
Quick Answer
Map one recent change before you estimate. conway's law is most useful when you compare communication handoffs with the module boundary, verify owners and signoff records, and treat missing evidence as discovery scope. Then remove one internal workflow bottleneck and test a small ownership-boundary adjustment where decisions keep stalling. Review handoff delay and reopened interface decisions at a short check-in before expanding.
The Professional's Guide to Conway's Law: A Framework for Risk, Resilience, and Strategic Advantage#
Use Conway's Law before you scope. If the architecture you are proposing depends on communication paths the client does not actually have, delivery risk is likely already present, even if the backlog looks tidy.
The practical definition is short: system design tends to mirror how the organization communicates. That matters because code coupling usually follows human communication. When the design fights the development organization, that tension tends to show up in the software. Treat this as a pre-scoping lens, not a theory lesson.
| Communication pattern | Likely architecture pressure | Immediate scoping response |
|---|---|---|
| One small team with deep informal communication | Simpler, more monolithic or single-pass designs are more likely | Do not force many service boundaries unless ownership is genuinely separate |
| Work split across separate teams | More module or multi-pass boundaries are likely | Price in interface decisions, integration time, and cross-team review points |
| Desired architecture conflicts with actual communication routes | Structural tension in delivery is likely | Mark the mismatch as a named risk before estimating |
Use the article in three steps:
- Diagnose the client first.
Ask how a real change moves from request to release, and note who must talk to whom for that to happen. Your checkpoint is simple: can you name the owners, reviewers, and blockers around the boundary you are about to build? If ownership is vague or approvals are shared across several groups, do not bury that uncertainty in a generic buffer. Call it out in scope, because unclear communication lines can show up as interface ambiguity and integration friction.
- Tighten your own business-of-one.
The same pattern applies to you. If client communication, technical decisions, and delivery work are split across too many disconnected places, your output can start to mirror that fragmentation. Trace one recent job end to end and spot where context gets re-entered, handed off, or quietly lost. If you keep rebuilding the same context, simplify your own handoffs before you add more architectural complexity.
- Reshape communication on purpose when needed.
If the target design and the current org shape clearly clash, consider the Inverse Conway Maneuver: change team or communication boundaries to support the architecture you want. This is a strategic move, not a slogan. Make the smallest ownership change that creates a cleaner technical boundary, then watch whether coordination actually gets clearer. Thoughtworks' note on this technique is historical rather than a current blanket recommendation.
If you manage several specialists, How to Manage a Global Team of Freelancers is a useful companion on the people side.
Start with the client. Before you estimate effort or promise a design, look for hidden risk in the communication structure. If you want a deeper dive, read How Amara's Law Applies to New Technology Decisions.
Part 1: The Law as a Diagnostic Tool - X-Raying a Client for Hidden Risk#
Do not estimate until you can verify how work actually moves. If communication boundaries and architecture boundaries do not match, the tension usually shows up in delivery.
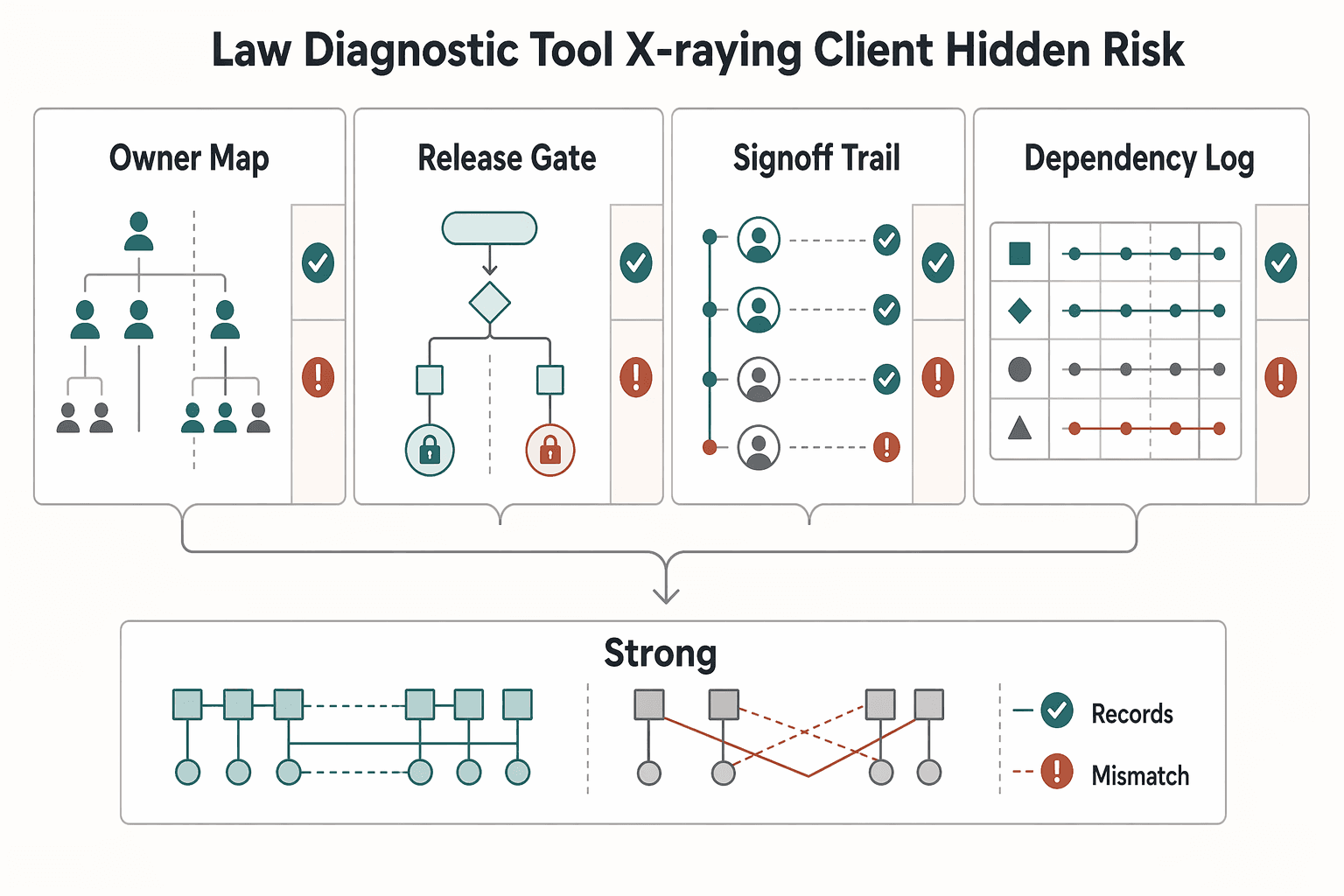
| Artifact | What to verify | If missing |
|---|---|---|
| Owner map | Who can approve requirements, approve or reject changes, and sign off release for this scope | If ownership is shared, rotating, or disputed, log it as an open assumption |
| Approval path | Evidence that a change was proposed, reviewed, approved or disapproved, and recorded | Treat verbal process without records as unverified |
| Signoff trail | A visible record of who signed off and when for the boundary | If signoff exists only as "we usually do this," treat it as unverified |
| Dependency log | Teams, vendors, components, repos, environments, and data owners that can block delivery, with a technical identifier and accountable contact | Do not promise interfaces before each dependency and owner is named |
Ask the client for one real recent change and trace it from request to release. Use these four artifacts as go/no-go inputs: owner map, approval path, signoff trail, and dependency log.
- Owner map: confirm accountable people, not team labels.
Ask who can approve requirements, who can approve or reject changes, and who signs off release for this scope. If ownership is shared, rotating, or disputed, log it as an open assumption.
- Approval path: verify decision records, not verbal process.
Request evidence that a change was proposed, reviewed, approved or disapproved, and recorded. Ticket history, release notes, and explicit approve/disapprove messages all work if they show the decision path and can be retained.
- Signoff trail: confirm a real release decision exists.
You need a visible record of who signed off and when for the boundary you are being asked to build. If signoff exists only as "we usually do this," treat it as unverified.
- Dependency log: name each dependency and owner before promising interfaces.
List teams, vendors, components, repos, environments, and data owners that can block delivery. For each item, include a technical identifier and an accountable contact.
- If evidence is missing, scope uncertainty directly.
Write proposal language such as: "Estimate assumes named ownership, written signoff, and confirmed dependencies. Where evidence is missing, work begins with bounded discovery (owner mapping, record review, approval-path confirmation). Build starts after those inputs are verified." If personal data is in scope, ask whether the client maintains Article 30 records or equivalent compliance records. For a companion process, use GDPR for Freelancers: A Step-by-Step Compliance Checklist for EU Clients.
| Evidence quality | What you can verify | Delivery risk read | Scope posture | Decision |
|---|---|---|---|---|
| Strong | Named owners, evidenced approval path, clear signoff trail, dependency log with accountable contacts | Lower hidden coordination risk | Estimate build work with normal change controls | Proceed |
| Mixed | Some ownership is clear, but records or dependency ownership are incomplete | Moderate risk of approval drag and interface surprises | Add a bounded discovery phase and keep assumptions explicit in writing | Proceed with controls |
| Weak | Ownership is disputed or verbal, records are missing, dependencies are vague or unowned | High risk of rework, blocked release, and scope disputes | Do not price full delivery yet; offer discovery only | Pause |
Your goal is not to judge the client. It is to tie your commitment to evidence.
Part 2: The Law as a Personal Blueprint - Architecting Your "Business-of-One"#
Your delivery reliability will mirror your own communication structure, not just your code quality. Treat your solo workflow like a small system: make state, ownership, and records explicit so decisions do not get lost between messages and release.
| Step | Core action | Checkpoint |
|---|---|---|
| Audit one real job end to end | Pick one recent project and trace it from intake to release | From one record, can you see what is current, who decides, and whether the work is actually done? |
| Separate automation from manual approval | Use automation to enforce consistency; keep human review for judgment calls | If you use code-owner rules, confirm each owner is a real, reachable reviewer |
| Run a repeatable governance cadence | Use the same checkpoints on every engagement: intake, pre-build, pre-release, and closeout | Confirm your documented information still shows both what was planned and what was actually done |
Step 1: Audit one real job end to end#
Pick one recent project and trace it from intake to release. For each stage, capture only these four entities, then apply the matching action:
| Entity | What to capture | Action |
|---|---|---|
| Workflow state | Current stage label | Standardize one shared legend |
| Handoff point | Where work moves tools or contexts | Integrate or collapse duplicate transfers |
| Approval owner | Named person for go/no-go | Standardize explicit ownership before build |
| Artifact location | Where the current record lives | Remove scattered copies; keep one authoritative location |
Work from a single source of truth. Include a status legend, a current-version marker, a named contact path, and a clear pending vs final flag. A practical legend is: Proposed, In Progress, Resolved, Complete. Checkpoint: from one record, can you see what is current, who decides, and whether the work is actually done?
| Weak habit | Likely delivery friction | Operating rule |
|---|---|---|
| Scope lives across inbox, chat, and notes | Version conflict and missed changes | Keep active scope in one authoritative record |
| Status labels change by project | Pending vs final confusion | Reuse one status legend across jobs |
| Approval is implied, not assigned | Late rework or blocked release | Name one approval owner before implementation |
| Final artifacts are mixed with drafts | Release uncertainty | Mark one current version and explicit final state |
Step 2: Separate automation from manual approval#
Use automation to enforce consistency, and keep human review for judgment calls.
| Automate | Keep manual |
|---|---|
| Tests and required status checks | Scope changes |
| Reviewer requests for owned code areas | Release decisions |
| Routine merge gating | Client-facing commitments |
If you use code-owner rules, make sure each owner is a real, reachable reviewer, not a placeholder.
Step 3: Run a repeatable governance cadence#
Use the same checkpoints on every engagement: intake, pre-build, pre-release, and closeout. At each checkpoint, confirm that your documented information still shows both what was planned and what was actually done.
If handoffs keep multiplying, use How Gall's Law Helps Independent Professionals Build Systems That Last as a companion lens before adding more process.
Part 3: The Law as a Strategic Lever - The Inverse Conway Maneuver#
Use this when your intended design keeps failing at handoffs, escalations, or approval bottlenecks. If communication structure is shaping the system, change communication and ownership boundaries first, then ask teams to deliver the architecture.
| Step | Action | Anchor or signal |
|---|---|---|
| Set the target architecture in one sentence | State the boundary you want, what stays outside it, and who should be able to ship inside it without waiting on other teams | Use one recent delayed or failed change as the anchor example |
| Name the org pattern blocking that target | Map one real request-to-release path and mark every team touch, approval stop, and escalation point | Diagnose delivery friction, not just the org chart |
| Test one boundary change, not a full redesign | Move one ownership boundary so routine design decisions need fewer cross-team negotiations | Document intended team type and main interaction mode on each side of the boundary |
| Define success signals before rollout | Replace vague goals with observable signals | Capture a simple before-state in workshop notes |
Run this as a focused workshop on one product area, one service boundary, or one request-to-release path that already shows friction.
Step 1#
Set the target architecture in one sentence. State the boundary you want, what stays outside it, and who should be able to ship inside it without waiting on other teams.
Use one recent delayed or failed change as the anchor example so the discussion stays evidence-based.
Step 2#
Name the org pattern blocking that target. Diagnose delivery friction, not just the org chart: interdependent teams, coordination problems, repeated escalation, slow pace, high feature costs, approval drag, or handoff delay.
Map one real request-to-release path and mark every team touch, approval stop, and escalation point. If the architecture and org structure conflict, org structure usually dominates outcomes, so this diagnosis is the critical step.
Step 3#
Test one boundary change, not a full redesign. Move one ownership boundary so routine design decisions need fewer cross-team negotiations.
As a lightweight Team Topologies aid, document only two items per side of the boundary: intended team type and main interaction mode. That keeps it specific and operational.
| Blocking pattern | Boundary change to test | Tradeoff or failure mode | What to monitor |
|---|---|---|---|
| Split ownership of one product area | Assign one team end-to-end ownership for that area | New bottleneck if key skills are missing, or shadow authority remains | Handoff count, reopened interface decisions, who gets pulled into routine changes |
| Interdependent teams for ordinary changes | Reduce shared surface area or regroup work around a cleaner boundary | Short disruption during responsibility transfer; hidden dependencies can persist | Handoff delay, coordination issues, pace of small changes |
| Repeated escalation for design decisions | Push routine decisions to the owning team with one clear exception path | Inconsistent decisions if criteria are unclear; informal gatekeeping can survive | Escalation frequency, approval drag, feature cost trend |
Step 4#
Define success signals before rollout. Replace vague goals with observable signals: fewer escalations, fewer teams per normal change, less waiting between handoffs, and fewer costly feature requests caused by boundary confusion.
Capture a simple before-state in workshop notes so later decisions are based on measured friction, not memory.
Phased rollout with guardrails#
Roll out in phases: pilot one boundary, run a limited delivery period, then expand, hold, or reverse using the same signals. Keep guardrails strict: one clear owner, one approval path, and no side channel that recreates the old handoff pattern. Narrow or roll back if escalations spread, handoff delay worsens, or interface ownership becomes unclear.
If your target state also requires cleaner service boundaries, read A Guide to Microservices Architecture for SaaS Applications. If the change depends on clearer cross-team operating rhythms, use How to Manage a Global Team of Freelancers as the companion playbook.
Conclusion: You Are The Architect#
You do not need a grand redesign to act on this. You need three concrete moves, in order: diagnose coordination risk from one real change, fix one blockage in your own delivery path, and test one ownership adjustment where decisions keep bouncing.
Before you start, trace one recent change from request to release and gather the records that show how decisions moved. If that path is hard to reconstruct, treat the gap as discovery work instead of assuming the boundary is already clear.
Diagnose client risk from a real change#
Take one recent feature, bug fix, or integration change and trace it from request to release. Write down who asked for it, who owned the boundary, and which teams had to coordinate for it to land. Then compare that path to the module or product area that changed.
Your checkpoint is simple: you should be able to name one real owner and the key decision and handoff points. If a client can only show you an org chart or a vague "team owns it" answer, treat that as a warning sign. Do not estimate a clean architectural boundary when the decision path is still fuzzy.
Fix your own delivery path before you prescribe theirs#
Run the same test on yourself. Follow one job from inbound request to shipped work and mark every pause caused by split notes, inboxes, approvals, or unclear ownership. If your proposal lives in one place, client comments in another, and release decisions in chat, your delivery will reflect that fragmentation.
Your verification point is whether one view of the work shows the current owner and the next decision. If you cannot tell what is blocked without searching across tools and messages, you likely have a hidden queue. Fix that before you recommend process changes to anyone else.
Choose a structural change you can monitor#
When the same boundary causes repeated negotiation, propose one clear owner for that area first. If the issue is wider, use the Inverse Conway Maneuver deliberately: define the target architecture, analyze the current structure, and ask for a restructuring plan that includes a timeline and a communication strategy. Then implement in phases and monitor it, rather than changing everything at once.
| Decision factor | Broad reorg | Small boundary change |
|---|---|---|
| Disruption | Can be higher, because role and communication changes may spread across more teams | Can be lower when you contain the change to one contested area |
| Reversibility | May be harder to unwind once reporting lines and ownership move widely | May be easier to revisit after a pilot period |
| Decision clarity | Can clarify many decisions if designed well, but may blur ownership during transition | Can clarify one decision path faster when one owner is explicit |
If your evidence points to one recurring coordination problem, a smaller move is often easier to test first. If the mismatch appears across several boundaries and leadership is prepared for phased change, a broader reorg may be justified.
That is the practical use of Conway's Law. It gives you a way to judge visible correspondence between communication and design, not a license to make big claims. Your next step is modest and testable: bring one recent change record to your next conversation, name the main handoffs and decision points, and make one recommendation you can revisit after a short check-in. If you need help thinking through boundary design, A Guide to Microservices Architecture for SaaS Applications is a useful next read.
We covered this in detail in A Guide to Continuous Integration and Continuous Deployment (CI/CD) for SaaS.
Frequently Asked Questions
How does this apply if you work alone?
It can still apply, just at a smaller scale. Map your own path from request to release and look for self-created handoffs between sales, design, coding, review, and client approval. If one change keeps bouncing between tools or decision points, your structure is already shaping the product.
Can you use this during client discovery?
Yes. Ask for one recent change and trace who requested it, who approved it, who implemented it, and who had to coordinate across boundaries. If the client cannot show that path clearly, treat the uncertainty as discovery work in scope instead of promising a clean delivery plan.
What should you verify instead of trusting the org chart?
Verify the real decision path: who owns the boundary, who approves routine changes, and which teams must talk for interfaces to work correctly. A title box is less useful than one concrete example from request to release. | Quick check | Org-chart assumption | Verified decision path | |---|---|---| | Owner | Team name on slide | Named person or team making routine calls | | Approval | Formal manager line | Actual signoff stop before release | | Dependency | “They collaborate” | Specific teams touched on a recent change |
What is a practical example of the Inverse Conway Maneuver?
One product area is split across multiple teams, so ordinary changes trigger negotiation and escalation. Instead of a broad reorg, move that area to one clear owner for a pilot period and track whether handoffs and reopened interface decisions change.
Is Conway's Law a rule, or just a useful lens?
Use it as a working constraint. The core point is simple: design tends to mirror communication, so ignoring communication paths usually creates tension in the software.
Does remote-first work differently from co-located work here?
The grounding here does not support a simple remote-versus-office ranking. What matters more is whether module owners communicate directly and whether approvals and dependencies are explicit.
What are the limits of this approach?
It will not tell you the perfect org design. The stronger use is iterative: map current teams and communication channels, test one small boundary change, and keep evidence on whether friction changes.
What is the easiest mistake to make with a client?
Committing to architecture before ownership, approvals, and dependency paths are verified. That can leave you estimating a clean boundary that the client cannot actually support.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
Includes 2 external sources outside the trusted-domain allowlist.
- csrc.nist.gov/pubs/sp/800/30/r1/finaltrusted
- csrc.nist.gov/pubs/sp/800/53/r5/upd1/finaltrusted
- en.wikipedia.org/wiki/Conway%27s_lawtrusted
- legislation.gov.uk/eur/2016/679/article/30trusted
- pmc.ncbi.nlm.nih.gov/articles/PMC11043955trusted
- iso.org/files/live/sites/isoorg/files/archive/pdf/en...external
- thoughtworks.com/en-us/radar/techniques/inverse-conway-maneuverexternal
Educational content only. Not legal, tax, or financial advice.
Related Posts

GDPR Compliance Checklist for Freelancers Working With EU Clients
Start by separating the decisions you are actually making. For a workable **GDPR setup**, run three distinct tracks and record each one in writing before the first invoice goes out: VAT treatment, GDPR scope and role, and daily privacy operations.

How to Manage a Global Freelance Team Without Compliance Gaps
If you want to manage a global freelance team without constant cleanup, use the same intake-to-payout process for every engagement and save an artifact at each gate. Common failure points are instinct-based classification, vague scope, and payments approved in chat with no audit trail.

Microservices Architecture for SaaS Without Finance and Compliance Surprises
Choose your operating model before you choose your decomposition pattern. For most early products, that means a modular monolith with clear domain boundaries, not a full microservices setup on day one. The reason is practical. Every new service adds cognitive load, failure points, and maintenance cost, so the split pays off only when your team and controls are ready.