
Quick Answer
Reduce KYC drop-off by measuring each verification step, delaying high-friction checks until they are needed, and giving applicants a clear fallback when automated review fails. The goal is not to remove controls, but to align document requests, watchlist screening, and manual review with real risk and a faster path to first payout.
KYC Signup Loss Is a Funnel Design Problem#
KYC signup loss is often driven by funnel design choices, not just by the fact that identity checks exist. The funnel is the path from signup to verification and approval, and users can leave at any stage. Abandonment can rise when the flow adds too many steps, unclear instructions, or technical friction such as unsupported upload formats.
A single completion rate does not tell you enough. If 1,000 users start verification and 700 finish, drop-off is 30%, but that only becomes useful when you know where the other 300 exited. Read drop-off as a journey signal, not a single event.
The right design depends on what your platform needs to control, and when. Teams need to balance required compliance checks with the onboarding efficiency users expect. This article compares common funnel patterns for contractor, seller, and creator platforms so you can decide whether earlier control or lower early friction matters more for your risk posture.
Most KYC execution includes document upload and selfie capture, and each step has its own failure modes. Users can stall on instructions or file format issues. Fragmented tooling can add unnecessary complexity for teams and users. Without stage-by-stage measurement, teams often treat all abandonment as one conversion problem instead of separating policy friction from technical breakage.
Start with one simple rule: do not optimize a blended onboarding metric. Break the funnel into stages, find the exact leak point, and then decide how much identity friction your compliance posture can justify.
If you need outside benchmark context while tuning the funnel, review the SME Finance Forum KYC onboarding brief and GBG's KYC conversion-rate guidance. Use them as benchmark inputs, not as a substitute for your own approval and drop-off data.
Selection criteria and audience fit#
Use this comparison when you need clear ownership from signup to activation, not just polish on the first screens.
- Audience fit
This is for compliance and risk owners, plus adjacent operations stakeholders, reviewing KYC-heavy onboarding flows. It is most useful when your team needs explicit stage ownership from signup through verification and the final activation gate.
- How to score each option
Score each funnel design on control strength, onboarding friction, auditability, operational load, and stage clarity. At minimum, you should be able to trace stage behavior from signup through verification outcome, including where drop-off happens and what blocks activation.
- What this is not for
This is not a copy-tuning checklist for button text or error-message polish. It is for funnel design choices, verification operations, and evidence quality. If your process depends on delayed batch data, treat that as a structural risk. In the cited onboarding example, 12 to 24 hour delays were enough to miss first-session conversion windows.
- Working triage rule
Start with the leak point. If failures cluster early in the flow, fix entry sequencing first. If failures cluster during verification, tighten verification operations first. A simple stage map, for example Invite -> Install -> KYC -> First top up -> First payment -> Invite, helps isolate where friction actually starts.
Related reading: The Best Community Platforms for SaaS Businesses.
The five-stage funnel and control owners#
If ownership is fuzzy, the funnel can break at handoffs. Use one primary owner, one evidence set, and one escalation path for each stage. Control failures can appear when a failed verification outcome has no clearly owned queue. This five-stage model is an operating choice, not a regulatory standard.
