
Quick Answer
Build it as an operations surface, not a help center. A strong self-service subscriber portal platform features ux implementation starts with table-stakes channels (FAQ, knowledge base, ticket tracking, mobile-ready UX), then adds payment-state clarity tied to webhook ingestion and ledger posting. Use explicit statuses such as processing, posted, failed, returned, and canceled, and only show final states after proof exists. If a user cannot complete a task, escalate with preserved context instead of forcing re-explanation.
What Finance and Ops Need From Self-Service#
A self-service subscriber portal is not just a nicer front end for support. Built well, it becomes a shared payment operations surface for finance, ops, and product. Subscribers can resolve simple issues themselves, and your team can align what the portal shows with underlying reconciliation and payout records.
That distinction matters because the goal is twofold. You want lower support volume through ticket deflection, but you also want fewer avoidable handoffs, cleaner status handling, and less confusion when money is moving. A portal that only answers common questions helps your FAQ page. A portal that shows usable payment states helps your operators too.
The standard to aim for is visibility that can be checked, not just visibility that looks clean in the UI. For payouts, that means explicit statuses such as processing, posted, failed, returned, or canceled where your provider supports them. Do not rely on vague labels like "done" or "in progress." For reconciliation, it means tracing each payment, refund, chargeback, and transaction cost back to the payout batch it belongs to. If a subscriber can see a status but your team cannot explain the record behind it, the portal is only moving work from one queue to another.
A good early checkpoint is simple. For every self-serve action or visible status, confirm the source record, the owner, and the escalation path. The source record might be a provider event or a settlement reconciliation export. The owner might sit in finance or ops, not support. The escalation path should be explicit enough that unresolved cases land in your ticketing system with the right context attached, instead of forcing a subscriber to explain the same issue again.
One common failure mode is showing finality too early. A payout can be initiated, look healthy, and still end up returned later. In Stripe Global Payouts documentation, payouts are typically returned within 2 to 3 business days, though timing depends on the recipient country. That is why this guide focuses on decision points, failure checkpoints, and audit-ready visibility instead of generic portal UX advice.
Keep one scope rule in view throughout. Features vary by market, program, geography, and integration path. Some capabilities are only available where supported or when enabled. If you do not state that boundary clearly in requirements and in-product copy, you will overpromise early and create exceptions later.
You might also find this useful: Vendor Portal Requirements Checklist: Permissions Approvals Audit Trails and Self-Service Workflows.
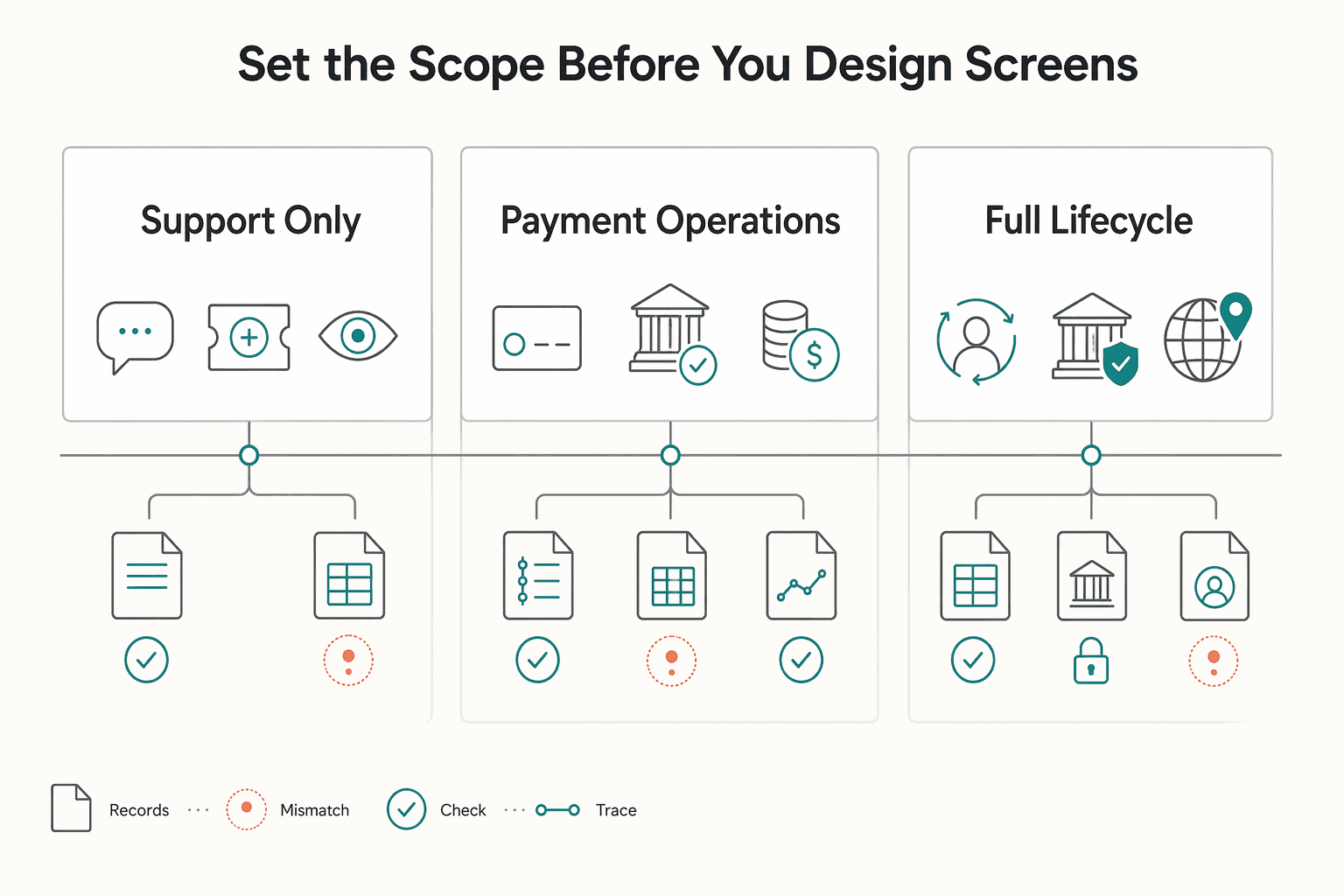
Set the scope before you design screens#
Set the operating boundary before you design screens, or the portal will promise actions your teams cannot reliably support.
| Scope | Includes |
|---|---|
| Support-only | Answers, case creation, and status visibility |
| Payment operations | Subscriber actions tied to reconciliation, settlement, or payouts |
| Full lifecycle | Can include virtual accounts and Merchant of Record responsibilities, but only where your market and program support them |
Step 1. Define the boundary in plain terms. Choose one scope: support-only, payment operations, or full lifecycle. Support-only covers answers, case creation, and status visibility. Payment operations adds subscriber actions tied to reconciliation, settlement, or payouts. Full lifecycle can include virtual accounts and Merchant of Record responsibilities, but only where your market and program support them. If MoR is in scope, document that it is the entity the processor recognizes as the seller so ownership and obligation language stays accurate.
Step 2. Lock minimum prep inputs before build. Before UI review, prepare:
- A RACI matrix for finance, ops, product, and engineering.
- Your current ticketing system taxonomy, including case types and escalation queues.
- Knowledge base gaps that currently drive support contact.
Use this as a gate: each planned page or action should map to one accountable owner and one source of truth.
Step 3. Set the self-serve boundary action by action. Keep lower-risk actions self-serve, and escalate actions that affect money movement, legal responsibility, or exception handling unless you can attach an audit trail. Capture who requested the action, when it happened, and what changed so agents do not have to reconstruct context later.
Step 4. Define success checkpoints before launch. Set support and operations checkpoints up front: ticket deflection, first-contact resolution, reconciliation lag, and settlement exception volume. If a feature does not reduce subscriber uncertainty or internal handling time against one of these checkpoints, cut it from phase one.
Choose mandatory features first and stage advanced features later#
Start with features that let a subscriber find answers, submit a request, and track status in one place. If a feature does not clearly reduce subscriber uncertainty or internal handling time, defer it to phase 2.
| Feature or channel | Tier | Use it for | Launch guidance |
|---|---|---|---|
| FAQ page | Table stakes | Fast answers to repeated, low-risk questions | Include at launch for narrow, stable questions, then link to deeper help. |
| Knowledge base | Table stakes | Detailed how-to and policy guidance | Include at launch, and surface suggested articles during request intake. |
| Ticketing system | Table stakes | Submit, update, and track requests | Include at launch. Request tracking is baseline self-service. |
| Responsive design | Table stakes | Usable layouts across desktop and phone | Treat as a launch criterion. |
| Mobile-first design | Table stakes | Core actions on phone screens | Treat as a launch criterion when users submit requests or check status from phones. |
| In-app guides | Guidance channel | Completing a known task in context | Use when the user is already in the right workflow and needs short, in-context help. |
| Chatbot | Guidance channel | Triage, answer retrieval, and routing | Use when intent is unclear or volume is high, but avoid making it the only route for complex tasks. |
| Community forum | Guidance channel | Reusable peer discussion | Use for repeat, non-sensitive questions, not private account-specific cases. |
| Webhook status tracking | Advanced operations | Event-driven status updates | Stage for phase 2 unless you already have a clear status model and async event handling. |
| Idempotency key safeguards | Advanced operations | Retry safety for write actions | Move earlier if users can retry money-related actions; same key should return the prior result. |
| Payout exception views | Advanced operations | Visibility into payout exception handling | Add after launch unless payout operations are already in scope and owned operationally. |
Be strict about channel fit. In-app guides help users finish a task already in progress, chatbots help route unclear intent, and forums help with repeat discussion. If your chatbot cannot pass intent and key context into the Ticketing system, it creates duplicate work instead of reducing it.
For each self-serve action you include at launch, require three checks: current status is visible, next action is clear, and the escalation path is explicit with context preserved. Validate this end to end: trigger intake, confirm Knowledge base suggestions appear while typing, submit the request, and verify status is accessible on phone and desktop. For retry-prone money-adjacent actions, test repeated submission and confirm idempotent behavior.
Design UX that lowers tickets without hiding financial complexity#
Design the default experience for quick resolution, then let users expand into operational detail when needed. In practice, that means simple first actions for most subscribers, with drill-down access to Ledger entries and Reconciliation evidence when a case moves beyond basic support.
Organize around subscriber tasks#
Use task-based navigation first. Labels like "track payout," "resolve failed settlement," and "submit tax form" are clearer than internal team labels because users arrive to complete a job, not decode your org chart.
In payment flows, this is critical when status is unclear. Users need to see why something failed, what happens next, and when resolution is expected. Task-first paths get them to that answer faster, then route to the right backend systems behind the scenes.
Run a simple check before launch: pick three real tasks and confirm a first-time user can reach the right flow without knowing which team owns settlement, payment records, or tax operations.
Use progressive disclosure for operational detail#
Keep the default view focused on three items: current status, next action, and escalation path. Then expose deeper detail on demand, including the transaction-level records and Reconciliation evidence ops uses in exception review.
Avoid both extremes:
- Hiding too much detail, which pushes routine questions into support
- Showing all operational detail up front, which makes simple actions harder than they need to be
Before signoff, define drill-down scope for ops permissions: what evidence is visible in expanded views, and what remains internal-only.
Carry context into escalation#
Treat unresolved FAQ and chatbot paths as escalation triggers to live-agent support, with context carried forward. The goal is continuity: the agent should pick up the case without forcing the user to restart.
At minimum, carry:
- selected task
- FAQ article viewed or chatbot intent reached
- conversation transcript or summary
- current visible payment status
- fields already entered by the user
Test this end to end before launch. If escalation produces a blank ticket and the user has to restate everything, the self-service layer is adding friction instead of reducing avoidable tickets.
Expose the payment state model subscribers can trust#
Subscribers trust your portal when each visible state maps to a specific operational checkpoint, not loose provider wording. Publish one subscriber-facing status dictionary across Virtual Accounts, Settlement, and Payouts, and map provider-specific events into it internally.
Define one subscriber-facing status dictionary#
Use one dictionary in the UI, and make clear it is your product definition rather than a universal provider standard. This is especially important for labels like "held" and "completed," which are not consistent across providers.
| Portal status | Operational meaning | Verification checkpoint |
|---|---|---|
| Processing or Pending | The payment instruction or inbound movement exists, but final posting is not complete | Provider event received or payment initiated, with no final posted entry |
| Posted or Completed | Funds are confirmed and the transaction is created and posted | Posted transaction exists and ties to the provider reference |
| Failed | The payment did not complete | Failure event is recorded, with no successful posting for that payment |
| Returned | Funds did not arrive at the destination and came back | Return event is recorded and return handling is visible in finance records |
| Canceled | The payment was stopped before completion | Cancellation event or action is recorded before final posting |
Do not show a final success state from an early success-like provider event. Use the confirmed-and-posted milestone as the defensible point for "posted" or "completed" status.
Update statuses in a fixed sequence#
Keep visible updates in a fixed order every time: provider event -> Webhook ingestion -> Ledger posting -> portal status update -> subscriber notification. If the order breaks, the subscriber can see a final state before finance can verify the posting.
Test this with one real payout, one inbound Virtual Account deposit, and one settlement case. For each, confirm you can trace provider reference -> webhook receipt -> posted entry -> exact portal status shown to the subscriber. If any link is missing, the state model is not ready for audit or monthly Reconciliation.
Write failure-mode rules before launch#
Define explicit rules for unmatched deposits, delayed confirmations, and duplicate event delivery before launch. Webhook consumers can receive the same event more than once, so duplicates must not create duplicate postings, duplicate notifications, or backward status changes.
| Scenario | Portal handling | Rule |
|---|---|---|
| Unmatched Virtual Account deposit | Show a non-final state like received, matching in progress | Do not show failed |
| Delayed provider confirmation | Keep the state as processing or pending until posting is complete | For returns, message that they are typically seen within 2-3 business days, but can take longer |
| Duplicate event delivery | Ignore the second one for state progression unless it adds new information | Never send a second final-state notification from a duplicate delivery |
For each status transition, keep a compact evidence pack: provider event ID or reference, webhook receipt timestamp, posting reference, portal status before/after, and notification record when sent. These checkpoints let finance prove traceability during Reconciliation and investigate missing payments or bookkeeping errors.
Add compliance and tax gates without creating dead ends#
If you block a user, make the block practical: state the policy gate, what is missing, and what they can do next. Generic errors like "verification failed" hide the real issue and drive avoidable support tickets.
Make each policy gate explicit in the UI#
Show KYC, KYB, AML, and VAT validation as named checkpoints, not hidden outcomes. Under AML, customer identification is part of the program, so your identity step should request required data such as name, date of birth, address, and identification number. For legal entities, state that beneficial-owner identification and verification are required.
For each blocked state, show:
- Policy area
- Missing or failed item
- Next action
For VAT checks, clarify whether the issue is number format, lookup failure, or a no-match result from VIES VAT number validation.
Separate visibility from high-risk actions#
When compliance evidence is incomplete, keep read-only visibility where your program allows it, and block high-risk actions like payout release or other money movement. If your regulated setup requires stricter restrictions, enforce that and state it clearly in-product.
Avoid dead ends by keeping history and context visible (transactions, tax status, open requests) while disabling blocked actions with plain remediation text and an escalation path.
Design tax-form flows for correction and scope clarity#
Be explicit about why each form appears:
| Form or topic | Article guidance |
|---|---|
| W-9 | Collect correct TIN data for information-return workflows |
| W-8 BEN | Collect when requested by the withholding agent or payer |
| Form 1099 | Specify the variant you support, such as Form 1099-NEC for nonemployee compensation |
| FEIE | If enabled, support guidance or intake; ties to Form 2555 |
| FBAR | If enabled, support guidance or intake; triggered when aggregate foreign financial accounts exceed $10,000 at any time during the calendar year |
Use caveat language on tax and VAT screens so users do not over-assume coverage: available only where supported and enabled for the market or program. If you use masked-field review or retry handling, present those as program features, not universal behavior.
Implement in sequence so retries are safe and auditable#
Build in this order: contracts, ingestion, idempotent writes, then portal status. If you surface status before retries and dedupe are reliable, you get a fast UI that finance cannot trust.
First, finalize API contracts and the event schema. Every write endpoint with financial side effects should require an Idempotency key, and every event should include a stable event ID, event type, occurrence timestamp, object reference, and processing status. Keep command payloads separate from status payloads so stale updates are easier to detect. Checkpoint: send the same event twice with the same event ID and confirm the second delivery is recorded as a duplicate, not processed as a new action.
Next, implement Webhook ingestion and deduplication before wiring subscriber-visible status. Assume repeat delivery from day one: persist the raw event, check whether the event ID was seen, then process downstream. If you cannot answer "have I already handled this exact event?", retries are not reliable yet.
Add stale-event rejection in the same step using state validity, not a universal timeout. Accept an event only when the referenced object is still in a valid state for that transition. In separate auth/capture card flows, capture should occur only from the correct state, and uncaptured payment intents cancel after 7 days by default. Checkpoint: replay a known webhook event and confirm the action is not duplicated and portal status does not flicker.
Enforce idempotent writes against the ledger#
Treat idempotency as a shared contract across API, workers, and internal retry jobs. Retry with backoff is only safe when the underlying operation is idempotent; otherwise duplicate partial effects can corrupt state.
Use the ledger as the authoritative record, and present wallets or balances as derived views. Asynchronous processing can leave reads stale for a few seconds, so mark derived balances as updating until the underlying posting is confirmed. Show completed only after the posting exists. Checkpoint: resend the same write request with the same Idempotency key and verify one side effect, one posting, and a deterministic response.
Wire portal statuses to auditable records#
Expose portal status only after ingestion and idempotent writes are stable. Wire status in this sequence: provider event -> webhook ingestion -> posting -> portal update. This keeps subscriber-facing labels tied to auditable records instead of intermediate state.
Final checkpoint: cross-check portal status, posted entries, and Reconciliation exports on a sample set. If those records disagree, fix the status source rather than patching the UI.
Common mistakes that break trust and how to recover fast#
After your write path is auditable, trust usually breaks in the status layer. The pattern is consistent: the portal sounds final before records are final, uses mixed language across surfaces, hides compliance blockers, or lets retries create duplicate effects.
- Bind final-success labels to proof, not optimism.
Only show completed when the ledger posting is confirmed and tied to a provider reference. Payouts can show as paid and still move to failed or canceled (including within 5 business days), and on auth/capture rails, authorization alone is not completion. If that proof is not available yet, use pending or processing.
Recovery checkpoint: review cases where status later changed and confirm portal history preserved the intermediate state instead of presenting it as final.
- Use one status dictionary across product, support, and help content.
If the UI, Ticketing system, and Knowledge base use different words for the same state, subscribers have to guess. Define one canonical set of subscriber-visible statuses and apply it everywhere.
Recovery checkpoint: compare recent tickets against portal copy and help text. When one condition has multiple names, fix the vocabulary before you add new screens.
- Make compliance blocks explicit and remediable.
A silent KYC/AML block looks like a product defect. Show the blocking reason in plain language, list what information is required, and show the review path, for example, submitted, under review, or more information required. When available, map provider verification requirements and errors directly into the portal.
Recovery checkpoint: support and the subscriber should see the same required-items view and latest submission state.
- Treat duplicate retries as normal and suppress them by design.
Webhook systems can deliver the same event more than once, so duplicate handling is mandatory. Enforce the same Idempotency key contract at write endpoints and alert ops when the same key or event ID repeats.
Recovery checkpoint: replay an event and retry the same write with the same key. The expected result is one business effect, one posting, and a duplicate-caught marker for ops.
If you want a deeper dive, read Supplier Portal Best Practices: How to Give Your Contractors a Self-Service Payment Hub.
Conclusion#
The right build is a control-first portal, not a prettier ticket form. If you cannot show clear self-serve actions, explicit state changes, and a clean handoff to human support, you are not ready to launch.
Use this checklist as your last gate before release. The point is not feature count. It is whether your subscriber view, your support tools, and your finance evidence all tell the same story.
- Confirm the table-stakes surfaces are live.
Publish the Knowledge base, FAQ page, and Ticketing system entry points, and verify the portal works on responsive and mobile layouts. The practical check is simple: pick three common tasks such as track payout, resolve a failed status, and, where applicable, submit a tax form, then complete each on a phone without forcing the user into free-text support. If a path ends in confusion, add the missing next step or escalation route before launch.
- Trace every visible status from
Webhookto posting to subscriber UI.
Payment events are asynchronous, so launch criteria should include Webhook ingestion, duplicate-event handling, and replay testing. A hard rule is simple: if you replay one known event, you should get one business outcome, one posting, and one subscriber-visible update. If that chain breaks, or if duplicate events can change the visible state twice, your portal will create trust problems faster than it reduces tickets.
- Require retry protection and audit evidence before you expose money movement states.
For POST retries, the same Idempotency key must reuse the prior result once execution has begun, rather than creating a second outcome. That matters most on writes tied to payout actions, account updates, or any state transition that can affect balances. Your verification pack should include the source event ID, the write request ID, the posting reference, and whatever reconciliation evidence your finance team uses to prove the status was earned, not assumed.
- Make compliance and tax gates practical, then monitor outcomes weekly.
KYC and AML blocks should explain what is missing, what document is needed, and what review state comes next. For tax collection, keep the exact form request clear: W-9 is used to provide the correct TIN, while W-8 BEN may be requested from a foreign person by the payer or withholding agent. Do not treat those forms alone as full compliance coverage. Also make sure beneficial-owner identification and verification procedures exist where required, and keep an evidence path that support and audit teams can actually retrieve.
After launch, review the same core metrics on a weekly cadence: ticket deflection, exception aging, payout failure rate, and reconciliation close time. If one of those moves the wrong way, go back to the broken status, gate, or handoff first. That is where most portal trust failures start.
Frequently Asked Questions
What features are mandatory in a self-service subscriber portal for payment operations?
Start with searchable Knowledge base content, case logging and tracking, and clear status views for self-serve actions that can affect money movement or compliance. Define the case intake fields early so users can log and view cases without free-text chaos. A good launch rule is simple: if the action exists, the portal should also show current status, next step, and how to escalate.
How do you design portal UX that reduces tickets without hiding critical payout and settlement detail?
Use task-based navigation such as track payout, resolve failed Settlement, or submit tax form, then reveal deeper detail only when needed. Keep the first screen plain, but let users drill into timestamps, references, and supporting records when something looks wrong. Weak account and self-service UX is common in practice, so the bar is not a pretty interface. It is whether users can answer the next practical question without opening a ticket.
Which implementation steps should come first, and what can wait until phase 2?
A practical order is: define API contracts and event schema, then implement Webhook ingestion with duplicate-event handling, enforce Idempotency key checks on writes, and connect subscriber-facing statuses to the underlying book of record. Verify behavior with replay tests and duplicate-event simulation before adding nicer surfaces. Phase 2 can include richer guidance layers like chatbot or community features if they materially reduce uncertainty or handling time.
How should unresolved self-service flows hand off to human support?
Do not make users restart the story in a ticket. When the portal, FAQ, or bot cannot finish the task, open a pre-filled Ticketing system case that carries current status, last event time, provider reference, and any document checklist already shown to the subscriber. The handoff should follow your existing routing flow so the right live agent is notified, not just a generic queue.
How do `Webhook` delays and duplicate events affect subscriber-visible statuses?
They are normal, so your portal copy has to expect them. Provider events are asynchronous, and webhook endpoints can receive the same event more than once, so show a holding state like pending or processing until the event is ingested and the authoritative result is reflected. A practical checkpoint is to replay one known event and confirm duplicate delivery does not create duplicate subscriber updates.
How do you apply `KYC`, `KYB`, and `AML` gates without killing completion rates?
Make the block explicit and practical: say what is missing, what document or field is required, and what review state comes next. For US-person tax collection, that can mean W-9 TIN collection; for foreign persons, W-8BEN may be requested by the payer or withholding agent; and for legal entities, KYB can include beneficial ownership verification. Keep blocked actions read-only instead of letting users retry blindly into the same failure.
What should be visible to subscribers vs. internal teams for `Ledger` and `Reconciliation` data?
Subscribers need understandable facts: amount, date, status, and reference points that explain where the payment stands. Internal teams need the audit trail behind that view, including posted entries, reconciliation evidence, and the source ID that ties a balance transaction back to the underlying payment object. If support cannot trace a portal status to that underlying record quickly, your drill-down is too shallow.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
- docs.stripe.com/webhookstrusted
- docs.stripe.com/global-payouts/manage-payoutstrusted
- ec.europa.eu/taxation_customs/viestrusted
- ecfr.gov/current/title-31/subtitle-B/chapter-X/part-1...trusted
- ecfr.gov/current/title-31/subtitle-B/chapter-X/part-1...trusted
- federalreserve.gov/frrs/regulations/section-1020220-customer-id...trusted
- irs.gov/forms-pubs/about-form-w-9trusted
- irs.gov/forms-pubs/about-form-w-8-bentrusted
Educational content only. Not legal, tax, or financial advice.
Related Posts

Supplier Portal Best Practices for a Self-Service Contractor Payment Hub
If you are building a **supplier portal self-service contractor payment hub**, the real issue is not terminology. It is whether the portal cuts payment-support load without weakening control or reconciliation.

What Is a Supplier Portal? How to Give Contractors Self-Service Access to Payment Status and Documents
A supplier portal can answer routine payment-status and document questions so fewer requests become support tickets. Oracle defines this as a secure self-service channel for buyer-supplier transactions, and SAP describes status portals as self-service access to invoice status and details. For contractor payout operations, this is a practical baseline: clear status visibility and usable document access.

Vendor Portal Requirements Checklist for Platform Payment Ops
A useful **vendor portal requirements checklist** starts with money movement, not screen mockups. Define which actions can create an obligation, release funds, or only capture data. Then set the control, evidence, and reconciliation rules before finance, ops, and product start building inside the same boundary.