
Quick Answer
Split only when your evidence says the monolith is now the bottleneck. The strongest triggers are shared deploy cycles repeatedly stretching toward 30-45 minutes, defects in the Payment module spilling into unrelated flows, and a bounded domain needing its own release cadence. Keep a monolith or modular monolith when those signals are absent, especially if CI/CD and tracing are still inconsistent. Decide from incident timelines and lead-time history, then extract one narrow unit with a rollback path.
Start with delivery evidence, not ideology#
The real decision is not monolith versus microservices as ideology. It is whether separating parts of your system is likely to improve delivery enough to justify the added operational complexity.
Start with the most grounded checkpoint in this research set: your project scope, team experience, and long-term business strategy. The tradeoff is clear. Small monolithic systems can be straightforward to build and maintain, while microservices can increase flexibility and independence but also introduce major operational complexity. If your scope is still manageable and your team is not yet strong at running distributed systems, an early split may create more problems than it solves.
It also helps to treat popular architecture stories as anecdotes, not proof. The examples in this pack point in opposite directions, so they are signals to interpret cautiously rather than universal outcomes.
Use your own operational evidence before you commit. This evidence set supports a context-dependent tradeoff, not a default winner, and it does not provide payment- or compliance-specific implementation guidance.
That is the lens for the rest of this guide. We will compare a monolith, a modular monolith, and microservices without assuming a default winner, then use context-based checkpoints to evaluate those choices.
At a glance comparison for payment platforms#
For payment platforms, a conservative reading of these sources is to keep a monolith until you have clear evidence that independent releases and smaller failure scope are worth the added operating load. This table stays strict about evidence and marks unsupported payment-control and compliance claims as not established.
| Criteria | Monolith architecture | Modular monolith | Microservices architecture |
|---|---|---|---|
| Core shape | Unified software system in a single codebase, deployed as one unit | Not defined in the provided excerpts | Application split into smaller, independent services |
| Deploy independence | Low. Components are deployed together | Not established in sources | High. Each service can be developed, tested, deployed, and scaled on its own |
| Incident blast radius | Higher. One failure can impact the entire system | Not established in sources | Lower in principle. Failures may stay isolated to one service |
| Staffing load | One shared codebase with centralized teams | Not established in sources | Higher operating burden at scale, with cross-functional teams owning services end to end |
| Change failure risk | Shared release means one bad change can affect the whole application | Not established in sources | Risk can be more localized per release, but added service count can increase operational complexity |
| Idempotency keys handling | Not established in sources | Not established in sources | Not established in sources |
| API webhooks complexity | Not established in sources | Not established in sources | Not established in sources |
| Ledger journals integrity | Not established in sources | Not established in sources | Not established in sources |
| Reconciliation exports effort | Not established in sources | Not established in sources | Not established in sources |
| KYC policy gates | Not established in sources | Not established in sources | Not established in sources |
| KYB policy gates | Not established in sources | Not established in sources | Not established in sources |
| AML policy gates | Not established in sources | Not established in sources | Not established in sources |
| Best fit by team shape and delivery pressure | Centralized teams in a shared codebase where full-app deploys are still acceptable | Not established in sources | Cross-functional teams owning services end to end where independent releases are needed |
The key difference here is operational. A monolith gives you one codebase and one deployment unit. Microservices give you independent deployability and potentially narrower failure impact, but they also add coordination and platform overhead.
For payments, do not assume architecture choice alone improves control quality. These sources do not support the idea that any architecture automatically handles idempotency keys, webhooks, ledger journals, reconciliation exports, or KYC, KYB, and AML gates better.
What the supported signals actually tell you#
If your main bottleneck is unrelated changes shipping together, microservices offer a structural advantage through independent deployment. If your main problems are not caused by deployment coupling, splitting may not address the root cause.
Team model is the other divider. The sources describe monolith-oriented work as centralized around a shared codebase, while microservices assume cross-functional ownership per service. That shifts release ownership and incident scope over time.
A grounded caution is the reported six-month migration from a Rails monolith to 27 microservices, followed by a "27 problems instead of one" outcome that signals higher operational complexity. It is not proof against microservices, but it is a credible failure mode.
How to use this table in practice#
Use the table to test whether your pain is structural enough to justify a split. Check deployment evidence first: do any payment domains truly need to be developed, tested, deployed, and scaled independently? Check incident evidence second: does one defect in shared code impact unrelated payment flows, or do failures usually stay contained?
Then rely on concrete records, not architecture debate. Review release history, incident timelines, and examples of domains that genuinely need different release timing.
Practical recommendation#
Favor a monolith if your team operates well in one shared codebase and payment changes do not require independent release cadences. Favor microservices when repeated deployment coupling or broad failure impact is materially slowing delivery. Do not use this comparison as proof that architecture shape alone will fix payment controls. Define those controls explicitly before you split.
If instant payout requirements are part of the architecture debate, Real-Time Payment Use Cases for Gig Platforms: When Instant Actually Matters shows where faster payout expectations actually change the operating model.
Payment architecture prerequisites before you split anything#
Do not split payment architecture by default. Split only when you have clear evidence that team autonomy and independent scaling are worth the added operational complexity, because rushing into microservices before readiness is a known failure mode.
For many teams, the real readiness checks are organizational and operational. If you are still under about 8-10 developers or have limited operational expertise, a monolith is often the safer default. In payments, that timing matters because scale, security, and regulatory pressure can raise the cost of architectural mistakes.
| Prerequisite area | Grounded guidance | Status in this grounding pack |
|---|---|---|
| Team and ownership model | Architecture tends to mirror team structure (Conway's Law). | Supported |
| Core tradeoff fit | Monoliths optimize for simplicity and development speed; microservices optimize for autonomy and independent scaling. | Supported |
| Operational maturity | Limited ops maturity is a signal to avoid early microservice adoption. | Supported |
| Observability baseline (distributed tracing, Prometheus, error ownership) | Potential internal validation item; not established in the provided excerpts as a mandatory gate. | Not established as a source-backed mandatory gate |
| Deterministic money movement (idempotency keys, replay-safe webhooks) | Potential internal validation item; not established in the provided excerpts as a mandatory gate. | Not established as a source-backed mandatory gate |
| Accounting clarity (ledger journals, reconciliation exports) | Potential internal validation item; not established in the provided excerpts as a mandatory gate. | Not established as a source-backed mandatory gate |
| Boundary visibility (Payment module, Payouts service, Virtual Accounts coupling map) | Potential internal mapping item; not established in the provided excerpts. | Not established in provided excerpts |
The practical takeaway is simple: keep the monolith until your team structure and operating model can support distributed complexity, then split only where autonomy and independent scaling are clearly needed.
For a step-by-step walkthrough, see Choosing ERP Sync Patterns for Payment Platforms.
When should you break apart the payment stack#
Split only when repeated delivery and incident evidence shows the monolith is the bottleneck, not because microservices feel like the next step.
Use a hard-trigger checklist#
| Decision point | Stay monolith now | Split now |
|---|---|---|
| Deployment blocking | Deploys are routine and not regularly blocking other teams. | Shared deploys repeatedly block teams or create freeze windows (for example, deploy cycles that repeatedly stretch toward 30-45 minutes in your environment). |
| Cross-team collisions | Most changes ship without heavy release coordination. | Unrelated teams frequently collide because one release train gates multiple domains. |
| Blast radius | Defects are usually contained to the changed area. | A bug in the Payment module affects unrelated flows. |
| Scaling asymmetry | Scaling the whole app is still acceptable. | One domain has materially different demand (for example, one module consuming most resources, or needing much higher scale than the rest). |
| Release cadence | Core payment domains can move on one cadence. | A bounded domain needs independent release timing to avoid slowing the rest of the stack. |
| Operational readiness | CI/CD and tracing are not consistently reliable yet. | You can run independent deploys and diagnose cross-service issues confidently. |
If you cannot show repeated delivery pain plus repeated reliability pain, stay with the monolith. Stay monolith when delivery is still fast, failures are contained, and your team is not ready to operate distributed complexity.
The stay-monolith branch#
This is especially true when the app and team are still small and releases are frequent without major scale pain. In that situation, splitting usually adds overhead before it adds value and can turn into a distributed monolith.
The split-now branch#
Split when a clearly bounded domain needs independent scaling or release cadence badly enough that shared deployment is slowing execution. In payment stacks, the first extraction depends on where the measured bottleneck is, and there is no universal first service to carve out. Profile bottlenecks first so you are solving measured constraints, not org friction.
Evidence that should decide the call#
Make the call from a small, recent evidence pack:
| Evidence | What to review | Decision use |
|---|---|---|
| Incident timelines | Whether Payment module failures spread into unrelated flows, and how long recovery took | Recent evidence for the split or no-split call |
| Deploy lead-time history | Whether shared releases are causing repeated blocking | Recent evidence for the split or no-split call |
| Operational records | Whether exceptions cluster around specific domains, releases, or retry-heavy periods | Use these signals to choose sequencing |
Use these signals to choose sequencing. If the evidence is mixed, keep the monolith and re-check after targeted bottleneck profiling.
If ERP handoffs are part of the bottleneck, SAP Integration for Payment Platforms: How to Connect Your Payout Infrastructure to SAP ERP shows the rollout and rollback details that usually surface before a split.
Before committing to a split, map your stop/go gates to concrete integration constraints and rollback checks in the Gruv docs.
Which service should move first and which should stay put#
Move the highest-pain, lowest-coupling domain first, and keep tightly entangled logic in the monolith, or modular monolith, until boundaries are stable.
If shared deploys keep blocking teams, one module needs isolated scaling, or a bug in one payment area still affects unrelated flows, start with the bounded unit closest to that pain. In one fintech case, carving out a scoped Payments domain first worked because it could become its own deployable unit.
Pick the first deployable unit, not the most important domain#
Your first extraction should be the domain you can release and roll back with minimal hidden dependencies. Profile first and use real bottleneck data, not org structure, to choose it.
If a single area is driving disproportionate load, for example near the "80% of resources" warning sign, or monolith deploys are already around 30 minutes, that domain is a stronger candidate for an independent deployable unit.
What should stay put first#
Keep domains that still change together in one place. If a path still depends on shared data, shared release timing, and side effects across multiple flows, splitting it early can recreate the same coupling across service boundaries and make operations harder.
First-cut candidates compared#
Use this as a selection aid, not a universal ranking.
| Candidate | Boundary clarity | Coupling risk | Rollback risk | Better first move when |
|---|---|---|---|---|
Scoped Payments domain (as seen in one case) | Often clearer when payment incidents, deploy friction, and scaling pressure cluster | Medium, depends on shared dependencies | Medium | Teams are blocked by shared deploys and the module needs isolated scaling |
| Module with clear bottleneck data | Clear when profiling shows concentrated load | Medium | Medium | One module is consuming a disproportionate share of resources |
| Entangled cross-cutting domain | Usually unclear early | High | High | Better kept in the monolith or modular monolith until boundaries are clearer |
If two options are close, choose the one with measurable recent pain, clear bottleneck evidence, and a rollback plan you can explain in a few steps.
If finance-system coupling is the deciding factor, Intacct vs. NetSuite for Payment Platforms: Which ERP Handles Multi-Currency and High-Volume AP Better helps frame where downstream AP and currency workflows start shaping architecture choices.
How to migrate in phases without breaking money movement#
Migrate incrementally, not in a single rewrite. Use the Strangler Fig pattern to replace features step by step instead of rewiring the whole app at once.
Before you split, make sure you already have reliable CI/CD and tracing. If those are weak, migration risk usually goes up because failures are harder to detect and isolate across multiple services.
| Phase | What to prove | Move forward when | Pause or roll back when |
|---|---|---|---|
| Readiness baseline | CI/CD and tracing are reliable | Deployments are predictable and traces are usable end to end | Build/release reliability or tracing coverage is still inconsistent |
| First incremental split | A narrow boundary can be separated safely | Ownership and rollback paths are clear for that boundary | Failures cross boundaries and accountability is unclear |
| Operate and evaluate | The split improves control without adding fragile coordination | Incidents stay contained and teams can recover quickly | Recovery depends on high-coordination handoffs |
| Expand selectively | Benefits justify added complexity | Independent deploy/scaling gains are clear | Operational overhead grows faster than delivery gains |
The point of phased migration is blast-radius control. A widely cited 2008 database-corruption incident that caused three days of downtime is a reminder that architecture changes should reduce outage scope, not shift risk into new failure modes.
Keep the tradeoff explicit throughout. Microservices can unlock independent deploys and scaling, but they raise ongoing operational cost. If a split improves control and independent delivery, continue. If it mostly adds coordination overhead and unclear ownership, pause and tighten boundaries before moving more responsibility.
How to keep payment data and audit trails correct across services#
Keeping records correct across service boundaries starts with readiness and clear boundaries before any split. The sources here support architecture-level guidance, not payment-specific control mechanics. In a monolith, tightly coupled components can hide dependency assumptions. In microservices, services can be deployed independently, but the tradeoff is higher operational complexity.
| Control point | What to do | Why it matters |
|---|---|---|
| Critical state ownership | Map dependencies and boundaries and document which service owns each critical state change | The core risk is unclear ownership across boundaries, especially during incidents |
| Service-local views | Treat service-local views as secondary unless ownership is explicitly defined | Operators need one clear answer when services disagree |
| Operator handling | Define what operators should do when services disagree | Incident handling stays consistent |
| Boundary readiness | Use an explicit readiness checkpoint before decomposition, then test boundary behavior before broader cutover | Helps avoid turning a split into an unmanageable distributed system |
| Repeatable checks | After each boundary change, run the same verification checks and confirm service outputs still align | Deploy success and logs are not a substitute for cross-service correctness checks |
| Pause condition | Pause further decomposition if you cannot consistently validate one clear answer across boundaries | Tighten boundaries and observability first |
Choose one authoritative outcome path#
Before you carve out any money-related capability, map dependencies and boundaries and document which service owns each critical state change. The core risk is unclear ownership across boundaries, especially during incidents.
Treat service-local views as secondary unless ownership is explicitly defined. Define what operators should do when services disagree so incident handling stays consistent.
Define boundary behavior up front#
Use an explicit readiness checkpoint before decomposition, then test boundary behavior before broader cutover. This helps avoid turning a split into an unmanageable distributed system.
Failure blast radius also changes with architecture: monolith failures can impact the whole system, while microservice failures may be isolated. Validate that your team can operate those failure modes before expanding the migration.
Verify with repeatable cross-boundary checks#
After each boundary change, run the same verification checks and confirm service outputs still align. Deploy success and logs are useful, but they are not a substitute for cross-service correctness checks.
If you cannot consistently validate one clear answer across boundaries, pause further decomposition and tighten boundaries and observability first.
Final-payment obligations are one place where boundary mistakes show up fast. Contractor Offboarding and Final Payment Compliance: What Platforms Must Do When a Contractor Leaves is a useful check on what still has to work when payouts and compliance records span teams.
Compliance and tax boundaries that architecture choices can break#
Architecture can create compliance risk when payout release is separated from the record that explains why release was allowed. If your platform has KYC, KYB, AML, tax-document, or filing obligations, keep one authoritative compliance record even when execution is split across services.
Where the architecture starts to matter#
One common failure mode is that one service releases money while checks and documents live elsewhere. If approval logic is split, operators may see "approved" but still be unable to show which checks, documents, and versions were in force at that moment.
A monolith can keep decision and evidence close together. A modular monolith can keep that benefit if one module still owns the final decision record. Full decomposition raises the bar because you need durable cross-service evidence, not just success responses.
| Architecture choice | Policy gate ownership | Evidence continuity risk | What to verify before payout release |
|---|---|---|---|
| Monolith architecture | Can be centralized in one codebase | Can be lower when records are versioned and queryable | Confirm the final approval record references the exact user, business, and tax-doc snapshot used |
| Modular monolith | Can remain centralized with cleaner boundaries | Can increase if modules cache different states | Check that one module remains authoritative for approve-or-block decisions |
| Microservices architecture | Can split across onboarding, risk, payouts, and reporting services unless explicitly centralized | Can be high unless decisioning is explicitly centralized | Require a single approval artifact or decision record that downstream services consume, not reinterpret |
If you split services, keep one operator rule: payout execution should consume a final decision, not recalculate it.
Tax documents and reporting continuity#
For W-8, W-9, and 1099 flows where enabled, keep the recommendation narrow: use one canonical document state, one owner for amendments, and a clear record of which version fed reporting. The grounding here does not establish specific W-8, W-9, or 1099 rule thresholds or deadlines.
| Topic | Grounded detail | Why it matters |
|---|---|---|
| W-8/W-9/1099 flows where enabled | Keep one canonical document state, one owner for amendments, and a clear record of which version fed reporting | Preserves reporting continuity when services split |
| FBAR threshold | Filing is required when a single-account maximum value or aggregate maximum account values exceed $10,000 | The system must still reproduce filing inputs after decomposition |
| FBAR no-file condition | No FBAR is required if $10,000 was not exceeded at any time during the calendar year | Threshold logic must remain reproducible after service splits |
| FBAR value reconstruction | Reconstruct maximum account value as a reasonable approximation of the greatest value during the year | Needs an auditable trail across services |
| FBAR currency record | Record values in U.S. dollars rounded up to the next whole dollar, and retain the exchange-rate source when no Treasury rate is available | Exchange-rate evidence has to stay queryable |
| FBAR amendment path | File a new full FBAR, check the Amend box in Item 1, and provide the Prior Report BSA Identifier | Prior filing data must stay in the same auditable trail |
| FBAR XML filing | Omission of required elements can cause rejection | Required-element validation cannot be lost in a reporting split |
FBAR is FinCEN Form 114. Filing is required when a single-account maximum value or aggregate maximum account values exceed $10,000, and no FBAR is required if $10,000 was not exceeded at any time during the calendar year.
After service splits, you still need to reconstruct maximum account value as a reasonable approximation of the greatest value during the year, record values in U.S. dollars rounded up to the next whole dollar, and retain the exchange-rate source when no Treasury rate is available.
Use this as a hard architecture check: can your system still reproduce filing inputs after decomposition? If not, pause and fix the boundary before any further split.
FBAR amendment and submission paths also show boundary risk. An amendment requires filing a new full FBAR, checking the Amend box in Item 1, and providing the Prior Report BSA Identifier. In FBAR XML filing, omission of required elements can cause rejection. If reporting is its own service, keep the prior BSA identifier, filed values, and required-element validation in the same auditable trail.
VAT validation and cross-border invoicing#
If your product includes VAT validation in cross-border invoicing or marketplace payments, keep one owner for the validation result and its evidence, then make invoicing and payouts consume that state consistently. The grounding here does not establish jurisdiction-specific VAT rules, so avoid treating this as market-by-market legal guidance.
Market variance you should not hand-wave away#
This grounding supports FBAR mechanics, including the $10,000 threshold, the April 15th due date, and the automatic extension to October 15th. It does not establish exact KYC, KYB, AML, W-8, W-9, 1099, or VAT requirements for each market.
So keep the sequencing practical: centralize the final compliance decision and filing dataset first, then split execution paths around that control point. If you cannot show one authoritative record for approval, amendments, and reporting inputs, the architecture is adding compliance debt.
Related: High-Earners vs. Low-Earners: A Breakdown of Platform Choices for Indian Freelancers.
The hidden operating cost of microservices in payments#
The hidden cost is operational, not conceptual. Microservices can give you faster independent deploys, but they also create ongoing operational overhead that a monolith or modular monolith may avoid.
Once you split services, architecture quality depends less on the diagram and more on whether the distributed system is actually operable during incidents.
What your team now owns#
In a monolith, most routing and release control stays in one coordinated codebase. In microservices, your team must explicitly own the runtime layer too, including service boundaries, deployment coordination, tracing coverage, and incident response across services.
The key point is ownership durability. These are not one-time setup tasks, and "shared" ownership without clear operators is usually where costs and response time drift.
The observability tax is real#
Weak CI/CD and weak tracing are strong reasons not to split. If you cannot run reliable CI/CD and tracing, service boundaries will likely make operations harder, not easier.
In practice, the burden shows up in day-to-day operations: cross-service diagnosis, release coordination, and keeping tracing usable across services. Clear ownership is what keeps those systems useful over time.
Speed gains versus sustained headcount#
| Option | Deploy independence | Operational overhead | Observability complexity | Typical fit |
|---|---|---|---|---|
| Monolith architecture | Lowest | Lowest | Lowest | Small app/team with healthy release velocity |
| Modular monolith | Medium | Medium | Medium | Growing teams that need structure without full distribution |
| Microservices architecture | Highest | Highest | Highest | Teams ready for sustained platform operations |
Use team-size guidance as a heuristic, not a rule. One cited framework maps 1-10 developers to monolith, 10-50 developers to modular monolith, and 50+ developers to microservices. The same framing emphasizes that the real decision is usually economic and operational, not trend-driven.
That caution shows up in consolidation behavior too. One cited 2025 survey excerpt reports 42% of organizations consolidating services into larger units. Treat that as a signal to validate your own context, not as a universal benchmark.
If your current monolith already ships quickly and incidents are understandable, keep it or modularize first. Split only when independent deploys solve a proven coordination problem large enough to justify permanent operating cost.
If the pressure to split is really coming from ERP handoffs, ERP Integration for Payment Platforms: How to Connect NetSuite, SAP, and Microsoft Dynamics 365 to Your Payout System helps separate integration pain from core payment-architecture limits.
Scenario choices for CTOs and product teams#
Start monolith-first unless a specific domain is under sustained pressure and you can show that splitting it will improve release speed or scaling flexibility without creating more operating risk than it removes.
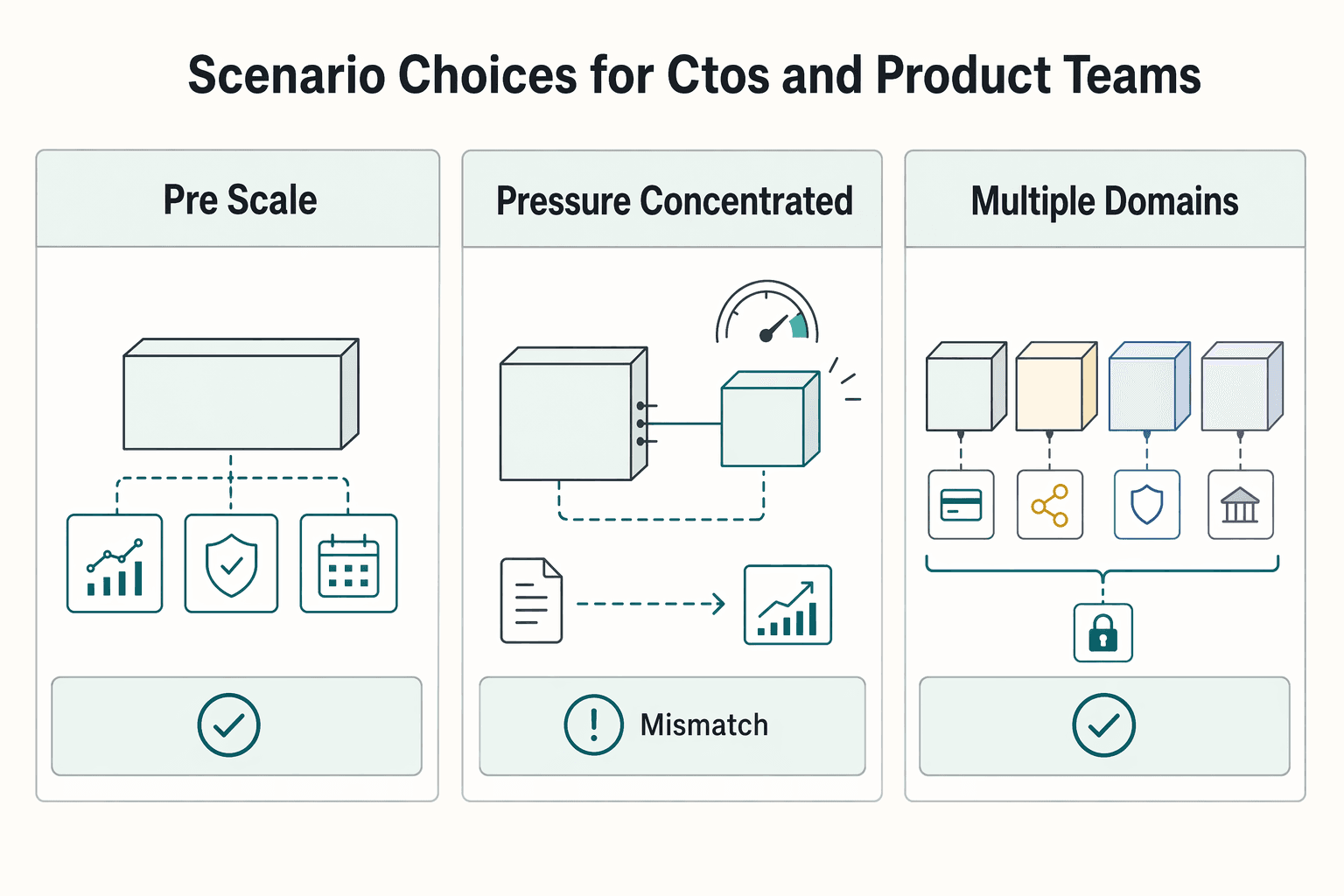
| Scenario | Recommended shape | Business outcome | Main risk to watch |
|---|---|---|---|
| Pre-scale, one delivery train, shared roadmap | Monolith architecture | Lower-risk delivery for many teams at this stage | If pressure concentrates in one domain, scaling everything together can add unnecessary cost and effort |
| Pressure is concentrated in one domain (for example, payments) while other areas are stable | Extract the pressured domain first and keep the initial split narrow | Targeted scalability and faster releases where pressure is real | Cross-service debugging and coordination overhead can arrive early if boundaries are unclear |
| Multiple domains need independent release cadence and ops maturity is already strong | Selective Microservices architecture rather than a full platform-wide split | Higher team autonomy, independent deploys, and scaling flexibility | Permanent platform overhead and harder diagnosis if observability and platform support are weak |
For many organizations, a monolith-first path is the lower-risk move. The decision should follow business context and organizational maturity, not architecture fashion.
When one domain is clearly the bottleneck, selective decomposition is the practical move. Make the split only when the pressure is explicit, such as localized scaling constraints.
Move to selective microservices only after you have real readiness: delivery discipline, observability, and platform support. Use an Architectural Decision Matrix to score boundaries against compliance, team size, and time-to-market, and split only where long-term business impact is clear over the next decade.
Related reading: Freemium vs Paid Tiers for Payment Platforms.
Do not split yet signals#
Do not split yet if your current system still ships frequently and your team cannot clearly show that a new boundary will reduce risk. Splitting into multiple independently deployable services adds coordination overhead, and hype-driven architecture decisions tend to age poorly.
Use the checks below as internal readiness gates, not universal industry rules. The grounding supports the general risk of extra coordination and harder diagnosis after a split, but it does not define external prerequisite gates for Idempotency keys, API webhooks, Distributed tracing, Reconciliation exports, or KYC/AML ownership.
| Stop signal | What to verify before any extraction | Why this blocks a split |
|---|---|---|
| You can still deploy multiple times a day without orchestration complexity | Confirm recent releases are frequent and do not require heavy service orchestration | This is a practical checkpoint that you likely have not earned the extra operating cost of a split yet |
| The proposed split is driven by trend pressure, not a concrete constraint | Write down the exact bottleneck or risk the new boundary removes; if it stays vague, pause | Hype-driven architecture decisions are explicitly presented as risky and likely to age poorly |
| You cannot point to a clear monolith failure mode that a split would fix | Verify whether one hotspot forces whole-system scaling or whether one component defect can break critical flows | Without a concrete failure signal, splitting can add coordination cost without clear benefit and make diagnosis harder across more network hops |
| You are treating unsupported prerequisites as mandatory split gates | Separate evidenced signals from non-evidenced ones (Idempotency keys, API webhooks, Distributed tracing, Reconciliation exports, KYC/AML) | This grounding pack does not define those requirements, so using them as hard prerequisites would overstate certainty |
A simple checkpoint still applies: if you can deploy multiple times a day without orchestration complexity, you likely have not earned the extra operating cost of a split yet.
Conclusion#
Keep your monolith or modular monolith until measured delivery and reliability pain clearly outweigh the added operating cost of splitting. Move to microservices for real deploy independence, not because they are fashionable.
This tradeoff is practical, not theoretical. Microservices increase technical and infrastructure complexity, and cross-service consistency is harder to manage. If you cannot already run reliable CI/CD and tracing, treat that as a pre-split stop signal.
Use a narrow, evidence-based next step:
- Run your decision checklist against measurable delivery and scaling pain, plus operational readiness.
- Choose one simple, fairly decoupled capability that is important to the business and changes often.
- Define verification gates before cutover, including trace visibility and proven independent deployability.
If you split, migrate incrementally with the Strangler Fig pattern and keep each step atomic. Small, bounded extractions make it easier to validate outcomes early without broad decomposition.
If you want a second opinion before committing, review the docs or book a demo to validate architecture choices against your payment flows, compliance requirements, payout boundaries, and reconciliation flow before cutover.
Frequently Asked Questions
When should a payment platform split a monolith?
Split when you need independent deploys, clearer domain isolation, or different scaling behavior, and you are ready for higher operating cost. Strong triggers are concrete: side-feature failures can take checkout down, every change requires full-regression testing, or peak traffic still breaks the system after basic capacity upgrades. If reliable CI/CD and tracing are not in place yet, wait.
What payment domain is usually the first extraction candidate?
Start with the riskiest slice that has a clear boundary. One cited approach is to begin with order management, payments, or stock reservation rather than splitting broadly. Keep the first carve-out narrow and operationally meaningful.
Can a modular monolith handle high payment volume without full microservices?
The provided sources do not set a universal high-volume cutoff. Volume alone is not a sufficient split trigger. One cited ecommerce heuristic keeps a monolith under roughly 100-200 orders per day with a 2-3 person team, but that is not a universal payment-platform benchmark. If local failures are still contained and full-regression burden is manageable, keep tightening boundaries before moving to separate services.
What must be in place before introducing service boundaries?
Reliable CI/CD and tracing are minimum readiness gates. Before splitting, prove you can deploy safely and trace incidents end to end across the current system. Also confirm the split addresses a recurring problem, such as side-feature failures taking checkout down or peak-load instability in the shared runtime.
How do we avoid duplicate payouts during retries and webhook replays?
The provided sources do not define a specific duplicate-payout control model, replay-ordering rules, or retry algorithm. Treat this as a critical pre-split requirement and define it clearly in your current system before adding service boundaries.
How do we migrate without breaking reconciliation and audit trails?
Use a phased migration, not a big-bang rewrite. The Strangler Fig pattern fits this approach by replacing slices incrementally instead of rewriting everything at once. Plan for real cost and timeline: in one cited ecommerce case, extracting a major module is estimated at three to six months and PLN 160,000-240,000, with large B2B cases exceeding PLN 250,000.
Try a related tool
A former product manager at a major fintech company, Samuel has deep expertise in the global payments landscape. He analyzes financial tools and strategies to help freelancers maximize their earnings and minimize fees.
Sources
Includes 3 external sources outside the trusted-domain allowlist.
- academia.edu/37444985/Debunking_Blockchain_The_case_for_c...trusted
- bsaefiling.fincen.gov/docs/XMLUserGuide_FinCENFBAR.pdftrusted
- fincen.gov/reporting-maximum-account-valuetrusted
- fincen.gov/report-foreign-bank-and-financial-accountstrusted
- scholarworks.waldenu.edu/cgi/viewcontent.cgitrusted
- aws.plainenglish.io/monolith-vs-microservices-what-actually-matt...external
- betterengineers.substack.com/p/monolith-vs-microservices-when-doesexternal
- cisin.com/coffee-break/the-cto-s-strategic-guide-monol...external
Educational content only. Not legal, tax, or financial advice.
Related Posts

When Instant Payout Matters for Gig Platform Payments
Instant payout is a tool, not the goal. The real operating decision is where instant timing creates measurable value, where batch timing is enough, and where both should run side by side.

High-Earners vs. Low-Earners: A Breakdown of Platform Choices for Indian Freelancers
Stop searching for the "best platform" and build a two-rail system, with one primary rail and one backup, that protects cashflow, FX, and reversals. As a freelancer, you're running a business of one. Getting paid is a core ops system, not a preference.

Contractor Offboarding Final Payment Controls for Multi-Market Platforms
Contractor offboarding is a compliance and money movement risk event, not an admin cleanup task. If you treat a departure like a simple HR ticket, contract status, access rights, tax reporting, and payout controls can all fail at once.