RCA paired with countermeasure action plans in non-payment contexts.
| Method | Role | Use here |
|---|---|---|
| Pareto | Focus on recurrence | Start with the dominant repeatable cluster, not the loudest incident |
| 5 Whys | Probe past the first plausible explanation | Run 5 Whys inside that one cluster and stop at the first controllable cause that could prevent recurrence across multiple incidents in that cluster |
| Fishbone | Completeness check | Use fishbone as a completeness check before finalizing the root cause |
- Start with the dominant repeatable cluster, not the loudest incident.
- Run 5 Whys inside that one cluster.
- Stop at the first controllable cause that could prevent recurrence across multiple incidents in that cluster.
- Use fishbone as a completeness check before finalizing the root cause.
For payout operations, treat fishbone branches like people, process, policy, integration, and rail or provider behavior as a practical review lens, not a proven taxonomy from the evidence here.
Avoid single-incident storytelling that cannot be reproduced. A stronger result is one another reviewer can re-run later from the same records in a Payment Platform Post-Mortem, then compare whether the same preventive fix is justified.
A useful discipline is to give each method a distinct role: Pareto to focus on recurrence, 5 Whys to probe past the first plausible explanation, and fishbone to test whether another branch better fits the evidence. Treat this as an internal operating pattern to test, not as an evidence-validated payout standard.
Decide When to Retry Reroute or Stop#
Use a conservative default: retry only for likely transient technical failures, reroute only when the issue appears route-specific, and pause automation when the decline reason is non-transient or unclear. These decisions should follow a predefined rule set plus real-time conditions, not urgency alone.
| Failure type | What it suggests | Default action | Continue only while | Stop when |
|---|---|---|---|---|
| Transient technical error | Technical availability issue, for example network outages | Retry first; reroute if one route appears impaired and an approved alternative path exists | Real-time signals still indicate a transient technical condition | The state is unclear or repeated declines continue without clearer evidence |
| Issuer-rule decline | A decline tied to issuer-side rules rather than route availability | Avoid rapid automated retries; reassess with current decline data | Updated signals suggest the decline condition may have changed | The same issuer-rule decline keeps repeating |
| Insufficient-funds decline | A funding constraint rather than a route outage | Do not treat rerouting as the default fix; wait for a meaningful state change before retrying | There is clear evidence the payment state has changed | Insufficient-funds declines continue |
Keep retry controls strict. Repeated declines can damage trust, and failed transactions in instant-payment contexts can create immediate frustration. In Merchant Payments flows, urgency should speed up escalation and communication, not lower control standards.
The plain rule is simple: recover quickly from temporary technical conditions, but pause automation when decline signals are non-transient or unclear.
When you do retry, verify that current conditions still support the same decision path. Retry and reroute decisions should stay dynamic as conditions change.
Standardize your retry and reroute rules against a concrete status model before automating decisions. Review the Payouts workflow.
Prevent Recurrence With Control Changes and Verification Checkpoints#
Preventing recurrence means turning each root cause into a control change with a named checkpoint, then proving that checkpoint moves. Once you decide to change the response path, remove the condition that forced that decision. If recurrence patterns or error-tracking signals do not improve, the fix is incomplete or still unproven.
Match the fix to the cause#
Map findings to a control type, then define the evidence that shows it works.
| Root cause pattern | Control change | Checkpoint to watch | What to verify |
|---|---|---|---|
| High-volume recurring error category | Targeted fix for the largest contributing category | Recurrence trend for that category | Error tracking shows fewer repeats in that category, not just fewer reported incidents overall |
| Repeated symptom-level fixes | Run a Five Whys pass and implement the root-cause action | Reopen rate for similar incidents | Corrective actions map to the identified cause chain, not only surface symptoms |
| Quality gaps between workflow steps | Add verification checkpoints during preparation | Checkpoint completion and exception trend | Required reviews happen before handoffs, and downstream exceptions decline |
| Reactive incident handling | Assign checkpoint ownership and scheduled follow-up analysis | Follow-up completion and repeat-incident trend | Teams are closing preventive actions, not only applying one-off patches |
Keep each checkpoint tied to a clear source of truth: stable error categories for recurrence, timestamped workflow history for timing, and tracked exception queues for unresolved work.
A good checkpoint also separates visible improvement from real improvement. A drop in surfaced failures may look like progress, but if downstream exceptions stay open, the control may only have relocated the work. That is why each checkpoint needs a verification step, not just a trend line.
