
Quick Answer
Build a payment notification system by defining one shared event record first, then routing email, SMS, and in-app alerts from that source of truth. Keep the in-app center as the durable history, apply severity-based channel rules, enforce consent and policy checks at send time, and test replay, deduplication, escalation, and auditability before expanding rollout.
What a Contractor Payment Notification System Needs to Do#
Build the record first, then the channels. Across email, SMS, and in-app alerts, trust comes from one event history, not three competing versions of what happened.
Sending messages is often the easy part. The hard part is keeping events, webhook-driven updates, and user-visible records aligned when delivery is delayed, messages bounce, or channels are received at different times. This guide focuses on that consistency problem so you can move quickly without creating reconciliation debt.
Treat channels as complementary, not interchangeable. Email and SMS can draw attention, while the in-app notification center serves as the durable history users can return to. If someone misses an external message, they should still be able to reconstruct recent updates in-app.
The scope here is intentionally narrow: source events, implementation order, failure handling, and launch checks. The sequence matters. Start with source events, then route by channel, then wire up webhook and event handling. Keep delivery and error tracking in place so production issues are debuggable instead of guesswork. For a related walkthrough, see How to Build a Milestone-Based Payment System for a Project Marketplace.
Define the contractor payment events before choosing channels#
Start with events, not channels. If you design email, SMS, or in-app flows first, teams can end up arguing about timing and copy before they agree on whether the underlying payment update is true.
Draft one event list your team will use#
Create a single, owned list of payment checkpoints before you route anything to a channel. A practical starting set can include an approval checkpoint before invoicing, invoice creation with an invoice identifier, and reminder checkpoints before the due date, on the due date, and after the due date.
If your flow has an approval checkpoint before invoicing, model it explicitly so "invoice created" has a clear proof point. For each event, require a one-sentence answer to one question: what objective signal makes this event true?
Mark where each event can originate#
Separate origin sources so your team knows which system is asserting each update.
From day one, store an evidence reference with each event, and record message receipt or acknowledgment when an alert requires a response. That gives support, finance, and engineering the same record to inspect when a status is challenged.
Define allowed transitions before notifications#
Write allowed transitions for each event family so notifications cannot jump to a reassuring final message without intermediate proof. Keep this practical. Block impossible jumps first, then refine edge cases.
Replay realistic timelines before you implement channel logic, including a normal path and delayed updates. If those timelines produce contradictory user messages, fix the event model before you touch templates or routing.
Store a minimum audit-friendly event payload#
Capture enough context to explain each event later. Keep a compact payload with the event name, invoice identifier when relevant, and the evidence record that supports the update.
Be explicit about what each field means. Note who or what triggered the event and which artifact supports the claim, such as an approval record, invoice record, or acknowledgment log.
For more on that, read Push Notification Strategy for Payment Platforms: How to Alert Contractors About Payouts.
Map event severity to channel selection rules#
Once your event list is stable, turn it into channel policy. Decide when a channel is allowed, who approves it, and what evidence must exist before anything is sent.
Build a small severity matrix with authorization fields#
Keep the matrix compact enough that payments, product, and ops can actually review it. Define each tier by business impact, then record the trigger condition, allowed channels, required evidence, escalation owner, and success signal.
Treat high-interruption channels as authorized actions, not defaults. If the event record does not have the required approval state and evidence reference, the intrusive route is not authorized.
Convert urgency into testable routing rules#
Write each rule so engineering can implement it and support can explain it: event condition, allowed channels, escalation owner, and required proof. That keeps channel choice consistent during live incidents instead of turning it into improvisation.
This gives you authorization and correction checkpoints, but you still need to define channel-by-channel severity routing. Add a correction gate before any high-severity route: approve first or require corrections, and avoid final-sounding messages while the underlying artifact is still correction-required.
Add suppression and correction handling for noisy event sequences#
Do not map every state change to an interruptive message in high-volume event flows. Reserve those channels for moments that are truly action-required, and keep intermediate transitions in lower-interruption surfaces.
Plan for reversals too. If an event is later corrected, suppress conflicting follow-on alerts or replace the earlier notice with one corrected message tied to the same evidence trail.
Review policy on a fixed reporting cadence#
Review policy like a reporting control, not a copy review. A grounded pattern is quarterly electronic reporting, including no-activity reporting, with a concrete artifact format such as an Excel spreadsheet transmitted electronically.
Apply that same discipline to your routing matrix. Report which tiers fired, which channels were used, and which rules stayed idle. If you need program-specific overrides, make them explicit with an owner and effective date so channel differences stay explainable and auditable.
Gather prerequisites and artifacts before engineering starts#
Before you write routing code, lock approvals, dependency boundaries, and audit artifacts. If you skip this step, you can end up reworking channel logic after controls are reviewed.
| Prerequisite | Lock before coding | Evidence or control |
|---|---|---|
| Make ownership and approval explicit | Who approves channel policy and who signs off on incident handling | Written proof of prior approvals before activation; written amendments for later changes |
| Inventory compliance and identity dependencies | Legal, compliance, and consent dependencies; identity and access controls for who can approve, resend, suppress, and investigate notices | Confirm current requirements with appropriate reviewers; published guidance is not legal or compliance sign-off |
| Register document steps early | Stable identifiers, owner teams, and evidence references for future event sources | Register them early even if phase one does not notify on them |
| Define the minimum Audit Trail package | Transaction-level audit events and related activity/data-access records tied to an audit trail | Validate with one end-to-end test event tied to a single identifier; produce quarterly electronic reporting, including explicit "no activity" periods where applicable |
Make ownership and approval explicit#
Create a compact ownership map across relevant teams with two named decisions: who approves channel policy and who signs off on incident handling. Treat policy activation as a control checkpoint, with written proof that the required prior approvals were obtained before anything becomes binding.
Handle change control the same way. If you later change escalation behavior or channel use, require written amendments so you can show why a notification did or did not send.
Inventory compliance and identity dependencies#
Before coding, list the legal, compliance, and consent dependencies that can block or reshape notifications. Pair that with identity and access controls for who can approve, resend, suppress, and investigate notices.
Use IAM guidance to structure those controls, but do not mistake that guidance for legal or compliance sign-off. Treat published guidance as potentially dated, and confirm current requirements with appropriate reviewers before enabling live outbound messaging.
Register document steps early#
Track additional document or regulatory milestones as potential future event sources, even if phase one does not notify on them. Define stable identifiers, owner teams, and evidence references early so those events are usable later instead of becoming another retrofit.
Define the minimum Audit Trail package#
Set a minimum observability package before implementation: transaction-level audit events and related activity/data-access records tied to an audit trail. A grounded pattern is recording each application transaction as an audit event.
Validate it with one end-to-end test event tied to a single identifier. Your evidence pack is not complete until you can also produce quarterly electronic reporting, including explicit "no activity" periods where applicable.
Related: Xero Integration for Payout Platforms: How to Sync Contractor Payments with Your Accounting System.
Choose what to build versus what to buy for delivery#
Buy delivery capability before you outsource notification decisioning. If contractor alerts must follow internal payment state and audit expectations, keep orchestration in-house and use external tools as channel adapters.
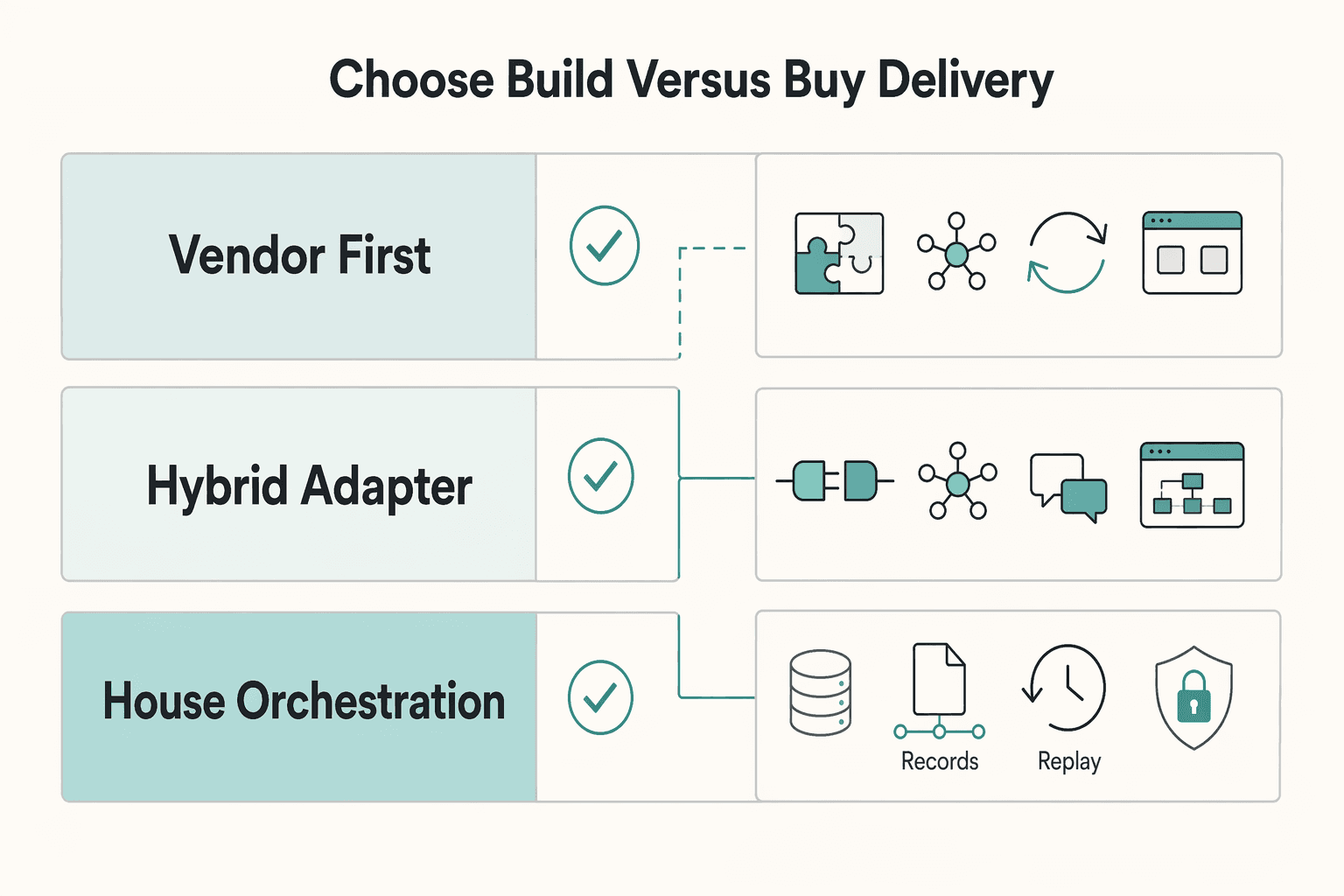
Choose based on integration depth, not channel count. Multi-channel alerts, two-way responses, integration-driven automation, and low-to-no-code setup are real strengths in modern notification products. Those claims do not establish payment-specific API or webhook compatibility, or replay behavior, so treat both as validation items.
| Pattern | When it fits | What to verify first |
|---|---|---|
| Vendor-first orchestration | Informational alerts, reminders, and lighter coupling to payment events | Whether routing and exports preserve your internal identifiers and retry expectations |
| Hybrid adapter model | Internal payment events with outsourced channel sending | Whether delivery outcomes map cleanly back to your event IDs and audit records |
| In-house orchestration and delivery | Strict replay requirements and high dependency on exact internal state transitions | Whether your team can operate channel reliability, consent controls, and monitoring over time |
Pick for coupling, not breadth#
Use a simple rule: if a message must follow your payment event model exactly, keep orchestration inside your platform. Let email, SMS, and in-app providers receive channel intents only after your system has already made the decision. If the use case is mostly reminders or broad status communication, vendor-first can be enough.
Evaluate candidate tools for delivery and configuration speed, but do not score them on channel breadth alone.
Stress-test lock-in and replay behavior#
Before you sign, run a staging test with duplicate and out-of-order events. Confirm whether you can preserve your Idempotency Key semantics and internal API event contracts without rewriting them into vendor-only routing logic.
The pass condition is straightforward: deterministic handling in staging, no duplicate contractor-facing alert for deduped events, and delivery records that still tie back to your original internal identifier.
Keep a decision evidence pack#
For each option, keep a compact artifact set: field mapping, resend behavior, suppression behavior, export sample, and delivery outcome mapping back to audit records.
If identifier round-trip is weak, keep that vendor at the edge as a delivery adapter. You still get speed where it helps, without giving up control of payment-critical notification logic.
Design a notification contract that survives change#
Treat your notification contract like a controlled internal document, not a loose implementation note. Make every change explicit and documented.
A useful control pattern here is amendment tracking with a clear amendment number and issue date, plus explicit labeling and submission checkpoints. Apply that same discipline to your contract history: record what changed, when it became effective, and keep revision notes aligned with the current spec.
Be just as clear about what is not established here. The source material does not define a formal payment-notification payload standard, required payload fields, per-channel rendering rules, or consumer backward-compatibility semantics.
Use that boundary during review. What is supported here: explicit change tracking and documented amendment history. What is not established here: required notification payload contents, SMS, email, push, or in-app message rules, replay or dedup behavior, or audit-trail schema requirements.
If you need hard requirements for those unknowns, define them as internal policy and validate them before rollout.
Implement ingestion and routing with replay safety#
Make ingestion and routing deterministic first. If retries create new alerts instead of replaying prior outcomes, the rest of the stack will not save you.
Use a shared mediation layer between event sources and notification sinks, not scattered channel-specific logic. Model both subscription and delivery as events in that framework, then run incoming notifications through one shared ingress and persist the raw payload before downstream business logic. Exact webhook verification mechanics are provider-specific and not established by these sources.
How you implement verification checks and metadata handling is an internal choice, but the control objective is stable: keep an immutable accepted-event record you can inspect and replay when retries or network disruption create ambiguity.
Treat deduplication as a routing gate, not a dispatch-only patch. Define an internal deduplication contract so repeated deliveries resolve to the same normalized event and routing result, not to new sends or duplicate in-app alerts. The specific key format, retention window, and hashing method are internal choices rather than source-validated requirements.
Keep one orchestration path with explicit checkpoints and linked audit trail records so outcomes are traceable end to end, for example from accepted event to normalized event to routed intent and final delivery status.
This checkpoint chain can sit inside the operating model you define internally, so validate it directly against provider behavior and downstream consumer needs.
Build the in-app alert center as the primary source of truth#
If users have to piece together update history from inboxes and text threads, notifications become harder to trust. The in-app center should be the persistent record, with SMS or push mainly pulling people back to that history.
Center the alert history in the app#
Build the notification center as a persistent in-app record of updates. A practical pattern is a bell icon, an unread badge, and a dropdown with timestamped previews, plus a full-page inbox for deeper review.
Keep the experience consistent across surfaces. The unread badge, dropdown preview, and full-page inbox should all reflect the same alert history so users can recover what they missed without stitching together fragments from different channels.
Make status clear to users and operators#
Use clear labels for unread and reviewed items so users can quickly see what is new. Those labels also help support and operations understand what happened without guessing.
Keep the wording direct and action-oriented so a user can quickly tell whether an alert is informational or needs a next step.
Keep alert details practical#
For important alerts, include enough context in the detail view for users to understand the update and what to do next. This is where action buttons and clear message detail do more work than short channel prompts alone.
The goal is to reduce back-and-forth. Users should be able to move from notification to action inside the app, not go hunting for context elsewhere.
Preserve one coherent timeline across channels#
When users miss updates in other channels, the in-app center should still hold the full alert context, with cross-channel sync helping keep the timeline coherent. Secondary channels can still prompt attention, but the in-app record should remain the place users and teams trust for history.
That avoids fragmented stories. It also makes it easier to review what was delivered, what is unread, and what may need action.
This pairs well with our guide on Build a Global Contractor Payment Compliance Calendar for Monthly, Quarterly, and Annual Obligations.
Add compliance and consent gates to notification logic#
Compliance should be enforced in dispatch logic, not in template wording alone. If your system cannot prove a send is allowed, hold that channel and rely on the authenticated in-app record.
Gate outbound sends on documented consent and policy checks#
Treat consent and jurisdiction checks as a final send gate, not a template concern. If your system cannot resolve whether a send is allowed, fail closed for that channel and use the in-app record as the fallback.
Document how consent data moves between teams and vendors with explicit artifacts. Aim for the level of specificity you would expect in formal documentation artifacts like sample information exchange agreements and sample forms, not informal notes.
For TCPA-sensitive SMS programs and similar regulatory areas, define exact rules with legal and compliance owners because those thresholds and requirements are not established here.
Keep message content narrow and enforce secure link paths#
Keep open-channel content to status, required action, and a path to authenticated detail. Keep sensitive context out of preview surfaces and full message bodies.
For any destination handling sensitive information, verify secure transport with HTTPS. If a workflow points users to a U.S. government site, verify both .gov and HTTPS, and share sensitive information only on official, secure websites.
Align payout alerts with policy-state handling#
Do not let notifications imply finality when policy or identity review may still change the outcome. When a hold or review state exists, keep the external message neutral and move the fuller explanation into the authenticated in-app experience.
Specific KYC and AML disclosure boundaries, and channel wording requirements, are not established here, so set those rules explicitly with your compliance team before enabling sends.
For related implementation context, see QuickBooks Online + Payout Platform Integration: How to Automate Contractor Payment Reconciliation.
Handle failure modes and escalation before launch#
Failure handling is not polish work for later. A missed critical alert can put people at risk, so detection, escalation, and recovery should be tested before go-live.
Model the failure cases you will test on purpose#
Define failure scenarios up front and test them deliberately instead of discovering them in production. Focus on scenarios where critical alerts are delayed, missed, or unresolved, and document them as explicit test cases.
| Scenario | Record for the test | Checkpoint |
|---|---|---|
| Delayed critical alert | Trigger, expected in-app state, and allowed outbound channels | One canonical incident state, one user-facing in-app outcome, and one operator action |
| Missed critical alert | Trigger, expected in-app state, and allowed outbound channels | One canonical incident state, one user-facing in-app outcome, and one operator action |
| Unresolved critical alert | Trigger, expected in-app state, and allowed outbound channels | One canonical incident state, one user-facing in-app outcome, and one operator action |
For each scenario, record the trigger, expected in-app state, and allowed outbound channels. Keep uncertain states detailed in-app until the record is resolved so external messages do not overstate finality. Checkpoint: each scenario maps to one canonical incident state, one user-facing in-app outcome, and one operator action.
Define the escalation ladder and make accountability visible#
Escalation should be documented, channel-aware, and tied to unresolved critical state. Define who gets alerted, in what order, and when ownership moves from automated alerts to an operator queue.
Fast delivery only matters if alerts reach the right people on the right channels. Where your tooling supports it, capture two-way responses so acknowledgments and follow-up actions are visible, not inferred from provider delivery alone. Checkpoint: unresolved critical events have a clear owner, an acknowledgment path, and a traceable outcome.
Add reconciliation checks between critical state and notification delivery#
Before launch, add reconciliation that compares critical-state changes with notification outcomes. This makes gaps visible early, including events that changed state without a matching user alert or escalations without acknowledgment.
Keep it simple at first, but make it auditable. You should be able to review what happened, what was sent, and what was acknowledged from one consistent record. Checkpoint: compliance and audit trail verification is part of routine operations, not a post-incident cleanup task.
Rehearse recovery and verify the corrected record#
Recovery should be rehearsed, not improvised. For each modeled failure, document the recovery action your system actually supports and verify the corrected in-app state plus complete audit trail history after the fix.
If your architecture uses idempotency controls, test that path and confirm the final record still reflects both the original fault and the repair. Checkpoint: post-recovery state, notification history, and operator actions tell the same story end to end.
For a step-by-step walkthrough, see How to Set Up a Healthy PO System for a Platform: From Requisition to Payment in 5 Steps. Before go-live, sanity-check your retry, idempotency, and status-transition design against the Gruv docs.
Roll out in phases across the first production window#
Roll out in controlled phases, not all at once. Widen scope only when records, delivery behavior, and approvals stay reliable under production conditions.
Launch a minimal scope you can audit end to end#
Start with the smallest useful set of notifications and prove traceability first. For each live notification, confirm that the underlying transaction is captured as an audit event and that delivery outcomes are tracked in the same operational trail.
Treat email sender readiness as a go or no-go gate. If your provider enforces verified domains, do not expand until that requirement is satisfied.
Expand event coverage only after the base path is stable#
Add more lifecycle notifications only after the base flow is consistently reliable. Do not expand while delivery tooling errors remain unresolved, and do not expand until the operational record stays clear under live traffic.
Formalize change control and phase reporting#
When a phase changes message behavior or commitments, treat it as a written and signed change before it becomes effective. Keep reporting explicit at a quarterly cadence, including clear "no activity" records when a cohort had nothing to process.
Use formal go/no-go approval before each expansion#
Before moving to the next phase, require documented approval against your defined gates and evidence chain. If a gate fails, hold scope and fix reliability or auditability first, then proceed.
Common mistakes and fast recovery actions#
As scope expands, focus recovery work on operating habits, not just on adding channels.
Stop treating any single channel dashboard as the full truth#
A one-way, blast-only view can create blind spots. Re-center investigations on a shared incident record that lines up the triggering event, what was sent across channels, and any two-way response you captured for accountability. Use vendor dashboards as supporting evidence, not the only evidence.
Reduce low-value SMS volume first#
Not every update needs a text, even in a multi-channel system. High-volume background SMS can create user harm and trigger anti-spam protections. Raise the bar for SMS and move routine informational updates to other available channels.
Formalize failure handling for integrations#
If integrations fail, handle that as an incident-response problem, not an ad hoc fix. Keep a practical threat checklist and incident-response playbook for notification failures, then test your recovery flow before widening scope.
Pause SMS expansion until accountability is enforceable#
Do not scale text alerts until you can consistently explain what was sent and capture recipient responses for accountability. Route sends through one enforceable process so support can explain why a user received a message.
Final takeaway and copy paste launch checklist#
Launch cleanly by separating what the provided materials verify from what your team still needs to define in platform policy. Use the checklist below as a sign-off tool for your own platform decisions, and require evidence for each item before broad rollout.
- One versioned event contract is approved, with clear owners and consistent language across support, engineering, and payments operations (platform-defined; not specified in the provided excerpts).
- Channel routing rules are documented for SMS, email, Push Notifications, and In-App Alerts, and one test event is verified for consistent meaning across channels (channel behavior must be defined internally; not specified in the provided excerpts).
- Replay and retry behavior is defined and tested so repeated deliveries do not create inconsistent contractor-facing outcomes (design requirement for your platform; not evidenced in the provided excerpts).
- Notification records are traceable enough to reconstruct what triggered a message, what was sent, and what delivery response came back (internal requirement to define in your stack).
- Consent and compliance gates are enforced at send time per your legal and program requirements; FTC COPPA FAQs are treated as non-binding staff guidance, not binding Commission action.
- Vendor and procurement evidence is stored in the launch packet. In the provided materials, Everbridge contract
#47QTCA24D0083shows coverageApril 19, 2024 to April 18, 2029, current throughMod # PS-0005effectiveJune 13, 2025. - If Order Level Materials are in scope, order-level pricing review is explicitly completed, since OLM pricing is set at the order level and fair-and-reasonable determination sits with the ordering contracting officer.
- A limited production cohort, named owners, and written go or no-go criteria are in place before expansion.
Validate the event contract and channel policy with your platform docs and ops owners, run the limited cohort, and scale only after the evidence trail is clean.
Need the full breakdown? Read ERP Integration for Payment Platforms: How to Connect NetSuite, SAP, and Microsoft Dynamics 365 to Your Payout System.
If you want this architecture on top of compliance-gated disbursements with batch visibility and audit-ready trails, explore Gruv Payouts.
Frequently Asked Questions
What payment and payout events should trigger notifications in a contractor platform first?
There is no universal first-event taxonomy established here. Start with a limited event set your team can clearly justify and explain, then expand only after implementation and testing are stable. If support cannot quickly explain why an alert was sent, tighten the trigger before adding more.
When should we send email versus SMS versus in-app alerts for payout-related events?
Use email, SMS, and in-app alerts as complementary channels, not competing ones. Set routing rules by urgency and required action in your own policy, and keep them consistent across teams. Be conservative with interruptive channels like SMS.
How do we design safe retry and deduplication patterns for payment notification webhooks?
Define replay behavior before implementation and test repeated deliveries against the same expected outcome. The article does not establish specific retry intervals or deduplication algorithms. The goal is predictable handling under retries, not ad hoc behavior by channel.
How can we prevent duplicate or out-of-order alerts when provider statuses change?
Treat duplicate or out-of-order alerts as a reliability problem and test for them before scale. The article does not prescribe a single method for provider status ordering. Use explicit implementation checkpoints so conflicting status changes are caught in testing instead of reaching users.
What consent and compliance checks are required before sending contractor SMS alerts?
Define SMS consent and compliance requirements with counsel and enforce them at send time. The article does not provide jurisdiction-specific consent thresholds or disclosure rules. It also warns against treating FTC COPPA FAQs as a rulebook for payout texting because they are supplemental staff guidance, not binding Commission rules.
What minimum fields should every notification event store for audit and reconciliation?
Store enough detail for an operator to reconstruct what triggered the notification, what was sent across channels, and what response came back. The article does not specify a mandatory minimum field set. The standard is traceability for audit, reconciliation, and accountability.
How should escalation work when a critical payout alert is unread or unresolved?
Escalation should follow state and ownership, so unresolved critical alerts move from automated messaging to clear human ownership with an incident record. The article does not define fixed escalation SLAs or timing thresholds. Pair the process with your payout-failure playbook so support knows how to resolve the issue once alerted.
Yuki writes about banking setups, FX strategy, and payment rails for global freelancers—reducing fees while keeping compliance and cashflow predictable.
Sources
- bgs.vermont.gov/sites/bgs/files/files/purchasing-contracting...trusted
- capitol.tn.gov/Archives/Joint/committees/fiscal-review/cont...trusted
- das.nebraska.gov/materiel/purchasing/6214/Vendor/6214%20Z1%20...trusted
- das.nebraska.gov/materiel/purchasing/5965/SWN%20Communication...trusted
- dodcio.defense.gov/Portals/0/Documents/CMMC/AssessmentGuideL2v2...trusted
- dodcio.defense.gov/Portals/0/Documents/CMMC/AssessmentGuideL2.pdftrusted
- doit.maryland.gov/contracts/DoIT-Contracts/Data-Telecommunicat...trusted
- fastpayments.worldbank.org/sites/default/files/2025-02/Cybersecurity%20...trusted
Educational content only. Not legal, tax, or financial advice.
Related Posts

How to Respond to a Subpoena for Business Records
Move fast, but do not produce records on instinct. If you need to **respond to a subpoena for business records**, your immediate job is to control deadlines, preserve records, and make any later production defensible.

A US Expat's Guide to Investing in UCITS ETFs to Avoid PFIC Issues
The real problem is a two-system conflict. U.S. tax treatment can punish the wrong fund choice, while local product-access constraints can block the funds you want to buy in the first place. For **us expat ucits etfs**, the practical question is not "Which product is best?" It is "What can I access, report, and keep doing every year without guessing?" Use this four-part filter before any trade:

Spain Digital Nomad Visa Guide: Requirements, Application & 2026 Updates
Stop collecting more PDFs. The lower-risk move is to lock your route, keep one control sheet, validate each evidence lane in order, and finish with a strict consistency check. If you cannot explain your file on one page, the pack is still too loose.