
Quick Answer
Default repeat payouts to local rails, and escalate to SWIFT only when corridor coverage is missing, proof requirements are higher, or risk is elevated. The practical rule is to decide at payout creation using destination, currency, required speed, and cost constraints, then store a route reason that finance can audit later. For wire cases, keep trace artifacts such as SWIFT references and use a separate exception path with clear ownership instead of ad hoc rerouting.
International wire vs local rails is a routing decision, not a preference#
Treat rail choice as product logic, not team habit. No rail wins everywhere. SWIFT and local payment rails solve different payout risks, so your job is to route each payout by destination, currency, speed, and cost, not by whichever option sounds more global or more modern.
| Field | How the article uses it |
|---|---|
| Destination | Choose the payout route by destination |
| Payout currency | Choose the payout route by currency |
| Required speed | Choose the payout route by speed |
| Cost constraints | Choose the payout route by cost |
| Route reason selected by policy | Record it so finance can explain the route later |
A payment rail is simply the network that moves digital money between payer and payee. At a practical level, ACH is a domestic rail for United States transactions, while SWIFT is the global messaging layer used for cross-border transfers. That does not make SWIFT the automatic answer for every international payout, and it does not make local rails the default for every corridor. The useful question is simpler: what risk are you trying to control on this payout?
If you run a marketplace, contractor, or creator program across multiple countries and currencies, you need one route for repeat volume and a clear exception path for payouts that do not fit. Local rails can be a strong starting point for recurring domestic payouts. SWIFT is the escalation path when the payout needs cross-border reach or when a local option is unavailable for the destination and currency. A workable starting policy is simple:
- Default recurring payouts to local bank transfer options where you have supported coverage.
- Escalate to SWIFT for edge cases where local coverage is missing or the payout is too important to leave to a vague fallback.
- Record the reason for the route choice at payout creation so finance can explain it later.
That last point matters more than teams expect. A defensible evidence trail should capture, at minimum, destination, payout currency, required speed, cost constraints, and the route reason selected by policy. If one of those fields is missing, you do not really have enough information to choose a rail with confidence. That is the first checkpoint worth enforcing in product before a payout ever reaches ops.
The common failure mode is not picking the wrong rail in the abstract. It is shipping one global default, then discovering that routine creator payouts, contractor batches, and one-off supplier settlements do not behave the same way across payment types, speeds, and geographies. Once that happens, engineering handles exceptions by hand, ops guesses at reroutes, and finance cannot defend why one payment used a local bank transfer while another went by SWIFT.
Set a default path for repeat payouts, define clear escalation rules for exceptions, and require evidence for every rail decision. The rest of this article turns that into a policy your team can ship and audit.
You might also find this useful: When to Use an Employer of Record for International Hiring.
Wires vs local rails at a glance for platform payouts#
For most platform payouts, start with local rails for repeat volume and use SWIFT as an exception path when cross-border reach or stronger wire-proof requirements drive the decision.
| Criteria | International wire transfer (SWIFT) | Local bank transfer (local rails) |
|---|---|---|
| Corridor reach | Built for international transfer messaging and often used when a local route is not available for the destination setup. | Best when your provider supports that destination through local payment rails; availability still depends on provider/program coverage. |
| Speed variability | Often more variable because wires can move through multiple intermediaries, with reported settlement commonly around 1 to 5 business days. | Often steadier for routine payouts when the flow stays on local banking paths and avoids correspondent-bank hops. |
| Fee predictability | Less predictable when intermediary/correspondent fees are added in transit. | Typically easier to forecast when fewer intermediary charges are involved. |
| Traceability | Can support formal wire tracing, but visibility can drop when correspondent banks sit in the middle. | Usually gives cleaner operational references for repeat support and reconciliation. |
| Failure handling | In-flight delays or shortfalls can be harder to explain when intermediaries are involved. | Exception handling is often more straightforward for repeat operational flows. |
| Compliance friction | Cross-border routing can add review and documentation friction. | Can be operationally simpler for routine disbursements, but some countries require certain authority payments to originate from local bank accounts. |
Blunt rule: routine repeat payouts usually start on local rails. Escalate to SWIFT when reach, proof needs, or payout certainty outweigh fee predictability and simpler local operations.
The key checkpoint is evidence quality, not marketing claims about the "fastest" rail. Before you launch, confirm for each corridor what trace or reference data finance will receive and whether intermediary deductions or delays can occur without advance visibility.
If your team cannot answer those two points in writing, the route decision is not yet defensible. That is usually where payout incidents become expensive.
If you want a deeper dive, read ACH vs. Wire Transfer for Contractor Payouts: Which Is Cheaper and When to Use Each.
Set your default routing policy before you ship payouts#
Set your routing policy before engineering builds payouts. Avoid hardcoded rail defaults that are not validated by your evidence for each corridor. If rail choice is left to case-by-case judgment, you get inconsistent behavior, weak audit records, and avoidable incident debates.
Use a routine path and an exception path, and make both explicit in product logic.
| Policy path | Use it for | Default route | What must be recorded |
|---|---|---|---|
| Routine payouts | Repeat creator, contractor, or marketplace disbursements with known beneficiary data | Your validated routine route | Selected route, reason code, timestamp, and any override note |
| Exception payouts | High-stakes one-off settlements, unusual vendor payments, or cases that do not fit routine criteria | Your validated exception route | Escalation trigger, approver, beneficiary details reviewed, and payout release record |
| Blocked or unresolved | Cases where required data or route eligibility is unclear | No payout released | Missing field, failed check, assigned owner, and next action |
Make your escalation triggers hard, not informal. If routine eligibility is missing, stop and move the payout into exception review. If finance requires stricter proof, enforce that requirement in policy instead of ad hoc chat decisions.
Keep routine and exception paths separate so finance, ops, and engineering can answer the same question later: why did this payout take this route? At minimum, store the chosen route, the trigger that selected it, who overrode it (if anyone), and when that happened. If that reason is not visible in your admin or export views, the policy is not ready to ship.
Do not rely on one global default. Write explicit market- or corridor-level policy for each launch scope, including default route, escalation triggers, exception owner, and logging location.
Related: Real-Time Payment Use Cases for Gig Platforms: When Instant Actually Matters.
Collect this minimum beneficiary data before rail selection#
Do not start rail selection until the beneficiary profile is complete for the route you plan to use. In cross-border flows, one payment can involve multiple rails in sequence, so missing or mismatched data early often turns into a return, retry, or exception later.
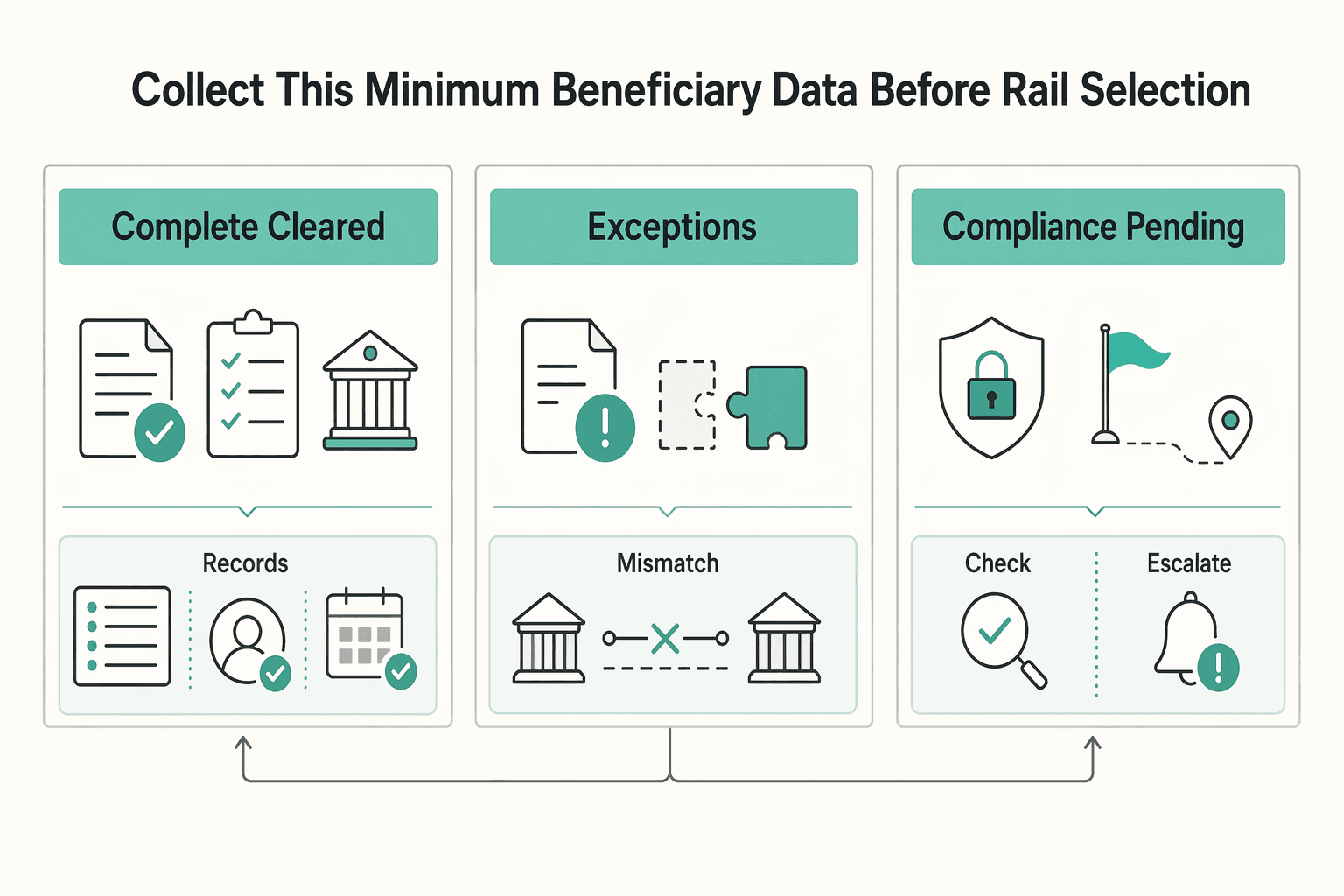
Keep the pre-routing gate small but strict: before you create the payout, confirm that the beneficiary record supports the planned route and payout setup. Treat route-format compatibility as a hard product check, not a manual cleanup step after queuing.
Apply the same standard to compliance status. If a record is still under review, expired, or otherwise not cleared, keep it out of payout creation and store the blocker reason in-system. If a sanctions-related authorization is part of the decision, keep the terms and validity window with the payout record, since authorizations can differ by purpose and expiration.
| Beneficiary state | Routing decision | What to store |
|---|---|---|
| Complete and cleared | Eligible for route selection | clearance status, review timestamp, route eligibility result |
| Incomplete or mismatched | Do not route | failed check, owner, next action |
| Compliance pending or expired | Do not route | blocker code, request/review timestamp, required follow-up |
A practical launch check is one pass case and one fail case per launch corridor, with the exact block reason visible in your admin view. The failure mode to avoid is silent override behavior: payout goes out, but the system cannot explain why an originally non-routable record was released.
Price the real landed cost, not the advertised transfer fee#
Price for landed outcome first: the right rail is usually the one that delivers a predictable amount with fewer exceptions, not the one with the lowest headline fee.
| Cost component | SWIFT | Local bank transfer | What finance should verify |
|---|---|---|---|
| Rail fee | Often explicit, but only one part of total cost | Often lower or bundled, depending on provider setup | Compare total provider debit, not just quoted send fee |
| FX spread exposure | Can shift total cost when conversion is involved | Still relevant when payout currency differs from source currency | Record applied FX rate and resulting beneficiary amount |
| Payout predictability | Can vary when intermediary handling is involved | Often more predictable on domestic-style routes | Check whether the beneficiary received the expected amount |
| Return/retry overhead | Exceptions can add tracing, rework, and delay | Rework may be simpler when route/data rules are clear | Track return reason, rework time, and whether a second payout was needed |
| Ops handling cost | More manual investigations when payouts arrive late or short | Lower when status flow is cleaner | Count manual touches, support tickets, and close-time exceptions |
Many teams misprice cross-border payouts by focusing on transfer fees alone. Real cost drag can come from exchange rates, transfer charges, and settlement delays, and advertised timelines may not include compliance checks, correspondent banking relationships, or weekend gaps.
Use predictability as a decision criterion, not just average cost. High-frequency, low-ticket flows often make local rails the better first option to test, while urgent or high-proof payments can still justify wire cost in specific cases.
Before finance signs off, run landed-cost tests in at least one corridor per launch region: one in the United States, one in Europe, and one in India. For each test, capture amount sent, total provider debit, amount received, and every manual touch or exception. If pricing is based only on quoted fees, the rail is not fully priced.
Define the evidence pack finance needs for tracing and close#
A payout is not close-ready until finance can trace it end to end: internal request, external proof, ledger posting, and clearly tagged unresolved items.
Use one evidence structure across rails, with rail-specific proof artifacts:
| Control point | Wire payout | Local rail payout | What finance should retain |
|---|---|---|---|
| External proof | SWIFT MT103 (when available) plus provider reference | Provider or bank reference | The exact external reference used for tracing |
| Internal audit trail | Request ID, status changes, timestamps, operator actions | Same | Immutable status history in the payout system |
| Reconciliation link | Request ID -> provider reference -> ledger posting -> export pack | Same | Export pack that shows each link in order |
| Exception handling | Trace request, pending investigation, returned/unresolved tag | Retry, return, or unresolved tag | Aged exception list with owner and next action |
At close, test reconciliation in both directions: ledger line back to payout request, and payout request forward to ledger line. If either direction breaks, the evidence pack is incomplete.
Keep tax and compliance outputs in the same record family. If your program generates Form 1099 outputs, tie them to payout-level identifiers. If you track FBAR or FEIE outputs, keep those tied to the same payout record and tax profile.
For FEIE, avoid assumptions: IRS guidance says taxpayers who qualify still file a return reporting income, and eligibility depends on facts such as a tax home in a foreign country and meeting tests like 330 full days in a 12-month period.
Set a written dispute policy with owner handoffs and escalation timing so payments ops and finance know exactly when unresolved items move to the next owner. For a wire-artifact refresher, see What is a SWIFT MT103 and How to Use It to Trace a Wire Transfer.
Plan for failure paths before they become incidents#
Define failure rules before incidents happen: fix and retry on the same local rail for data-quality errors, and escalate to SWIFT when the issue is corridor reach or coverage.
| Situation | Investigation step |
|---|---|
| Local rails (including Automated Clearing House-style flows) | Match outbound instruction to provider reference, then check inbound reject, return, or settlement events on that same reference |
| SWIFT payouts | Confirm traceable outbound references exist before labeling the payment missing |
| Inbound and outbound events do not join cleanly | Pause reprocessing until request ID, provider reference, and ledger entry are reconciled |
| Outbound exists but downstream events do not | Investigate status freshness before escalating |
That split matters because these rail families break in different places. Traditional cross-border payments rely on correspondent banking and SWIFT messaging, and intermediary chains can add delay, fees, and corridor-to-corridor variability. Non-bank transfer operators can bypass parts of that chain with local settlement accounts, which is one reason costs can be lower in high-volume corridors.
| Failure path | What it usually means | Preferred action | Verification detail |
|---|---|---|---|
| Beneficiary-name mismatch or local data-format reject | Instruction was not acceptable for that local rail or bank format | Correct the beneficiary data and retry the same local rail | Confirm the failed field, validate corrected format, and keep the same request ID linked to the retry |
| Coverage or reach failure on a local rail | The local route cannot complete this corridor or beneficiary type | Escalate to SWIFT instead of repeating local retries | Record the provider reason, confirm coverage is the blocker, and log why routing changed |
| Returned credit after apparent completion | Funds were sent, then returned or not accepted downstream | Mark unresolved, hold or reverse ledger treatment as needed, and avoid auto-resend | Match outbound provider reference to inbound return before any new send |
| Delayed settlement in correspondent chains | Payment may still be moving through intermediaries while internal status stays unchanged | Investigate and trace before treating as failed | Use request ID and provider reference to confirm where the payment is in the chain |
| Stale internal status assumption | Platform status no longer matches external state | Reconcile status before close and before retry | Confirm request ID, provider reference, external events, and ledger posting still align |
Treat blind retries as a control failure. Once an attempt has an external provider reference, do not issue a new send until the prior attempt is confirmed terminally failed or intentionally replaced. Keep one stable payout identifier for one payout intent, and anchor every retry decision to that record.
For investigations, use the same sequence every time:
- For local rails (including Automated Clearing House-style flows), match outbound instruction to provider reference, then check inbound reject, return, or settlement events on that same reference.
- For SWIFT payouts, confirm traceable outbound references exist before labeling the payment missing.
- If inbound and outbound events do not join cleanly, pause reprocessing until request ID, provider reference, and ledger entry are reconciled.
- If outbound exists but downstream events do not, investigate status freshness before escalating.
The operating rule is simple: repair local data issues locally, escalate true reach limits to SWIFT, and never let retries outrun traceability.
Related reading: How Independent Contractors Should Use Deel for International Payments, Records, and Compliance.
Roll out in phases with clear ownership across product, engineering, and finance#
Scale a corridor only when ownership and launch gates are explicit. Product should own routing policy, engineering should own execution traceability, and finance should own reconciliation and close-readiness. If rail exceptions do not have a clear approver, do not ramp traffic.
| Owner | Primary responsibility | Gate before ramp |
|---|---|---|
| Product | Routing policy | If rail exceptions do not have a clear approver, do not ramp traffic |
| Engineering | Execution traceability | Verify each payout can be traced from internal request to provider reference to ledger outcome |
| Finance | Reconciliation and close-readiness | Have finance confirm records are usable for close, not just operations review |
For the UK corridor, include compliance-record gates alongside delivery checks. HMRC says people who need to complete a tax return for the previous year must tell HMRC by 5 October, and sole-trader guidance says registration is required if earnings exceed £1,000 in a tax year. HMRC guidance also says to keep records such as bank statements or receipts, so your payout exports need to preserve those records in a usable form.
A practical rollout sequence is:
- Start with one corridor and a small traffic slice.
- Verify each payout can be traced from internal request to provider reference to ledger outcome.
- Have finance confirm records are usable for close, not just operations review.
- Expand traffic only after those checks pass.
For UK operations, confirm records are ready for filing on or after 6 April following the tax year, with payment due by 31 January. Use the same phased pattern for Europe and India, but do not assume UK checks transfer directly. Keep an internal rail decision log with corridor, selected rail, exception reason, and retained evidence so repeated exceptions can be resolved from policy, not re-debated each time.
Choose a default rail, then codify exceptions you can defend#
Default to local payment rails for repeat operational payouts, and escalate to an international wire transfer only when policy says reach, proof, or risk requires it. That gives you one standard path for volume and one exception path finance, ops, and engineering can defend.
Use a compact decision table so routing is explicit before money moves:
| Payout situation | Default rail | Why this default holds | Check before release |
|---|---|---|---|
| Repeat payouts in a supported corridor | Local payment rails | Keeps routine traffic on the operational default path | Validate corridor coverage, beneficiary data compatibility, currency support, and status visibility |
| Corridor or bank is not reliably supported on local rails | International wire transfer | Prioritizes reach when local routing is not dependable | Confirm receiving-bank compatibility, exception owner, and retained reference trail |
| Elevated operational or finance risk | International wire transfer | Applies the exception path deliberately, not ad hoc | Confirm approval policy, investigation owner, and required evidence pack |
The key control is corridor-level validation. Faster payment systems can move funds within seconds or a few hours, and newer rails are expanding options, but those category-level claims do not prove your exact route will perform as expected. Validate the corridor you are actually sending through, rather than assuming a rail type is always faster or more reliable.
If a local transfer fails, do not treat that alone as proof that wires are better. Usually, it proves that one route did not qualify. Before expanding coverage, lock three items first: your decision table, your finance evidence pack for exceptions, and your failure-path rules for block, investigate, and escalate states.
This pairs well with our guide on Why International Wire Transfers Arrive Short and How to Reduce Fee Leakage.
Frequently Asked Questions
Are local rails always cheaper than international wires?
No. Local payment rails can reduce cost in some corridors, especially when you can pay from an in-country account on domestic systems such as ACH or SEPA, but that is not universal. Compare total payout cost by corridor, including possible intermediary (correspondent) bank fees on wire routes.
When should a platform force SWIFT instead of a local transfer?
Use SWIFT when local-rail coverage is unavailable or unreliable for the corridor, or when wire-style trace documentation is required and the flow supports it. If repeated failures point to coverage or bank-compatibility limits rather than fixable data issues, escalating to a wire route may be more reliable than repeated retries on the same local path.
Is SWIFT always slower than local rails?
Not always, but it is more variable. SWIFT is a messaging network, not the movement of funds itself, and intermediary banks can add both delays and extra fees. Published timelines differ by source and route, so validate speed by corridor rather than assuming one fixed timeline.
What is the minimum beneficiary data required before payout routing?
This section does not establish a universal minimum beneficiary-data set. Required fields vary by rail, provider, corridor, and compliance context, so route only after validating the requirements for the specific path you plan to use.
What tracking proof should finance require for cross-border payouts?
Finance should require a traceable record that links the payout request, provider reference, status history, and final posting outcome. For wire flows, an MT103 can be useful when the flow supports it, but do not assume it exists for every payout type. If you need a refresher on the document itself, see What is a SWIFT MT103 and How to Use It to Trace a Wire Transfer.
How should we handle failed payouts without creating duplicates?
Treat retries as idempotent and avoid creating a second send before the first attempt is clearly resolved. If a failure is a fixable data issue, correct it and retry; if it is a coverage issue, switch rails only after reconciling the original attempt and reference.
Which regions should we test first before global rollout?
This section does not support a fixed rollout-region order. Prioritize corridors where you can validate rail coverage, traceability, and operational follow-through before scaling further.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
- comptroller.war.gov/portals/45/documents/fmr/volume_15.pdftrusted
- congress.gov/86/crecb/1960/05/03/GPO-CRECB-1960-pt7-9-1.pdftrusted
- dot.ca.gov/-/media/dot-media/programs/design/documents/...trusted
- ecfr.gov/current/title-15/subtitle-B/chapter-VII/subc...trusted
- federalregister.gov/documents/2022/09/30/2022-21020/beneficial-o...trusted
- federalreserve.gov/mediacenter/files/financial-inclusion-panel-...trusted
- fincen.gov/report-foreign-bank-and-financial-accountstrusted
- hbs.edu/ris/Publication%20Files/Du_Huang_Scharfstein...trusted
Educational content only. Not legal, tax, or financial advice.
Related Posts

How to Use a SWIFT MT103 to Trace a Delayed Wire Transfer
Start with `Field 20`, then verify the core details before you contact support. That gives your bank a usable trace anchor and helps you avoid delays caused by mismatched payment data.

ACH vs Wire Transfer for Contractor Payouts When Platform Teams Should Use Each
Use **ACH transfer** as the default for routine contractor payouts, and treat **Wire transfer** as a controlled exception. For most teams weighing ACH against wire, that one decision clears up more day-to-day confusion than starting with edge cases. If you need one rule your team can apply under deadline, start there.

When Instant Payout Matters for Gig Platform Payments
Instant payout is a tool, not the goal. The real operating decision is where instant timing creates measurable value, where batch timing is enough, and where both should run side by side.