
Quick Answer
Use a hybrid setup for the unbundling of it agencies: keep high-judgment work bundled, split repeatable production, and centralize money controls. Start by naming one accountable owner, then enforce handoff checks with Webhooks, Ledger reconciliation, and payout-state reviews. Add compliance gates for GDPR, KYC/KYB, AML, and VAT before release or payout approval. Expand scope only after a pilot cycle closes with consistent records and no recurring exception pattern.
Why Unbundling Needs a Delivery and Payment Plan#
Unbundling is no longer a theoretical strategy choice. For freelancers and small cross-border teams, it is an operating decision about where accountability must stay tight and where specialized execution can be split without creating hidden risk.
Most avoidable failures do not come from bad intent or weak effort. They show up when teams move faster than ownership, approvals, and records can support. Teams that do this well choose their operating shape first, then shift scope in controlled steps. Teams that skip that order usually find the gaps late, when release pressure is high and no one wants to slow down long enough to fix them.
In practice, this is organizational unbundling in its simplest form: semi-autonomous contributors connected by shared services. Focused work gets separated, while finance, IT, and HR support stay centralized so handoffs do not become blind spots. That model only works when ownership is explicit at every boundary and every exception has a home.
Three shifts are making the decision more urgent for smaller teams:
- Lower transaction friction. APIs, plug-ins, open standards, and extensions make it easier to combine services and replace weak components.
- Smaller teams can compete. Lean teams can assemble real capability through composition, not just headcount.
- Platform tradeoffs are harder to ignore. Platform-mediated work can broaden access in cross-border markets, but it can also constrain mobility and protections.
The goal is not to split everything. Unbundle repeatable, lower-judgment tasks. Keep high-judgment decisions bundled where trust, quality, and risk control depend on one accountable owner. Then put practical controls at the seams where failures usually hide: approvals, reconciliations, and evidence capture.
Use one stop rule from day one: if no single person can approve critical delivery decisions and cash-movement exceptions, pause before unbundling further. That single check prevents most coordination debt before it starts and makes the next model choice much cleaner.
How to choose your model before you unbundle anything#
Start with the operating model, not the vendor swap. If you cannot name one accountable owner for delivery outcomes, compliance-sensitive decisions, and payout exceptions, you are not ready to split execution.
This guide is for independent professionals and small cross-border teams that need reliable invoicing, payouts, and exportable records for privacy and tax operations. It is not aimed at enterprise modernization programs that are primarily architecture-led. The context here is practical: small teams moving fast, handling cross-border complexity, and still needing records that hold up under review.
Use one scorecard across every option so you are comparing operating choices, not sales promises:
- Ownership clarity: name one accountable owner in writing before any scope shift.
- Speed to launch: measure how fast you can go live without introducing hidden handoff risk.
- Quality control: define acceptance criteria before work is distributed across contributors.
- Payment reliability: identify where invoice, approval, and payout states can drift.
- Compliance burden: treat GDPR, KYC, AML, and VAT as jurisdiction-specific checkpoints that must be validated.
- Documentation quality: keep an Audit Trail and exportable records so decisions remain traceable.
To make the scorecard useful, rate each option for your next operating cycle, not for an ideal future state. Add the top failure mode for each option in one line. That turns planning into a decision record you can revisit, rather than a preference debate you repeat every quarter. It also gives you a clean way to explain the choice when stakeholders ask six weeks later why the team moved one way and not another.
| Option | Best for | Main upside | Main risk | Required controls |
|---|---|---|---|---|
| Keep core agency | High-stakes launches | Clear escalation path | Cost and lock-in | SLA, delivery acceptance, Audit Trail |
| Hybrid stack | Growing cross-border teams | Flexibility with guardrails | Coordination drag | API contracts, Webhooks, Idempotency Key |
| Platform-first | Ops-mature teams | Lower cost and faster cycles | Process fragility | Ledger checks, KYC or KYB gates, payout monitoring |
| Specialist pod | Niche outcomes | Expert depth | Continuity and bus-factor risk | Backup ownership, documented handoffs |
Two discipline points matter more than they first appear. First, establish source hierarchy early. Separate guidance from binding requirements before policy decisions spread across vendors. Second, when legal interpretation drives a go or no-go decision, verify against official editions and store that verification in your evidence pack. If that feels slow, remember the tradeoff: a short delay in validation is cheaper than a cross-vendor rollback after launch.
If you want to tighten the privacy side before model selection, use How to Make Your Freelance Website GDPR Compliant as a practical baseline. Once the criteria are set, the next sections show where each operating shape works, where each one fails, and how to keep scope changes from outrunning controls.
Best option for high-stakes delivery with low coordination overhead#
If failure could damage revenue, trust, or both, keep a core agency for strategy, integration oversight, and final acceptance. Unbundle only commodity production around that core. In high-downside work, one clear escalation path is usually worth more than maximum flexibility.
This model earns its keep when launches are complex or regulated, multiple specialists are contributing, and client confidence depends on one final authority for scope and release decisions. In that setting, clarity matters more than theoretical efficiency. You are paying for fewer moving parts at the moments that matter most.
The common failure is split sign-off language. One party approves delivery while another controls release or payout exceptions. If that conflict is not resolved in the contract before kickoff, teams usually discover it in launch week, when confusion is most expensive. The work may be complete, but no one can authorize the final move without reopening earlier decisions and re-litigating ownership under time pressure.
Keep this model tight with a short control set:
- Single owner mandate: one person approves scope changes, release readiness, and exceptions.
- Evidence-backed milestones: require Audit Trail exports and API event logs for release-critical checkpoints.
- Compliance evidence map: define where each record lives and who signs off before release.
- Source hierarchy check: separate guidance from obligations, and verify legal obligations in regulation text.
The tradeoff is straightforward. You gain tighter quality and risk control, but velocity can drop if bundled scope is never revisited. Treat bundled scope as intentional, not permanent. Reassess what stays bundled at fixed intervals so you do not keep paying a coordination premium after the original risk has passed.
Before launch, do one alignment check using records from the same window. Delivery acceptance records, Audit Trail data, and API event history should tell the same story. If they do not line up, hold release and resolve the mismatch first. That pause often makes the difference between a controlled launch and a costly post-launch dispute.
Best option for most cross-border small teams using a hybrid stack#
If you do not need the tighter control of a core agency, a hybrid stack is usually the practical default for cross-border small teams. Keep high-judgment work close to one accountable lead, distribute repeatable execution to specialists, and centralize money controls so handoffs do not distort payouts.
For most teams, this is the best balance of speed, cost, and control. It lets you move faster and lower operating cost without giving up payout reliability. The upside is flexibility: you can replace a weak provider without rebuilding the entire service. The risk is just as clear: vague interfaces turn handoffs into blame loops, and those loops eat more time than the savings you expected.
That is why operating discipline matters more than the tool list. Look at full cost, not sticker price, and define interfaces before volume rises. A simple four-part filter keeps the model honest:
- Modular vendor mix: assign invoicing, Virtual Accounts, and Payout Batches to platform rails, while specialists handle scoped delivery.
- Explicit interfaces: define webhook ownership and ledger reconciliation ownership for each money event.
- Handoff ownership map: name who owns each checkpoint from completed work to payout confirmation.
- Commercial reality check: compare base and add-on fees together before commitment.
A pattern that works in practice is simple. A platform handles invoicing, Virtual Accounts, and Payout Batches. Specialists handle design and content delivery. One internal owner monitors webhook delivery and reconciles payout status to the Ledger at day end. Exceptions route to a named owner, not across an open chain of vendors. That owner does not need to do every fix, but they must own closure and timestamped status so issues do not disappear into chat threads.
This model depends on routine, not heroics. Keep weekly review windows fixed, keep exception categories stable, and track repeat failure types across cycles. Predictable review habits make handoff risk visible before clients feel it. Teams that skip this rhythm often mistake silence for stability until reconciliation gaps have already piled up and payout questions start landing at the worst possible time.
Use one weekly exception review with three artifacts from the same period: payout status export, webhook delivery log, and ledger variance report. If the counts do not match, pause new onboarding until you explain and fix the mismatch.
If payout errors repeat for two cycles, narrow scope before expanding again. Centralize payout orchestration first, tighten reconciliation, and then continue unbundling in smaller increments. That keeps momentum without compounding weak controls.
Best option for operator-led teams ready to bring most execution in-house#
Bring most execution in-house only when your operator-led team can absorb integration, monitoring, and exception handling without degrading delivery quality. If that ownership is not real and daily, projected savings are usually overstated.
Done well, this model improves margin and cycle speed on standardized work. It also moves the control burden inward. You gain direct visibility into failures, and you inherit responsibility for retries, replay handling, reconciliation, and ongoing compliance checks. You are not only replacing vendors. You are taking on the operating duties those vendors previously absorbed.
Before you expand in-house scope, confirm who owns three jobs every day: monitoring, exception triage, and ledger reconciliation. When those responsibilities rotate informally, process quality usually drops in busy cycles and the first sign tends to appear in payout exceptions. If ownership is shared, define primary and backup roles clearly so there is no ambiguity during release windows.
Keep the stack disciplined. Use one execution stack for collections and payouts. Enforce Idempotency Key handling on retryable writes. Reconcile every status change to the Ledger so issues show up in event history, not after payout disputes.
No automation or vendor change should reach production without test evidence for three checks:
- Retry handling with
Idempotency Keyand no duplicate financial effect. - Webhook replay handling with no duplicate ledger outcome.
- Payout state consistency between exported statuses and Ledger records.
Treat this as a staged rollout, not a single cutover. If exception volume rises across consecutive payout cycles, freeze additional scope and tighten controls before adding new in-house lanes. Expansion should follow proof, not confidence alone.
Best option for niche outcomes using a specialist freelance pod#
Not every team wants more internal execution. When the real need is a narrow, high-skill outcome, a specialist pod is often the better choice. Used with discipline, it gives you sharper execution and flexible capacity. Used loosely, it creates continuity risk and fractured ownership.
The pattern is familiar. Work often shifts from solo freelancers toward coordinated small teams when outcomes become specialized. That is a useful signal, but it is not proof that every pod fits your constraints. Validate the model against your delivery requirements before you widen scope. The right question is not whether the pod is talented. It is whether the pod can deliver repeatably inside your controls.
The basics matter more than the talent pitch. Define one outcome and one acceptance standard before staffing. Select for team execution quality, not just individual resumes. Centralize KYC or KYB, AML, VAT, and GDPR checks in one operating layer tied to payout approval. Keep shared payment rails so controls stay consistent as contributors rotate. Set handoff ownership before kickoff, including backup ownership if a specialist exits.
Before you expand the pod, run a continuity drill on paper. Who takes over if one specialist leaves mid-cycle, and where are the latest acceptance records stored? This low-cost exercise exposes ownership gaps while they are still easy to fix. It also forces clearer documentation before pressure rises and makes later scaling decisions less emotional.
The mistake to avoid is scaling pod scope before continuity controls are stable. Start narrow, verify handoff reliability, and then increase scope lane by lane. If you support EU clients, a baseline checklist such as GDPR for Freelancers: A Step-by-Step Compliance Checklist for EU Clients helps keep pods aligned on privacy expectations.
What breaks first in unbundled models and how to catch it early#
Regardless of which model you choose, early failures usually follow the same pattern. The first breaks are rarely about creative quality. They are control failures: unclear ownership, weak reconciliation, inconsistent compliance gates, and ad hoc tax-document capture. Catching them early is mostly a matter of sequence and review discipline.
| Failure point | Typical sign | Control |
|---|---|---|
| Ownership drift between delivery and finance operations | Exceptions stall between delivery and money operations | Assign one release approver and one payout approver, then set same-day escalation when either path blocks |
| Data mismatch between events and balances | Status counts stop matching or records fail to reconcile | Run daily Webhooks-to-Ledger checks and clear one exception queue before day end |
| Compliance drift before release or payout | KYC, AML, and VAT checks are applied unevenly across contributors or jurisdictions | Keep one gate sequence and require dated evidence before release and before payout approval |
| Tax-document chaos in cross-border records | W-8, W-9, FEIE support files, FBAR inputs, and Form 1099 records are collected ad hoc | Maintain one evidence pack per contributor and review it on a fixed cadence |
The warning signs are operational and repeatable. Exceptions age without owner action. Status counts stop matching. Approvals rely on chat context instead of dated records. When those signals appear together, quality and payout issues usually follow. The sequence matters: control drift appears first, then confidence drops, then delivery quality and payment reliability deteriorate.
- Ownership drift between delivery and finance operations
When approval authority is vague, exceptions stall between delivery and money operations. Assign one release approver and one payout approver, then set same-day escalation when either path blocks. The aim is simple: every exception has a named owner and a clock. If ownership changes mid-cycle, update the record immediately so open exceptions do not lose accountability.
