
Quick Answer
Choose by workload and recovery needs: Kafka fits replayable event history through offsets, RabbitMQ fits routing-heavy command handling, and SQS fits AWS-managed queue operations when simpler ownership is the priority. For payment systems under audit pressure, approve the design only after your team can prove ordering scope, retry behavior, and post-incident reconstruction for a real flow.
How to Choose Between Kafka, RabbitMQ, and SQS#
For payment platforms, the expensive mistake is usually not choosing the broker with the "wrong" benchmark. It is choosing a message design that cannot prove what happened when incidents show up under pressure.
- Proof matters more than raw speed
Start with a simpler question: can you reconstruct the sequence, not just move messages quickly? Replay and ordering are real architecture boundaries. Kafka is positioned for replay and multiple consumers, RabbitMQ supports replay in stream-oriented use, and SQS does not provide replay in that same event-history sense. Ordering also differs: Kafka per partition, RabbitMQ per queue, and SQS per message group in FIFO only.
- This comparison is for teams operating under audit pressure
If you are building payment-platform flows, broker choice becomes part of your control surface. You are deciding how much routing logic you own, how much infrastructure you run, and how much history you can recover when finance or operations asks what happened. In that context, Kafka is framed as a distributed log for persistent history and audit trails, RabbitMQ for flexible routing and traditional work queues, and SQS for AWS-native managed queueing with straightforward messaging needs.
- The real choice is Kafka, RabbitMQ, SQS, or a deliberate split
Kafka fits when replayable history and multi-consumer patterns matter. RabbitMQ fits when routing rules are central, especially with exchange-based patterns. SQS fits when you want minimal infrastructure ownership in AWS, can work with queue-level routing and SNS for fan-out, and accept retention up to 14 days rather than event-history replay. At scale, many teams use more than one broker because one tool rarely fits every payment workload well.
That is the point of this article: not a benchmark winner, but a defensible choice your team can operate, replay, and explain when incidents turn architecture into evidence.
Choose the broker by payment workload and operating constraints#
Choose the broker by workload shape and operating constraints first, then compare cost. If your system has strict requirements for ordering, durability, or incident visibility, this level of analysis is necessary. If it only runs a small set of low-risk background jobs, it may be more than you need.
| Decision lens | What to define | Why it matters |
|---|---|---|
| Workload shape | Classify each flow as point-to-point or publish/subscribe | Avoid forcing unrelated traffic into one broker pattern and discovering the mismatch during incident response |
| Failure tolerance | Decide outcomes after a timeout, a consumer crash, and repeated processing failures; include retries with backoff and graceful degradation | These are operating rules teams depend on when an incident needs a fast, clear answer |
| Ordering and processing boundaries | Apply ordering only where the business process actually needs it and name the business key that requires serialization | Keeps teams from over-constraining the whole system |
| Ops ownership before pricing | Decide who owns observability, recovery, and message-contract discipline during incidents | If no team clearly owns the answer on the last accepted message, retry state, expected outcome, and recovery path, the design is still too vague |
- Workload shape
Start by classifying traffic as point-to-point or publish/subscribe. In point-to-point, each message is consumed by exactly one receiver. In publish/subscribe, multiple subscribers can receive the same message, which is useful when one event needs to drive several downstream actions. Write this down per flow, not just per platform. A command flow, an event stream, and a status-update workflow may belong in different patterns even if they live in the same product. If you classify only at a high level, teams can force unrelated traffic into one broker pattern and discover the mismatch during incident response.
- Failure tolerance
Define acceptable failure outcomes before you pick a tool. Queues improve reliability by decoupling services and buffering spikes, but you still need explicit behavior for slow or failed consumers, including retries with backoff and graceful degradation. For each critical flow, decide what should happen after a timeout, after a consumer crash, and after repeated processing failures. Those are not implementation details to postpone. They are operating rules teams depend on when an incident needs a fast, clear answer.
- Ordering and processing boundaries
Apply ordering only where the business process actually needs it, rather than enforcing global ordering everywhere. Keep requirements explicit so your team can evaluate tradeoffs clearly instead of over-constraining the whole system. Name the business key that requires serialization. If the real need is "events for one entity" or "commands for one workflow," say that directly. Teams get into trouble when they ask for ordering everywhere even though only a narrow slice of state transitions actually depends on it.
- Ops ownership before pricing
Decide who owns observability, recovery, and message-contract discipline during incidents. Architecture choices are tradeoffs, and availability, consistency, and cost cannot all be optimized at once, so require clear operating checkpoints from day one. A simple test helps here: if a critical flow fails midway, who can explain the last accepted message, the retry state, the expected outcome, and the recovery path without opening multiple systems? If no team clearly owns that answer, the design is still too vague, regardless of expected cost.
Compare Kafka RabbitMQ and SQS for payment-grade decisions#
Make this decision from operability and evidence, not benchmark folklore. With the sources available, treat ordering, replay, throughput, and cost claims as unverified until your team validates them in your own environment.
| Broker | Best for | Ordering model | Replay model | Routing model | Failure handling | Operational burden | Payment-specific caveats |
|---|---|---|---|---|---|---|---|
| Apache Kafka | Cases where a separate broker is justified and the team expects scale pressure. In the June 18, 2024 discussion, Kafka was described as fitting "really high-scale applications," but that is a user-stated theory, not proof. | If your design uses Kafka partitions and Kafka consumer groups, map them directly to your ordering scope. Exact guarantees are not verified in this evidence pack. | Treat replay behavior as a design assumption that must be tested and documented. | If you are comparing this with RabbitMQ bindings, validate fan-out and consumer isolation in design review instead of assuming equivalence. | Require explicit retry, poison-message, and recovery procedures before approval. | Running a separate broker adds operational cost. | Do not assume broker choice alone gives you audit-ready reconciliation evidence. |
| RabbitMQ | Teams using a broker for asynchronous communication between nodes. | If your design relies on RabbitMQ bindings for ordering-related behavior, document the assumptions and validate them. Guarantees are not verified here. | Do not treat queue retries or redelivery as proven durable replay. | If bindings are part of your routing plan, review dispatch rules explicitly. | Define ownership for slow consumers, failed consumers, and bad-message handling. | Running a separate broker adds operational cost. | If disputes require reconstruction, verify what is retained and what is not. |
| Amazon SQS | AWS-centered teams where historical AWS guidance has pushed SQS and asynchronous decoupling is the priority. | If ordering matters, review FIFO queues explicitly. Exact guarantees and tradeoffs are unverified here. | Do not assume retries equal durable historical replay without proof in your implementation. | If you are comparing SQS with RabbitMQ-style binding control, document any extra routing components and validate them. | Make timeout, retry, and re-drive ownership explicit. | Verify comparative cost and performance outcomes against your own benchmarks. | Simpler-operation claims still need proof of traceability from message to payment outcome. |
A practical comparison lens is this: Kafka partitions + consumer groups vs RabbitMQ bindings vs SQS FIFO queues. Treat these as potentially non-interchangeable controls until your team validates them against the same flow and failure scenarios.
In design review, compare one concrete payment flow through each lens. Ask what defines the unit of ordering, where a second consumer would attach, how a failed consumer resumes, and what evidence remains after a message has been processed. That exercise is usually more useful than a generic feature comparison because it shows whether the broker matches the flow you actually need to run.
Unknowns to call out in review#
Throughput and cost claims are the biggest unknowns here. The main artifact is an Ask HN thread dated June 18, 2024 with 389 points and 364 comments. That shows discussion volume, not verified benchmark or pricing truth. Two other scraped comparison sources were not usable for broker facts, one blocked and one cookie-preference UI, so performance and cost claims should be marked unverified until validated.
Decision checkpoint#
If audit replay is mandatory for reconciliation, flag designs that rely only on queue retries and have no documented durable history. Require written recovery evidence, not just architecture diagrams, before you approve a payment-grade implementation.
That evidence should answer three things: where history is retained, how a consumer is pointed back to the required checkpoint, and how the rebuilt result is compared with the existing ledger or report output before normal processing resumes.
For a closer look at downstream ERP event flows, see ERP Integration Architecture for Payment Platforms: Webhooks APIs and Event-Driven Sync Patterns.
Pick Apache Kafka when replayable history is a product requirement#
If replayable event history is a hard requirement, Kafka is the stronger fit than a queue-first design. It retains events in an ordered, immutable log, so consumers can restart from specific Kafka offsets and rebuild downstream outputs after issues.
- Best for: replayable event history, multi-consumer analytics and read models, and controlled reprocessing from known checkpoints.
- Key pros: durable log retention for replay, checkpoint control via
Kafka offsets, and work distribution viaKafka consumer groups. - Key cons: higher operational discipline, risk of overfitting simple queue use cases, and failure risk if offset commit behavior is not handled carefully, for example auto-commit timing around crashes.
- Concrete use case: one event stream feeds multiple read models in parallel, while each consumer path can recover by replaying from a chosen offset.
Choose Kafka because replay and independent reprocessing are product requirements, not because it can also emulate a simple work queue. If the real need is just "send one command to one worker and remove it after success," Kafka can still be made to work, but that does not make it the cleanest fit.
Pick RabbitMQ when routing logic and command handling are the bottleneck#
Choose RabbitMQ when your main problem is routing commands to the right handler, not replaying a long event history. Its strength is explicit dispatch through AMQP, RabbitMQ exchanges, and RabbitMQ bindings, so routing rules stay visible in broker configuration.
Where RabbitMQ fits best#
RabbitMQ gives you an inspectable flow: producers publish to exchanges, bindings route to queues, and consumers read from queues. That model works well for operational command flows where handling changes by review type, risk class, or owning team.
It also keeps producers decoupled from consumers. A service can publish once, while exchange and binding rules decide which operational lane receives the command.
What to verify before committing#
Trace one command end to end: exchange, routing key, queue, consumer receipt, and ack behavior. If you cannot trace that chain quickly, routing incidents become slow to debug.
Also trace the unhappy path, not only the success path. Follow what happens when a consumer receives a command, performs part of the work, then fails before the ack. You want retry or redelivery behavior, and the operator view, to be predictable before this pattern reaches money movement or payout review flows.
Reliability is configuration-dependent. Delivery semantics vary with ack mode and broker setup, so validate how your environment behaves and design consumers accordingly.
Tradeoff to plan for#
RabbitMQ is not a default fit for replay and long-term history. It is not a default fit for large-scale event-sourcing or log-centric analytics history, so do not treat it as your only history layer if rebuild or reprocessing is a requirement.
Durable queues and persistent messages are possible, but durability under load brings operational cost. Disk I/O, garbage collection, throughput tuning, and node resource management all matter as volume grows.
Concrete payment example#
After your own KYC or AML checks produce a risk decision, publish a payout.review command to an exchange with a risk-based or review-based routing key. Bind separate queues for manual review, document follow-up, and downstream status updates so command handling stays explicit while consumers remain independent. Related reading: Accounting Cycle for Payment Platforms: How to Structure Month-End and Quarter-End Close.
Pick Amazon SQS when speed to production and AWS ownership model matter most#
Consider Amazon SQS when AWS ownership and speed to production are priorities. The case here is operational: AWS provides a decision guide for choosing an application integration service, and the provided cloud-architecture source states that managed services can provide scalability, reliability, and efficiency out of the box.
Why this choice is often sensible#
This is mainly an ownership decision. If your team needs to ship integration work quickly and keep the operational surface area smaller, a managed path can be the practical default.
That can be especially attractive when the question is not "which broker has the broadest control surface." It is "which option can the current team run cleanly without adding another system to manage." In that situation, smaller operational ownership can be the deciding constraint.
What to verify before committing#
Use the AWS artifact titled "Choosing an AWS application integration service" and include its Open PDF export in your design review so the decision has a dated reference point.
Then validate required behavior in current AWS product docs and in your own tests before approval. Check routing needs, ordering expectations, retry handling, and recovery or audit expectations explicitly rather than assuming a managed option will match them by default.
Test one operational scenario that matters to finance or ops, not just a happy-path send and receive. For example, prove what evidence remains when processing fails, when exception handling is required, and when a support team member needs to connect that path back to the business outcome.
Decision rule#
Pick Amazon SQS only when AWS ownership and speed to production are the primary constraints and your required behavior is verified. If key behaviors are not yet verified, treat fit as unproven.
Use a hybrid architecture when one broker cannot satisfy both control and history#
If you need simple operational control and replayable history, consider separating those paths instead of forcing one broker to do both. In practice, queue-style control traffic and stream-style history can require different replay, ordering, delivery semantics, and failure behavior.
A single-broker design can misfit in both directions. One cited team used Kafka for everything and ended up with a six-broker cluster, 200+ topics, and a reported $14,000/month bill, even though some topics had a single consumer at about 2 messages per second.
Another used SQS where replay was later needed, could not replay two days of events after consumption, and reportedly spent a week reconciling from snapshots and processor logs. Fit matters more than tool purity.
1. Use a clear split rule#
Use a simple workload-fit rule. Match each path to the guarantees it needs instead of defaulting to one broker for every use case. In the cited incidents, Kafka was a poor fit for simple task queues, while SQS was a poor fit when replayable event history was required.
Make the split visible in diagrams and contracts. A command should have a clear completion path, and a replayable event should have a clear place in history. If the same message is being used as both operational instruction and durable audit history, challenge that dual purpose early.
2. Validate replay before approval#
Ask one approval question: "If we must replay two days of events after a downstream defect, where does that history live?" If the answer depends on consumed SQS messages, your recovery path is likely weak.
Do not stop at the verbal answer. Ask the team to show the checkpoint they would use, the consumer they would restart, and the comparison they would run before accepting rebuilt output as correct. Replay only becomes a real control once the path is demonstrated. Hybrid designs are easier to operate when ownership is explicit:
- Platform team: broker contracts and publish rules between control and history paths.
- Domain teams: idempotent consumers and duplicate-safe or replay-safe handling.
- Ops stakeholders: reconciliation acceptance checks for recovery scenarios.
3. Define ownership boundaries early#
If these boundaries are unclear, incidents can turn into reconciliation work instead of controlled reprocessing. The handoff between the queue path and the history path is where confusion tends to appear. Define which event marks operational completion, which write is authoritative, and which team approves recovery when the two views diverge.
Related: Revenue Share Architecture: How MoR Platforms Split Payments Between Platform and Contractor.
Prevent the failure modes that create duplicate money movement and broken trust#
When you design control traffic and replayable history, assume failure is normal and design controls above the broker. Broker choice bakes in ordering, replay, delivery semantics, and failure behavior, so payout safety cannot depend on Kafka, RabbitMQ, or SQS defaults.
- Treat duplicate attempts and partial retries as possible.
No broker alone guarantees end-to-end exactly-once money movement. For Gruv payout flows, safe retries should behave like replays, not duplicates, so enforce idempotent handling at the payout and ledger boundary instead of relying on queue semantics alone. In practice, separate two checks: did the provider-facing action happen twice, and did the internal ledger advance twice? Validate both during tests and incidents.
- Use replay and ordering rules deliberately.
Kafka offsets make replay checkpoints concrete: a consumer can start earlier to replay old events or later to read only new ones. That helps when recovery depends on controlled reprocessing. But do not treat arrival order as business truth across partitions or FIFO lanes. Validate state transitions before progressing payouts. If you run on SQS, consumed messages are not replayable the same way, so keep a separate durable ledger-relevant history. This is where you should define the exact state-transition guardrails a consumer is expected to enforce, instead of assuming the broker's delivery order will protect business correctness by itself.
- Contain poison messages early.
Dead-letter handling is a reliability control, not housekeeping. Repeated failures can escalate into queue-wide lag and memory pressure. In one reported RabbitMQ spike, classic queues with prefetch at 300 saw latency rise from 50ms to 40 seconds, backlog reach 2M messages, and the broker stop accepting new messages. Route deterministic failures out of the hot path quickly so healthy payouts keep moving.
- Set stop-the-line and traceability gates before replay.
If reconciliation diverges from ledger expectations, pause automated payout release and investigate before re-drive. Require every retry path to produce a traceable chain across request, broker identifier or Kafka offset, provider reference, and final ledger posting. If that chain cannot be shown for a failed payout, do not resume automation yet. Before replay begins, define who can authorize it, what mismatch triggers the stop, and what comparison confirms the system is safe to resume. Without those gates, replay can become another source of uncertainty instead of a controlled recovery step.
If you are turning this checklist into runbooks, map each retry and dead-letter path against Gruv webhook and payout state models in the developer docs.
Roll out in phases from single queue to payment-grade architecture#
Start simple, then add capabilities only when failure evidence shows the queue pattern is no longer enough. A practical sequence is queue-first for operational work, then a streaming lane for continuous flow, then governance drills.
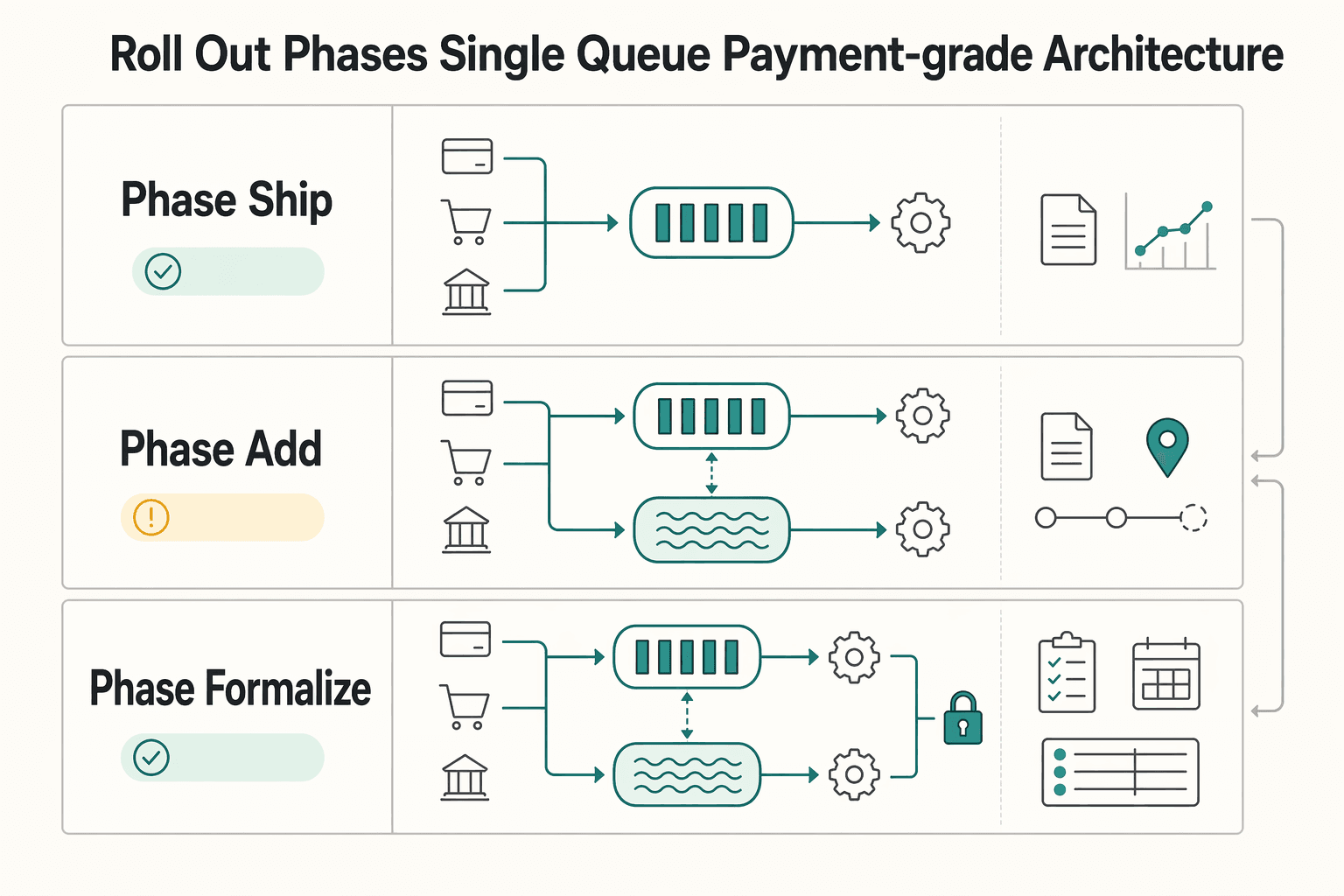
| Phase | Broker or capability | Key objective | Evidence to collect |
|---|---|---|---|
| Phase 1. Ship the core async queue path | Amazon SQS or RabbitMQ | Use a tight work-queue model where one message is one business action and one consumer handles that action | Forced-failure tests that verify retry behavior does not create a second business outcome |
| Phase 2. Add a streaming lane for continuous data flow | Apache Kafka alongside the queue path | Keep the queue path focused on operational execution and use streaming for continuous data flow and real-time processing | Evidence that the use case now needs more than acknowledge-and-remove queue flow |
| Phase 3. Formalize governance and incident readiness | Schema and version-change rules, consumer ownership, and incident runbooks | Test recovery steps instead of assuming them | Production-like drills and defined exit criteria for each phase |
Phase 1. Ship the core async queue path#
Use Amazon SQS or RabbitMQ for operational events with a tight work-queue model: one message is one business action, and one consumer handles that action. That matches traditional point-to-point queue delivery and helps avoid duplicate effort across workers.
Treat consumer acknowledgement as a hard control point, because acknowledged messages are removed from the queue. Validate retry behavior with forced-failure tests before widening scope.
Those tests should reflect real operational breakpoints. A useful pattern is to force failure after the business action has started but before the consumer is considered complete, then verify that retry behavior does not create a second business outcome.
Phase 2. Add a streaming lane for continuous data flow#
When acknowledge-and-remove queue flow is no longer enough for a use case, add a streaming platform such as Apache Kafka alongside the queue path. Keep the queue path focused on operational execution, and use streaming for workloads that need continuous data flow and real-time processing. Queueing and streaming are not interchangeable defaults, so assign each to the use case it handles best.
A practical milestone here is moving from "we can retry failed work" to "we can handle continuous event flow in real time where needed," rather than forcing every workload through one pattern.
Phase 3. Formalize governance and incident readiness#
Once both lanes are live, formalize schema and version-change rules, consumer ownership, and incident runbooks. Then run drills on production-like incidents so recovery steps are tested, not assumed.
Define exit criteria for each phase and advance only with evidence from your environment.
For governance, keep the rules short enough that teams will use them during an incident. A runbook that clearly states who stops processing, who validates incident scope, and who signs off on resumed automation is more useful than a long architecture document nobody opens when time matters.
For a step-by-step walkthrough, see Choosing ERP Sync Patterns for Payment Platforms.
Build an evidence pack that satisfies finance ops and compliance reviewers#
Turn your filing and operations setup into evidence a reviewer can follow quickly: what should happen, what happened, and what changed if corrections were required. Keep queue/replay and duplicate-prevention notes as internal-control evidence, not as stated FBAR requirements.
| Evidence area | What to retain or confirm | Grounded limit or scope |
|---|---|---|
| Threshold and value decision | Maximum account value method, whether a single-account maximum or aggregate maximum exceeded $10,000, exchange-rate source when Treasury rates were unavailable, and U.S.-dollar amounts rounded up to the next whole dollar | Keep these in one review bundle with submitted values and the final filing outcome |
| Amendment path | Amended filing record, the Amend step, and the Prior Report BSA Identifier checkpoint or the instructed placeholder when that identifier is unknown | Use when errors are found in a previously filed FBAR |
| Filing timeline | FinCEN Form 114 and its filing checkpoints | Baseline timing is April 15th with an automatic extension to October 15th; verify current FinCEN notices for event-based extensions |
| Scope boundary | KYC, KYB, AML, W-8, W-9, and 1099 are out of scope here; confirm requirements with the relevant authority. | Masking, tokenization, retry/dead-letter design, and retention standards are internal policy decisions rather than FBAR-mandated controls |
1. Lock the artifact set for each critical flow#
For each critical filing flow, keep one review bundle with the FBAR inputs and outcomes: your maximum account value method, whether filing was triggered because a single-account maximum or aggregate maximum exceeded $10,000, exchange-rate source when Treasury rates were unavailable, and U.S.-dollar amounts rounded up to the next whole dollar.
A reviewer should be able to open that bundle and follow one path without hunting across systems: the threshold decision, the value calculations, the submitted values, and the final filing outcome. If corrections were needed, include the amended filing record in the same bundle.
2. Map onboarding and tax evidence to filing checkpoints#
Keep onboarding and tax evidence in separate review tracks, and treat non-FBAR workflows (KYC, KYB, AML, W-8, W-9, 1099) as out of scope; confirm each requirement with the relevant authority.
For FBAR, anchor the pack to FinCEN Form 114 and preserve the filing checkpoints: maximum account value method, exchange-rate source when Treasury rates are unavailable, and U.S.-dollar amounts rounded up to the next whole dollar. If errors are found in a previously filed FBAR, document the amendment path, including the Amend step and the Prior Report BSA Identifier checkpoint, or the instructed placeholder when that identifier is unknown. Baseline timing is April 15th with an automatic extension to October 15th, and teams should still verify current FinCEN notices for event-based extensions.
3. Show that sensitive data stays contained and traceable#
Your pack should make scope explicit: what is a filing requirement and what is an internal control choice. The provided FBAR materials support filing thresholds, value reporting rules, and amendment checkpoints, but they do not prescribe specific masking, tokenization, retry/dead-letter design, or retention standards.
This is also where implementation choices become reviewable. If you include payload design or support-export handling, label those as internal policy decisions rather than FBAR-mandated controls.
4. Tie messaging decisions back to the system of record#
For each architecture decision, document what your system treats as authoritative and what is derived, but present those as internal design choices. The provided FBAR sources do not mandate a specific message broker, idempotency-key format, ACID boundary, or eventual-consistency model.
When this is written clearly, reviewers can separate filing compliance checkpoints from platform implementation details. If you want a deeper template for internal write-path documentation, use Database Architecture for Payment Platforms: ACID Compliance Sharding and Read Replicas.
Conclusion#
Choose the broker your team can defend during incidents, not the one with the best benchmark story. A reliable decision path is workload shape first, replay control second, and operational complexity third.
- Match the broker to the message pattern first
For point-to-point work queues where one consumer should process each message, RabbitMQ and Amazon SQS are usually the cleaner fit. For ordered, immutable, replayable event history, Apache Kafka is usually the stronger fit.
- Validate control behavior before scaling volume
Prove the behavior you depend on in failure drills. For Kafka, confirm you can replay from an older offset, for example offset 2, and verify downstream behavior. For SQS, confirm whether you need Standard or FIFO semantics, and account for SNS if you need fan-out.
- Use hybrid boundaries deliberately when needed
A split design is often cleaner than forcing one tool to do everything: routing-heavy commands in RabbitMQ or queue workflows in SQS, and replay-critical event history in Kafka. This keeps command handling and replay responsibilities explicit.
- Prefer evidence over opinion
Broker choice affects failure handling and monthly cost, not just service-to-service communication. If the team cannot quickly explain retry vs replay behavior for a critical flow, the architecture is not ready to scale.
For implementation depth, continue with ERP Integration Architecture for Payment Platforms: Webhooks APIs and Event-Driven Sync Patterns, Revenue Share Architecture: How MoR Platforms Split Payments Between Platform and Contractor, and Database Architecture for Payment Platforms: ACID Compliance Sharding and Read Replicas.
For a deeper integration view, see ERP Integration for Payment Platforms: How to Connect NetSuite, SAP, and Microsoft Dynamics 365 to Your Payout System.
When your team is deciding between queue-only and hybrid replay designs for payout operations, review the operational controls in Gruv Payouts.
Frequently Asked Questions
Kafka vs RabbitMQ vs SQS for payment platforms which should we choose first?
Choose based on your dominant message pattern, not vendor preference. For point-to-point work queues, RabbitMQ and SQS are usually the cleaner fit, while replayable event history points to Kafka’s log-based model. If you choose the wrong fit early, you can end up with an architecture that fights you.
Can Apache Kafka replace RabbitMQ in payout operations?
Sometimes, but not cleanly for every payout flow. Kafka is strongest for durable event history and replay, while RabbitMQ is typically stronger for request-reply and routing-heavy operational actions. A practical split is to keep command handling in RabbitMQ and publish replay-critical events to Kafka.
When is Amazon SQS enough for payment and onboarding workflows?
SQS is often enough when workflows are mostly straightforward work queues where one consumer processes each message. It becomes less direct when you need fan-out, because that usually adds SNS, or when you need Kafka-style replayable history. Cost outcomes also vary. One anecdotal case reported higher monthly cost after three months, including a $3,000 a month title figure, but that is not a universal rule.
Do payment platforms need replay with Kafka offsets or are retries enough?
Retries can be enough when you only need to complete in-flight work. If you need to reprocess historical events, replayable history matters, and Kafka offsets provide that control. A practical checkpoint is proving a consumer can re-read from an earlier offset, for example offset 2.
Which broker is best for reconciliation events tied to payout batches?
Kafka is usually the stronger fit when reconciliation depends on an ordered, immutable log and replay. Retries alone do not provide the same history model for after-the-fact investigations. If operational routing is also required, a split approach is RabbitMQ or SQS for commands and Kafka for reconciliation events.
Should one payment platform run multiple messaging systems at the same time?
Yes, when each broker has a clear boundary tied to a real messaging need. A mixed design can be practical when one system handles work queues or routing and another handles replayable event history. The key is to avoid overlap without ownership by documenting the authoritative path and replay or retry validation expectations.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
Includes 5 external sources outside the trusted-domain allowlist.
- bsaefiling.fincen.gov/docs/XMLUserGuide_FinCENFBAR.pdftrusted
- fincen.gov/reporting-maximum-account-valuetrusted
- fincen.gov/report-foreign-bank-and-financial-accountstrusted
- arxiv.org/pdf/2510.04404external
- aws.amazon.com/compare/the-difference-between-rabbitmq-and-...external
- backendbytes.com/articles/message-queue-comparisonexternal
- cloudurable.com/blog/kafka-vs-jms-2025external
- danubedata.ro/blog/rabbitmq-vs-kafka-vs-sqs-comparison-2026external
Educational content only. Not legal, tax, or financial advice.
Related Posts

The Freelance Payment Penalty: A Modeled Audit of Platform Fees, FX Spreads, and Payout Delays
The money rarely disappears through a single, easy-to-spot fee. The real loss is stacked. A marketplace takes its commission, a processor adds a charge for international cards, a bank or payment company converts the currency at a spread, a platform holds the funds before release, and a wire sheds a little to intermediaries on the way in. Each layer looks defensible on its own, but the worker feels the combined result as a smaller deposit and a later payday.

How to Respond to a Subpoena for Business Records
Move fast, but do not produce records on instinct. If you need to **respond to a subpoena for business records**, your immediate job is to control deadlines, preserve records, and make any later production defensible.

A US Expat's Guide to Investing in UCITS ETFs to Avoid PFIC Issues
The real problem is a two-system conflict. U.S. tax treatment can punish the wrong fund choice, while local product-access constraints can block the funds you want to buy in the first place. For **us expat ucits etfs**, the practical question is not "Which product is best?" It is "What can I access, report, and keep doing every year without guessing?" Use this four-part filter before any trade: