
Quick Answer
Start by treating fraud as a pre-release payout decision, then map each check to one outcome: approve, hold, block, or review. Keep required gates such as KYC, KYB, AML, and W-8/W-9 deterministic in the rules engine, and use model scoring only for ambiguous patterns. For every action, log timestamp, reason code, actor, and case ID so overrides and replays stay traceable. Any signal that arrives after execution should stay in monitoring, not frontline prevention.
What a Fraud Detection Pipeline for Payouts Needs to Do#
Step 1 Frame payout fraud as a payout-time decision#
Treat payout fraud as a live decision problem first, not a reporting problem. If a control fires after the money has moved, you may still learn something useful, but you have not prevented the loss. That is the practical difference between payout-time prevention and post-event detection: batch processing may review activity hours or days later, while real-time checks act when risk appears and can still change the outcome.
A simple verification point helps. For any suspicious payout, ask: could this signal still change an approve, hold, block, or review decision before release? If not, it belongs in monitoring or investigation, not in your frontline control path.
Step 2 Split rules and AI by job, not by hype#
Set a clear job split early. Rules are useful for explicit payout-time actions such as velocity checks, fixed thresholds, and hard review triggers. AI earns its place where behavior is less obvious and the pattern is too subtle for static logic alone.
The common failure mode is straightforward: teams keep adding signals because they are available, not because they are practical. More data is not automatically better. Keep profile, device, behavior, and transaction inputs only when they can change a live decision or improve a reviewer's judgment without creating avoidable friction.
Step 3 Lock ownership and evidence before tuning#
Before you debate threshold tweaks, pin down who owns each payout decision, who can override it, and what evidence must be captured. That record should let your team explain why a payout was approved, held, blocked, or sent to review, and what evidence supported that decision.
That checkpoint sets up the rest of the article: map states, bucket signals, define rule outcomes, and require override evidence before you tune anything else.
What to prepare before you design controls#
Do this prep before you write any rule logic. Your target output is a pre-code architecture document with four artifacts, so your controls start from evidence and decision timing instead of guesswork.
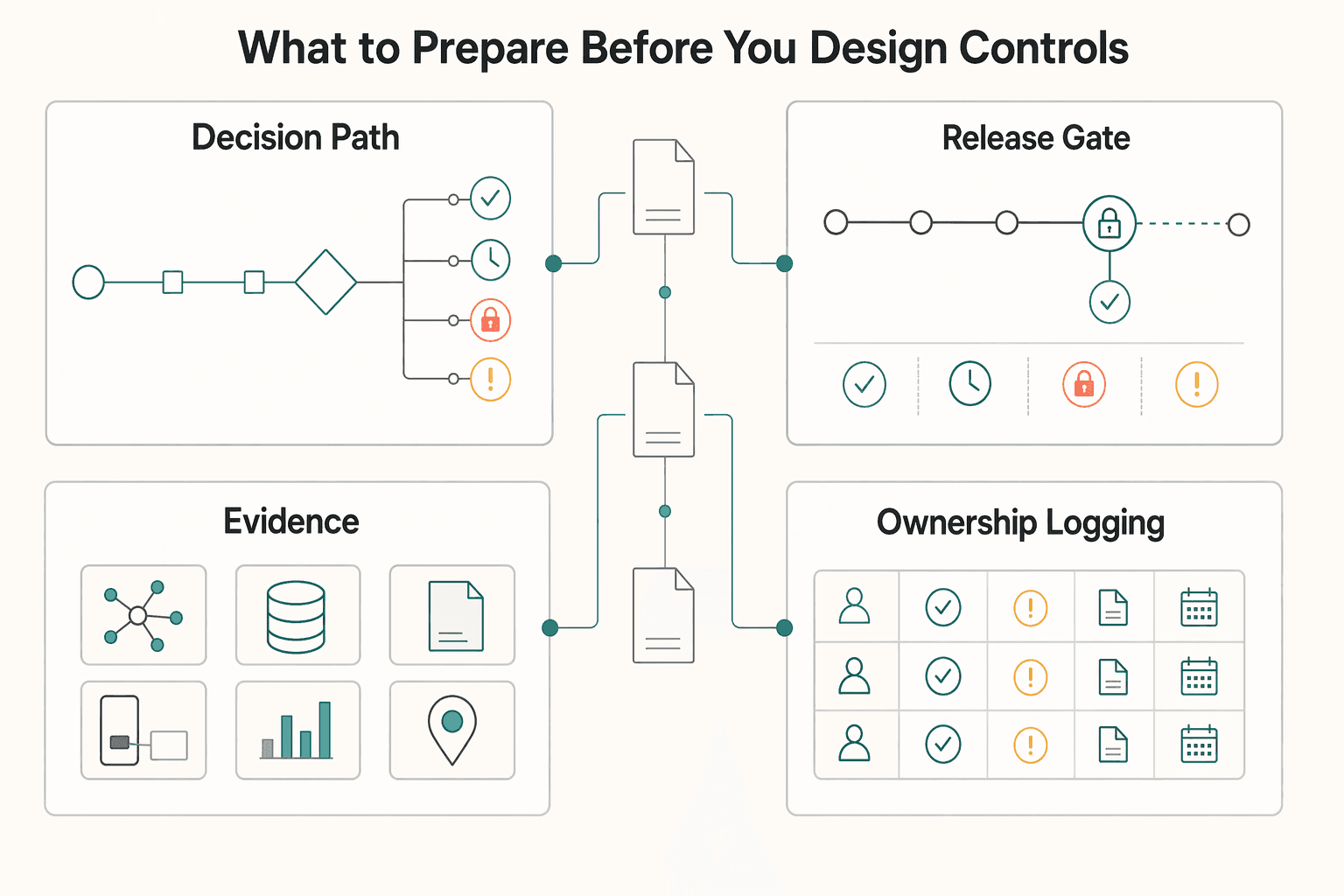
| Artifact | Include | Purpose |
|---|---|---|
| Decision-path snapshot | Request entry point, last point where you can still intervene, and data available at decision time | Separates frontline prevention from monitoring or investigation |
| Baseline evidence pack | Declined transactions, clustered decline patterns, comparison with confirmed fraud cases, BIN/IP/device clusters, false-positive behavior, and manual review queue health | Creates a true before-state for later measurement |
| Policy-gate matrix | Non-bypassable gates, advisory signals, KYC, KYB, AML, tax-document workflows, and a jurisdiction-specific placeholder | Keeps program requirements separate from advisory checks |
| Ownership and logging plan | Owners across Risk, Compliance, Ops, and Engineering, plus timestamp, reason code, actor, linked case ID, and idempotent retry/replay handling | Supports override decisions, queue handling, SLA adherence, and manageable rule growth |
Step 1. Create a decision-path snapshot for each payout rail. For each rail you use, capture the request entry point, the last point where you can still intervene, and the data that is actually available at decision time. Use one clear checkpoint: can this signal still change approve, hold, block, or review before release? If not, treat it as monitoring or investigation input, not frontline prevention.
Step 2. Build a baseline evidence pack before tuning. Export declined transactions, cluster decline patterns, and compare those declines against confirmed fraud cases. Add clustering by BIN, IP range, and device fingerprint where available, and document false-positive behavior alongside manual review queue health. Record weaknesses, projected loss, and missed patterns so you have a true before-state for later measurement.
Step 3. Separate mandatory policy gates from advisory checks. Build a simple decision matrix with two columns: non-bypassable gates and advisory signals. Place checks like KYC, KYB, AML, and tax-document workflows (for example W-8/W-9) in the matrix based on your program requirements, then add a placeholder row for jurisdiction-specific requirements marked "verify with Compliance or counsel before launch."
Step 4. Assign ownership and decision logging up front. Define clear owners across Risk, Compliance, Ops, and Engineering for override decisions, queue handling, SLA adherence, and instrumentation. Require each approve, hold, block, and override outcome to log timestamp, reason code, actor, and linked case ID, with idempotent handling for retries/replays. This keeps rule growth manageable and helps you avoid the common failure mode where large rule sets increase friction and flag more legitimate payouts.
If you want a parallel read on where model-based scoring fits after this prep, see AI-Powered Fraud Detection for Subscription Platforms: Beyond Rules-Based Approaches. With these four artifacts in place, you can move directly into mapping the live decision path and ownership by state transition in the next section.
If you want a deeper dive, read Velocity Checks for Payment Platforms: How to Cap Payout Frequency and Amount to Prevent Fraud.
Map your payout decision path and ownership#
Map the payout path so each transition has one clear owner and one clear evidence record, and make sure prevention happens before execution, not after.
Step 1. Draw the path as decision states. Use operational states, not tool names: request received, signal enrichment, Real-Time Risk Scoring, decision, payout execution, and Audit Trail retention. If a signal arrives after execution, it is monitoring data, not a real-time prevention control.
| State | Named owner for transition | Evidence produced |
|---|---|---|
| Request received | Ops or platform owner | Request timestamp, payout ID, source surface |
| Signal enrichment | Engineering owner | Input sources used, lookup success/failure, enrichment timestamp |
| Real-Time Risk Scoring | Risk owner | Score or risk tier, triggered signals, model/rule version |
| Decision | Risk or Compliance approver | Approve, hold, block, or review decision with reason code |
| Payout execution | Payments or Ops owner | Release timestamp, rail used, execution result |
| Audit Trail retention | Compliance or data owner | Decision log location, retention confirmation, record completeness check |
Step 2. Assign override ownership in the Escalation Workflow. Define who can release a hold, reverse a block, or escalate to review, and log reviewer identity, timestamp, case note, and reason code for every override.
Step 3. Define required evidence per state. Treat evidence as part of the control path, not a reporting add-on. Each state should emit at least one retrievable artifact. When you use signals like impossible travel (for example, activity from New York at 2:00 PM and London at 2:05 PM), record whether the signal arrived in time to affect the live decision.
Step 4. Simplify flows that cannot be run consistently. A shorter path with complete ownership and evidence is stronger than a complex path with unclear accountability. In decision windows that are very tight (often around 100-200 milliseconds), late checks should not be treated as payout-time blockers.
This pairs well with our guide on Beneficial Ownership Verification for Platforms and UBO Rules That Control B2B Payout Risk.
If you need a quick next step, browse Gruv tools.
Choose real-time signals that change payout decisions#
Use only signals that arrive before payout execution and can change a live outcome: approve, hold, block, or review. If a signal lands after release, keep it in monitoring and tuning, not payout-time prevention.
Step 1. Rank signals by payout-time decision value#
First question: Can this signal arrive in time? Real-time systems may need decisions in milliseconds, and some flows can clear in a few hundred milliseconds, so timing is a control boundary.
Start with four practical signal groups, then map each one to explicit payout actions:
| Signal group | What it can tell you at payout time | Default action role |
|---|---|---|
| Device Fingerprint | Whether the request comes from a familiar or novel device | Usually supports approve/review via scoring; hold when risk is elevated |
| Identity Signals | Whether identity or profile data is consistent with known records | Supports approve when aligned; hold/block when a policy gate fails or material inconsistency appears |
| Transaction Context | Whether amount, timing, frequency, or sequence departs from baseline behavior | Common hold/review trigger; can support approve when behavior is normal |
| Location Anomalies | Whether location behavior is unfamiliar or contradictory | Usually review/hold; block only when explicitly promoted after testing |
Quick action map: Device data usually maps to approve/review. Identity data can map to approve/hold/block. Transaction context often maps to hold/review. Location signals usually map to review/hold, unless you have promoted a narrow high-confidence pattern to block.
Verification check: sample recent decisions and confirm each signal timestamp is earlier than payout execution in the decision log. If you cannot prove ordering, that signal did not affect the live decision.
Step 2. Put every signal into an action bucket#
Second question: What action can it trigger? Keep decision rights explicit so signals do not drift into inconsistent enforcement.
- Policy-gate signals
These can enforce hard stops. Use them for required pre-payout conditions; if they fail, hold or block based on written policy.
- Risk signals
These can influence scoring, approve confidence, or review routing. They should not hard-block on their own unless explicitly promoted after testing, logging, and sign-off, consistent with your rules and machine learning decision design.
- Monitoring-only signals
Use these when inputs are late, noisy, unstable, or weakly sourced. They still help anomaly detection and tuning, but not payout-time intervention.
Threshold-triggered automation is useful only when you define which signals are allowed to move from observation into enforcement.
Step 3. Set a trust contract for source freshness and reliability#
Third question: How reliable is it right now? Real-time fraud decisioning is always under uncertainty, so each source needs a simple trust contract before production use.
Record this minimum contract per source:
- Source name
- Request timestamp
- Result timestamp
- Confidence state or returned status
- Fallback path if the source fails
- Decision-threshold note: verify any threshold against current source records, risk policy, and approved operating rules before use.
Make fallback behavior explicit: continue with reduced confidence, route to review, or demote the source to monitoring-only. Treat stale or unknown-confidence results as weaker evidence than fresh, confirmed results.
Watch for review pileup as a tuning trigger. When ambiguous signals accumulate, demote weak inputs to monitoring-only, keep high-confidence signals that change outcomes, and re-check decision-log completeness before expanding coverage. Alerts should trigger investigation, but not every alert should trigger a payout-time stop.
If rail timing is part of the issue, keep the decision window tied to payout method in FedNow vs. RTP: What Real-Time Payment Rails Mean for Gig Platforms and Contractor Payouts.
Related: Adverse Media Screening for Contractors on Real-Time Payment Platforms.
Set rules engine actions with clear hold block review thresholds#
Start with a small action set, then force every rule to map to exactly one outcome: approve, hold, block, or escalate to review. A fraud rules engine works by applying predefined logic and risk parameters in real time, so each action needs a clear reason code that teams can trace.
Step 1. Assign one action and one reason code to every rule#
A rule should not end at "high risk." It should state what happens next.
| Action | Use when | Minimum record to emit | Reviewer expectation |
|---|---|---|---|
| Approve | Risk evidence stays below your intervention threshold | decision timestamp, action, reason code, key signals used | Usually no manual touch unless later investigation is needed |
| Hold | A required verification gate is incomplete or unresolved | decision timestamp, action, reason code, unresolved check | Reviewer confirms the requirement before release |
| Block | Evidence is strong enough that payout should not proceed | decision timestamp, action, reason code, triggering rule IDs, supporting signals | Reviewer validates closure or follow-up investigation path |
| Escalate to review | Signals conflict or confidence is mixed | decision timestamp, action, reason code, routed queue, evidence snapshot | Reviewer documents whether to release, continue hold, or block |
Keep early logic blunt: if a required gate is unresolved, hold; if evidence is high-confidence and clearly adverse, block; if evidence is suspicious but not decisive, review.
Step 2. Separate policy gates from risk scoring#
Keep required gates out of the score so mandatory checks do not get diluted by weighted signals. Then build score rules with a clear hierarchy by transaction type or value band, including a maximum acceptable fraud-loss level and a target false-positive rate.
This prevents overreaction at the low end and underreaction at the high end. A £10 transaction and a £5,000 payout should not receive the same scrutiny. Track false-positive rate directly as the share of legitimate declines out of total declines, because over-cautious controls can cut revenue and flood review queues.
Step 3. Emit structured records and audit outcomes before retuning rules#
Every automated action should write a structured audit trail record: request or payout ID, decision timestamp, final action, reason code, triggering rules, and signal timestamps. Retries should produce one coherent decision history, not conflicting outcomes.
Before rewriting rules or buying new tooling, run a gap audit for a week or more. Export declined transactions, group by decline reason, compare those groups against confirmed fraud cases, and check gateway logs for decline clusters by BIN, IP range, or device fingerprint. Use those results to tighten thresholds deliberately, since static rules alone can struggle as threats evolve.
Related: Payment Status Visibility: How Real-Time Payout Tracking Reduces Support Load.
Decide where AI adds value and where rules stay mandatory#
Make this split non-negotiable: mandatory policy and compliance gates stay deterministic in the rules engine, and model output never releases a payout when a required gate is unresolved. Keep the same approve, hold, block, and escalate actions from the last section so this runs as one system, not two competing paths.
| Component | Primary role | Boundary |
|---|---|---|
| Mandatory gates | Rules engine enforces required pre-settlement verification and required checks before money moves | A model should not convert an incomplete or failed gate to approve |
| Model output | Produces risk scores or tiers for pattern drift, ambiguous behavior changes, and fast-moving typologies | Not final release authority; keep performance claims neutral until verified on your traffic |
| Rules | Assign final action using approve, hold, block, and escalate actions | Keeps the process as one system, not two competing paths |
| Reviewers and owners | Document overrides and review override clusters before widening model authority | Prevents advisory scores from becoming release signals without enough traceability |
Step 1. Keep mandatory gates deterministic#
Use the rules engine for pre-settlement verification and any required check that must pass before money moves. Automation should implement obligations, not override them. If a gate is incomplete or failed, the model can add context, but it should not convert that outcome to approve.
Before production, validate gate integrity with a short checklist:
- Build missing-gate test cases for each mandatory check and confirm they always route to the expected action and reason code.
- Require a specific unresolved-gate reason code, not a vague label like "high risk."
- Confirm the audit trace links request ID, decision timestamp, triggering rule ID, model score or tier, and final action in one coherent record.
- Re-run the same missing-gate cases and verify replay consistency, so outcomes do not drift between hold, review, and approve.
Step 2. Put models in the gray zone#
Use models where static logic loses coverage: pattern drift, ambiguous behavior changes, and fast-moving fraud typologies that simple if-then rules miss. Rule-based checks still work well for predefined business logic in real time. The warning signs are familiar: rule sets expand into hundreds or thousands of conditions, legitimate payouts are flagged too often, and adaptation to new patterns can lag by days or weeks.
In this zone, the model should produce risk scores or tiers, not final release authority. Keep performance claims neutral until observed lift is verified against current platform data and model evaluation records.
Step 3. Formalize handoff and override control#
Keep handoff explicit: model outputs risk tier, rules assign final action, reviewers document overrides, and owners review override clusters before widening model authority. This keeps accountability clear when a payout decision is challenged.
Tune with evidence, not intuition. Export declined transactions, group by decline reason in a spreadsheet, and compare with confirmed fraud and override outcomes. If overrides cluster in one score band or reason code, do not expand model authority yet; fix thresholds, retrain, or tighten gate logic first.
Authority creep is the failure mode to prevent: advisory scores gradually become release signals without enough traceability. For a deeper implementation view, see Fraud Detection on Payment Platforms with Rules and Machine Learning.
Related reading: How EdTech Platforms Pay Tutors: Tax and Payout Architecture.
Build review operations and escalation evidence#
Run review as a tiered escalation flow, not one backlog. Fraud can move in quick succession, and delayed batch-style handling can surface issues hours or even days later, after losses are already realized.
Step 1 Define tiers by action speed and risk#
Set a fast first pass for immediate screening, then route flagged cases to deeper analysis, with human-in-the-loop review reserved for higher-risk or higher-value alerts. This keeps routine decisions moving while protecting time for the cases that can change outcomes.
Step 2 Escalate consistently and document the path#
Use consistent escalation criteria so similar alerts get similar handling across reviewers and shifts. The goal is calibrated control: reduce missed fraud without flooding operations with false positives that add friction and manual load.
Step 3 Keep one case record that can be reused across teams#
For each escalated case, keep a single evidence trail from initial flag to final action so Risk, Ops, Finance, and Legal can review the same history without rework. Include what triggered the review, what was checked in follow-up analysis, and why the final release, hold, or block decision was made.
If a case includes tax-position claims (for example, FEIE), record the claim context and route tax interpretation to the appropriate finance or tax owner rather than deciding it inside fraud review.
Need the full breakdown? Read Transaction Monitoring for Platforms: How to Detect Fraud Without Blocking Legitimate Payments.
For a step-by-step walkthrough, see How to Build a Payout Network Without a Money Transmitter License for Platforms.
Measure performance and tune without breaking compliance#
Tune in small, provable steps. The goal is lower friction without increasing confirmed fraud or losing control of review operations.
| Tuning step | Requirement | Evidence |
|---|---|---|
| Weekly scorecard | Track fraud loss trend, False-Positive Rate, hold-to-release ratio, queue aging, and reversal outcomes with the same lookback window, payout rails, and decision segments each week | One weekly scorecard across fraud and operations |
| Isolated changes | Change one rule family or one model feature set per cycle, then compare pre- and post-impact on fraud outcomes and payout latency | Pre- and post-change comparison per cycle |
| Promotion gates | Confirm no regression on deterministic policy rules, no gaps in the Audit Trail, and no unmanaged queue or review-volume growth | Sampled case checks across approve, hold, block, and override paths |
| Rollback and sign-off | If false positives drop but confirmed fraud rises, roll back first, then document owner, date, affected control set, expected outcome, comparison window, observed impact, compliance review, and rollback decision | Documented change log with accountable sign-off |
Step 1 Track a balanced scorecard every week#
Use one weekly scorecard across fraud and operations: fraud loss trend, False-Positive Rate, hold-to-release ratio, queue aging, and reversal outcomes. A single metric can improve while overall outcomes get worse.
Keep comparisons consistent by using the same lookback window, payout rails, and decision segments each week. This helps you separate true performance changes from shifts in traffic mix or decision timing.
Step 2 Change one control family at a time#
Change one rule family or one model feature set per cycle, then compare pre- and post-impact on fraud outcomes and payout latency. If multiple controls move together, you lose causal clarity.
Keep each cycle narrow and explainable. In fraud detection, class imbalance, concept drift, and delayed ground-truth labels make tuning noisy, so isolated changes are easier to defend, monitor, and reverse.
Step 3 Verify promotion gates before release#
Before promoting any tuning change, confirm:
- no regression on deterministic policy rules
- no gaps in the Audit Trail
- no unmanaged queue or review-volume growth
Use sampled case checks, not dashboard-only review. Validate approve, hold, block, and override paths, and confirm each record still carries the required decision fields and decision-time rule or model outputs.
Step 4 Roll back fast and document intent#
If false positives drop but confirmed fraud rises, roll back first, then tighten high-risk segments before expanding controls more broadly. Missed fraud can be more damaging than extra alerts, so protect that side of the tradeoff.
Document every change with accountable sign-off: owner, date, affected control set, expected outcome, comparison window, observed impact, compliance review, and rollback decision.
We covered this in detail in Device Fingerprinting Fraud Detection Platforms for Payment Risk Teams.
Conclusion and copy-paste launch checklist#
If you are close to launch, the real test is simple: can you show what gets checked, who owns the decision, what evidence is produced, and how you will catch drift after go-live? If any item below has no named owner or no verification artifact, treat that as a launch blocker, not a paperwork gap.
Step 1: Confirm scope before you argue about model quality. List the channels, programs, and markets in scope, then log the constraints that change decisioning in each one. Separate mandatory gates from advisory signals. The check here is not whether the list exists, but whether Risk, Ops, and Engineering all point to the same version. A common failure mode is fragmented decisioning, where one team treats a gate as mandatory and another treats it as score input.
Step 2: Lock deterministic rules, adaptive model logic, and decision-threshold ownership. You want explicit action logic with clear ownership for each path, not implied behavior spread across services and analyst habits. For launch readiness, verify that each required control is implemented as a rule, threshold policy, or review gate, and that overrides have a named owner. If mixed signals or stale inputs can still trigger irreversible automated actions, tighten that before launch.
Step 3: Prove your decision trail works on real cases, not just in diagrams. Spot-check recent approve, hold, block, and manual review outcomes and confirm that each action writes a decision record with enough context to explain who acted, why, and when. Also verify that case-management handoffs and decision sources can be traced end to end. The red flag is a record that shows only the final outcome with no clear decision path.
Step 4: Test operations under pressure, not just happy-path routing. Your Manual Review Queue, Escalation Workflow, and orchestration path should be exercised before launch with realistic edge cases such as conflicting risk signals or repeated anomalies. The checkpoint is whether reviewers know what evidence they must add and where an unresolved case goes next. If escalation depends on tribal knowledge or one unavailable person, you do not have an operating model yet.
Step 5: Capture a baseline and schedule empirical tuning discipline from day one. Record your starting precision-recall tradeoff before you change rules, thresholds, or model influence. Then set a fixed post-change verification cadence and run empirical comparisons of adaptive learning strategies on fresh data. That matters because fraud data is hard in practice: events are rare, verified feedback is often delayed, and concept drift is real. If a change lowers friction but increases confirmed fraud or unexplained queue pressure, roll it back and retest the narrower segment that moved.
Copy this checklist into your launch review doc and require a named owner plus a verification note for every line. That is what turns a control design into something you can defend in production.
Related reading: Account Takeover in Payout Platforms and How to Stop Payee Hijacks.
Frequently Asked Questions
What is a fraud detection pipeline for payout platforms in plain terms?
It is the decision path from payout request to approve, hold, block, or review before funds leave. In practice, a rules engine checks transactions against predefined business logic and risk parameters in real time. If a check runs only after execution, it may still help investigation, but it usually cannot prevent that payout.
Which real-time signals are most useful when payout timing is tight?
Use signals that arrive in time to change the live decision, not signals that look interesting only after the fact. Card BIN, IP range, and device fingerprint patterns can all help, but only if they map to a clear action. If a signal cannot reliably drive approve, hold, block, or review within your decision window, keep it monitoring-only.
How should teams decide between hold, block, and manual review?
Route by consequence and confidence, not by a generic score alone. Use blocks for explicit hard-stop conditions, holds where more evidence can resolve risk quickly, and manual review for ambiguous cases that need context. Review thresholds regularly and test against false-positive rate and confirmed fraud trends together. The goal is risk management, not blocking everything suspicious.
When should a rules engine stay primary instead of handing off to AI?
Keep rules primary for explicit policy checks, known bad patterns, and actions that must be deterministic and explainable. Use AI to score risk, spot subtle behavior changes, and prioritize borderline cases before money leaves the account. The red flag is letting a model silently replace hard rules that reviewers still need to understand.
What evidence should be ready before launch so decisions are audit-ready?
You should be able to explain why each approve, hold, block, or override happened without guessing intent. Before launch, document weaknesses, projected loss, and missed patterns, then verify records across all paths so the evidence can serve as both a business case artifact and a measurable baseline for improvement. Missing evidence makes tuning harder and can leave you more exposed when losses, chargebacks, support overhead, or reputational damage increase.
How do you know the controls are ready for production?
A good readiness check is small and concrete. Export declined transactions, group decline reasons, compare them with confirmed fraud cases, and inspect gateway logs for clustered patterns such as shared card BIN, IP range, or device fingerprint. Document each weakness, projected loss, and missed pattern so you have both a baseline for improvement and a clear business case for what goes live first.
Try a related tool
A former product manager at a major fintech company, Samuel has deep expertise in the global payments landscape. He analyzes financial tools and strategies to help freelancers maximize their earnings and minimize fees.
Sources
Includes 5 external sources outside the trusted-domain allowlist.
- pmc.ncbi.nlm.nih.gov/articles/PMC12102310trusted
- pmc.ncbi.nlm.nih.gov/articles/PMC12500087trusted
- sec.gov/files/ctf-written-input-daniel-bruno-corvelo...trusted
- al-kindipublishers.org/index.php/bjmss/article/download/12287/10971...external
- arxiv.org/html/2601.07276v2external
- conduktor.io/glossary/real-time-fraud-detection-with-stre...external
- confluent.io/blog/real-time-streaming-prevents-fraudexternal
- dl.acm.org/doi/10.1145/3794859external
Educational content only. Not legal, tax, or financial advice.
Related Posts

FedNow vs RTP for Gig Platform Contractor Payouts
You are not choosing a payments theory memo. You are choosing the institution-backed rail path your bank and provider can actually run for contractor payouts now: FedNow, RTP, or one first and the other after validation.

Real-Time Payout Tracking for Platforms That Reduces Support Load
Faster rails do not fix unclear payout state. Payout tracking matters when each payout can be followed from authorization through reconciliation, not when disbursement is merely faster.

AI Fraud Detection for Subscription Platforms Beyond Rules-Based Approaches
An **AI fraud detection subscription platform** is not just a model score. For a subscription business, it should help you manage fraud risk and compliance exposure across onboarding, recurring payments, and payouts or withdrawals. It should also give your risk, finance, legal, and compliance teams decisions they can defend.