
Quick Answer
Start with one auditable use case tied to a single monetization outcome, then expand only when holdout results and operating load both improve. For an ai personalize subscriber experience at scale platform strategy, the article recommends sequencing work in this order: governed profile data, architecture sign-off, narrow launch, and weekly cross-functional review. Use deterministic rules for high-error-cost decisions, add model-driven ranking where upside is clear, and require rollback ownership before broader rollout.
Where AI Improves the Subscriber Experience#
Treat ai personalize subscriber experience at scale platform as an operating and margin decision first, not a messaging upgrade. If you start with campaign ideas before you decide what data, controls, and staffing you can actually support, you can add complexity faster than you improve retention.
That framing matters because the business case is real, and so are the constraints. Microsoft notes that 71% of consumers expect personalized interactions, while 76% get frustrated when they do not get them. The same source cites revenue gains of 10% to 15% for companies that get personalization right, with company-specific results ranging from 5% to 25%. Use those numbers as a benchmark for why leaders care, not as a promise that your platform will see the same lift without baseline testing.
Market content from Braze, Adobe, and Twig is useful for showing what modern tools can do. Braze talks about moving beyond basic tactics to true personalization at scale. Adobe frames the next layer as Customer Experience Orchestration, or CXO, where connected experiences and AI work across touchpoints. Twig shows how real-time support conversations can be personalized at scale. For operators, the harder part is sequencing under real constraints. Teams still have to decide what to launch first when data is fragmented, latency is a risk, and operating costs and compliance requirements are real.
This guide stays focused on that operator problem. The goal is to improve subscriber revenue and retention with AI while keeping the model manageable, auditable, and realistic. We will focus on decision order, verification points, and the moments where a lighter rule-based choice beats a more ambitious build.
Before you start#
Use these three checks before you expand scope:
-
Name the business outcome. Pick one subscriber moment and one economic target, such as activation, expansion, or churn reduction. If the goal is vague, implementation usually turns into channel activity without a clear payback test.
-
Verify operating readiness. Confirm you can identify the profile data you will use, who can access it, and where exceptions go when a message, offer, or support action is wrong. A practical checkpoint is whether product, finance, and operations can all explain why a subscriber would receive a given treatment.
-
Call the tradeoff early. Richer personalization can improve relevance, but it also raises the burden on data quality, latency, and compliance review. Microsoft explicitly points to fragmented data, latency issues, and high operational costs when the cloud and data foundation are not ready.
Define what counts as real personalization at scale#
Real personalization at scale means real-time, profile-driven decisioning coordinated across channels, not campaign-level customization. If the system is mostly inserting a first name into campaign content, it has not crossed into true at-scale personalization.
Define the decision first, then the message. The core unit is the subscriber profile plus current context, and the practical test is whether your team can name the profile signals and recent behavior that led to a specific treatment.
Use three required layers:
- Decisioning logic: chooses the message, offer, or support response from profile and context.
- Delivery channels: executes that decision consistently across subscriber touchpoints.
- Operating controls: provide audit visibility so actions are explainable and recoverable.
If any layer is missing, you do not have production-grade scale. Siloed multi-channel execution is still siloed, even when it looks broad in reporting.
Set an explainability bar before expansion. If product, finance, or ops cannot explain in plain language why a subscriber received a specific message, offer, or response, treat that as a readiness failure. Explainability supports trust and adoption, and it should come from logs and audit access, not assumptions.
Prepare the prerequisites before any AI rollout#
Do the groundwork first: if profile governance, compliance boundaries, and approvals are unclear, pause rollout before you tune models or write targeting rules.
| Data or workflow | Handling in article |
|---|---|
| KYB-style beneficial ownership data | Where legal-entity customers are in scope, treat as controlled at account opening |
| W-9 data | TIN for information-return workflows; keep explicit handling boundaries |
| W-8BEN data | Foreign-status evidence; keep explicit handling boundaries |
| Foreign-account reporting data tied to FBAR (FinCEN Form 114) | Keep explicit handling boundaries |
| VAT- or FEIE-adjacent workflows | Keep on compliance-reviewed paths instead of letting growth logic infer from them |
Start with a governed first-party data spine built around a stitched subscriber record across product, support, billing, and messaging. That is the practical value of a Real-Time Customer Profile-style capability: unified data from multiple sources, available as an individual profile.
Use a simple verification check on a live subscriber: can product and finance trace which fields were stitched, where they came from, and who can access them? Where legal-entity customers are in scope, treat KYB-style beneficial ownership data as controlled at account opening. Do not let onboarding, transaction, and marketing data collapse into one broad access pool that can leak AML or beneficial-owner fields into messaging.
Define tax and compliance edges before you design subscriber-facing journeys. W-9 data (TIN for information-return workflows), W-8BEN data (foreign-status evidence), and foreign-account reporting data tied to FBAR (FinCEN Form 114) should have explicit handling boundaries. If your product touches VAT- or FEIE-adjacent workflows, keep those on compliance-reviewed paths instead of letting growth logic infer from them.
For each use case in Gruv operations, keep a short evidence pack:
- fields used
- decision policy
- excluded sensitive fields
- approval owner
- rollback owner
Then set go-live gates that finance and product can verify:
- data quality checks on profile inputs
- policy approval on the use case
- audit-log visibility for finance and product stakeholders
In regulated financial contexts, risk-based AML/CFT program design is required, so approvals should confirm the use case does not bypass those controls. If you cannot show the access trail, decision rule, and rollback contact on the same day, it is not production-ready.
Choose your platform architecture with explicit tradeoffs#
After data boundaries are clear, choose architecture based on control under failure, not feature breadth in a demo. The best pattern is the one your team can explain, override, and recover quickly when a decision misfires.
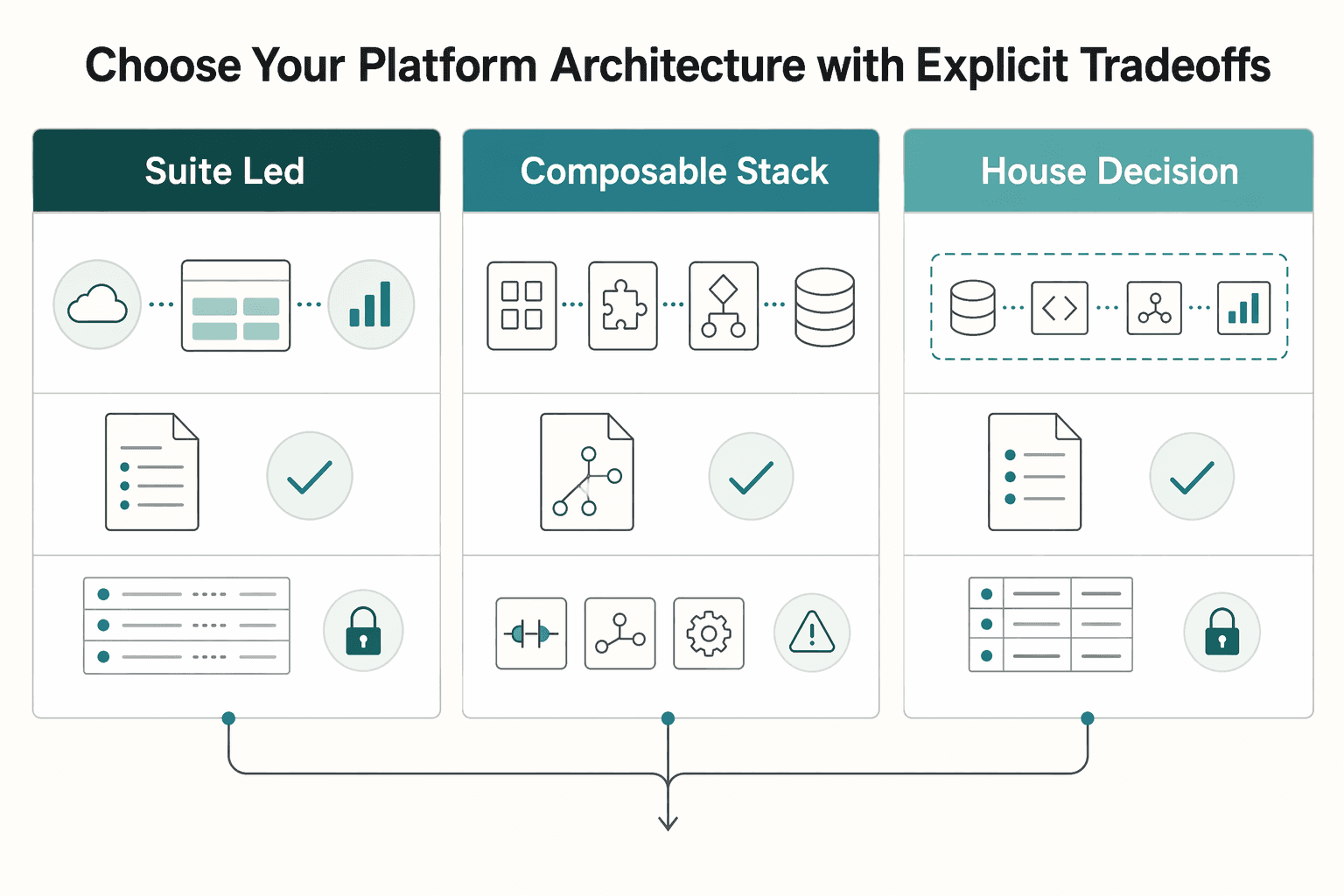
| Pattern | Best fit | Main advantage | Main tradeoff | Verification checkpoint |
|---|---|---|---|---|
| Suite-led orchestration such as Braze Canvas or Adobe journey tooling | Cross-channel programs with frequent changes and many stakeholders | Faster launch through built-in orchestration; Braze positions Canvas as a no-code journey builder, and Adobe documents cross-channel journeys with real-time decisioning | You operate inside the suite's model, data assumptions, and integration boundaries | Can product and finance trace one live decision from profile input to channel output without engineering rebuilding the path manually? |
| Composable stack | Teams mixing best-of-breed data, decisioning, and channel tools | More component control and easier swap-outs over time | Higher integration burden and more failure points | Can you name the source of truth for profile data, decision logic, and delivery logs, then show each handoff? |
| In-house decision engine with channel tools | Narrow or highly specific use cases where custom logic matters most | Maximum control over logic, ranking, and policy overlays | Time-to-launch often stretches; AWS notes in-house personalization can take a lot of time | If the lead engineer is out for a week, can another operator still pause a bad path and explain what fired? |
Use this build-vs-buy rule as a decision aid, not as a law: if logic changes often and each change needs heavy compliance or finance review, centralize orchestration. If use cases are narrow with limited branching, keep it lightweight. The practical choice is usually SaaS, custom build, or a hybrid, not a strict either-or.
Pressure-test vendor claims with operator criteria: workflow explainability, override controls, integration burden, and failure handling. Ask Braze, Adobe, Twig, Attentive, or any shortlisted tool to walk one sample subscriber end to end: which inputs are read, what logic fired, who can override, and what happens if a downstream tool times out or returns stale data.
Route decisions by problem type. Use deterministic rules where error cost is high, and use model-driven components where classification or ranking adds value; NLP is useful when unstructured text meaning changes the decision. In many cases, hybrid routing is safer: model output first, deterministic checks before send.
Before you implement, require a one-page architecture sign-off from product, finance, and engineering. Include the chosen pattern, systems involved, decision-logic owner, override path, failure path, and rollback contact, then keep it with the use-case evidence pack in Gruv operations.
Tie subscriber moments to monetization levers#
Start with lifecycle economics, not channels: map each subscriber moment to one monetization lever, then scale decisioning effort by expected LTV upside.
| Intervention depends on... | Gruv module |
|---|---|
| billing, tax handling, or VAT responsibility | Merchant of Record (MoR) |
| receiving account setup, balances, or fund routing | Virtual Accounts |
| how funds reach a payee, creator, or partner | Payouts |
Use the subscription lifecycle as the operating frame: onboarding, activation, expansion, churn risk, and winback.
Step 1: Assign one economic outcome to each moment. Keep each moment tied to a single money outcome so teams can measure what changed. Expansion should map to higher revenue per subscriber, churn risk to retained revenue protection, and winback to reactivated revenue. If a moment has multiple competing goals, narrow it before you personalize.
Step 2: Tie each lever to the Gruv module that changes money movement. If the intervention changes billing, tax handling, or VAT responsibility, map it to Merchant of Record (MoR). If it depends on receiving account setup, balances, or fund routing, map it to Virtual Accounts. If the outcome depends on how funds reach a payee, creator, or partner, map it to Payouts. This is not a claim that modules create revenue on their own; it is a control point so product and finance are reviewing the same commercial mechanism.
A practical checkpoint is one traceable chain per segment: targeted moment, monetization lever, implicated Gruv module, and success event.
Step 3: Route by expected LTV upside. For lower-upside segments, use deterministic rules and narrow offers. For higher-upside segments, allow richer model-driven ranking or real-time personalization, with business-rule overlays for eligibility, exclusions, and finance-sensitive triggers. In practice, a hybrid model is often strongest because deterministic segment rules and dynamic decisioning can work together.
Step 4: Lock segment constraints before launch. Document constraints per segment so low-impact cohorts do not absorb high-cost personalization:
- allowed channels
- prohibited channels
- allowed offer types
- excluded offer types
- approval and rollback owner
If you want a step-by-step walkthrough, see Choosing Creator Platform Monetization Models for Real-World Operations.
Implement in sequence with verification at each step#
Once your moment, monetization lever, and segment constraints are defined, scale in sequence, not all at once. Trust breaks fast when identity, event quality, and exception ownership are unproven.
| Step | Verification focus |
|---|---|
| Launch one high-signal use case | Verify event quality across the full flow and identity resolution quality |
| Add one additional channel | Use holdout testing to confirm incremental impact and confirm operations can support exception handling |
| Operationalize alerts | Monitor error rates, profile-quality issues, delivery risks, stale profiles, and policy-rule breaks |
| Formalize a weekly review | Review KPI vs holdout, exception volume, alert history, profile-quality issues, and proposed rule changes |
Start with one use case you can actually audit#
Step 1: Launch one high-signal use case in Adobe Experience Platform Agents, broader Adobe tooling, or an equivalent decisioning layer, and tie it to one KPI. Start with one high-impact use case, one KPI, and a clear action set.
Verify two things before expanding:
- event quality across the full flow (trigger, profile update, decision, send/action, downstream commercial event)
- identity resolution quality, so known and unknown interactions are unified when they should be and kept separate when they should not be
If you cannot reconcile those records reliably, treat the pilot as still in setup.
Add reach only after incrementality and exception handling hold up#
Step 2: Add one additional channel only after holdout testing confirms incremental impact and operations can support exception handling. Use a persistent control group to measure lift against no-message exposure, and use path experiments when you need treatment/control comparisons inside the journey.
Do not scale a new channel on volume alone. Check KPI movement and operational load together; if exceptions rise faster than impact, pause expansion and fix the operating path first.
Because failed actions can stop an individual journey, define fallback actions before launch. For Gruv-connected flows, document who is notified on failed handoffs, what fallback experience is sent, and when to suppress further attempts.
Step 3: Operationalize alerts before widening exposure. Use system alerts to monitor live journey risk signals, including error rates, profile-quality issues, and delivery risks, then add checks for stale profiles and policy-rule breaks in your own logic. For each live use case, keep an evidence pack with the rule version, alert thresholds, fallback action, holdout definition, and rollback owner.
Step 4: Formalize a weekly review with product, finance, and ops. Weekly is a practical operating cadence, not a universal mandate. Review KPI vs holdout, exception volume, alert history, profile-quality issues, and proposed rule changes, then make one decision per use case: expand, pause, or revise.
Measure economics before adding complexity#
If the economic signal is unclear, stop adding models, channels, or decision branches. The goal is to prove better unit economics by segment, not just more activity.
Build one shared scorecard#
Use one scorecard that finance, product, and ops read the same way: conversion lift, retention movement, support load change, and cost-to-serve delta by subscriber segment, measured against a holdout or control. That keeps the discussion on incremental value, not vanity movement.
Treat support and service effort as part of the result, not a side metric. IBM's framing is that AI support should personalize while minimizing human involvement, so if human effort rises while commercial movement stays flat, the economics are likely getting worse.
Set a practical stop rule for complexity#
Define a stop rule before anyone asks for another model layer. As a house rule, if incremental gain is flat for two review cycles, pause complexity and fix data quality, features, or journey design first.
Google's guidance supports that sequence: most gains come from better features, and poor data quality leads to poor outcomes. If inputs are weak, more model sophistication usually compounds noise instead of improving decisions.
Pressure-test market narratives against your own economics#
Use vendor and analyst claims as context, not as operating assumptions. Salesforce positions the target as real-time 1:1 personalization across touchpoints with operator control and impact visibility, while McKinsey cites a 10 to 30 percent uplift range for revenue and retention under fully implemented personalization.
If you see case examples like 33% conversion lift and 40% product-view growth, compare them to your own staffing, channel mix, and data maturity before budgeting for similar outcomes. For Gruv-connected journeys, include downstream operating effects in the same review, especially when support, billing, or payout exceptions change.
Draw explicit automation boundaries#
Document three decision buckets with clear owners:
- AI-driven: choices like ranking, timing, or variant selection where downside is limited.
- Human approval required: decisions that can materially affect margin or create disputes.
- Permanently rule-based: policy and compliance conditions where consistency matters more than experimentation.
For each live journey, make it easy to show which bucket applies, who can override it, and what record is kept if the outcome is challenged.
Avoid common failure modes and recover fast#
Once automation boundaries are set, operating drift usually breaks before model quality does. When growth, product, and finance can each change subscriber decisions in separate systems, stop expansion and fix ownership before adding more AI.
Step 1#
Unify decision ownership before you tune outputs. Assign one decision owner and one shared backlog across growth, product, and finance. Fragmented teams and fragmented data limit personalization outcomes, and the usual incident pattern is that no one can trace which change caused the result.
Use one live journey as a control test: every rule, message variant, and eligibility condition should map to the same owner and queue. If copy, triggers, and billing or payout conditions can ship through separate paths, conflict risk stays high and recovery slows down.
Step 2#
Treat AML and tax-document paths as controlled lanes, not experiment lanes. Before send or decision execution, enforce pre-send checks for any flow that touches AML review or tax-document collection. Under 31 CFR 1020.210, AML programs require internal controls and designated day-to-day compliance responsibility, so ownership and suppression logic should be verified before launch.
Apply strict controls to W-8BEN, W-9, and Form 1099-NEC journeys. W-9 supports correct TIN collection for information-return filing, W-8BEN is submitted when requested by the payer or withholding agent, and 1099-NEC is used to report nonemployee compensation. If personalization can change when these are requested, hidden, or reminded, require compliance signoff before launch.
Step 3#
Make every automated decision explainable and reversible. Require logs that capture the inputs used, rule or model version, output, timestamp, and any human override. Black-box behavior erodes trust during incidents, and versioned rules with rollback let you return to a last known good state quickly.
Run a production-readiness check on a single subscriber: reconstruct why they got a message, offer, or document prompt. If that takes longer than a few minutes, the system is too opaque.
Related: Finance Automation and Accounts Payable Growth: How Platforms Scale AP Without Scaling Headcount.
Copy and use this launch checklist#
Keep the first launch narrow, measurable, and auditable. Lock scope, governance, and ownership before you add channels or model complexity.
- Define one outcome, one lifecycle moment, and one monetization lever.
Choose one journey moment, one audience segment, and one KPI before anyone writes decision logic. If product, finance, and ops describe different goals, fix scope first.
- Verify governed data access before using any field in personalization decisions.
Confirm approved fields, excluded sensitive fields, policy gates, and clear audit trails showing how inputs drive outcomes. If you cannot explain why a subscriber received a specific message or offer, do not launch.
- Launch one use case first, then validate incremental impact with a holdout test.
Use holdout methodology to answer the counterfactual, not just headline engagement. Review results with economics and operating signals, like support or billing exceptions, before expanding channels.
- Lock escalation paths before go-live.
Use an approved incident response plan that defines owners and actions across compliance, billing, support, and engineering. Escalation behavior should also be clear for missed reporting obligations or failed handoffs.
- Expand only when outcomes stay measurable and decision logic stays explainable.
Add complexity only when gains are visible, operations are stable, and finance and product leaders can follow the decision path. As coverage grows, explainable audit trails become a control, not a nice-to-have.
Related reading: Build a Platform-Independent Freelance Business in 90 Days.
Frequently Asked Questions
What does AI personalization at scale actually require on a platform team?
You generally need three capabilities working together: a unified profile layer, one orchestration point across channels, and clear operating controls. Adobe’s Real-Time Customer Profile is a useful label for the first part: data from multiple sources merged into an individual profile that downstream tools can use. A practical checkpoint is whether your team can trace a subscriber decision back to its inputs and channel output.
Can we deliver 1:1 subscriber personalization without increasing headcount?
Sometimes, but do not treat that as a promise. Managed options can reduce the need for deep ML staffing early, especially if your use case is narrow and the team mostly needs orchestration rather than custom model development. As scope expands across more journeys and channels, ownership and operating capacity usually need to expand too.
What is the practical difference between basic personalization and true real-time orchestration?
Basic personalization changes a message using stored attributes or campaign rules. Real-time personalization adapts instantly based on current behavior and data, and cross-channel orchestration coordinates that decision across digital touchpoints from one layer. If event data is not turning into usable attributes fast enough for activation, you are still doing better targeting, not true real-time orchestration.
How should leadership prioritize rollout across data, orchestration, and AI decisioning?
Start with infrastructure readiness, then expand orchestration and heavier AI decisioning. That sequencing matters because weak foundations create predictable first-year problems: fragmented data, latency, and rising operating cost. If leadership is choosing where to spend next quarter, fund profile quality and data foundation work before expanding model complexity.
Which operating risks matter most in year one of implementation?
The big three are fragmented data, latency, and cost pressure, and they usually compound each other. In practice, that can look like stale profiles feeding poor decisions and teams spending more time reconciling outputs than improving outcomes. A useful early warning check is a weekly review of one live journey that verifies profile freshness, channel handoff success, and downstream operational fallout.
Should we build in-house or use platforms like Braze, Adobe, Twig, or Attentive first?
Use a platform first if your team needs cross-channel journey orchestration quickly and your logic changes often enough that internal maintenance would become a tax. Build more in-house only when you have clear requirements the vendor layer cannot meet, such as custom decision logic, tighter internal integrations, or specific control needs. Whatever you choose, test the same operator questions before signing: can you override decisions, inspect outcomes, and recover cleanly when a handoff fails?
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
- cisa.gov/sites/default/files/publications/Incident-Re...trusted
- csrc.nist.gov/projects/incident-responsetrusted
- ecfr.gov/current/title-31/subtitle-B/chapter-X/part-1...trusted
- ecfr.gov/current/title-31/subtitle-B/chapter-X/part-1...trusted
- fdic.gov/banker-resource-center/anti-money-laundering...trusted
- fedramp.gov/docs/rev5/playbook/csp/continuous-monitoring...trusted
- irs.gov/forms-pubs/about-form-w-9trusted
- irs.gov/forms-pubs/about-form-w-8-bentrusted
Educational content only. Not legal, tax, or financial advice.
Related Posts

Airline Delay Compensation Payments for Customer Experience and Control
If you are evaluating an `airline compensation payments customer experience delays platform`, split the work into three lanes first: legally owed refunds, discretionary compensation, and outsourced claims recovery. Vendor pages often blur these together, but they lead to different policy choices, ledger treatment, and customer outcomes.

How Platform Teams Scale AP Volume Without Adding Headcount
Use this as a decision list for operators scaling Accounts Payable, not a generic AP automation explainer. In these case-study examples, invoice volume can grow faster than AP headcount when the platform fit is right, but vendor claims still need hard validation.

How Platforms Validate Bank Accounts Before Mass Payouts
For mass payouts, the real question is not whether to verify payees. It is how much verification you require before release, who can override it, and what evidence you can produce later. If you cannot show that evidence on demand, your release rule is weaker than it looks.