Verify the fix before and after release#
Before you ship a process, integration, or policy change, run a short pre-release failure review: assume failure, identify likely break points, and confirm what evidence would resolve ambiguity quickly. In practice, that means checking that logs and event history can establish the last known good state.
After an incident, run a post-incident review to test whether the control prevented recurrence in a comparable workflow. Review the original timeline, the changed control, the first post-release results, and any open exceptions. If alerts drop but unresolved downstream exceptions persist, the issue may have moved rather than been fixed.
Make the before-and-after review explicit. Compare the failure path that existed before the change with the first comparable path after the change. If you cannot perform that comparison from the retained evidence, your verification design is too weak.
Prioritize controls by net operational effect#
Prioritize controls by observed impact, not debate volume. A Pareto view helps you rank recurring categories so you address the biggest contributors first, without assuming failures always follow an 80/20 split.
Operationally, favor controls that reduce repeat failures while avoiding new queue pressure elsewhere. If a change lowers visible failures but increases downstream backlog, treat that as an explicit tradeoff, not an automatic win. The pattern to avoid is firefighting: local patches with no checkpoint owner and no follow-up analysis.
Set Governance Cadence and Reporting That Finance Teams Can Trust#
Put governance on a fixed cadence with a single scorecard, or RCA starts to read like commentary instead of trusted reporting.
Keep the cadence simple and repeatable#
If you run weekly and monthly reviews, use them to move work, but treat them as governance layers on top of daily control checks. Review recurring issues, reopenings, backlog closure, ownership clarity, and whether reconciliation exceptions are clearing or aging.
Do not rely on monthly meetings to surface balance risk. Daily automated reconciliation for the accounts and cash positions that drive financial reporting should remain the operating baseline.
The value of cadence is consistency, not ceremony. If teams review one week by route, another by provider, and another by individual incident stories, trend lines become hard to trust and owners become hard to hold accountable.
Use one scorecard, not competing decks#
Maintain one shared scorecard across ops, product, engineering, and finance, with fixed definitions that stay consistent over time. If useful, align terminology to Payout Failure Benchmark Report categories.
| Metric | Definition note |
|---|---|
| Total incidents and repeat incidents | Use consistent category definitions |
| Open reconciliation exceptions | Link to incident IDs |
| Closure status for open items | Named ownership |
Prioritize traceability in every metric. If incident counts fall while reconciliation exceptions stay open, closure is incomplete or the problem may have shifted downstream.
Name owners and preserve audit evidence#
Assign a named owner to each open issue end to end, even when containment, defect correction, and policy changes span different teams. Without clear ownership, backlog closure turns into status reporting instead of resolution.
Design reporting for audit readiness. Effective internal controls should leave a verifiable, auditable trail for reported numbers, and ad hoc controls are a governance risk. For Compliance Audits, keep the evidence pack for each closed item: incident timeline, reconciliation status, owner decision, source logs, and any external compliance reference in official form. For Federal Register material, retain the official edition or PDF with the document citation and number, not only an XML copy.
You might also find this useful: Mobile Contractor Payout UX: Design Rules and Launch Checks.
Handle Country and Program Variance Without Guesswork#
Treat country and program variance as the default, not the exception. Payment performance and decline drivers can differ by country and market, so avoid assuming one pattern applies everywhere.
Use a country comparison table to decide where to investigate first instead of reacting to raw incident totals.
| Country | Monthly volume | Average decline rate | Main decline reason |
|---|---|---|---|
| USA | $500,000 | 2.5% | Soft declines, insufficient funds |
| Germany | $150,000 | 7.0% | Cross-border declines |
| Brazil | $80,000 | 12.0% | Cross-border and payment method issues |
This view helps you separate concentration from noise and avoid copying a fix from one market into another where the failure drivers differ.
Before rollout, confirm these in writing:
- KYC checks used to verify identity at onboarding
- AML controls used to monitor and report financial-crime risk
- Country-level decline assumptions and the main reason expected in each priority market
KYC and AML are complementary but distinct controls, so do not collapse them into one root cause.
Use a cautious confirmation sequence:
- Review internal policy and process docs so KYC onboarding checks and AML controls are defined as separate, related controls.
- Build or refresh the country table with volume, decline or failure rate, and the main stated reason.
- Test with a controlled cohort before broad rollout, then compare observed decline and failure patterns to your assumptions.
Keep the decision evidence pack: the country table snapshot, policy references, cohort definition, and the post-test results tied to those assumptions.
A practical reading of the table is to ask two questions in order: where is the concentration, and are the reasons comparable enough to share a fix. High volume alone does not mean highest priority, and a higher decline rate alone does not prove the same mechanism is at work across markets.
Conclusion#
Fast containment matters, but durable payout performance comes from evidence-first RCA and control changes you can verify. Clearing the visible symptom may restore one payout while leaving the same failure path in place.
RCA works when you connect signals to operational data and aim at recurrence, not just closure. Methods can vary by context, but the standard should not: no conclusion without evidence, and no fix marked done until the prior failure pattern no longer holds up in review.
The next move is practical. Start with a defined problem statement, then run a repeatable RCA method that fits the incident, for example a fishbone or the 5 Whys. Anchor decisions to the operational records you have, and if those records conflict on the last successful state transition, treat the RCA as incomplete and close the evidence gaps before you go deeper.
From there, use recurrence as the checkpoint. If visible failures drop but the same underlying pattern returns, treat the change as partial. Push past contributing factors until you reach the controllable cause, then review your documentation to confirm country and program coverage and any policy-gated payout behavior for your setup. Before rollout, confirm coverage, policy gates, and operational fit for your setup with your team via Gruv contact.
Frequently Asked Questions
What is payout failure root cause analysis, in one practical definition?
Payout failure root cause analysis means tracing a failed payout to the condition that caused it, not just clearing the visible error. In practice, you document the event sequence, identify causal factors, and separate the immediate cause from the root cause. If you only restore service, the same failure path can return.
How do we separate bank, user, and processor errors when symptoms overlap?
Start with evidence, not labels. Reconstruct the event sequence and causal factors, then keep the classification provisional until the causal chain is clear. The provided material does not define definitive bank-versus-user-versus-processor classification rules, so avoid forcing a final label when evidence is incomplete.
What minimum data should we collect before running 5 Whys?
Collect enough evidence to test causality, not just describe symptoms. A concrete evidence pack can include logs, metrics, traces, deploy records, feature-flag history, topology/dependency health, plus operational context. The provided material does not define a payout-specific minimum checklist beyond that.
When should we retry a payout versus reroute it versus stop it?
Use your documented controls and the current evidence. The provided material does not specify exact retry counts, backoff windows, reroute thresholds, or stop conditions, so treat those as internal policy decisions that should be defined explicitly.
How do idempotency controls change RCA outcomes for duplicate-risk incidents?
The provided material does not define payout-specific idempotency control design or duplicate-prevention thresholds. In RCA terms, rely on available evidence and mark conclusions as uncertain when duplicate-risk causality cannot be shown clearly.
Which checkpoints prove a fix worked and reduced recurrence?
Use recurrence as the primary checkpoint: confirm the same failure path does not return after the fix. Document the event sequence and causal factors so you can compare before-and-after conditions. The provided material does not define payout-specific reconciliation checkpoints or target metrics.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
- apps.legislature.ky.gov/law/kar/titles/907/001/672trusted
- cms.gov/Outreach-and-Education/Medicare-Learning-Net...trusted
- fdic.gov/regulations/safety/manual/section3-2.pdftrusted
- federalregister.gov/documents/2025/11/05/2025-19787/medicare-and...trusted
- federalreserve.gov/supervisionreg/files/credit-risk-models.pdftrusted
- gta.georgia.gov/sites/gta.georgia.gov/files/pm_course_docs/R...trusted
- michigan.gov/-/media/Project/Websites/dtmb/Procurement/Co...trusted
- nrc.gov/docs/ML2507/ML25071A060.pdftrusted
Educational content only. Not legal, tax, or financial advice.
Related Posts

How to Conduct a Payment Platform Post-Mortem: Root Cause Analysis for Outages and Errors
Treat the post-mortem as a decision document, not just an outage recap. A rollback may restore service quickly, but it does not prove you understand the failure. This guide is for running a blameless incident review that turns incident learning into concrete prevention decisions.

How to Conduct a 'Pre-Mortem' to De-Risk a Large Freelance Project
If you want fewer project surprises, do the risk planning before launch, not after problems show up. A pre-mortem helps because you assume the current plan has already failed, then work backward to identify what likely caused it and how you will prevent it.

Payout Failure Benchmark Report for Platform Teams
A useful **payout failure benchmark report** is not a prettier exception export. It is the operating document that tells your platform team which payout failures are real rail problems, which ones are recipient-data problems, which ones were held before release, and which ones were later recovered.