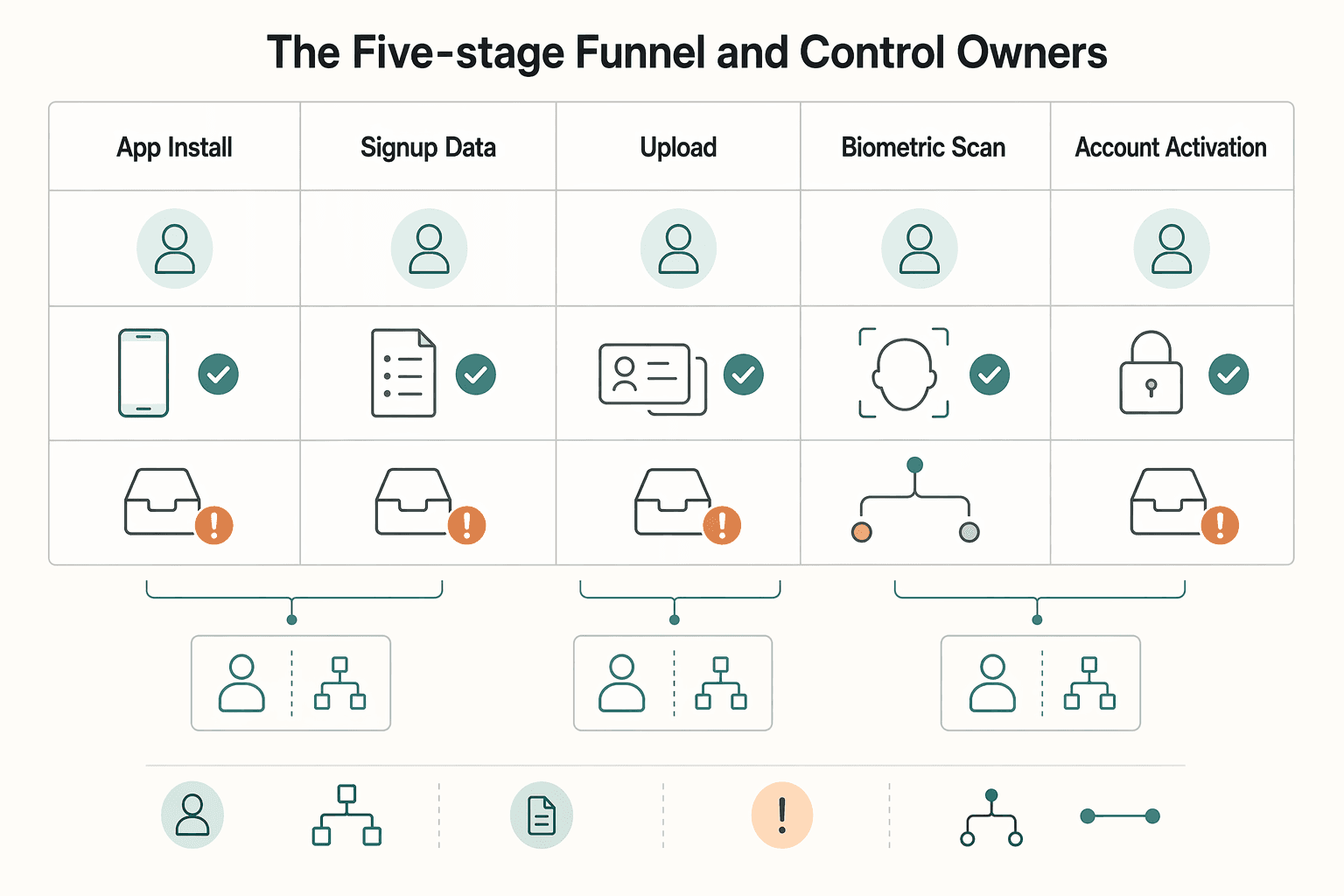
| Stage | Control objective | Required evidence | Allowed retries | Escalation owner |
|---|---|---|---|---|
| App install | Keep users on a valid entry path into verification | entry-path event record, timestamp | Team-defined; separate technical re-attempts from identity checks | Product (or equivalent) |
| Signup data capture | Capture the data needed to open a verification case | submitted signup data, timestamp | Team-defined; allow correction of clear input errors | Product (or equivalent) |
| ID upload | Collect document evidence to support visual identity, name, and address, then run source checks | uploaded document data, extracted fields, check results, timestamp | Policy-defined; avoid open-ended retries without review | Payments Ops (or equivalent) |
| Biometric scan and Liveness check | Verify the presenter is real and support identity matching where used | biometric capture result, liveness result, verification response | Policy-defined; separate capture failure from mismatch | Payments Ops (or equivalent) |
| Account activation | Apply a final proceed / further-checks / do-not-proceed decision | final decision status, for example Red/Amber/Green, decision record | Policy-defined; route unresolved cases to review | Compliance (or equivalent) |
One workable split is Product for App install and signup data capture, Payments Ops for ID upload and biometric or liveness checks, and Compliance for Account activation. That can work well, but only if you document the handoffs so no failed case sits unassigned.
Use one handoff rule, not a shared inbox#
Do not send every failure into the same queue. Define who acts next by failure type. Entry-path issues, submission-quality issues, and policy disposition should not land together. If you use Red/Amber/Green, keep the action rule explicit: Green indicates a match and can proceed per policy, Amber requires further checks, Red does not proceed.
Some verification outcomes return within seconds, but quick machine output does not remove the need for a named owner on Amber and other non-clear outcomes.
Track outcomes by cause, not just by drop-off#
A single "did not complete" number is too blunt to manage. Track stage outcomes by cause, such as technical failure, user abandonment, policy block, or manual-review pending, based on how your workflow is designed.
If repeated failures cluster at ID upload or liveness, review evidence quality and retry policy before widening traffic. Small frictions and slow onboarding can push abandonment up fast, so cause-level tracking is what keeps your fixes targeted.
Option 1 front-door identity capture#
Use front-door identity capture when you need identity evidence before meaningful product action. That means putting ID upload, identity verification, and often liveness checks before activation or other high-value steps.
Best for: onboarding flows where identity must be verified, documented, and defensible from the start.
Key pros: earlier control over risky or unclear cases, plus verification artifacts from first touch. This model is strongest when you need a certified, auditable record of identity verification and transaction evidence, and explicit handling of non-clear outcomes.
Operational minimum: keep one verification case record that reconciles identity-check inputs, outcomes, and final decision status. Route unresolved edge cases to human-in-the-loop review when automated checks are not sufficient.
Key cons: higher first-contact abandonment risk, since identity steps are a common break point. Track technical failure, abandonment, policy block, and manual-review pending separately so fixes target the real bottleneck.
Concrete use-case: regulated or high-value onboarding where your standard requires identity to be verified, documented, and defensible before access. If support coverage for manual review is weak, tighten that path before enforcing this model.
Option 2 registration first and KYC before sensitive actions#
This can be a practical default when you need early signup momentum but can still hard-block payouts, withdrawals, and other sensitive actions until verification clears. Users can reach a low-risk product state first, and KYC is enforced at the action boundary.
- Best for: products where pre-KYC activity is genuinely low risk and does not allow money movement.
- Key pros: lower friction at signup and potentially better completion when users hit KYC at a clear trigger point.
- Key cons: unverified accounts can accumulate, so control design must be tighter.
- Concrete use-case: some creator or seller flows may allow users to browse or prepare listings first, then complete KYC before financial actions.
- Non-negotiable: if policy gates are not technically hard-enforced, do not use this model.
Why it can convert better#
This model can perform better when the reason for KYC is clearer at the moment users request a sensitive action. Drop-off between signup and first deposit is not only marketing-related. It can also include unclear bonus conditions, payment method friction, and KYC complexity.
The same timing risk applies here. Delayed, batch-style prompts can miss high intent. In-session prompts at the exact gated action are more likely to hit that window than triggers that land 12 to 24 hours later or after overnight updates.
What must be true operationally#
The model is only defensible if the gate is explicit, shared, and auditable.
- Keep an exact list of blocked actions.
- Use one authoritative verification status across product and payments decisions.
- Maintain one case record linking submitted signup data, ID upload, verification results, and final decision status.
At the gate, track outcomes separately: technical failure, abandonment, policy block, and manual-review pending. If all failures are merged into one bucket, remediation will target the wrong issue.
Main risk and red flags#
The main risk is inflated top-funnel optics caused by unverified-account buildup. Monitor the path from signup to first sensitive action and completion of verification, not account growth alone. Treat rising document-capture failures, rising policy blocks, and any support or API bypass path as separate red flags.
If you cannot enforce the block at both the product layer and the money-movement layer, move the KYC gate earlier. Related: Continuous KYC Monitoring: Why One-Time Verification is No Longer Enough.
Option 3 payout-triggered KYC gate#
Use this gate when payout is treated as the first meaningful risk boundary. If users can create meaningful risk earlier, waiting until payout may be too late.
This design pushes verification later instead of at signup. That can support a data-minimization approach, but delayed collection does not mean lower risk.
When it fits#
This model works best when payout eligibility is a hard, explicit control point, not a vague "verify later" step. If users remain active before payout, payout itself still needs to stay blocked until verification clears.
Keep one authoritative verification status across product and payments. If those systems disagree on whether an account is payout-ready, control quality can erode quickly.
A useful way to test this option is at the account level. If earlier account activity already creates fraud, impersonation, or operational strain, payout-only gating is under-controlled from the start.
What to instrument before you choose it#
Treat "request payout" to "funds released" as its own funnel, and split outcomes at minimum into technical failure, abandonment, policy block, and manual-review pending.
If 1,000 users start payout-stage verification and 700 complete it, the KYC drop-off rate is 30%. In this model, that checkpoint gives a direct view of where verification is stalling.
Keep one case record tying together:
- payout request timestamp and requested amount
- KYC start event and current verification status
- ID upload and document-verification result
- manual-review notes, final decision, and payout release or hold status
Where this model breaks#
Even small frictions can drive abandonment. Long forms, unclear instructions, and ambiguous requirements are common failure points.
Another failure mode is status mismatch across teams and systems. If user-facing payout status, support status, and compliance status are not synchronized, operational strain can rise and root-cause analysis gets harder.
If payout-stage failures or pending queues keep rising, reassess the gate design and consider moving some checks earlier.
Option 4 risk-tiered progressive KYC#
Use this model when your platform has genuinely different risk cohorts and you need to balance conversion with control. Keep early onboarding lighter, then step up to stronger identity checks when account-level risk signals rise.
This can work when payout-only gating is too late, but full upfront verification would add unnecessary friction for lower-risk users. The tradeoff is governance. Step-up rules, evidence, and blocking actions must stay consistent across Product, Payments Ops, and Compliance.
When it fits#
A single KYC level can be inefficient for mixed cohorts. That includes lower-risk creators and higher-risk business sellers, or multi-market accounts where risk changes by jurisdiction or feature use.
The structure can mirror the split between account creation and identity verification, then escalate only when signals increase. Design decisions should stay account-led, not purely transaction-led. On high-volume digital platforms, fake accounts, impersonation, and abuse can appear before payout.
How the tiers should look#
Keep tiers simple and enforceable. Most teams do better with a small number of clear levels and explicit controls.
| Risk tier | Trigger event | Required checks | Blocking actions | Manual-review SLA | Legal escalation threshold |
|---|---|---|---|---|---|
| Baseline | Account creation for a lower-risk cohort | Basic account data capture and risk flag logging | Block higher-risk actions until next-tier checks clear | Follow internal policy when automated checks fail | Use documented internal escalation criteria |
| Step-up | Higher-risk feature use, first meaningful payout request, repeated mismatch signals, or jurisdiction/feature change | Identity verification and additional policy-required screening | Block payout or sensitive feature access until verification clears | Route failed or ambiguous cases into a documented review queue | Escalate unresolved identity or screening concerns per policy |
| Enhanced | Adverse screening result, stronger impersonation indicators, or reviewer concern | Enhanced identity review and full case documentation under internal policy | Freeze onboarding progress or payout release pending disposition | Priority handling under the documented escalation path | Apply policy-defined legal/compliance escalation criteria |
The labels matter less than consistency. Every trigger should map to a known check, block, and owner, and your team should be able to explain why two similar accounts were treated differently.
Where teams usually get this wrong#
The failure is usually weak rule design, not just friction. One system flags account risk, another shows identity as passed, and support sees only partial status. That creates inconsistent treatment and audit gaps.
Track abandonment by tier, not only at the top of the funnel. A progressive flow can look healthy in aggregate while one step-up path underperforms badly.
A practical control check is weekly reconciliation of three fields: assigned tier, checks actually run, and permissions actually enforced.
What evidence you need on each case#
Keep one case record showing why the tier changed and what happened next. At minimum: trigger event, current tier, identity-verification result, document-verification outcome, screening results, manual-review notes, and final unblock or deny decision with approver identity.
That record matters during disputes, investigations, or legal scrutiny, where card checks alone are not enough. For higher-risk accounts, you may also need a deeper review path beyond standard identity checks. That is where Source of Funds Checks for High-Risk Payout Accounts: When Platforms Need More Than KYC becomes relevant.
Decision rule#
Choose this option when cohorts truly differ and your teams can enforce tier changes consistently. Skip it when your user base is mostly homogeneous, policy logic is still unstable, or systems cannot maintain one authoritative status across onboarding, screening, and payout controls.
For a step-by-step walkthrough, see The Best Platforms for Selling Digital Products.
Option 5 full KYC before account activation#
Choose this model when your policy is clear: no account becomes active until KYC verification is complete. It is most useful when you cannot support any temporary active state for an unverified user and compliance certainty outweighs signup volume.
Where it fits#
Use this when you need one strict sequence and one clear status standard across teams: signup, KYC, then account activation. This aligns with a checkpoint flow where KYC happens before first top-up and first payment.
The main benefit is control clarity, not faster conversion. Product, Ops, and Compliance all work from the same activation rule, so handoffs and decisions stay consistent.
What usually breaks#
The tradeoff is friction at the top of the funnel. KYC flows already face drop-offs, and extensive documentation requirements can increase abandonment, so this should be a deliberate policy choice, not a default.
Track the funnel in clear checkpoints such as signup completed, KYC started, verification passed, and account activated. Signup alone is not the success metric. Verified progression is.
Do not try to reduce friction by removing required disclosures or rewriting fee claims without compliance approval. Improve instrumentation instead. Keep one activation record with timestamped verification status and final activation decision.
Comparison snapshot of the five options#
If your risk profile is fairly consistent and your team is still building reliable policy gates, Option 2 can be a practical starting point compared with Option 4. Consider moving to Option 4 when risk clearly differs by segment or market, and your team can apply tier rules consistently from start to finish.
| Option | Conversion friction | Control confidence | Operational burden | Escalation risk pattern |
|---|---|---|---|---|
| Option 1 front-door identity capture | Friction appears early because identity checks start at first contact | Strong early control signal | Added onboarding load, especially when checks fail and retries are needed | Early escalation risk from failed capture and policy blocks |
| Option 2 registration first, KYC before sensitive actions | Lower signup friction, then higher friction at gated actions | Strong when sensitive actions are reliably blocked until KYC clears | You must operate both unverified and verified states | Escalation risk can cluster when users hit gates unexpectedly |
| Option 3 payout-triggered KYC gate | Low early friction, high friction at payout time | Control is deferred until later in the journey | Review queues can spike at payout moments | Escalation risk can concentrate around first-payout urgency |
| Option 4 risk-tiered progressive KYC | Friction varies by tier: lower-risk users see less, higher-risk users see more | High when tier logic is clear and applied consistently | Higher complexity across rules, evidence, and reviews | More edge-case escalation risk when tier logic is unclear |
| Option 5 full KYC before account activation | Highest early friction because activation waits for full verification flow | Clearest activation control standard | Front-loaded onboarding operations and exception handling | Escalation risk centers on failed verification outcomes |
Keep match rate and conversion rate separate in this comparison. A user can match trusted data sources and still fail to convert if later steps add too much friction.
Option 2 tends to fit when customer acceptance policies are explicit and your controls can reliably block sensitive actions until KYC completion. Option 4 tends to fit when risk diversity is persistent and your team has the maturity to run tiered logic without manual stitching across sanctions, biometric, and document checks.
No independent cross-vendor benchmark defines a universal conversion baseline for all platforms. Use a structured proof of concept with real customer data. Then compare drop-off by stage and reason before locking a model for a three-to-five-year operating horizon.
Before you commit, verify two operational checks. First, your event trail should reconcile stage outcomes from signup through activation. Second, your timing should not introduce 12 to 24 hour delays that miss high-intent verification windows.
Weekly reporting checklist for compliance and risk owners#
Your weekly pack should answer two questions quickly: where users exit the funnel, and whether core controls actually ran. If you cannot separate technical breakage, policy blocks, and review delay, you may fix the wrong issue and weaken your audit trail.
Stage conversion and failure reasons#
Start with stage-by-stage conversion, because users can drop out at each step. At minimum, report how many users entered and completed each step, for example across signup data capture, ID upload, document verification, review, and account activation.
Use one consistent drop-off method. If 1,000 users start verification and 700 complete it, drop-off is 30%. Then, where possible, split losses into technical failure, user abandonment, and policy block so conversion decline becomes practical. Long forms, confusing instructions, and unclear requirements should be tracked as friction drivers, not mislabeled as pure policy failure.
Keep retry outcomes in the same weekly view. Show second-attempt recovery, repeat-failure patterns, and whether retries fail for technical or policy reasons. Key differentiator: separate failure type before debating policy changes.
Manual review aging and queue pressure#
Manual review should be reported as a control state, not a black box. Each week, show cases entered review, cleared, rejected, and still pending, with aging tied to first submission time and current status.
Manual AML handling increases error, delay, and penalty risk, so queue aging is a control signal, not just an ops metric. The 14-day wait example is best treated as a warning pattern, not a universal benchmark.
For each aging bucket, include case count, oldest case age, primary blocker, and owner. If delays are driven by missing customer evidence, say that. If no reviewer picks up cases, treat it as a capacity issue. Key differentiator: review aging shows whether controls are being executed or deferred.
AML evidence, sanctions hits, and override logs#
Conversion metrics are not enough. The report also needs to show control execution. Include evidence that AML screening completed, sanctions and PEP checks were run, and any overrides were approved and logged.
A practical weekly set can include screenings run, hits found, true matches versus cleared alerts, and each override with approver, timestamp, and disposition note. Keep retrievable artifacts such as AML reports comparing customer or representative data against sanctions lists, plus archived activity history for later audit reconstruction.
Watch override creep closely. Rising overrides with incomplete approver logs can signal an evidence gap and should be fixed before policy is loosened. Key differentiator: prove what ran, not just what policy intended.
Data governance and event reconciliation#
Add a weekly governance view that flags where sensitive data appears and where controls may be missing. Track exposure points across analytics events, review tools, exports, support tickets, and internal notes, and log policy exceptions clearly.
Then reconcile product funnel events against compliance case records so both systems describe the same journey. Signup data, ID upload, screening status, review status, and account activation should align for the same user or case reference where available.
Use a repeatable spot-check process each week, document root causes for mismatches, and assign owners. Repeated mismatches can indicate reporting defects and should be addressed before approving policy changes. Key differentiator: reconciliation keeps performance reporting and control evidence aligned.
If your chosen model relies on hard payout gating, validate your trigger and status design against Payouts.
Escalation matrix and stop-automation rules#
Use escalation rules to separate true compliance risk from technical breakage. Stop automation when the case affects sanctions exposure, payout release, or core identity confidence. Reproducible product defects should go to Product or Ops for remediation.
Use three internal severity bands#
Treat these as internal control bands, not universal legal tiers.
- Severity 1 (highest control risk): sanctions-related flags, and similar cases where payout actions should stay blocked pending review.
- Severity 2 (identity confidence risk): non-technical identity or document verification failures that require manual judgment.
- Severity 3 (technical failure): clear system or flow defects that block the user but do not, by themselves, establish policy risk.
If high-risk screening flags appear, send the case to Compliance and keep payout actions blocked until a disposition is recorded in your case log.
| Trigger | Owner | Required evidence | Decision checkpoint | Customer communication rule | Unblock condition |
|---|---|---|---|---|---|
| Sanctions-related flag | Compliance | Screening result, matched fields, case ID, analyst note, timestamp | Before payout release or other funds-flow action | State the account is under review; do not commit to a payout date | Authorized disposition recorded; payout block removed |
| Identity confidence conflict with screening context | Compliance and Risk | Attempt history, conflicting identity data, document images, screening context | Before payout release or other funds-flow action | Request targeted missing evidence only | Risk decision logged; required KYC steps completed |
| Non-technical document verification failure | Identity Ops or Compliance | Failed verification result, submitted document images, matching inputs, review note | Within your manual-review process | Explain exactly what is missing or mismatched | Reviewer clears case or requests one specific resubmission path |
| Repeated identity verification mismatch | Identity Ops, with Compliance escalation when risk signals stack | Verification results, prior attempts, document verification status, reviewer note | Within your manual-review process | Tell the user whether to retry now or wait for review | Reviewer records approval, rejection, or alternate path |
| Reproducible technical verification failure | Product or Ops | Error logs, session or case reference, device or app context, screenshot if available | Within remediation process | Acknowledge technical issue and preserve user progress | Fix or workaround confirmed; no compliance hold remains |
Evidence quality is the release control#
Do not unblock on vague notes. Each case file should show why automation stopped, who reviewed it, what evidence was used, and when status changed. For business onboarding, that evidence can include Chamber of Commerce extract, director passports, UBO data, and sanctions screening inputs.
Keep payout release tied to completed KYC pillars in your own policy record. The grounded sequence is to identify and verify the customer, understand ownership, purpose, and risk, and monitor the relationship. In the cited example, funds flow only after those core pillars are satisfied. Keep customer messaging precise to avoid repeated document requests and unclear status, which can increase abandonment and create inconsistent case evidence.
Failure modes competitors underplay#
Once stop-automation rules are set, the next risk is diagnosis. Diagnosis should test whether teams are optimizing the wrong bottleneck and whether decisions are explainable from start to finish.
Policy signals treated as pure UX#
Do not assume every drop-off problem is a copy or flow problem. Test whether apparent abandonment could be a policy-state issue before rewriting UX. Operational misalignment can degrade user experience and increase compliance risk at the same time, so completion decline should be checked against case outcomes, not product events alone. Reconcile funnel events with case records, and if AI-assisted checks produce unverifiable outputs, require human review before any unblock decision.
Activation defined before control completion#
The grounding does not provide direct evidence that early activation counting hides KYC weakness. Treat this as a diagnostic hypothesis: if activation is counted before control and review states are complete, the metric may overstate real readiness. Keep milestones separate so reporting shows where progress stops instead of collapsing different states into one "active" label.
Excess logging without decision value#
Collect evidence that explains decisions, not every possible payload. The grounding does not provide a specific legal threshold here. Use an operational rule instead: retain what is needed to explain a state change, reproduce a failure, and support reviewer decisions. If logs expand without improving explainability, diagnostics do not improve.
Fragmented tools with no single explainer#
Fragmented tooling can weaken explainability unless systems stay synchronized. Cross-system consistency supports reporting, accounting, and fraud detection, so each case should have a canonical record with shared identifiers and clear ownership. In backend flows, unified ledgers and transaction validation protocols are a practical checkpoint to prevent conflicting statuses across tools.
Conclusion#
The right choice is not the lightest flow or the strictest gate on its own. It is the model that matches your risk posture and shows exactly where users fail.
- Choose one model deliberately, then enforce it.
A staged approach can reduce friction, but required verification steps still need to stay in place before Account Activation. If your program cannot tolerate any active state before verification, run full KYC before activation and accept higher friction. Do not mix models informally, or you create exceptions you cannot explain.
Use evidence from the five stages: App Install, Registration, ID Upload, Biometric Scan, and Account Activation. If leakage is concentrated in one handoff, fix that handoff first. A cited case showed a 45% drop-off between ID Upload and Biometric Scan.
- Assign named owners by stage and run the same weekly review every time.
Set one accountable owner per stage and keep a shared review pack for Product and Compliance. Review stage conversion and failure-type split, then confirm your instrumentation reflects what users actually experienced. If your stage data is incomplete, your diagnosis will be wrong.
Track one concrete execution signal early, such as "Retake Photo" press rate, to separate user error, capture quality issues, and device failures. Keep sensitive fields masked at the SDK layer, for example passport numbers or OCR results, so optimization does not increase privacy risk.
- Define market and program differences before rollout.
If gates vary by market or program, document those gates and review paths before launch. The same UI can still hide different approval paths and block points.
Tag technical failures correctly. Permission failures can produce black-screen camera steps, and browser or WebView incompatibility can break capture flows. Both can look like policy friction if you do not classify them. And if 60% of users drop before completion, compliance correctness alone will not protect onboarding performance.
Choose the model, assign ownership across all five stages, publish the weekly checklist, and set escalation rules before scale. If you cannot explain why users stop at ID Upload, Biometric Scan, or Account Activation, the funnel is not ready for broader rollout.
Before rollout across markets, align ownership and coverage assumptions with Gruv’s team via Contact.
Frequently Asked Questions
What is a KYC funnel for platforms?
A KYC funnel for platforms is the step-by-step path from signup to verified status, not a single pass or fail event. A common sequence is App Install, signup data capture, ID Upload, Biometric Scan, and Account Activation. Treat each stage as its own control gate, because users can complete early onboarding steps and still fail verification later.
Where do platforms usually lose users in KYC?
There is no universal loss point, so stage-level analysis matters more than aggregate bounce rates. In one cited deployment, drop-off was 45% between ID Upload and Biometric Scan, which points to execution issues in that transition. Long or complex flows can also raise abandonment, and weak networks can disrupt video verification when audio quality drops.
How do we separate UX friction from compliance friction?
A practical split is technical failure, user abandonment, or policy block, then assigning an owner to each class. Use custom UI event tagging at the exact step where users fail so you can distinguish broken flow paths from user exits. Keep analytics privacy-safe by masking sensitive identity fields at the SDK level.
Which metrics should compliance and risk review weekly?
Review stage conversion by step and overall KYC drop-off rate every week. Pair that with step-level event data so teams can separate technical failures from user exits and policy outcomes. If conversion falls at a specific transition, investigate technical or flow design issues first.
When should automated KYC escalate to manual review?
The grounding here does not define universal escalation thresholds. A practical default is to escalate when automated checks cannot clear identity at a specific step or when check outcomes conflict, then pass along stage-level failure signals for manual review.
Should every platform run full KYC at signup?
Not necessarily. One cited operator playbook uses staged verification: softer checks before first deposit and heavier checks before withdrawal. The tradeoff is conversion versus control, and delayed verification only works if sensitive actions stay blocked until checks clear.
Asha writes about tax residency, double-taxation basics, and compliance checklists for globally mobile freelancers, with a focus on decision trees and risk mitigation.
With a Ph.D. in Economics and over 15 years of experience in cross-border tax advisory, Alistair specializes in demystifying cross-border tax law for independent professionals. He focuses on risk mitigation and long-term financial planning.
Sources
Includes 4 external sources outside the trusted-domain allowlist.
- sec.gov/Archives/edgar/data/1782170/0001782170230000...trusted
- sec.gov/Archives/edgar/data/1889123/0001193125261108...trusted
- stripe.com/ae/resources/more/crypto-onboarding-best-pra...trusted
- tiffin.edu/wp-content/uploads/AI-Tools-with-Description...trusted
- countly.com/blog/optimizing-kyc-onboarding-reducing-fric...external
- dialnexa.com/blogs/types-of-funnelsexternal
- didit.me/blog/kyc-drop-off-analysis-optimizationexternal
- engage.so/blog/optimizing-kyc-and-user-onboarding-proc...external
Educational content only. Not legal, tax, or financial advice.
Related Posts

The Freelance Payment Penalty: A Modeled Audit of Platform Fees, FX Spreads, and Payout Delays
The money rarely disappears through a single, easy-to-spot fee. The real loss is stacked. A marketplace takes its commission, a processor adds a charge for international cards, a bank or payment company converts the currency at a spread, a platform holds the funds before release, and a wire sheds a little to intermediaries on the way in. Each layer looks defensible on its own, but the worker feels the combined result as a smaller deposit and a later payday.

How to Respond to a Subpoena for Business Records
Move fast, but do not produce records on instinct. If you need to **respond to a subpoena for business records**, your immediate job is to control deadlines, preserve records, and make any later production defensible.

A US Expat's Guide to Investing in UCITS ETFs to Avoid PFIC Issues
The real problem is a two-system conflict. U.S. tax treatment can punish the wrong fund choice, while local product-access constraints can block the funds you want to buy in the first place. For **us expat ucits etfs**, the practical question is not "Which product is best?" It is "What can I access, report, and keep doing every year without guessing?" Use this four-part filter before any trade: