
Quick Answer
Mobile-first payment UX for contractors should be designed as a traceable payment lifecycle, not just a polished checkout screen. It needs one initiation event, shared states for action needed, processing, success, failure, and review, webhook-driven status sync, audit logs, and idempotent retries. The flow is ready only when every contractor-visible status maps to backend evidence, provider events, and reconciliation records.
Why mobile-first payment UX matters for contractors#
Mobile-first payment UX for contractors is an operations problem first, not just a screen-design project. If initiation is unclear, status labels do not match provider states, or exceptions end in generic errors, cleanup work can shift to support, finance, and reconciliation.
These issues are not cosmetic. Payment-flow usability problems can block completion. They can also create repeated submissions, unclear pending states, and investigations without a reliable event trail.
For product, ops, and finance teams, the practical requirement is to define payment behavior before layout decisions. Treat mobile as the front end of a traceable payment lifecycle with explicit states, action rules, and audit checkpoints that still hold up under retries, webhooks, and provider-side state changes.
A strong baseline is one lifecycle object per payment session, visible across the full journey. Stripe's PaymentIntent model shows the pattern: one object tracks progression from creation through checkout and preserves attempt history for later investigation. Whether your provider uses that model or result codes, the operating goal is the same. You need a status source and investigation chain that can be reconciled to real events.
At minimum, define these control points clearly:
- a single initiation event
- a state model that includes pending and intervention-required paths
- synchronization from provider events into internal status tracking, typically via webhooks
- an audit log of who did what and when
- idempotent retry handling so repeated mobile requests do not create duplicate operations
Decide verification checkpoints early. Every contractor-visible status should map to a backend event, provider state or result code, or a reconciliation-relevant update. If a state cannot be traced to a lifecycle record, webhook-driven event, or audit log entry, it is not production-ready. Apply the same discipline to reporting, since reconciliation failures often come from reporting-period and timezone mismatches.
This article stays in that lane. It focuses on production controls over visual inspiration, with emphasis on state handling, escalation rules, evidence paths, and release checkpoints that reduce manual cleanup.
Define mobile-first payment UX in operational terms#
Mobile-first payment UX is the full payment lifecycle on mobile, not just checkout polish. It starts at payment initiation and continues through status retrieval, settlement, and reconciliation.
For contractors, that means speed, clarity, and trust. For operations and platform finance, it means traceability: a stable reference, retrievable status, evidence of consent and authentication, and records that match the ledger. If your definition ends at "tap pay, see success," it can miss where mismatches and cleanup begin.
What belongs inside the definition#
UX covers the full interaction with the service, not only interface visuals. In payment operations, that means supporting both initiation and what happens after it. Status retrieval is part of payment-initiation capability, and settlement is where funds are finalized between parties. If a contractor can initiate payment on mobile but you cannot fetch status or explain where it stands, the experience is incomplete.
Use one practical checkpoint: every contractor-visible payment should have a stable transaction identifier you can retrieve later. Stripe's PaymentIntent ID is one example of that pattern. Without a reusable reference, support investigations become harder, reconciliation confidence can drop, and teams may create labels that do not map cleanly to real payment states.
Who you are designing for#
You are designing for two audiences at once. Contractors need low-friction mobile entry and clear security steps when consent or authentication is required. Internal teams need status traceability, fewer manual interventions, and records that reconcile with accounting.
That split defines success. A faster flow is only an improvement if it does not increase duplicate submissions, mismatches, or payment queues that require human handling. If simplification removes key references, status checkpoints, or evidence trails, the UI may improve while operations get worse.
If you're comparing app behavior across devices, Mobile Payment Apps for Contractors: iOS and Android Comparison covers the key differences.
Map the full contractor payment lifecycle before UI decisions#
Define a shared payment state map before you change mobile UI. If product, operations, and platform finance use different meanings for states like pending, paid, or failed, support handling and reconciliation can drift.
Use a real provider lifecycle as the backbone, then add internal states for review and accounting. Stripe's PaymentIntent lifecycle is a concrete example with statuses like requires_payment_method, requires_confirmation, requires_action, processing, requires_capture, canceled, and succeeded. It is not a universal model for every processor, but it shows the precision you need.
Use one shared state table#
Your state table should define the contractor label, internal owner, evidence artifact, and whether the state can write to the ledger or is status-only.
| State in your map | Example provider signal | Contractor sees | Primary owner | Evidence and source-of-truth note |
|---|---|---|---|---|
| Initiated | requires_payment_method or requires_confirmation | Payment started | Product or app backend | Store request record, a stable transaction ID (for example, a PaymentIntent ID), and idempotency key. Not a money-movement event. |
| Action needed | requires_action | Verify or complete a step | Contractor first, support second | Treat as intervention, not failure. Keep provider snapshot or webhook/event record as evidence. |
| Processing | processing | Payment pending | Operations monitoring | Final outcome is not known yet. Prefer webhook-driven updates for async methods that can remain here up to a few days. |
| Manual review | Review queue or internal hold | Under review | Risk or finance ops | Review case ID or queue item is the artifact. Avoid treating it as final failure while review is open. |
| Succeeded | succeeded | Payment completed | Platform finance for posting checks | Use money-movement evidence such as BalanceTransaction where available. This is where posting and reconciliation checks are meaningful. |
| Failed or canceled | canceled or terminal failure status | Payment failed | Support or product, depending on cause | Keep failure reason, event ID, and retry rule. Do not post success entries. |
Tie every state to evidence#
Each state needs a proof artifact and a clear owner. For asynchronous outcomes, webhooks matter because they push final results and include a resource snapshot your system can apply.
