
Quick Answer
Use dunning for subscription platforms as an operations sequence, not just a reminder campaign: detect a failed renewal, apply retry rules, send customer notices, offer a payment-method update path, then decide account state. Begin with billing-native defaults, but only keep them if finance can reconcile outcomes cleanly. The article’s checkpoint is concrete: for one failed invoice, confirm provider result, internal status, and final ledger posting all match before enabling aggressive auto-cancel behavior.
What Dunning Looks Like in a Subscription Platform#
Most articles stop at the definition. That part is easy. The harder question is whether your team can choose an approach that product, engineering, finance, and ops can actually run without creating hidden risk.
- Dunning is simple to define, but harder to run well
At its core, dunning is the process of asking customers for money they owe. In recurring billing, that usually means an automated response to failed or overdue payments, not a one-off reminder from finance. This guide treats it as an operating decision, not a vocabulary lesson.
- Failed payments are a churn problem, not just a collections problem
Many payment failures have nothing to do with a customer choosing to leave. Common causes include expired cards, insufficient funds, and bank-side authentication issues, which is why involuntary churn needs its own treatment. Stripe has said failed subscription payments can cost businesses approximately 9% of annual revenue, so the recovery path matters before you even get into cancellation policy or retention math.
- Subscription platforms need a broader lens than reminder emails
If you run recurring billing, the real work starts after the first decline. You have to decide what happens next across customer notices and other recovery steps, including payment method updates, retries, and account state. The scope here is practical: how those decisions connect to billing behavior, not just how to word a reminder email.
A strong recovery process can save revenue and reduce churn, but only if the moving parts stay consistent. Your customer experience, payment handling, and financial records cannot tell three different stories. Start with one checkpoint. If your team cannot trace a failed charge to the notice sent, the retry decision made, and the recorded outcome, you are not ready for aggressive automation.
This is where teams get into trouble. They may improve retries or messaging, recover some cash, and still face messy reconciliation, confused support cases, or disputed account status. The failure mode is not always low recovery. It can also be weak auditability, duplicate actions after repeated payment events, or customer trust damage when an account gets restricted even though payment was later fixed.
There is no universal template to copy. Approaches and requirements vary across countries, so a policy that feels routine in one market may need different controls in another. The goal of this guide is narrower and more useful: help you choose an approach that improves failed-payment recovery and involuntary churn outcomes while keeping your books accurate, your audit trail clean, and the customer experience clear.
How to choose a dunning approach for your platform#
Choose the dunning setup your team can explain end to end across product, engineering, and finance, not the one with the strongest marketing claim.
| Factor | Detail | Check |
|---|---|---|
| Recovery impact | Stripe cites failed subscription payments as costing businesses about 9% of annual revenue | Confirm the change recovers real revenue, not just reminder volume |
| Native baseline | Yotpo default: 8 payment attempts once per day; configurable from 1 to 15 attempts before cancellation | Use this as a starting point, not a universal target |
| Traceable outcomes | Verify recovered payment, attempts exhausted and canceled, and customer cancellation while in dunning | Trace request, provider response, and ledger effect; in Yotpo, cancellation while in dunning stops further attempts |
| Non-collectible events | Yotpo prepaid $0.00 charges on delivery dates are non-collectible events | Do not treat them like collectible failed payments; score compliance friction and operating overhead separately from recovery |
- Score recovery impact first
Start with failed-payment exposure, because that is the business case. Stripe cites failed subscription payments as costing businesses about 9% of annual revenue, so first confirm whether a change will recover real revenue, not just increase reminder volume.
- Use native defaults as a baseline, not a verdict
Native dunning can be enough for straightforward billing rules. In Yotpo Subscriptions, the default is 8 payment attempts run once per day, and merchants can configure 1 to 15 attempts before cancellation. Treat that as a starting point, not a universal target.
- Make outcome traceability a hard gate
Before rollout, verify you can clearly trace retry outcomes across request, provider response, and ledger effect for: recovered payment, attempts exhausted and canceled, and customer cancellation while in dunning. In Yotpo, if a customer cancels while in dunning, further attempts stop.
- Score compliance and operational friction separately from recovery
Include compliance friction and operating overhead in the decision, but do not let that hide core retry behavior. Also check event handling so non-collectible events, such as Yotpo prepaid $0.00 charges on delivery dates, are not treated like collectible failed payments.
For more detail, see A Guide to Dunning Management for Failed Payments. If you want a quick next step, try the free invoice generator.
The best dunning setups for subscription platforms#
For most platforms, the practical order is simple: start native, add an overlay only if messaging/testing is the bottleneck, and build deeper orchestration only when policy and control requirements justify it. Keep the setup you can trace end to end from retry attempt to provider result to finance records.
| Setup | Best for | Key pros | Key cons | Concrete use-case | Required integrations | Verification checkpoints |
|---|---|---|---|---|---|---|
| Billing-suite native dunning | Teams already deep in Stripe Billing or Maxio | Fast launch, built-in retries, fewer moving parts | Less control in edge cases and segmented grace logic | Single-entity SaaS with standard card failure patterns | Billing-suite configuration, webhooks, finance mapping to journal outcomes | Validate recovered payment, attempts exhausted, and customer-canceled-during-dunning outcomes in records |
| Revenue-recovery overlay | Teams that need faster messaging/testing cycles, including tools like ProsperStack | Faster experimentation on timing and payment-update prompts | Added integration complexity, attribution complexity, duplicate-comm risk | High-volume card renewals where communication optimization is the main lever | Billing suite + overlay events, shared customer state, webhook deduping | Keep one source of truth for attempt state and reconcile "recovered" claims to provider-confirmed success |
| In-house orchestration on billing rails | Teams with strong engineering capacity and strict policy control needs | Custom retry logic, segmented rules, tighter product control | Build and maintenance burden, higher testing load | Multi-plan embedded payments with nonstandard retry and grace policies | Billing APIs, webhooks, internal state service, finance mapping, support tooling | Test idempotency, out-of-order webhooks, and cancellation suppression after successful recovery |
| Hybrid financial-infrastructure orchestration | Platforms that need lifecycle control across Gruv modules and billing systems | Stronger audit trail, clearer handoffs across product/finance/ops | More design work upfront, more dependency mapping | Contractor, creator, or marketplace models with cross-border complexity | Gruv modules + billing provider + compliance states + payout controls + finance records | Confirm recovery state cannot trigger payout release, hold release, or MoR state changes without explicit approval logic |
- Billing-suite native dunning
Use this first when billing rules are straightforward and your core issue is missed collections. Stripe/Maxio-native retries are often the lowest-friction starting point because billing objects and retry state already live in one system.
- Revenue-recovery overlay
Add this when experimentation speed is the limiting factor. The native-vs-dedicated split is a real decision category, but treat it as a routing choice, not automatic proof of better recovery.
- In-house orchestration on billing rails
Build this when retry policy is product behavior, not just collections ops. If you use Stripe Connect and choose "you handle pricing," Stripe lists $2 per monthly active account and 0.25% + 25¢ per payout sent. If Stripe bills connected accounts directly, Stripe says platforms do not incur additional account, payout volume, tax reporting, or per-payout fees.
- Hybrid financial-infrastructure orchestration
Choose this when dunning is tied to broader money-lifecycle controls. With Gruv, define authority by state, such as retry eligibility, payment-method updates, payout holds, and posting completion, so teams can enforce controls without breaking recovery paths.
If you want a deeper dive, read Subscription Billing for Platforms: How to Manage Plans Add-Ons Coupons and Dunning.
What every setup must automate from day one#
Once you choose native, overlay, or custom orchestration, the non-negotiables are the same: automate the failed-payment flow so product, support, and finance are working from the same state.
- Lock the order of operations
Define one clear sequence for every failed charge: detect failure, decide the retry path, notify the customer, provide a payment-method update path, then decide subscription state. This keeps your dunning flow aligned with the core model of notifying customers and guiding corrective action after a failed subscription payment.
Visibility matters as much as automation. You should be able to see whether an account is waiting on a retry, a customer update, or a final status decision.
- Handle retries and repeated events consistently
Treat repeat outcomes as normal and make sure the same event does not create conflicting customer actions or finance outcomes. The goal is one clear business result per real payment outcome, even when systems resend or replay events.
A practical check is to replay failed-payment and recovery paths in test and confirm your subscription and finance states still agree.
- Separate recoverable failures from true exceptions
Most failed payments are operational, not immediate cancellation intent. Common causes include expired cards, insufficient funds, authentication issues, bank declines, and billing errors.
Route recoverable cases into self-serve updates plus retries, and send only true exceptions to ops. If every renewal cycle floods your queue, your exception criteria are too broad.
- Verify billing outcomes before hard cancellation
Before you enable aggressive cancellation behavior, confirm your billing outcomes and finance records are aligned on the key end states. This reduces avoidable customer impact and prevents downstream support and accounting conflicts.
Keep the checkpoint focused on your core outcomes and fix mapping gaps before expanding cancellation automation. For a broader view, read Best Platforms for Creator Brand Deals by Model and Fit.
Where to put compliance gates without killing recovery#
Place compliance gates where risk is real, and keep payment repair fast for legitimate accounts.
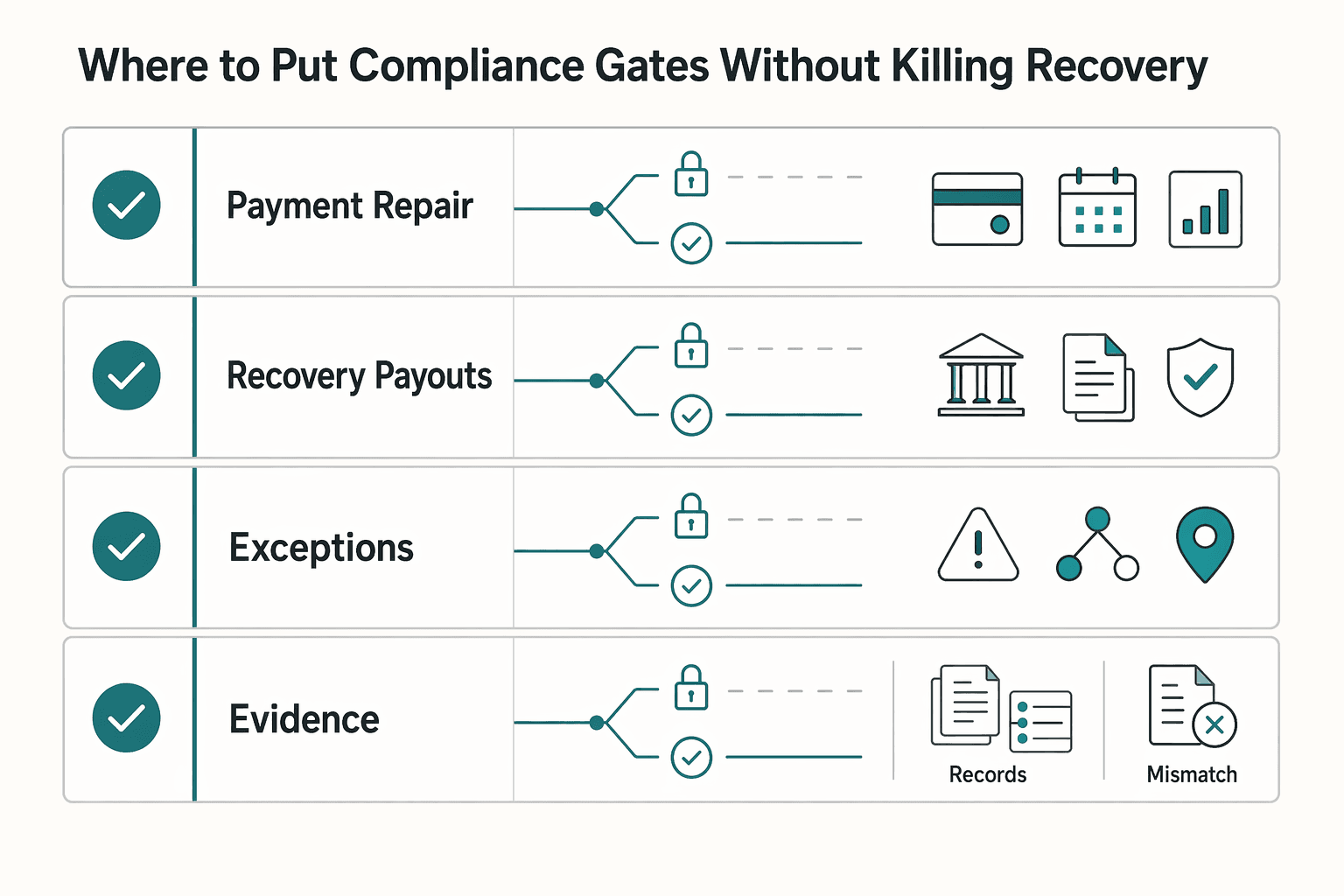
| Area | Keep separate | Grounded note |
|---|---|---|
| Payment repair | Payment-method update path from manual compliance review | An existing account should be able to move from failed payment to recovered without defaulting to manual compliance review |
| Recovery vs Payouts | Recovery status from Payouts release | Recovery is about collecting earned revenue; payout eligibility is about whether funds can be released under compliance rules |
| Market/program exceptions | Billing recovery from payout release or location-driven compliance | Tax obligations for digital products are generally tied to customer location, not company location; do not imply universal Merchant of Record or local-rail behavior |
| Evidence pack | Policy matrix, escalation owner, and audit evidence | Record what is gated, who owns review or override, and what decision was taken and when |
- Gate money movement, not basic payment repair
Put KYC, KYB, and AML checks on higher-risk actions, but keep the failed-payment update path clean when a customer is simply fixing a payment method. Failed payments often sit with other revenue-leakage issues, so adding avoidable friction can delay collection without reducing meaningful risk. Use a simple checkpoint: an existing account should be able to move from failed payment to recovered without defaulting to manual compliance review.
- Keep recovery status separate from Payouts eligibility
Treat recovery and Payouts release as separate decisions. Recovery is about collecting earned revenue; payout eligibility is about whether funds can be released under your compliance rules. If you collapse both into one status, you can block valid recovery for reasons unrelated to billing. Keep explicit states for each and log how they connect.
- Document market and program exceptions in policy
Recovery performance and payment-failure patterns vary by market, and cross-border operations add tax, payment, and operational complexity. Tax obligations for digital products are generally tied to customer location, not company location. For global programs, do not imply universal Merchant of Record or local-rail behavior. Record market/program exceptions in your policy matrix so teams can see whether a gate is about billing recovery, payout release, or location-driven compliance.
- Retain a minimal evidence pack for each gated action
Keep each decision auditable with a short, repeatable record:
- Policy matrix: what is gated, why, and whether it affects recovery, payout release, or both
- Escalation owner: the team or role responsible for review or override
- Audit evidence: what decision was taken and when
This is the balance: strict controls where risk is material, and a fast path when a customer is trying to recover a failed payment. Related reading: Choosing Between Subscription and Transaction Fees for Your Revenue Model.
How to keep dunning decisions reconcilable in the ledger#
Use your ledger as the source of truth for dunning outcomes, and only finalize cancellation, write-off, or recovery states when the matching entries reconcile.
| Control | Requirement | If not aligned |
|---|---|---|
| Journal mapping | Define posting patterns for every retry, recovery, write-off, and reversal | Finance cannot trace provider events, internal decisions, and resulting entries without manual backfilling |
| Webhook handling | Design for out-of-order events, duplicates, and late provider confirmations from asynchronous Webhooks | Duplicate postings or incorrect account-status flips can occur |
| Status disagreement | If provider status and ledger state diverge, route to an exception queue | Pause access removal, account closure, and downstream notices until reconciliation completes |
| Close review | Review open unpaid invoices, recovered revenue, and unresolved exception queues directly | If contract terms changed during dunning, treat it as a revenue-schedule adjustment case, not a standard recovery posting |
- Map each billing outcome to a journal pattern
Define posting patterns for every retry, recovery, write-off, and reversal before automation goes live. For any unpaid invoice, you should be able to trace the provider event, your internal decision, and the resulting entries without manual backfilling.
Run a simple check: pick one invoice that failed and later recovered, then confirm finance can trace the full sequence end to end. Keep reversal notes as part of that trail; in SAP S/4HANA 2021, reversal reasons for dunning notice reversals are available and optional, but recording them improves traceability.
- Assume Webhooks will be messy
Design for out-of-order events, duplicates, and late provider confirmations from asynchronous Webhooks. Your handling should prevent duplicate postings and prevent account status from flipping incorrectly when callbacks replay.
Idempotency and sequencing are the core controls. Replayed events should not post a second recovery, and late success events should trigger reconciliation actions instead of silently overwriting prior accounting outcomes.
- Freeze cancellation downstream when provider and records disagree
If provider status and ledger state diverge, route to an exception queue and pause cancellation-driven actions until reconciliation completes. That includes access removal, account closure, and downstream notices that assume non-payment is final.
Make the exception operationally visible: provider status, journal IDs, event timestamps, and current owner should be easy for support and finance to see in one view.
- Build finance close checks around unpaid invoices and exceptions, not dashboard wins
Reconciliation should match payments to records so you can catch missed, duplicate, incorrect, or unauthorized transactions early, while supporting accounting and tax-compliance controls.
During finance close, review open unpaid invoices, recovered revenue, and unresolved exception queues directly. If contract terms changed during dunning, such as an upgrade or downgrade, treat that as a revenue-schedule adjustment case, not a standard recovery posting.
Decision checkpoints before you enable cancellation automation#
Treat cancellation as a last resort. Do not enable auto-cancel until retries, customer messaging, and a grace period are working as intended.
- Fix the payment-update path before hard cancellation
Dunning starts when a scheduled payment fails, but reminders alone do not recover accounts. If messages are live and customers still struggle to update payment details, delay hard cancellation and fix that flow first. Run the full journey yourself and confirm support can reproduce it end to end.
- Use conservative cancellation thresholds until retry logic proves itself
Smart dunning retries first, then escalates to customer notifications if retries fail. If you still run one generic retry policy across failure types, keep cancellation conservative and expand only after cohort-level results show what actually recovers.
- Define clear fallback states for dependency-blocked accounts
If non-payment dependencies can block account actions, make the account state explicit before cancellation is considered. Support should be able to tell whether the case is in payment recovery, dependency resolution, or both, and follow a short, repeatable resolution path.
- Publish owner-level go/no-go criteria before launch
Auto-cancel should launch only after product, engineering, and finance agree on decision rules, exception handling, and rollback triggers. Put that decision record in writing before enabling automation.
For a step-by-step walkthrough, see Retainer Subscription Billing for Talent Platforms That Protects ARR Margin.
Mistakes that quietly increase churn and audit risk#
The biggest dunning failures are usually process failures, not obvious bugs. Treat these as launch-time controls, not cleanup work for later.
- Believing recovery claims you cannot inspect
Do not use headline recovery rates as policy input unless the method is transparent. If a case study or internal summary does not clearly show cohort, time window, recovery definition, and post-recovery outcomes, treat it as directional only and measure your own baseline first.
- Reducing dunning to email copy
Dunning is not an email program; it is a system across API, Webhooks, and Ledger state. Validate one failed payment end to end so provider response, retry state, customer-facing status, and finance records stay aligned.
- Letting tax workflows leak into payment recovery
Keep FEIE, FBAR, and 1099 workflows adjacent to recovery, not embedded in retry or cancellation logic. FEIE depends on tax conditions like a foreign tax home and physical presence of 330 full days during any period of 12 consecutive months (the days do not have to be consecutive), and excluded foreign earned income still must be reported on a U.S. tax return. FBAR is a separate "Report Foreign Bank and Financial Accounts" topic, so document explicit handoffs instead of mixing these checks into dunning state decisions.
- Ignoring red flags until close
Define red flags before launch: repeated retries with no state change, unresolved unmatched events, and manual overrides without audit notes. When one appears, pause automation on that account and require a clear note on who changed state, why, and what was reviewed.
We covered this in detail in Merchant of Record for Platforms and the Ownership Decisions That Matter.
Conclusion#
The right finish is usually conservative: pick one approach, prove it works on your own data, and resist the urge to scale based on reminder volume or vendor lift claims. Failed payments are a common source of preventable revenue loss, but the fix is not simply "send more emails." It is clear policy, reliable retries, a usable payment update path, and records that finance can reconcile.
- Choose one operating model
Start with a single setup and score it against the criteria that actually change outcomes for your team: recovery impact, engineering lift, reconciliation quality, and operational overhead. Focus matters. One setup is easier to verify than a mixed approach where multiple billing tools and custom logic all change state in different places. If you cannot explain the failed charge event, retry decision, customer notice, payment-method update, and subscription-state decision in one sequence, you are not ready to automate cancellation.
- Verify truth before you optimize copy
Your first checkpoint should be one failed invoice traced end to end: failure event, retry attempts, customer communication, and final payment or cancellation state. What matters here is reconciled financial truth, not headline recovery claims. Vendors may promote outcomes like "up to 39%" churn reduction, but that is marketing, not your baseline. If your process can still produce conflicting statuses or duplicate reminders, keep retries conservative and hold cancellation-triggered downstream actions until reconciliation is clean.
- Expand only after evidence is stable
Once one cohort behaves predictably, then widen rules by failure type or customer segment. The point is controlled expansion. Smart retries, payment-detail updates, and personalized communication can all help, but only after your team can separate "recoverable now" from "needs manual intervention" without flooding ops. A good evidence pack is simple and repeatable: one account, one failed invoice, one recovery or write-off outcome, and an audit note showing who changed state and why.
That is the practical bar. Keep claims conservative, keep controls explicit, and treat dunning management as part of subscription billing integrity, not just customer messaging. If you want a next document to build from, use a short go or no-go sheet shared by product, engineering, and finance. Then review it after daily reconciliation and again at monthly close. That pace is less glamorous than chasing aggressive recovery promises, but it is what keeps churn decisions, unpaid invoices, and financial records aligned.
Frequently Asked Questions
What is dunning for subscription platforms in plain terms?
It is the set of actions you take after a renewal or invoice payment fails so you can recover payment before deciding the next account state. That can include retry logic, customer notices, a payment-method update path, and a clear subscription-state decision. What matters most is not the email copy by itself, but whether provider events, your app state, and the finance record all agree.
Why do failed payments happen so often in recurring billing?
Recurring charges hit the same customer repeatedly, so ordinary card and bank issues can show up more than once. Payment complexity also increases around cases like international cards and currency conversion. Under Stripe Standard card pricing, those can add 1.5% and 1% respectively when applicable, and country-specific pricing can supersede generic fee tables. Treat failure as a normal operating condition, not an exception.
What should be automated first in dunning management?
Automate the order of operations first: failed charge event, retry decision, customer notice, payment update flow, and subscription-state change. Make API and webhook handling idempotent before you tune messaging, because duplicate callbacks can create duplicate reminders or journal entries. A useful first checkpoint is tracing one failed invoice end to end and confirming provider response, internal status, and posting match.
How many retries should a platform run before cancellation?
There is no reliable universal retry count in the material here, so do not copy a number from a vendor deck and treat it as policy. Start conservative, segment by failure type, and delay hard cancellation if your payment-method update UX or reconciliation is still weak. If retries repeat with no state change, stop escalation on that account and require manual review.
How do you reduce involuntary churn without weakening collections discipline?
Recoverable failures should get a fast path to update payment details, while true exceptions should go to ops with a note and evidence. You keep discipline by documenting who changed state, why they changed it, and what was reviewed, rather than letting support make silent one-off fixes. If provider status and finance records diverge, freeze cancellation-triggered downstream actions until reconciliation is complete.
Should we use Stripe Billing or Maxio defaults, or build our own dunning logic?
Use native defaults first if your setup is simple, your failure patterns are standard, and finance can verify outcomes without custom stitching. Build your own when you need segmented rules, stricter journal mapping, or dependencies that cross billing, payouts, and compliance. On the Stripe side, also price the broader operating model: Stripe Standard has no setup, monthly, or hidden fees; in Connect, handling pricing can add $2 per monthly active account and 0.25% + 25¢ per payout, while Stripe-handled pricing avoids additional account, payout volume, tax reporting, and per-payout fees; and Managed Payments adds 3.5% per successful transaction on top of standard Stripe processing fees.
What proof should finance ask for before trusting dunning performance claims?
Ask for the cohort, time window, definition of "recovered," and what happened after recovery, including later cancellations, reversals, and write-offs. Then ask for one concrete evidence pack: provider event, webhook record, subscription-state change, and final journal entry for the same failed invoice. If a team cannot show that chain, you have a marketing claim, not decision-grade proof.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
- fincen.gov/report-foreign-bank-and-financial-accountstrusted
- irs.gov/individuals/international-taxpayers/figuring...trusted
- irs.gov/individuals/international-taxpayers/foreign-...trusted
- justice.gov/atr/p2208-oracle-question-answer-document-or...trusted
- shelterislandtown.gov/Archive.aspxtrusted
- stripe.com/pricingtrusted
- stripe.com/connect/pricingtrusted
- support.stripe.com/questions/managed-payments-pricingtrusted
Educational content only. Not legal, tax, or financial advice.
Related Posts

Subscription Billing Platforms for Plans, Add-Ons, Coupons, and Dunning
**Treat subscription billing as an operating discipline, not just a pricing setup.** A subscription is the billing object used to charge a customer for a selected plan. Every choice around Plans, Add-ons, and Coupons has downstream effects once renewal time arrives.

A Guide to Dunning Management for Failed Payments
If you run recurring invoices, failed payments are not back-office noise. They create cashflow gaps, force extra follow-up work, and increase **Involuntary Churn** when good clients lose access after payment friction.

How Platforms Detect Free-Trial Abuse and Card Testing in Subscription Fraud
If your platform sells subscriptions while also handling contractor, seller, or creator payouts across markets, this is not just a signup filter issue. It is a control design issue that cuts across risk, finance, legal, compliance, and product. The damage often shows up later in the customer lifecycle, not only at account creation.