
Quick Answer
Start with one baseline sequence: Pre-dunning reminders before renewal, then Day 0, Day 3, Day 7, and Day 14 recovery steps tied to real payment actions. Keep retry timing separate from service-impact language so temporary failures are not escalated too early. Before adding segments, verify one failed invoice end to end in Chargebee or Stripe: failed attempt, notice sends, retry outcomes, and final status in Webhooks and the Ledger journal.
Build a Dunning System You Can Run in Production#
Step 1 Define the operating goal#
Build this as an operating sequence, not a template library. In practice, dunning starts after a recurring auto-collection attempt fails and combines payment retries with customer notices. Your job is to recover revenue from failed recurring payments without pushing good customers into churn or creating customer confusion.
That tension matters because failed-payment churn can be involuntary, and generic retention tactics often do not solve it on their own. If you treat every failure like a cancellation risk, you can over-message. If you treat every failure like a temporary card issue, you can wait too long on accounts that actually need a payment method update.
Verification point: before you design timing or copy, write down the primary decision you are trying to improve. A usable answer is specific: recover more failed renewals, reduce churn from failed charges, or reduce manual collections work. "Improve dunning" is too vague to run.
Step 2 Set the unit of control#
Start with one default path you can explain, monitor, and change. Many billing setups support a default dunning campaign for invoices unless a separate campaign is assigned. Some also let you create targeted campaigns for specific plans or accounts. For platform teams, that's the right starting model: one baseline sequence first, targeted tracks later when the data shows you need them.
Keep the scope honest here. Do not assume one global sequence should apply to every segment, payment method, or product tier forever. A creator subscription, a marketplace seller plan, and a larger B2B account can fail for different reasons and respond differently to the same message tone or retry spacing.
Recommendation: if you do not have segment data yet, launch a default campaign first and hold off on special-case branches until you can prove they are needed.
Step 3 Treat timing and messaging as defaults to test#
Use examples as operating defaults, not benchmarks to copy blindly. One documented commerce setup retries every 2 days up to 5 times. That is useful because it is concrete and easy to instrument. It is not a universal best practice. Your own billing context will change what "too fast" or "too slow" looks like.
A common operational risk is treating a vendor default as universally correct. A production-ready sequence needs checkpoints. You should be able to verify, for each failed invoice, the failed attempt, the retry schedule, the notices sent, and the final outcome. If you cannot trace that chain reliably, do not trust early recovery numbers yet.
