
Quick Answer
Start by auditing your stack with the 3-Tier Criticality Framework, then create fallback actions for each critical app you cannot afford to lose. A practical disaster recovery plan for saas means you own continuity: keep accessible exports, define outage owners, and prepare a Tier 1 Code Red folder for invoicing and payment continuity. When disruption hits, verify impact first, communicate with a fixed update format, and execute the preselected workaround instead of improvising.
The Business-of-One Resilience Protocol: Your SaaS Disaster Recovery Plan#
A usable disaster recovery plan for saas starts with one plain fact: your provider is responsible for restoring its service, and you are responsible for keeping your business running when that service is unavailable. For a business of one, that is not abstract. If a key app is down for hours or days, you need to know what stops, what can wait, and what you can do by hand.
In SaaS, this split is often called the Shared Responsibility Model. In practice, the vendor runs the platform; you own your data and continuity. Four terms matter for the rest of this article:
- Business continuity: your documented plan to keep operating and limit outage damage.
- Backup ownership: keeping your own copies, exports, or recovery method instead of relying only on vendor defaults.
- Recovery time objective (RTO): how quickly you need a function back.
- Recovery point objective (RPO): how much data loss you can tolerate.
In practice, it looks like this:
| Provider responsibility | Your responsibility | Practical consequence if you ignore your side |
|---|---|---|
| Keep the SaaS platform available and recover their service | Decide how your business keeps moving when the app is unavailable | You wait on the vendor while delivery and operations stall |
| Protect and restore their environment at a platform level | Protect your SaaS data with your own backup ownership approach | A deletion or sync issue can leave you with incomplete records |
| Offer whatever export and restore options their product supports | Verify what you can actually export, restore, and recover | You discover too late that point-in-time or partial recovery is not available |
| Support data access and migration within their product constraints | Document fallback steps for each critical app and dependency | Cross-tool workflows can break, and recovery may depend on vendor support |
Three failure modes tend to show up first when you work alone. Cash collection blocked means your billing, invoicing, or payment admin tool is unavailable right when you need to send invoices or chase payment. Client delivery blocked means files, approvals, or customer messages are trapped inside a tool your client never thinks about. Cross-tool dependency breakage is the subtle one. One app fails, then calendar syncs, automations, forms, or CRM records stop moving with it.
The real tradeoff is convenience versus control. SaaS makes operations lighter, but many products still do not offer fine-grained recovery controls, and moving data out can be complex, slow, or impossible without vendor support. That is why your most important decision is not which vendor promises resilience. It is whether you have your own documented recovery steps for each critical product you rely on.
A real plan is a working document with processes and specific steps. A useful readiness checkpoint is a tabletop test. If you cannot walk through fallback actions for each critical app, the plan is not ready. So start by auditing every tool in your stack by how badly its failure would interrupt your business continuity.
Step 1: Audit Your Stack with the 3-Tier Criticality Framework#
Audit every tool by business impact in one pass. Your goal is to separate outages that stop revenue, outages that delay delivery, and outages that are mostly inconvenient.
Classify each tool with three direct decision rules#
Use these rules tool by tool. Do not make exceptions:
| Tier | Apply this decision rule | Business impact if it fails | Owner | Fallback expectation | Prepare next in Step 2 |
|---|---|---|---|---|---|
| Tier 1 | If this tool is unavailable today, can you still get paid or deliver the core service clients bought this month? If no, place it here. | Revenue interruption or immediate delivery stop | You | Same-day manual or alternate path | Offline access, current exports, direct communication method, manual transaction or delivery option |
| Tier 2 | If this tool fails, can you still operate for a few days without visible client disruption, even if work is slower? If no, place it here. | Delivery delay, admin backlog, reputational drag | You | Short-term workaround with acceptable delay | Backup copies, alternate tool or manual process, dependency notes |
| Tier 3 | If losing this tool is frustrating but does not block payment or promised delivery, place it here. | Convenience loss only | You | Wait, pause, or skip temporarily | Minimal notes only; no heavy recovery prep |
For solo operators, Tier 1 often includes invoicing, payment admin, primary client email, and your main delivery repository. Tier 2 often includes scheduling, file storage, CRM, proposal tracking, and contract-signing tools. Tier 3 is usually convenience software you can pause without affecting payment or delivery.
Treat ownership as an operating rule: the vendor restores its service, but you own continuity for your business. For each tool, record the owner, admin login location, export location, status page, support path, and any SLA, SOW, or documentation location.
Do not mark a tool as recoverable just because an export exists. If restore has never been tested, mark it as unverified and queue it for Step 2.
Run the audit in one pass#
| Audit step | Detail |
|---|---|
| List every tool | Include billing, payments, email, storage, contracts, CRM, scheduling, support inboxes, forms, and client portals |
| Map dependencies and integrations | Note what breaks if that tool fails and which downstream steps stall |
| Assign each tool to a tier | Apply the decision rules above, not brand preference or subscription cost |
| Flag single points of failure | Mark tools with one admin account, no alternate access, no export path, or one critical integration everything depends on |
- List every tool you rely on. Start with billing, payments, email, storage, contracts, CRM, scheduling, support inboxes, forms, and client portals.
- Map dependencies and integrations. Note what breaks if that tool fails and which downstream steps stall.
- Assign each tool to a tier. Apply the decision rules above, not brand preference or subscription cost.
- Flag single points of failure. Mark tools with one admin account, no alternate access, no export path, or one critical integration everything depends on.
Checkpoint: every Tier 1 and Tier 2 tool should have a named owner, a fallback expectation, and a clear Step 2 prep item. Any blank field becomes your immediate follow-up list.
Step 2: Implement Your "Circuit Breakers" for Each Tier#
Turn the audit into recovery decisions by tier. For each tier, set the maximum downtime you can accept (RTO) and the maximum data loss you can tolerate (RPO). Then build preparation around those limits.
| Tier | Objective | Required preparation | Activation signal | Acceptable downtime posture |
|---|---|---|---|---|
| Tier 1 | Keep revenue moving if the primary tool fails | Offline-accessible Code Red folder, payment fallback, billing contacts, verified export routine | You cannot invoice, collect payment, or access billing records in the primary tool | Minimal interruption, same-day manual continuity |
| Tier 2 | Keep delivery and operations moving with controlled friction | Separate backup destination, restore owner, activation trigger, simple switch-over path | Outage or data issue blocks active client work past your defined limit | Short interruption is acceptable if restore or switch-over is clean |
| Tier 3 | Avoid over-planning low-impact tools | Deliberate defer decision plus a review trigger | Repeated failures, or the tool becomes client-facing or revenue-adjacent | Wait, pause, or replace later |
Build your Tier 1 Code Red folder#
For Tier 1, plan for failure at the worst moment. Protect revenue continuity first.
| Folder element | Requirement |
|---|---|
| Access | Store the folder where you can access it without relying on the same billing system |
| Invoice template | Include a plain invoice template you can edit quickly |
| Payment links | Include direct payment collection links |
| Billing contacts | Include current client billing contacts |
| Invoice export | Include a recent export of open invoices or equivalent billing records |
| Cadence note | Backup cadence pending policy/source verification. |
Do not assume a cadence before testing. Export the file, open it on a different device, and confirm it contains what you need to invoice and reconcile. If you cannot send a bill from this folder in a short test, it is not ready.
Define a simple Tier 2 switch-over path#
Tier 2 is about keeping delivery moving, not rebuilding your full stack.
For each Tier 2 tool, document:
- Backup destination
- Restore owner
- Activation trigger
- Switch-over path
Keep the backup destination separate from the primary tool. Write the fallback path in plain language: project tracking moves to a simple list or sheet, files come from a separate synced copy or export, and calendar access comes from a locally available copy or export. Then verify one current restore path before an incident so you know it works.
Human error can be harder to recover from than obvious outages, so keep restore steps clear. Avoid adding unnecessary complexity that creates new failure modes.
Defer Tier 3 on purpose#
For Tier 3, a defer decision is fine if you make it explicit. Mark these tools as deferred, then set a quick review trigger so priorities stay aligned with business impact.
Use simple triggers: repeated failures, a new client-facing dependency, or movement closer to billing or delivery.
Related: How to Create a Disaster Recovery Plan for Your Freelance Business.
Step 3: Your "Day Zero" Emergency Action Checklist#
On Day Zero, use this order: verify, communicate, activate, then stabilize and log. Treat alerts as a signal, not proof that recovery is working.
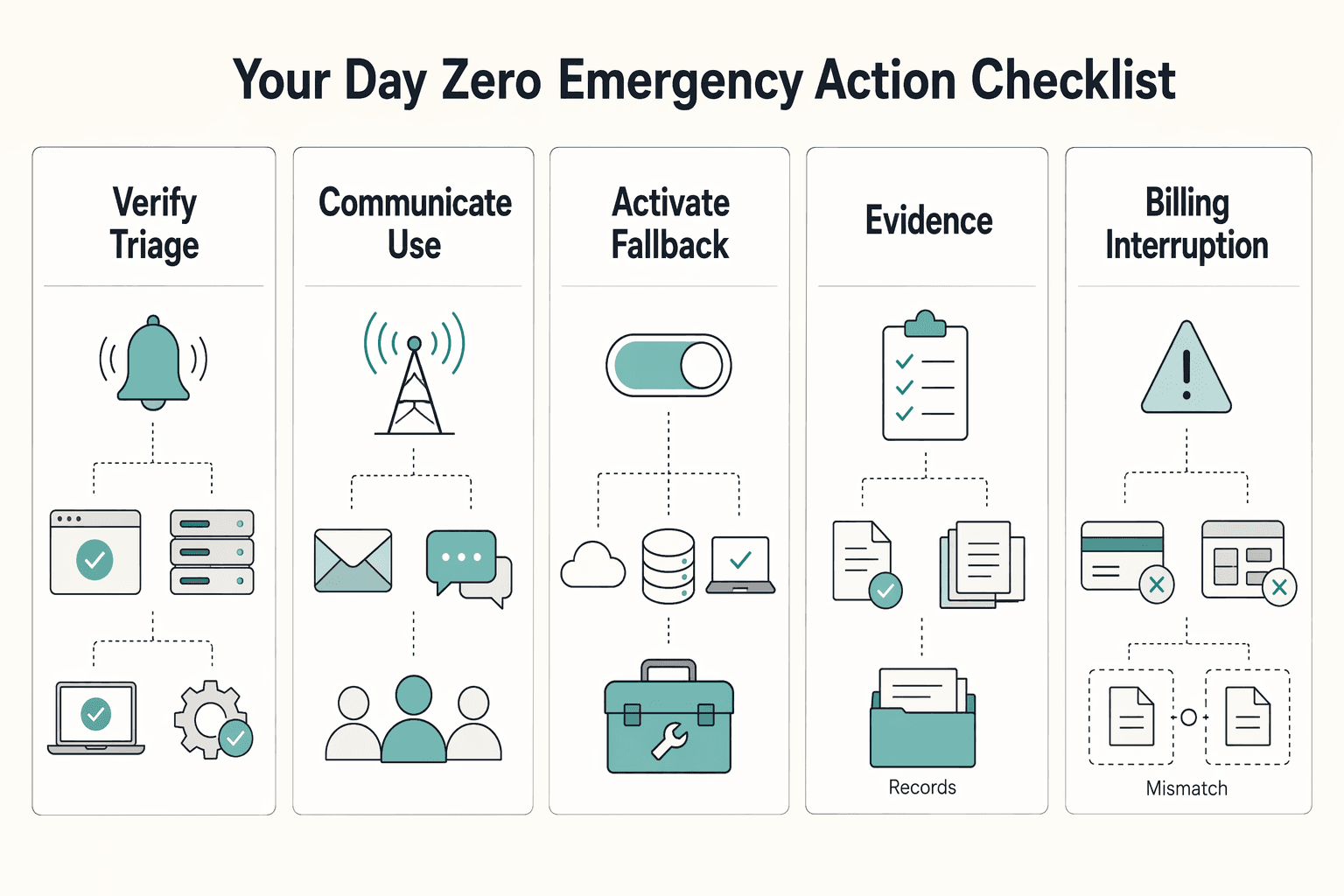
| Response phase | What to do |
|---|---|
| Verify and triage | Confirm whether the provider is reporting an incident on its official status channel, do a quick local sanity check, and identify which Tier 1 and Tier 2 tools are blocked |
| Communicate | Use one message format every time: status, impact, workaround, next update |
| Activate fallback | Activate the fallback by outage type and owner |
| Stabilize and log | Record the timeline, affected tools, fallback activated, and gaps to fix in the next review |
- Verify and triage first
Confirm whether the provider is reporting an incident on its official status channel. Then do a quick local sanity check for access or configuration issues on your side. Identify exactly which Tier 1 and Tier 2 tools are blocked before you take client-facing action. Decision point: if impact is limited, keep the response narrow; if core billing or delivery tools are affected, move to communication and fallback activation.
- Communicate with one reusable structure
Use one message format every time: status, impact, workaround, next update. For clients, keep it outcome-focused: what is affected, what is still running, and how delivery continues. For internal stakeholders, keep it operational: affected tools, current owner, selected fallback, and open checks.
- Activate the fallback by outage type and owner
| Outage type | Owner | Immediate action | Step 2 fallback asset |
|---|---|---|---|
| Billing interruption | Billing owner | Keep invoicing and collection moving manually | Code Red folder: invoice template, payment links, billing contacts, recent invoice export |
| File access interruption | File/data owner | Switch to the separate copy or export and continue from there | Separate synced copy or export |
| Project-system interruption | Delivery owner | Move active work tracking to the backup workflow | Simple list or sheet switch-over path |
- Stabilize and log before you close
Record what happened, what you used, and what slowed you down: timeline, affected tools, fallback activated, and gaps to fix in the next review. If records changed during the incident, keep the audit trail and run a checkpoint such as batch-number validation to catch duplicate or skipped entries.
We covered this in detail in How to Create a Secure Backup Strategy for Your Freelance Business.
Conclusion: From Anxiety to Antifragility#
Your business continuity plan is not finished until you can access it during a disruption and run it without improvising. In a real incident, that is the difference between waiting on dependency timelines and executing prepared continuity steps.
-
Finish the shift to owner mode. Stop assuming a provider timeline is enough for your business. Your continuity depends on what you can activate yourself right now. Verification point: confirm the latest plan is accessible, key escalation contacts are current, and the fallback path you chose is still usable.
-
Use the plan to reduce incident drag. Without a plan, one disruption can ripple across interconnected operations and affect customers. With a plan, you detect and validate disruptions faster, execute the fallback you already selected, and recover with less guesswork. That is the practical value of continuity planning and disruption detection.
-
Store the evidence and rehearse it. Keep the plan and critical recovery records somewhere you can access if primary systems are unavailable. Add a dated test note each time you check it. A common failure mode is documentation that exists but cannot be used under pressure. Final step: schedule a short drill, validate the plan end to end, and record what you learned.
For a step-by-step walkthrough, see Build a One-Page Business Continuity Plan for a Natural Disaster. Want to talk through your setup? Talk to Gruv.
Frequently Asked Questions
Who is responsible if your SaaS data is lost?
Assume you are. Under shared responsibility, the provider covers platform infrastructure and uptime, while you protect your data, business processes, and account access. Treat any vendor backup as support for their recovery, not proof that your business can recover. For every critical app, write down who exports the data, where the copy lives, and what you use if the app is unavailable.
Is there a simple template you can actually use?
Yes. Keep it lean: classify tools, define fallback actions, and keep a Day Zero checklist you can run under pressure. If a tool is only inconvenient, do not spend Tier 1 effort on it. Mark each app as revenue-stopping, operations-critical, or nice-to-have, then finish the first group before touching the rest. | Item | What it means in practice | Common mistake | What to record now | |---|---|---|---| | Provider backup | A copy the vendor may use to restore their own service after a platform incident | Assuming it will restore your deleted records, account mistakes, or working process on your timeline | Whether the contract says anything about backup and recovery requirements | | Your backup | A copy you can access separately from the provider when you need continuity | Leaving it untested, incomplete, or stored in the same place as the live app | Export frequency, storage location, and one file-open check | | RTO | The maximum downtime you can accept before the impact is unacceptable | Treating it as a technical metric only, instead of a business limit | Your downtime tolerance for each critical tool, ideally in hours | | RPO | The maximum data-loss window you can accept | Backing up weekly when losing a week of data would hurt client work or billing | Your acceptable data-loss window, ideally in hours |
How should you back up data from your SaaS apps?
Start with each app's built-in export or account-data option, then save the export in a separate location you control. Do not hard-code old click paths into the plan. Record that the current export path is pending vendor/source verification before the plan is used. The checkpoint that matters is simple: open the export and confirm at least one current record is readable.
What should you do first if your invoicing app goes down?
Use the outage checklist you already defined: verify the outage scope, communicate through your planned channels, activate the billing fallback, and log what changed. Avoid sending a client message before you know whether the issue is local, account-specific, or provider-wide. Open your Code Red folder now and confirm the invoice template, recent open-invoice export, and payment links still work.
What do RTO and RPO mean in plain English?
RTO is how long you can afford to be down. RPO is how much recent data you can afford to lose. The practical point is that both should drive your prep, and contracts often express them in hours, which is more useful than vague promises. Write a downtime limit and a data-loss limit for each Tier 1 tool, even if you refine them later.
How often should you test your plan?
Test often enough that your fallback stays real, not theoretical. A useful test is whether you can access the backup location, open the latest export, and find the vendor escalation contact without hunting. Keep evidence of the test, because a dated note or screenshot is stronger than memory.
What should you ask a vendor before you trust their recovery claims?
Ask for the contract terms on risk classification, availability requirements, and backup or recovery requirements, with RTO and RPO measured in hours if available. Then ask for named vendor roles, escalation contacts, a SOC 2 or equivalent artifact, and proof of annual disaster recovery testing with the findings retained. One red flag is when marketing promises reliability but support cannot produce current recovery documentation.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
- academia.edu/27448086/The_Philosophy_of_Software_Code_and...trusted
- cisa.gov/sites/default/files/2024-05/Compendium%20CIS...trusted
- cybersecurity.yale.edu/saas-paas-dr-planstrusted
- dgs.ca.gov/-/media/Divisions/PD/PTCS/OPPL/GP-Updates--C...trusted
- dodcio.defense.gov/Portals/0/Documents/Library/CloudSecurityPla...trusted
- newcastlede.gov/DocumentCenter/View/27598/E4-Attachment-4-Fu...trusted
- pmc.ncbi.nlm.nih.gov/articles/PMC8993411trusted
- security.cms.gov/policy-guidance/information-system-contingen...trusted
Educational content only. Not legal, tax, or financial advice.
Related Posts

Canada Digital Nomad Visa Planning for Visitor Status and Work Permits
The phrase `canada digital nomad visa` is useful for search, but misleading if you treat it like a legal category. It is shorthand for existing Canadian status options, mainly visitor status and work permit rules, not a standalone visa stream with its own fixed process. That difference is not just technical. It changes how you should plan the trip, describe your purpose at entry, and organize your records before you leave.

How to Create a Disaster Recovery Plan for Your Freelance Business
Build this as a baseline to create a freelance disaster recovery plan you can run under pressure: clear recovery targets, a restore order, client-ready messages, and one restore proof record. This helps reduce improvisation during an outage.

The Best Security Scanners for Your Web Application
The right scanner stack is the one you can run on a schedule, triage without drama, and explain later with evidence. A web app scanner, or DAST-style tool, tests a live application and flags likely weaknesses. It does not give complete coverage, and it does not make you compliant on its own.