
Quick Answer
Start with dunning management best practices that segment decline causes on Day 0, then route each account to retries or a billing-update action. Keep outreach staged and finite instead of extending reminders indefinitely. Define success as both recovered cash and operational stability by checking unresolved cases, support impact, and reconciliation alignment. This approach improves recovery odds while reducing avoidable churn risk and cleanup work.
Treat dunning as recovery control, not reminder copy#
Dunning in platform billing is a margin and control decision, not just a reminder-email sequence. It starts when a recurring payment fails, and what you do next affects recovery outcomes, customer response, and how much operational drag the issue creates.
Failed payments are a common source of preventable revenue loss in subscription businesses. They usually follow ordinary events like card declines, gateway errors, or insufficient funds. That is why Day 0 is more than a collections moment. At that point, product, finance, and revenue choices can shape whether you recover the charge, lose the subscription to involuntary churn, or add more support burden.
This guide is for teams that own that tradeoff end to end. Founders need to know whether recovery effort protects margin or just adds noise. Revenue leaders need to reduce churn risk without pushing customers toward cancellation. Product teams need update and retry paths that do not end in dead ends. In practice, a strong approach has three parts:
- Automation
Detect and handle failed recurring charges as they happen.
- Retries
Retries can recover some failures, but repeated retry and outreach cycles can become messy and poorly received.
- Follow-up messaging
Follow-up communication is a core part of dunning and should point clearly to the next customer action.
These parts should stay close to the checkpoints that matter most: invoice issuance as the first step, the failed payment event on Day 0, and final notice as the last step before escalation.
Keep one tradeoff in view from the start. Delayed escalation can lead to service impacts, while aggressive outreach can create customer and support friction. The practical goal is to reduce involuntary churn where possible, with controlled retries and clear action paths, while keeping operations manageable.
How to pick the right dunning strategy for your platform#
Pick your strategy from the shape of your failures and your operating constraints, not from email templates. Use these four filters before you change retry cadence or message copy.
| Filter | What to assess | Detail |
|---|---|---|
| Start with failure mix | Group failed payments by cause | Separate credit card declines, gateway errors, and insufficient funds, then match the action to the cause |
| Match effort to automation readiness | What the team can run consistently | Use automation, retries, and clear self-serve update flows as the baseline, then add manual follow-up where it meaningfully improves recovery |
| Be realistic about support capacity | Operational drag from exceptions | Track failed-payment volume alongside billing-related support contacts, and keep the flow lighter and more automated if the team cannot absorb repeated billing replies and follow-up |
| Define success beyond recovery alone | Broader outcome measures | Measure fewer unresolved failed payments, lower involuntary churn risk, and stable support load |
- Start with failure mix
Group failed payments by cause first: credit card declines, gateway errors, and insufficient funds. Then match the action to the cause. Payment-detail issues usually need a clear update path, while temporary declines may recover through retries and follow-up. A common failure mode is treating every failed payment the same, which can leave the root issue unresolved.
- Match effort to automation readiness
Align your approach with what your team can run consistently. Use automation, retries, and clear self-serve update flows as the baseline, then add manual follow-up where it meaningfully improves recovery. This keeps dunning from turning into a long, unwieldy process.
- Be realistic about support capacity
Dunning gets unwieldy when exceptions pile up in manual queues. If your team cannot absorb repeated billing replies and follow-up, keep the flow lighter and more automated. Track failed-payment volume alongside billing-related support contacts so you can see whether recovery gains are creating operational drag.
- Define success beyond recovery alone
A strong strategy is not just about collecting one missed payment. Measure outcomes across fewer unresolved failed payments, lower involuntary churn risk, and stable support load. The right choice improves recovery while keeping customer experience and operations workable.
Compare the seven best practices before implementation#
Use this comparison as an implementation tool, not a universal template. These practices carry different costs and risks, so prioritize them by your failure mix and support capacity.
| Practice | Best for | Key upside | Key downside | Required systems | Verification checkpoint |
|---|---|---|---|---|---|
| Segment failed payments by cause | Programs with mixed decline reasons | Better targeting and less reminder waste | Needs reliable decline categorization and branching | Failure-cause visibility and reporting | Review a sample of failed payments and confirm each followed the intended path |
| Automated payment retries | Programs where retries are part of recovery | Can recover payments without customer action | Treating all declines the same can reduce recovery | Retry scheduling and payment-state tracking | Compare retry attempts to recovered payments by decline type |
| Clear billing-update CTA | Accounts with expired cards or stale details | Reduces friction and speeds self-serve recovery | Vague or multi-purpose CTAs can cause inaction | Usable billing-update flow and clear message templates | Track update-click to completed update to successful payment |
| Branded reminder cadence | Teams where email is central to the cycle | Improves recognition and response consistency | Too many reminders can create fatigue and alienate customers | Reliable reminder delivery and recognizable sender identity | Monitor response quality as cadence increases |
| Escalation path beyond reminders | Cases where payment is still unresolved after reminders and retries | Preserves a path to more formal action when needed | Unclear escalation criteria can create inconsistent handling | Escalation criteria and clear ownership | Confirm unresolved cases move through escalation without gaps |
| Reconciliation-linked measurement | Teams that need defensible recovery reporting | Grounds recovery claims in reconciliation checks | Requires discipline during close and review | Reconciliation workflow and recovery-status tracking | Trace a missed invoice from detection to resolved or unresolved status during reconciliation |
| Benchmark with ranges, not absolutes | Teams setting recovery targets | Prevents overfitting to a single benchmark | Published involuntary-churn benchmarks can conflict across sources | Baseline churn and recovery reporting | Compare your outcomes against a range and adjust targets over time |
The biggest tradeoff is cadence. A common benchmark is 3 to 4 messages over 28 days, but that is a starting point, not a rule. Increase frequency only when segmentation and message quality support it.
Before rollout, verify outcomes in reconciliation, not only in dashboards. If you cannot follow a failed payment through reminder and retry activity to a confirmed final state, the setup is not ready to scale. For the finance side, see Controller-Grade Accounting Best Practices for Payment Platform Finance Ops.
If you want to pressure-test your retry logic and reconciliation checkpoints against an API workflow, review the Gruv docs.
Best practice one segment failed payments before outreach#
Segment failed payments by likely cause before outreach so each account starts on the right recovery path on Day 0. In subscription billing, many failures come from expired cards, insufficient funds, or bank-side authentication issues, and treating them all the same can weaken recovery.
| Likely cause | Recovery path | Message detail |
|---|---|---|
| Likely temporary issue | Run retries first | Keep messaging focused |
| Customer-action required | Ask for a new payment method | Send a clear billing-update action |
| Unclear cause | Send a neutral failed-payment notice | Still offer an update path |
After a failure, you usually have two practical paths: retry the current payment method or ask for a new one. A workable program uses both, because recovery is not only about retries.
Use a simple decision rule based on likely cause. A practical first-pass split is:
- Likely temporary issue: run retries first and keep messaging focused.
- Customer-action required: send a clear billing-update action.
- Unclear cause: send a neutral failed-payment notice that still offers an update path.
This can reduce billing-related support issues and premature cancellations. Track each case from failure to outcome so the path and result stay visible instead of sitting under a generic "failed payment" status.
As an operating check, sample failed payments regularly. Confirm the process started immediately after failure, the intended retry or update path was used, and each case reached a clear outcome. For a separate compliance perspective, see KYC Best Practices for Reducing Money Laundering Risks: A Payment Platform Compliance Guide.
Best practice two make retries safe and deterministic#
Make retries deterministic before you make them aggressive. Once you know whether an account belongs on a retry path or an update path, make sure each retry follows one clear route from trigger to closure.
As billing complexity grows, automation becomes a control requirement, especially when failed payments sit across systems that do not stay in sync. The practical win is control: fewer handoff errors, less rekeying, and faster cycle time.
What "deterministic" should mean for your team#
For your team, deterministic means the same trigger produces the same next step, status transition, and audit trail. Start with three controls:
- Assign each retry attempt a stable reference from creation to final state.
- Define explicit statuses, including unambiguous terminal states.
- Document who owns each step, when it runs, and which system handles it.
If your team cannot quickly answer "how many retries were attempted, which one succeeded, and what happens next," the flow is not deterministic yet.
Where execution usually breaks#
Execution usually breaks when failed payments, billing events, and finance records are handled across systems that do not stay aligned. That is where retry history drifts across product, support, and finance views and creates extra cleanup later.
A useful warning sign can appear earlier than teams expect. One founder reported invoice-to-usage alignment became unmanageable at 60 paying users. Retry and reconciliation issues can surface around that point or sooner.
Set clear controls and verify regularly#
Define clear transition points before launch so accounts do not loop through disconnected handoffs. If a retry path stalls, use a documented next step instead of an ad hoc fix.
Then review the workflow regularly from trigger through customer and finance outcomes. Treat mismatches as control issues to fix, not reporting noise.
Best practice three remove friction from the payment update path#
The strongest support for this section is not a dunning-specific UX claim. It is a control pattern: define what the payment update path includes, what it excludes, and who owns it.
When to simplify the update flow#
Use this approach when you are refining an existing flow and the real problem is unclear scope or ownership. In the material here, the strongest support is coordination and documentation across teams, not tooling claims or performance claims.
What to change#
If you simplify the flow, treat choices like a single primary action or a separate support route as local design decisions. Do not present them as proven best practices from these sources. Keep the work focused on clear scope, ownership, and status handling.
The document that keeps this from drifting#
Formal scope control matters here. The FM Solution/Service Definition Template (December 2025) is designed to define what is included and excluded, and the Service Provider-Service Customer service agreement documents components, resources, and responsibilities.
Use that structure to lock four basics in one place: what the user can update, what is intentionally excluded, who owns changes, and which record is authoritative.
Verification and red flags#
Before rollout, use the completed template to identify the applicable evaluation criteria and service measures. Treat the examples as assistive only, not as requirements. If your current flow is built from inherited examples and ownership is unclear, document scope and ownership first.
Need the full breakdown? Read Payment Webhooks Best Practices for Reliable Event Flows.
Best practice four escalate communication without sounding like collections#
Escalate in stages so urgency rises without tipping into collections language. If escalation stays too soft for too long, failed payments can remain unresolved and put subscriptions at risk.
When staged escalation fits best#
This works best for teams that need recovery and retention to work together, not compete. In subscription billing, expirations, declines, and billing errors can interrupt recurring charges. If they are not resolved quickly, active subscriptions are put at risk.
Respectful does not mean vague. Each notice should clearly explain what failed and what the customer should do next, then become more urgent if the issue remains unresolved. Use straightforward language and avoid jargon so customers can resolve the issue quickly.
A practical escalation ladder#
There is no single channel order that fits every platform. A practical pattern is to begin with a gentle reminder and increase urgency only if payment is still unresolved.
| Stage | Primary job | Operator detail |
|---|---|---|
| Initial reminder | Start with a gentle nudge and one clear action | Explain the issue in straightforward language and avoid jargon |
| Follow-up reminder | Increase urgency if the issue is still open | Keep the resolution step explicit and easy to complete |
| Escalated reminder | Add a more pressing message before account action | Reference agreed payment details (such as amount, service period, or due date) so the message feels legitimate rather than robotic |
Match cadence to account economics, not just communication preference. Self-serve accounts often require automated suspension within 10-14 days if unresolved. Relationship-driven enterprise accounts may operate with 60+ day grace periods and payment cycles around 45-65 days.
When escalation stops helping#
If repeated reminders are not resolving the issue, shift to a direct support or account-management conversation.
If most of this is still manual, prioritize automation early, since manual dunning is hard to sustain beyond roughly 50-100 customers.
Best practice five apply compliance gates with precision#
Apply compliance gates narrowly: gate the risky action, not every customer action by default. If KYC, KYB, or AML reviews touch your flow, document related decisions clearly so accountability stays visible.
When precise compliance gates matter#
This matters most in setups where account actions may be paused for review. The benefit is clearer accountability. The tradeoff is that broad or early gates can add operational friction and extra manual handling.
Automated billing already handles routine work like subscription billing, invoice payments, and repeated failed payments. When multiple decisions are bundled into one account-wide switch, a recoverable billing issue can turn into extra manual follow-up across teams.
What to gate and what not to bundle#
Scope each control to the action that creates the risk, and document that scope in your process. For billing recovery actions, follow your policy and keep decisions explicit rather than relying on one blanket hold state.
A practical pattern is to keep process steps clear and recorded so billing outcomes and review outcomes are not conflated. The core principle is precision: avoid tying billing logic and account-status logic to one blunt hold state.
Verification points that catch real mistakes#
Use simple checks that preserve accountability and record quality:
- Record each hold and release with clear decision notes so teams can trace what changed and why.
- Confirm the ledger remains accurate after recovery events and related status changes.
- Confirm one event does not silently clear a different hold state without an explicit decision.
These checks reduce status confusion between teams. Spreadsheet-heavy workflows are especially prone to error, so this is a high-value place to reduce manual handling.
Exception paths and manual overrides#
Define exception steps before queues build up. When records are incomplete, document who reviews and what decision notes are required. Structured process steps improve accountability and help reduce liability.
Keep overrides rare and visible. A manual release without clear documentation can become a reconciliation problem later. In practice, the standard is simple: keep decisions precise and leave a clear audit trail for exceptions. Related reading: Payout API Design Best Practices for a Reliable Disbursement Platform.
Best practice six tie dunning outcomes to ledger truth and month end close#
Tie each dunning outcome to close-ready records so finance can tell the difference between collected cash, customer action, and unresolved exceptions. If you cannot trace recovery claims in the records finance uses at close, reporting is hard to trust.
This matters most for finance operators who need recovery performance to hold up under reconciliation and review. A likely upside is cleaner reporting and fewer surprises at close. The tradeoff is discipline: teams need a shared rule for what each event means and how it should be counted.
Why this matters#
Failed payments can be material. Vendor-reported benchmarks treat the revenue at risk and the share of failures recovered as directional context, not a guarantee.
In B2B billing, failures are not only card issues. Invoice routing errors, missing purchase orders, approval delays, and reminders sent to unattended procurement inboxes can all break the collection flow. So outcome labels should reflect what actually happened, not just what looked promising in the timeline.
Keep event meanings explicit#
Use a simple event map so product, support, and finance classify outcomes the same way:
| Event type | What it proves | Reporting treatment |
|---|---|---|
| Failed payment | A collection attempt failed | Keep in active recovery tracking |
| Payment method update completed | Billing details were updated | Track as a progress signal, not recovered cash |
| Successful retry or payment completion | Funds were collected | Count as recovered revenue in finance reporting |
| Exception workflow resolution | A non-standard case was handled | Mark separately so it does not blur recovery performance |
| Close-period finance snapshot | What finance reviewed at close | Use as the control view for period reporting |
Verification checkpoint#
Run a small recurring sample and confirm customer-level events and close-period finance reporting tell the same story. Keep a lightweight evidence trail for each sample so review questions are easy to answer.
Also track Invoice Accuracy Rate and Invoice-to-Payment Time before and after process changes. If reported recovery rises without movement in those flow-quality metrics, you may be improving labels more than collections.
Best practice seven set stop rules and ownership before launch#
Set stop rules and ownership before launch so your dunning sequence ends in clear decisions, not cross-team gaps. Without this, retries can continue by habit, visibility can drop, and escalations can arrive without context.
This matters most when multiple teams touch the same account. The upside is faster decisions and less conflict. The cost is explicit governance: who decides, who measures, and what happens when the scheduled sequence ends without payment completion.
Treat the sequence as scheduled and finite#
Dunning works best as a scheduled sequence, not an open-ended follow-up loop. A practical flow is immediate notice after failure, then timed follow-ups, for example 2 days later and 5 days later, before a suspend-service decision. Some teams use intervals like 1 day, 3 days, and 7 days.
The key rule is to make stop points explicit. The evidence here does not support one universal retry-stop threshold, so avoid hard-coding a single number as a default best practice. Set stop logic by failure pattern and account value scoring, then move to the next action instead of extending the same retry path.
Also avoid treating a fixed 14-day window as automatically correct. The source material presents that as a debated operator viewpoint, not a universal standard.
Codify four triggers before launch#
Document these decisions before your first live sequence:
- When retries stop
Define the last automated retry and the next state, for example a payment-method update or manual review.
- When escalation starts
Define when you escalate beyond baseline reminders and which cohorts qualify.
- When manual ownership takes over
Hand off on clear conditions, such as customer response, exception handling, or outcome mismatch.
- When the sequence is exhausted
Define the next account state when the sequence ends without payment completion.
Use scoring to route treatment and ownership#
Use scoring as the routing mechanism for stop rules and escalations. Oracle's collections guidance frames scoring as foundational, and scoring can run at customer, account, bill-to, or delinquency level. That gives you a practical way to apply different treatment at the right operational level.
In practice, use higher-touch handling for higher-value or higher-priority delinquencies, and keep lower-value cases in automated paths when appropriate. This can help keep queues focused and reduce unnecessary escalations.
Make ownership explicit and test it weekly#
Choose an ownership split and write it down before launch. The exact split can vary by team, but each trigger should have one accountable owner, a handoff rule, and a measurable check.
Run a weekly sample of stopped or escalated accounts and confirm each case shows the trigger used, current owner, handoff timestamp, and final status aligned with reconciliation records. A common failure mode is accounts sitting between teams after the last automated contact. For a step-by-step walkthrough, see Key Best Practices for Improving Accounts Payable on a Two-Sided Payment Platform.
30 day implementation sequence for platform teams#
If you need this live in 30 days, keep the rollout narrow, rule-based, and measurable before you add more channels or complexity.
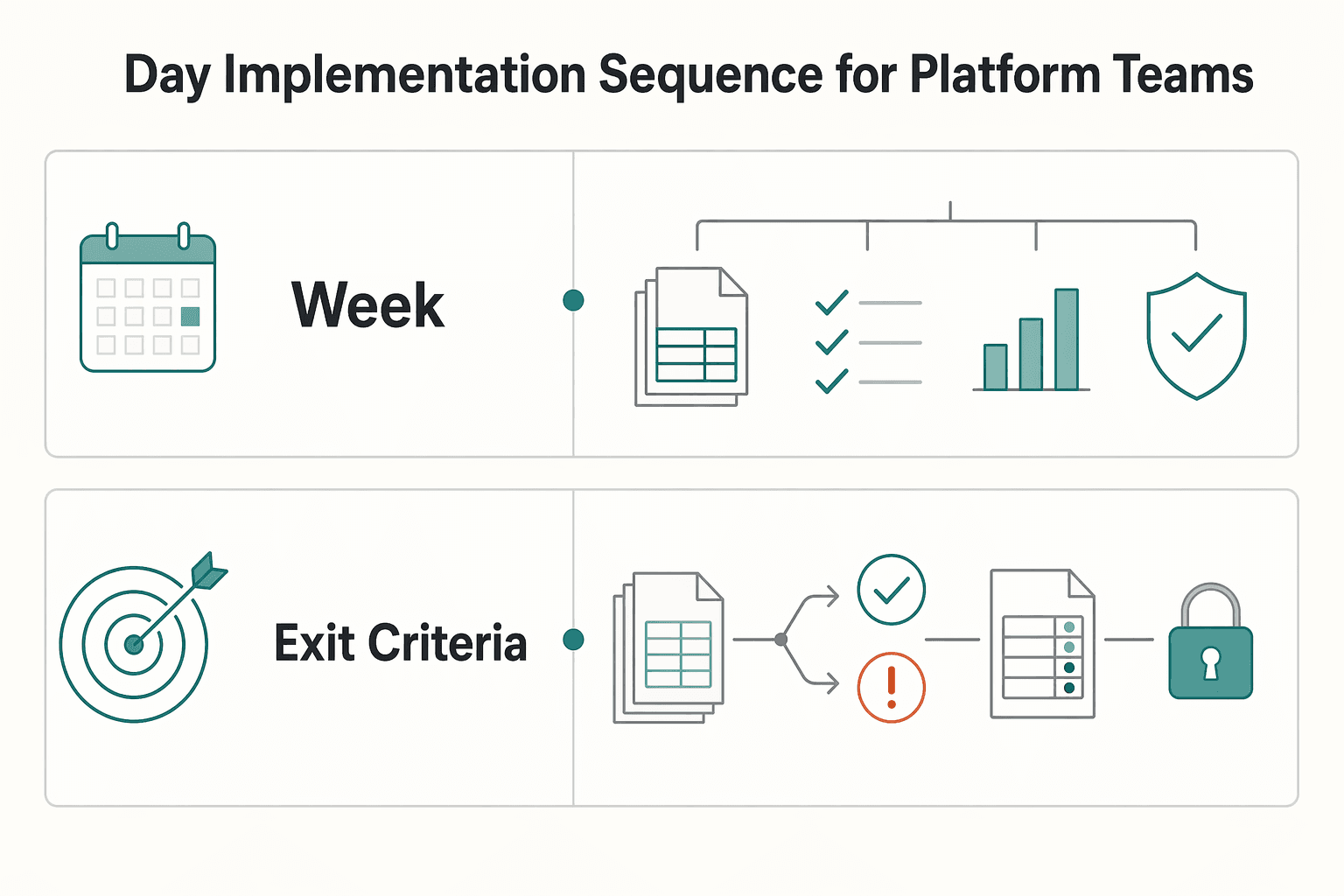
| Phase | Primary focus | Key check |
|---|---|---|
| Week 1 | Baseline overdue invoices, collection outcomes, and current dunning behavior | Pause if finance and account counts, timestamps, or final states do not align |
| Week 2 | Ship segmentation and rule-based controls | Document how each rule maps to an outcome and keep an exception log by record, owner, and timeline |
| Week 3 | Improve communication and payment method updates | Ensure each notice includes needed invoice details and keep documentation current |
| Week 4 | Run a verification pack before launch | Run audit-trail spot checks, review reconciliation exports, and verify documentation is complete for escalation and bad-debt handling |
| Exit criteria | Scale only when outcomes hold | Cash-flow outcomes improve without creating avoidable relationship strain, support load is manageable, and reconciliation breaks are resolved |
- Week 1: baseline the current state
Start with a clean baseline for overdue invoices, collection outcomes, and current dunning behavior. Reconcile the finance and account records your teams use, and pause if counts, timestamps, or final states do not align. Split results by billing model so simple recurring, usage-based, and sales-negotiated contract accounts are not treated as one pool.
- Week 2: ship segmentation and rule-based controls
Make behavior deterministic before improving message design. Turn on segmentation and rule-based dunning schedules, and document how each rule maps to an outcome. Keep an exception log that makes account state explainable by record, owner, and timeline.
- Week 3: improve communication and payment method updates
Focus on recoverable failures by making the update path simple and clear. Use direct dunning notices with one primary action and status language that matches actual account state. Ensure each notice includes needed invoice details and keep documentation current in case legal action or tax-related bad-debt handling is required.
- Week 4: run a verification pack before launch
Treat this week as proof, not polish. Run audit-trail spot checks, review reconciliation exports, and verify documentation is complete for escalation and bad-debt handling. Confirm customer-facing outcomes and finance records stay aligned across successful retries, failed retries, and state changes.
- Exit criteria: scale only when outcomes hold
Exit when cash-flow outcomes improve without creating avoidable relationship strain, support load is manageable, and reconciliation breaks are resolved. For invoice-heavy operations, DSO movement is a practical finance checkpoint. Close with a compact evidence pack: baseline vs current metrics, sample account journeys, exception handling records, and finance sign-off.
Conclusion#
The point is not just sending more reminders. It is running a clear recovery cycle with automation, retries, follow-up messaging, and escalation paths that move failed payments back to successful charges.
Treat operations as part of recovery, not cleanup after the fact. Identify missed invoices during reconciliation, and connect dunning with your billing, accounting, and CRM systems so teams work from one consistent view. Keep communication respectful and rule-driven so you recover revenue without damaging customer trust.
If you are choosing tools next, use this structure to evaluate fit. Then compare options in /blog/best-tools-for-managing-subscription-billing and deepen execution in /blog/guide-to-dunning-management-for-failed-payments.
When you are ready to map your dunning controls to a full collect-to-payout operating model, talk to Gruv.
Frequently Asked Questions
What is dunning management in platform billing?
Dunning management is the structured process of recovering failed payments and unpaid invoices through customer communication. In platform billing, it usually combines automated retries and follow-up messages to guide the customer back to a successful charge. The goal is recovery without creating a punitive experience while keeping billing operations consistent.
How many dunning emails should most teams send before escalation?
There is no universal email count that works for every platform. A safer pattern is staged escalation: start with friendly reminders, then move to more urgent notifications if needed. Use escalation stages instead of assuming more messages will always improve recovery.
Should we retry the same card first or ask for a new payment method immediately?
Use the failure reason to decide, not a fixed rule. Card expirations, bank declines, and billing errors can require different responses, so your retry logic should reflect API error codes and decline reasons. When signals point to a payment-method problem, consider prompting for an update early.
When should a dunning campaign stop and hand off to support?
Consider a handoff when automated retries and follow-ups are no longer resolving the payment issue. Also hand off when manual review is required, including compliance-related review in regulated or high-risk contexts. Include clear event and status context in the handoff to reduce duplicate or conflicting actions.
Which metrics matter most for dunning performance beyond recovery rate?
Recovery rate matters, but it is not enough on its own. Also track failure mix, for example expirations, declines, and billing errors, plus outcomes after retries and follow-ups and data-consistency issues such as duplicate actions. Those signals help show whether recovery performance is operationally reliable.
How do idempotency keys and webhook events reduce dunning errors?
Webhooks drive event-based recovery, but they need safeguards. Idempotency keys plus signature verification help prevent duplicate actions and improve data consistency when events are asynchronous. Testing handlers with tools like Test Clocks and the Stripe CLI helps confirm that one failure does not trigger conflicting retries or records.
How do KYC, KYB, and AML checks affect payment recovery and payouts?
In high-risk or regulated contexts, KYC and AML controls can require identity verification and affect account workflows. These checks can add review steps, so teams should define how recovery and payout workflows interact under their own policies. KYB specifics depend on your regulatory and policy setup, so treat those rules as implementation-specific rather than universal.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
- federalreserve.gov/boarddocs/supmanual/cch/200806/cch200806.pdftrusted
- ipac.ecosphere.fws.gov/project/5WDZZBE4SRDZFHKJBEIM7MCKBY/documents...trusted
- ncbi.nlm.nih.gov/books/NBK621497trusted
- osha.gov/sites/default/files/enforcement/directives/A...trusted
- public-inspection.federalregister.gov/2025-19787.pdftrusted
- snap.berkeley.edu/project/12416885trusted
- snap.berkeley.edu/project/13128922trusted
- wise.com/gb/blog/dunning-managementtrusted
Educational content only. Not legal, tax, or financial advice.
Related Posts

The Best Tools for Managing Subscription Billing
**Protect cashflow by selecting for recovery and control first, then layering convenience features.**

A Guide to Dunning Management for Failed Payments
If you run recurring invoices, failed payments are not back-office noise. They create cashflow gaps, force extra follow-up work, and increase **Involuntary Churn** when good clients lose access after payment friction.

A Guide to Client-First Development in Webflow
**Treat Client-First in Webflow like a system for delivery decisions, not a styling trend, so you can move faster today without creating surprises tomorrow.**