
Embedded insurance is worth building into a contractor platform only when coverage status, proof of insurance, renewals, claims routing, and payout controls can be owned end to end.
Why this matters for contractor platforms now#
Start with the business decision, not the feature. For a contractor platform, the real question is whether embedded insurance removes onboarding friction, proof-of-insurance chasing, and claims confusion, or simply adds more support, finance, and exception handling. Insurance is truly embedded only when quote, bind, document delivery, and servicing happen inside workflows your team already owns.
Evaluate it inside the contractor journey. Judge the offer where contractor behavior actually changes in your flow, not in a demo. That is why this guide is decision-first, not demo-first. You are deciding where insurance belongs, whether it is opt-in at point of sale or built into the service, and who owns exceptions when insurance status and work status do not line up.
A practical checkpoint: if you cannot name one exact contractor event where insurance changes the user journey, treat it as a side offer, not a strategic product move.
Treat timing as real, but avoid overclaiming. Digital insurance distribution is already under closer scrutiny. EIOPA's report on the application of the Insurance Distribution Directive is a reminder that product design, selling methods, and cross-border distribution are not side issues once insurance moves into a platform experience.
Keep scope tight. This guide is about product strategy, unit economics, and execution checkpoints for an embedded insurance contractors platform decision. It is not a legal memo. If your program depends on formal product-governance or distribution questions, read EIOPA's approach to product oversight and governance together with local counsel and partner guidance before launch.
By the end, you should have these three things:
- A launch sequence for where insurance enters the contractor flow.
- A go/no-go logic tied to economics and operating readiness.
- A copy/paste leadership checklist for build approval.
If you want a deeper dive, read Platform Banking: How Marketplaces Can Offer Embedded Bank Accounts to Contractors.
Define embedded insurance for contractor workflows#
Use a narrow definition. Insurance is embedded only when it sits inside contractor actions your platform already runs. If it is mainly a referral or a generic checkout add-on, treat it as a side offer rather than a core product motion.
Map insurance events to contractor actions#
Use this guide's working lifecycle as an internal planning aid, not a universal standard:
- Quote during in-flow contractor steps where eligibility is checked.
- Contract when coverage is issued in-flow, without sending the contractor to separate sites or form stacks.
- Renew / Endorse if work details change and coverage terms may need updates.
- Cancel if coverage is no longer needed or the contractor requests termination.
Checkpoint: if you cannot name the contractor action that triggers each event, it is probably not embedded in any operational sense.
Define two internal design surfaces first#
Before you implement anything, define these internal control surfaces:
- Policy configuration: who sees the offer, when it appears, what data is prefilled, and what proof you store after issuance.
- Claims configuration: how incidents are reported, where claims are routed, what status support can see, and who owns escalations.
One practical control is Certificate of Insurance (COI) tracking. NEXT's overview of the ACORD certificate of liability insurance is a useful reminder that the certificate is proof of current coverage, not a replacement for your own status logic. If proof of insurance is part of your compliance process, keep COI tracking with payments and compliance operations. Fragmented inboxes and spreadsheet handling usually create gaps and slow the team down.
| Lifecycle moment | Decision the platform owns | Evidence to store | Primary owner |
|---|---|---|---|
| Onboarding | Does this contractor need coverage before activation? | COI or quote request, effective date, market or jurisdiction. | Platform operations |
| Job acceptance or compliance check | Is active coverage still required for this job or payout path? | Policy number, coverage status, additional insured request if needed. | Compliance ops |
| Renewal window | What happens if coverage expires or terms change? | Renewal notice, updated certificate, change log. | Contractor success or risk ops |
| Incident or claim intake | Who receives the first report and who answers the contractor? | Claim reference, insurer contact, escalation record. | Support plus claims owner |
Separate contractor coverage from a checkout add-on#
Contractor insurance is not the same as a standard ecommerce add-on. A checkout upsell is often a one-time conversion play. Contractor coverage can affect in-flow eligibility checks and proof/compliance management over time.
That creates a different failure mode. NEXT's general contractor insurance overview illustrates how contractor coverage can span liability, workers' compensation, commercial auto, and tools or equipment. You can have healthy starts and still slow the platform down if insurance and compliance handling stays manual or fragmented.
Use one rule to decide if it is truly embedded#
If insurance is not connected to the same in-flow contractor steps and proof/compliance workflows, do not price or prioritize it as a core product move. Treat it as an affiliate-style referral or ancillary revenue stream instead.
This pairs well with our guide on How to Scale a Gig Platform From 100 to 10000 Contractors: The Payments Infrastructure Checklist.
Gather prerequisites before you commit engineering time#
Pause if you cannot assemble the evidence pack and assign owners before scoping the build. Flows built first and ownership assigned later usually create rework.
Build a minimum evidence pack first#
Build a minimum evidence pack from your own operating data in one decision-ready document. Include four views, and keep them simple and usable:
- Coverage requirements by contractor cohort: which contractor types, markets, or jobs need proof of insurance and which can stay optional at launch.
- Document and evidence flow: where you collect COIs, endorsement requests, additional insured certificates, and renewal dates, and who approves exceptions.
- Partner operating responsibilities: who owns quote and bind, first notice of loss, servicing requests, and contractor-facing support messages.
- Baseline operating measures: quote completion, proof approval time, claims-routing latency, and support volume so launch performance can be compared against something real.
Verification point: a non-product stakeholder should be able to explain which cases are in scope, who approves handoffs, and what fails the gate. If the answer is still "everyone," the prerequisites are not ready.
Define technical readiness before estimating the build#
Define technical readiness before estimating engineering work. You need clear ownership for eligibility rules, quote initiation, policy and document storage, renewal handling, and exception resolution.
The key check is lifecycle traceability. Each action should map to an internal owner and a state change. If you cannot trace quote, bind, proof-of-coverage delivery, endorsement requests, cancellations, and claim intake into internal records, you are not ready.
Set instrumentation at the start. Measure quote completion, document approval time, renewal churn, claim-intake response time, and support contacts from day one.
Confirm partner and distribution readiness#
Confirm partner readiness with external partners before you build to assumptions. Document who owns quote and bind, who receives first notice of loss, how contractor documents are retrieved, and how exceptions are escalated.
Do not skip partner workflow controls. If a partner cannot clearly explain eligibility rules, document requirements, servicing ownership, and the handoff between platform support and claims teams, treat that as a no-go until clarified.
Assign owners before build starts#
Assign legal, claims, and finance ownership before build starts. At minimum, you need one owner for compliance review, one for claims escalation, and one for reconciliation.
Use a short owner sheet for each role:
- Named person
- Decision rights
- Required response channel
Formal implementations still fail when named contacts and escalation paths are vague. Use the same discipline here: specify the channel for coverage questions, the route for claims escalation, and the approver for payout-impacting exceptions before engineering work starts.
Need the full breakdown? Read Platform Fee Structures: How to Price Your Marketplace Without Losing Contractors.
Pick the right integration model for your operating reality#
Choose the model your team can operate end to end after launch, not the one that looks best in a demo. The buy-build-partner framing in Qover's embedded insurance guide is useful because it forces a control-versus-speed decision early. If product velocity is high and in-house insurance depth is low, a partner-led path is often easier to operate early. If long-term control and differentiation matter most, API-first can be a better fit.
Compare models based on operating fit#
Use this comparison to test operating fit. Embedded insurance is a B2B2C model and a business-model change, so the key question is not just pricing UX. It is whether policy, billing, claims, and contractor records stay aligned in live operations.
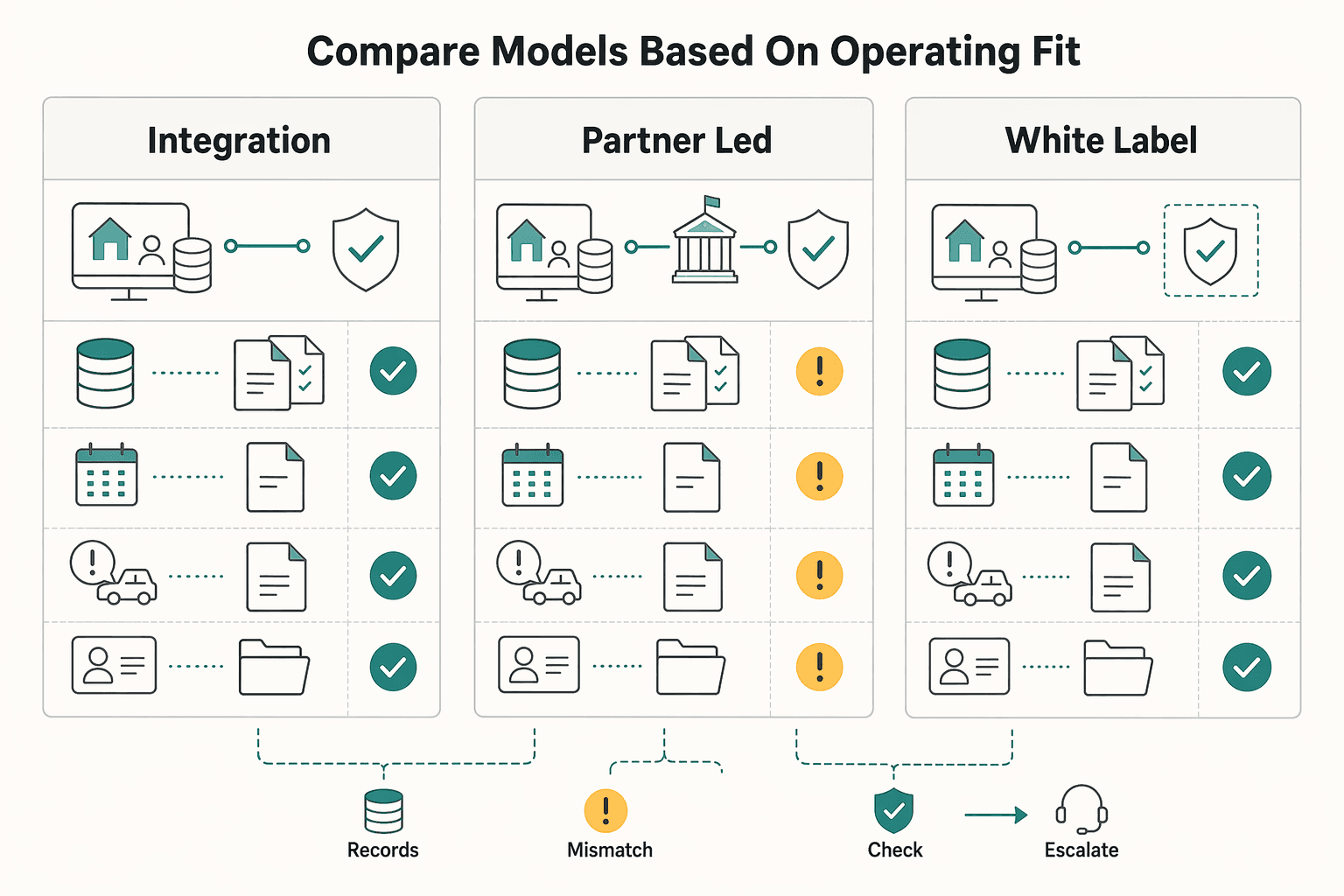
| Model | Best fit when | What you gain | What you still own | Main red flag |
|---|---|---|---|---|
| Direct API | Insurance must sit inside onboarding, job acceptance, or compliance checkpoints. | More control over UX, data capture, and lifecycle logic. | Integration architecture, monitoring, reconciliation, and exception handling. | You surface every systems gap the moment quote or status events drift. |
| Partner-led distribution | You need faster launch and the partner can take more insurance operations. | Narrower path to market with more operational support. | Data handoffs, contractor messaging, escalation paths, and partner governance. | Your team still absorbs confusion if support and claims ownership are blurry. |
| White-label flow | You need a packaged offer before committing to deeper product work. | Lower initial product build burden. | Document retrieval, servicing visibility, and reconciliation around the partner flow. | The insurance experience can stay detached from the contractor lifecycle you already run. |
Weigh the three tradeoffs that usually decide it#
Three tradeoffs usually decide the outcome:
- Speed to launch vs UX control: More managed models can reduce build burden, while API-first usually gives you more control over lifecycle touchpoints.
- Optionality vs implementation load: Integration quality drives scale and transaction accuracy, so map systems, data movement, overlapping records, and workflow triggers before you touch UI.
- Revenue share vs support burden: A managed model can lower build effort, but support and claims friction still land on your team if ownership is unclear.
Set a checkpoint before vendor selection#
Use a hard checkpoint before vendor selection:
- Start partner-led or white-label when speed and external support are the priority.
- Prioritize API-first when insurance must become core platform logic.
- Pause if you cannot map key lifecycle steps to owned internal records and exception paths.
When reviewing providers, avoid logo-led decisions. Use the same operating checklist for each: integration depth, lifecycle ownership, support escalation, and reconciliation readiness.
Related: How to Offer Spending Accounts to Your Contractors: Embedded Debit and Spend Management.
Design where insurance appears in the contractor journey#
Once you pick an integration model, place insurance at journey points your team can run end to end in real time. Prioritize placements where you can reliably create pricing and keep lifecycle statuses (such as Contract, Cancel, and Renew / Endorse) aligned with contractor records.
Start with contractor events you already control#
Start with contractor events you already control, then decide placement with configurable logic. In contractor flows, candidate points can include onboarding, job acceptance, pre-payout checks, and renewal prompts, but there is no single validated default sequence.
Keep rules configurable, not hardcoded, if they may vary by market or partner setup. For each placement point, confirm:
- the trigger event
- the partner or insurer response
- the internal owner
- the fallback when an API response fails or is delayed
If your stack still depends on batch updates, manual file transfers, or siloed databases, be cautious with hard pre-payout gating until real-time status is dependable.
Ask only for data you can use later#
There is no single validated rule for questionnaire depth at launch. Use a Dynamic quoting questionnaire when missing data blocks valid pricing or creates downstream policy-record issues. If reliable contractor and job data already exist, prefill what you can and ask only for the gaps.
Be strict about fields. Every answer you collect should map to a downstream field you can service later. If you cannot show where a field lands after the pricing step, do not collect it yet.
Track starts, abandon points, and repeat-question support contacts. A centralized performance dashboard helps, but at launch the real requirement is shared visibility across stakeholders.
Make the pricing-to-contract handoff explicit#
Make the pricing-to-Contract handoff explicit at the trust moment. When coverage is accepted, clearly show policy state, what happens next, and where proof or servicing actions live.
Apply that same clarity to Cancel and Renew / Endorse. If insurance is visible in-app, the change, renewal, or cancellation path should also be visible, with clear ownership for the next step.
Decide opt-in vs mandatory based on lifecycle stability#
Do not assume opt-in is always superior at launch. Choose opt-in versus mandatory coverage based on compliance requirements, partner terms, and lifecycle readiness.
If you move toward mandatory coverage, do it after core lifecycle reliability is demonstrated: stable pricing flow, visible Contract status, and dependable Cancel and Renew / Endorse handling.
Related reading: FDIC Pass-Through Insurance for Platform Wallets: How to Protect Your Contractor Funds.
Build the unit economics model before rollout#
Do not launch on commission math alone. Proceed only if the upside stays positive after claims handling, support load, and reconciliation work are included.
The journey triggers are now defined. The next question is whether they create margin or simply shift cost into support, finance, and ops.
Split value into separate pools before forecasting#
Split value into three pools before you forecast. In a B2B2C setup, insurance may affect acquisition, retention, and operational drag in different ways, and blending them can hide weak economics.
Your decision table should include:
- attach rate assumptions by cohort or placement point
- commission or revenue-share assumptions
- claims and support cost assumptions
- churn or retention impact assumptions
- contribution margin after servicing and finance overhead
Model acquisition lift, retention impact, and operational drag as separate lines. Require a named source and owner for each assumption before approval.
Build cost assumptions for a messy first phase#
Build costs as if integration will be messy at first. Price the first phase to include quote and bind plumbing, document storage, entitlement checks, support training, and reconciliation work, not just UI.
Do not underwrite revenue while ignoring mismatch costs. A common failure mode is status drift: coverage is active with the partner, expired in your platform, or still stuck in a manual review queue. That drives correction work and support load.
Before finance sign-off, require this checkpoint from the build plan: map core systems, data movement, duplicate records, and manual review queues. If that work is incomplete, raise cost assumptions or delay rollout.
Stress-test the model with operating scenarios#
Stress-test with operational scenarios, not just sales variance. The harder cases are usually coverage-document review, failed status syncs, claims questions, and renewal spikes that hit support and finance at once.
| Scenario | What changes | What finance should test |
|---|---|---|
| Best-case growth | Higher attach, faster proof approval, lower exception volume. | Whether margin still depends on manual document review or partner escalation. |
| Base-case operational load | Moderate attach, expected support and reconciliation effort. | Whether contribution margin stays positive after servicing labor. |
| Downside support spike | Lower conversion, heavier claims questions, more status mismatches. | Whether economics turn negative once overhead and correction work rise. |
If the downside case creates a material drain you cannot absorb, do not launch broadly. Pilot first or narrow the scope.
Use a finance checkpoint that can stop rollout#
Use a finance checkpoint that can stop the rollout. Proceed only when projected upside remains positive after claims-handling overhead and reconciliation effort are fully included.
Use system architecture as context, not proof. Architecture choices and workflow orchestration affect transaction accuracy and scalability, but they do not guarantee returns.
Technology spend can still erase margin if the platform duplicates insurer data, relies on manual reconciliation, or needs a large support layer to keep statuses aligned.
Go/no-go rule: if the upside disappears once exceptions, reconciliation, and claims-related service work are included, the case is not ready.
For related compliance workflow guidance, see How to Build a Risk-Based KYC Framework for Your Platform: Tiering Contractors by Risk Level.
If your upside is sensitive to ops overhead, pressure-test implementation and reconciliation assumptions in the Gruv docs.
Assign compliance and claims ownership before launch#
Do not launch until ownership is explicit for Policy configuration, Claims configuration, and servicing operations. Insurance can fit into the buying flow, but policy and claims work still needs compliance and security controls. Unclear ownership increases execution risk.
Name accountable owners for each control surface#
Create a practical ownership map (for example, a RACI) for Policy configuration, Claims configuration, and servicing. Keep it simple, but make accountability unambiguous for each task.
For each area, document:
- who approves changes
- who must be consulted before go-live
- who provides written authorization
- where the decision record is stored
Pressure-test the matrix with a real scenario. If your team cannot quickly identify the accountable owner for a claims or policy-change case, ownership is not ready.
Document first-touch ownership for lifecycle events#
Write first-touch responsibility for key lifecycle events before launch, such as Contract, Renew / Endorse, and Cancel. These are the moments where ownership gaps become visible.
For each lifecycle event, record:
- trigger
- first responder
- approver
- downstream teams notified
- system of record created
Require written authorization for material changes. A simple change record with scope, effective date, impacted contractor cohort, and named approver is a defensible control point.
Set launch gates for licensing, authorization, and records#
Set non-negotiables: no launch without licensing checks, written authorization paths, and audit-ready records for policy and claims decisions.
Minimum pre-launch evidence should include:
- licensing or certification readiness status
- written go-live authorization with approver name and effective date
- stored decision records for policy and claims changes
If you start with a link-out model, keep the same governance gates. Early-stage distribution is not a reason to skip ownership, authorization, or records.
Run a controlled launch with hard go or no-go gates#
Once ownership is assigned, do not roll out broadly. Launch in stages, keep the first contractor cohort narrow, and let expansion be earned by evidence.
Digital channels are making embedded insurance easier to deploy, but hard gates still matter because issues surface across multiple handoffs between the platform, the insurance partner, and the contractor experience. Even defined workforce-protection programs such as Qover's Deliveroo case study are framed around a specific use case, not a generic add-on. Phased execution gives you a chance to catch operational gaps while the blast radius is still limited.
Start with a deliberately narrow pilot cohort#
Start with one limited pilot cohort, not your full contractor base. Choose a segment you can observe closely, such as one geography, one contractor type, or one onboarding channel, and document why it is first.
In setup, produce a short launch record with the pilot cohort, expected support capacity, named escalation contacts, and the events you will watch across pricing, Contract, Renew / Endorse, and Cancel. If support, finance, and product cannot all name the same pilot population and start conditions, you are not in a controlled launch.
Do not widen the cohort just because early attach looks strong. Early demand alone is not proof that claims and servicing are ready at scale.
Instrument event health before trusting pilot results#
Treat Embedded insurance API event health as a primary checkpoint, because weak event data can distort downstream metrics. Check whether expected events arrive, arrive in order, avoid duplication, and reconcile with insurer-side acknowledgements.
Apply the same discipline to the Dynamic quoting questionnaire. Look past completion rate. Review abandonment points, retry-triggering questions, support contacts, and whether completed questionnaires produce usable pricing responses and expected Contract events. If a path drives drop-off or repeated manual support, fix it before expanding volume.
Prioritize reconciliation in every review cycle. Compare contractor-facing state, your system of record, and the insurer or partner record on a pilot sample. If those do not match, the pilot is not ready to scale.
Predefine no-go triggers in writing#
Define no-go triggers before launch. At minimum, specify what happens if attach drops below your internal target band, claims turnaround slips against partner expectations, or support demand exceeds planned capacity.
Put these triggers in the same launch record used by product, legal, finance, and support. Specify who can pause expansion, who must be notified, and what evidence is required to restart, such as event-error logs, support ticket themes, open claims status, and pilot unit-economics views.
If a go decision depends on licensing, distribution authority, or cross-border questions, get written guidance from counsel and your insurance partner before rollout. Do not treat a product demo or sales deck as a regulatory answer.
Expand only after stability and economics are proven#
Scale only when event accuracy is stable, claims handling is reliable in live cases, and pilot unit economics remain positive after support and servicing load.
Make the scaling rule explicit. If data quality is unstable or claims handling still needs manual rescue, keep the cohort narrow even if attach is promising. If operations are smooth but economics are still negative, pause and rework placement, pricing, or questionnaire friction before expanding.
Connect insurance events to Gruv finance operations#
Finance traceability is a hard gate. Do not expand until insurer-side actions can be traced through internal status, money treatment, payout decisions, and reconciliation outputs without guesswork.
Capture the insurer event before money moves#
Treat insurer events as inputs that should be normalized before finance acts. In a B2P2C setup, status changes can happen outside your product surface, so event intake should lead and UI state should follow.
Use a documented intake flow before any finance or payout action is allowed. Keep key insurer lifecycle states shared across product, ops, and finance, and make each state meaning explicit in your workflow docs.
Run sample traces regularly. Insurer status, internal status interpretation, and downstream finance view should match record by record.
Post ledger treatment only from internal state#
Do not post from raw external events. Put financial treatment behind an internal status layer so finance, support, compliance, and product use the same interpretation.
Predefine treatment per state, including when the correct action is no posting and manual review. The priority is consistency, not complexity. Keep an exception log with insurer reference, internal status, payout status, owner, and resolution notes so reversals and disputes stay visible.
Gate payouts from the same status logic as compliance#
If insurance status affects eligibility, payout gating and compliance checks should read from the same internal status logic. Avoid parallel manual trackers that can drift out of sync.
Make the reason for each payout hold or release visible in the same operational view the team already uses. Keep an audit trail of status changes, exception decisions, and payout actions so reviewers can reconstruct what happened end to end.
Feed dashboards and reconciliation exports from the same flow#
API-based partner integrations should feed finance and ops dashboards, not only product analytics. The useful view is the one that shows insurer status, internal status, payout status, finance treatment, last sync outcome, and current owner in one traceable path.
Execution still has unresolved challenges, so avoid rigid workflow claims that your team has not validated in writing. If lifecycle-state mapping is incomplete, keep the cohort narrow.
For a step-by-step walkthrough, see Gig Worker Financial Wellness: How Platforms Can Offer Savings and Insurance as Benefits.
Spot failure modes early and recover without chaos#
Treat early breakdowns between pricing, Contract, claims, and servicing as potential trust and governance risk, not just UX noise.
Simplify the path from Quote to Contract#
If starts are high but Contract completion is weak, review the Dynamic quoting questionnaire first. Keep only truly required questions, improve the order, and remove avoidable intake friction before widening the cohort.
Verification point: review abandoned pricing sessions, identify the exact field or screen where exits cluster, and fix that point before scaling.
Tighten claims handling before trust breaks#
Claims friction can quickly erode confidence. Tighten Claims configuration, publish SLA expectations in plain language, and assign clear escalation ownership across support, claims ops, and insurer contacts.
Verification point: every open claim should show a current owner, latest update, and next action in one shared view. After serious disruption, run a focused trust reset: document what failed, what changed, and what contractors should now expect.
Make servicing actions visible in the product#
Make Renew / Endorse and Cancel paths explicit in product surfaces so contractors can see available actions and expected outcomes. Hidden servicing flows can create confusion and additional support load.
Verification point: confirm each servicing path is clear end to end, including what changes for coverage visibility and downstream operations.
Enforce routed events and periodic audit checks#
Integration drift can start when tools interpret insurer events differently. Use Intelligent Orchestration-style routing only if it gives product, support, compliance, and finance the same normalized event, and run periodic audit checks across pricing, Contract, Renew / Endorse, and Cancel.
Verification point: keep a versioned change log for mapping or contract-change decisions with owner and effective date. If routing breaks claims or payout visibility, escalate it as a fiduciary-risk issue and apply graceful degradation patterns while recovery is in progress.
You might also find this useful: How Home Services Platforms Pay Contractors: Insurance Verification Background Checks and Payouts.
Evaluate vendors with a decision scorecard#
Make vendor selection comparable, not persuasive. Score every provider on the same rubric so the decision rests on evidence, not demo polish.
Set one rubric across all vendors#
Use one shared scorecard with clear criteria. A scorecard helps because it makes evaluation consistent and turns subjective feedback into side-by-side data.
Rate vendors on common checkpoints such as quality, delivery timeliness, cost competitiveness, risk/compliance, and innovation.
If you start in a spreadsheet, that is fine as a low-barrier starting point. Just treat it as a starting point, since spreadsheet scorecards depend on manual updates and have limited real-time visibility.
Require evidence for every score#
Do not score from memory after calls. For each criterion, attach proof from demos and review materials so each rating is defensible.
- Quality: evidence of service quality.
- Delivery timeliness: consistency against expected timelines.
- Cost competitiveness: commercial competitiveness relative to alternatives.
- Risk/compliance: risk mitigation and compliance readiness.
- Innovation: ability to improve capabilities over time.
Verification point: update the scorecard after each demo and attach supporting artifacts. If a claim is not supported by product, documentation, or contract materials, mark it unverified.
Treat discovery lists as input, not proof#
Use list pages for discovery only. Validate meaningful vendor claims in live demos, then validate again in legal and commercial review before final selection.
Tie-break rule: pick the vendor that best fits your operating model, not the one with the broadest marketing promise.
Make the decision and execute with discipline#
If you cannot name the owner, integration model, and no-go triggers in one meeting, do not launch yet. This is a business-model change, not a lightweight add-on, so the decision needs explicit operating commitments.
Map insurance to real lifecycle moments#
Map insurance to real contractor lifecycle moments, not generic checkout placement. Use concrete points like onboarding, proof-of-coverage checks, renewal, and claim intake, and tie each to a specific product event.
Use one shared event language across product, support, and finance. If teams label sales-side and claims-side events differently, exceptions can rise when volume spikes.
Pick one integration path and document the tradeoff#
Pick one integration path and document the tradeoff in plain English before build starts. The key question is what control, speed, and operating responsibility you are trading.
Confirm the integration covers both policy sale and claims recording. Document handoffs, servicing ownership, and continuity plans before you commit to a launch date.
Approve economics only after downside review#
Approve economics only after a downside review, not a single upside case. Possible commission or revenue-share upside means little if document handling, claims support, and reconciliation costs rise with volume.
Review multiple scenarios: expected adoption, support-heavy adoption, and stress conditions with higher request or claims activity. If the case fails once servicing and exception-handling costs are included, pause the launch.
Assign named owners before code ships#
Assign named human owners before production code ships. Set clear accountability for policy decisions, claims escalation, and finance operations.
Avoid shared ownership without a final decision-maker. When status changes and first-response ownership is unclear, processing costs can rise and trust can fall.
Define launch gates, then validate vendor claims#
Define launch gates and no-go triggers first, then validate vendor claims with evidence. Require a live demo of your required flows, documentation for event handling and servicing, and at least one operational reference.
Keep one hard technical gate in the review: integration must cover both sales-side events and claims-side recording. If event accuracy or ownership is unresolved, keep the decision at no-go.
Copy and paste checklist
- We mapped insurance to customer lifecycle points, not generic checkout placement.
- We chose one integration model with explicit tradeoffs.
- We built and reviewed a unit economics model with downside scenarios.
- We assigned clear ownership for policy, claims, and finance operations.
- We defined launch gates and no-go triggers before writing production code.
- We validated vendor claims through demos, documentation, and operational references.
- We linked insurance events to Gruv audit-ready records and exception handling.
When your checklist is complete and you need to confirm program fit and rollout constraints, talk to Gruv.
Frequently Asked Questions
What is an embedded insurance contractors platform, and how is it different from a checkout add-on?
An embedded insurance contractor platform keeps quote, bind, coverage proof, and servicing inside the product experience. If the contractor is pushed to a generic referral or end-of-checkout offer, it is closer to a side offer than a true embedded workflow.
Should a marketplace offer embedded insurance for contractors or stay with external referrals?
Embed insurance when it belongs in a core workflow where timing and in-product experience matter, such as contract or sale moments. Use external referrals as an interim model when you are not ready to run that workflow in-product. The decision is about operating fit, not just demand.
How do we decide between an API-first model and a white-label model?
Choose API-first when real-time quote, bind, status sync, and document access must live inside your product flow. Choose white-label when speed matters more than deep control and you can accept a looser fit with the contractor journey.
What should we measure in the first launch phase before scaling?
Measure whether the end-to-end insurance flow is operationally reliable before you scale volume. At minimum, verify quote, bind, and issuance handoffs are working and that finance reconciliation is workable, including commission tracking and settlements. If these foundations are still unstable, scaling will usually amplify exceptions.
How does embedded insurance change contribution margin and support cost?
The grounded sources here do not provide quantified contribution-margin uplift or support-cost deltas. They do show insurance programs tied to commission tracking and settlement workflows, which means financial upside and operating load should be modeled together. Treat margin impact as case-specific until your own data is stable.
What are the biggest compliance and claims risks teams miss at launch?
Common misses are vague distribution ownership, weak document handling, and unclear claims escalation. Teams also underestimate how quickly trust falls when contractors cannot see current coverage status or get a clear answer on where a claim belongs.
How do we connect insurance lifecycle events to payout controls and reconciliation?
Start by matching quote, bind, issuance, commission, settlement, and payout-impacting status events across systems. Use one internal status layer for finance and compliance, and keep a manual exception log until the event feed is stable.
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
Includes 4 external sources outside the trusted-domain allowlist.
- eiopa.europa.eu/publications/eiopas-approach-supervision-pro...trusted
- eiopa.europa.eu/publications/report-application-insurance-di...trusted
- nextinsurance.com/glossary/acord-certificate-of-liability-insu...external
- nextinsurance.com/business/general-contractor-insuranceexternal
- qover.com/blog/buy-build-partner-embedded-insuranceexternal
- qover.com/case-studies/deliveroo-protecting-gig-worker...external
Educational content only. Not legal, tax, or financial advice.
Related Posts

The Freelance Payment Penalty: A Modeled Audit of Platform Fees, FX Spreads, and Payout Delays
The money rarely disappears through a single, easy-to-spot fee. The real loss is stacked. A marketplace takes its commission, a processor adds a charge for international cards, a bank or payment company converts the currency at a spread, a platform holds the funds before release, and a wire sheds a little to intermediaries on the way in. Each layer looks defensible on its own, but the worker feels the combined result as a smaller deposit and a later payday.

How to Respond to a Subpoena for Business Records
Move fast, but do not produce records on instinct. If you need to **respond to a subpoena for business records**, your immediate job is to control deadlines, preserve records, and make any later production defensible.

A US Expat's Guide to Investing in UCITS ETFs to Avoid PFIC Issues
The real problem is a two-system conflict. U.S. tax treatment can punish the wrong fund choice, while local product-access constraints can block the funds you want to buy in the first place. For **us expat ucits etfs**, the practical question is not "Which product is best?" It is "What can I access, report, and keep doing every year without guessing?" Use this four-part filter before any trade: