
Quick Answer
For AI agent payment rails, launch only when you can prove delegated authority, transaction authenticity, accountability, and clean reconciliation for one narrow use case. Start with one vertical and transaction pattern, build an evidence pack and operator runbook, compare protocol claims against known rail costs and unknowns, and scale only after pilots pass authorization, reconciliation, and incident-response gates without manual stitching.
What Payment Rails for AI Agents Need to Handle#
Protocol headlines can distort launch decisions. For AI agent payment rails, the real question is whether you can launch with acceptable market coverage, provable delegated authority, and controls your finance team can defend. Use this guide to make three decisions before you scale:
- Where to launch first
- Which protocol path to test first
- What evidence must exist before rollout expands
The goal is not to pick a winner from headlines around Machine Payments Protocol (MPP), Agent Payments Protocol (AP2), and ATXP. It is to turn public claims into your own country-specific and vertical-specific go or no-go decisions.
Public detail is uneven. AP2 has the clearest public framing here: Google describes it as an open protocol for agent-led payments, published September 16, 2025, and positions it as a payment-agnostic trust layer. Google also says AP2 can extend A2A and MCP, supports payment types including cards, stablecoins, and real-time bank transfers, and was developed with more than 60 organizations. Treat those as design and network signals, not proof of production reliability, settlement behavior, or market-by-market acceptance.
Use one strict checkpoint for any candidate approach: can it evidence authorization, authenticity, and accountability on each agent transaction? If that proof is weak, treat it as a control gap, not a later cleanup item.
Public commentary has flagged a mismatch between human-centric rails and autonomous agent behavior. But that mismatch does not prove a newer protocol is ready. It only explains why this problem keeps resurfacing.
This guide stays narrow. It uses grounded public claims where they exist and treats missing protocol, performance, settlement, and ATXP details as unknowns. If a provider cannot show who authorized spend, how responsibility is assigned when something goes wrong, and how transaction events map to your ledger, that is a no-go for now.
For a step-by-step walkthrough, see Choosing Payment Rails for Autonomous Agent Transactions.
Set the decision objective before choosing rails#
Start with the decision objective, not a protocol ranking. Current payment systems were built for people, not machines, so first decide whether the pilot can prove one launch outcome clearly enough to keep.
Step 1 Choose one primary outcome#
Pick one outcome for launch: faster, confirmable machine-to-machine payments, clearer post-payment handling (receipts, refunds, reconciliation), or stronger control over who is allowed to spend. Write one pass-or-fail sentence so everyone can tell whether the pilot worked.
Step 2 Lock the first vertical and transaction shape#
Fix the first use case before tooling decisions. Keep scope tight to one vertical and one transaction pattern, for example API micropayments or one defined service-purchase flow, so results stay comparable.
Step 3 Write go/no-go tests under three headings#
Use authorization, authenticity, and accountability as explicit approval headings. AP2 is publicly framed around authorization, so require clear evidence of who is allowed to spend and under what rules. Then define your own checks for authenticity and accountability, including who owns refunds, receipts, and reconciliation.
Step 4 Define reject conditions before protocol selection#
If your team cannot state when to reject a transaction, delay choosing a rail and finish control design first. Your reject criteria should be specific enough that payments ops, finance, and product would all reject the same transaction for the same reason.
Build a prerequisite evidence pack before architecture work#
Before you debate architecture or vendors, build the evidence pack. You should be able to prove three basics on paper: what actions automation is allowed to take, who can authorize payment actions, and how you will explain failures after the fact.
Step 1 Build an operating constraints sheet#
Create one sheet per pilot flow with the system of record, allowed actions, and required guardrails. If a row does not have a dated source, owner, and last review time, mark it unknown.
Use this checkpoint: each row should tell operators what can run automatically, what needs human approval, and how exceptions are escalated on day one.
Step 2 Draft an authority model from intent to action#
Write a short document that maps user intent to machine action. Define who grants authority, what scope is allowed, what caps apply, how revocation works, and what record proves the grant existed at execution time.
Be strict about evidence. A prompt or approval message alone is not enough unless it links to an explicit permission record. You should be able to trace one payment attempt from request to granted scope to executed action to approval or rejection.
Step 3 Write the operator runbook for exception workflows#
Draft the operator guide before launch, even if it is incomplete. Cover the repetitive, high-stakes workflows that break teams in practice: retries, disputes, refunds, reconciliation, onboarding, and incident response.
For each workflow, document the trigger, owner, next action, required evidence, and customer-facing explanation. Assume money movement errors can be irreversible or surface later as churn, chargebacks, or accounting issues.
Step 4 Lock the pilot audit set before any build starts#
Define the pilot's required artifacts for every transaction decision and outcome. Include guardrail records such as approvals, allowlists, and audit logs, plus the internal records your team needs to reconstruct what happened.
Test the pack on one representative success path and one failure path. If any required artifact still depends on ad hoc reconstruction, fix evidence capture before investing in architecture.
Related guide: Payment Infrastructure Trends 2026: How Marketplace Operators Should Prioritize Real-Time Rails, Stablecoins, BNPL, and Embedded Checkout.
Compare protocol options by what is known and what is still unknown#
Compare MPP, AP2, and ATXP using verified evidence, not narrative strength. Keep any claimed benefit in the unknown column until you have primary documentation, test output, and production evidence.
Use the evidence pack from the previous section as your filter. Country constraints, authority records, and audit artifacts should drive protocol diligence, not marketing copy.
Step 1 Define what counts as known#
A claim is known only when a primary source clearly states commercial model or operating behavior. The strongest verified inputs are baseline rail economics from Stripe and Stripe Connect, not protocol specs.
| Baseline item | Price | Applies when |
|---|---|---|
| Domestic card transaction | 2.9% + 30¢ | Successful domestic card transaction |
| International cards | 1.5% | For international cards |
| Currency conversion | 1% | For currency conversion |
| ACH Direct Debit | 0.8% | Capped at $5.00 |
| Stablecoin payments | 1.5% of the transaction amount in USD | USD transaction amount |
| Monthly active account | $2 | When platform handles Connect pricing |
| Payout sent | 0.25% + 25¢ | When platform handles Connect pricing |
| Managed Payments | 3.5% | In addition to standard Stripe processing fees |
Use that baseline as your reality check: Stripe Standard lists 2.9% + 30¢ per successful domestic card transaction, plus 1.5% for international cards and 1% for currency conversion. ACH Direct Debit is 0.8% with a $5.00 cap. Stablecoin payments are 1.5% of the transaction amount in USD. If a protocol pitch implies materially different economics, require explicit proof of where costs move and who owns collection, conversion, payout, disputes, and returns.
Use one checkpoint for your comparison sheet: every row needs a source URL, capture date, short quote, and one missing-field note. If a row still says "assumed lower cost" or "should be faster," it is not decision-ready.
Step 2 Build a known versus unknown table#
| Option | Intent to test | What is known | Unknowns that still matter |
|---|---|---|---|
| MPP | May be framed as an alternative agent-payment model. Treat as hypothesis until evidenced. | No verified MPP protocol behavior, settlement guarantees, or reliability data here. Hard benchmarks are existing rail prices: cards 2.9% + 30¢, ACH 0.8% capped at $5.00, stablecoin 1.5%. | Authority proof storage, revocation behavior, dispute ownership, all-in cost, production volume. |
| AP2 | May be positioned around trust or accountability outcomes. Not proven without technical and operational evidence. | No verified AP2 trust mechanics, merchant acceptance, or settlement path available. | Merchant-visible records, liability when agents misfire, settlement certainty, real acceptance, production usage. |
| ATXP | May be positioned as an alternative transaction flow. Keep in test status until fee and settlement details are disclosed. | No verified ATXP fee model, latency, or settlement design available. Platform benchmark still includes Connect costs when platform handles pricing: $2 per monthly active account and 0.25% + 25¢ per payout sent. | True all-in micropayment cost, reconciliation model, payout timing, cross-border usability, production scale, failure handling. |
A common failure mode is comparing protocol claims only to raw card fees while ignoring platform-layer costs. If the platform handles Connect pricing, you may also absorb $2 per monthly active account and 0.25% + 25¢ per payout. For Managed Payments, 3.5% is in addition to standard Stripe processing fees, not a replacement.
Step 3 Separate network signals from maturity evidence#
Track partner names and network mentions in a separate tab. Partner, network, or cloud-vendor mentions are alignment signals, not proof of integration depth, reliability, or production volume.
Use a simple operator rule: a partner mention does not move an option into a trusted bucket. Promote a signal into a decision input only with concrete evidence. That evidence should cover live countries, merchant categories, settlement currency, dispute ownership, and a reconciliation artifact linking request to provider reference to payout or return outcome.
Step 4 Apply a recommendation rule and keep a do-not-assume list#
If your immediate blocker is merchant trust, accountability, or authorization traceability, treat related protocol claims as diligence items until primary evidence is in hand. If stream-like, low-value transactions are central, stress-test protocol assumptions against the fixed 30¢ domestic card component and payout-layer fees. Keep every option exploratory until primary evidence covers cost, settlement, and reconciliation.
Do not assume any of the following:
- Lower cost without modeling processing, international uplift, FX, payout fees, and additive platform fees
- Faster settlement or any settlement guarantee
- Cross-border acceptance from a pricing page or partner mention
- Merchant trust from accountability claims alone
- Technical maturity from cloud, network, or partner logos
The goal is not to pick a winner yet. It is to make unknowns explicit before you commit engineering scope or launch dates.
Related: FedNow vs. RTP: What Real-Time Payment Rails Mean for Gig Platforms and Contractor Payouts.
Match rail strategy to vertical transaction patterns#
Once you separate what is real from what is still hypothetical, match rails to the transaction pattern you actually need to support. Brand familiarity is not fit.
Step 1 Classify the transaction pattern before choosing a rail#
Use these as operating categories, not market standards. One cited source says three transaction patterns are emerging, but does not enumerate them.
- High-frequency low-value API calls
- Agent-managed procurement
- Recurring service orchestration
Treat your pattern labels as internal decision tools.
Step 2 Map fit and friction by pattern#
Use this table as a testing guide, not a performance ranking. It should help you compare fit and friction by pattern.
| Transaction pattern | Card paths (Visa, Mastercard) | Bank transfer paths | Stablecoin paths (BVNK, broader stablecoin infrastructure) | First-test rule |
|---|---|---|---|---|
| High-frequency low-value API calls | Can be a familiar default, but fit should be tested against pattern economics and controls | Can be viable, but operational flow and visibility must be clear | Often discussed for machine-driven flows, but fee transparency is still uncertain in this network | If count is high and ticket size is low, test protocol and fee assumptions before defaulting to any rail |
| Agent-managed procurement | Familiar merchant path, but delegated authority and dispute accountability are central | Can work if approval evidence and settlement path are clear | Only test where delegation artifacts and exception handling are explicit | Start with the rail that gives enforceable delegation artifacts and clear operator visibility |
| Recurring service orchestration | Can support recurring charges, but retries and disputes still need clear handling | Can fit recurring operations when status handling is reliable | Test only with clear reconciliation and operational traceability | Prioritize the rail your team can reconcile daily without manual stitching |
Keep two constraints in view:
- Zero per-transaction protocol claims can coexist with opaque platform-fee claims, and fee certainty remains limited
- Provider mentions are signals to investigate, not proof of best fit
Step 3 Apply hard disqualifiers before pilot scale-up#
Before pilot scale-up, disqualify a rail for the pattern if any of these remain unresolved:
- You cannot enforce delegated authority with clear artifacts
- Dispute accountability is unclear
- Operator visibility is weak across request, status, and outcome
- Settlement path is unclear
Step 4 Pass or fail pilots on reconciliation#
A pilot passes only if payment events reconcile to ledger entries without manual stitching. "Payment accepted" alone is not enough. For each pilot class, keep an end-to-end evidence chain from request through final outcome. If the flow still depends on manual CSV merging to explain outcomes, the rail is not operationally ready.
For a closer look at the tradeoffs between stablecoin and bank-based routing, read Stablecoin vs Traditional Payment Rails for Cross-Border Payout Routing.
Sequence country rollout using constraints first and demand second#
After you pick the transaction pattern, rank countries by operational constraints first and use demand to break ties. If two markets look similar on demand, launch where AP2 or MPP needs fewer manual exceptions and has a clear escalation path.
Step 1 Rank countries by constraint burden#
Start with the same three filters: resilience readiness on always-on rails, cross-border interoperability burden, and governance/audit burden. The goal is to find the first market where controls hold under real traffic, not to predict top-line revenue.
Use a short scorecard per country and penalize anything that adds custom approval logic, extra exception handling, or manual review. Also penalize paths that depend on always-on or programmable 24/7 settlement if resilience is weak, because latency and downtime become business risk. Use one hard checkpoint: can exceptions be escalated with full audit trails? If not, that market is not launch-ready.
Step 2 Layer demand only after protocol fit is clean#
Bring demand back in only after protocol fit is clean. For AP2 and MPP, prefer markets where exception handling, evidence records, and escalation ownership stay consistent across systems.
If demand is high but the market needs custom overrides in controls, reconciliation, or exception routing, push it down the list. A slightly smaller market with one control model, one evidence chain, and one escalation process is usually the stronger first launch.
Step 3 Treat A2A and MCP as shortlist signals#
Use A2A and MCP interoperability claims as compatibility signals, not launch guarantees. They can help shortlist markets, but they do not prove operational readiness.
You still need proof that payment events and exception states map to your existing controls and audit requirements. Cross-border conditions are evolving through ISO 20022 harmonization and interconnection of domestic real-time systems, but governance and interoperability requirements still need to be handled in operations.
Step 4 Choose the first launch market by exception load#
Pick the first launch country by the lowest manual exception load after burden ranking and protocol-fit filtering. That means fewer one-off rules, fewer special-case flows, and clearer escalation ownership when exceptions occur.
If two countries have similar demand, choose the one where your team can explain failures quickly, escalate with full audit trails, and avoid manual cross-system reconciliation. That is a more reliable launch-readiness signal than demand alone.
Design delegated authority controls before enabling autonomous spend#
Once you know where and how you may launch, the next gate is delegated spend. Do not enable autonomous spend until delegated authority is fully auditable.
Step 1 Define grant, narrow, and revoke authority#
Start by defining exactly who can grant authority, narrow it, and revoke it. This authority map should be in place before the first live transaction.
Record every authority change in an event log with an approval record. At minimum, capture agent identity, authorizing human or organization, action taken, effective limits, timestamp, and approval reference. Your ops checkpoint is simple: can you reconstruct why an agent was allowed on a specific payment attempt without relying on chat or ad hoc notes? If approvals live in Slack, email, or dashboard comments, treat that as a control gap.
Step 2 Model scopes and caps before the first transaction#
Define scopes and caps before execution begins. Delegated spend should be constrained by allowed actions and limits, but do not assume provider mechanics your stack cannot verify.
Set clear boundaries for action type, amount, expiration, counterparties, and when a request must be routed to review. At execution time, make the trust decision explicit: allow, deny, or review.
Validate revocation behavior in normal and degraded conditions, including unreliable connectivity with queue-and-sync flows. If authority is revoked while requests are in flight or queued, enforce a clear handling rule and preserve a clean audit trail.
Step 3 Enforce identity and compliance gates before execution#
Put identity and compliance gates before transaction execution. Agents break the legacy assumption of a verified human actor, so you need verifiable, auditable agent identity plus proof of delegation and limits up front.
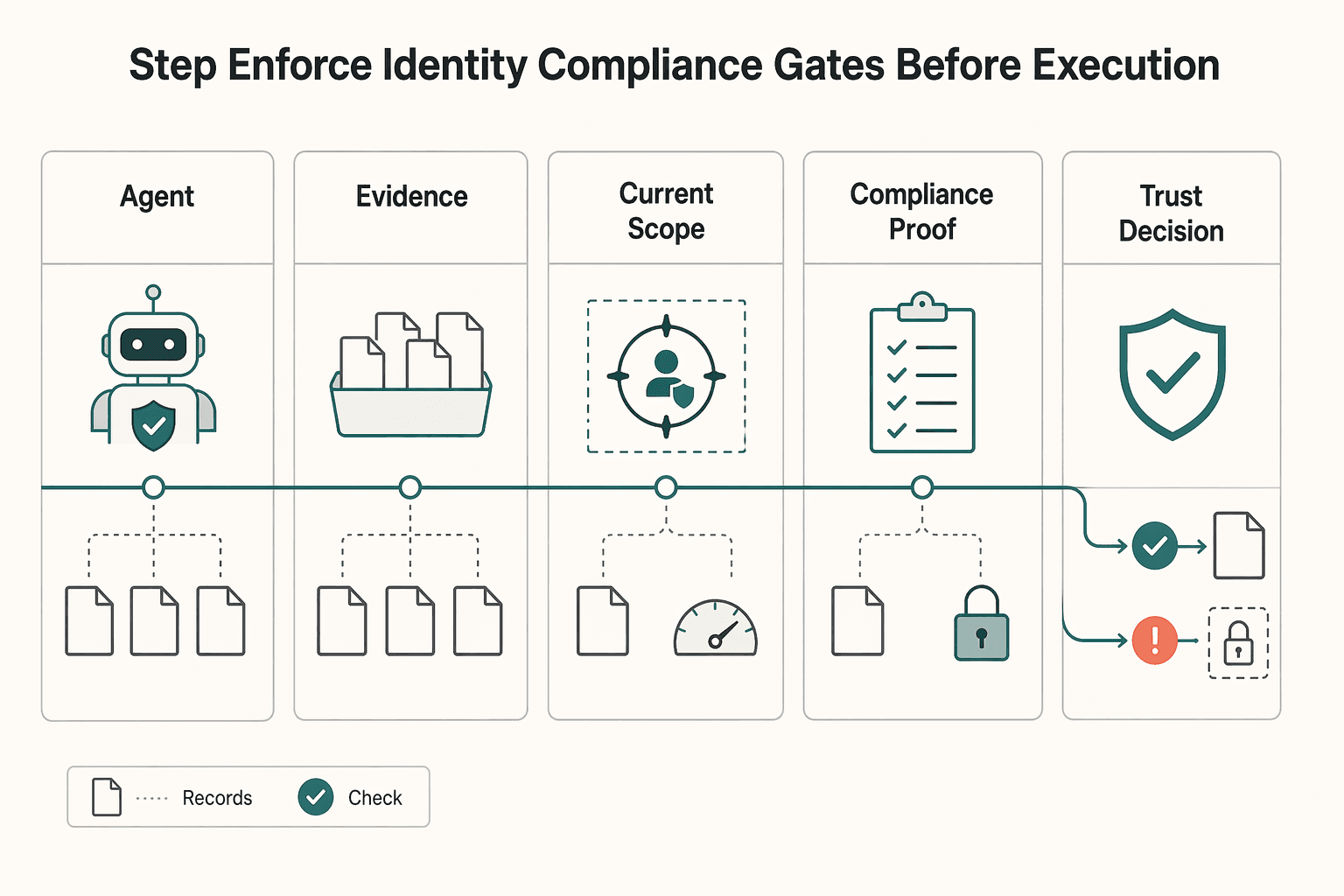
| Artifact | Purpose | Rule |
|---|---|---|
| Agent ID | Verifiable, auditable agent identity | If identity proof is incomplete, block the payment attempt |
| Grant record | Proof of delegation and limits | If authorization proof is incomplete, block the payment attempt |
| Current scope version | Current scope version at execution | If authorization proof is incomplete, block the payment attempt |
| Compliance proof | Required compliance checks before execution | If compliance proof is incomplete, block the payment attempt |
| Trust decision result | Allow, deny, or review result | Missing artifacts should fail preconditions |
| Proof artifact tied to the payment request | Links proof to the payment request | Missing artifacts should fail preconditions |
Where compliance checks are required, enforce them before execution. If identity, authorization, or compliance proof is incomplete, block the payment attempt.
For each transaction, keep a complete evidence pack: agent ID, grant record, current scope version, trust decision result, and proof artifact tied to the payment request. Missing artifacts should fail preconditions, not become post-settlement cleanup.
Step 4 Assign dispute ownership by payment method#
Set dispute ownership per payment method before launch. Define in advance who supplies evidence, who engages counterparties, who approves remediation, and who records the final outcome.
If ownership is ambiguous for a method, keep autonomous spend off for that method. Ambiguity creates conflicting narratives and slows resolution when incidents occur.
For the controls side of payment operations, read Internal Controls for Payment Platforms: Segregation of Duties Dual Approval and Audit Trails.
Build settlement and reconciliation you can defend in an audit#
If you cannot defend settlement and reconciliation in an audit, you are not ready to scale. In fast agent-driven flows, accountability still sits with a legal entity, so your controls need to produce records an auditor can follow.
Step 1 Make ledger postings the source of truth#
Treat ledger postings as the authoritative record, and treat wallet or balance screens as derived views. If a screen can drift from the journal, it is an operational view, not audit evidence.
Use an append-only pattern for the journal, or the event stream feeding it, so records are not overwritten. The practical test is whether finance can rebuild balances and history from ledger entries and references without relying on provider dashboards.
Step 2 Make replay handling explicit before volume grows#
If your flow uses webhooks or other provider callbacks, replay behavior should not create duplicate financial outcomes. Validate and document how duplicates are handled, and keep a clear retry trail.
This matters even more when one agent conversation can trigger hundreds of micro-transactions. At that pace, duplicate-handling gaps can turn into recurring reconciliation problems.
Step 3 Reconcile the full chain, not just the settled amount#
Reconcile the full chain: request -> provider reference -> ledger journal -> outcome state, for example paid, returned, reversed, or pending. If any link exists only in chat or memory, you have a control gap.
Keep a transaction evidence pack that ties IDs, timestamps, amounts, currency, and outcome artifacts together. That is how you produce receipts that connect the decision, approval, rule set, payment, and documentation.
Do not collapse asynchronous states into a single "done" status. Some traditional card settlement paths can take 1-3 business days.
Step 4 Define and test FX quote-expiry handling#
If FX conversion is in flow, define how stale quotes are handled before you scale. Confirm that stale-quote rejection or FX hard-fail controls are already in place, and treat this as a required design and testing decision.
Step 5 Define daily controls for unmatched deposits and returned credits#
Set daily controls for unmatched deposits and returned credits before scaling volume. Each exception should carry enough detail to investigate and resolve quickly.
Use a simple checkpoint: can the team classify or close each unmatched item every day instead of letting exceptions accumulate? Faster workflows make ambiguity more expensive, so daily exception discipline is part of core control.
Related reading: Build a Payment API for 1 Million Transactions a Day.
Run a phased pilot with explicit go or no-go gates#
Treat the pilot as an operations readiness test, not a product demo. Expansion should wait until governance and control evidence is clear, because pilot success in a controlled setup does not by itself prove production readiness.
Step 1 Narrow scope so failure is diagnosable#
Keep the first phase intentionally small so each result answers one decision question. A narrow scope can be defined by limiting vertical, corridor, and transaction-class variables, with a structured charter that defines goals, success metrics, and risk controls.
Step 2 Use explicit gates before any expansion#
Do not expand on intuition. Expand only when predefined checks pass across a full pilot window.
| Gate | Pass condition | Scope |
|---|---|---|
| Authorization integrity | Executed payments map to valid delegation and approval records | Sample successful, failed, and reversed transactions |
| Reconciliation completeness | Requests, provider references, ledger records, and outcomes match end to end | Sample successful, failed, and reversed transactions |
| Incident response performance | Alert-to-triage-to-resolution is measurable against your operating target | Sample successful, failed, and reversed transactions |
Use successful, failed, and reversed transactions in the sample so the gates reflect exception handling, not only the happy path.
Step 3 Add a pre-scale governance review#
Before adding rails or countries, run a formal pre-scale review of governance, infrastructure readiness, and cross-team operating ownership. Confirm production access across enterprise systems and access policies before expansion, since this is a common scaling failure point.
Step 4 If outcomes are mixed, reduce scope and fix one failure class#
Mixed pilot results are a signal to tighten scope, not broaden it. Isolate one failure class at a time, remediate it, and rerun the same gate set before expansion.
If the pilot touches consumer flows, include liability treatment in go or no-go decisions. Current industry discussion notes uncertainty in how unauthorized-transaction protections apply when agents initiate payments, and that uncertainty can make expansion premature for some use cases. Before expanding scope, align your go/no-go controls with implementation details in the Gruv docs.
Avoid common launch mistakes and recover fast#
A recurring launch failure pattern is weak controls, not missing another protocol announcement. In practice, teams can overweight visibility signals and underweight governance, reliability, and reconciliation evidence before autonomous execution goes live.
Step 1 Re-rank options by failure mode, not by logo#
Treat mentions of Stripe, Visa, or Mastercard as market signals, not launch proof. Re-rank AP2, MPP, ATXP, and conventional rails by the failure you most need to prevent first: duplicate execution, unclear dispute ownership, weak operator visibility, or missing audit trace.
Use one hard checkpoint for your first transaction class: can you trace approval record, payment request, provider reference, ledger posting, and final outcome without manual stitching? If not, logo visibility did not reduce your real launch risk.
Step 2 Keep a known vs. unknown register and force proof#
Assume protocol claims are unverified until you prove them in your environment. Clean testing signals are not a guarantee in agentic systems: one reported incident degraded within hours with queue spikes, duplicate tasks, and stuck high-value orders, and cited design gaps where retry behavior or missing permission checks duplicated financial actions. Treat examples like this as practitioner evidence, not audited benchmark data.
Keep a two-column register for each option: public claim versus verified behavior. Before promotion, force proof checkpoints for retry replay, permission enforcement after scope changes, and late or duplicate provider responses.
Step 3 Freeze autonomy when revocation or dispute ownership is unclear#
Do not enable autonomous spend until revocation works and dispute ownership is explicit. If you cannot show who can grant, narrow, and revoke authority, pause new agent permissions and close that governance gap first.
Recovery planning should include dispute evidence workload, not just policy language. One cited scenario required 11 weeks, three rounds of evidence submission, and $430 in ops costs on a $299 transaction. Your pack should already include approval logs, revocation events, intent records, provider records, and a dispute-ready evidence bundle.
Step 4 Block scale-up until reconciliation stays clean for a full billing cycle#
Treat reconciliation as a scale gate, not post-launch cleanup. Expand only after end-to-end trace quality stays clean for one full billing cycle across successful, failed, reversed, and returned transactions.
If unmatched items persist, reduce scope instead of adding volume. The fastest recovery path is usually to stop scale-up, isolate one break class, fix it, and rerun the same checks before reopening traffic.
Choose vendor posture with a simple buy extend wait rule#
After closing obvious control gaps, use a hard rule: buy when fit and accountability are clear, extend when your controls already do most of the risk work, and wait when material operating risk is still unresolved. This keeps rail decisions tied to evidence instead of protocol momentum around AP2, MPP, or ATXP.
Step 1 Apply a buy now test#
Buy now only if the provider fits the markets you already chose and can support the full transaction lifecycle: intent, negotiation, and execution. Use one practical checkpoint: a test trace that links approval or delegation record, payment request, provider reference, ledger posting, and final outcome without manual stitching.
Also verify exception ownership in practice, not in pitch language. If ownership of held, reversed, returned, or disputed transactions is unclear, you are trading faster launch for heavier cleanup risk later.
Step 2 Extend your current stack first when control depth is already strong#
If your ledger is the source of truth, reconciliation is clean, and delegated permissions plus revocation are already enforced, extension can be the lower-risk move. In that case, treat new compatibility claims as signals to test, not a reason to replace payment and control layers that already work.
This path is strongest when pilot evidence already exists: request logs, provider references, ledger journals, and reconciliation exports. One risk is assuming an adapter fixes governance when it only changes the interface.
Step 3 Wait when unknowns are still material#
Wait when your team lacks a formal strategy and risk management framework, or when material data quality, governance, trust, and security risks are still unresolved. Network momentum can be real while provider implementation maturity in your context still needs independent validation.
Be explicit about rail tradeoffs before you proceed. Centralized API paths can allow operator intervention and data access, while transparent-chain paths can make transaction activity broadly visible. If either tradeoff conflicts with your customer or regulatory posture, pause and record it as a no-go.
Step 4 Record the decision as a tradeoff, not a story#
Close with a one-page memo: why buy, extend, or wait; what speed you gain; what control depth you give up; and what evidence would change the decision. That shared record gives finance, ops, and compliance a common basis for execution.
Use a Gruv-first implementation slice to de-risk production#
Do not activate every rail at once. Start with one narrow Gruv slice that proves traceability, policy enforcement, and exception handling end to end, then expand.
Step 1 Scope one money lifecycle and freeze the edges#
Start with one transaction class and define the full chain: collect, hold or track, convert only when needed, and pay out. Do not treat longer-term rail choices as a substitute for the first production test: one explainable path from action to financial outcome.
Use one hard checkpoint for every test transaction: the same internal request ID should map to approvals, provider reference, ledger posting, and final outcome. If that chain requires manual stitching, keep the slice in prototype status.
Step 2 Use Virtual Accounts and Payouts where enabled to expose failure modes early#
Where enabled for your Gruv program and market, include Virtual Accounts and Payouts in the first slice so you can observe asynchronous credits, returns, and replay attempts early. These states can expose weak implementations quickly.
Treat idempotent posting as a release condition. Replayed credits, returns, or callbacks should create one financial posting with a visible replay trail, not duplicate booked movements.
Step 3 Keep controls fully on from day one#
Run the slice with compliance-first controls active from the start: KYC and AML policy gates where required, KYB where your program uses it, approval chains, masked PII handling, and reconciliation exports. That is how you confirm control logic and money movement work together in production conditions.
This is a control-heavy environment, not a shortcut environment. The 2025 "regulatory shift" framing, plus explicit focus on governance and controls, supports a stricter launch posture. Keep scope narrow until you are audit-ready.
Step 4 Instrument statuses and webhooks so ops can diagnose quickly#
Give ops and finance clear, shared statuses for meaningful states, and map each webhook or callback into that state model. When issues happen, the team should quickly determine whether money moved and who owns the next action.
Assume dependencies can fail at runtime. Track visible checkpoints for adapters or components as a basic sanity signal, but do not confuse visible activity with production reliability.
Step 5 Expand only after exception handling is routine#
Add new rails, countries, or conversion paths only after the first slice consistently handles returns, retries, and escalations without manual log reconstruction. If exceptions still require senior-engineer archaeology, hold scope. The operating rule is simple: prove one slice until failures are understandable and recoverable, then widen.
Conclusion#
The right move is not to pick the loudest protocol. For AI agent payment rails, launch readiness is a proof question: can you operate one market with clear authority boundaries, usable reconciliation, and explicit ownership when outcomes go wrong?
The mismatch is still the core issue. Conventional rails were built assuming a human is in the flow, and they can falter when software needs to pay for things like an API call, GPU second, or data token. Activity from Visa, Mastercard, PayPal, and efforts like x402 signals momentum, but it is not proof of production readiness on its own.
Before expanding, make sure your team can answer these from stored transaction records, not screenshots or chat threads. Use this checklist as a gate, not a planning exercise:
-
What exactly was authorized?
-
What happened at the provider?
-
What hit your ledger?
-
Who owns the exception path?
-
Defined one vertical, one transaction pattern, and one primary success metric
-
Built a known-vs-unknown table for x402 and announced programs (Visa Intelligent Commerce, Mastercard Agent Pay, PayPal Agent Toolkit)
-
Documented delegated authority, revocation, and dispute ownership for your own implementation
-
Verified an end-to-end trace from request to ledger to outcome in your pilot environment
-
Passed pilot gates before adding countries, rails, or transaction types
On the known-vs-unknown table, separate design intent from production evidence. For x402 and the announced network programs, public positioning can be clear while implementation maturity remains uncertain, so avoid treating network visibility as proof of settlement guarantees, broad acceptance, or proven reliability.
For audit trace and delegation, test real and broken cases, not only happy-path demos. If one checklist item is still unproven, hold scope. That restraint is often the difference between a credible launch and an expensive demo.
For the EU licensing side, read EU Payment License Types Explained: EMI vs PI vs Agent Model for Platforms.
Need a market-by-market readiness review before rollout? Talk with Gruv.
Frequently Asked Questions
What are AI agent payment rails?
AI agent payment rails are payment methods and protocols that let software initiate, authorize, and execute transactions without a human checkout step. In practice, they are often API-first, with the agent sending structured payment fields and receiving structured outcomes such as authorization results, transaction IDs, and follow-up actions.
Why are traditional payment rails insufficient for autonomous agents?
Traditional rails are a weak fit because autonomous workflows need payments that are programmable, always available, and not dependent on manual approval at each step. Card networks often rely on human identity flows, and bank transfers can depend on business-hour operations, which breaks down for always-on machine activity.
What problem does `AP2` claim to solve compared with `MPP`?
The article does not support a proven performance ranking between AP2 and MPP. It supports a narrower point: the hard problem is authorization, constraints, auditability, and accountability, not basic payment initiation. Treat both as emerging protocol efforts with uncertain implementation maturity.
What does delegated payment authority mean in practice?
Delegated payment authority means an agent can execute payment decisions independently, but only within user-defined parameters and authorized boundaries. Those boundaries should be explicit and reviewable. If they are unclear, delegation is harder to control and audit.
How should operators compare card rails, bank rails, and stablecoin options?
Start with transaction shape and operating constraints, not protocol headlines. Card rails still carry human-centered identity assumptions, bank rails can conflict with always-on automation when they operate on business-hour schedules, and stablecoin paths should be tested for fee transparency, reconciliation, and operator visibility. If transaction count is high and ticket size is low, stress-test cost assumptions before defaulting to any rail.
What is the minimum evidence required before scaling beyond a pilot?
The minimum evidence is original transaction artifacts retained from the system, not reconstructed later. Keep the structured request artifact and the processor outcome artifact together, including the authorization result, transaction ID, and any required follow-up actions. Before scaling, requests, provider references, ledger records, and outcomes should match end to end without manual stitching.
Which unknowns matter most when evaluating `ATXP`, `MPP`, and `AP2`?
Implementation maturity is the key unknown across all three. Important open questions include fee model or all-in cost, settlement behavior, production usage, dispute ownership, reconciliation, and enforcement of authority boundaries. Evaluate all three on whether they preserve auditable accountability under real operating conditions.
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
Includes 1 external source outside the trusted-domain allowlist.
Educational content only. Not legal, tax, or financial advice.
Related Posts

The Freelance Payment Penalty: A Modeled Audit of Platform Fees, FX Spreads, and Payout Delays
The money rarely disappears through a single, easy-to-spot fee. The real loss is stacked. A marketplace takes its commission, a processor adds a charge for international cards, a bank or payment company converts the currency at a spread, a platform holds the funds before release, and a wire sheds a little to intermediaries on the way in. Each layer looks defensible on its own, but the worker feels the combined result as a smaller deposit and a later payday.

How to Respond to a Subpoena for Business Records
Move fast, but do not produce records on instinct. If you need to **respond to a subpoena for business records**, your immediate job is to control deadlines, preserve records, and make any later production defensible.

A US Expat's Guide to Investing in UCITS ETFs to Avoid PFIC Issues
The real problem is a two-system conflict. U.S. tax treatment can punish the wrong fund choice, while local product-access constraints can block the funds you want to buy in the first place. For **us expat ucits etfs**, the practical question is not "Which product is best?" It is "What can I access, report, and keep doing every year without guessing?" Use this four-part filter before any trade: