
Quick Answer
Dunning management in SaaS is a structured recovery process for failed payments that combines reminders, safe retries, payment-method updates, and clear escalation rules before service interruption. For freelancers and small teams, the practical win is using one risk-first playbook across clients so recovery improves, involuntary churn drops, and every decision is documented for audits and disputes.
Stop Revenue Leakage With a Risk-First Get-Paid System#
If you run recurring invoices, failed payments are not back-office noise. They create cashflow gaps, force extra follow-up work, and increase Involuntary Churn when good clients lose access after payment friction.
As the CEO of a business-of-one, you do not get to hand billing off to finance, so your get-paid system has to work like one.
Dunning works best when you treat it as a system, not a reminder email. In plain terms, dunning management is a structured communication process for overdue receivables. In subscription billing, that process starts right after a recurring payment fails, often because of card-related payment friction. It should move through clear recovery steps before you interrupt service.
This guide gives you a reusable playbook you can run client by client with your existing recurring invoice and payment-link workflow. It covers decision rules, message structure, retry timing logic, and escalation boundaries you can use in real accounts. Inconsistent follow-up can quietly erode margin over time.
The standard is straightforward: fix payment-process issues, send reminders in a deliberate sequence, offer a clean way to update payment details, and log each action so you can explain every decision later. You protect revenue and relationships at the same time by keeping messages firm, specific, and respectful as nonpayment continues.
Scope matters. The tactics here target service businesses that bill on a recurring cadence through invoices and payment links. Where market rules or provider programs differ, we will call that out so you can adapt without guessing.
If you want a stronger baseline for retention tracking, review How to Calculate and Manage Churn for a Subscription Business before you implement this workflow.
This guide sets one standard: recover failed payments with a repeatable system that supports recovery, reduces churn, and leaves a clear documented trail.
If you want a deeper dive, read The Silent Profit Killer: How to Stop Margin Erosion in Your Freelance Business.
What Is Dunning Management in SaaS and How Is It Different From Collections?#
Dunning is retention-first payment recovery that runs from failure detection through retries and payment-method updates before you suspend access.
It starts when a recurring payment fails and sits between billing and collections. You move through reminders, retries, and payment-method updates before service suspension or further escalation. The goal is to recover revenue without burning trust. Treat most failures as payment friction first, not bad intent. That posture protects revenue and reduces avoidable Involuntary Churn.
Collections solves a different problem. It focuses on debt recovery after internal recovery paths fail, and in some AR contexts it can escalate into firmer actions such as phone follow-ups, demand notices, and other formal steps. Keep the two motions connected but distinct. Recover the account first, then escalate when recovery paths fail.
| Motion | Primary objective | Typical actions | Client experience |
|---|---|---|---|
| SaaS dunning | Recover payment and retain the relationship | Retry logic, reminders, payment update link, staged escalation | Clear, supportive, action-oriented |
| Collections | Recover delinquent debt after recovery fails | Stronger follow-up, formal recovery actions, and, in some contexts, legal escalation | Firm, enforcement-oriented |
Two terms help prevent expensive mistakes:
- Idempotency means your retries behave safely and do not create duplicate effects when you send the same payment request again under provider rules.
- Ledger means your source of truth for payment state and history, so you can track attempts, outcomes, and final status without guesswork.
Use a consistent flow: trigger, notify, retry, update method, escalate, then resolve or suspend. Log each state change with event objects so you can explain exactly what happened and why. A common mistake is jumping to aggressive outreach before retry and update paths run. That shortcut can damage trust.
Want a quick next step? Try the free invoice generator.
Why Do Good Clients Still Fail to Pay on Time?#
Good clients miss due dates because payment friction breaks the flow.
The goal is not more reminders. It is diagnosing the failure so you choose the right branch before you escalate.
Missed payments often come from ordinary breakdowns: insufficient funds, billing-data mistakes, network interruptions, or incorrect card details after a Credit Card Decline. None of those signals bad faith by default. Involuntary Churn starts when you treat friction like intent, lock accounts too early, or send the wrong message at the wrong moment.
Use a simple triage view before you contact the client:
| Failure signal | What it usually means | First action |
|---|---|---|
| Decline with insufficient funds | Account timing issue, not refusal | Retry on your planned schedule, then send a clear reminder |
| Decline after data mismatch | Card details or billing info error | Send one update link and ask for corrected details |
| Processor or network interruption | Technical break in the payment path | Reattempt once the connection stabilizes, then confirm status |
| Bank transfer via Virtual Accounts not matched | Transfer arrived but reconciliation failed | Route to manual reconciliation before escalation |
Cards and bank transfers are different operational tracks. Bank transfers through virtual account numbers run asynchronously, so confirmation and reconciliation can take longer.
Unmatched transfers can sit in customer balance until you reconcile them manually. Do not treat them as the same queue.
Retry timing is another quiet failure mode. In practice, retrying every payment at 2:30 a.m. often just repeats the same failure instead of fixing it. Build your sequence around when clients can actually respond.
Decision rule:
- If the failure points to data, request an update first.
- If the failure points to timing or network, retry first.
- If the failure involves virtual-account reconciliation, resolve matching before you escalate.
Which Recovery Path Should You Use for Each Failed Payment?#
Use automated recovery for soft failures, and switch to payment-method updates or manual review when declines harden or risk increases.
Routing is where most teams leak margin. You want a default path that handles the common cases automatically, plus a clear pause button when risk increases or the account needs review.
Start with the failure type, then layer in client value and risk signals. Soft failures usually belong in automated recovery, where smart timing and clear reminders can recover revenue without extra friction. Hard declines need a different path. Do not keep retrying a hard decline until the client adds a new payment method. For any retry call, use idempotent request behavior so your team avoids duplicate operations.
| Failure pattern | Client and risk signal | Recommended path | Required controls |
|---|---|---|---|
| Soft decline or temporary processing failure | Established client, no risk flags | Automated retry sequence plus reminder | Standard event logging and retry safeguards |
| Hard decline | Any client segment | Prompt payment-method update, then retry | Block further retries until method update |
| Repeated failures plus unusual behavior | Elevated risk profile | Manual review before additional attempts | Ongoing AML monitoring and risk-based identity checks |
| Legal-entity account with unresolved ownership data | High-value or higher-risk account | Hold retry, complete business verification, then resume | KYB beneficial-owner verification |
Define escalation boundaries in policy language, not gut feel:
- Move from automated reminders to support outreach when failures persist after the allowed retry path, or when risk signals increase.
- Pause service when your policy-defined recovery and outreach steps are exhausted, or when AML review requires you to stop processing.
Keep every decision tied to evidence. Your Ledger should capture payment state, retry attempts, outreach actions, and final outcomes. Your event history should also log system signals like invoice.payment_failed and webhook-driven updates, so you can explain what happened in a dispute, audit review, or client call.
The common mistake is letting urgency override controls. If a large client asks for an immediate rerun while ownership checks remain incomplete, complete the KYC or KYB gate first. Then proceed. That discipline protects cashflow and prevents avoidable operational risk.
If you are comparing implementation options, see The Best Tools for Managing Subscription Billing.
How Do You Build a 15-Minute Dunning Playbook You Can Reuse?#
Build a reusable dunning playbook with assigned owners and logged state changes from failure detection through resolution or service pause.
| Step | What the playbook does |
|---|---|
| Detect failure | Trigger the playbook when the billing system records a failed invoice or subscription payment event |
| Send first reminder | Deliver a firm, plain-language email after each failed payment with one clear action link |
| Retry safely | Use idempotency keys on retry requests and automated retry logic that fits the billing pattern |
| Prompt payment update | Route the client to an in-app recovery form or update page if retries fail |
| Escalate to support | Hand off to a human owner when automated steps exhaust or account risk increases |
| Apply account action | Resolve and close, or pause service according to policy and recorded history |
A good runbook does two things: it removes improvisation, and it makes "what happens next" obvious for both you and the client. You can build a reusable workflow quickly if you keep it linear, assign owners, and log every state change.
Use one default flow for recurring invoices, then tune timing by segment after you collect results.
- Detect failure: Trigger the playbook when your billing system records a failed invoice or subscription payment event.
- Send first reminder: Deliver a firm, plain-language email after each failed payment with one clear action link.
- Retry safely: Use idempotency keys on retry requests so repeat calls return the same outcome instead of creating duplicate effects. Use automated retry logic (smart or custom) that fits your billing pattern.
- Prompt payment update: If retries fail, route the client to an in-app recovery form or update page to replace payment details.
- Escalate to support: Hand off to a human owner when automated steps exhaust or account risk increases.
- Apply account action: Resolve and close, or pause service according to your policy and recorded history.
A channel sequence works when each touchpoint has an owner and you capture events consistently. Capture key state changes through Webhook event payloads so the record stays machine-readable.
| Channel | Owner | Purpose | What you log |
|---|---|---|---|
| Billing ops | Immediate recovery prompt after failure | Send time, template used, client action | |
| In-app follow-up | Product or billing owner | Fast method update inside active workflow | Page visit, update attempt, completion status |
| Support touchpoint | Account or support lead | Contextual outreach for unresolved cases | Conversation summary, next step, deadline |
Write templates that protect the relationship while staying direct and specific. Ask for one action, name the exact blocked outcome, and avoid legal overreach language in routine reminders. The common mistake is over-optimizing wording before you assign ownership. Start with clear ownership before copy polish.
Before you send anything, confirm invoice state, retry eligibility, client status, and communication history. If any item fails validation, fix the record first.
If you need tooling options to support this workflow, review The Best Tools for Managing Subscription Billing.
What Controls Make Your Dunning Process Audit-Ready and Compliance-Safe?#
An audit-ready dunning process uses risk-based gates (KYC/AML and tax checks where applicable) plus a ledger and event trail that show who did what and when.
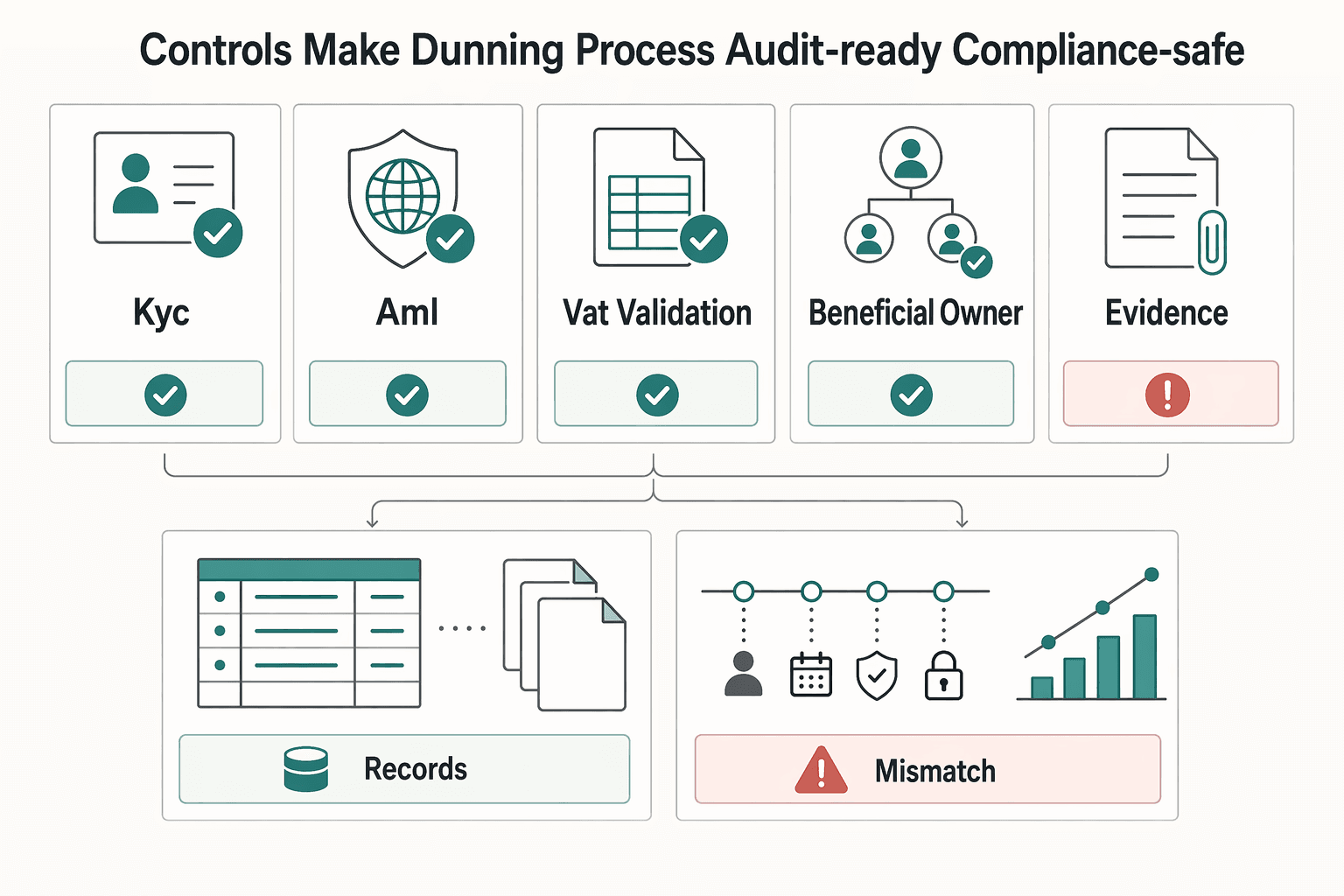
| Check | What to confirm | When it applies |
|---|---|---|
| KYC | Status and current risk tier | Before high-impact recovery actions |
| AML | Monitoring flags and required review status | Before high-impact recovery actions |
| VAT validation | VAT validation status | When VAT handling applies |
| Beneficial-owner verification | Legal-entity beneficial-owner verification | When required |
Controls are what let you run recovery aggressively without drifting into chaos. If your team cannot prove what happened, who decided it, and which gates were checked, you do not have a system. You have a scramble that works until it does not.
Start with identity, risk, and tax checks that match your program and market. Use KYC as a risk-based identity verification process, and keep it inside your AML compliance program instead of treating it like a one-time onboarding task. For legal-entity clients, add beneficial-owner verification when your rules require it. If a client provides an EU VAT number, validate it through VIES before you rely on that tax profile in billing decisions.
Use this gate check before high-impact recovery actions:
- Confirm KYC status and current risk tier.
- Confirm AML monitoring flags and required review status.
- Confirm VAT validation status when VAT handling applies.
- Confirm legal-entity beneficial-owner verification when required.
Then tighten your evidence trail. Your Ledger should capture actions, actor IDs, and timestamps at minimum. Pair that with API request identifiers and event history so you can reconstruct the sequence during disputes or audits.
The common mistake is splitting evidence across inboxes and spreadsheets. When a chargeback arrives, that fragmentation slows response and weakens your case.
| Structure choice | What it centralizes or changes | Control implication |
|---|---|---|
| Merchant of Record (MoR) | Legal selling entity and payment liabilities such as tax, PCI scope, refunds, and chargebacks | Shift controls to MoR workflows and reporting boundaries |
| Virtual Accounts | Inbound payment routing and transaction-level reconciliation | Strengthen reconciliation controls and exception handling |
| Payout Batches | Grouped settlement and payout operations | Reconcile recovery outcomes at batch and transaction levels |
Keep tax-adjacent records scoped to payout context, not every failed payment. W-9 supports TIN reporting flows, W-8 BEN supports withholding-agent requests, and 1099 obligations can depend on category thresholds. FEIE and FBAR questions can appear for cross-border operators, but confirm applicability by jurisdiction and program.
Practical rule: no retry-to-payout handoff moves forward until gate status and trace logs both pass.
Which Metrics Prove the System Is Working Without Guesswork?#
Track dunning recovery rate, recovered revenue, subscriptions saved, failed-payment events, and retry-attempt updates to see where recovery stalls and involuntary churn risk rises.
Metrics only matter if they change behavior. The point of tracking is to see where recovery stalls and where churn risk starts rising early enough to fix it.
Build a scorecard you can review regularly#
Start with leading indicators from your webhook telemetry, not end-of-month anecdotes. Track dunning recovery rate: the share of invoices recovered after entering dunning, along with recovered revenue and subscriptions saved. Add failed-payment events and retry-attempt updates so you can see both cash impact and retention impact in one view.
| Metric | What to capture from telemetry | What it tells you |
|---|---|---|
| Recovery rate | Invoices that enter dunning and are later recovered | Overall recovery effectiveness |
| Recovered revenue | Revenue tied to invoices recovered after dunning | Cash impact of recovery efforts |
| Subscriptions saved | Subscriptions retained after overdue invoices are recovered | Retention impact |
| Failed-payment events | invoice.payment_failed events | Where payment failures cluster |
| Retry-attempt updates | Retry-attempt updates in payment failure workflows | Whether retry strategy is progressing or stalling |
Turn trends into controlled changes#
Involuntary churn is customer loss caused by payment or banking friction, not customer intent, so track it by client segment and billing profile. Teams often over-tune retry counts before they fix reminder timing and message clarity. That is backwards.
Review where in the dunning cycle recoveries happen and how email timing affects recovery. Then change one lever at a time: retry windows, message templates, or escalation triggers.
Some setups allow up to three custom retries. Others use Smart Retry defaults such as 8 tries within 2 weeks. Choose a schedule that fits your client behavior and risk posture.
Log each change with date, owner, hypothesis, and expected effect. If recovery or churn moves, you can compare outcomes to specific decisions instead of guessing. For deeper churn tracking, use this companion framework: How to Calculate and Manage Churn for a Subscription Business.
Build the System Once and Run It on Every Client#
Use one risk-first dunning playbook across clients, then optimize from evidence instead of treating each failure as a one-off. Standardizing retries, reminders, and outcome logging gives you a repeatable recovery path and clearer cashflow control, while keeping the customer experience more consistent.
Start with safe defaults you can defend#
Automate the routine path first: failed-payment retries, post-failure emails, and one direct payment-update action in every message. Keep retry timing configurable, because there is no universal schedule that fits every portfolio.
Keep traceability tight from day one. Capture real-time webhook events and record immutable transaction outcomes in your ledger-style history so each status change is explainable in reviews and audits. Prioritize clean event capture before message fine-tuning.
Run the first rollout this week#
Apply one operating checklist to each client segment:
| Checklist item | Detail |
|---|---|
| Enable retries and reminders | Enable automated retries and post-failure reminders with one clear payment-update action |
| Record events and ledger rows | Record Webhook events and immutable transaction rows in your Ledger |
| Start KPI reviews | Start KPI reviews after the next billing cycle, then continue on a weekly or monthly cadence |
| Track outcomes and adjust carefully | Track recovery rate and unresolved failures, and adjust one variable at a time |
| Recheck launch constraints | Recheck market coverage and plan entitlements before launch, since availability can vary by country and plan |
If you run subscription billing across markets, confirm commercial and program fit before scaling. Validate coverage and feature access with provider sales or support so you enable the right controls in the right regions. For implementation options, see The Best Tools for Managing Subscription Billing.
Frequently Asked Questions
What is dunning management in SaaS?
Dunning management is the process of communicating with customers to collect overdue payments. In SaaS, it often starts when an automatic payment attempt fails and continues through reminders, retries, and payment method updates. The job is to recover revenue without pushing good customers into avoidable churn.
How does a dunning workflow run step by step?
A practical flow is: detect failed payment, send a reminder, retry the charge, request a payment method update, escalate if needed, then resolve the account based on policy. The trigger is the failed attempt for automatic charges, or when a manual invoice surpasses its net terms.
What should a failed-payment retry and reminder sequence include?
Include three parts: a clear failure notice, scheduled retries, and a frictionless payment update path. Keep each message specific, with one action and one owner, so the customer knows exactly what to do next. Automate the routine path so support time stays reserved for exceptions.
How can freelancers and small teams reduce failed-payment churn?
Automate the routine recovery path first, then review unresolved declines and involuntary churn by client segment on a regular cadence. Fix reminder timing and message clarity before you add more retry attempts, because communication gaps can block recovery even when retries are enabled. If you want a practical way to monitor churn by segment, use How to Calculate and Manage Churn for a Subscription Business.
What is the difference between automated dunning and manual collections?
Automated recovery runs system-driven emails, retries, and payment update prompts after failed payments. Manual collections rely on human follow-up and are common when you do not store a payment method for automatic charging, and for exceptions when automated recovery does not resolve the payment. Use automation for repeatable cases, then reserve manual handling for exceptions and higher-risk accounts.
What controls are needed for compliant, audit-ready payment recovery?
Set clear gates for retries, escalations, and account actions, then enforce them every time. Keep an event trail for failure notices, retry attempts, payment updates, and final outcomes so your team can explain each decision. For tax handling, follow a clean sequence: identify where you must collect tax, register in those locations, then calculate and collect correctly.
How do cross-border rules change dunning workflows and who should I confirm with?
Cross-border workflows need location-aware tax handling because rates and rules vary by region. You may need to account for sales tax, VAT, or GST depending on where you and your customer operate. Confirm registration and filing obligations with your tax advisor and relevant local tax authorities before you standardize the workflow.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
Educational content only. Not legal, tax, or financial advice.
Related Posts

Stop Freelance Profit Margin Erosion Before It Hits Cashflow
Revenue can hold steady while the business underneath it gets weaker. What comes in matters, but what you keep after the work is delivered is the clearer signal of health.

How to Calculate and Manage Churn for a Subscription Business
If you treat churn as a report you glance at after month end, you find the problem after cash flow has already tightened. Turn churn from an after-the-fact metric into a repeatable control loop so you can protect renewals, keep forecast confidence, and reduce the pressure to buy replacement revenue.

The Best Tools for Managing Subscription Billing
**Protect cashflow by selecting for recovery and control first, then layering convenience features.**