
Quick Answer
Start by treating machine-to-machine billing as an operations decision, not a trend choice: launch first where you can prove one successful flow and one failed flow with provider reference, internal event ID, timestamps, and a reconciliation record. Pressure-test late, duplicate, and out-of-order updates before scale. When reversals or disputes are likely, prioritize traceability over speed claims, and keep market coverage plus compliance and tax gates conditional until providers validate your exact transaction path.
Why Autonomous Agents Need Machine-to-Machine Billing#
Use machine-to-machine billing as an operational split between two different problems: Wholesale Telecom Billing for connected-device usage, often IoT, and Machine-to-Machine Payments for autonomous transactions between devices or software agents.
That split is a decision frame, not a strict industry definition. The telecom side comes from communications charging and settlement models. The autonomous-payments side is closer to programmable value transfer between software actors, often through digital wallets and real-time execution. If your product depends on a machine taking paid action immediately, the real question is whether you can settle, control, and reconcile exceptions without creating manual cleanup.
Your evidence base changes by lane. OECD M2M communications material focuses on connected devices and mobile wireless infrastructure, not payment operations. TM Forum TR185 is more relevant for telecom charging because it is built to surface M2M billing and charging gaps in existing frameworks. It is a useful checkpoint, but not a complete list of M2M challenges, so standards references alone are not enough for launch decisions.
The core judgment is operational: which markets and verticals can absorb your actual settlement behavior, compliance gating, and reconciliation load. A market can look strong on volume and still create heavy ops pressure if transaction-state updates and reconciliation records do not stay in sync. The same problem shows up in AI-agent flows when payment-state changes are hard to explain from provider-side records.
One early architecture tradeoff is where billing logic lives. A documented M2M payment design view is the on-chain versus off-chain logic tradeoff, including higher development difficulty as more logic moves onto devices. Even if you do not use that exact architecture, the practical takeaway is the same. The more payment intelligence you distribute, the cleaner your event records and source of truth need to be. Before you commit to a first launch market, validate directly with providers:
- Ask for the full evidence path for one successful payment and one failed payment: provider reference, your internal event ID, state-change timestamps, and the reconciliation journal or export.
- Test late, duplicate, and out-of-order events.
- Treat compliance and market-coverage claims as conditional until verified for your exact flow, entity type, and settlement direction.
This article uses that lens. It is not a marketing-page comparison. It is go or no-go validation for where to launch first and what remains unknowable until providers prove it in your transaction path.
We covered this in detail in AI-Native Monetization for Products Where the User Is a Machine.
What machine-to-machine billing means in operations#
Use a practical split. Machine-to-Machine (M2M) Billing can be treated as usage and settlement across connected systems. Machine-to-Machine Payments is a narrower case where software or devices can initiate value transfer without a human action each time.
That distinction matters because the operating pattern changes with transaction shape. For small, frequent transactions, high-volume processing economics matter: margins are tight, and weak controls or exception handling can quickly break the model.
The OCC merchant-processing model is a useful control lens: gather transaction data, obtain authorization, collect funds, then reimburse the merchant. If you cannot show an equivalent evidence path for a machine-initiated flow, you do not yet have an operable payment product.
Digital Wallets and Payment Routing choices can change your control surface, not just movement of funds. They can affect where authorization records live and where transaction prohibitions must be enforced. A wallet balance view may help product behavior, but it may not be enough for finance controls if provider references, timestamps, and journal postings do not align. Ask each provider to prove one successful and one failed transaction end to end, including:
- your internal event ID
- the provider reference
- state-change timestamps
- the final reconciliation record
If your promise depends on instant machine action, scope settlement behavior first. Features can wait. Fast triggers with unclear posting, prohibited counterparties, or weak evidence trails can create manual cleanup before durable revenue.
Where IoT billing ends and AI-agent payments begin#
The practical boundary is settlement behavior, not whether the actor is an IoT device or an AI agent. In machine-payment designs, the payment decision can happen inside the live transaction instead of only in a later billing cycle.
| Dimension | Telecom-style billing patterns | AI-agent payment stacks |
|---|---|---|
| Rating logic | Can center on usage accounting and downstream reconciliation | Payment decision tied to a live request, often per call or per action instead of period-end usage |
| Settlement timing | Can be separated from the live request path | Closer to request time; some designs return structured payment requirements during the interaction and expect software to act automatically |
| Dispute frequency | Not meaningfully benchmarked here | Not meaningfully benchmarked here; per-transaction exceptions matter more when access or execution depends on payment outcome |
| Integration effort | Can emphasize billing and reconciliation workflows | Focus on identity, authorization, rail connectivity, payment-state updates, and evidence for failures or reversals |
Control primitives change more than the interface does#
The interface can look similar while the control model changes. In AI-agent payments, controls move closer to policy and transaction-time authorization.
Openfort's distinction is useful here: agentic commerce can still include a human principal, while machine payments remove the human from the flow. At that fully autonomous end, described as Level 4, operational load increases across identity, authorization, payment rails, and dispute resolution. In practice, these controls need to be designed into the operating model early, not treated as cleanup later.
x402 is relevant but narrow. It is described as an emerging standard built on HTTP 402 Payment Required, where a server can return structured payment requirements that software can execute automatically. That helps software detect and respond to a payment requirement, but it does not by itself cover the full identity, authorization, and dispute-resolution stack.
What your journals can prove, and what they cannot#
Your journals should prove your internal story: event received, amount determined, payment attempt made, entries posted, and status changes timestamped. That proof is strongest when each journal entry is linked to the external provider or on-chain reference.
Journals alone may not prove external finality. You may still need provider logs, rail references, or chain records to show the requirement presented, the authorization outcome, and whether settlement completed. In some blockchain-based flows, automated cryptographic proof of payment can strengthen that evidence set, but it does not replace internal posting records.
Run one success case and one failure case through the exact production path you plan to sell. Keep the request payload, returned payment requirement if present, provider or on-chain reference, journal linkage, and final outcome state.
The real tradeoff is traceability versus speed claims#
If disputes and reversals matter, prioritize reconciliation and traceability over "instant" payment claims. API-layer synchronous behavior can still sit on rails constrained by time zones, holidays, and weekday-only processing.
Treat prepaid or subscription workarounds carefully for machine consumption. A cited failure mode is overcommitment, where buyers pay for capacity they do not use. That can be tolerable for predictable usage. It can misfit bursty agent-to-agent activity where value transfer may need to map tightly to each request, including very small amounts such as $0.001.
If your product promise depends on machine-initiated payments, optimize for evidence quality under failure, not just trigger speed under ideal conditions. Related: How to Implement Intelligent Payment Retries: Timing Signals and ML-Based Approaches.
Pick your first launch vertical by payment behavior#
Choose your first launch vertical based on daily operational proof, not projected volume. The right first market is the one where your team can verify payment state and reconciliation every day with low ambiguity.
Start with a behavior matrix focused on payment shape, not category labels: transaction frequency, ticket size, and whether real-time settlement is required for the product promise.
| Vertical (candidate) | Transaction frequency | Ticket size | Real-Time Settlement necessity | Daily-close confidence (1-5) |
|---|---|---|---|---|
| Mobility | Your estimate | Your estimate | Your estimate | Your score |
| Utilities | Your estimate | Your estimate | Your estimate | Your score |
| SaaS agents | Your estimate | Your estimate | Your estimate | Your score |
| Industrial IoT | Your estimate | Your estimate | Your estimate | Your score |
Then score operational friction against the controls you actually run:
- Identity and compliance control readiness
Use KYC as an operating checkpoint, not a one-time task. A stronger setup has policy logic, telemetry, clear ownership, and lifecycle management. If those are missing, treat readiness risk as high before scale.
- Exception pressure
Manual billing errors create disputes, delay cash flow, and hurt trust, and the damage compounds in complex, high-volume services. Favor verticals where you can keep exception handling automated and visible.
- Timeliness of charging and rating
Near real-time aggregation and rating can reduce bill-shock and control-failure risk. One source example shows a $10,000 threshold exceeded on day two but detected on day five, with $15,000 in unintended credit and potential $50,000 invoice shock.
- Architecture fit
If control issues keep recurring, treat them as an architecture problem, not just a tooling gap. Score each candidate by whether your operating model can run billing and KYC controls consistently.
Add one explicit caveat row for unresolved assumptions: list what still needs validation before launch, and do not treat unknowns as confirmed capabilities.
The decision rule is simple: launch first where you can produce a clean daily close from internal records to required references, explain failures quickly, and operate controls consistently. If two verticals look similar, pick the one with fewer compliance handoffs and the shorter evidence chain. Related reading: Choosing Payment Rails for Autonomous Agent Transactions.
Decide your money movement stack before go-to-market commitments#
Choose the narrowest stack your team can operate with clear records on a bad day. Adding rails or providers may improve coverage, but it can also increase context switching, manual data movement, and the risk of conflicting records.
Compare options by evidence chain, not positioning#
Use VBAs, checkout plus MoR, and wallet flows as operating models to test, not assumptions to ship. For each path, confirm how many systems your team must touch to explain one failed payment end to end.
| Option | What to verify before launch | Risk signal |
|---|---|---|
| Virtual Accounts (VBAs) | How payment identifiers map into your internal records, and how unmatched cases are resolved | Teams need multiple tools to explain one payment |
| Checkout + Merchant of Record (MoR) | Which transaction states and references you receive, and where support ownership starts and ends | Status and support handoffs are unclear |
| Direct wallet-based flows | How balance and transfer states are recorded, retried, and reviewed by operators | Pending and final states are difficult to reconcile across systems |
Pick the option with the shortest, clearest evidence chain first.
Treat routing and fallback as control-surface expansion#
Routing and fallback may increase coverage, but each added branch can create more states to observe and close. If exception handling is not visible and mostly automated, fallback can shift risk instead of reducing it and force more human intervention.
Define one system of record per decision point#
Avoid multiple sources of truth. If your flow relies on more than one record stream, define exactly which record is authoritative for each state transition so operators can reconstruct outcomes without depending on fragile UI automations.
Non-negotiable controls before first live transaction#
Lock control ownership before the first real payment. Do not go live until your team can explain each state transition and show who resolved each exception.
This is a control-design problem, not a positioning problem. 25 CFR Part 542 explicitly uses Minimum Internal Control Standards. Nevada Regulation 5 names a compliance review and reporting system (5.045) and a system of records (5.107). Those sources do not define AI-agent payment product rules, but they do support the operating discipline: document standards, assign owners, and keep producible records.
Publish the minimum controls list#
Use a written, versioned checklist as a launch gate. Include:
- named control owners across the workflow
- defined exception-routing and resolution steps
- recordkeeping requirements aligned to your system-of-record expectations
- a pre-release defect-triage cadence
Define ownership by workflow state, not just by team name. For each key state, one queue should own the next action.
Tie compliance checks to transaction states#
Treat required compliance checks as flow gates, not side-process reminders. Decide where each check applies in your state model, then encode it in the transaction path and release tests.
If checks happen after funds movement begins, teams create preventable rework: blocked entities discovered late, reconciliation noise, and manual notes compensating for missing rules. If a gate can stop settlement or payout, it belongs in the flow definition before launch.
Make every path reconstructable#
Require a standard evidence pack for each payment path, with fields defined in your own control policy and available for review when exceptions occur. If core artifacts are missing, incident handling degrades into ad hoc dashboard reconstruction.
Nevada Regulation 5 also calls out access to premises and production of records (5.060). It is not a direct governing rule for this product context, but it is a practical posture for internal review, partner scrutiny, and post-incident analysis.
Test failure on purpose before launch#
Do not stop at happy-path UAT. The DDS RFI expects test execution before User Acceptance Testing (UAT) and at least weekly defect-prioritization meetings, which is a useful release standard for money movement flows.
Run controlled failure drills in non-production for the highest-risk failure modes in your flow. Pass only if records remain consistent, alerts route to the right owner, and operators can close with a complete evidence trail.
For a step-by-step walkthrough, see How Platform Operators Should Prepare for the Machine Payments Protocol. Before you ship, map each control in this checklist to concrete system and ledger events in the docs.
Design event flow so retries never duplicate money movement#
Define one sequence of record and one financial authority in your system before launch, because retries are part of the contract here, not an edge case.
Publish one record order and keep it stable#
Pick a local sequence, publish it, and make every team use it when events arrive late, twice, or in conflict. For example:
- API request accepted
- provider call attempted
- incoming event received
- ledger journal posted
- balance projection updated
This is not a universal standard. It is a local operating contract so product logic, ops handling, and reconciliation interpret the same timeline the same way. If your event stream is immutable, correct bad outcomes by appending linked correction events instead of editing history.
Document eventual consistency in plain language#
If balance projections can lag posted journals, say that clearly in the UI, API docs, and incident playbook. Do not present temporary views as if they are final records.
For each payout, operators should be able to confirm quickly what was attempted, what was received back, and what was journaled. If those checks require dashboard archaeology, the flow is still too implicit.
Treat step order as versioned behavior as well. In replay-sensitive systems, adding, removing, or reordering activities without versioning can break running flows, including failures that surface much later.
Put idempotency at each side-effect boundary#
Do not rely on one generic retry key across the whole flow. Define local boundaries where duplicates are costly, such as:
| Boundary | Requirement | Detail |
|---|---|---|
| Money-moving request creation | One business intent maps to one external attempt; retries reuse the same key | A side-effect boundary where duplicates are costly |
| Inbound event ingestion | Deduplicate on a stable event identifier and persist your own receipt record for replays | Covers duplicate and delayed events |
| Batch build and submission | Protect both generation and submission so rebuilds or resubmits do not duplicate money movement | Covers repeated batch submissions |
- Money-moving request creation: one business intent maps to one external attempt; retries reuse the same key.
- Inbound event ingestion: deduplicate on a stable event identifier and persist your own receipt record for replays.
- Batch build and submission: protect both generation and submission so rebuilds or resubmits do not duplicate money movement.
Test duplicate requests, duplicate and delayed events, and repeated batch submissions before launch. Pass only when retries produce one money movement effect, a coherent journal trail, and an operator timeline that shows event order without rewriting history.
Handle compliance and tax gates by market from day one#
Eligibility is a launch gate, not cleanup work. If you cannot show who is being paid, which tax profile applies, and what data you can retain, the payout flow is not ready.
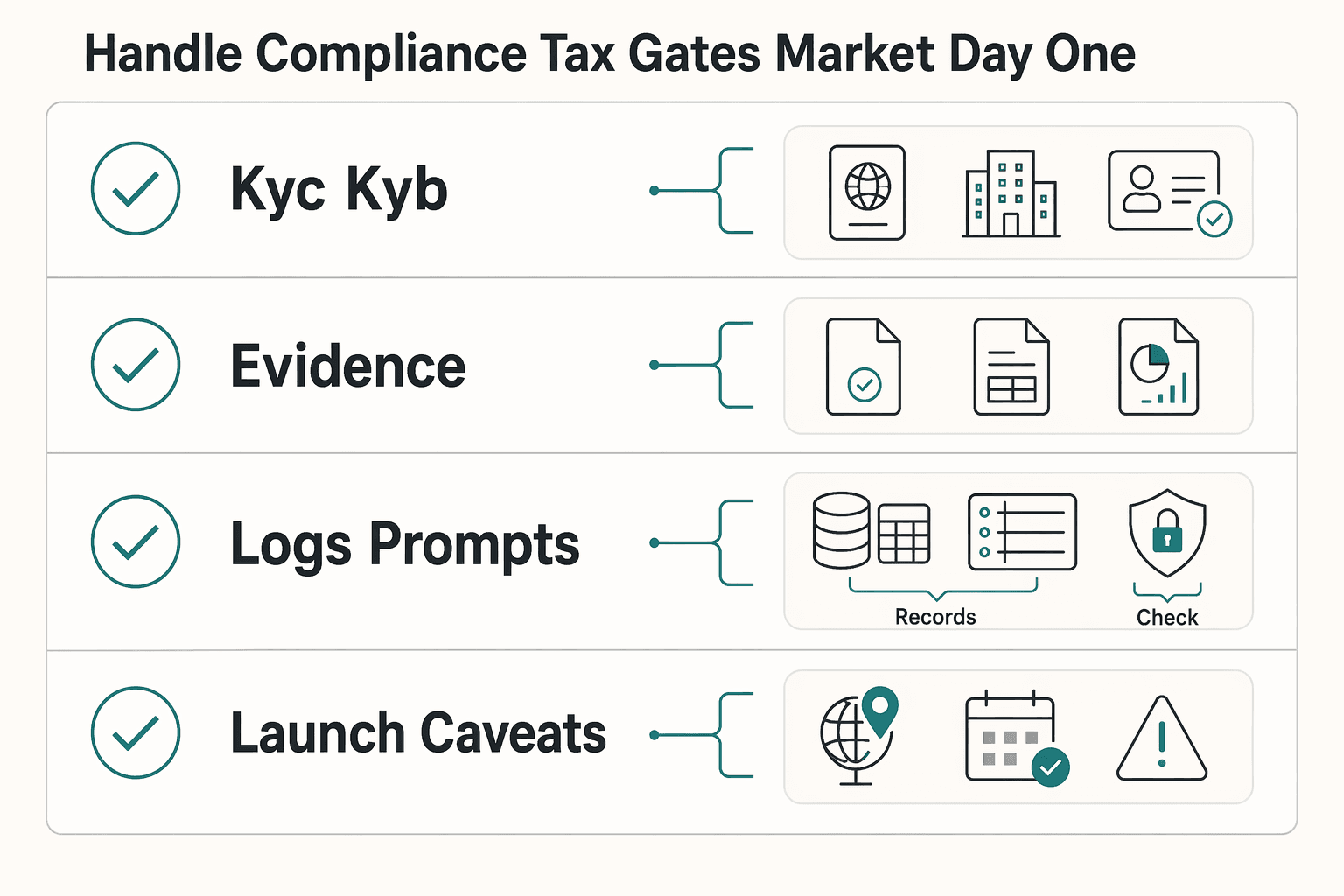
| Area | What to define | Operational note |
|---|---|---|
| KYC and KYB | Keep KYC and KYB as separate decisions; for each target market define payee type, required verification type, and payout state when verification is incomplete | Payout eligibility can depend on whether a payee is handled as an individual or an entity in a specific provider program |
| Tax documentation | Treat W-8, W-9, and related reporting flows such as 1099 as potential operational gates; collect tax forms at onboarding or before first payout and evaluate re-collection when payee details change | Prove the submitted form version matches the payee record used for payment |
| Logs, prompts, and support notes | Include where personal data can appear across payloads, prompts, and logs, retention rules for those records, and a process to verify and respond to consumer requests | If personal information appears in logs, prompts, or support notes, privacy compliance becomes day-to-day operations |
| Launch caveats | Use "coverage varies by market/program" and "confirm with provider before launch" in market notes, readiness checklists, and provider comparisons | Do not assume broad provider tax or geographic coverage applies uniformly across every rail, entity type, and reporting path |
Treat identity, tax, and privacy as market-and-program preconditions, not one global checklist. Use these caveats in launch docs: "coverage varies by market/program" and "confirm with provider before launch."
Separate person checks from business checks#
Keep KYC and KYB as separate decisions in your rollout plan. The practical question is whether a payee is handled as an individual or an entity in a specific provider program, because payout eligibility can depend on that split in some programs.
For each target market, define three fields in your launch sheet: payee type, required verification type, and payout state when verification is incomplete. If provider documentation is unclear by rail or program, treat that as unresolved risk before launch.
Put tax documents on the critical path#
Tax documentation can become a payout gate depending on market, program, and provider setup, so design it into the payment journey early. W-8, W-9, and related reporting flows such as 1099 should be treated as potential operational gates, not back-office follow-up.
Build explicit touchpoints for:
- collecting tax forms at onboarding or before first payout
- evaluating re-collection when payee details change
- proving the submitted form version matches the payee record used for payment
Make operator timelines explicit when a payout is on tax hold, so teams do not misclassify it as a rail failure.
Treat logs and prompts as regulated data, not debug exhaust#
If personal information appears in logs, prompts, or support notes, privacy compliance becomes day-to-day operations. The cited California regulations effective 1/1/2026 explicitly cover required disclosures, request handling and verification, record-keeping, and cybersecurity audit controls. That includes Privacy Policy (Section 7011), Record-Keeping (Section 7101), and Requirement to Complete a Cybersecurity Audit (Section 7120).
Your evidence set should include:
- where personal data can appear across payloads, prompts, and logs
- retention rules for those records
- a process to verify and respond to consumer requests
Use explicit caveat language in launch docs#
Use the caveats verbatim in market notes, readiness checklists, and provider comparisons: "coverage varies by market/program" and "confirm with provider before launch." That prevents teams from assuming broad provider tax or geographic coverage applies uniformly across every rail, entity type, and reporting path.
If you adopt broad tax infrastructure, plan for integration tradeoffs. Vendor scope can span tax determination, e-invoicing, compliance reporting, and tax data. That breadth can add operational complexity, including across multiple ERP systems.
Pricing and settlement choices that reshape unit economics#
Pricing and settlement can be margin levers, not just packaging choices. Teams often compare usage-rated billing, a subscription layer, and pure Micropayments based on whether per-action settlement is central to the product and whether costs are predictable.
| Model | Best fit | Main unit-economics risk |
|---|---|---|
| Usage-rated billing | You can measure volume, executions, steps, or cost per execution reliably | Weak guardrails on volatility if you skip caps or overage handling |
| Subscription layer | Buyers need clearer budgeting and cost predictability | Price/value drift if usage and outcomes diverge |
Pure Micropayments | The product depends on per-event settlement at machine speed | Buyers may view technical meters as noisy if they are not outcome-linked |
Real-Time Settlement can improve product responsiveness when autonomous loops cannot wait two to three days for confirmation. But speed can shift more work into operations, including tighter monitoring and more reconciliation events. High settlement throughput is still not the same as profit.
A major margin drag can be failure handling, not just the posted fee. Retry volume, exceptions, and proving what happened can erase gains from lower unit fees, especially when retries are not tightly controlled and delayed confirmations create extra cleanup work.
Model gross margin with full operating friction included:
- volume, executions, steps, and cost per execution
- exception-review effort
- reconciliation effort per settlement event
- retry cleanup and write-off risk
Before launch, validate daily hard metrics and reconcile settled totals against ledger totals. If they do not align without manual investigation, treat the pricing model as optimistic.
Failure modes that break trust in autonomous billing#
Trust usually breaks when your systems cannot provide a verifiable execution guarantee that one delivered action led to one valid settlement:
- Settlement risk spikes when money moves before work delivery is verifiable.
- Reconciliation confidence drops when payment records are treated as proof of completion; payments, escrow, and identity alone do not prove task completion.
- Human-in-the-loop payment requirements add friction that can break autonomous agent commerce flows.
- Cross-chain and multi-system automations stack trust assumptions, and each added layer can increase latency, cost, and systemic risk.
As rails and systems fragment, trust overhead compounds. Treat each added assumption as a launch risk until it is verified.
Need the full breakdown? Read AI Billing Infrastructure for Startups Using Credits Tokens and Metered Usage.
90-day rollout sequence with go or no-go checkpoints#
Treat the early rollout as an operational proof, not a speed run. You are validating classification, daily close, and exception control before you add complexity.
| Phase | Scope | Evidence focus |
|---|---|---|
| Phase 1 design | Lock transaction taxonomy first and define control gates against transaction states early | Produce a consistent Evidence Pack and query logic for any transaction path without dashboard hunting |
| Phase 2 pilot | Keep the pilot narrow: one vertical and limited scope, with daily Automated Reconciliation | Daily close should reconcile to ledger outcomes and the evidence standards set in phase 1 |
| Phase 3 scale | Expand in steps only after pilot operations are stable | Carry forward the same Evidence Pack and Examiner Query Pack discipline, plus defined Liquidity Gates and automated response mechanisms |
Phase 1 design#
Lock your transaction taxonomy first. You need a hard boundary between payment activity and anything that behaves like a different product class, so flows are not reworked mid-launch. A useful model is the February 17, 2026 SEC companion framing of Category 1, payment, versus Category 2 and 3, yield and investment.
Define control gates against transaction states early, and define required evidence for each flow. The goal is reconstructability: your team should be able to produce a consistent Evidence Pack and query logic for any transaction path without dashboard hunting.
Phase 2 pilot#
Keep the pilot narrow: one vertical and limited scope, with daily Automated Reconciliation. Daily close should reconcile to ledger outcomes and the evidence standards set in phase 1, not just wallet or provider views.
Make exception triage explicitly owned. A lightweight RACI is enough if it clearly assigns who investigates failed payouts, who approves corrections, and who closes cases with evidence attached.
Run a daily verification sample of failed or delayed transactions and confirm the team can rebuild the full sequence without manual re-entry. If reconstruction depends on manual correction loops, you are seeing operational drag, not readiness.
Phase 3 scale#
Scale only after pilot operations are stable. Then expand in steps, carrying forward the same Evidence Pack and Examiner Query Pack discipline, plus defined Liquidity Gates and automated response mechanisms for run-risk scenarios.
Assume each expansion increases exception patterns and reconciliation complexity. Monitoring should distinguish issue types so response stays precise as volume grows.
Go or no-go checks#
Use evidence, not volume, as the gate. Before expanding scope, confirm:
- Classification boundaries are still clear between payment activity and yield or investment activity.
- Examiner-ready artifacts are complete: Evidence Packs plus query-pack logic can reconstruct transaction paths without technical friction.
Liquidity Gates, automated response steps, and accountability ownership are in place and can be executed consistently.
If those outcomes still depend on heroic manual effort, call no-go and stabilize before scaling.
This pairs well with our guide on Fraud Detection on Payment Platforms with Rules and Machine Learning.
Conclusion#
The winning decision is not which trend is bigger. It is which market and vertical you can run with explainable records, provable controls, and risk you can absorb when failures happen.
Execution risk is operational before it is narrative. In IoT and M2M billing, teams must handle very large data volumes, multi-variable pricing, and cross-jurisdiction compliance. In autonomous designs, tradeoffs include execution speed, cost, and billing-logic placement. Published M2M implementation lessons also warn that more on-device logic makes application development harder.
Start narrower than your roadmap suggests. Prove one launch slice end to end: event accepted, payment or billing record captured, records updated, exception reviewed, and mismatch resolved before it compounds. The provider-specific checks are not side details. They are examples of launch-gating questions that decide whether a flow is operable.
Use a traceability test before expansion. For one disputed transaction, can your team produce the processing path quickly, including the relevant records, a processing identifier such as a Trace ID Number, and the balancing control that ties records together? If not, your control surface is still weak.
Also test duty separation. Payment execution and record transfer are distinct responsibilities in formal financial operations, and treating them as one function creates avoidable failure modes.
Expand only after you can demonstrate reliable records, controlled execution, and repeatable exception closure under real operating conditions. If those controls are not stable, broadening scope adds volume, not resilience.
If you want to validate market coverage, compliance gates, and rollout sequencing against your target vertical, contact Gruv.
Frequently Asked Questions
What is machine-to-machine billing, and how is it different from machine-to-machine payments?
In these materials, machine-to-machine billing can mean API access to billing objects such as bills and billing accounts. Orange’s Billing for Business API is one example because it exposes billing-related resources. A clean industry-wide boundary between billing and payments is not established in these sources.
When should a platform use telecom-style IoT billing instead of autonomous payment rails?
Use telecom-style billing when your core need is to read billing data from an operator-facing API. If your product must move funds autonomously, confirm that the billing API includes a payment execution layer before building on it. Decide based on whether your first requirement is billing visibility or money movement.
What minimum controls are required before enabling autonomous agent payments?
Confirm the minimum control set for autonomous agent payments with your providers and legal team. Orange's API access requirements are concrete: OAuth 2.0 Client Credentials plus X-Api-Key on each request. Treat broader control requirements as a separate review item and confirm them directly with providers and your legal and compliance teams.
Which unknowns must be confirmed by country before launch?
Confirm eligibility first, because Orange states this API is restricted to International Orange Business customers. Confirm which authentication mode is available for your integration, since Orange marks 2 legs + API Key as M2M-oriented while 3 legs is described as not yet available. Country rollout assumptions should be verified directly with the provider.
What should founders compare first when evaluating providers for M2M billing?
Compare who can access the API, how authentication works, and which billing resources are actually exposed. A practical checkpoint is whether you can complete a /bills call with the required Authorization token and X-Api-Key headers. Also compare credential lifecycle burden, including Orange’s documented API key expiry after 2 years.
How do idempotency and webhooks affect financial risk in real deployments?
Treat idempotency standards, webhook ordering guarantees, and replay-safe patterns as open risk until tested. Verizon's guide also states information may change without notice and does not guarantee network availability. Plan for the possibility of delayed, missing, or stale external signals, and validate your handling before scale.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
- azmag.gov/Portals/0/Documents/MagContent/2022-2023_UPW...trusted
- business.ucdenver.edu/content/ai-revenue-cycle-management-rcmtrusted
- cppa.ca.gov/regulations/pdf/cppa_regs.pdftrusted
- das.nebraska.gov/materiel/purchasing/120277%20O3%20REBID/Nets...trusted
- ecfr.gov/current/title-25/chapter-III/subchapter-D/pa...trusted
- farmingdale.edu/courses/index.shtmltrusted
- fdic.gov/bank-failures/purchase-assumption-agreement-...trusted
- federalregister.gov/documents/2024/11/15/2024-25534/negative-opt...trusted
Educational content only. Not legal, tax, or financial advice.
Related Posts

Freelance Liability Clauses That Limit Risk Without Stalling the Deal
Start with one written freelance contract, then negotiate liability-related terms from that same text. That keeps payment, scope, and risk terms tied to the same deal. If you skip that step, both sides are more exposed to misunderstandings and avoidable disputes.

How to Implement Intelligent Payment Retries: Timing Signals and ML-Based Approaches
If your team still uses a fixed retry schedule, recovery outcomes can depend heavily on timing. A better approach is a governed decision system: use machine learning to choose retry timing, then apply policy rules that block non-retryable cases and keep you inside network limits.

Using Machine Learning to Reduce Payment Failures on Subscription Platforms
Machine learning helps most when recurring-payment failures are probabilistic, not deterministic. If a charge might succeed later because timing, issuer behavior, or customer segment matters, model-driven retry timing can improve recovery. If the failure is deterministic, such as an invalid API call, a blocked payment, or a hard decline that cannot be fixed right away, rules and process fixes usually do more good.