Set a hard checkpoint: every mobile-visible status must trace to a backend event, provider object, or ledger posting. If a contractor sees pending review and later failed, your team should be able to retrieve the transaction ID, relevant webhook or event ID, and review artifact without reconstructing logs by hand.
Archive evidence intentionally. Stripe Retrieve Event API access is limited to 30 days, so provider history should not be your long-term audit store.
Separate source of truth from derived labels#
Do not write ledger entries from UI transitions or optimistic client responses. Treat contractor-facing labels as derived status views over provider and internal events, not accounting facts.
When funds move in Stripe, each movement creates a BalanceTransaction. Use that as money-movement evidence for payout composition and reconciliation, while keeping it separate from your full company general ledger.
Document reconciliation triggers in the same state map. For manual payouts, Stripe places reconciliation responsibility on your team, so trigger reconciliation after final success and after the related money-movement evidence is available.
Write progression and timeout rules now#
State names are not enough. Add explicit rules for progression, retry, and timeout handling so product and ops execute the same playbook.
- If state is
requires_action, route the contractor back to the required step. Only treat it as failed after a terminal failed or canceled outcome. - If state is
processing, keep it in a true pending bucket. Some async methods can remain there up to a few days. - If mobile submit can be retried, require server-side idempotency keys so repeated requests return the same result, including
500responses.
Treat idempotency retention as an operations decision too. Stripe keys can be removed after at least 24 hours, so keep the key in your own records as part of the audit trail.
For a step-by-step walkthrough, see Agency Scaling Blueprint for Hiring Your First Global Contractors.
Design separate paths for new and returning contractors#
Once the state map is clear, split the contractor journey by what you already know. Use three routes. Create full onboarding for first-time contractors, a fast path for returning contractors with valid profiles and no new risk signals, and a policy-gate route when risk or required data changes.
Start with different assumptions#
First-time payouts typically need complete eligibility setup, but that does not mean collecting every future field on day one. Stripe Connect supports either up-front collection or incremental onboarding, so you can collect what is currently due and defer future-only requirements.
Returning payouts should prioritize speed only when core conditions still hold. If profile data is still valid and risk checks show no new flags, compress the flow to review, confirm, and submit. That is similar to stored-credential one-click patterns that reuse details already on file.
What the fast path can and cannot skip#
A fast path should remove repeated input, not required controls.
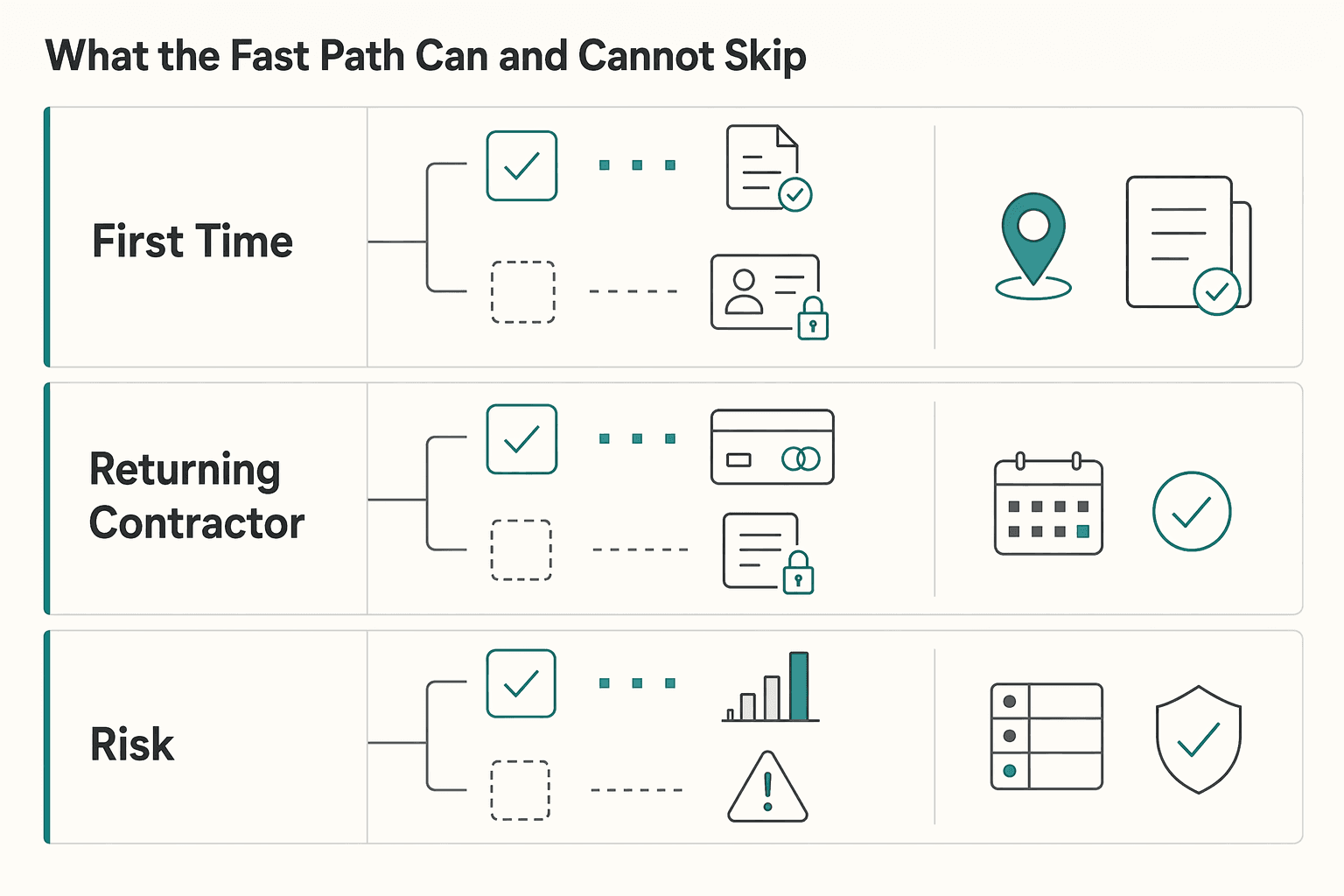
| Path | Can be compressed | Must stay mandatory |
|---|---|---|
| First-time contractor | Future-only fields, optional profile enrichment, nonessential education screens | Required identity or KYC inputs, payout setup, required terms acceptance, required review when payout eligibility is not yet met |
| Returning contractor, no new flags | Re-entry of unchanged profile data, repeated explainer screens, full payout-method re-setup | Required confirmation of prefilled data, required terms acceptance where applicable, backend risk check, auditable payout submit event |
