
Quick Answer
Track contractor productivity analytics metrics that change decisions at weekly review: execution throughput, cycle time, exception rate, rework rate, settlement timeliness, and reconciliation completion. Tie each one to a checkpoint from approval through close, assign a single owner, and require supporting artifacts such as webhook history and ledger journals. If a metric cannot trigger a concrete action or hold up during reconciliation, remove it from the core set.
Metrics that support real operational decisions#
Payment operations metrics matter only if they help you move from approved payment intent to clean reconciliation faster and with less friction. If a number looks good on a dashboard but does not reduce delays, exception handling, or close-time drag, it is noise.
That framing helps if you work in finance, operations, or product and own some part of Payouts, batch operations, or reporting across multiple markets. In payment operations, the job is not just sending money. It is matching records across gateways, banks, internal payment states, and accounting ledgers so each transfer can be explained later with confidence. That is what payment reconciliation is for: matching records across systems to ensure financial accuracy.
Any metric set that matters has to survive asynchronous reality. Providers and payment platforms often send status changes through webhook events, not in a neat sequence. Stripe describes webhooks as real-time event data pushed to your application, and products such as Worldpay account payouts expose asynchronous webhooks for status updates. A batch can look "sent" in one view while a later provider event changes the real outcome. If your reporting ignores API events and webhook timing, you can overstate throughput and miss the exceptions finance still has to clear.
The checkpoint that matters most is traceability. You should be able to start with a balance or batch result, drill into the relevant ledger journals, and keep going to the underlying subledger transactions and status evidence. Oracle's account reconciliation guidance is useful here because it treats reconciliation as a drill path from account balances to journals and underlying transactions, not a screenshot exercise.
A good first verification step is simple. On a regular cadence, pick one batch and confirm that the executed amount, provider status events, and journal entries tell the same story. If they do not, your metric layer is ahead of your control layer.
This article is for operators who need numbers that trigger action, not commentary. The focus is practical scorecard inputs and decision checkpoints tied to concrete artifacts such as ledger journals, API events, and reconciliation packs. The goal is not to collect every possible KPI. It is to help you see where payment operations slow down, where evidence goes missing, and where a fast transfer can still become a month-end problem because reconciliation quality was weak.
Keep one red flag in view from the start: faster execution is not automatically better.
Reconciliation quality affects how quickly you can close the period and how reliable later decisions will be. So the useful question throughout is not, "What can we measure?" It is, "What can we measure that changes the next payment decision and still holds up at close?"
Define contractor productivity for money movement operations#
For money movement operations, productivity is not output per worker. It is your team's ability to move valid contractor payments from approved intent to reconciled close with minimal rework and clear control evidence. That is the standard your contractor productivity analytics metrics should support.
This is where labor KPIs and payment operations KPIs separate. Labor productivity is output per hour, which helps with work-performed tracking. A Rhumbix-style Production Tracking view can show execution activity, but it does not show whether a Gruv payout batch reconciled cleanly, whether payout-state changes were captured through webhooks, or whether finance can trace outcomes through ledger journals.
A practical way to organize your scorecard is into four buckets:
- Throughput: how many valid payments moved.
- Timeliness: how long movement took from approval to execution, then to reconciliation.
- Quality: how much rework, exception handling, or mismatch cleanup was needed.
- Control evidence: whether webhook history and ledger journals provide a clear drill path into underlying transactions.
Use one completed batch as a standing test. Confirm the approved amount, webhook status history, and journal entries align without manual narrative. If a metric does not help finance, ops, or product decide the next action, keep it out of the core scorecard.
For a step-by-step walkthrough, see Which Contractor Payment Experience NPS Metrics Actually Predict Retention.
Map checkpoints to owners before choosing tools#
Set checkpoint owners and evidence before you pick tools, or your dashboard can look clean while operations are still unresolved. Define the handoffs first, then decide which Gruv module or reporting surface should show each checkpoint.
A practical baseline sequence is: intake complete, compliance cleared, payout executed, provider status resolved, and reconciliation closed. It may vary by rail or market, but this order keeps readiness, execution, outcome, and close separate so your metrics do not blur compliance delay with execution delay.
Use owner splits to protect control quality#
Owner assignment is a control decision, not just an org chart decision. Keep separation of duties so one person is not handling consecutive accounting tasks when close evidence is expected later.
| Checkpoint | Likely primary owner | Verification artifact | What to confirm |
|---|---|---|---|
| Intake complete | Ops | intake record or approval log | Payment intent is approved and required fields are present |
| Compliance cleared | Ops or compliance partner | onboarding or compliance status record | KYC obligations are satisfied before execution where applicable |
| Payout executed | Ops | execution log or batch record | Payment was submitted with the expected amount and recipient |
| Provider status resolved | Product for event reliability, ops for exception handling | status logs and webhook event history | Final state is explicit: processing, posted, failed, returned, or canceled |
| Reconciliation closed | Finance | reconciliation export plus ledger journals reference | Batch maps to included transactions and closes cleanly in the books |
This split is a strong default, not a universal rule: finance owns close accuracy, ops owns exception clearance, and product owns API and webhook reliability.
Match evidence to the Gruv module in use#
Map checkpoint evidence to the module you are actually running. Virtual Accounts, Payouts, and Merchant of Record do not produce the same bottlenecks or evidence trails.
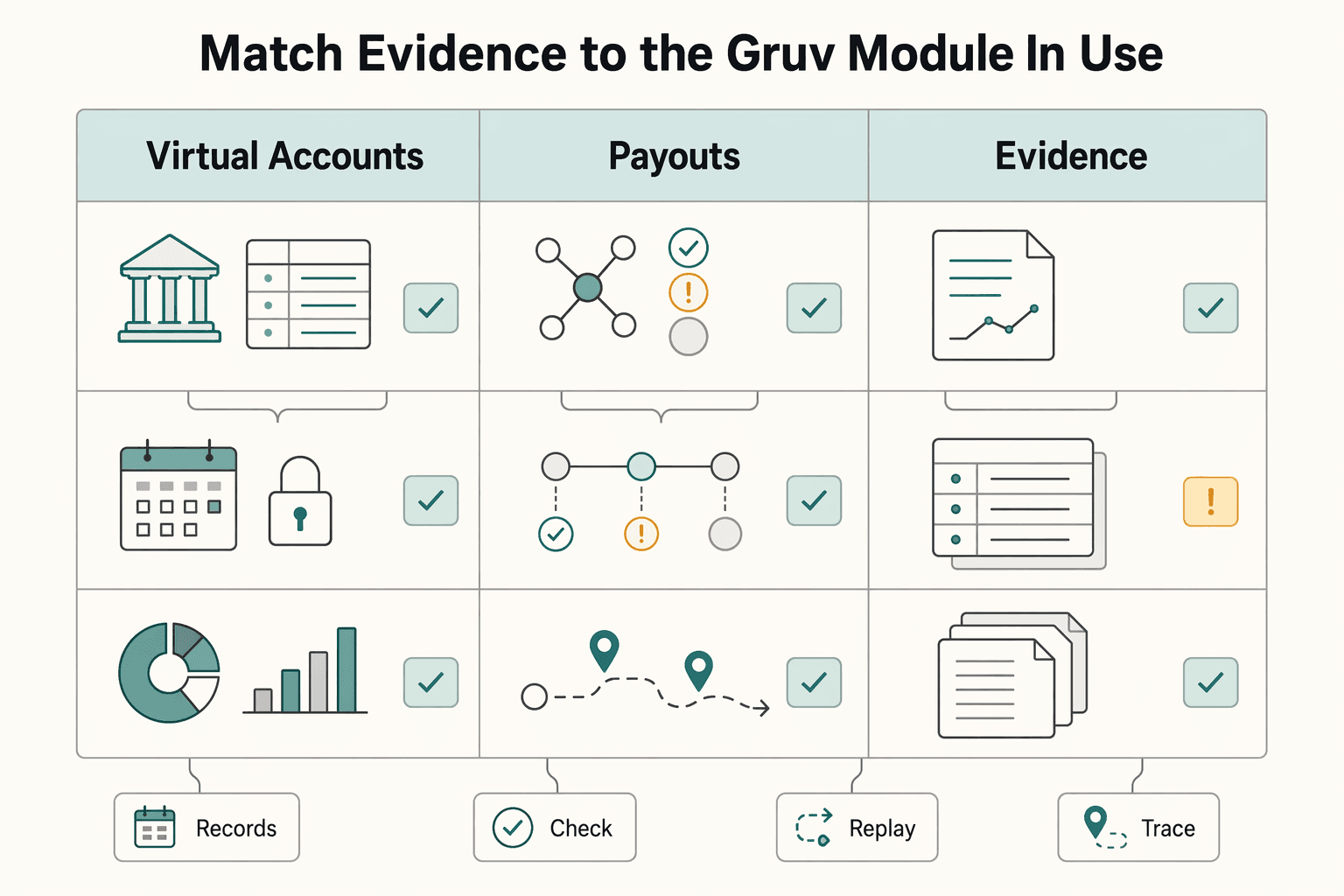
| Module | Evidence focus |
|---|---|
| Virtual Accounts | stronger cash-flow tracking and reconciliation control; proof may center on reconciliation artifacts |
| Payouts | execution records, provider statuses, and event history |
| Merchant of Record | reporting and reconciliation responsibilities; execution proof alone is not enough |
Virtual Accounts usually lean toward cash-flow tracking and reconciliation control. Payouts lean toward execution records, provider statuses, and event history. Merchant of Record adds reporting and reconciliation responsibilities, so execution proof alone is not enough.
Product reliability is part of checkpoint quality. If webhook events drive status metrics, return a successful 2xx quickly before heavy processing. Undelivered webhook events can be retried for up to three days, so define a timed escalation path before ops starts manually clearing outcomes that are actually ingestion failures.
A simple verification test is to sample one completed payment end to end: approval record, compliance-ready proof (if relevant), execution log, provider status history, reconciliation export, and ledger journals. If any checkpoint depends on email, memory, or manual narrative, that is your next tool requirement.
This pairs well with our guide on Payout Error Rates in Contractor Payroll Teams Can Actually Reduce.
Build a weekly scorecard that tells you what to do next#
Once owners and checkpoint evidence are set, keep the weekly scorecard small and action-linked. If a metric does not trigger a clear next step for finance, ops, or product, it is not core yet.
A KPI should be tied to an objective and defined target, not tracked as a raw count. For Gruv teams, each metric should clarify whether approved payments move through Payouts cleanly, settlement reporting arrives on time, and reconciliation closes with audit-ready linkage.
| Metric name | Definition | Source event | Warning signal | Owner | Next action | Audit artifact |
|---|---|---|---|---|---|---|
| Execution throughput | Count of payments executed in the weekly period | Executed event or batch record | Volume drops while approved intake is stable | Ops | Check for stalled batches, compliance holds, or provider submission failures | Execution log or batch record |
| Cycle time | Time from approved payment intent to executed or posted | Approval timestamp plus status timestamps | Cycle time rises without a matching intake spike | Ops | Split delay into pre-execution, execution, and status-resolution stages | Approval record plus status history |
| Exception rate | Share of payments ending in failed, returned, or canceled versus total processed | Outbound payment status distribution | Failed, returned, or canceled outcomes rise | Ops | Triage by failure type and corridor before changing staffing or policy | Provider status log |
| Rework rate | Share of payments that required resubmission, correction, or manual repair after first pass | Reopened case, resubmission, or correction event | More fixes are needed after initial execution | Ops | Review stale approvals, duplicate retries, and bad recipient data | Case notes plus corrected execution record |
| Settlement timeliness | Whether settlement reporting arrives and matches the expected reporting window | Settlement report availability and batch inclusion | Reports arrive late or records are missing from the expected window | Finance | Hold close assumptions, confirm provider report timing, and isolate missing items | Settlement report and inclusion record |
| Reconciliation completion | Share of batches fully matched to underlying transactions and closed | Settlement-batch reconciliation status | Open or partial matches persist into the next weekly review | Finance | Work unmatched items and confirm transaction linkage before close | Reconciliation report data that matches payments to transactions |
Use this minimum set first. It covers flow, quality, timeliness, and control evidence without adding noise.
Sample one completed batch each week and walk the evidence end to end. For Payouts, confirm the approval record, execution log, status history, and payment-to-transaction matching artifact agree. If you use Virtual Accounts or Merchant of Record, apply the same standard: the review ends at reconciliation and ledger support, not at submission success.
Add scale metrics only after the basics are stable#
Add complexity only after the minimum scorecard is reliable and exception ownership is clear.
| Scorecard layer | What belongs here | When to use it | Main value | Common mistake |
|---|---|---|---|---|
| Minimum viable scorecard | Throughput, cycle time, exception rate, rework rate, settlement timeliness, reconciliation completion | Starting point for any payment program | Shows where flow breaks and whether close evidence exists | Adding sub-metrics before owners trust the basics |
| Scaled scorecard | Unmatched item aging, manual touchpoints per batch, webhook retry success, close latency by corridor | After status mapping and reconciliation discipline are stable | Isolates volume bottlenecks and corridor-level differences | Treating technical event noise as pure ops underperformance |
Webhook retry success belongs in the scaled view because webhook handling supports large volumes of business-critical events, and undelivered events can be retried for up to three days. Review retry outcomes jointly across product and ops before ops starts manually clearing "missing" outcomes that are really delayed event ingestion.
If you need one boundary for weekly review quality, use this: do not stop at processing or posted; close the week only after settlement-batch reconciliation and transaction matching are complete.
Set decision rules that prevent dashboard theater#
Use your weekly scorecard to make decisions, not just describe movement. The point is choosing the next action, especially when execution looks healthy but reconciliation support is weakening.
Start with a core triage set: exception rate, cycle time, and accuracy. If exception rate rises while throughput stays stable, triage root cause first by failure reason and checkpoint before treating it as a staffing problem.
| Metric pattern | First decision | What to verify | Common wrong move |
|---|---|---|---|
| Exception rate up, throughput stable | Triage root cause before adding headcount | Sample failed or manually repaired payments and group by reason code, corridor, and owner | Treating every spike as a capacity problem |
| Cycle time up, exception rate flat | Split delay into approval, execution, and status-resolution stages | Check timestamps across approval records, execution logs, and provider status history | Blaming ops for a product or provider latency issue |
| Throughput up, reconciliation completion down | Prioritize data integrity before more speed work | Compare payment records to ledger journals and transaction-matching artifacts | Celebrating volume while close evidence degrades |
| Settlement says complete, close says incomplete | Escalate through a defined path, with finance as the default final owner for this conflict | Reconcile settlement report contents against ledger journals and unmatched-item queue | Marking the week clean because provider reporting arrived |
The operating contrast is straightforward: faster is not better if the week cannot close cleanly. Reconciliation practices are expected to avoid or resolve discrepancies so customers are not harmed, and unresolved gaps within required timelines can become compliance concerns. In practice, that makes a slower week with complete matching and clean evidence safer than a fast week with weak close support.
For Gruv teams, define the escalation path in advance. If settlement timeliness and reconciliation completion disagree, route the incident so finance makes the final close decision, while ops handles exception clearance and product handles status mapping and event reliability.
Keep the recommendation narrow: pause new optimization aimed at speed, automation, or volume expansion when reconciliation completion degrades, and fix ledger journals and status mapping first. Use one concrete checkpoint from Payouts or Virtual Accounts: trace a batch from approval through execution, ledger posting, and settlement inclusion, and confirm identifiers align.
Related reading: How to Lock In FX Rates for Contractor Payouts Using Forward Contracts.
Instrument data so metrics survive audits#
To keep these metrics defensible, design instrumentation around three controls: safe retries, stable status definitions, and ledger-anchored reporting.
| Control | Requirement | Check |
|---|---|---|
| Safe retries | Use idempotency keys for mutating API writes and persist the first result by key | Confirm each intent ended as one record, one execution outcome, and one journal impact |
| Status definitions | Maintain one status mapping that ties provider events to your internal states and expected ledger effect | Validate allowed predecessors, required event evidence, and expected ledger state |
| Ledger anchor | Anchor reporting to ledger journals and treat wallet or UI balances as derived views until they tie back | Keep a journal extract and the matching finance export |
Make every retry collapse to one financial outcome#
Retries are normal, and many transient faults clear on retry. The control is idempotency: the same business intent should resolve to one financial outcome, not duplicate records or postings.
Use idempotency keys for mutating API writes and persist the first result by key. Keep webhook write paths on the same one-effect rule so replayed events do not create a second payment record or ledger impact. Stripe's 24 hours key-retention example is a practical reference point for defining your retry window.
Check this directly: sample retried flows and confirm each intent ended as one record, one execution outcome, and one journal impact.
Lock status meanings before you scale reporting#
Reporting drifts when status definitions are ambiguous. GAO found definition quality gaps that led to inconsistent reporting, and the same pattern shows up when provider events and internal states are not aligned.
Maintain one status mapping that ties provider events to your internal states and expected ledger effect. If meanings change, log the change date so export differences are explainable later. For every reporting-terminal state, validate allowed predecessors, required event evidence, and expected ledger state before treating it as complete.
Treat ledger journals as the reporting anchor#
For finance, reconciliation, and audit use cases, anchor reporting to ledger journals and treat wallet or UI balances as derived views until they tie back. A ledger-centered record is what supports a traceable audit trail.
Keep weekly controls focused on evidence you can reproduce: a retry/idempotency sample, the active status mapping version, a journal extract, and the matching finance export. That keeps the scorecard reliable when someone asks you to prove how a number was produced.
We covered this in detail in Real-Time Reporting Metrics Platform Finance Teams Can Actually Control.
Account for compliance and tax gates in productivity math#
Do not count compliance and tax holds as execution time. To keep contractor productivity analytics metrics tied to the right owner, track gating delay separately from execution delay.
In practice, capture distinct timestamps for approval received, compliance cleared, payment submitted, and payment resolved. Verification can be a hard prerequisite before processing payments or payouts, so KYC, KYB, AML, or VAT validation holds should stay in a policy-gate bucket, not an ops-throughput bucket.
Treat tax-document readiness the same way. Form W-9 is used to provide a correct TIN, and Form W-8 BEN is submitted when requested by the payer or withholding agent. Missing tax-status information can pause payouts, and incorrect or missing TIN data can trigger backup withholding.
Use a simple checkpoint:
- Gate-cleared timestamp on each payment-ready record.
W-8/W-9document-on-file flag where relevant.- Explicit reason code when readiness is blocked.
A common failure mode is starting the cycle-time clock at commercial approval when the contractor has not supplied the required tax form.
For programs touching FEIE, FBAR, or 1099, define what is in productivity scope before setting targets. FEIE qualification follows IRS rules, including one route based on 330 full days in 12 consecutive months. FBAR applies when aggregate foreign account value exceeds $10,000 during the calendar year. These are not automatically productivity steps unless your team owns collection, reminders, or handoff status.
State market caveats plainly. VAT validation coverage varies by jurisdiction and program, and reference services can change, including the EU VIES update for UK (GB) VAT validation after 01/01/2021.
Catch failure modes before they become month-end incidents#
Catch drift early by monitoring a short set of operational red flags: rising manual touchpoints, stalled payout batches, repeated webhook retries, and a growing unmatched-item queue.
These are practical because they map to distinct failure paths. Repeated webhook retries are not harmless noise; in live mode, retries can continue for up to three days, so one broken endpoint can leave status stale for days. A growing unmatched-transactions queue is a direct reconciliation warning.
Triage in a fixed order#
When a signal fires, run the same checklist every time:
| Step | What to do | Key detail |
|---|---|---|
| Classify failure type | Mark it as intake data, execution, provider-status, reconciliation, or reporting evidence | Run the same checklist every time |
| Isolate the affected module | Confirm whether the break is in Virtual Accounts or Payouts | Identify the affected module before deeper review |
| Confirm ledger impact | Verify whether ledger journals moved incorrectly, did not move, or moved without matching external status | For stalled batches, pull the batch reference and review settlement evidence for affected transactions |
| Assign owner and severity | Set both explicitly at triage | Exceptions do not sit in a shared queue |
| Set a recheck time | Put a clock on the next review | Avoid month-end rediscovery |
Use a simple routing rule: if the ledger is correct but provider status is stale, treat it as status ingestion; if provider status is correct but ledger evidence is missing, treat it as a finance-close risk first.
Document failure categories clearly: stale approvals, duplicate retries without idempotency keys, provider return loops, and incomplete reconciliation evidence. For any retried write path, require idempotent requests so the same retry does not create the same operation twice.
Stop doing#
- Expanding vanity KPI sets before core exceptions are stable
- Leaving unmatched items or batch exceptions without a named owner
- Copying generic
AutodeskorAcumaticaKPI templates that track activity but miss payment context, ledger impact, and reconciliation evidence
This discipline matters more than expanding the metric set. If your incident log cannot show what broke, where it broke, who owns it, and what evidence proves impact, the scorecard is decoration. Related: The Best Analytics Platforms for SaaS Businesses.
Conclusion#
The goal is not a bigger dashboard. It is an owner-linked scorecard that tells finance, ops, and product what changed, who owns the next move, and what evidence proves the decision. If a metric cannot trigger action, it is commentary, not control.
That owner link matters because payment flows break in stages, not all at once. A shared KPI view helps the right teams catch issues early, but only if your checkpoints line up with the actual path from approved payment to reconciled close. In practice, tie each checkpoint to something you can verify: general ledger records for financial truth, provider or webhook status for execution state, and compliance flags for hold reasons. Reconciliation is the discipline of comparing those records to confirm they agree. If your scorecard cannot be traced back to those records, month end will expose the gap.
The control detail that usually matters most is reliability around retries and status handling. Your API layer should support idempotent request handling so a retry does not create duplicate side effects. Your event processing also needs to account for webhook redelivery that can continue for up to three days. A common failure mode is celebrating throughput while duplicate-safe processing, status mapping, or reconciliation evidence is weak. Fast execution with unresolved exceptions is not a win if finance cannot close cleanly.
You also make better decisions when compliance and return risk stay visible instead of getting buried inside one cycle-time number. Separate policy holds from execution delay, and keep return-rate monitoring owned. ACH programs assign explicit monitoring responsibility to ODFIs, with thresholds like 0.5% for unauthorized returns and 3.0% or 15.0% for administrative or overall return levels acting as clear warning lines. If those numbers are moving the wrong way, do not hide the problem inside aggregate productivity reporting.
A practical next move is to pilot the minimum scorecard in a limited scope, review the decisions it drives over a short cycle, and expand only when the evidence holds up. That follows the same small-test logic behind PDSA: test quickly on a limited scope, study what actually improved, then scale. Keep the pilot tight. Track a handful of payment KPIs, require an audit trail for each one, and write down what changed because of the review. If the scorecard reduces exception backlog, tightens reconciliation against general ledger records, and surfaces reliability or compliance bottlenecks earlier, you have earned the right to widen it.
Frequently Asked Questions
What contractor productivity analytics metrics matter most for payout operations first?
Start with speed to money and quality of close. In practice, begin with processing or settlement time and reconciliation accuracy, then add exception rate and rework or manual-touch signals that fit your workflow. Those contractor productivity analytics metrics show whether payments moved, whether records matched, and whether people had to patch around weak data.
How do I measure contractor productivity beyond output per worker?
Measure how cleanly approved payments move from intent to reconciled close, not just how much work someone completed. Good payment KPIs show where payments break down, where revenue is slipping, and where processes need attention. A simple checkpoint is whether each payment can be tied back to ledger journals, provider status, and final reconciliation evidence without manual digging.
Which metrics should finance own versus payments ops versus product?
A practical split is by failure domain, not by org chart. Finance can own reconciliation accuracy and close readiness. Payments ops can own exception clearance, settlement timeliness, and return-rate monitoring. Product can own idempotency, webhook reliability, and status-mapping integrity. If a metric cannot trigger a clear owner action, it probably does not belong in the weekly review.
What are early indicators of payout and reconciliation bottlenecks?
Watch for repeated webhook retries, growing unmatched-item queues, rising manual touches per batch, and increasing return rates. Webhook delivery can keep retrying for up to three days, so stale status feeds can quietly mask real backlog. For ACH-style programs, return-rate thresholds are not abstract: unauthorized returns at 0.5% and administrative or overall levels at 3.0% and 15.0% are clear warning lines to investigate.
How many metrics should a weekly scorecard include before scaling up?
Keep it small enough that each metric has an owner and a next action. For most teams, that means a compact set centered on throughput, timeliness, quality, and reconciliation, then adding scale metrics only after the basics stay stable for a few cycles. If discussion time goes to explaining definitions instead of making decisions, you already have too many.
How do compliance gates like `KYC` and `AML` change cycle-time interpretation?
Separate compliance hold time from execution time, or your ops team will get blamed for policy controls. CIP timing is risk-based and must happen within a reasonable time after the account is opened, which is very different from saying every program should hit one universal KYC clock. Also track tax readiness separately: a missing Form W-9 can affect payment eligibility because it provides the TIN needed for information returns, and backup withholding can apply at 24 percent in some cases.
What evidence should I keep to make productivity reporting audit-ready?
Keep the artifacts that let another team reproduce your conclusion: ledger journals, reconciliation exports, batch references, settlement details, webhook event logs, and the status-mapping document used to translate provider events into internal states. Because webhook endpoints can receive the same event more than once, keep duplicate-safe processing evidence such as event IDs and idempotency keys. The common failure mode is a dashboard showing "completed" while your records cannot prove which records settled and which simply retried.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
- bls.gov/opub/ted/2026/productivity-output-and-hours-...trusted
- docs.stripe.com/webhookstrusted
- docs.stripe.com/webhooks/process-undelivered-eventstrusted
- ec.europa.eu/taxation_customs/viestrusted
- ecfr.gov/current/title-31/subtitle-B/chapter-X/part-1...trusted
- gao.gov/products/gao-16-261trusted
- irs.gov/businesses/small-businesses-self-employed/re...trusted
- irs.gov/individuals/international-taxpayers/foreign-...trusted
Educational content only. Not legal, tax, or financial advice.
Related Posts

How to Calculate and Manage Churn for a Subscription Business
If you treat churn as a report you glance at after month end, you find the problem after cash flow has already tightened. Turn churn from an after-the-fact metric into a repeatable control loop so you can protect renewals, keep forecast confidence, and reduce the pressure to buy replacement revenue.

The Best Analytics Platforms for SaaS Businesses
**Pick a SaaS analytics stack by role fit and decision ownership, not by the longest feature list.** Ad hoc dashboards drift when traffic, product, and subscription reporting split across tools, and decisions slow down.

How to Set Up Google Analytics 4 on Your Freelance Website
**Treat GA4 as operational infrastructure, not a marketing toy.** That's how you trust your website analytics when you make pricing and channel decisions. The win is not "GA4 installed." The win is GA4 that is **owned cleanly**, **configured intentionally**, **verified fast**, and **credible** enough that you stop second-guessing your numbers.