- Data mismatch between events and balances
Statuses can change while records still fail to reconcile. Run daily Webhooks-to-Ledger checks and clear one exception queue before day end. Keep one-pass verification across event counts, payout states, and ledger movements so teams cannot mark work complete on partial evidence. If the same mismatch keeps reappearing, treat it as a control defect, not a one-off inconvenience.
- Compliance drift before release or payout
KYC, AML, and VAT checks are often present but applied unevenly across contributors or jurisdictions. Keep one gate sequence and require dated evidence before release and before payout approval. For U.S. contributors using FEIE, keep the practical constraint in view: it applies only to qualifying individuals, excluded income is still reported on a U.S. return, and limits are year-specific, including $130,000 for 2025 and $132,900 for 2026.
- Tax-document chaos in cross-border records
W-8, W-9, FEIE support files, FBAR inputs, and Form 1099 records degrade quickly when collection is ad hoc. Maintain one evidence pack per contributor and review it on a fixed cadence. For account-value reporting inputs, capture each account separately and convert maximum values to U.S. dollars rounded up to whole dollars, so $15,265.25 becomes $15,266. This avoids inconsistent reporting inputs that become expensive to unwind later.
A common failure pattern is repeated reconciliation misses in a short window. When that happens, pause onboarding and repair ownership and evidence gates before scaling further. That pause is usually cheaper than cleaning up a wider failure later.
The 7-step checklist to unbundle agency services without raising risk#
Once you know what usually breaks first, turn those failure points into a go or no-go gate. Expand only when ownership, controls, and records are already working in live operations. Treat each step as evidence-based, not aspirational.
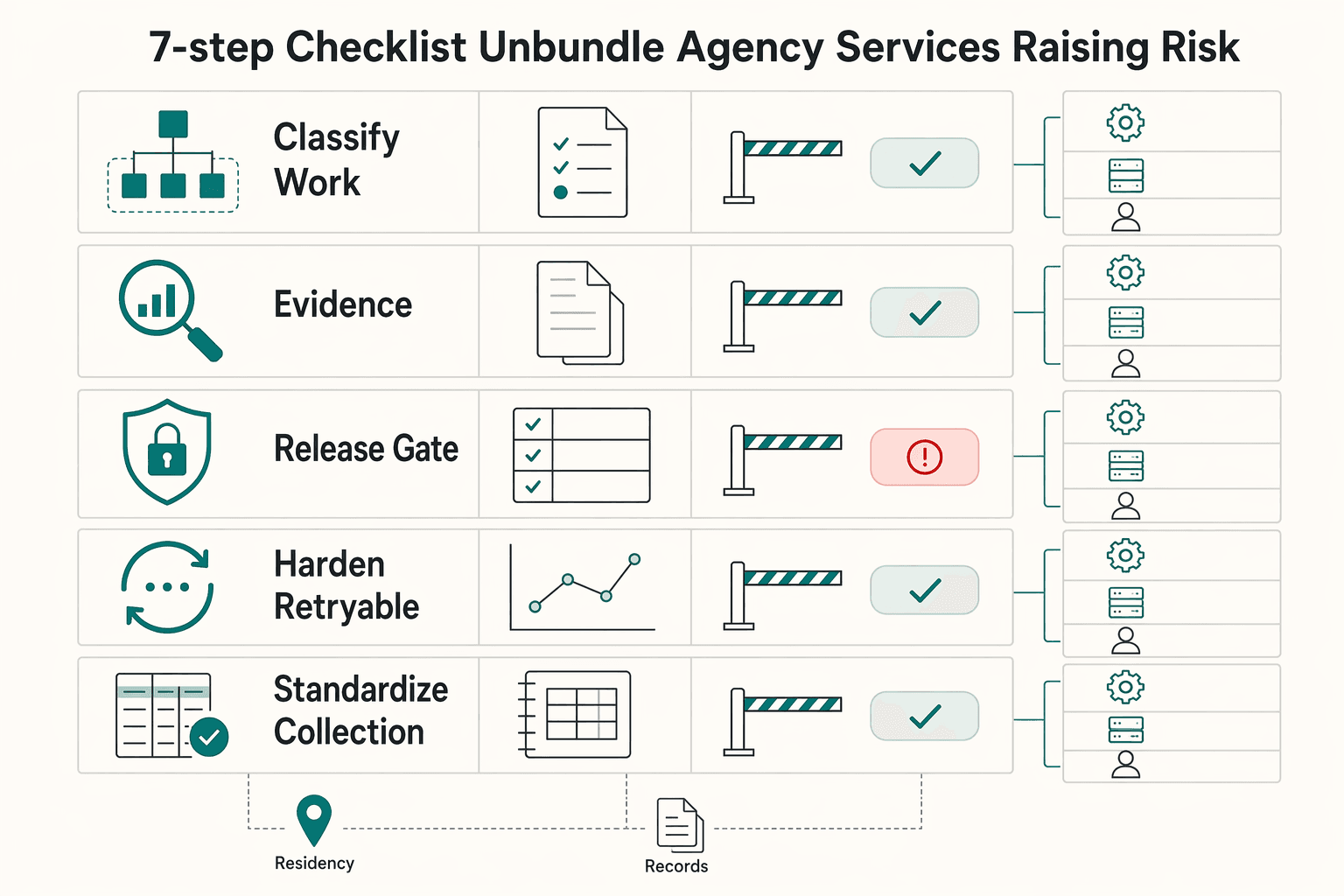
| Step | Focus | Key gate |
|---|---|---|
| Classify work before you move it | Split tasks into automate, platform-enable, and expert-only lanes | Assign one accountable owner to each lane for at least one full cycle |
| Use one money record as the decision point | Choose one Ledger as the system of record | Reconcile to it first each payout period using Audit Trail exports; pause release approvals if totals do not match |
| Set policy gates before onboarding and payout | Define KYC or KYB, AML, and VAT checks where applicable | Require evidence before activation and before payout approval |
| Harden retryable technical paths before launch | Require explicit API contracts, clear webhook ownership, and Idempotency Key handling on retryable writes | Run replay tests and require sign-off before go-live |
| Standardize collection and disbursement operations | Use Virtual Accounts for intake and Payout Batches for outbound payments where available | Route exceptions into one review queue with named owners and response times |
| Lock tax-document evidence capture | Maintain one contributor evidence pack for W-8, W-9, FEIE support, FBAR inputs, and Form 1099 records where applicable | Date every file and keep the review cadence fixed |
| Pilot before scaling | Run a 30-day pilot with fixed scope | Review exceptions weekly and expand only after clean closing weeks |
- Classify work before you move it
Split tasks into automate, platform-enable, and expert-only lanes. Assign one accountable owner to each lane for at least one full cycle. Ownership should follow task class, not convenience or org-chart habit. Document the lane owner before any vendor transition starts, and keep that owner visible in weekly reviews.
- Use one money record as the decision point
Choose one Ledger as the system of record. Reconcile to it first each payout period using Audit Trail exports. If totals do not match, pause release approvals until the variance is explained and documented. Keep the variance note attached to the same review period so later audits do not depend on memory.
- Set policy gates before onboarding and payout
Define KYC or KYB, AML, and VAT checks where applicable. Require evidence before activation and before payout approval. Keep jurisdiction-specific rules in one maintained policy set so contributors are not assessed against changing, undocumented criteria. A stable gate sequence prevents last-minute policy improvisation.
- Harden retryable technical paths before launch
Require explicit API contracts, clear webhook ownership, and Idempotency Key handling on retryable writes. Run replay tests so retries do not create duplicate financial effects after deployment. Store replay results with release evidence, not in ad hoc notes, and require sign-off before go-live.
- Standardize collection and disbursement operations
Where available, use Virtual Accounts for intake and Payout Batches for outbound payments. Route exceptions into one review queue with named owners and response times. Centralized cash movement reduces failure variance as delivery vendors change and keeps reconciliation logic stable.
- Lock tax-document evidence capture
Maintain one contributor evidence pack for W-8, W-9, FEIE support, FBAR inputs, and Form 1099 records where applicable. FEIE still requires filing, and limits are year-specific, including $130,000 for 2025 and $132,900 for 2026. Date every file and keep the review cadence fixed so no document drifts out of cycle.
- Pilot before scaling
Run a 30-day pilot with fixed scope. Review exceptions weekly and expand only after clean closing weeks. If account-value reporting is required, round U.S. dollar amounts up to whole dollars, so $15,265.25 becomes $15,266. Use pilot findings to tighten ownership and documentation before expanding lanes.
Use one red-flag rule throughout the checklist: if the same exception type appears in two consecutive weekly reviews, stop scope growth and fix the owner, test case, or document gap before resuming expansion.
Conclusion#
Selective unbundling is usually safer than a full split on day one. Treating every task as replaceable too early often creates coordination costs that erase the expected gains. For most cross-border teams, the stable baseline is consistent: keep high-judgment work bundled, distribute repeatable execution, and centralize shared controls so ownership and records stay clear.
That is usually how this works in real operations. Semi-autonomous contributors can move quickly when shared services and decision authority stay coherent. Lower transaction friction and API-based recombination make modular delivery more viable, but they do not create better outcomes by themselves.
If you need a practical order of operations, use this sequence and treat each step as a decision checkpoint:
- Choose the operating shape before changing vendors.
Map who owns delivery decisions, payout approvals, and exceptions for the next cycle. Put those owners in writing before scope moves, and confirm escalation paths before launch pressure starts.
- Start with a hybrid split unless the risk profile says otherwise.
Keep strategy, client communication, and final quality judgment with one accountable lead. Unbundle repeatable production with explicit acceptance checks and visible escalation paths.
- Scale only after one clean cycle.
Run the checklist on live work, review exceptions weekly, and expand only when control evidence stays clean for the full cycle.
One rule carries through every model: expand only what you can verify. If you need help validating the next move for your team, Talk to Gruv.
Frequently Asked Questions
What is the unbundling of IT agencies in plain terms?
It means breaking one end-to-end service into smaller blocks you can buy, run, and replace separately. This aligns with service-model unbundling as separating work into manageable components. It does not mean every team should split everything at once.
Unbundling vs disintermediation: what is the practical difference for freelancers and small teams?
Unbundling separates work into components. Disintermediation usually means reducing or removing intermediaries between buyers and specialists. In practice, teams can unbundle work while still keeping a coordination layer.
When should a small team replace an agency with platforms, and when should it not?
Replace agency scope when work is repetitive, clearly specified, and easy to verify with acceptance checks. Keep bundled support when outcomes depend on cross-functional judgment, unclear requirements, or high downside from failed delivery. AI is accelerating this split by pushing agencies toward strategy and orchestration while more standardized execution gets separated.
What usually fails first after unbundling, delivery quality or payment operations?
A common early failure point is unclear ownership after responsibilities split. Delivery quality and payment operations can both degrade when exceptions have no clear end-to-end owner. If the same exception repeats across reviews, pause expansion and fix ownership before adding vendors.
What is the minimum operating setup for cross-border teams to stay compliant and get paid reliably?
There is no universal minimum setup for every cross-border team. Start with clear ownership for delivery decisions, one source of truth for payments, and a documented approval path. Then validate jurisdiction-specific legal and tax requirements before scaling.
Which controls are non-negotiable if we use multiple tools and specialist vendors?
Keep contract-level responsibility clarity, reliable reconciliation, and documented approval gates that match your jurisdiction and sector. Require clear escalation owners and dated records for approvals. Treat legal terms carefully because rules from one context do not automatically transfer to agency operations.
How do we keep flexibility without losing accountability?
Use modular vendor choices, but lock accountability to named roles and measurable checkpoints. Expand only after a pilot window with clean exception reviews, then add one lane at a time. Flexibility comes from replaceable components, while accountability comes from explicit ownership and documented decisions.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
Educational content only. Not legal, tax, or financial advice.
Related Posts

GDPR Compliance Checklist for Freelancers Working With EU Clients
Start by separating the decisions you are actually making. For a workable **GDPR setup**, run three distinct tracks and record each one in writing before the first invoice goes out: VAT treatment, GDPR scope and role, and daily privacy operations.

How to Make Your Freelance Website GDPR Compliant
You can get your website to a practical, GDPR-style minimum viable setup in one working session by (1) setting a safe default for tracking, (2) implementing real cookie consent behavior, (3) publishing a plain-English privacy notice, and (4) keeping lightweight "prove-it" records. You run a business of one, so your compliance setup needs to be operational, maintainable, and fast to verify. You do not need enterprise compliance theater. You need a freelancer-grade system you can keep running without slowing deals.

The Freelance Payment Penalty: A Modeled Audit of Platform Fees, FX Spreads, and Payout Delays
The money rarely disappears through a single, easy-to-spot fee. The real loss is stacked. A marketplace takes its commission, a processor adds a charge for international cards, a bank or payment company converts the currency at a spread, a platform holds the funds before release, and a wire sheds a little to intermediaries on the way in. Each layer looks defensible on its own, but the worker feels the combined result as a smaller deposit and a later payday.