| Returning contractor, risk changed or data stale | Only navigation simplification | Route to required policy gates, required step-up checks, review hold where payout cannot proceed safely |
KYC prerequisites for payout remain mandatory where your payment program requires them. Ongoing monitoring also remains in force, including risk-based updates to customer information over time.
Define reroute triggers up front#
Define fast-path break conditions before launch: newly required or outdated information, payout-profile changes, or new risk-review signals. Risk-aware authentication and policy routing can still apply to returning contractors when risk changes.
Set one hard checkpoint for auditability. For each fast-path payout, retain the contractor ID, profile version used, risk decision result, any required confirmation of prefilled data, required terms record, and the backend event that initiated payout execution.
One failure mode to watch for is silent staleness: a contractor appears eligible in the app, submits, and only then lands in review or failure. If eligibility cannot be evaluated before final submit, it is usually not a true fast path.
Add policy gates without breaking mobile completion#
Policy gates should change the decision, not just add friction. Put them where risk, regulation, or a material profile change can affect the outcome, and keep them off the rest of the flow.
For contractor payment UX on mobile, gate on risk signals, required regulatory triggers, and meaningful profile changes rather than on every tap. Modern identity guidance supports adding controls when context is anomalous, and EMV 3DS challenge flows can be triggered by high risk or by country requirements.
Hard blocks and soft prompts are not the same decision#
Treat retryable outcomes, step-up authentication, and no-retry outcomes as separate paths. If you collapse them into one failure state, recovery paths break.
| Outcome type | What it means | What your mobile flow should do |
|---|---|---|
| Risk-based step-up | Extra authentication is required because risk or regulation triggered it | Keep the user in the same payment attempt, launch the step-up path, then return to the original state |
| Soft decline | The payment was declined, but can be retried with authentication such as 3DS | Route to a retry path with authentication, not a permanent failure screen |
| Hard block | Retry is not allowed, or a required control failed | Stop the flow, explain the next action, and route to the documented escalation owner |
A soft decline should not send the contractor to a dead-end failure screen when the supported path is retry with step-up authentication. By contrast, Category 1 declines are no-retry outcomes, so escalation should not instruct repeated resubmission.
Put the gate where it changes the outcome#
Place the gate at the point where it can still change the outcome, typically at payment initiation or when a material risk signal appears. In PSD2-style contexts, SCA applies when a payer accesses an account online or initiates an electronic payment, with exemptions only under defined conditions.
If you use TRA, thresholds are specific. For card payments of EUR 100 or less, the PSP fraud-rate condition is 0.13% or less. Up to EUR 250, it is 0.06% or less. Even then, the payer-side PSP or issuer makes the final decision on accepting an exemption, so design for fallback step-up and soft-decline recovery.
Document escalation for blocked payouts, and log each gate decision with attempt ID, rule version, trigger reason, hard-versus-soft outcome, and escalation owner for operational review.
Earlier control versus later friction#
Make the tradeoff explicit before launch. Earlier checks can reduce late exception handling. Later checks can reduce upfront friction but may shift more exceptions to post-submit handling. Product, finance, and support should agree on which failure mode they are willing to absorb.
Expect market and program variance#
Do not hardcode one universal sequence. Gating logic differs by program and jurisdiction. UK SCA rules have applied since 14 September 2019, while India's 2025 authentication directions are primarily scoped to domestic transactions, with compliance required by April 01, 2026.
Use jurisdiction-aware and program-aware routing so authentication timing can change without rewriting the full mobile flow.
Make status tracking usable for contractors and finance teams#
Once gates are defined, status design has to carry both the contractor experience and the operational truth. Status tracking is stronger when one backend state model drives both contractor labels and ops handling, so the same payout is less likely to be described in conflicting ways.
Standardize labels from provider states, not from screen copy#
Start from provider-defined states, then map them to UI labels. Stripe's PaymentIntent flow includes states that require intervention, including requires_action with next_action, so avoid flattening those into a generic "pending." For payouts, keep Stripe lifecycle states distinct in operations, such as pending, in_transit, then paid, failed, or canceled, even if mobile shows fewer labels.
| Contractor-facing label | Internal state example | What the user should see | Evidence to retain |
|---|---|---|---|
| Action required | requires_action with next_action | Clear next step to continue payment or authentication | PaymentIntent ID, latest event, action type |
| Processing | pending | Request received plus last updated time | Payout ID, timestamp |
| Sent to bank | in_transit | Submitted to bank and processing | Payout ID, state-change timestamp |
| Completed / Failed | paid / failed / canceled | Final outcome plus support reference | Payout ID, final event |
Treat pending states as support content, not filler text#
Each status update should include a timestamp and, when applicable, the next action. Keep provider timestamp standards in APIs and internal records (for example, ISO 8601 where required), and render local time in the app if needed.
Keep messages tied to the real state. If status is requires_action, tell the contractor what action is needed. If payout is pending, say it has not yet been submitted to the bank. If it is in_transit, say it has been submitted and is processing. For ops context, Stripe notes that after bank submission, payouts can resolve to paid, or to failed or canceled within 5 business days.
Make the reference chain visible end to end#
Every payout event should carry a reference chain that survives contractor, support, and finance handoffs: your internal reference plus provider object IDs. Keep provider-native IDs visible in tools and exports when available.
PayPal's model shows why. Teams can track across reports using Transaction ID and PayPal Reference ID, and use payout_batch_id to retrieve payout status. If staff cannot move from the contractor-visible reference to the provider record quickly, resolution can slow and audit steps can become manual.
Before launch, run a traceability check for each mobile status. Confirm that each state can be traced to backend evidence, such as provider events and object IDs, including any derived UI status.
Design failure handling before launch day#
Failure handling should be designed before launch, not patched in after the first incident. Treat non-responses as ambiguous, make retries replay-safe by default, and assign first ownership for each exception path so support and finance are not improvising in production.
This follows directly from status design. If states are clear but exception paths are not, the same payout can appear as "processing" in the app and "unknown" in operations.
Build the failure-response table first#
Start with a compact table that locks detection, evidence, first owner, and contractor message to provider objects and your internal reference chain.
| Failure mode | Detection and evidence to keep | First actor you should assign | Contractor message rule |
|---|---|---|---|
| Duplicate submit or idempotent retry | Same request identity, same payload, one provider object ID, one ledger effect | Automation first | Confirm request received and continue processing. Do not ask the user to resubmit. |
| Timeout or missing response | Client timeout, no synchronous response, later webhook or provider lookup result | Automation first, then support if unresolved | Say the request is still being checked. Tell the user not to send again unless support confirms failure. |
| Reversal or returned payout | Provider event showing reversal, refusal, or return; payout ID; state timestamps | Finance ops first, support informed | Explain that the payout changed after submission and that review is in progress before any resend. |
| Mismatch between app, provider, and ledger | Status conflict across UI, provider event history, and internal journal or reference chain | Finance ops first | Avoid generic success or failure text. Tell the user the payment needs review and give a support reference. |
Before launch, confirm each row. Check what detects it, which record proves it, who acts first, and what the contractor sees.
Make retries replay-safe by default#
Assume duplicate submits can happen on mobile networks. Use one unique request identity per money-moving POST, and keep that same identity across retries of the same attempt.
| Provider | Term used | Article detail |
|---|---|---|
| Stripe | Idempotency keys | Up to 255 characters; keys can be removed after they are at least 24 hours old |
| Adyen | idempotency-key | Maximum length 64 characters; valid for a minimum of 7 days after first submission |
| PayPal | PayPal-Request-Id | UUID guidance within 38 single-byte characters; support varies by API |
Stripe supports idempotency keys up to 255 characters and notes keys can be removed after they are at least 24 hours old. Adyen's idempotency-key has a maximum length of 64 characters and is valid for a minimum of 7 days after first submission. PayPal uses PayPal-Request-Id for supported APIs, with UUID guidance within 38 single-byte characters, and support varies by API.
The key rule is simple: after a timeout or missing response, retry with the same idempotency identity, not a new one. A new identity can turn ambiguity into duplicate-payment risk.
Treat timeouts as unknown, not failed#
A timeout only means the client stopped waiting. It does not prove provider failure. Move the app into a "checking status" or "processing" state until you have a definitive provider event or lookup result.
Use webhook delivery to resolve ambiguous outcomes and reconcile that event back to the original request identity and payment record. Do not create a second processing path for the same attempt.
Do not use one universal timeout or retry count across providers. Set your own thresholds and use backoff with jitter to reduce synchronized retry bursts during incidents.
Define reversals and mismatches before finance sees them#
Design for post-success exceptions. A payout reversal can move from paid to failed, so UX and ops need a clear handling path even when users believed payment was final.
Keep provider windows provider-specific. Stripe reversal eligibility includes payouts expected to arrive less than 90 days ago. PayPal notes unclaimed payouts are returned after 30 days. Treat these as different cases with different handling.
For mismatches, require an evidence pack before manual status edits: internal reference, provider object ID, latest webhook payload, request identity, and related ledger or journal records. If app status conflicts with provider history or ledger state, pause self-serve resend and route to review.
Give contractors a next step, not a dead end#
Exception copy should prevent repeat attempts and reduce support noise:
- If the request timed out, say it is still being checked and ask the user not to submit again yet.
- If the request was safely retried, confirm receipt and say it is processing.
- If the payout was reversed, say the transfer changed after submission and is under review.
- If records do not match, say manual review is required and show a support reference.
Avoid generic "try again" when money movement is still uncertain. In mobile flows, that prompt can create the duplicate you later need to unwind. Related: Mobile-First Payout Experience: How to Design Contractor Payment Flows for Mobile.
Connect mobile UX choices to ledger and reconciliation outcomes#
If failure handling is weak, finance will end up cleaning up the result. Your mobile payout UX is operationally sound only if finance can trace each money-moving tap to provider evidence and a reconciliation path. Treat that traceability as a priority control for critical paths, not a nice-to-have after launch.
Every action that can move money needs an explicit accounting expectation in your ledger and a later reconciliation check. Use your own chart of accounts, but keep the journal outcome explicit so the app state, provider object, and internal record stay aligned.
| Mobile action | Expected internal record | Provider or report evidence | Reconciliation check |
|---|---|---|---|
| Submit payout | One payout-initiation journal sequence tied to your internal reference | Provider payout object or equivalent ID | Can you trace that record into payout reporting without manual lookup? |
| Retry same payout after timeout | No new money-moving journal if it is the same attempt | Same provider object and reference for the same attempt | Confirm one ledger effect, not two |
Show processing or other pending states | Open item remains unresolved, not treated as final cash movement | Provider lifecycle still pending | Keep it on the open-items list until settled or failed |
| Mark payout paid or completed | Completion journal posted only when supported by provider event or report | Stripe balance transaction, payout reporting, or equivalent settlement evidence | Match completed status to settled funds, not just UI success |
| Resend after reversal or return | New journal sequence with a link back to the original failed payout | Reversal or return evidence and new payout ID | Reconcile original and replacement separately |
Weak state design becomes month-end noise#
Weak state design turns into reconciliation noise fast. Funds in pending balance are not settled or spendable yet, so if your app says "paid" while provider lifecycle is still pending, you create preventable mismatches.
Long-running processing can also create reconciliation discrepancies. Unresolved pending states, broken reference chains, and settlement timing gaps can add month-end exceptions.
Manual edits increase risk here. Matching logic depends on stable references, and changed matched records can become unmatched and unreconciled again. Keep manual status edits rare and evidence-based.
Use the provider artifacts that actually close the loop#
Define the exact artifact your team will rely on before launch. For Stripe, use balance transaction records and payout reconciliation reporting to connect payout deposits back to underlying transactions. Automatic payouts preserve transaction-to-payout association. With manual payouts, your team owns that reconciliation work.
For Adyen, settlement reconciliation is batch-driven, so batch close is a real control point. Configure payout frequency before settlement reconciliation, and use transaction-level settlement details when reconciling per payment.
Give platform finance a pre-close input list#
Before each batch payout window, give platform finance a short operational checklist:
- Open
pending stateswith internal reference, provider object ID, age, and expected next evidence - Payout frequency and batch-close timing confirmed for providers that reconcile by settlement batch
- Separate queue for manual payouts, because reconciliation ownership is operator-side
- Lagging exceptions still in watch status, including returned payouts that may come back in 2-3 business days and payout traces that can remain pending for up to 10 days after
arrival_date - Close assumptions pinned, including report-handling changes that affect journal interpretation, such as Stripe's Debits and credits handling change from March 1, 2025
Keep one standard across this section: do not show a contractor-facing money state unless finance can tie it to backend evidence and a defined reconciliation path.
A good mobile payment experience still depends on a clean accounting foundation, so How to Build a Deterministic Ledger for a Payment Platform is useful if you're aligning product design with finance operations.
Set iOS and Android implementation priorities with ops impact in mind#
Once ledger and reconciliation rules are set, prioritize behavioral parity over visual parity. The critical requirement is the same money-moving behavior on iOS and Android. You need the same initiation logic, the same retry protections, and the same state meaning when the app is interrupted and resumed.
The main risk is platform background execution, not UI cosmetics. On Android 6.0+ (API level 23), Doze and App Standby can block network access and defer jobs, which can delay status refreshes and retry timing. For flows that must survive screen exits or app invisibility, use WorkManager so work can persist across app restarts and device reboots with configurable retry and backoff. On iOS, background URLSession can continue transfers when the app is suspended or terminated, but force-quit is a real edge case: background transfers are canceled and the app is not automatically relaunched.
| Reliability concern | iOS priority | Android priority | Ops rule |
|---|---|---|---|
| Payment initiation survives app interruption | Background URLSession where transfer continuity matters | WorkManager for persistent work | One server-side request identity across resumes |
| Retry after timeout or weak network | Resume using a prior request reference when available | Retry with backoff, not blind resubmit | Idempotency on every money-moving create or update |
| UI parity choices | Native navigation patterns can vary | Native component patterns can vary | Core payout states and controls must not vary |
Keep parity strict for anything that can change cash state: submit behavior, disabled and loading states, processing, failed, completion labels, retry eligibility, reference visibility, and support escalation paths. Let lower-risk elements follow platform conventions, such as toolbar title alignment or peripheral navigation components.
Before launch, run one interrupted-flow scenario on both platforms with the same internal payout reference and confirm one backend operation, one idempotency key, and one reconciliation path. If your API supports idempotency keys, keep each key stable for a single logical attempt. Stripe allows keys up to 255 characters and says they can be pruned after at least 24 hours. If Android retries through WorkManager while iOS may require a fresh submit after force-quit, duplicate-submit risk rises unless both paths resolve to the same backend attempt. Related reading: Virtual Cards for Contractors and the Real Cost of Getting Issuance Wrong.
Use launch decision checkpoints across product, ops, and finance#
Launch should be a go or no-go decision on operational readiness, not a calendar milestone. For mobile-first contractor payment flows, ship only when exception handling is tested and you can show what changed, who approved it, and how rollback works if money movement behaves unexpectedly.
Use a formal cutover go or no-go checkpoint with stakeholder sign-off, not an informal approval. If any critical payout path still lacks traceable evidence through reconciliation, treat that as a launch blocker.
Define the minimum evidence before go-live#
Your go-live checklist should answer these questions with evidence:
- Is coverage complete across key money-moving paths and outcomes?
- Have exception paths been tested across system, integration, functional, user acceptance, and security testing?
- Is the audit workflow ready, including a persistent change trail and documented rollback steps?
Prioritize business sign-off on completed test cycles with exit criteria met. Product, operations, and finance stakeholders should confirm that payout references and reconciliation outputs are traceable and that escalation paths are clear.
If evidence is thin, do not compensate with launch messaging. Keep an approved change record, test results, audit-trail artifacts, rollback steps, and at least one reconciliation view that ties each payout to the transactions it settles.
Make unresolved risk ownership explicit#
Require sign-off from product, operations, and finance stakeholders, with explicit system-owner authorization before implementation. Shared awareness is not enough. Assign each unresolved risk a clear owner, mitigation plan, and escalation trigger.
If a known issue appears during rollout, ownership should already be clear. For example, if a duplicate-submit edge case is still open, define who decides pause or continue, who reviews affected payout references, and who communicates to support.
Drill the failure modes before launch#
Run tabletop exercises for the top failure modes. Use payment-flow scenarios so teams validate roles, decision rules, and escalation contacts before release.
Useful scenarios include provider timeout after submit, failed automatic payout, reconciliation mismatch, and an ACH exception case requiring documentation exchange. In each drill, confirm the first responder, the communication plan, and the evidence used to decide whether funds moved.
Tie post-launch review to reconciliation and exceptions#
Set review windows before launch so monitoring starts on day one. A practical cadence can include a same-day operational check for asynchronous events and failed payouts, then a daily finance review after reconciliation data is available.
Stripe payout reconciliation data is computed daily beginning at 12:00 am, which supports a next-morning review cycle. If you operate ACH, monitor exception trends and relevant return-rate levels. For example, 3.0% administrative and 15.0% overall apply in Nacha inquiry or evaluation context. Treat those thresholds as ACH-specific rather than universal. If unmatched payouts, failed payouts, or exception cases rise after release, handle it immediately as a cross-functional issue.
Account for country and program differences without overpromising#
Do not promise one universal payout experience. Country support, payout rails, and compliance sequencing vary by market and provider program, so each launch corridor needs its own approval and evidence pack.
| Program | What varies by market | Article detail |
|---|---|---|
| Stripe | Onboarding requirements and initial payout timing | Country Specs document country-specific onboarding requirements; initial payouts are typically scheduled 7-14 days after the first successful live payment |
| Adyen | Verification requirements | Verification requirements vary by country or region |
| PayPal | Payout capabilities | Payout capabilities are separated by country feature level |
| Venmo | Regional availability | US-only |
Stripe documents country-specific onboarding requirements through Country Specs, Adyen states verification requirements vary by country or region, and PayPal separates payout capabilities by country feature level. Some country setups are receive-only, and some rails are region-locked, for example Venmo is US-only. If your mobile UX shows identical payout options everywhere, it likely overstates real support.
Latin America is a practical example of why this has to be handled country by country. The World Bank reports that 11 countries in the region have followed different fast payment system trajectories, with central-bank-operated FPS in Brazil, Bolivia, Costa Rica, El Salvador, Mexico, and Paraguay. So even when the contractor journey looks similar on screen, onboarding fields, payout behavior, and control points can differ by country. Timing can differ as well: Stripe says initial payouts are typically scheduled 7-14 days after the first successful live payment. Avoid copy that implies identical first-payout speed across countries or risk tiers.
What to verify before rollout#
Before launching a new market or program, confirm in current provider and compliance docs:
- live country coverage, including whether that country can send payouts or only receive them
- required onboarding and verification fields for that country or region
- payout rail and currency limits, including conversion restrictions that affect settlement
Use a versioned market matrix with country, provider program, enabled rail, required documents, and expected reconciliation path. A failure mode is promising a method or timeline the provider does not support in that country, then discovering the mismatch in support before finance sees it in reconciliation.
Ship a practical 90-day execution checklist#
Treat this 90-day plan as a proving window, not a universal benchmark. Do not expand the payout flow until critical paths have clear ownership, retry safety, and reconciliation you can defend.
| Weeks | Focus | Checkpoint or gate |
|---|---|---|
| Week 1-2 | Lock the state model and owner map for critical paths first | Every app status must trace to a backend event or ledger change |
| Week 3-6 | Instrument status tracking and make retries safe before adding volume | Test idempotent retries under real mobile failure patterns and keep provider event IDs and internal request IDs as separate controls |
| Week 7-10 | Run pilot traffic end to end and reconcile production outcomes against transaction history and system-of-record outputs | Fix the reference chain before scaling if finance still needs manual stitching across tools |
| Week 11-13 | Scale by cohort, not by global switch | Gate promotion on reconciliation health, support load, and exception aging |
Week 1-2#
Lock the state model and owner map for critical paths first. At minimum, map first payout, repeat payout, timeout, manual review, reversal, and mismatch.
For each path, define the contractor-facing mobile status, internal status label, state-change trigger, owning team, and whether it writes directly to the ledger or is derived. Keep one shared checklist artifact that product, ops, and finance all use, including reference chains, event names or sample payloads, and required finance evidence for incident review. Checkpoint: every app status must trace to a backend event or ledger change.
Week 3-6#
Instrument status tracking and make retries safe before adding volume. Payment stages are often asynchronous, and webhooks are used to track them. Some provider responses can be intermediate states, not final outcomes.
Test idempotent retries under real mobile failure patterns, for example duplicate taps after a poor connection. Stripe recommends idempotency keys for create or update calls, and PayPal uses PayPal-Request-Id on REST POST calls to help prevent duplicate effects. Keep provider event IDs and internal request IDs as separate controls.
Simulate reversals and mismatches in this window. For ACH flows, test against ACH-specific reversal rules: reversal fields like Company ID, SEC Code, and Amount must match the original, and timing is within 5 banking days. If the flow is not ACH, do not apply that rule set by default.
Week 7-10#
Run pilot traffic end to end, then reconcile production outcomes against transaction history and system-of-record outputs. Use payout settlement-batch reconciliation and include instant payout transaction-history checks.
Review each pilot from mobile action to provider event to ledger journal to payout or bank-facing record. If finance still needs manual stitching across tools to explain a critical path, fix the reference chain before scaling.
Week 11-13#
Scale by cohort, not by global switch. Use a canary-style rollout so a subset proves performance before broader exposure.
Add promotion gates and enforce them. At minimum, gate on reconciliation health, support load, and exception aging, and block promotion when criteria are not met. Expand only after the current cohort shows stable evidence.
When you turn this plan into implementation tickets, use the Gruv docs to align status models, retries, and webhook handling with your ops workflow.
Conclusion#
A mobile-first contractor payment flow is only ready when it stays traceable through retries, stalled states, audit review, and reconciliation without manual reconstruction.
Before launch, align payment initiation, status tracking, policy gates, and reconciliation to the same underlying events and records. If a mobile status cannot be tied to a backend event or transaction record, treat it as unfinished work.
Define explicit non-final and final states, then drive action-required states to a final outcome. Show clear status feedback and next-step guidance when processing is still in progress or stalled, because progress indicators only help when they reflect actual system state.
Design first for retry risk on weak connections. Use idempotency so repeated requests do not create duplicate operations, and account for key lifecycle rules, for example keys can be removed after at least 24 hours. A reliable path should let you trace one chain from request key through status updates to the resulting payout or transaction record.
Use reconciliation as a release gate, not a cleanup task. Reconciliation is batch-oriented in major platforms, with payout and settlement reporting designed to match bank payouts to underlying transactions, and instant payouts still require your team to reconcile against transaction history. If finance cannot trace a pilot corridor end to end without spreadsheet stitching, do not scale yet.
Apply the checklist from this article to one payout corridor first, and force it through retry tests, timeout handling, action-required states, payout reconciliation, and audit-trail review. If that pilot holds, expand corridor by corridor or cohort by cohort, and keep the rule simple: no new market, rail, or fast path until traceability, status messaging, and reconciliation quality remain reliable.
Before rollout across markets, confirm program coverage and policy-gate details for your payout corridors with Gruv's team.
Frequently Asked Questions
What is mobile-first payment UX for contractors in operational terms?
It is the full payment lifecycle on mobile, not just checkout design. It includes initiation, status updates, exceptions, settlement, and reconciliation in one connected flow. If a mobile status cannot be traced to backend evidence and a payout or reconciliation record, the UX is incomplete.
What are the must-have states in a contractor payment flow?
Use clear non-final and final states that ops and finance can act on. A practical baseline includes pending, in_transit or another processing state, paid, failed, and canceled, with review states where needed. Do not collapse intermediate states into success or failure before the provider reaches a final outcome.
How do we reduce mobile friction without weakening compliance controls?
Use risk-tiered controls instead of removing gates across the board. Keep lower-friction paths only where policy allows and risk stays low, and reroute changed-risk or newly required cases through required checks. In PSD2 scope, strong customer authentication can still apply to online account access and electronic payment initiation.
Which failure modes should we design first for contractor payouts?
Start with duplicate submits, provider timeouts, and non-final states that can stall. Use idempotent requests so retries after weak connections do not create duplicate money movement. For each exception, keep a traceable chain from internal request to provider status to payout or reconciliation record.
What should finance and ops measure to confirm the flow is working?
Track failed payout volume and reconciliation completeness first. Use payout reconciliation reporting to match bank payouts to the settled transaction batches underneath them, and review failed payout breakdowns directly. If a payout cannot be traced end to end without manual stitching, treat it as an operational risk.
How should we handle new versus returning contractor payment paths?
Do not assume returning contractors can always skip controls. Use faster paths only when profile data remains valid, risk stays low, and policy allows it. Route changed-risk, stale-data, or newly required cases back through required checks.
How do country and program differences change payout UX decisions?
They change available payout features, onboarding requirements, rails, currencies, and expected timing. Some markets have limited or restricted payout features, and country feature tiers vary, so one global timing template is unreliable. Validate each program and corridor before rollout.
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
- blogs.worldbank.org/en/latinamerica/fast-payment-digital-transfo...trusted
- csrc.nist.gov/glossary/term/audit_logtrusted
- csrc.nist.gov/glossary/term/Tabletop_Exercisetrusted
- docs.stripe.com/api/idempotent_requeststrusted
- docs.stripe.com/payments/paymentintents/lifecycletrusted
- ecfr.gov/current/title-31/subtitle-B/chapter-X/part-1...trusted
- ithandbook.ffiec.gov/it-booklets/information-security/ii-informat...trusted
- ithandbook.ffiec.gov/it-booklets/retail-payment-systemstrusted
Educational content only. Not legal, tax, or financial advice.
Related Posts

The Freelance Payment Penalty: A Modeled Audit of Platform Fees, FX Spreads, and Payout Delays
The money rarely disappears through a single, easy-to-spot fee. The real loss is stacked. A marketplace takes its commission, a processor adds a charge for international cards, a bank or payment company converts the currency at a spread, a platform holds the funds before release, and a wire sheds a little to intermediaries on the way in. Each layer looks defensible on its own, but the worker feels the combined result as a smaller deposit and a later payday.

How to Respond to a Subpoena for Business Records
Move fast, but do not produce records on instinct. If you need to **respond to a subpoena for business records**, your immediate job is to control deadlines, preserve records, and make any later production defensible.

A US Expat's Guide to Investing in UCITS ETFs to Avoid PFIC Issues
The real problem is a two-system conflict. U.S. tax treatment can punish the wrong fund choice, while local product-access constraints can block the funds you want to buy in the first place. For **us expat ucits etfs**, the practical question is not "Which product is best?" It is "What can I access, report, and keep doing every year without guessing?" Use this four-part filter before any trade: