
Quick Answer
Start by defining one billable machine-driven event and proving it from product telemetry to invoice line. AI-native monetization works when finance can reconcile contract terms, rated usage, payment status, and any payout movement without spreadsheet guesswork. For most teams, that means beginning with usage-based or hybrid pricing, then adding bounded outcome upside only after attribution and dispute handling are stable. Enter countries in sequence using explicit go/no-go gates for rails, compliance, and recovery operations.
Start with the billable machine event#
The hard part of AI-native monetization is not just setting a price. It is deciding how to charge when a human still approves the budget, but usage, cost, and much of the perceived value come from an autonomous agent acting on that person's behalf.
That tension matters because older pricing assumptions can break quietly. In a conventional SaaS product, buyer count, login count, or seat count often work as rough proxies for value and billing. In the agentic internet, that link gets weaker. New Enterprise Associates describes this shift as one where AI systems mediate discovery and "resolve intent and narrow the scope at the point of query," instead of sending people through a long chain of pages and apps. That is a useful operator lens, even if it is only one firm's framing and not a universal taxonomy.
This is not another broad argument that "pricing must change." The goal is narrower and more practical: to help you make better calls on three issues that usually decide whether monetization holds up under pressure. First, which pricing metric finance and procurement can actually reconcile. Second, which countries are worth entering first once payment rails, payout reliability, tax, and support burden are factored in. Third, where margin starts leaking when model usage, API events, or payout exceptions are allowed to grow faster than billing controls.
Read the examples in that spirit. References to NEA and other company examples in this piece illustrate public narratives and operating patterns; they do not claim a settled market standard. The evidence base is still thin. One recent arXiv paper on AI readiness argues that "no empirical framework currently exists for benchmarking where a firm stands," and notes that many organizations still rely on qualitative judgment and ad hoc maturity labels. That is a real checkpoint for founders and operators. If you cannot verify your own value event, cost event, and billable event, outside benchmark talk will not save you.
A second checkpoint is to be careful with era language. NEA's "Expansion to Distillation" framing is useful because it captures a web that moved from surface area growth toward intent resolution. Their examples are striking: websites grew from 17 million in 2000 to more than 1 billion by 2024, and the App Store went from 500 apps in 2008 to more than 2 million by 2025. But those numbers are context, not a pricing answer.
The useful question for the rest of this piece is simpler. When machine activity becomes the usage driver, what exactly are you charging for? Where can you collect it cleanly? What operational evidence will hold up when a customer, auditor, or finance lead asks you to prove the bill?
Define AI-native monetization in operator terms#
AI-native monetization is the operating design for who pays, which machine-driven event counts as delivered value, and how that value is measured so revenue is dependable, not just priced.
In practice, that definition starts at the API control layer. Production AI APIs are both cost drivers and potential revenue engines, so monetization depends on enforcement, security, and governance at the gateway where requests are controlled and recorded. If you cannot reliably connect governed request activity to billable terms, you have usage, but not a dependable business model.
This is also where seat-based pricing starts to strain in AI-native SaaS. Seats can still work for buyer access or approvals, but they are often weak as the only usage meter when machine activity drives delivery. A practical pattern is to keep seats as an access or commitment construct and tie monetization logic to governed usage events or resolved tasks.
The Expansion Era versus Distillation Era framing is useful context here, not proof. If value is now captured through trusted intent resolution rather than raw distribution, pricing logic should move closer to verified outcomes and controlled API events than to simple human login counts.
For usage-based pricing patterns in AI products, see How to Price AI Products: Usage-Based Monetization Frameworks for AI-Native Startups.
Map where money is captured across the stack#
Once you meter value at the API layer, treat monetization as a stack problem, not a single pricing decision. Money is captured across different layers, and blending them together usually hides margin risk and demand risk.
Three layers, three economics#
| Layer | Who gets paid | What usually triggers revenue | What you need to watch |
|---|---|---|---|
| Hyperscaler infrastructure | Cloud and model providers | Compute, inference, storage, network, model usage | Rising COGS from API calls, model selection, retries, and human-in-the-loop support |
| AI-native SaaS | The application vendor | Subscription, usage, or outcome terms in a product contract | Whether customer billing keeps up with machine-driven usage |
| Native and contextual advertising | Publishers, platforms, ad intermediaries | Sponsored placements, content-adjacent inventory, context-driven demand | Demand volatility, attribution limits, and assumptions that differ from product-contract revenue |
The common planning error is to over-model the middle row and under-model the first. AI COGS are not near-zero: each query has a real cost, and COGS can include compute, inference, and human-in-the-loop support. If agent-driven traffic grows faster than your billing logic, margin can deteriorate before topline growth flags the issue.
Directional data reinforces that risk. One analysis reports combined hyperscaler AI spending above $400 billion in 2025, with projections near $600 billion in 2026. Another estimates startups are spending about $2 on compute per $1 of revenue. These are not audited consensus benchmarks, but they are strong signals to model infrastructure exposure directly. A practical checkpoint is to reconcile, per paying account, contract terms with actual API calls, model tier used, and manual review events.
Demand paths are not the same#
Model direct product contracts separately from ad-mediated demand. In direct contracts, revenue comes from access, usage, or completed actions in your product. In media-style demand, revenue comes from attention, placement, or context.
Native and contextual advertising can still matter, but they monetize discovery around a task rather than task execution itself. Keep those channels in a separate forecast with separate proof standards. If margin depends on API activity, run it as product economics. If revenue depends on media demand, manage it as a distinct channel with its own volatility.
For a step-by-step walkthrough, see Choosing Creator Platform Monetization Models for Real-World Operations.
Choose the pricing metric your finance team can defend#
Choose a charge metric your finance team can trace from product behavior to an invoice. In most cases, that means starting with usage-based pricing or a hybrid model, then adding limited outcome upside once measurement is stable.
Use this comparison before you lock pricing terms:
| Pricing metric | Predictability | Customer trust | Auditability | Sales friction |
|---|---|---|---|---|
| Token-based pricing | Low to medium because spend can move with model usage patterns. | Stronger with technical buyers; weaker with broader procurement teams. | Medium if telemetry is clean, but harder for teams that do not buy in token units. | Medium to high outside developer-led sales. |
| Usage-based pricing | Medium to high when the billing unit is visible and stable. | Usually stronger when the unit maps to work buyers already track. | High relative to the others when usage can be tied to product events and contract terms. | Medium, with common questions on overages and spend control. |
| Outcome-based pricing | Lower for finance unless outcomes are immediate and clearly measurable. | Can be strong when buyers trust the outcome metric. | Low to medium until attribution and exception handling are clearly defined. | High in enterprise deals because more stakeholders must agree on measurement. |
If procurement needs clear reconciliation, lead with usage-based pricing and add bounded outcome upside later. If value realization is delayed or hard to attribute, avoid pure outcome pricing until your measurement and dispute handling are contract-ready.
Where token and outcome models usually break#
Token pricing can mirror model cost, but many buyers do not buy in token units. It tends to work better with technical buyers and creates more friction with non-technical procurement.
Outcome pricing can improve value alignment, but it also shifts more cost variability to you. That risk increases when outcomes are delayed or contested.
Move from seat-based pricing to a hybrid plan#
If you sell seats today, migrate in steps: keep a base subscription, then add usage tiers for machine-driven work that no longer tracks with human logins. Hybrid plans are often the practical middle ground when demand is still taking shape.
During migration, make two rules explicit:
- Define how autonomous workload bursts are billed, including included usage, overages, and spend controls.
- Put overage governance in writing so billing actions are predictable when usage crosses plan limits.
Your verification checkpoint should be strict: every billable event should map to system evidence, including the event log, rated usage record, contract term, and invoice line item. If any link is missing, the invoice is harder to defend at scale.
Pick verticals and countries in the right order#
Start with the vertical where your value is hardest to displace, then pick countries where you can execute cleanly. That usually beats a TAM-first launch because durable value and operational readiness determine whether revenue is repeatable.
The strongest launch candidates tend to have a system-of-record advantage and a domain-specific workflow moat: your product sits inside a mission-critical workflow, uses proprietary data, and supports work the customer already treats as essential. That matters more now that many enterprise buyers are moving from AI experimentation to implementation.
Score monetization fit before market size#
Before you prioritize market size, score each launch candidate on:
- payment method coverage for how customers actually pay
- contract enforceability and local buying norms
- payout reliability if your model includes partner or recipient disbursements
- support burden when payments, invoices, or payouts fail
If one market requires frequent cross-border payouts, treat that operating complexity as part of the launch decision, not a post-launch cleanup task.
Country factors that change unit economics#
Country rollout order should reflect execution risk, not just customer density. Foreign exchange (FX) exposure, settlement timing, and local acceptance of your payment and contract model can all change unit economics.
Use a pre-launch checkpoint: trace one realistic transaction from contract to invoice to payment confirmation and, where relevant, payout completion. If that path is unclear, market readiness is still unproven.
Use a go or no-go gate#
For each new market, require a short written check before sales scales volume:
| Go or no-go item | What to verify |
|---|---|
| Payment rails | Expected collection methods and recipient flows are supported for your customer and payout pattern |
| Tax and compliance readiness | Required business, invoicing, and payout checks are defined before billing or disbursing |
| Contract norms | Order form, usage terms, dispute language, and collection rights fit local contracting expectations |
| Recovery path | Clear ownership and process for failed payouts, rejected payments, reversals, and customer support |
Sequence markets in two waves: start where compliance and collections are simpler, then expand into markets that need heavier localization and exception handling. For related reading, see How to Use the Pyramid Principle for Client Communication.
Design billing operations before scaling GTM#
Scale sales only after billing controls can handle enterprise volume without manual cleanup. Here, that is operational risk management, not delay: Chargebee reports that AI-native companies are entering enterprise sales earlier and that the SaaS ramp can compress from seven years to two years or less. When GTM compresses, billing errors compound faster than finance teams can absorb.
Lock the money sequence first#
Set and document one fixed money flow before expanding GTM. Treat the charge metric as a strategic choice, not just an invoice setting, and keep the sequence explicit: event capture, rating, invoice generation, payment confirmation, payout initiation, then reconciliation closure.
Use a simple readiness check: trace one invoice line backward to usage, contract term, and rated quantity, then forward to payment status and any related payout. If that trace still depends on ad hoc spreadsheet work, the operation is not ready to scale. Where payouts are involved, avoid releasing funds on estimated usage if collections still settle on confirmed payment.
Make retries bill-safe#
Retries are expected; duplicate charges are not. Use idempotent event handling so a stable key (event ID, retry token, or equivalent) resolves to one billable record even when requests are replayed after timeouts.
Test this directly by replaying retry traffic and confirming invoice lines, totals, and balances do not change. Watch both failure modes: overcharging from duplicate records and underbilling from over-deduping distinct events. That control matters even more in AI delivery models where each query can carry non-trivial cost and margins are tighter than classic SaaS.
Define the enterprise evidence pack#
Before scaling enterprise volume, make invoice questions answerable without pulling engineers into every case. At minimum, your evidence pack should include:
| Evidence item | What it includes |
|---|---|
| Usage ledger export | event IDs, timestamps, account, billable quantity, and charge metric |
| Adjustment log | credits, rerates, write-offs, and reason codes |
| Dispute path | how invoice challenges are investigated and how outcomes are documented |
| Approval trace | nonstandard pricing, manual overrides, and payout-release approvals |
Update these controls whenever product behavior changes workload shape. If more autonomous behavior increases event volume, retries, and exceptions, billing operations must be updated before sales expansion. If finance cannot explain the unit economics at 10 customers, they will not improve at 1,000.
Handle cross-border money movement and compliance gates#
Treat cross-border payout reliability and compliance completion as expansion gates, not back-office cleanup. If either is below your internal target, pause acquisition in that market and fix operations first.
That matters even more here, where volume can rise before finance ops catches up. Nuvei's 2026 framing is clear: fully autonomous payments are still limited, while agent-assisted flows (human intent, AI execution within guardrails) are moving into production. Design for controlled release points instead of assuming machine-triggered money movement can scale safely on its own.
Use a country-readiness table before launch#
Open a country only when you can show a usable payout route, a workable KYC/KYB completion path, AML controls in the flow, and a clear recovery path for failed disbursements.
| Readiness status | Payout route availability | KYC/KYB completion path | AML control posture | Operational caveat |
|---|---|---|---|---|
| Ready now | Route is working end to end | Required onboarding path is clear and consistently completed | Screening/review is built into release flow | Launch only if failed payouts can be retried or reversed cleanly |
| Conditional | Route exists but has delays or edge-case failures | Completion is inconsistent or slow | Reviews frequently move to manual handling | Limit volume until completion and payout success stabilize |
| Hold | No dependable route | Required entity/beneficiary data cannot be completed reliably | Review path is unclear or regularly blocks execution | Do not scale GTM yet |
Run a live path test for each target country: approved setup to payout release to reconciliation close. If your team cannot trace status, provider references, and ledger impact quickly, that market is not operationally ready.
Where margin leaks first#
Margin usually leaks through delayed or failed disbursements, FX quote expiry during approval delays, and manual exception handling. These are not isolated ops issues; they directly affect cost, risk, customer experience, and growth.
| Leak source | What happens |
|---|---|
| Delayed or failed disbursements | rework and duplicate-release risk if status and provider references are not retained end to end |
| FX quote expiry during approval delays | FX exposure compounds when approval and release are separated by review queues |
| Manual exception handling | close slows and auditability degrades when exceptions dominate |
In practice, delayed payouts can trigger rework and duplicate-release risk if status and provider references are not retained end to end. FX exposure also compounds when approval and release are separated by review queues. And when exceptions dominate, close slows and auditability degrades. Keep a hard policy gate between "pending checks" and "released."
Build audit-ready release controls#
Keep controls simple and visible:
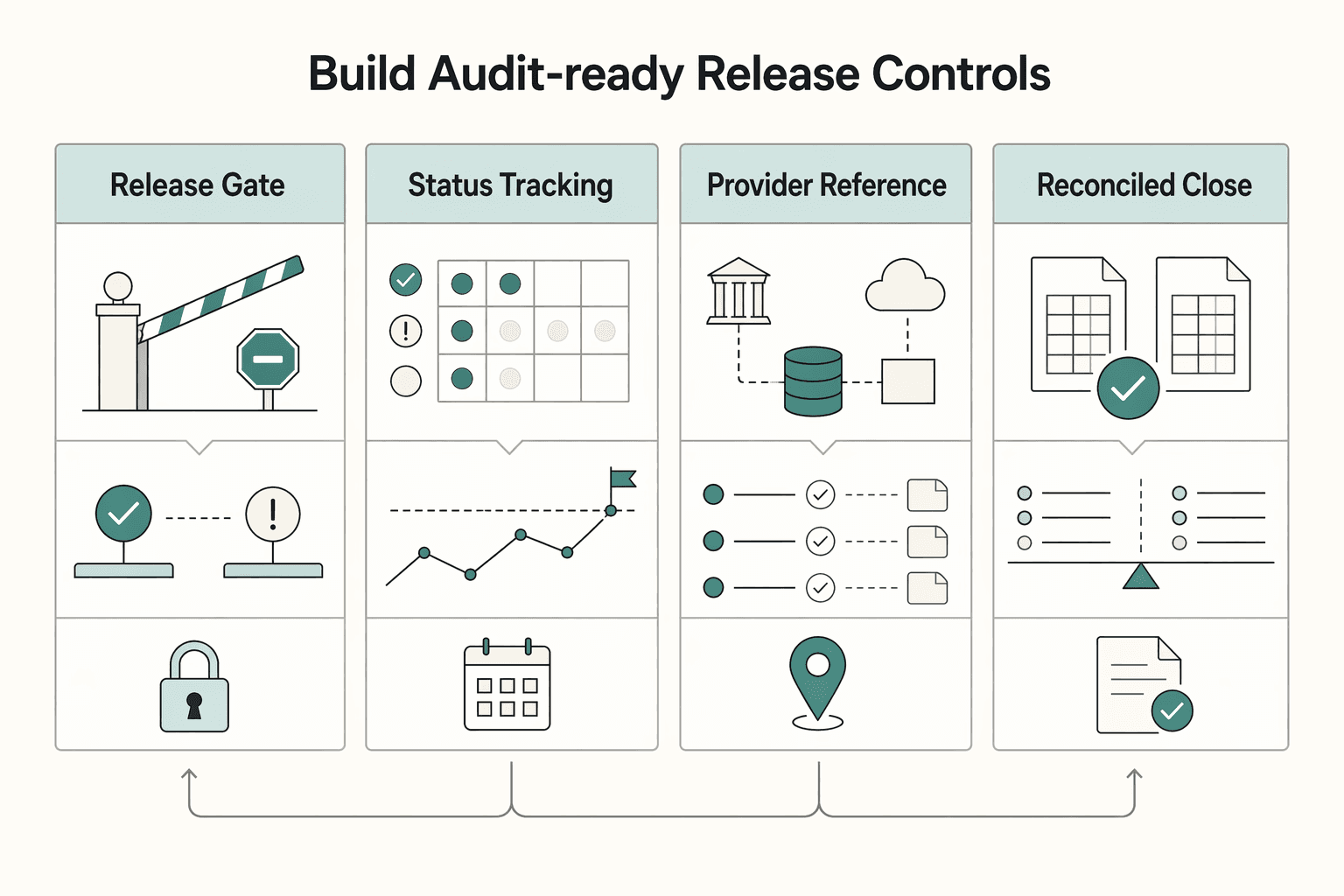
| Control | What it covers |
|---|---|
| Policy-gated releases | payout initiation is blocked until required checks are complete |
| Status tracking | a clear lifecycle such as created, under review, approved, released, failed, returned, reconciled |
| Provider reference retention | for each release, reversal, and return |
| Reconciled close reports | tying approved payouts, provider movement, returns, fees, and unresolved items back to the ledger |
Decision rule: if payout reliability or compliance completion is below target, stop increasing acquisition spend in that market until the failing gate is fixed. Related: Webflow Memberships for Community: Compliance, Stack, and Monetization Guide.
Spot failure modes before they erode margin#
Margin erosion is usually visible before it shows up in finance close if you track the right operating signals. If you cannot reconcile gross revenue to net revenue each month with source records, treat that as an active failure mode.
Watch for four early warnings:
- unbillable value events (high-value product activity with no clear path to a usage record, contract term, invoice line, or approved adjustment)
- rising disputes and credit requests
- pricing-plan drift (growing one-off terms and exception handling)
- support-heavy billing explanations for charges that should be self-evident
Cost discipline is the core check. Recent 2026 operator commentary makes the same point from different angles: teams that choose pricing models before understanding cost structure are more likely to lose margin as usage scales.
If demand depends heavily on dynamic ad creative or contextual advertising, expect more volatility when attribution is weak. AI search advertising and AI-powered conversation ads are evolving quickly, so channel performance can shift even when demand looks strong. Do not let ad-led growth carry your margin model unless attribution is reliable enough to support pricing decisions.
Review one monthly margin pack:
- gross-to-net revenue bridge, including credits, refunds, and non-collectible items
- infra pass-through trend, using vendor invoices against billed usage categories
- payout failure causes, grouped by return reason or provider status
- compliance queue backlog, with aging by status so delays are visible early
Conclusion#
Winning AI-native monetization is less about having a clever pricing theory and more about whether your value capture survives scrutiny. If you cannot show what happened, why it was billable, and how cash actually settled, your model is not ready to carry more volume.
That standard matters more now because buying and usage can be more compressed and more agent-mediated. NEA described this as a shift from the Expansion Era to Distillation, where agents "resolve intent and narrow the scope at the point of query." At the same time, Salesforce says customers are moving past hype and want autonomous agents with clear, measurable bottom-line impact. Put those together and the operating bar gets stricter. Pricing has to be measurable, explainable, and supportable when a buyer or finance team asks for proof.
The execution order is not complicated, but skipping steps gets expensive:
- Choose a metric you can measure and defend.
- Validate market and money-movement constraints before launch.
- Harden billing evidence and dispute handling.
- Only then scale distribution and sales effort.
For most teams, the first hard checkpoint is still the right one: every billable event should map cleanly to an event log, usage record, contract term, and invoice line. If that chain breaks anywhere, you do not just have a pricing problem. You have an auditability problem. The same logic applies to market rollout. If a target market still requires manual workarounds to bill, collect, reconcile, or recover from failed settlement, treat that as a blocker, not a small ops annoyance to clean up later.
The common failure mode is trying to grow around weak proof. Teams launch a hybrid plan, add exceptions for a big customer, absorb a few disputed invoices, and tell themselves they will tighten controls after revenue ramps. That usually shows up later as unbillable value, support-heavy billing explanations, or margins that no longer match actual workload. The evidence pack is what keeps you honest: usage ledger export, adjustment history, approval trace, provider references, and a clear path for payment or payout failures.
A practical next step is simple. Run one market-by-market monetization review and write down, in plain language, where your current model fails on auditability, operational reliability, or margin resilience. If one market cannot produce a defensible invoice trail, fix measurement before you add spend. If another market can bill and collect cleanly, but exceptions are rising, tighten controls before sales pushes harder. That review will tell you more than another pricing brainstorm, because it shows whether the model works where money actually moves.
Frequently Asked Questions
What is AI-native monetization in one practical definition?
AI-native monetization is a practical way to define who pays, what event counts as delivered value, and how you verify that value when machine activity drives the work. In practice, pricing cannot depend only on a human login or seat if autonomous agents are doing most of the useful work.
Why does seat-based pricing fail faster in agentic products?
It breaks when AI does the heavy lifting and usage can expand without more people logging in. Autonomous agents may run for hours or days to finish one objective, so a fixed seat or flat monthly fee can hide a real variable cost per task. That is why a flat plan, like the "$20 per month" example, can create margin risk quickly when one customer runs heavy autonomous workloads.
How do I choose between token-based, usage-based, and outcome-based pricing?
Usage-based and outcome-based pricing are both viable models, alongside credits and subscriptions. A practical starting point is to choose a model where delivered value and cost can be measured clearly, then adjust as attribution and operations mature.
What should I validate before launching AI monetization in a new country?
Validate that your pricing model still works when autonomous usage increases and task-level costs vary. Confirm country-specific launch requirements and compliance thresholds with the relevant authority before entering a new market.
Which compliance gates matter most for cross-border payouts and enterprise trust?
For enterprise trust, keep pricing tied to clearly delivered value and measurable usage so margin and billing logic remain defensible. Confirm cross-border payout gates and KYC/KYB/AML thresholds with the relevant authority.
What are the first signs that my pricing model is destroying margin?
The first signal is a widening gap between what autonomous work costs per task and what you bill. In practice, fixed monthly pricing is a warning sign when heavy autonomous usage can consume far more cost than the plan price covers.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
Includes 6 external sources outside the trusted-domain allowlist.
- sec.gov/Archives/edgar/data/0001845815/0001104659260...trusted
- sec.gov/Archives/edgar/data/1419275/0001185185260005...trusted
- adventureppc.com/blog/chatgpt-ads-vs-gemini-ads-2026-comparin...external
- ai-ran.org/documents/AI-RAN-WG3-AI-on-RAN-Whitepaper.pdfexternal
- ainativegtm.substack.com/p/the-emerging-ai-native-gtm-playbookexternal
- arminkakas.medium.com/ai-software-pricing-models-metrics-and-a-pra...external
- arxiv.org/pdf/2603.13278external
- bvp.com/atlas/the-ai-pricing-and-monetization-playbookexternal
Educational content only. Not legal, tax, or financial advice.
Related Posts

How AI-Native Startups Price Products With Usage-Based Monetization
If you are pricing AI products, do not treat usage-based monetization as a last-step packaging exercise. The hard part is that AI usage can drive cost up quickly while the value delivered is often less obvious, so your charge metric, billing model, and guardrails need to be decided together.

Quiet Disclosure for Unreported Foreign Accounts and Safer IRS Options
If you found an offshore reporting gap, your next move will shape your risk from here on.

How to Invest in Farmland
Choose the vehicle before the property. The right path depends on your liquidity needs, how much control you want, and how much admin work you are willing to carry. If you need easy exits and very little operational burden, direct ownership is often not the right starting point.