
Quick Answer
A business continuity plan for a payment platform should define which payment functions must keep running, which must pause, who decides, and what evidence is required before normal processing resumes. Build it around a narrow Business Impact Analysis of ledger, balance checks, release processing, payout execution, and reporting, then add recovery targets, stop-go rules, degraded mode procedures, named owners, communication paths, compliance controls, and testing.
What a Business Continuity Plan for a Payment Platform Should Cover#
A usable Business Continuity Plan (BCP) for payments is an execution plan, not a file you hope to use later. Continuity planning means maintaining or recovering operations during adverse events while continuing to serve customers. In payments, disruption can escalate quickly when decisions are unclear.
This guide is scoped to payment-platform operations where continuity decisions can create financial and control risk. It focuses on the functions that determine whether money movement should continue, pause, or resume safely:
- Ledger integrity and posting continuity
- Balance checks across balances, transactions, and exceptions
- Release processing and downstream file or rail dependencies
- Payout execution and approval controls
- Reporting continuity for finance, operations, and audit follow-up
That scope is deliberate. Before speed, you need confidence in records and control evidence. The plan should state what must keep running, what must pause, and what evidence is required before normal processing resumes.
This is written for the people who make those calls in real incidents: finance, operations, and product owners, usually with engineering and compliance involved. The output should be concrete decision rules, recovery priorities, and checkpoints your team can test under pressure instead of debate in the moment.
One principle sits above every later decision: protect customers, financial integrity, and compliance before speed. Continuity objectives include recovering operations, continuing to serve customers, minimizing financial loss, and remaining compliant. When records or approvals are uncertain, a controlled restart is often the safer choice.
A final caution: FFIEC and OCC continuity guidance is a strong risk lens, but it is written for bank and service-provider contexts. For non-bank platforms, use it as serious guidance, not as a one-to-one rulebook.
What to prepare before you start writing#
Before you draft procedures, assemble one evidence packet with your risk assessment, current process maps, recent failure evidence, and the dependency documents that will constrain recovery choices. If any artifact has no clear owner or last-validation date, treat that as a continuity gap before you start writing. Build the packet from three inputs.
| Input | What to gather | Details to record |
|---|---|---|
| Operating picture | Current process maps for mission-essential and supporting operational flows | A practical BPA-level view for each flow: steps, people, activities, inputs, and outputs; clear ownership for each map; visible gaps where critical steps are still undocumented or held in individual memory |
| How operations actually fail | Recent incident logs, exception reports, and recovery notes | Major and routine disruptions, not just headline outages |
| Documents that constrain recovery decisions | Current risk, recovery, and continuity-supporting dependencies | For each artifact: location, owner, backup owner, last review date, and any vendor contact needed during an incident |
Start with the operating picture for mission-essential and supporting flows: current process maps, a practical BPA-level view of steps, people, activities, inputs, and outputs, and a named owner for each map. Mark any critical step that is still undocumented or held in individual memory.
Then pull recent incident logs, exception reports, and recovery notes from both routine and major disruptions so the draft reflects how operations actually fail, not just headline outages.
Finally, collect the documents that constrain recovery decisions. For each artifact, record the location, owner, backup owner, last review date, and any vendor contact you may need during an incident.
This prep keeps the plan grounded in current operations and helps you avoid writing recovery steps around stale assumptions.
If ledger recovery is part of your continuity scope, read How to Build a Deterministic Ledger for a Payment Platform.
Step 1 define critical scope and incident tiers#
Lock scope and incident tiers before you write recovery steps. If scope is loose, the first version turns into an inventory instead of an operating plan. Set the initial must-run scope to a short list of essential functions: the operations most important and time-critical to keep service running with minimal disruption.
| Tier | Primary signal | Business impact |
|---|---|---|
| Tier 1 | Contained disruption | Limited service impact and predictable outcomes |
| Tier 2 | Visible service degradation | Rising financial exposure |
| Tier 3 | Disruption where outcomes are unknown | Confidence in core operations is compromised |
- Functions required to keep serving customers and market participants
- Operations with the highest financial-loss exposure if they stop
- Core records and processes needed for reliable decisions
- Critical dependencies those functions rely on
Treat this as an explicit version-one scoping choice, not a universal template. For every in-scope function, record key dependencies and the business consequence if it stops. For anything out of scope, mark it clearly so the plan stays usable.
Tier incidents by business impact, not just technical severity:
- Tier 1: contained disruption with limited service impact and predictable outcomes
- Tier 2: visible service degradation or rising financial exposure
- Tier 3: disruption where outcomes are unknown or confidence in core operations is compromised
Add one plain-language stop rule near the top for cases where confidence in core records is uncertain: define which outward actions pause, who decides, and how controlled resumption begins. Keep this first release narrow with explicit testing scope and objectives, then expand scope in later updates as operations and threat scenarios change.
Related reading: How to Build a Payment Health Dashboard for Your Platform.
Step 2 run a payment specific Business Impact Analysis#
Use the scope from Step 1 to drive recovery decisions, not just descriptions. For each function, define what fails, what the impact is, what can be done manually, and what evidence is required before normal processing resumes.
Keep the first pass narrow. A practical payment-focused first pass can start with Ledger, balance checks, release processing, and Payout execution, then expand to reporting and support operations so money movement and record integrity stay at the top of the queue.
Build the first BIA table#
Use structured interviews or a short workshop with each function owner. For each function, capture the impact label, failure mode, downstream blast radius, manual fallback, and resume evidence. Use High / Medium / Low labels, and avoid marking everything High.
Use this as a working template, not a mandated field set:
| Function | Impact | Failure mode and blast radius | Manual fallback | Evidence before normal resumption |
|---|---|---|---|---|
| Ledger | High | Posting delays, missing journals, or uncertain balances affect downstream release and reporting decisions. | Pause outward movement and use controlled manual posting only where validated. | Journal completeness checked, gaps resolved, owner sign-off on balance reliability. |
| Balance checks | High | Internal and provider records diverge, increasing exception and exposure uncertainty. | Work exception queues manually and prioritize critical batches. | Discrepancies resolved, or explicitly reviewed and accepted by a named approver. |
| Release processing | High | Files are delayed, mismatched, or unconfirmed, affecting release confidence and cash timing. | Hold release or run controlled manual review of instructions. | Outputs reviewed against internal records before release, with required confirmations captured. |
| Payout execution | High | Batch generation or release controls fail, increasing customer impact and duplicate-risk exposure. | Run controlled priority batches only. | Batch totals approved, duplicate checks complete, upstream checks passed. |
| Reporting | Medium | Reporting is delayed or incomplete, reducing decision visibility during the incident. | Produce minimum viable manual reports for cash, exceptions, and releases. | Core outputs regenerated, limitations noted, finance owner confirms usability. |
| Support operations | Medium | Queue handling slows when status data is stale or volume spikes. | Use manual queues and approved status messaging. | Backlog triaged, status source validated, open customer-impact list current. |
Score dependencies, not just functions#
A function can look recoverable on paper and still fail because one dependency blocks it. After you score functions, score dependency risk for each one using the same High / Medium / Low method. Include internal services, external providers, and required control checks that can block funds movement.
Use one shared scoring method across rows so the comparisons stay usable. A simple test works well: if this dependency is unavailable for more than an hour in your scenario, do you continue normally, degrade safely, or stop?
Define resume evidence before an incident#
Do not wait until an incident to decide what "safe to resume" means. Write resume checkpoints now, and keep them plain enough for operators to make yes-or-no decisions quickly.
Use function-level evidence artifacts, such as matching outputs, journal exports, downstream confirmations, approval logs, or exception lists. The BIA should drive the rest of the plan, so keep the highest financial and operational impact functions at the top of the recovery order.
For a step-by-step walkthrough, see How to Build a Payment Reconciliation Dashboard for Your Subscription Platform.
Step 3 set recovery targets and stop go rules#
Once the BIA tells you what matters most, set Recovery Time Objective (RTO) and Recovery Point Objective (RPO) for each critical function. Then define the stop-go action when a target is likely to be missed. A single platform-wide target is often too broad when critical functions have different impact levels.
RTO is the target time to recover and resume normal operations. RPO is the maximum data loss you can tolerate, measured as time. Set both from function criticality and impact, using your BIA as the baseline.
Set targets from impact, not from infrastructure#
For each critical function, answer two questions: how long can the disruption last, and how much missing data is acceptable before restart becomes unsafe? Tie those answers to business impact criteria your team already uses, such as customer impact, financial risk, regulatory exposure, and reputational impact.
| Function | RTO question | RPO question | Practical stop-go rule |
|---|---|---|---|
| Payout execution | How long can payouts be delayed before impact is unacceptable? | How much payout-state loss is tolerable before release risk is too high? | If expected recovery exceeds payout RTO, escalate to the continuity lead and use the documented contingency workflow. |
| Release processing | How long can this pause before release confidence or cash timing becomes unacceptable? | How much related data can be missing before verification is unsafe? | Keep normal release paused until the planned recovery evidence is completed and approved. |
| Balance checks | How long can exception clearing be delayed before finance and ops decisions become unreliable? | How much transaction history can be unavailable before deltas are not dependable? | Stay in degraded mode until critical gaps are resolved or explicitly accepted by the named decision owner. |
Do not copy illustrative numbers, such as a 2-hour RTO or 12-hour RPO, unless your own impact analysis supports them.
Write stop-go rules as clear if-then decisions#
A rule is only useful if someone can see the trigger and act on it. Make each one observable and owned: trigger, response, owner, and recovery evidence. Before you return to normal flow, define the evidence pack up front, including impact status, service or data recovery status, communications, and required approvals.
Name override authority and logging now#
If someone can override a threshold, document that now, before the incident starts. Record who can do it, what evidence they must review, and where the decision is logged in your continuity plan. Keep it auditable: named decision owner, rationale, risk accepted, evidence reviewed, and timestamp.
Step 4 design degraded mode execution paths#
Degraded mode should protect control and decision quality first, then restore speed. Operating disruptions can happen with or without warning, and outcomes may be predictable or unknown. When normal processing is unavailable, keep service running only where you still have confidence, while preserving record accuracy and auditability.
Compare each critical flow before you write procedures#
Do not write one generic incident path for the whole platform. Inbound intake, internal processing, outbound execution, and finalization can fail in different ways. Document each flow in normal mode and degraded mode, plus what proves it is safe to resume.
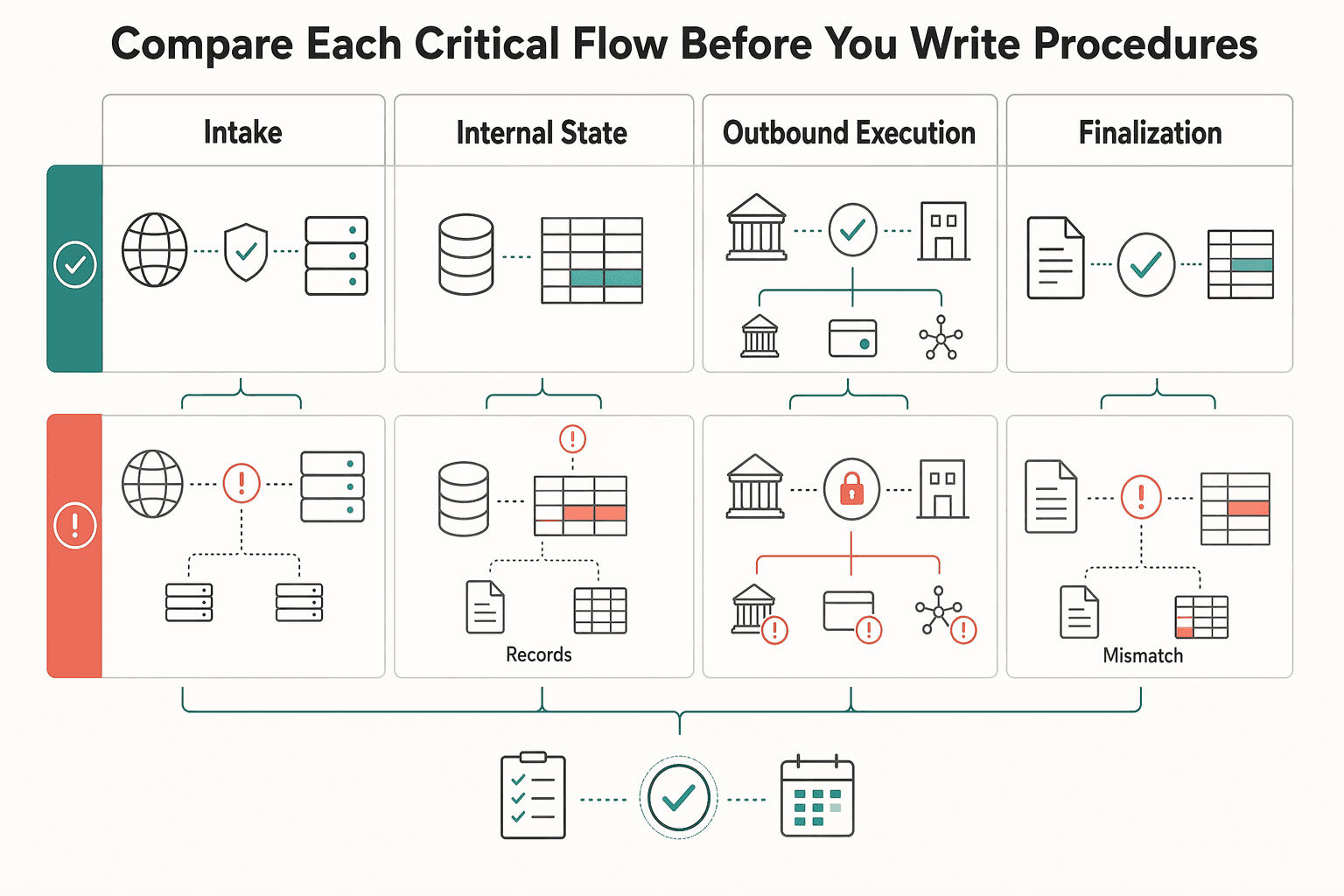
| Function | Normal operation | Degraded mode design choice | Resume checkpoint |
|---|---|---|---|
| Intake | Inbound events post through the standard flow | Continue intake only when posting confidence is intact; otherwise queue or mark pending review | Data synchronization complete and queued items matched to source records |
| Internal state updates | Records follow normal processing rules | Separate visibility from final action when event confidence is low | State validated against recorded entries and source confirmation |
| Outbound execution | Outbound actions run through normal approval and provider paths | Constrain release to controlled handling, or pause irreversible movement when state confidence is low | Approval record, exception disposition, and state verification |
| Finalization | Standard finalization timing and release process | Hold normal release when confirmations or internal records are incomplete | Output checked against internal records and required confirmations |
A practical default is to tighten irreversible outbound movement earlier than inbound handling when control confidence drops. That tradeoff matters even more with third-party dependencies, where added capability can come with reduced direct operational control and higher disruption risk.
Write the degraded order of operations explicitly#
Operators need a sequence they can follow without improvising. This is a plan design choice, not a mandated industry order:
- Freeze hard-to-reverse actions first. Pause outward releases and other irreversible steps tied to uncertain state.
- Protect recorded state as decision truth. Limit exception handling and keep a clear audit trail for every override.
- Process priority work with named approval. Route only pre-defined urgent work through controlled review.
- Clear backlog before broad resumption. Resolve or formally accept deltas, then log return-to-normal approval.
Define a visible evidence pack before exit from degraded mode, such as matching output, exception list, relevant confirmation, approval record, and data synchronization status.
Make retries safe before you need them#
Document retry guardrails before you need them. State in plain language when retries are allowed, what checks must pass first, and when events require manual review before they can change records.
In operations, add a simple checkpoint: review a sample of retried events and confirm a successful replay does not create new posting impact when the original pass already succeeded.
Route by dependency and control confidence, not incident label#
The right degraded path depends on where control is reduced, not on the incident label. The core rule is simple: route by where confidence is lower and what evidence is available to recover safely.
- Provider outage: Keep internal records clean, queue provider-dependent actions, and use alternate routing only if it is pre-approved and operational impact is understood.
- Internal outage or denied/degraded access: Apply stricter controls and keep outward movement constrained until your own state integrity is trusted again.
- Disruption or exfiltration concern: Increase verification and explicit approvals before broad resumption.
Step 5 assign owners approvals and communication paths#
Once you have degraded paths, reduce improvisation. Assign clear owners, define approval triggers, and prewrite communication paths.
Assign one accountable owner per lane#
Each decision lane should have one accountable owner, one backup, and a written escalation trigger. Define lanes that fit your operating model (for example operations, finance, compliance, engineering, and customer communications). These are plan design choices, not a regulator-mandated title list.
Use named people, not only team names, and regularly verify backup coverage. If you already use continuity coordinator or mission-owner structures, map them directly here so authority is not split across parallel models.
Tie escalation to function and evidence#
Escalation should follow the impaired function, with a clear trigger, approver, and evidence required to continue, pause, or resume.
- Integrity uncertainty: route decisions to the designated function owners and constrain high-risk actions until integrity is trusted
- Confirmation gaps: the designated approval owner decides hold-or-release based on predefined checks and required confirmations
- Compliance queue blockage: compliance decides what can move without bypassing required review controls
- Balance-check breaks tied to payout state: define your own payout-resumption rule explicitly, including whether leadership sign-off is required by your internal policy
For each trigger, specify the minimum evidence pack, such as affected payout or release IDs, current exception state, required checks, and approval log entry.
Write communication paths before the incident#
Write short templates now so people can use them under pressure.
For internal updates, include current status, affected functions, go or hold decision, next checkpoint time, named owner, and missing evidence. For external updates, focus on service impact, current action, next update time, and support path.
For sensitive or protected information, keep broad updates high level and route case-specific details through restricted channels.
Keep one contact matrix and verify it#
Maintain one contact matrix, then tailor notification paths by market and program.
| Contact type | When to use it | Owner | Shareable content |
|---|---|---|---|
| Payment/rail vendor | Provider outage, delayed files, posting mismatch | Incident/engineering owner | Scope, impacted service, timestamps, investigation references |
| Bank/program partner | Release issue, funding delay, payout hold | Finance owner | Financial impact summary, affected references, containment plan |
| Regulator/supervisory contact (if applicable) | Market/program notification event | Compliance owner | Approved incident facts required for that market/program |
Add a last verified date to each row and validate contacts regularly. Keep the matrix with the signed plan-authorization artifact so execution authority and responsibilities stay explicit.
Step 6 build compliance and documentation controls into continuity#
Set this boundary clearly: degraded operations are not a bypass. If a required compliance review cannot be completed and evidenced, hold the affected activity, log why, and escalate to the named approver.
For each critical flow, document the control that must still occur, who can approve or deny, and the evidence required to prove the decision. Use evidence you can reconstruct later, such as case or ticket ID, reviewer, decision timestamp, account reference, and hold or release outcome.
Map document dependencies before the incident#
Tax and reporting records are continuity dependencies, not side tasks. Where relevant to your model, map FBAR dependencies to owners, retrieval paths, and resume criteria.
For FBAR, keep the mechanics explicit in the plan:
| FBAR checkpoint | What to preserve in continuity |
|---|---|
| Filing threshold | File if a single account or aggregate maximum account values exceed $10,000 during the calendar year; no filing if the threshold is never met. |
| Maximum value method | Use a reasonable approximation of the greatest value during the year. |
| Currency conversion | For non-U.S. currency accounts, use Treasury's Financial Management Service year-end rate; if unavailable, use another verifiable rate and record its source. |
| Value formatting | Round up to the next whole U.S. dollar, for example $15,265.25 -> $15,266; if computed maximum is negative, enter 0. |
| Corrections | To fix a filed FBAR, submit a new complete FBAR, select Amend, and provide the Prior Report BSA Identifier; if unknown, use O00oooooooo00. |
| Timing note | Filing instructions state an annual due date of April 15th with an automatic extension to October 15th. |
Add the regulatory caveat explicitly#
State this directly in the plan: templates do not guarantee compliance. Identify any obligations outside FBAR with your compliance and legal owners rather than assuming a generic continuity plan is sufficient.
Constrain sensitive information in incident channels#
Keep sensitive tax and account records in restricted systems. FinCEN notes information submitted on its secure site is encrypted and transmitted securely, so route FBAR filings through secure portals rather than broad chat or email threads.
Add a post-incident check: review access logs for sensitive records where available.
Related: How to Write a Payments and Compliance Policy for Your Gig Platform.
Step 7 define testing cadence and evidence standards#
A BCP is only credible if you test it, keep the evidence, and update the plan when operations change.
| Testing step | Focus | Required detail |
|---|---|---|
| Set a cadence tied to risk and change | Test the highest-impact disruption scenarios first | Run an additional test whenever a major flow, provider dependency, or approval path changes |
| Test the critical path end to end | Run continuity drills across each critical service path as one connected workflow | Set checkpoints and measurable recovery objectives (RTOs and RPOs) before the test starts |
| Require a standard evidence pack after every test | Retain a consistent evidence set after each exercise | Timeline of events; decision log with approvers; control exceptions or controls not executed; remediation owner and due date for each gap |
| Refresh the plan when product flows move | Update the BCP when major product flows change | Record one explicit outcome: either the current plan remains valid, or a named owner updates it by a due date |
Step 1 set a cadence tied to risk and change#
Test the highest-impact disruption scenarios first. Use exercises that validate both decision quality and operational execution under pressure.
Do not treat this as a once-a-year document task. Keep a standing cadence, and run an additional test whenever a major flow, provider dependency, or approval path changes.
Step 2 test the critical path end to end#
Infrastructure recovery is not enough. Run continuity drills across each critical service path as one connected workflow, and make sure the BCP references DR runbooks and IR playbooks.
Set checkpoints and measurable recovery objectives (RTOs and RPOs) before the test starts so each stage has clear pass-or-fail evidence. If one stage cannot be evidenced, document the gap and treat the drill as incomplete.
Step 3 require a standard evidence pack after every test#
After each exercise, retain a consistent evidence set, such as:
- timeline of events
- decision log with approvers
- control exceptions or controls not executed
- remediation owner and due date for each gap
Store this with the version-controlled plan and test results. The standard is not just to have a written plan, but to establish, document, test, and maintain it with auditable evidence.
Step 4 refresh the plan when product flows move#
Write change triggers directly into the plan: when major product flows change, update the BCP. Do not wait for an annual review.
Treat continuity as a loop of analysis, planning, testing, and improvement. After every test, record one explicit outcome: either the current plan remains valid, or a named owner updates it by a due date.
Common mistakes that break payment continuity plans#
Continuity and recovery plans usually fail for familiar reasons: they are not tested, updated, or reviewed, so the document looks complete on paper but does not guide real decisions under pressure.
- Treating all critical functions as one problem. If you do not identify critical functions and map risks to each, teams default to a generic response that is hard to run.
- Leaving third-party dependencies implicit. Vendor failures can break continuity, so those dependencies need to be explicit in the plan.
- Assuming distributed teams operate under identical conditions. Internet, power, and workspace reliability can vary by location and disrupt execution.
- Testing whether the document exists instead of whether operations can run. Untested, stale, or unreviewed plans often fail in real crises.
- Treating continuity planning as a one-time task. The plan should be a living document, reviewed and updated as operations, technology, and risks change.
If you need a scenario-specific appendix, see How to Create a Business Continuity Plan for a Natural Disaster.
Copy paste BCP launch checklist#
Use this checklist only when all five items are true at the same time. Otherwise, the plan is not launch-ready.
-
Lock scope and confirm accountable owners. Define the mission-critical services and processes this BCP covers, then get cross-functional sign-off from accountable owners. In payment operations, functions like ledger, balance checks, payout execution, and reporting belong here only if they are truly in scope for your team.
-
Complete the BIA at function level. For each in-scope function, document dependencies, including vendors, fallback or manual workaround paths, and the checkpoint that shows it is safe to resume. If a checkpoint is missing, treat that function as not ready for activation or recovery.
-
Approve recovery targets and stop-go rules. Make recovery targets explicit, for example RTO, capture owner approval, and name who can authorize exceptions. If exception authority is unclear, decision-making can stall during disruption.
-
Make activation mechanics live before launch. Publish the contact matrix, confirm the command center or equivalent response structure, and pre-position the resources needed to continue or recover critical services. Keep an assigned evidence repository with current checklists, forms, procedures, and links to related DR and incident materials.
-
Set test and update cadence, then map fallback handling. Schedule exercises or training at least annually, along with annual updates for the plan and associated checklists, forms, and procedures. Document how approvals and controls are handled during fallback processing.
Turn this checklist into an executable runbook by mapping each control to your payout/webhook flow and incident evidence fields in the Gruv docs.
Conclusion#
A strong Business Continuity Plan is a decision system your team can execute under pressure, not a document they only reference. It is credible when ownership is explicit, recovery targets are measurable, and each recovery action is clear and traceable.
Continuity is broader than disaster recovery alone. Restoring infrastructure is only part of the work. The plan also needs finance, compliance, customer communications, vendors, and leadership decision-making, because disruption in one area can cascade into others in a matter of hours.
Run one cross-functional simulation#
Pick one scenario and run the plan through the functions you treat as critical across operations, finance, support, and communications. Evaluate the drill on decision quality: did the right owner make the right call with the information available at the time?
By the end, you should be able to show who owned each decision, which recovery target they used, what evidence they reviewed, and when they chose to continue, pause, or resume activity. If you cannot reconstruct that decision trail, the plan is still too vague.
Capture gaps as operational defects#
After the exercise, log every hesitation, approval bottleneck, stale contact, and missing proof-to-proceed as a BCP defect. A well-built continuity program should clarify priorities, assign owners, and define measurable recovery targets. Any ambiguity the drill exposes is work to fix.
A common failure mode is treating continuity as IT restoration and assuming the rest will self-correct. In practice, finance, compliance, and customer communications each need clear decision paths, and plans break when speed on paper replaces control in execution.
Ship a tighter revision immediately#
Update the plan while the drill is fresh: owner names, approval paths, evidence requirements, and the checkpoints for resuming normal operations. If the team could not operate confidently across critical workflows, the fix is not a cleaner template. It is tighter decision rules.
Include at minimum:
- Scenario timeline and key decisions
- Evidence reviewed at each stop or resume point
- Control exceptions or missing dependencies
- Owner and due date for each remediation item
Run one cross-functional simulation, capture the real gaps, and publish a revised BCP with sharper decision rules. If the plan helps your team recover with confidence and leaves a clear decision trail, you are operating a continuity capability, not maintaining a template.
If you want a second set of eyes on your stop-go rules, ownership matrix, and market-specific compliance gates, talk with Gruv.
Frequently Asked Questions
What should a business continuity plan for a payment platform include first?
Start with a Business Impact Analysis so you can decide which operations to maintain or recover first. Build the rest of the plan around clear continuity objectives such as continuing service, minimizing financial loss, and protecting critical financial services.
How is a payment-platform BCP different from a generic BCP template?
A payment platform BCP must show how critical financial services stay available during disruption. Generic templates can help structure the document, but they still need decisions defined through the BIA, risk assessment, and plan development process.
How do we set realistic **RTO** and **RPO** targets for payouts and settlement?
Set RTO and RPO using your BIA and risk assessment, not arbitrary numbers. Use targets tied to business impact that your team can actually operate against during a real disruption.
Do templates from providers or industry sites guarantee compliance with **FINRA Rule 4370** or other obligations?
No. Templates can speed up drafting, but they do not guarantee compliance. Route applicability and sufficiency to compliance or legal review.
Which incidents should we test for payments operations?
Test multiple disruption types, including natural disasters, technology failures, human error, and terrorism. Use methods such as tabletop or mini-drill exercises, and validate assumptions, information accuracy, and procedure completeness.
How often should we update a BCP when payment operations change?
Update the plan whenever business processes, major flows, provider dependencies, approval paths, or threat scenarios change. Do not wait for a fixed annual cycle if procedures, owners, or recovery steps are no longer current.
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
- bsaefiling.fincen.gov/docs/XMLUserGuide_FinCENFBAR.pdftrusted
- c3.unu.edu/projects/security/vrm/outputs/4_buffer_claim...trusted
- fdic.gov/regulations/examinations/supervisory/insight...trusted
- federalreserve.gov/frrs/guidance/third-party-risk-management-a-...trusted
- fema.gov/sites/default/files/2020-10/non-federal-cont...trusted
- fema.gov/sites/default/files/documents/fema_oncp_fcd-...trusted
- fincen.gov/reporting-maximum-account-valuetrusted
- fincen.gov/system/files/shared/FBAR%20Line%20Item%20Fil...trusted
Educational content only. Not legal, tax, or financial advice.
Related Posts

The Freelance Payment Penalty: A Modeled Audit of Platform Fees, FX Spreads, and Payout Delays
The money rarely disappears through a single, easy-to-spot fee. The real loss is stacked. A marketplace takes its commission, a processor adds a charge for international cards, a bank or payment company converts the currency at a spread, a platform holds the funds before release, and a wire sheds a little to intermediaries on the way in. Each layer looks defensible on its own, but the worker feels the combined result as a smaller deposit and a later payday.

How to Respond to a Subpoena for Business Records
Move fast, but do not produce records on instinct. If you need to **respond to a subpoena for business records**, your immediate job is to control deadlines, preserve records, and make any later production defensible.

A US Expat's Guide to Investing in UCITS ETFs to Avoid PFIC Issues
The real problem is a two-system conflict. U.S. tax treatment can punish the wrong fund choice, while local product-access constraints can block the funds you want to buy in the first place. For **us expat ucits etfs**, the practical question is not "Which product is best?" It is "What can I access, report, and keep doing every year without guessing?" Use this four-part filter before any trade: