
Quick Answer
Set domain-level objectives first, then select patterns that can prove both downtime and data-loss limits in drills. In payment operations, request intake, event replay, payout execution, and reporting should be treated as different recovery domains with distinct verification signals. Run failover and return as gated phases, and require explicit replay plus reconciliation checks before declaring success. If a domain cannot recover independently, treat that coupling as design debt before tightening targets.
How to Set Recovery Targets for Payment Infrastructure#
Disaster recovery for payment infrastructure is an architecture decision, not just a documentation exercise. Use RTO, RPO, failover planning, and data-protection strategy to decide what you build and how you run it.
RTO is the maximum acceptable time a system can be unavailable after disruption. RPO is the maximum acceptable data-loss window, measured in time. They are related, but independent. You can set an RTO of 30 minutes and an RPO of six hours if that matches the business tolerance.
In practice, the tradeoff is direct. Tighter RTO targets push you toward high-availability design and automated failover. Tighter RPO targets push you toward continuous data protection, more frequent backups, and enough storage capacity to support that cadence.
Before you choose patterns, start with one checkpoint: map application dependencies. If dependencies are unclear, your RTO and RPO targets are hard to validate. An RPO of 15 minutes requires backup capture at least every 15 minutes. An RTO of two hours requires restoration to complete inside that window.
This article does not assume one platform-wide target. Payment systems can use different RTO and RPO pairs by recovery domain, and those choices should be explicit.
The scope is cross-cloud, but it does not assume provider parity by default. One implementation reference is explicitly AWS-scoped, so the guidance stays focused on decisions and verification points you can carry across environments and adapt per provider.
Related reading: How to Version Your Payment API: Strategies for Backward-Compatible Changes.
Define RTO and RPO in payment terms#
Set two targets for each payment function: Recovery Time Objective (RTO) and Recovery Point Objective (RPO). RTO is the maximum acceptable time a service can be unavailable after disruption. RPO is the maximum acceptable data-loss window, measured in time. They are related, but independent, so you should set them based on actual risk, not by habit.
In payment operations, missing RTO means extended downtime in critical workflows. Missing RPO is a different failure: service can return while some recent payment data is permanently lost, with potential financial and regulatory consequences.
Do not use one platform-wide target. Recovery objectives should vary by application and business criticality, so set separate RTO and RPO decisions for each critical payment function.
Validate each target before it goes into your Disaster Recovery (DR) or Business Continuity Plan. If RPO = 15 minutes, your backup cadence must meet that interval. If RTO = 30 minutes, your recovery approach should restore service inside that window in real runs, not just on paper.
For adjacent architecture work, see Building a Multi-Tenant Payment Platform with Defensible Data Isolation.
Break the platform into recovery domains before choosing architecture#
Define recovery domains before you pick backup or replication patterns. Otherwise, your RTO/RPO targets can look clean on paper and still break on hidden dependencies during an incident.
Start with the usual DR sequence: business impact analysis, then dependency mapping. For each domain, ask one practical question: can it fail, recover, and be verified without forcing the rest of the platform to recover first?
A practical split is:
| Domain (example) | First dependency question | Recovery proof signal |
|---|---|---|
| Request intake | Can intake recover without waiting on non-intake services? | A controlled request is accepted and creates the expected record/event |
| Asynchronous processing | Can delayed events be replayed safely? | Replay completes and duplicate handling behaves as expected |
| Core data updates | Which upstream writes and downstream reads block recovery? | Replayed and new updates align with expected data state |
| Scheduled/batch jobs | Can batch processing resume independently? | Batch state and downstream handoffs align |
| Reporting exports | Is reporting freshness coupled to core processing? | Export timestamps and counts match the restored data window |
Treat this as a working split, not a universal model. The point is to separate domains that have different business impact and different restore paths.
Before you tighten objectives, check for coupling. Shared queues, shared schemas, or provider control-plane limits can prevent independent recovery; if they do, document that dependency and account for it in design and target setting.
Provider scope can also shape domain design. For example, OCI Full Stack DR is scoped to resources in the same tenancy and does not currently support cross-tenancy DR, so isolation and recovery assumptions should stay inside those boundaries.
Once the domains are clear, document per-domain procedures and review them periodically. Keep each one explicit enough to run under stress, with clear restore steps and verification checks.
If you want a deeper dive, read How to Create a Disaster Recovery Plan for a SaaS Business.
Match DR patterns to business impact and tolerance#
Pick a DR pattern that fits the domain's business impact and tier target for RTO and RPO. The practical sequence is simple: classify by criticality first, then map each domain to a strategy that balances recovery capability and cost.
| Tier example from source | Example workload | RTO | RPO | Strategy |
|---|---|---|---|---|
| Tier 1 (Critical) | Payment processing | Under 15 minutes | Near-zero | Warm standby or multi-site |
| Tier 2 (Important) | CRM, ERP, customer portal | 1-4 hours | Under 1 hour | Pilot light |
| Tier 3 (Standard) | Internal tools, reporting | 8-24 hours | Under 24 hours | Backup and restore |
| Tier 4 (Non-critical) | Dev/test, archives | Days | Days | Backup only |
Read these patterns as tradeoffs, then verify them against dependency and business-priority checks.
| Pattern | Typical use after tiering | Strengths | Failure risks | Verification checkpoints |
|---|---|---|---|---|
| Backup and Restore | Domains with higher outage tolerance after tiering | Fits less aggressive RTO/RPO targets | Ad hoc recovery decisions, dependency surprises, longer downtime/data-loss risk | Restore from backup, document dependencies that must recover together, and define recovery sequence by dependency and business priority |
| Pilot Light | Important domains targeting faster recovery than backup-only | Better recovery posture for mid-tier targets | Activation steps can fail under pressure if sequence/dependencies are unclear | Use infrastructure as code for repeatable activation, document dependencies, and define recovery sequence by dependency and business priority |
| Warm Standby | Critical domains with tight recovery targets | Aligned with the Tier 1 example in the source | Recovery can fail if dependencies and sequence are not explicit | Document dependencies that must recover together and define recovery sequence by dependency and business priority |
| Hot Standby | Not explicitly defined in the provided source excerpts | Organization-specific choice when your own targets and runbooks justify it | Unsupported assumptions if selected without validated targets and runbooks | Define and test clear activation and verification criteria before relying on it |
Traffic switching deserves its own attention. The source gives one concrete AWS example: Route 53 health checks with failover routing policies. It does not define a standard fallback model, so document return-to-primary criteria and recovery sequence explicitly, including dependency order and business priority.
Choose replication strategy by data class, not by database brand#
Choose replication by loss posture for each data class, not by database feature checklists. In practice, ledger events, transaction states, payout instructions, and audit artifacts can have different recovery needs, so one replication mode for everything is usually the wrong default.
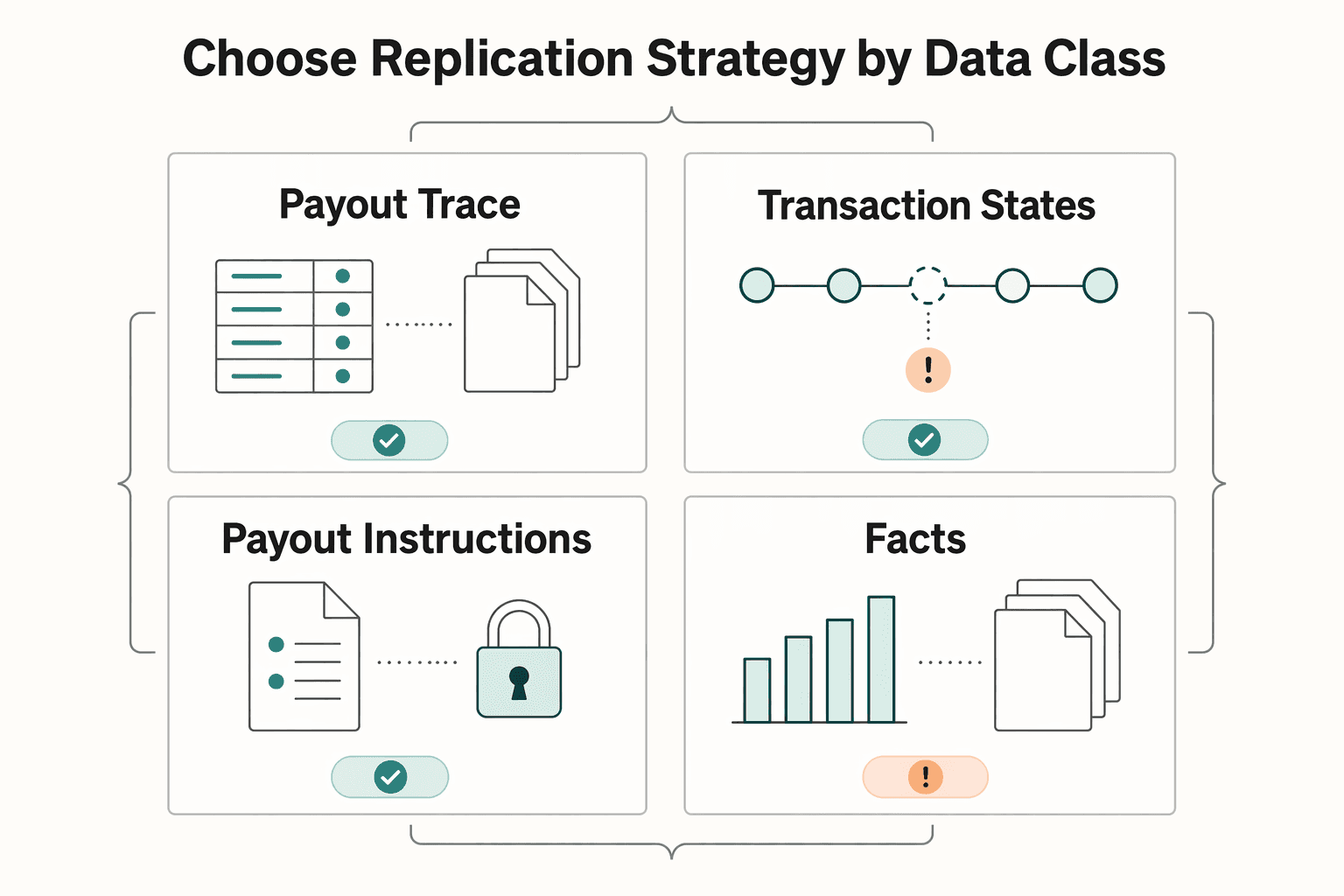
Because RTO and RPO are independent, set both for each class before picking a method. You can recover service quickly and still lose recent data. You can also keep a tighter data window and still miss recovery-time expectations. A good planning checkpoint is to audit each class by data type, transaction volume, and system criticality.
If a class has an RPO of 15 minutes, protection has to capture changes at least every 15 minutes. If a payment system has an RTO of two hours, restore work has to complete inside that window. These are example values, but they show why targets should drive replication design.
| Data class | Replication method to evaluate | Acceptable loss posture | Replay strategy | Operational caveats |
|---|---|---|---|---|
| Ledger events | Synchronous mirroring; remote journaling where a bounded gap is acceptable | Define the maximum tolerable data-loss window explicitly | Reconcile any gap between last protected point and restored state | Missing RPO targets can create permanent data loss with financial and regulatory consequences |
| Transaction states | Remote journaling | Bounded loss window tied to business impact | Reapply journaled changes and reconcile post-recovery state | Journal cadence is interval-based (often hourly in traditional examples), so a recent-change gap may still need reconciliation |
| Payout instructions | Remote journaling or electronic vaulting, based on target strictness | Class-specific loss window must be set explicitly | Recover to the last protected point, then reconcile subsequent changes | Method choice should follow target loss posture, not database brand defaults |
| Audit artifacts | Electronic vaulting | Periodic-copy model with a time gap between backups | Restore from the latest vault and reconcile post-backup changes | Bulk transfer leaves a temporal gap after the last backup |
Before cutover, document your recovery and reconciliation sequence in runbooks and test it. The useful proof is whether you can report the last protected timestamp, restore completion time, and what was reconciled after recovery for each data class.
Engineer failover and fallback paths for idempotent money movement#
Treat the switch away from primary and the return path as two separate recovery phases that you need to exercise end to end, not as a simple traffic toggle. In money movement systems, operational risk can rise around repeated instructions and unclear signals during disruption, so the design and the runbooks both need to make those repeats explainable under pressure.
| Recovery area | What to cover | Why it matters |
|---|---|---|
| Retries and replays | Set a clear rule for how the system classifies a repeated instruction during an incident; re-run in-flight scenarios; include accidental deletion or misconfiguration | Operators can explain what happened and why the system took that path |
| Webhooks | Treat external notifications as signals that must be checked against internal recovery state; document disagreement cases and missing or unclear signals in the main playbook | Keeps the incident process focused on validation and troubleshooting, not assumptions |
| Failback | Use explicit readiness checks for return-to-primary; capture cutover and failback timestamps, what was validated, what exceptions were found, and how they were resolved | Going back without clear validation and operator verification can reintroduce uncertainty at the worst moment |
Make retries behave like replays#
Set a clear rule for how your system classifies a repeated instruction during an incident, then test that rule during drills. The goal is not a perfect theory of retries. It is a recovery path where your operators can explain what happened and why the system took that path.
Do not stop testing at infrastructure cutover. Re-run in-flight scenarios through the recovery path and verify that outcomes, audit records, and operator notes stay consistent. Include human-error scenarios, such as accidental deletion or misconfiguration, because they create the same uncertainty you face in real incidents.
Treat webhooks as lagging evidence, not instant truth#
If external notifications are part of your flow, treat them as signals that must be checked against your internal recovery state. That keeps your incident process focused on validation and troubleshooting, not assumptions.
Document how your team handles disagreement cases and missing or unclear signals during recovery. DR guidance treats troubleshooting common issues as part of execution, so this should sit in the main playbook, not as an afterthought.
Treat failback as a gated return, not a reset#
Return-to-primary should have explicit readiness checks, just like the initial switch. Going back without clear validation and operator verification can reintroduce uncertainty at the worst moment.
Capture evidence for each exercise: cutover and failback timestamps, what was validated, what exceptions were found, and how they were resolved. A common policy pattern is annual review with quarterly testing, but the point is discipline. Test often enough that the process works under pressure, not just in audits.
Keep compliance controls alive during incidents#
Recovery is incomplete if control evidence does not survive the same event. Treat incident behavior for controls and records as part of your design, and validate it with legal and compliance teams for each program.
Define degraded mode before a vendor outage forces it#
If a critical dependency is impaired, predefine incident states and decision ownership so your operators are not improvising under pressure. Document what happened and why, with an auditable trail rather than silent exceptions.
Do not assume a universal bypass, hold, or release rule for screening, onboarding, or payouts during incidents; those decisions are program-specific and should be explicitly approved.
For each affected action, capture:
- affected record ID
- unavailable dependency
- incident window and decision timestamp
- temporary status during the outage
- decision owner
- outcome after recovery
Treat tax artifacts as recoverable records, not side files#
For U.S. tax workflows, verify that records and related metadata are restored together, not just raw files. FEIE claims are tied to filing artifacts (Form 2555 or Form 2555-EZ), and the taxpayer still files a U.S. tax return reporting the income.
| Check area | Requirement or artifact | Detail |
|---|---|---|
| FEIE filing artifact | Form 2555 or Form 2555-EZ | FEIE claims are tied to these filing artifacts |
| Income reporting | U.S. tax return | The taxpayer still files a U.S. tax return reporting the income |
| Physical presence test | At least 330 full days during a 12-consecutive-month period | A full day is a 24-hour period from midnight to midnight |
| Waiver condition | War, civil unrest, or similar adverse conditions | The minimum time requirement may be waived when departure is caused by these conditions |
If your product stores FEIE eligibility inputs, restore validation should also check time-based logic. The physical presence test uses at least 330 full days during a 12-consecutive-month period, where a full day is a 24-hour period from midnight to midnight. Missing that day-count requirement can disqualify the test, although the minimum time requirement may be waived when departure is caused by war, civil unrest, or similar adverse conditions.
Expect timelines to move during real-world disruptions#
Do not hard-code filing assumptions during an incident. FinCEN's FBAR Filing Due Date page has posted event-specific relief notices, including an additional extension tied to Hurricane Milton on 10/11/2024.
Store the notice or case note that justified any deadline decision so the rationale stays auditable after recovery. Control coverage and automation depth can vary by program, so confirm both the legal requirement and the restore expectation explicitly.
Sequence implementation to avoid hard-to-untangle platform debt#
Use a phased sequence so recovery restores service behavior, not just infrastructure. The order matters because it keeps dependencies visible while the design is still easy to change.
| Phase | Main actions | Checks or evidence |
|---|---|---|
| Phase 1 | Set domain-level RTO and RPO, then map dependencies; document the application entry path, state store, event path, external dependency, and who confirms business recovery | Data restoration alone is not enough if users or operators still cannot access the application path they need |
| Phase 2 | Implement replication, idempotency, traffic switching, and recovery verification | Run a restore drill that checks the application endpoint is reachable, restored state aligns with the defined RPO posture, and recovery and replay behavior is controlled to avoid unintended duplicate effects |
| Phase 3 | Harden production operations after the mechanics are proven in drills; assign clear incident ownership and make invocation steps explicit | Keep a Recovery Plan artifact with trigger conditions, approvers, restoration order, rollback conditions, required post-incident evidence, and a defined testing checkpoint |
Phase 1#
Start by setting domain-level Recovery Time Objective (RTO) and Recovery Point Objective (RPO), then map dependencies. RTO is the maximum acceptable downtime, and RPO is the limit on acceptable data loss. Set both by business impact and system criticality, not with one default target.
If your payment stack spans multiple services, define each as its own recovery domain before implementation. For each domain, document the application entry path, state store, event path, external dependency, and who confirms business recovery. Data restoration alone is not enough if users or operators still cannot reach the application path they need.
Phase 2#
Once the domains are defined, implement core controls for replication, idempotency, traffic switching, and recovery verification. This keeps data survival, replay handling, and cutover behavior explicit before you rely on automated switching.
For each domain, run a restore drill that checks:
- the application endpoint is reachable
- restored state aligns with the defined RPO posture
- recovery and replay behavior is controlled to avoid unintended duplicate effects
Phase 3#
Harden production operations only after the mechanics are proven in drills. Assign clear incident ownership across engineering and payments ops, and make invocation steps explicit so time is not lost deciding how to start recovery.
Keep a concrete Recovery Plan artifact with trigger conditions, approvers, restoration order, rollback conditions, and required post-incident evidence. Include a defined testing checkpoint and treat failback as its own risk decision rather than an automatic step.
Consider confirming the current phase with restore-drill evidence and review before you expand to additional domains.
If you are converting this rollout sequence into engineering tickets, use the Gruv docs to align APIs, webhooks, and operational status checks before your next drill.
Test for reality, not paper compliance#
A DR program is only real if it works under failure, not just in documentation. Mark a drill as successful only when you restore within the declared Recovery Time Objective (RTO), keep data loss within the declared Recovery Point Objective (RPO), and confirm business operations can close the affected period without creating new issues.
Declare pass/fail before the drill#
Set success criteria before the exercise starts: recovery domain, incident type, start signal, stop signal, and explicit pass/fail checks.
Keep technical and business outcomes separate:
- RTO: did service return within the target window (for example, 2 hours)?
- RPO: did restored data stay within the allowed loss window (for example, 15 minutes)?
- Business outcome: can teams complete reconciliation and handle customer impact without unresolved exceptions?
Do not collapse this into a single "recovered" label. Recovery speed and data currency are different objectives.
Run drills for the failures that actually happen#
Use targeted drills that reflect real risk:
- Outage drills: verify service restoration within the RTO window.
- Ransomware drills: verify you can restore clean, usable data, not just restore quickly.
If infrastructure appears back but transactions fail, data is corrupted, or operations cannot close the loop, treat the drill as failed.
Use Chaos Testing selectively at critical boundaries#
Apply Chaos Testing where boundary failures are most likely to break recovery. The goal is to expose where recovery fails, not to create broad disruption.
Tight RTO targets usually require high-availability design and automated failover, while stringent RPO targets require continuous protection and frequent backups. Test those outcomes directly.
Measure closure, not just restoration#
A drill is complete only when both technical restore and business closure are validated. Capture evidence that includes:
- Start and end timestamps
- Recovery point used
- Data completeness checks
- Reconciliation outcome
- Support-ticket impact during the drill
In ransomware scenarios, treat "backup exists" as insufficient. Backups can exist and still fail at restore time, so test data cleanliness and usability, not just backup presence.
For a fuller cost view, read Building Payment Infrastructure In-House: Engineering, Compliance, and Maintenance Costs.
Prevent the failure modes that break trust first#
Focus first on the failures users feel immediately: service unavailability and data gaps or loss. Hitting RTO alone is not enough because RTO and RPO are independent and can fail separately.
Use recovery checks that map directly to those risks:
| Failure to prevent | Why it breaks trust | What to verify first |
|---|---|---|
| Missed RTO | Extended downtime and interrupted operations | Service returns inside the declared outage window (for example, 30 minutes or 2 hours). |
| Missed RPO | Data gaps or permanent loss, even after restore | Recovered state stays inside the declared data-loss window (for example, 15 minutes). |
| Misaligned targets by system | Over- or under-protection on critical workflows | RTO/RPO targets are set by business function and criticality, not as one default for every system. |
Treat the tradeoffs explicitly during design and drills. Shorter RTO targets usually require faster recovery mechanisms such as automated failover, while stricter RPO targets require tighter backup and replication cadence. A plan can meet one target and still miss the other, for example 4 hours RTO and 1 hour RPO, so validate both before calling recovery complete.
Build the evidence pack executives and auditors will ask for#
Your recovery story is only credible if you can prove what happened quickly from one repeatable evidence set. Keep it compact, consistent, and tied to the payments annex in your contingency plan rather than spread across tickets, chat, and ad hoc exports.
Put the payments annex in one place#
Keep one short annex that defines scope, owners, dependency assumptions, and the declared recovery objectives for each payment domain. This keeps contingency decisions and disaster recovery aligned: disaster recovery covers IT restoration after a major event, while contingency planning covers broader disruption scenarios.
Use a simple check: you should be able to answer from that annex alone who owns payout recovery, what it depends on, and what counts as success.
Keep drill proof, not just drill notes#
For each drill, preserve durable evidence, not just a pass/fail summary:
- Start and end timestamps
- Restore logs
- Reconciliation outcomes
- Unresolved exceptions
- Corrective actions opened after the exercise
If you align to NIST-style contingency planning, CP-4 emphasizes testing at a defined frequency and documenting results, with annual testing at minimum called out in the summary guidance.
Make traceability and retrieval boring#
Make end-to-end traceability easy to reconstruct from one evidence set, including the identifiers and records your workflow already uses. A practical test is whether you can reconstruct one transaction path end to end without cross-team screenshot hunts.
If examiner or legal requests are realistic for your business, treat these as useful implementation patterns rather than rule text: content-addressed storage for integrity proof, standardized Preservation Bundles for retrieval, and legal-hold controls to reduce accidental deletion risk during active inquiries.
Conclusion#
Disaster recovery only counts if you can restore critical capabilities within declared RTO and RPO targets and prove the recovered state is usable. Set those targets from business requirements, not defaults, because RTO and RPO are independent and tighter values create different architecture and operational burdens.
Treat the tradeoff directly. Tighter RTO pushes you toward higher availability and faster cutover. Tighter RPO pushes you toward more frequent data protection and stricter recovery discipline. Those pressures are not interchangeable. A target like RTO 30 minutes with RPO 6 hours can be valid, and an RPO of 15 minutes is only credible if data capture happens at least every 15 minutes.
Keep decisions at the subsystem level. If one domain can tolerate longer disruption and another cannot, give them different targets and different designs. If a domain cannot recover independently, address that coupling before tightening objectives.
Use two checks as your release gate for DR readiness:
- Validate recovery time and application function in failover testing, not just service boot.
- Do not trust an untested plan. Credibility comes from drills that show restore time and recoverable data age hold up in practice.
A practical next step is a short domain-by-domain decision matrix your engineering and operations teams can review together before the next release.
If you want a domain-by-domain review of your DR targets against Gruv modules and market-specific constraints, contact the Gruv team.
Frequently Asked Questions
What is the difference between RTO and RPO in payment infrastructure?
RTO is the maximum acceptable outage duration after a disruption. RPO is the maximum acceptable data-loss window, measured backward from the disruption to the last acceptable recovery point. You need both, because fast recovery without recent recoverable data can still create serious operational impact.
How do I choose replication and backup strategy when RTO is strict but RPO is moderate?
Start with restore-time requirements, since tighter RTO typically pushes architecture toward high availability and automated failover. Then make sure your data-protection approach can keep recovered data inside the declared loss window. For example, an objective pair like 30 minutes RTO and 6 hours RPO emphasizes getting service back quickly while accepting a larger recoverable data gap.
When should I use backup and restore, pilot light, warm standby, or hot standby?
This grounding does not provide universal thresholds for choosing among those patterns. Use your declared RTO and RPO as the decision anchors: aggressive RTO usually requires more availability automation, while stringent RPO usually requires more continuous data protection and backup frequency. If a pattern cannot reliably meet both objectives, it is not the right fit for your risk tolerance.
How often should we test failover targets?
There is no universal test cadence in the provided sources. Set a cadence that repeatedly proves two outcomes: recovery time meets RTO, and recoverable data age meets RPO. If your RPO is 15 minutes, your protection method must capture data at least every 15 minutes for that target to be credible.
How do we sequence DR work without creating integration debt?
Set RTO and RPO first, then prioritize implementation work based on which objective is hardest to meet. Tighter RTO usually drives high-availability design and automated failover, while tighter RPO usually drives continuous protection and more frequent backups. Use those objectives as independent decision criteria when sequencing recovery work.
What is still unknown from most public DR guides?
From this grounding, payment-specific implementation details and production-validated replication benchmarks remain open questions. Provider constraints can also change what is feasible in practice. For example, OCI Full Stack DR currently requires same-tenancy resources, does not support cross-tenancy DR, and describes on-prem, hybrid, and multicloud DR as roadmap rather than current capability.
Try a related tool
A former product manager at a major fintech company, Samuel has deep expertise in the global payments landscape. He analyzes financial tools and strategies to help freelancers maximize their earnings and minimize fees.
Sources
Includes 2 external sources outside the trusted-domain allowlist.
- fincen.gov/report-foreign-bank-and-financial-accountstrusted
- irs.gov/individuals/international-taxpayers/foreign-...trusted
- irs.gov/individuals/international-taxpayers/figuring...trusted
- michigan.gov/-/media/Project/Websites/dtmb/Procurement/Co...trusted
- sec.gov/files/ctf-written-fcck-pilot-evidence-02-16-...trusted
- wordpress.nccommunitycolleges.edu/wp-content/uploads/2026/03/Ex-Libris-ILS-50-...trusted
- cloudtech.com/resources/aws-rto-rpo-disaster-recoveryexternal
- datacamp.com/blog/rto-vs-rpoexternal
Educational content only. Not legal, tax, or financial advice.
Related Posts

How to Respond to a Subpoena for Business Records
Move fast, but do not produce records on instinct. If you need to **respond to a subpoena for business records**, your immediate job is to control deadlines, preserve records, and make any later production defensible.

A US Expat's Guide to Investing in UCITS ETFs to Avoid PFIC Issues
The real problem is a two-system conflict. U.S. tax treatment can punish the wrong fund choice, while local product-access constraints can block the funds you want to buy in the first place. For **us expat ucits etfs**, the practical question is not "Which product is best?" It is "What can I access, report, and keep doing every year without guessing?" Use this four-part filter before any trade:

Spain Digital Nomad Visa Guide: Requirements, Application & 2026 Updates
Stop collecting more PDFs. The lower-risk move is to lock your route, keep one control sheet, validate each evidence lane in order, and finish with a strict consistency check. If you cannot explain your file on one page, the pack is still too loose.