That is the standard for the rest of this guide: clear timing, clear messaging, and measurement you can defend. The examples ahead are starting points to test, not universal answers.
If you want a deeper dive, read What Is Dunning? A Platform Operator's Guide to Recovering Failed Recurring Payments.
What to Prepare Before You Turn It On#
Before launch, lock down ownership, data flow, and compliance gates. If those are unclear, failed-payment volume usually turns into an operations and reconciliation problem instead of a recovery gain.
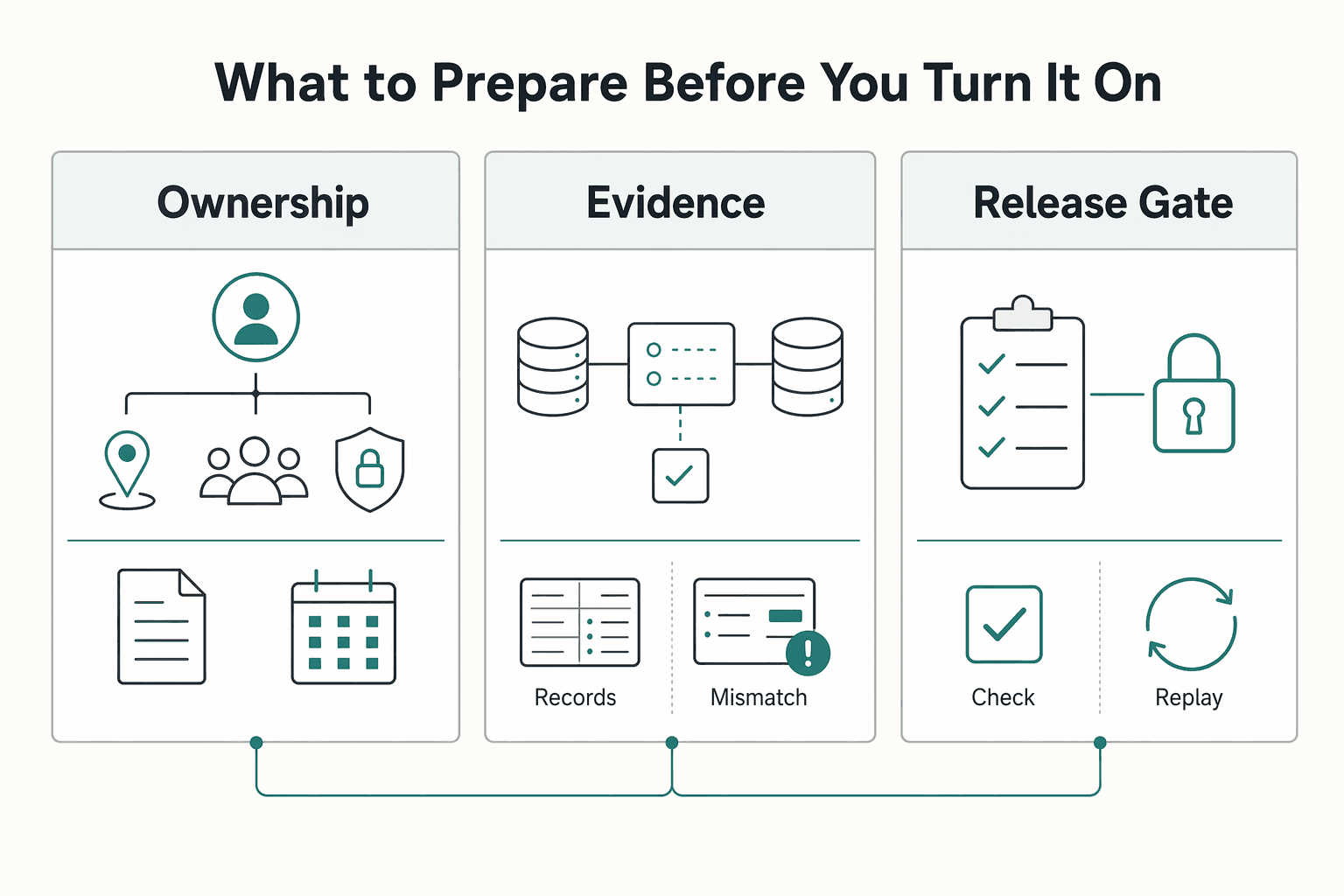
| Area | What to confirm | Check |
|---|---|---|
| Ownership | Payment retry logic owner and customer messaging approval | Team can answer who can pause retries immediately |
| Systems of record | Billing platform, Webhooks, and Ledger journal end to end | Validate one recent failed renewal and confirm all three records match |
| Compliance gates | Which KYC, KYB, or AML status blocks action and who reviews exceptions | Document exceptions; some AML programs require formal internal controls such as 31 CFR 1020.210 in U.S. banking scope |
| Launch evidence pack | Baseline recovery rate, retry success rate, and top failure reasons | Segment by plan, payment method, failure reason, and customer tenure |
-
Name decision owners for retries and messaging. In tools like Chargebee, dunning covers both retry execution and failed-payment emails, so set clear ownership for Payment retry logic and clear approval for customer messaging. If your team cannot answer who can pause retries immediately, do not launch yet.
-
Confirm your systems of record end to end. Define where billing state lives, how events move, and where accounting is reconciled: billing platform (for example Chargebee), Webhooks for event delivery, and a Ledger journal (journal-entry layer) for traceability. Validate this with one recent failed renewal and confirm that all three records match.
-
Document compliance gates that can suppress recovery actions. Where KYC, KYB, or AML checks apply, not every account should follow the same recovery path. Write down which status blocks action and who reviews exceptions; in some contexts, AML programs require formal internal controls (for example, 31 CFR 1020.210 in U.S. banking scope).
-
Prepare a launch evidence pack by segment. Include baseline recovery rate, retry success rate, and top failure reasons, segmented by plan, payment method, failure reason, and customer tenure. This gives you a defensible starting point before you change timing or messaging.
Map the Failure Flow and Instrument It End to End#
Make the recovery path observable before you tune timing. If you cannot trace one failed invoice from first failure through Post-dunning closeout, pause optimization.
- Step 1. Draw the exact event chain from failure to outcome.
Start with the real trigger: dunning starts when an automatic invoice fails its initial payment attempt. Map the failure event, each retry attempt, each customer notification, and the terminal Post-dunning state your team uses. If you use Chargebee, include both retry collection and failed-payment emails in the same flow map.
- Step 2. Make retries and webhook processing idempotent.
Treat replays as normal and design for one outcome per event. Use an Idempotency key for retry jobs, and make webhook consumers prevent duplicate processing so one event cannot create a second collection attempt, second email, or second closeout action. Also account for operational impact if acknowledgements are missed: when Stripe does not receive a successful response to invoice.created, automatic invoice finalization can be delayed for up to 72 hours.
- Step 3. Journal each meaningful state transition and align internal views.
Support, finance, and audit should be able to read the same state model, even if they do it in different tools. Record each transition with stable labels and tie money-moving events to your Ledger journal or journal-entry layer so the operational timeline and accounting record stay reconcilable. If support and ledger states diverge, your instrumentation is already drifting.
- Step 4. Add async checkpoints for bank rails, Virtual Accounts, and mixed methods.
Do not assume payment outcomes arrive synchronously. Keep an explicit pending state between "retry sent" and "retry failed/succeeded" for asynchronous confirmations, including flows that use Virtual Accounts or mixed collection methods. Include webhook redelivery behavior in that design; for example, Stripe can resend undelivered webhook events for up to 3 days, and some settlement setups can complete 2 business days later.
Need the full breakdown? Read Subscription Billing Platforms for Plans, Add-Ons, Coupons, and Dunning.
Choose Baseline Timing and Retry Cadence by Risk Profile#
Use one clear baseline first, then tune by segment. A practical starting sequence is Pre-dunning 3 to 7 days before renewal or expiry, a Day 0 failure message, then retries around Day 3, Day 7, and Day 14. Keep retry timing separate from consequence timing so temporary issuer issues do not get treated like persistent non-payment.
Step 1 Set a fixed baseline before you optimize#
If you want tighter control, start with fixed offsets. A common fixed pattern is retries at 3, 7, and 14 days after the initial failure, plus a Day 0 notice immediately after failure.
If you use Stripe Billing, decide upfront between explicit control and automation. Smart Retries can auto-select retry timing, and Stripe's recommended default is 8 tries within 2 weeks. If you need explicit spacing for measurement, Stripe also supports fixed rules with up to 3 retries, each set by days after the previous attempt.
If you use Chargebee, set Dunning frequency (days between retries) and define the post-exhaustion action on the invoice or subscription before launch.
Step 2 Pair each message with actual retry behavior#
Each message should tell the customer the next operational step: automatic retry, or payment-method update required. For soft or temporary failures, auto-retry may be appropriate. For hard declines, treat method update as the gate: retries may be scheduled, but execution should wait until a new payment method is available.
| Profile | Cadence setup to start with | Message tone | Escalation trigger |
|---|---|---|---|
| Low-ticket SaaS | Apply the same baseline sequence first, then tune by recovery data | Brief, self-serve, update/action link first | Shift to consequence language near the end of the retry window |
| High-ticket B2B invoice | Keep technical retry timing explicit; add manual AP follow-up where needed | Direct and account-specific | Escalate commercially after repeated failure or no response |
| Marketplace subscriptions | Keep retry timing and service-impact timing on separate tracks | Clear and trust-preserving | Escalate when the technical recovery window is close to exhausted |
Treat this table as a starting operating model, not a benchmark.
Step 3 Separate technical recovery from commercial pressure#
Use one decision rule: if retries fail but payment-method updates are relatively high, slow retry frequency and increase "update method" prompts. If updates are low, bring urgency forward and clarify the final action window sooner.
Track recovery rate, churn, and retry success together when you review results. If recovery is flat while churn or support load rises, timing may be acceptable but message pressure is too aggressive. For a deeper retry-sequencing framework, see Smart Dunning Strategies: How to Sequence Retry Logic for Maximum Recovery.
Write Stage-Based Messages That Recover Revenue Without Burning Trust#
Once timing is set, each message should match the account stage and make the next step obvious.
