
Quick Answer
Use an immutable transaction log in a payment platform only when you must reconstruct ordered state changes, provide a stronger audit trail, or handle frequent concurrent updates on the same entity. For most systems, CRUD remains the better default. If you adopt event sourcing, start with one bounded flow, prove replay and ordering, and keep the event store as the system of record.
Why Event Sourcing Works for Payment Platforms#
For most systems, and for most parts of a payment platform, event sourcing is not necessary. Use an Immutable Transaction Log only when current-state tables are no longer enough for audit trail, reconstruction, or ordered asynchronous behavior.
At its core, event sourcing stores the full series of actions on an object in an append-only store, then reconstructs current state by replaying events. In the right domain, that can improve auditability and write performance.
The tradeoff is real: this pattern is complex, traditional CRUD is enough for most systems and most parts of a system, and moving to or from event sourcing is expensive.
Before you start#
Before you commit to an append-only design, use these checks:
| Check | Action | Why |
|---|---|---|
| Name the domain that needs reconstruction | Start with one domain where history materially matters | If a current-state model is enough, keep CRUD |
| Define the investigation question events must answer | Be explicit about what you must reconstruct from events for audits and traceability | Historical reconstruction should answer audits and traceability questions |
| Set an ordering rule per aggregate | If T1 -> E1 and T2 -> E2, publish E1 before E2 for that same aggregate | Preserve order for the same aggregate |
| Plan for the write-path constraint | Define how events are persisted and published while preserving order for the same aggregate | Do not depend on 2PC across a database and message broker |
This guide stays practical. The examples stay focused on payment flows, with "where supported" caveats for rollout and compliance constraints. The goal is simple: place an Append-Only Log where it can reduce risk, and avoid hard-to-reverse architecture debt where it does not.
Decide if Event Sourcing is justified for this payment domain#
Default to CRUD. Reach for Event Sourcing only when historical reconstruction and a defensible audit trail clearly outweigh the added complexity and lock-in. Use this as a go/no-go screen, not a hard mapping:
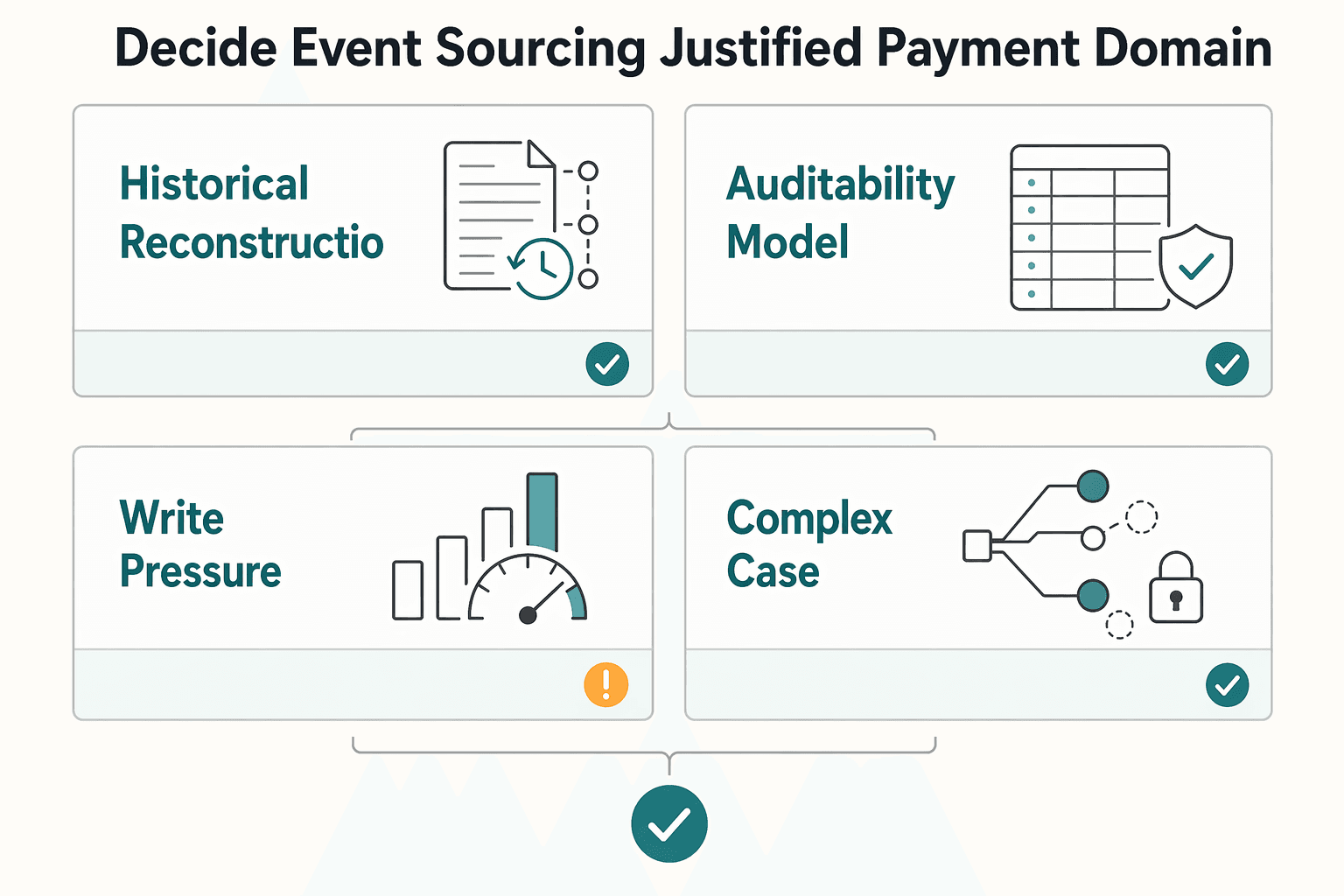
| Decision signal | Favor Event Sourcing when | Keep CRUD when |
|---|---|---|
| Historical reconstruction | You need to reconstruct an ordered sequence of state changes for investigations | The current state answers most operational and finance questions |
| Auditability model | You need immutable events as the system of record | Current state plus audit logs or history tables is enough |
| Write pressure | Frequent concurrent updates to the same entity become a bottleneck under load | Contention is low and in-place updates stay manageable |
| Complexity and lock-in | The auditability and reconstruction gains justify higher complexity and migration cost | Traditional data management is sufficient for this part of the system |
One rule cuts across all signals: if you must explain how it got here, not just what it is now, that area is a stronger candidate.
Favor Event Sourcing only when all three checks pass for that domain:
- You must reconstruct historical state changes, not just read current state.
- You need an audit story stronger than separate logs or side tables.
- You have frequent concurrent updates on the same entity, where in-place CRUD updates become a bottleneck under load.
Use this decision gate with product and engineering: Can we explain how this state changed over time from immutable events? If yes, an append-only store can act as the system of record for that aggregate and support rebuilding state as needed. If no, keep CRUD and improve history and audit coverage first.
Before you commit, run a lock-in checkpoint:
- Complexity: event sourcing introduces significant trade-offs.
- Migration cost: moving to or from event sourcing is costly once adopted.
- Operational ownership: replaying events and rebuilding state is an ongoing responsibility.
Event sourcing can improve auditability and write performance in complex systems, but it remains costly to adopt or unwind. For most systems and most parts of a system, traditional data management is still the right default.
Related: ERP Integration Architecture for Payment Platforms: Webhooks APIs and Event-Driven Sync Patterns.
Define the first scope and prerequisites before writing any events#
If the domain clears the go/no-go gate, keep the first slice deliberately narrow. Define one bounded flow, align on shared language and ownership for that flow, set operating expectations, and explicitly leave adjacent domains for later.
Step 1 Pick one bounded flow you can fully own#
Choose a single flow your team can explain end to end, test under failure, and replay without ambiguity. Phase one is not about rail coverage. It is about a flow where product, ops, and engineering agree on what starts the sequence and what outcome proves it finished correctly.
That keeps the rollout realistic. Event sourcing can be useful when you need to preserve what happened and reconstruct history, but replay and read-model recovery can become a real operating burden. In one practitioner account, replay eventually took DAYS. Phase one should stay small enough to rehearse and recover safely.
Step 2 Write prerequisites before defining event types#
Set shared prerequisites before the first schema hardens. For phase one, align on shared language for the flow, ownership for contract and read-model changes, and what reconciliation outcomes mean in your context.
This is not paperwork for its own sake. It is risk control. One practitioner account described projection sprawl, with multiple copies of data across services and updates touching 5-10 different projects. Settling meaning and ownership early can reduce that blast radius.
Step 3 Set operating expectations before the first projection#
Make operating expectations explicit before implementation. Agree on how replay readiness will be judged, what read-side staleness is acceptable for this flow, and who owns response when write and read sides diverge.
CQRS can improve scalability by separating reads and writes, but it also means those paths must be operated deliberately. Phase one goes better when ownership and recovery decisions are clear before the first incident, not during it.
Step 4 Exclude adjacent domains on purpose#
Keep the phase-one boundary explicit and testable. Write down what this phase proves and what it does not, so success is measured on one bounded flow rather than platform-wide coverage.
That discipline keeps the first event store and read models understandable, and it makes post-incident review more honest about what was actually validated.
Design an event contract your team can live with for years#
Treat the contract like long-lived infrastructure. In event sourcing, your event log is an append-only system of record, and changing direction later can be costly. Keep the contract explicit and reviewable so it supports auditability and historical reconstruction while reducing avoidable migration risk.
Step 1 Define a clear canonical envelope and apply it consistently#
Use one envelope shape for the in-scope aggregate and keep changes intentional. Document the metadata your team agrees each event should carry, rather than leaving interpretation producer by producer.
If a field matters for shared reasoning, define it in the contract and review it centrally.
Step 2 Keep events focused on what happened in the domain#
Record domain actions in the append-only log, then materialize state from that record as needed. That keeps the event store useful as a system of record over time.
A practical review check is whether current state can still be rebuilt from raw event history.
Step 3 Use write contention as an adoption checkpoint#
In traditional CRUD models, read-modify-write cycles with row-level locking can create concurrent write bottlenecks under load. Use that failure mode as a concrete checkpoint when deciding whether event sourcing is warranted for this domain.
Event sourcing can improve write performance in complex systems, but the benefit should be tied to your actual workload.
Step 4 Set schema and query evolution expectations early#
Event sourcing changes how teams evolve schemas and query state, so align on a clear change process before multiple consumers depend on the contract.
Because migration to or from event sourcing is costly, treat major contract changes as long-term decisions.
Step 5 Reconfirm that benefits justify the complexity#
Adopt event sourcing when benefits like auditability and historical reconstruction justify its complexity.
For related operational context, keep this companion guide on audit trails nearby.
For a broader implementation walkthrough, see ERP Integration for Payment Platforms: How to Connect NetSuite, SAP, and Microsoft Dynamics 365 to Your Payout System.
Choose your event store based on operating constraints#
Pick the store you can operate and recover reliably, because the event sequence is the authoritative record, not a side log. If the team cannot explain failures, replay history, and restore service under pressure, the design will not hold when incidents happen.
Step 1 Match the store decision to operating ownership#
You are choosing an operating model as much as a data technology. Make ownership explicit for on-call response, backups, replay drills, upgrades, and incident timelines before you commit.
Treat the table below as checks to run in your own environment for EventStoreDB, Apache Kafka, and PostgreSQL.
| Option | What to validate before committing | Red flag |
|---|---|---|
| EventStoreDB | Replay and investigation checks from raw events are repeatable in staging | Ownership for operations and recovery is unclear |
| Apache Kafka | Re-read and replay tests are documented and downstream behavior is verified | Consumers create side effects when events are re-read |
| PostgreSQL append-only pattern | Each mutation is persisted as an event-row INSERT, with state-table updates handled from events, ideally in the same transaction | Business state can still be changed outside the event path |
For the PostgreSQL append-only pattern, treat it as a community-described approach and verify it in your own system. If you need one unique order across all events, add a global sequence and confirm consumers read from that order.
Step 2 Prove ordering and replay behavior with real checks#
Do not assume event support equals reliable history reconstruction. Run tests that show what is ordered, how replay is triggered, and whether rebuilt state matches expected state.
A practical check is to replay one aggregate from zero, then compare the rebuilt state with expected production behavior. If replay creates ambiguous history or unstable outputs, treat that as an operating gap to fix before you scale.
Step 3 Validate integration paths that depend on history#
If your stack includes webhook consumers, finance exports, or reconciliation reads, test one end-to-end flow from event write through state materialization and downstream outputs, then run it again from historical events.
Capture replay output, duplicate-handling notes, and the exact breakpoints when events are re-read. If you cannot document that path clearly, you are still making the store decision without enough evidence.
Step 4 Use a review cadence tied to measurable pain#
Choose a store you can defend with operating evidence, then review that choice on a planned cadence. Revisit it only when you can point to repeated replay incidents, investigation delays, or integration failures during historical reprocessing.
Until those pain signals are concrete, reliability beats store churn.
Build the write path with command handling and duplicate safety#
A practical write path in Event Sourcing does three things clearly: it validates commands before append, handles retries without hidden duplicates, and surfaces concurrency outcomes instead of masking them.
| Area | Rule | Check |
|---|---|---|
| Validate commands before append | Reject invalid state transitions at the Aggregate boundary before writing to the Append-Only Log | From event history alone, an operator should be able to explain why a command was accepted or rejected |
| Stable idempotency | Define one stable duplicate rule for the same business intent and apply it consistently at each entry point | A duplicate attempt should either return the prior accepted result or fail with an explicit duplicate outcome |
| Explicit concurrency | Define what happens after conflict; some commands can retry after reloading new events, others should fail fast | Logs or admin tooling should show which command lost the race, what version it expected, and whether a retry appended new events |
| Release checks | Inject deliberate duplicates, send commands in invalid order, and replay a sample aggregate | Compare rebuilt state with live read models |
Because moving to or from event sourcing is costly, and adoption can constrain later design choices, these write-path rules should be explicit before rollout.
Step 1 Validate commands before any event is appended#
Reject invalid state transitions at the Aggregate boundary before writing to the Append-Only Log. In Event Sourcing, that often means rebuilding current aggregate state from prior events, then deciding whether the command is valid before append.
This is where teams slip back into CRUD repair habits. In an append-only model, the event history is the system of record used to materialize state, so a bad transition is not only a local mistake. It can follow you into replay, investigation, and downstream read models.
A practical standard is this: from event history alone, an operator should be able to explain why a command was accepted or rejected.
Step 2 Enforce stable idempotency across entry points#
Treat duplicate handling as a write-path requirement. This grounding does not define a required idempotency-key schema or dedupe window, so define one stable duplicate rule for the same business intent and apply it consistently at each entry point.
Do not claim exactly-once behavior unless you can prove it end to end. A better operating rule is simpler: a duplicate attempt should either return the prior accepted result or fail with an explicit duplicate outcome.
For release evidence, sample commands and record the fields you need to trace decisions, such as aggregate ID, duplicate key, expected version, append result, and emitted events.
Step 3 Make concurrency explicit and operator-visible#
Concurrency handling needs to be explicit in the write path. Event Sourcing changes how concurrency is handled, so conflict outcomes should be visible instead of hidden.
Define what happens after conflict. Some commands can retry after reloading new events; others should fail fast with a clear state such as conflict, stale command, or already applied. Avoid silent overwrite patterns that hide drift until later reconciliation.
A useful checkpoint is observability: your logs or admin tooling should show which command lost the race, what version it expected, and whether a retry appended new events.
Step 4 Add release checks that try to break the write path#
Before each release, run checks that pressure the write path:
- Inject deliberate duplicates and confirm one intent does not append extra events.
- Send commands in invalid order and confirm the aggregate rejects illegal transitions.
- Replay a sample aggregate and compare rebuilt state with live read models.
Replayability is one reason teams accept event-sourcing complexity: replaying events can rebuild state at a chosen point in time. If replay cannot reliably rebuild state at a chosen point in time, your write rules are already ambiguous and should be fixed before wider rollout.
Build read models that finance and ops can trust#
Do not force one read model to satisfy product UX, finance, and investigations at the same time. Build separate views for each from the same event history, so outputs stay aligned with the decision they support.
Step 1 Split projections by decision, not convenience#
Define separate read models for product UX, reconciliation, and investigation timelines. In Event Sourcing, the event history in an append-only log is the authoritative source of truth, and each view is a purpose-built interpretation of that history.
For finance and investigation views, keep the event artifacts needed for traceability and replay. That includes StreamID, event name, version, timestamp, and the event data that explains a balance change or state transition.
Step 2 Anchor balances to an event-derived ledger view#
For wallet or stored-value flows, consider deriving ledger-facing balances from events and treating cached product balances as convenience copies. This keeps balance explanations tied to the same sequence you can replay for current-state or past-state reconstruction.
If you keep mutable side tables for latency or search, reconcile them back to the event-derived view instead of treating them as the source of truth.
Step 3 Add operator views for ticket-heavy cases in scope#
When payout and credit workflows are in scope, add dedicated operational views so teams do not have to investigate from raw events alone. Design each ops view to link back to the underlying stream so analysts can verify the exact event sequence behind an issue.
Step 4 Check projection drift and rehearse rebuilds#
Read-side drift is not just theoretical. Run drift checks on a cadence that matches your transaction volume. When mismatches appear, capture evidence such as stream ID, read-model version, last processed event, expected values, and actual values.
Rehearse replay-based rebuilds of critical views under controlled conditions to measure rebuild behavior and operating cost. These drills do not prove recoverability on their own, but they show whether read-side maintenance is still manageable as the surface area grows.
Related reading: Payment Volume Forecasting for Platforms: How to Predict Cash Flow.
Model hard payment lifecycles before they become incidents#
Incomplete lifecycle modeling is where payment teams get into trouble. If you only model happy paths, operators are left guessing from current state, and reconstruction gets slower the moment balances or statuses do not line up.
Step 1 Map business-fact events for critical payment flows#
Model payment flows as business facts, not generic status changes. Capture events such as payment attempt, authorization, settlement, and provider outcome using the terms your provider and ops team actually use.
The practical check is replayability. For a problematic payment, you should be able to explain when a balance changed, why it changed, and what happened next from the event stream alone.
Step 2 Add explicit timeout paths for missing confirmations#
Model non-events and delayed outcomes, not just successful transitions. Include paths for missing payment confirmations, KYC timeouts, and silently missed settlement deadlines when expected lifecycle events do not arrive.
Treat deadline handling as a first-class part of the lifecycle. Keep deadline records searchable and cancellable, and expose them in operator views so support can quickly distinguish pending, timed out, and canceled paths.
Step 3 Define edge paths before your first batch incident#
For long-running payment flows, define timeout, failure, and cancellation paths before incidents happen. A single generic failed state hides the next action operators need to take.
If you orchestrate across multiple services, make cancellation explicit as part of the model rather than an implied side effect.
Step 4 Attach operator actions and evidence to every path#
Each lifecycle state should include the expected operator action and the evidence recorded at that point. Keep event history, timestamps, latest outcome signals, and active or canceled deadlines tied to the same flow.
That is the real operational value of an immutable transaction history: not just replay, but a clear, audit-ready explanation of what happened and why.
Handle schema changes and replay without breaking production#
In an event-sourced payment platform, schema and reader changes can become production changes, because current state is rebuilt by replaying events from an append-only system of record.
Step 1 Set versioning expectations before changing contracts#
Define and document how your team treats event schema and contract changes so decisions stay consistent. The goal is not extra ceremony. It is avoiding ambiguous changes that become hard to untangle during incidents.
Before merge, make replay impact explicit: whether older events remain readable, whether existing consumers are expected to behave the same way, and whether any state differences are intentional.
Step 2 Validate replay impact before release#
For changes that affect serialization, readers, or read-model logic, treat replay behavior as release-critical. Use replay checks that fit your system, and investigate unexplained differences before broader rollout.
Event sourcing only delivers auditability and historical reconstruction when replay stays dependable.
Step 3 Prepare rollback guidance for replay-path failures#
Document how to respond when a deploy changes event write or read behavior and replay outcomes degrade. Keep the guidance focused on fast diagnosis and controlled recovery, with clear evidence about impacted event types and payloads.
When rollback is not clean, prioritize preserving record integrity over ad hoc read-side fixes in production, and recognize that these systems can be costly to change and hard to debug under eventual consistency.
Add compliance gates and evidence packs to the event stream#
Treat compliance decisions as first-class events so reviewers can reconstruct what happened from the stream and referenced evidence, not from tickets or inboxes.
| Event area | What to record | Grounded note |
|---|---|---|
| Compliance gate transitions | Compliance outcomes and policy-gate transitions in the event history, with stable references to the related case and evidence pack | Keep the full decision path, including holds, escalations, and releases |
| Tax-document milestones | For FEIE and FBAR, model lifecycle events plus document or version references and review outcomes | For FEIE, the claim artifact is Form 2555/2555-EZ; if physical-presence support is tracked, record the claimed period and review status against the 330 full days in 12 consecutive months test |
| Export events | Log who requested the export, the scope, when it was generated, and which artifact bundle was produced | One case should be reconstructible from events plus referenced documents alone |
Step 1 Record compliance gate transitions as auditable events#
Capture compliance outcomes and policy-gate transitions in the event history, with stable references to the related case and evidence pack. Keep the full decision path, including holds, escalations, and releases, so the Audit Trail explains why onboarding or payout state changed. Store references to controlled evidence artifacts.
Step 2 Add tax-document milestones only for workflows you actually support#
If tax workflows are enabled, model milestones for FEIE and FBAR as lifecycle events, plus document or version references and review outcomes. For FEIE, keep the evidence chain explicit: the exclusion applies only to a qualifying individual with foreign earned income, the income is still reported on a U.S. return, and the claim artifact is Form 2555/2555-EZ.
If you track physical-presence support, record the claimed period and review status against the 330 full days in 12 consecutive months test. Note that the qualifying days do not need to be consecutive.
Step 3 Design export events before requests arrive#
Define export requirements now so compliance and finance can satisfy internal reviews and external requests without ad hoc data pulls. Log who requested the export, the scope, when it was generated, and which artifact bundle was produced. Your verification check is straightforward: one case should be reconstructible from events plus referenced documents alone.
Common implementation mistakes and how to recover fast#
Most recovery plans come back to the same moves: narrow scope, re-establish the Event Store as the system of record, and expand only when the benefits are clear.
Step 1 Shrink the blast radius when scope spread too far#
If event sourcing was applied too broadly on day one, pull back to a smaller scope first. Event sourcing is a complex pattern with significant tradeoffs, and traditional data management is sufficient for most systems and most parts of a system.
Use a simple gate: keep event sourcing where auditability and historical reconstruction clearly justify the complexity, and leave adjacent areas on CRUD where it is sufficient. That also reduces early architecture lock-in, which is costly to undo later.
Step 2 Re-anchor everyone on the Event Store when projections drift#
Treat read models as useful views, not truth. In this pattern, the Event Store is the authoritative source used to materialize domain objects.
Recover in two moves: rebuild from the append-only store for a real case, then verify the materialized state against the expected result. When a view and the rebuilt state disagree, treat the event-backed rebuild as authoritative.
Step 3 Address write contention before load turns it into a bottleneck#
Under load, concurrent writes to the same entity can degrade performance and become a bottleneck.
Test your high-contention paths early and tighten the write path before expanding event-sourced scope further.
Step 4 Check migration and lock-in risk before expanding again#
A common failure mode is underestimating how costly it is to migrate to or from an event-sourcing solution.
Before each expansion, document what you are committing to, what would be hard to reverse, and why event sourcing is still justified for that scope.
Release-readiness checklist#
Before each phase expansion, confirm all of the following:
- Event-sourced scope is explicitly limited, and traditional data management remains in place where it is sufficient.
- The Event Store is documented as the system of record, and at least one domain object has been materialized from the append-only store.
- The decision to use event sourcing is tied to auditability and historical reconstruction benefits, not default architecture preference.
- High-contention write paths have been tested for concurrent writes to the same entity.
- Migration and lock-in implications have been reviewed before adding more scope.
If you are validating replay behavior in your own stack, the Gruv docs provide API and webhook patterns you can map to your architecture.
Conclusion and copy-paste launch checklist#
Use Event Sourcing only where immutable, replayable history clearly reduces investigation or reconstruction risk. If a domain does not need to answer how current state was reached from recorded facts, keep it on CRUD.
Step 1#
Start with one bounded flow. Keep stream scope tight so each stream remains the full history for its domain object and source of truth.
Your first go or no-go check is simple: can you explain current state by reading the stream and applying events in order? If not, narrow the scope or tighten the event definitions.
Step 2#
Approve event names and payloads before writing production events. Because events are immutable, changes can be harder later.
Use replay as a release check. Rebuild a real stream and compare the result to the expected state.
If you want to pressure-test your rollout plan against real payout and compliance constraints, talk to Gruv.
Frequently Asked Questions
What is Event Sourcing in a payment platform, and how is it different from a traditional ledger table?
Event Sourcing stores the full series of actions in an append-only store and rebuilds current state by replaying events. In a traditional CRUD-style table, teams usually store current state directly and update rows in place. Here, the event store is the system of record, and read views are derived from event history.
When should a payments team choose Event Sourcing over CRUD, and when should it avoid it?
Choose Event Sourcing when auditability and historical reconstruction clearly justify the added complexity. Avoid it when current-state data is enough and full historical reconstruction is not a core requirement. For most systems and most parts of a system, CRUD remains the better default, and moving into or out of event sourcing is costly.
What is the minimum architecture needed to launch an Immutable Transaction Log safely?
There is no proven universal minimum checklist. At minimum, keep an append-only store as the primary record, define events with stream identifier, event name, version, and payload, and verify that state can be rebuilt from events. A practical check is replaying a real stream end to end and confirming the rebuilt state matches the expected result.
Does event sourcing replace double-entry accounting or only complement it through Projection and replay?
The article does not present event sourcing as a replacement for double-entry accounting or ledger controls. It describes event sourcing as a way to record operational events and rebuild state from event history. In that framing, it complements projection and replay rather than replacing accounting controls.
What are the biggest operational risks around schema evolution, concurrency, and Event Replay?
Schema and version evolution are risky because old events remain part of the system and design choices become harder to change later. Ordering is also critical, because events must be published in the same order as the underlying transactions for correct replayed state. Another risk is write-plus-publish inconsistency when reliable distributed transaction support such as 2PC is unavailable or undesirable.
How should teams start small without overcommitting to CQRS everywhere?
Start selectively where immutable history, auditability, and historical reconstruction are clearly valuable. Keep other areas on CRUD by default. The article does not set a rule that CQRS must be used everywhere.
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
Includes 7 external sources outside the trusted-domain allowlist.
- baytechconsulting.com/blog/event-sourcing-explained-2025external
- dzone.com/articles/event-sourcing-guide-when-to-use-av...external
- eventsourcing.readthedocs.io/_/downloads/en/v7.2.0/pdfexternal
- learn.microsoft.com/en-us/azure/architecture/patterns/event-sour...external
- liora.io/en/all-about-event-sourcingexternal
- microservices.io/patterns/data/event-sourcing.htmlexternal
- softwaremill.com/implementing-event-sourcing-using-a-relation...external
Educational content only. Not legal, tax, or financial advice.
Related Posts

The Freelance Payment Penalty: A Modeled Audit of Platform Fees, FX Spreads, and Payout Delays
The money rarely disappears through a single, easy-to-spot fee. The real loss is stacked. A marketplace takes its commission, a processor adds a charge for international cards, a bank or payment company converts the currency at a spread, a platform holds the funds before release, and a wire sheds a little to intermediaries on the way in. Each layer looks defensible on its own, but the worker feels the combined result as a smaller deposit and a later payday.

How to Respond to a Subpoena for Business Records
Move fast, but do not produce records on instinct. If you need to **respond to a subpoena for business records**, your immediate job is to control deadlines, preserve records, and make any later production defensible.

A US Expat's Guide to Investing in UCITS ETFs to Avoid PFIC Issues
The real problem is a two-system conflict. U.S. tax treatment can punish the wrong fund choice, while local product-access constraints can block the funds you want to buy in the first place. For **us expat ucits etfs**, the practical question is not "Which product is best?" It is "What can I access, report, and keep doing every year without guessing?" Use this four-part filter before any trade: