
Quick Answer
Start with a leakage map and only then choose tactics for subscription revenue recovery. Define what counts as recovered in ledger terms, assign one owner per failure lane, and verify each change with event-level proof from billing to settlement. Implement involuntary churn controls in order: updater services such as Account Updater, normalized retry logic, and then Dunning management. If lift is uncertain, pick the option with clearer observability and rollback instead of adding more automation.
How Revenue Recovery Decisions Affect Margin#
Subscription revenue recovery is an operating discipline, not a billing add-on. Your job is to find where money is leaking, separate recoverable loss from true churn, assign an owner to each fix, and prove in your own data that the fix worked.
That distinction matters because teams use "recovery" to mean very different things. Some mean failed-payment collection. Others mean broader retention work. Some vendors bundle almost anything that keeps customers subscribed under the same label. The useful definition is narrower and more practical: actions to regain lost or at-risk income, with an explicit focus on fixing the cause of loss, not just sending more retries.
If you are a founder, product lead, finance owner, or ops manager, the real work is connecting product design, pricing, retention, and collections under real constraints. Those constraints include limited engineering time, uneven reporting, support load, and the need to protect customer trust while improving margin. That is why this guide treats recovery as a sequence of decisions, not a feature checklist.
A good starting rule is simple: do not assume all churn is recoverable, and do not let one tactic stand in for the whole problem. If your first instinct is to jump straight to dunning management, pause. Ask which customers have recoverable revenue, what failure mode you are trying to address, and what evidence will tell you the fix is real.
Use this guide like an operator#
Work through the next sections in order. Make three decisions before you expand scope:
- Set the boundary. Separate at-risk income you can plausibly recover from losses you cannot. That keeps forecasts honest.
- Name the owner and proof. For each intervention, decide who is responsible and what checkpoint counts as success. A recovery claim without a baseline or event trail is just a vendor story.
- Choose the next best move, not every move. If the root cause is unclear, pick the option that gives you cleaner observability and an easy rollback before you add complexity.
A common failure mode is easy to recognize. Teams buy tools, launch retries, send more emails, and then cannot explain whether revenue was actually recovered, merely delayed, or offset by more complaints and later churn. Product blames billing, finance distrusts the numbers, and ops inherits the cleanup.
This guide aims to give you something more useful. You should leave with a clear order of operations, a way to validate impact against your own baseline, and a sharper filter for vendor claims. Some claims sound strong until you try to tie them back to internal evidence.
For a step-by-step walkthrough, see Building Subscription Revenue on a Marketplace Without Billing Gaps.
Define revenue recovery boundaries and goals#
Set the boundary first: treat revenue recovery as broader than failed-payment retries, but narrower than "anything that improves retention."
| Bucket | What it covers | Reporting note |
|---|---|---|
| Prevention of involuntary churn | Avoidable payment or billing friction | Report separately |
| Recapture of failed collections | After a charge or invoice fails | Dunning management belongs here, not in the full recovery strategy |
| Churn-risk retention | Customers likely to cancel but still recoverable | Report separately |
| Pricing leakage | Packaging, discounting, or fee ownership decisions that reduce realized revenue | Report separately |
Work in four buckets and report them separately:
- Prevention of involuntary churn from avoidable payment or billing friction.
- Recapture of failed collections after a charge or invoice fails.
- Churn-risk retention for customers likely to cancel but still recoverable.
- Pricing leakage from packaging, discounting, or fee ownership decisions that reduce realized revenue.
That split keeps Dunning management in the right place: it belongs in failed-collection recapture, not the full recovery strategy. If you report dunning lift as total recovery, you can miss larger losses in retention design or pricing structure.
Define "recovered" in ledger terms before you choose tools. Decide whether the metric is gross invoice value, collected cash, or net after fees and taxes. That choice matters in Stripe setups: Managed Payments charges 3.5% per successful transaction and is in addition to standard processing fees, with additional charges noted for subscription payments. In Connect, economics also change depending on whether Stripe handles pricing or you handle pricing.
Your checkpoint is straightforward: finance should be able to trace each recovered dollar from billing event to payment, fee line, and payout or settlement entry. Treat claims from Recurly, 2Checkout, or MGI Research as directional inputs, not your KPI baseline.
Once those boundaries are explicit, map where loss occurs and assign ownership for each fix.
For a more detailed look at dunning at scale, see The $1 Billion Revenue Recovery Opportunity: How Smart Dunning Saves Subscriptions at Scale.
Baseline leakage map and ownership#
Build your baseline leakage map around one question: where does revenue get lost between a buyer or billing signal and the action that should follow? Then give each row one accountable owner so the work stays operational instead of turning ambiguous.
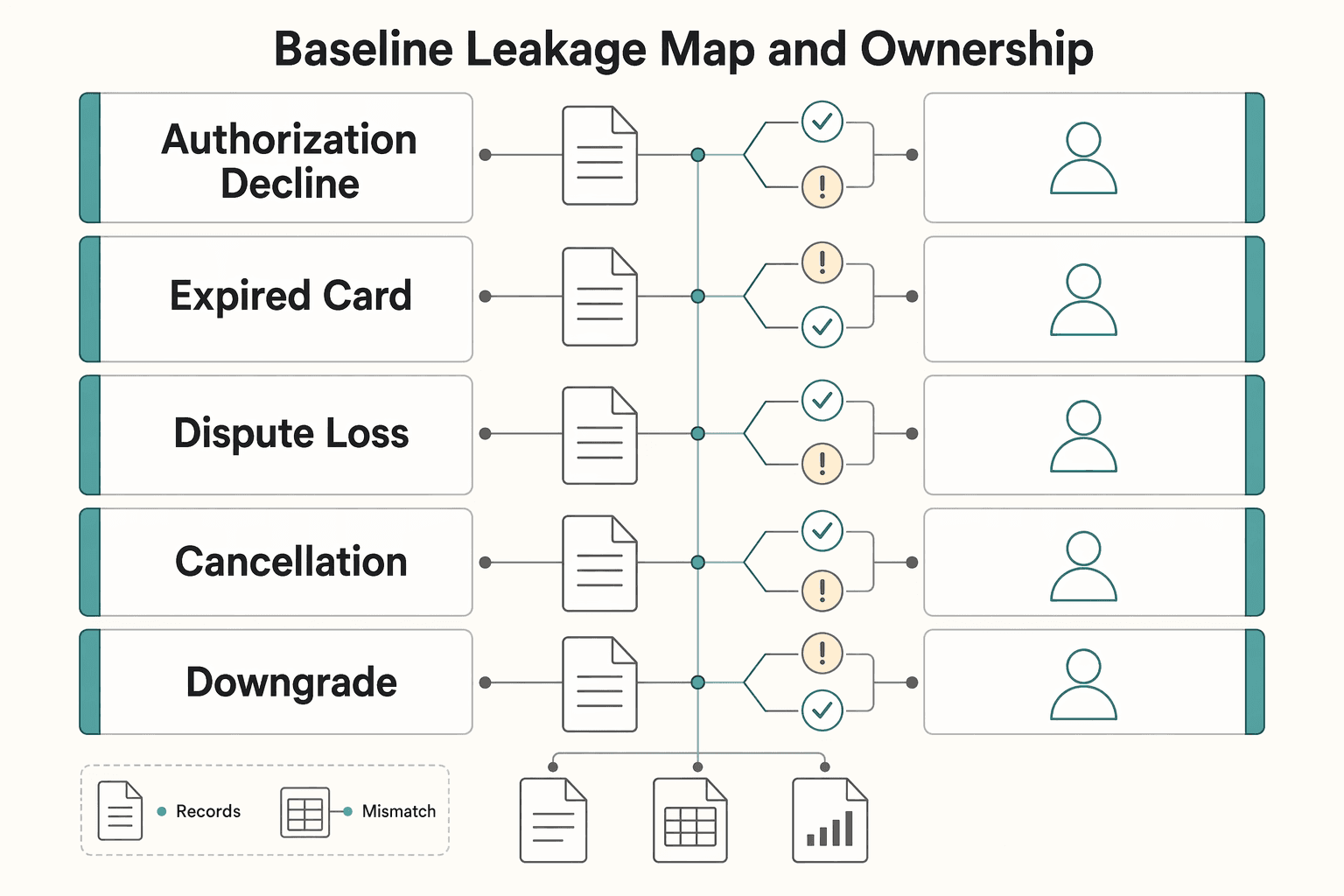
A workable model is one primary owner per lane:
- Product for customer-facing UX and lifecycle interventions.
- Finance for reconciliation, reporting, and metric definitions.
- Ops for queue hygiene, exception handling, and action completion.
Use a simple inputs -> steps -> outputs record for every row:
- Input: the event source that starts the case.
- Step: the intervention you run.
- Output: the expected state change.
- Evidence: where finance can verify what happened.
| Failure point | Primary owner (example) | Example intervention | Evidence location |
|---|---|---|---|
| Authorization decline | Ops | Retry flow review; Advanced Authorization Report when available | Gateway events, decline-reason export, payment-attempt history |
| Expired card | Product | Payment update flow; Pre-expiration billing when enabled | Notification logs, card-update events, renewal outcome |
| Dispute loss | Ops | Dispute prevention service or manual review rules where supported | Dispute record, representment file, final outcome |
| Cancellation | Product | Save flow and lifecycle messaging tests | Cancellation event, reason capture, funnel/session data |
| Downgrade | Product | Plan comparison and packaging updates | Plan-change event, MRR delta report, account history |
| Pricing mismatch | Finance | Price table audit and contract-to-invoice checks | Invoice line items, price catalog, reconciliation file |
| Tax or compliance block | Finance | Validation review and exception routing | Validation result, blocked invoice record, settlement exception log |
If a row cannot be tied to both an event source and an evidence location, do not count it in recovery reporting yet.
Related reading: How to Create a Disaster Recovery Plan for a SaaS Business.
Choose first bets with a prioritization matrix#
Pick one or two first bets by scoring each intervention on impact, implementation effort, operational risk, and time-to-confidence, then force a decision: do now, do later, or do not do yet. If you cannot define how lift will be verified from your own records, treat it as later.
Use 1-5 scoring if helpful, but attach one proof sentence per score:
- Impact: tie it to your current loss mix.
- Effort: name the actual integration or process change.
- Risk: state what could break or add customer friction.
- Time-to-confidence: name the evidence you will read (for example, payment attempt history, invoice state changes, dispute outcomes, or exception volume).
Use the failure mix, not vendor claims#
If losses are concentrated in card freshness issues, evaluate updater services first (Account Updater, External Account Updater, Visa Account Updater, Mastercard Automatic Billing Updater) before adding dunning complexity.
If disputes are rising, prioritize prevention workflow and evidence quality before expanding retry logic. Extra retries without clean evidence can increase ops load and make outcomes harder to explain.
Before any change, capture a baseline snapshot from your own systems (decline reasons, expired-card share, dispute categories, and manual exceptions). Without that baseline, you can report activity, but not verified recovery.
Compare options on control first, then cost#
Compare 2Recover add-on, Revenue Recovery Tools, Stripe Billing, and Recurly on the same filters every time: controllability, reporting depth, and integration burden. The grounded pricing specifics here are Stripe-specific, so use them as the benchmark and require equivalent detail from other options before you commit.
| Option or model | Controllability | Reporting depth | Integration burden | What to verify before decision |
|---|---|---|---|---|
| Stripe Standard | Lower fee-design control in a pay-as-you-go model | Baseline billing and payment reporting | Stripe presents no setup, monthly, or hidden fees; domestic cards listed at 2.9% + 30¢ per successful transaction | Whether fixed pricing matches your unit economics |
| Connect where Stripe handles pricing for your users | Lower control over end-user processing fees (Stripe sets and collects them) | Clear separation of who is charged | Stripe states no additional account, payout volume, tax reporting, or per-payout fees in this model | Whether simplicity is more valuable than custom fee control |
| Connect where your platform handles user pricing | Higher control, higher operator responsibility | More direct visibility into per-account and payout economics | Stripe lists $2 per monthly active account and 0.25% + 25¢ per payout sent | Whether pricing control is a real requirement |
| Managed Payments | Additive-fee model | Review must include base processing plus Managed Payments layer | Stripe states 3.5% per successful transaction in addition to standard processing fees | Whether additive fees still work for your margin profile |
2Recover add-on / Revenue Recovery Tools / Recurly | Confirm with vendor documentation | Confirm event-level and finance-audit reporting | Confirm integration and operating burden | Do not decide until controls, reporting, and costs are equally specific |
For Stripe economics, also include listed extras where relevant: 0.5% for manually entered cards, 1.5% for international cards, and 1% if currency conversion is required.
Write one tradeoff rule before you buy#
Document this rule in the matrix: if recovery lift is uncertain and ops load is high, choose the option with stronger observability and rollback.
If two options look similar on expected lift, pick the one finance and ops can verify, unwind, and explain fastest.
Execute involuntary churn controls in order#
For involuntary churn, execution order matters more than retry volume. Treat recovery as a payment-failure life cycle, then add controls in layers so you can verify what actually improved.
| Order | Control | Key check |
|---|---|---|
| 1 | Card-freshness controls | If expired or replaced cards are a meaningful part of your decline mix, turn on updater services first |
| 2 | Retry policy | Add retry policy after failure states are normalized |
| 3 | Idempotent retry execution | Use stable attempt IDs and state checks so replayed jobs do not create duplicate charges or ledger confusion |
| 4 | Dunning management | Layer it after retries are state-aware and send messages only when the failure state is clear |
| 5 | Pre-expiration reminders and dispute handling | Add as later controls; if disputes are already a leading loss lane, move prevention and evidence quality forward |
- Start with card-freshness controls.
If expired or replaced cards are a meaningful part of your decline mix, turn on updater services first, then measure whether renewals recover after payment credentials are updated.
- Add retry policy after failure states are normalized.
With more than 2,000 reported decline codes across providers, map raw responses into clear action buckets before automating retries. Avoid repeated retries on hard-failure or elevated-risk states.
- Make retry execution idempotent before expanding coverage.
Use stable attempt IDs and state checks so replayed jobs do not create duplicate charges or ledger confusion while async gateway outcomes are still settling.
- Layer
Dunning managementafter retries are state-aware.
Send messages only when the failure state is clear and the customer has one obvious next action. If complaint volume or false-positive recovery attempts rise, fix timing and status mapping before adding more messaging. For deeper message design, see A Guide to Dunning Management for Failed Payments.
- Add pre-expiration reminders and dispute handling as later controls.
Use reminders to increase valid payment-method updates ahead of renewal, and use dispute handling with a full evidence trail from earlier phases. If disputes are already a leading loss lane, move prevention and evidence quality forward without skipping core retry discipline.
After each phase, stop and verify three checkpoints: recovery by normalized reason code, complaint trend, and false-positive recovery attempts. If recoveries improve but support friction or duplicate-charge issues also increase, pause and fix the current layer before adding the next one.
Once these controls are stable, test whether remaining leakage is still a collections problem or a pricing, product, or fit issue.
Add pricing and lifecycle interventions#
If payment-failure controls are stable but net retention is still slipping, move upstream to plan design, packaging, and lifecycle timing before adding more payment tooling.
A practical rule: stable failed-payment rates with weaker expansion or more downgrades usually point to a value and offer-fit problem, not an authorization problem. In recurring subscriptions, customers can keep paying even when perceived benefit drops below price, so cancellation can lag and hide mismatch until renewal or card-replacement moments.
Use these decision rules#
- If recovered payments rise but retention quality falls, do not treat that as success.
Check whether recovered accounts soon churn, downgrade, or need credits. If that pattern appears, you may be delaying churn rather than improving value.
- If declines are stable but net retention falls, inspect packaging before retry expansion.
Look for weak plan separation, usage-based surprises, and poor upgrade paths. Billing complexity often comes from pricing experiments, usage components, and mid-cycle upgrades or downgrades, so leakage may sit in the offer, not the charge attempt.
- If churn clusters around value-timing gaps, fix the lifecycle moment.
Look for cancellations around onboarding or renewal. Reminders can help only when customers can clearly see what they are paying for next.
Prioritize plan-level evidence over aggregate "saves." Break out retention, downgrades, and expansion by plan, cohort, and renewal month, then compare against payment metrics. If recovery is steady but a specific package underperforms, treat that as a pricing or lifecycle intervention signal.
Avoid using aggressive recovery messaging to hold poor-fit customers in poor-fit plans. That can improve short-term collections while weakening expansion and increasing support burden. Keep one shared evidence pack across product, finance, and payments, because entitlement alignment and revenue accuracy usually fail in different places.
If you need deeper execution detail on messaging, use A Guide to Dunning Management for Failed Payments. For implementation depth on plans and billing structure, use Subscription Billing Platforms for Plans, Add-Ons, Coupons, and Dunning.
Build compliance and tax evidence into the flow#
Recovered cash is not really recovered if it later stalls on missing evidence. Put compliance and tax checks at the front of the flow, and make document state visible before you expand new recovery experiments.
Treat evidence as execution data, not end-of-month cleanup. Where your stack supports gates such as KYC, AML, or VAT validation, define which statuses allow retry, posting, or manual review so holds are predictable instead of discovered late.
- Set gates before money movement or ledger finalization.
Capture decision timestamp, result code, reviewed entity, and actor so finance can trace exactly why funds are held.
- Track tax records as explicit states, not loose attachments.
For cross-border programs, keep structured states for W-8, W-9, FEIE, FBAR, and Form 1099 artifacts where enabled (for example: requested, received, validated, rejected, expired, not applicable).
- Keep an audit-ready chain from request to export.
Maintain traceability from request to review outcome to ledger posting to export pack, with immutable IDs, version history, and masked sensitive fields.
FEIE is a useful example of why state quality matters. In IRS context, eligibility requires foreign earned income and a foreign tax home, and one route uses physical presence of 330 full days in a 12-month period. A taxpayer still files a return reporting that income, and taxes on excluded income cannot also be used for the foreign tax credit (claimed on Form 1116).
Use one operating rule: if compliance exceptions are growing faster than ops can clear them, pause new recovery experiments until evidence quality is stable.
Run sanity checks before rollout#
Do not call an uplift subscription revenue recovery until your baseline is fixed and attribution is clear. Before rollout, confirm what changed, when it changed, and what else moved at the same time.
| Check | What to confirm | Example detail |
|---|---|---|
| Baselines and attribution | Freeze the pre-change window, define the exact outcome metric, and keep event mapping stable during the test | Report markets or programs separately if coverage differs |
| Ownership and rollback | Assign a named owner, a clear stop or reverse condition, and a first post-launch check | One documented production deployment flagged 47 new database changes and then reported blocked payments tied to auth issues |
| Regressions outside collection totals | Track customer friction, dispute spillover, reconciliation delays, manual exception queues, and support backlog | Pause expansion if operational strain rises faster than recovered cash |
| Qualifiers in messaging | State where an intervention is supported, when it is enabled, and how coverage varies by program or market | If qualifiers are not visible, teams will overstate results |
- Lock baselines and attribution before release.
Freeze the pre-change window, define the exact outcome metric, and keep event mapping stable during the test. If coverage differs by market or program, report those segments separately so partial enablement does not look like portfolio-wide lift. Finance should be able to trace each recovered invoice or retained subscription to one intervention and one timestamp.
- Assign ownership, rollback conditions, and verification checkpoints.
Treat each intervention as a release-confidence gate with a named owner, a clear stop or reverse condition, and a first post-launch check. This is practical risk control: one documented production deployment flagged 47 new database changes and then reported blocked payments tied to auth issues.
- Check for regressions outside collection totals.
Track customer friction, dispute spillover, reconciliation delays, manual exception queues, and support backlog alongside recovery metrics. If operational strain rises faster than recovered cash, pause expansion and fix the flow.
- Make qualifiers explicit in customer and internal messaging.
State where an intervention is supported, when it is enabled, and how coverage varies by program or market. If those qualifiers are not visible, teams will overstate results.
Related: How a Subscription Brand Recovered Revenue From Failed Payments.
Conclusion and next step#
The right next move is still decision first, not tactic first. In practice, recovery means defining scope, mapping where cash leaks, ranking fixes by tradeoff, executing in order, and verifying each result with evidence instead of vendor-style uplift claims.
A good closing checklist looks like this:
- Name the leakage before you try to fix it.
Start with the gap between revenue earned and cash collected, then separate payment failure, cancellation intent, pricing leakage, and process issues. A failed payment is not the same as a customer wanting to leave, so do not treat every miss as churn. If you are seeing mostly soft declines, that points toward payment recovery work. If failures are flat but retention is slipping, move your attention to pricing and process leakage instead.
- Build one leakage map that commercial, finance, and ops can all read.
Keep it concrete: event source, failure cause, intervention, expected state change, owner, and evidence location. The most useful checkpoint is whether you can trace one recovered invoice or subscriber account from failure event to status change to cash outcome without filling gaps by hand. If that trace breaks, your reporting is not ready for scale.
- Prioritize by tradeoff, not by feature appeal.
Score each intervention on likely impact, implementation effort, operational risk, and time to confidence. If two options look similar, choose the one with cleaner observability and a clear rollback path. A common failure mode is adding more retry and messaging steps before you trust your failure-cause data, which leaves you with more ops load and weak proof of what actually worked.
- Commit only the few actions you can verify end to end.
For each launch, keep a small evidence pack: customer or invoice ID, failure reason, intervention timestamp, before and after payment state, and final cash collection result. Also watch for spillover that can hide behind apparent gains, especially complaint volume, dispute trend, and reconciliation delay. If you cannot prove whether a lift came from recovery, retention, or a reporting change, do not call it recovered revenue.
Teams that connect collection controls, pricing choices, and process checks usually make cleaner monetization decisions because fewer blind spots survive review. Your next step is not to buy more tools. Build the leakage map and prioritization matrix first, then approve only the top interventions your team can measure, reconcile, and defend end to end.
Frequently Asked Questions
What is subscription revenue recovery, and what is outside its scope?
It is the set of actions you use to keep subscribers and regain lost or at-risk income. In practice, that can include failed-payment recapture and churn management, but not every billing or growth change belongs in the bucket. If a tactic does not clearly reduce attrition, keep a subscriber active, or bring back income you would otherwise lose, do not report it as recovery.
How is revenue recovery different from `Dunning management`?
Recovery is broader. Dunning management is one part of it, focused on failed-payment follow-up to recover revenue and reduce avoidable churn. If you need deeper detail on that lane, start with A Guide to Dunning Management for Failed Payments.
What usually causes `involuntary churn` in recurring billing?
The core trigger in the cited material is missed payments and failed charges. One excerpt reports that businesses can lose almost 6 out of 10 subscribers to involuntary churn, so failed collections should not be treated as background noise. Your first check is simple: split churn by payment-failure-related exits versus deliberate cancellations before you decide what to fix.
Which tools should a team implement first: updater services, retries, or dunning?
There is no universal first move supported by the cited excerpts alone, so start with the failure pattern you can prove. Then test one lane at a time (updater services, retries, or dunning) and compare before-and-after results using a consistent definition of recovered revenue.
How should we evaluate claims from vendors like `Recurly` and `2Checkout`?
Treat vendor claims as directional until you can see the counting rules. Ask what they include in "recovered" revenue, which failure types are in scope, how they separate retention from payment recovery, and what raw evidence you can export. A red flag is any claim that bundles retries, churn reduction, and generic revenue uplift without event-level detail or clear qualifiers.
When should we focus on pricing and lifecycle changes instead of payment-failure tactics?
Use this as a signal check: if payment-failure indicators look steady while churn or retention trends worsen, broaden the diagnosis beyond payment recovery. Recovery tactics address lost collections, but other retention problems may require pricing, packaging, or lifecycle changes.
What should finance, product, and ops each own in a recovery program?
There is no single ownership model in the cited excerpts. A practical split is: finance owns the definition of "recovered" and reporting logic, product owns customer experience and retention levers, and ops owns execution hygiene and traceability. The failure mode to avoid is shared ownership where everyone can act, but nobody can prove what changed or why.
Try a related tool
A former tech COO turned 'Business-of-One' consultant, Marcus is obsessed with efficiency. He writes about optimizing workflows, leveraging technology, and building resilient systems for solo entrepreneurs.
Sources
- bac.umd.edu/wp-content/uploads/2025/03/White-Paper_RRAFT...trusted
- gsa.gov/buy-through-us/purchasing-programs/multiple-...trusted
- irs.gov/individuals/international-taxpayers/figuring...trusted
- irs.gov/individuals/international-taxpayers/foreign-...trusted
- kings.edu/pdf/graduate-catalog-24-25.pdftrusted
- nmahoney.people.stanford.edu/sites/g/files/sbiybj23976/files/media/file/m...trusted
- revisor.mn.gov/statutes/cite/325E/pdftrusted
- sandiegocounty.gov/content/sdc/auditor/orrfaq.htmltrusted
Educational content only. Not legal, tax, or financial advice.
Related Posts

A Guide to Dunning Management for Failed Payments
If you run recurring invoices, failed payments are not back-office noise. They create cashflow gaps, force extra follow-up work, and increase **Involuntary Churn** when good clients lose access after payment friction.

The $1 Billion Revenue Recovery Opportunity in Subscription Dunning
Treat dunning as an operating decision, not a copy tweak. The goal is simple: recover revenue with low friction and enough traceability that product, support, and finance can all trust what happened.

How a Subscription Brand Recovered Revenue From Failed Payments
A **failed payment recovery case study** is only useful if it helps you decide what to keep, change, or stop. If it skips baseline evidence, decision rules, and verification, it is a win story, not operating guidance.