Step 1 Use the phase to define the message job#
Pre-dunning should prevent failure, not sound like collections. If renewal risk is known, use a light prompt to update payment details before the next billing cycle.
| Stage | Purpose | Key detail |
|---|---|---|
| Pre-dunning | Prevent failure | Should not sound like collections; use a light prompt to update payment details before the next billing cycle |
| Active dunning | Recover after a failed charge | Explain the failure clearly and point to the fastest fix |
| Post-dunning | State service impact and the reactivation path | Pause or cancellation may apply; a canceled subscription may require a new subscription flow rather than reinstatement |
Active dunning starts after a failed charge. Explain the failure clearly and point to the fastest fix. Post-dunning should state service impact (for example, pause or cancellation) and the reactivation path. Be explicit about end states, because a canceled subscription may require a new subscription flow rather than reinstatement.
Verification point: sample one message per stage and confirm subject line, body, and CTA match the real account state.
Step 2 Include operational specifics in every message#
Each send should do three things quickly: say what happened, say what happens next, and provide the shortest path to resolution.
Minimum content in every message:
- next retry window, or a clear note that retries are paused
- direct payment-method update or manual payment path
- support escalation route with a real sender and reply-to setup
If failed-payment emails are automated after each failed attempt, keep the copy aligned with that behavior so customers are not guessing what the system will do next.
Step 3 Adapt templates to your platform context#
If you start from an email template, treat it as a draft and rewrite it for your platform relationship. A marketplace, creator, and contractor workflow can share structure, but the consequence language and recovery path should reflect the actual user impact in your product.
If you also use in-app or SMS recovery notices, keep wording and instructions consistent across channels. Mixed instructions erode trust quickly, especially when retry status and required customer action do not match.
By the end of this step, each stage should have one approved message that names the exact action, consequence, and recovery path in plain language.
Set Segment Rules Instead of One Global Sequence#
One global sequence is rarely the best control. Once stage-based messaging is set, the next lift usually comes from routing by the factors that change recovery outcomes: plan tier, payment method, failure reason, and customer tenure.
Step 1 Build segments that change the next action#
Use the Count + Chargebee analysis pattern as your baseline: compare performance by plan, payment method, failure reason, and tenure. These cuts help you decide whether a failed payment should stay in retries, move to a payment-method update flow, or exit the sequence.
Start with one export from a full billing cycle and tag each failed invoice with those four fields. Verification point: every failed charge should map cleanly to a segment, without a large "unknown" failure-reason bucket. If decline codes are missing or lumped into "other," fix classification before you tune timing.
Step 2 Write simple "if X, do Y" rules per segment#
Keep routing simple. You need a small set of explicit rules tied to real recovery mechanics, not dozens of branches.
| Segment signal | Do this | Why |
|---|---|---|
| Hard decline | Stop repeated retries and route to payment-method update | Hard declines require customer or operator intervention and are not retried until payment details are updated |
| Soft decline | Keep in retry queue and schedule a later retry | Soft declines are temporary and can recover on a later attempt |
| Update-required payment method issue | Shorten message gap and make the CTA payment-method update | Recovery depends on customer action, not another immediate retry |
| Temporary decline pattern | Use a longer retry gap before the next attempt | Temporary issues may resolve without immediate intervention |
Use plan tier and tenure as filters, not assumptions. If a segment shows higher recovery but also higher churn after aggressive messaging, soften the message or widen the retry gap for that segment.
Step 3 Add a stop-loss rule and review recovery with churn#
Define a clear end state. When recovery attempts are exhausted, route accounts out of active dunning into pause/cancel handling and your re-engagement path, such as a win-back campaign. If you use Paddle Billing without Retain, the default window can run up to seven retries over 30 days before cancellation.
Evaluate segment performance with recovery rate, churn, and retry success together, not in isolation. A practical review view is one row per segment with those three metrics side by side. If retry success is weak while churn rises in the same segment, stop pushing harder and change the route.
Add Compliance and Audit Controls Before Scaling Volume#
Do not scale dunning volume until compliance gates and audit traces are in place for what happens after recovery. If a recovered account can resume payout-related activity, treat gating as a release valve, not an afterthought.
Step 1 Gate recovery-linked actions on compliance status#
Separate "payment recovered" from "account fully re-enabled." If successful recovery can reopen payout-related capabilities, require the applicable KYC, AML, and program-specific checks before those capabilities return.
Use a simple verification check: sample recently recovered accounts and confirm billing recovery did not bypass identity or payout holds. A common failure mode is tying reactivation directly to payment success while operational reviews are still pending.
Step 2 Keep tax and identity collection out of dunning messages#
Keep dunning focused on payment recovery, not tax onboarding. Form W-9 is for requesting a U.S. person's TIN and certifications, and Form W-8BEN is used by a foreign individual to establish foreign status; keep those flows operationally linked but separate from payment-failure notices.
Maintain the same separation in reporting logic. Card and third-party network transactions are reported on Form 1099-K, not 1099-MISC or 1099-NEC, so mixing tax collection into dunning increases the risk of requesting the wrong artifact at the wrong time.
Step 3 Record every attempt and override in the Ledger journal#
Require a Ledger journal entry for each retry attempt, customer notice, manual suppression, and operator override, and keep audit-ready exports available. In regulated contexts, control design includes creating and retaining records, so each decision should be traceable to what happened, who changed it, and why.
If an override cannot be tied to a journaled event, treat it as a control gap before increasing volume.
You might also find this useful: How to Choose a Merchant of Record Partner for Platform Teams.
Common Failure Modes and How to Recover Fast#
After audit controls are in place, fix execution reliability and data visibility first. Message tuning will not help if your sequence runs twice or hides where failures are concentrated.
| Failure mode | Recovery | Key note |
|---|---|---|
| Duplicate retries from replayed events | Enforce duplicate protection in workers and Webhooks consumers | Use an Idempotency key and design webhook handling to tolerate duplicate delivery and out-of-order events |
| High email volume, low payment updates | Reduce unnecessary sends and make the payment-update path clearer | Rebalance Payment retry logic; aggressive daily retry loops can backfire and appear risky to processors or banks |
| Retry performance improves, but churn rises | Soften early Pre-dunning language and delay hard consequence messaging | Keep early messages guidance-oriented so recovery pressure does not create avoidable cancellations or downgrade behavior |
| Blended metrics hide segment-level problems | Instrument failed-payment analysis by payment method, cohort, failure reason, and time period | If you cannot segment clearly, hold timing steady and instrument first |
Failure mode 1: duplicate retries from replayed events. If duplicates show up, check both workers and Webhooks consumers. Use an Idempotency key on retryable create/update operations, and design webhook handling to tolerate duplicate delivery and out-of-order events rather than assuming strict sequence.
Failure mode 2: high email volume, low payment updates. If volume is high but updates are low, the answer usually is not more reminders. Make the payment-update path clearer, and rebalance Payment retry logic so retries are strategic rather than daily by default. Aggressive daily retry loops can backfire and appear risky to processors or banks.
Failure mode 3: retry performance improves, but churn rises. If recovery improves while churn rises too, your pressure is probably landing too early. Soften early Pre-dunning language and delay hard consequence messaging. Keep early messages guidance-oriented so recovery pressure does not create avoidable cancellations or downgrade behavior.
Failure mode 4: blended metrics hide segment-level problems. In Chargebee (or equivalent), break failed-payment analysis out by payment method, cohort, failure reason, and time period before you change cadence again. If you cannot segment clearly, hold timing steady and instrument first.
Copy-Paste Launch Checklist and Next Step#
Keep the first launch boring, visible, and easy to unwind. A baseline sequence you can audit is more useful than a clever one you cannot trace once support tickets and replayed events show up.
- Confirm owners and document the event map.
Assign clear owners for retry logic, customer messaging approvals, and final account-state decisions when recovery fails. Map the path from payment failure to retry attempts, customer notices, payment-update flow, and closeout. Verification point: when a customer says "I updated my card" or "I already paid," support knows exactly who checks the event trail and who can override status.
- Validate instrumentation before any live message.
Launch only when retries, notifications, and outcomes are traceable in Webhooks logs and your Ledger journal states (or equivalent system of record). Because webhook endpoints can receive duplicate deliveries, log processed event IDs and skip already-processed ones. Use an idempotency key for retry jobs so replayed requests do not create duplicate financial effects. Verification point: take one failed invoice and trace it from webhook receipt through retries and notices to a final state (for example, recovered or exhausted). Red flag: Stripe can resend undelivered events for up to three days, so same-day-only monitoring can miss replay-driven duplicates or late recoveries.
- Ship one baseline sequence, then tune in controlled steps.
Start with one sequence that includes customer notifications, retry behavior, and an in-app or hosted recovery path. Let it run through a full recovery cycle, then adjust timing or messaging in a controlled way so you can attribute impact. Retry outcomes should inform communication timing, and communication responses should inform retry decisions. Verification point: after one full cycle, you can identify which retry, notice, or payment-update prompt changed outcomes.
- Align cross-border rules with payment accountability.
For cross-border flows, confirm whether a Merchant of Record (MoR) or similar setup changes who is responsible for collecting and remitting sales tax, VAT, or GST. If you use Virtual Accounts where supported, account for pay-ins and payouts routing through virtual accounts while underlying fund movement sits under a physical header account. Verification point: your dunning logic should not mark an account unpaid or trigger the wrong message while funds are still reconciling across those structures.
Next step: run a focused 30-day optimization loop by segment, then publish your internal launch standard based on what you observed.
Frequently Asked Questions
What is dunning for a platform operator versus a standard subscription business?
The core definition is the same: dunning starts after an automatically collected subscription payment fails, and the subscription typically moves to past due while recovery begins. For a platform operator, the practical difference is scope. It can involve managing retries, reminders, and support impact across more segments, payment methods, and account types instead of treating all failed recurring payments as one bucket.
What default timing sequence should we launch first if we have limited historical data?
If your billing stack supports Smart Retries, start there first, because Stripe documents that data-point-based retry timing is more effective than a fixed schedule. If you need a manual default, keep it simple and easy to audit. Chargebee’s example is retries at 1, 4, and 8 days from initial failure, and Recurly Commerce’s example is every 2 days, up to 5 times. Your check is whether each retry attempt, notice, and account-state change is visible in one place before you add more complexity.
How often should we send dunning messages before they start hurting retention?
There is no single message frequency that is safe for every segment, and you should be wary of anyone offering one. A practical starting rule is to tie reminders to meaningful retry or account-state events, not to send extra notices just because you can. If message volume rises but payment updates and recoveries do not, that is a red flag that frequency or message usefulness is off.
Which metrics prove our dunning sequence is working beyond total recovered revenue?
Track the basics Stripe calls out in recovery analytics: payment failure rates, recovery rates, and recent failed payments for top customers. Then add operator checks that show whether the sequence is healthy, such as retry success by segment and whether accounts recover before you reach the final retry. If you cannot tell which retry or reminder actually changed the outcome, the measurement is not good enough yet.
How should we adjust timing by failure reason and payment method?
Do not assume one rule works across gateways or geographies. If you have Smart Retry support in tools like Chargebee, use that before hand-tuning lots of schedules. If you do not, keep one manual pattern until your data shows a clear split by failure reason or payment method. A common risk is overfitting too early and ending up with many sequences you cannot explain or verify.
When should we stop dunning and move an account to win-back instead?
A sound stop condition is when the configured retries have failed and your billing tool is set to pause or cancel if retries fail, which is a documented pattern in Recurly Commerce. Do not anchor on one universal day count. Anchor on exhausted recovery options and a clear status transition out of past due. At that point, switch from payment correction to reactivation messaging. If you need a model for that handoff, use a separate win-back motion.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
- docs.stripe.com/webhooks/process-undelivered-eventstrusted
- docs.stripe.com/billing/revenue-recovery/smart-retriestrusted
- ecfr.gov/current/title-31/subtitle-B/chapter-X/part-1...trusted
- ecfr.gov/current/title-31/subtitle-B/chapter-X/part-1...trusted
- irs.gov/instructions/i1099mectrusted
- irs.gov/instructions/iw9trusted
- law.cornell.edu/cfr/text/31/1022.210trusted
- stripe.com/resources/more/involuntary-churn-101-what-it...trusted
Educational content only. Not legal, tax, or financial advice.
Related Posts

Win-Back Campaigns That Reactivate Churned Subscribers Without Margin Loss
Assume from the start that a win-back flow can lift reactivations and still be a bad trade. If you do not measure what those returns cost in incentives and short-term re-churn, you can end up celebrating activity that does not help the business.

What Is Dunning? A Platform Operator's Guide to Recovering Failed Recurring Payments
Dunning management is an accounts-receivable process for recovering overdue balances. In recurring billing, it also covers failed-transaction notices and overdue-payment reminders. For platform teams, that means dunning is not an ad hoc email task. It is an operating process with clear triggers, owners, and end states.

Smart Dunning Strategies to Sequence Retry Logic for Maximum Recovery
If you treat retry logic as a billing setting, you may get some upside and still create hidden operational gaps. A better starting point is shared ownership across teams. Product decides customer treatment. Engineering controls retry execution and event integrity. Finance ops owns reconciliation and audit-trail review.