
Quick Answer
Start by drafting a one-page business continuity plan natural disaster sheet that names your top critical functions, fallback triggers, and owners, then test it immediately with a short Tabletop Exercise. Keep continuity actions separate from technical restoration so service can continue while systems recover. Use a simple two-lane structure: immediate response and staged recovery. Include a communication template, a backup method for each priority function, and a small evidence pack so decisions do not stall.
Build a Natural-Disaster Continuity Plan in One Afternoon#
Use this afternoon to produce a practical first draft: a one-page continuity plan for a natural disaster and a short tabletop test. This is not a regulator requirement; it is a practical way for an independent professional or small team to protect critical functions, keep client commitments visible, and make better decisions under stress.
Continuity planning means maintaining or recovering operations during disruption, whether the event comes with warning or not. Public guidance supports assigning ownership and documenting actions. In a very small business, that can be as simple as naming who decides and who takes over if that person is unavailable.
Step 1 Define what must survive first#
List your Critical Business Functions in priority order. For each one, define the minimum acceptable level of service. If someone else cannot read the list and tell what gets restored first, tighten the wording.
Step 2 Draft a one-page operating plan#
Create a one-page sheet with clear fields for each function: who owns it, how work continues if normal tools fail, and what recovery looks like. Add one trigger line that states when to switch to fallback mode. Keep one short client-status template so updates stay consistent during disruption.
Step 3 Separate immediate response from staged recovery#
Plan in two lanes: immediate response and staged recovery. Some conditions are predictable and some are not, so you need both first moves and follow-through. Keep continuity and technical recovery linked: continuity protects service delivery while recovery restores systems and data.
Step 4 Pressure-test with a tabletop exercise#
Run one realistic scenario and force real decisions. Check communication, access to essential records or tools, and payment flow. Log what failed, assign one owner to each fix, and set deadlines so the plan stays usable.
By the end of the session, you should have a shareable draft plan, one tested scenario, and a short fix list with clear ownership. That is enough to reduce guesswork now and improve over time. For a deeper cross-border planning example, read Canada's Digital Nomad Stream: How to Live and Work in Canada.
Gather What You Need Before You Start#
Collect inputs before drafting so the session stays focused on decisions, not document hunting. Start with records readiness, then move into prioritization.
Step 1 Collect your current BCP and DR documents#
Pull your latest Business Continuity Plan (BCP) and Disaster Recovery (DR) Plan files, even if incomplete. Put current and prior versions in one folder so gaps are easy to spot. If something is missing, mark it missing, assign an owner, and keep going.
Step 2 Pull the minimum evidence set#
Build a small evidence pack you can scan quickly during a disruption:
- active client contracts with delivery and notice terms
- current vendor list with account owner and support contact
- tool login access details and recovery methods
- backup locations for critical files and client records
- draft Response and Communication Plan messages
Quick check: confirm you can find contract terms, access delivery tools, and draft a client status update without digging through extra apps.
Step 3 Prepare the one-page working sheet#
Create one sheet with four columns: Critical Business Functions, owner, fallback method, and recovery target. Keep each row short and specific so you can use it during a tabletop exercise. If a row has no owner or no fallback method, treat it as incomplete.
Step 4 Keep filing checks open and include cross-border compliance files#
Keep IRS Form 8938 filing guidance open while you draft and test. If you operate cross-border, add a compliance subfolder now and include Form 8938 materials, relevant foreign account records, and FBAR references.
For U.S. filers, keep these distinctions visible:
- Form 8938 applies only when specified foreign financial assets exceed the applicable threshold.
- Thresholds vary by filing profile.
- Some financial accounts are excluded from Form 8938 reporting.
- Filing Form 8938 does not replace FinCEN Form 114 (FBAR) when FBAR is otherwise required.
- Form 8938 is attached to an income tax return.
- If no income tax return is required for the year, Form 8938 is not required.
With this prep complete, you can start the continuity session with evidence in reach and fewer avoidable decisions. For related tax continuity context, see Tax Compliance Anxiety: The Primary Pain Point for High-Earning Nomads.
Decide What Must Stay Running No Matter What#
This is where you decide what must keep running before disruption forces the call. Separate essential continuity work from work that can pause, and keep version one strict so it stays usable under pressure.
Step 1 Classify work by consequence#
Sort active responsibilities into two buckets: must run and can pause. Use one rule for every item: if pausing it would materially disrupt essential operations, put people at risk, or compromise critical assets, keep it in must run; if not, pause it.
Step 2 Rank Critical Business Functions in hard order#
Turn the must run list into a clear sequence based on impact. Put crisis communication and the functions that keep essential operations running at the top. Avoid ties so decisions stay fast when conditions are unstable.
Step 3 Set checkpoints and fallback triggers#
For each function, set one checkpoint question: can this continue or resume efficiently with current access and staffing? If not, switch to the predefined fallback. Assign an owner and backup for each trigger, and document the procedure so the switch does not stall.
Step 4 Keep BCP and DR scope distinct#
Keep the first draft concise: function, owner, checkpoint, trigger, and fallback. Keep the boundaries clear: the BCP covers continuity decisions across communication, people, partners, and critical assets, while the DR plan focuses on restoration.
Map Your Business Impact Analysis to Real Work#
Use your Business Impact Analysis (BIA) to turn priorities into execution. It is the point where planning moves from assumptions to documented decisions, with a broader view than IT restoration alone.
Step 1 Build one BIA line for each Critical Business Function#
Create one line per critical function. For each line, document the people, software, and third-party services required to deliver minimum acceptable service. Write it so someone else can quickly understand what must stay available.
Step 2 Define failure mode, impact, and minimum acceptable service#
For every line, add three short fields: failure mode, business impact, and minimum acceptable service. Keep each one concrete and operational. If minimum service is vague, tighten the function definition before moving on.
Step 3 Expose dependency weak points before they fail#
Flag concentration risks directly, even if they feel obvious. Then check for shared weak points across top-priority functions, since one outage can disrupt multiple commitments:
- single laptop
- single internet provider
- single payment rail
- single contractor holding key process knowledge
Step 4 Verify ownership and backup method on every line#
As a practical check, record an owner and a backup method on each line. Then run a quick handoff check: the backup should be able to explain the trigger, fallback action, and minimum acceptable service using only the document. If they cannot, revise the line.
Recent U.S. disaster losses have been cited at about $149.3 billion per year (2020-2024), which is a practical reminder to keep this section specific. A tight BIA helps keep critical operations prioritized and supports faster recovery decisions.
Run a Natural-Disaster Risk Assessment That Matches Your Location#
Build the Risk Assessment around local hazards, not a generic threat list, so each risk leads to a clear continuity decision. This helps keep your BIA usable during real disruption.
Keep your Risk Assessment draft, BIA, and BCP open together, then work line by line so each risk maps to a concrete response.
Step 1 Build the Risk Assessment around local events#
Create one row for each likely local event, then add operational effects that can interrupt delivery, such as power loss, connectivity issues, transport disruption, and loss of property access. Natural disasters and power outages are both common threat categories, so write each row as an interruption scenario.
For each row, map the event to one critical BIA function, define minimum acceptable service, assign one owner, and name one fallback action. Use a quick handoff check: if a backup contact cannot explain the trigger and fallback from the row alone, it is not complete.
Step 2 Contrast flood-heavy and wildfire-heavy scenarios#
Use scenario contrast so priorities match your location. The flood-heavy and wildfire-heavy rows below are example planning lenses, not fixed rules.
| Local profile | Example first continuity priority | First verification check |
|---|---|---|
| Flood-heavy | Keep remote access available during property access limits | Confirm you can send client updates and process billing from an alternate connection |
| Wildfire-heavy | Enable relocation with ready-to-go devices and essential records | Confirm essential files are available on relocation-ready devices before leaving site |
A common planning gap is funding only one side of this contrast. If your operating location changes seasonally, document which scenario takes priority for that period and update ownership.
Step 3 Fund and test highest-risk scenarios first#
Prioritize high-likelihood, high-impact scenarios for funding and testing first, since unprepared disruptions can cause financial and reputational damage. Recent reporting cited 24 weather events in 2024 with losses above the $1 billion threshold, reinforcing why this prioritization is practical.
Record each approved choice in the BCP with an owner, fallback method, and test date. Any high-priority scenario with funding but no test plan is still unresolved.
Set Backup and Recovery Requirements for Data and Money Flows#
Set recovery requirements by business function first so outages do not choose priorities for you. Define what must be restored first to keep critical operations and communication moving.
Step 1 Anchor recovery order to business functions#
Use your BIA, risk assessment, BCP, and DR plan together, then set restore order by outcome, not by tool. Start with the functions your BIA identifies as highest impact.
| Critical function | Restore first | Verification checkpoint |
|---|---|---|
| Revenue-critical operations | Core records and access needed to continue essential transactions | Complete one representative transaction from restored data |
| Core service delivery | Active work files and required operating documents | Complete one minimum service task from restored data |
| Stakeholder communication | Contact lists, message templates, and status notes | Send one outage update through a backup communication channel |
Your BCP should name function-level recovery order, and your DR plan should map technical restore steps to that same order. This keeps restore decisions tied to business impact instead of tool convenience.
Step 2 Define recovery objectives and fallback ownership#
Document fallback paths for critical functions before disruption starts. Include a clear description of the process, objectives, and outcomes for each path. For each path, name the trigger, owner, and where status updates are recorded. Define recovery objectives (RTO and RPO) for each critical function so teams know the recovery targets they are working against.
Track each critical recovery item with a short status record:
- item ID
- current state
- last update time
- owner and next action
Verification checkpoint: a backup person can execute one recovery task and record one status update using only the written steps. If they cannot, tighten the handoff notes before the next drill.
Step 3 Require recoverable records for handoff#
Maintain the records needed to verify restored operations and support handoff during an incident. Store current recovery records in a secondary location, and index those records in the BCP for faster handoff.
A failure mode to watch for is partial recovery: the app can come back while critical records remain incomplete, which can slow status updates and follow-up actions. If you cannot trace one sample critical workflow end-to-end using backup records, the evidence pack is not ready.
Step 4 Test restore speed and redesign weak backups#
Treat restore testing as a pass-or-fail gate. One cited survey reported that 80 percent of respondents had been hit by ransomware, 30 percent could not recover after a successful attack, and 18 percent of affected respondents did not recover within 48 hours. The same reporting described downtime as financially material, including a $9,000 per minute example and outages in the $100,000 to $1 million range.
Decision rule: if a backup cannot be restored and verified quickly in a test, treat it as non-existent and redesign it. A backup line with budget approval but no timed restore test is still an open risk, not a control.
Write a Response and Communication Plan Clients Will Trust#
Prewritten communication helps protect trust during disruption and supports recovery work. Write communication procedures in advance so updates stay consistent during and after an incident.
Step 1 Draft prewritten updates for defined checkpoints#
Create message templates for clients, vendors, and partners at checkpoints you define in advance. Each template should state what happened, what still works, what the recipient should do next, and when the next update will be sent.
| Checkpoint | Audience focus | Required elements |
|---|---|---|
| Initial update | Active clients and key vendors | Incident status, immediate impact, next update time |
| Follow-up update | Clients, vendors, partners | Confirmed recovery actions, temporary delivery path, owner contact |
| Stabilization update | All affected stakeholders | Stabilization status, revised milestones, scope or contract implications |
Verification checkpoint: have your backup contact send a simulated first notice from the template. If they need to improvise core details, tighten the template.
Step 2 Assign communication ownership in your Business Continuity Team#
Assign one primary sender and one backup sender, even if your team is very small. Record ownership, approved channels, and approval rights in your BCP and related disaster recovery procedures so role ambiguity does not delay updates.
Run a short handoff drill: primary unavailable, backup sends the first client message and logs send time. The notice should go out without rewrites or approval confusion.
Step 3 Define escalation rules before pressure spikes#
Set escalation rules that are specific enough to execute quickly. Include when to pause new work, when to renegotiate deadlines, and when to review contract terms if relevant.
- If minimum service cannot be met by the next checkpoint, pause new intake and notify affected clients first.
- If delivery dates are no longer credible, send a renegotiation option with a revised date and reduced-scope alternative.
- If contractual obligations may be affected, log the contract review step before changing commitments.
Step 4 Standardize evidence logging for Recovery Management#
Use one evidence-log format so every major decision, timestamp, and outbound notice is captured consistently. At minimum, track date and time with timezone, sender, audience, channel, message version, and acknowledgment status.
Verification checkpoint: after a drill, ask someone outside the exercise to reconstruct the communication timeline from the log in five minutes. If they cannot, simplify fields and tighten logging discipline.
Build Time-Phased Actions for 0-24 Hours, 24-72 Hours, and 3-30 Days#
Use these phase windows as planning targets, and adjust them to fit the incident. Focus first on protecting people, then maintaining minimum critical operations, then restoring full service quality. Keep continuity and recovery details accessible, since a continuity plan can contain critical information for recovery after natural, manmade, or technological disasters.
| Phase | Primary focus | Key actions |
|---|---|---|
| 0-24 hours | Protect people and restart minimum service | Confirm current operating status; send a clear status update to clients; log each critical function as active, degraded, or paused |
| 24-72 hours | Stabilize capacity and clear priority obligations | Shift to a repeatable daily routine; clear the most time-sensitive obligations first; keep a short continuity summary ready for emergency coordination if multiple businesses are affected |
| 3-30 days | Restore full quality and update the plan | Close temporary workarounds; restore normal service quality; document what worked and what failed |
0-24 hours protect people and restart minimum service#
Start with life and safety, confirm current operating status, and restart only the minimum service for your critical functions. Send a clear status update to clients using your prewritten communication flow, even if you are still assessing impact.
Log each critical function as active, degraded, or paused, and assign an owner and backup for each one.
24-72 hours stabilize capacity and clear priority obligations#
Shift from ad hoc actions to a repeatable daily routine, then clear the most time-sensitive obligations first. If multiple businesses are affected, keep a short continuity summary ready for emergency coordination. Fire departments are often first on scene during disasters, and continuity information in emergency pre-plans can help expedite recovery and set priorities when multiple businesses are affected.
3-30 days restore full quality and update the plan#
Close temporary workarounds, restore normal service quality, and document what worked and what failed. Update your continuity and recovery procedures while details are still fresh so the next response is faster and clearer.
If a phase target is missed, branch explicitly#
If a phase target is missed, make an explicit branch decision instead of waiting for perfect information. Options can include:
- Reduce scope when minimum quality cannot be maintained across active deliverables.
- Extend timelines when quality is still achievable but capacity is constrained.
- Outsource a constrained function when handoff risk is lower than delay risk.
Record the decision, owner, and client impact in your recovery log so later updates stay consistent.
Assign Ownership and Escalation for a One-Person or Tiny Team Business#
Clear ownership makes a continuity plan executable under pressure. Assign a primary owner and a backup owner in advance so authority does not depend on who is available in the moment.
Name the owner and backup#
Set one primary continuity owner and one backup, even in a one-person-plus-contractor setup. The primary leads continuity decisions; the backup takes over when the primary is unavailable.
Define decision rights in writing#
Document decision rights inside the plan so actions are clear during disruption. For example, specify who can:
- Approve emergency spending
- Pause client intake
- Authorize vendor changes
Avoid borrowed thresholds that do not match your business. If the primary cannot respond, the backup should act within documented authority and record the decision and client impact.
Link ownership to core artifacts#
Tie each owner to explicit update and approval duties in your core documents, such as:
| Artifact | Owner duty |
|---|---|
| BIA | Update dependencies and minimum service levels |
| Risk Assessment | Update hazards, impacts, and assumptions |
| Response and Communication Plan | Approve message flow and contact paths |
Validate with a focused escalation drill#
Run a short tabletop exercise to test authority transfer and escalation. If decisions stall, revise roles and rights first, then update the related plan artifacts in the same session.
A useful standard here is straightforward: plans should clearly communicate goals and required actions, stay flexible in real conditions, and treat planning relationships as important as the document itself.
Stress-Test the Plan in 60 Minutes with a Tabletop Exercise#
Run a short tabletop exercise after roles are assigned so you can evaluate whether your current response concepts, plan, and capabilities hold up in a plausible disruption. Keep the session timeboxed so the team stays focused.
Step 1 Build a focused scenario#
Use the Business Continuity Plan Situation Manual as your scenario base. Keep the scenario narrow enough to force real decisions instead of broad discussion.
Step 2 Facilitate with the official exercise guides#
Use the Business Continuity Plan Test Exercise Planner Instructions and the Business Continuity Plan Test Facilitator and Evaluator Handbook to run the session. Keep it discussion-based and nonthreatening so constraints and gaps surface clearly.
Note: the Business Continuity Planning Suite is no longer supported or downloadable, so rely on current guidance and your current plan documents.
Step 3 Test your chosen breakpoints#
Pressure-test the breakpoints that matter most for your scenario. For each one, require:
- A named owner
- A clear decision point
- A fallback action
If the team relies on unwritten assumptions, log that as a plan gap. Then assign an owner to close it.
Step 4 Close with outcomes and owners#
End with clear outcomes tied to actions. Record:
- What worked
- What failed
- Who owns each fix
- When each fix is due
Before you close, schedule the next tabletop exercise so the plan stays active instead of becoming shelf documentation. Put the date in the same log as your fixes. If you want related context, see A Freelancer's Guide to the US-Australia Tax Treaty.
Fix Common Mistakes Before They Become Expensive#
Costly continuity failures often come from decision gaps, not just missing paperwork.
- Mistake: treating disaster recovery as full continuity. Recovery focuses on restoring systems; continuity focuses on keeping client service moving while recovery is in progress. If service is still degraded, trigger client-facing actions with status updates, revised dates, and scoped alternatives.
- Mistake: overbuilding documentation and under-testing execution. Keep the core plan brief enough to use under pressure, then run tabletop drills and fix the exact step that slowed decisions.
- Mistake: letting compliance continuity break. Form 8938 is used to report specified foreign financial assets when the applicable threshold is exceeded, and when required it is attached to the annual income tax return. Thresholds vary by filer type, and filing Form 8938 does not remove a separate FinCEN Form 114 (FBAR) requirement when FBAR otherwise applies. If required records are inaccessible during disruption, treat that as a continuity failure.
After each drill or incident, update one page first: priorities, owners, and triggers. Then update supporting detail.
If your plan depends on one person, one tool, or one location, treat that dependency as a red flag and remove it before the next event.
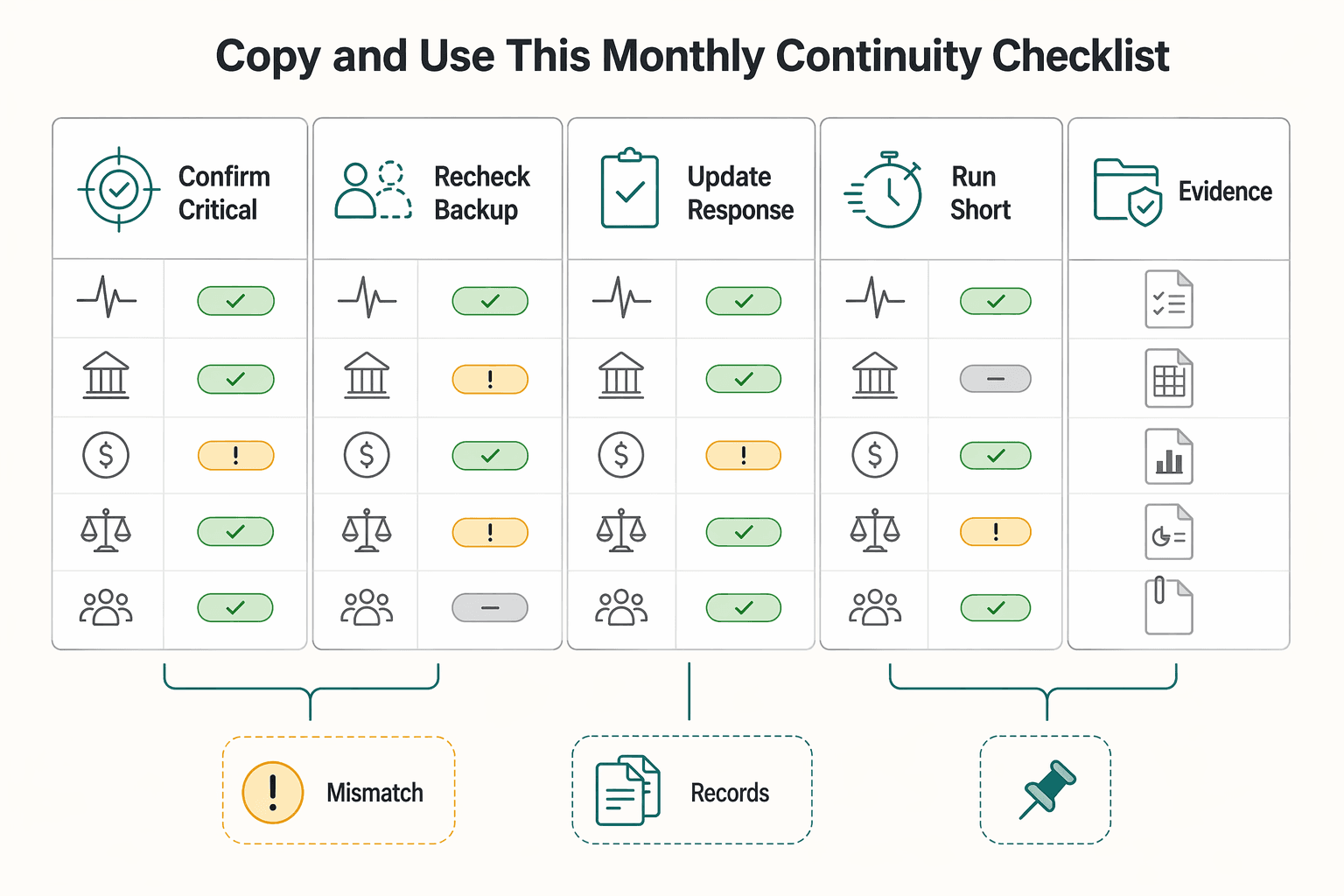
Copy and Use This Monthly Continuity Checklist#
Use this as a monthly maintenance check so your plan stays executable, not theoretical. Keep it short, update what changed, and log open actions.
| Monthly check | What to confirm |
|---|---|
| Confirm critical functions and owners | Top functions still match current obligations, cash flow needs, and legal duties; each function has a primary owner and a backup |
| Recheck backup and recovery with one real restore test | Run one live restore for a high-impact asset; record restore time and whether minimum service could resume in your target window |
| Update response and communication contacts and templates | Refresh client, vendor, and backup-owner contact paths; send one test message through your backup channel and confirm receipt |
| Run a short tabletop exercise and log actions | Use one plausible disruption scenario; focus on one known weak point; assign an owner and due date to each action from the exercise |
| Verify compliance and tax record access | Confirm access to records needed to determine whether Form 8938 reporting applies and treat Form 8938 and FinCEN Form 114 (FBAR) as separate filing obligations when both apply |
| Keep one current one-page BCP visible and shareable | Keep version date, priorities, owners, triggers, and first-hour actions on one page that is easy to open from primary and backup access points |
- Confirm critical functions and owners.
Make sure your top functions still match current obligations, cash flow needs, and legal duties. Confirm a primary owner and a backup for each function, with current contact details. If any function has no backup, treat it as a high-priority fix this month.
- Recheck backup and recovery with one real restore test.
Run one live restore for a high-impact asset and verify the restored data works in real use. Do not stop at "backup completed." Record restore time and whether minimum service could resume in your target window.
- Update response and communication contacts and templates.
Refresh client, vendor, and backup-owner contact paths, and update message templates to match current services and timelines. Send one test message through your backup channel and confirm receipt. Log timestamp and ownership in your recovery notes.
- Run a short tabletop exercise and log actions.
Use one plausible disruption scenario and test decisions, not theory. Focus on one known weak point, then assign an owner and due date to each action from the exercise. If decision authority is unclear, update your one-page BCP right away.
- Verify compliance and tax record access (including FBAR/Form 8938 materials, where relevant).
Confirm you can access records needed to determine whether Form 8938 reporting applies, including who owns that check and whether an income tax return is required for the year. Form 8938 reporting depends on applicable thresholds, and when required it is attached to the annual return and filed by that return's due date, including extensions. Also confirm your process treats Form 8938 and FinCEN Form 114 (FBAR) as separate filing obligations when both apply.
- Keep one current one-page BCP visible and shareable.
Keep version date, priorities, owners, triggers, and first-hour actions on one page that is easy to open from primary and backup access points. Ask your backup to run the first steps using only that page. If they need extra explanation, tighten the page before month-end.
If time is tight, complete all six checks at lighter depth rather than skipping categories.
Frequently Asked Questions
What is a business continuity plan for natural disasters in plain terms?
A business continuity plan is a predefined approach for how you keep operating during an emergency or interruption. The goal is to keep critical functions continuing or resuming during and after the event. In practice, it should be developed, tested, and kept ready before disruption starts.
What is the difference between a Business Continuity Plan (BCP) and a Disaster Recovery (DR) Plan?
A BCP explains how operations continue while disruption is happening. A DR plan explains how full functionality is restored after a system failure or compromise. Put simply: continuity keeps service moving; recovery returns systems to normal.
What are the first five steps a solo professional should take this week?
There is no universal, evidence-based first five-step sequence that fits every business. A practical starting checklist is to identify your critical functions, document team contact information, list the risks most likely in your location, assign backup coverage for important job functions and incident response tasks, and write continuity steps with recovery priorities and procedures. Then test that draft and keep it ready for use.
How often should I test my continuity plan with a Tabletop Exercise?
There is no universal legal testing frequency that applies to every business. Set a cadence that matches your disruption exposure and operational needs, then keep the plan in a tested, ready state. As one institutional example, some campuses conduct emergency practice drills twice a year.
What must be included in a natural-disaster continuity checklist?
At minimum, include team contact information and continuity steps that define recovery priorities and procedures. Add the risks most likely for your geography so the checklist reflects real exposure. Include backup coverage for important job functions and incident response tasks.
How long should I expect disruption to last after a major event?
There is no reliable fixed duration you can assume for every major event. Plan for continuity during disruption and for resumption after disruption, rather than a single timeline. Keep your plan ready to adapt as conditions change.
Who owns continuity planning if my business is just me and a contractor?
In many organizations, continuity ownership sits with the operational lead. If your business is just you and a contractor, that typically means you own the plan while documenting backup coverage for important functions and incident response tasks. Make both roles clear and familiar before an incident.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
- clame.nyu.edu/Resources/E0230H/311371/DisasterRecoveryAndB...trusted
- irs.gov/businesses/corporations/do-i-need-to-file-fo...trusted
- keiseruniversity.edu/business-continuity-vs-disaster-recoverytrusted
- ready.gov/business/emergency-plans/continuity-planningtrusted
- sba.gov/blog/seven-ways-start-your-business-continui...trusted
Educational content only. Not legal, tax, or financial advice.
Related Posts

Canada Digital Nomad Visa Planning for Visitor Status and Work Permits
The phrase `canada digital nomad visa` is useful for search, but misleading if you treat it like a legal category. It is shorthand for existing Canadian status options, mainly visitor status and work permit rules, not a standalone visa stream with its own fixed process. That difference is not just technical. It changes how you should plan the trip, describe your purpose at entry, and organize your records before you leave.

How High-Earning Nomads Reduce Tax Compliance Anxiety
For many nomads, a preventable risk is not exotic planning. It is letting filing and reporting fall behind while travel, contracts, and banking move faster than your records.

A Freelancer's Guide to the US-Australia Tax Treaty
If you freelance across borders, a defensible tax position is usually the fastest route to a clean filing. The order matters: lock down the facts, test the treaty treatment, then map the filings and relief choices. If you reverse that order, it is easy to optimize for an answer that falls apart once someone asks for support.