
Quick Answer
Build your system around written scorecards, lean KPI/OKR rules, and documented one-on-one evidence. Remote team performance management works when you separate meeting purposes, log decisions with owners and checkpoints, and move from coaching to formal correction only after a recorded pattern. For distributed IT agencies, evaluate reliability through delivery quality and handoff clarity rather than chat visibility or reply speed.
What remote performance management looks like in an IT agency#
If your remote team performance management feels inconsistent, the problem is often not distance itself. It is ambiguity. Performance breaks down when expectations, feedback, and decisions live in chat history or manager memory instead of a written record you can review. In remote and hybrid teams, documented expectations and outcome-based measures matter more than office visibility, so your first move is to make the standard visible.
Start with three controls. Write down what good work looks like for each role. Put regular review touchpoints on the calendar instead of waiting for problems to pile up. Use async updates for predictable status, then use live conversations for coaching, tradeoffs, and judgment calls that need context. In an IT agency, people should not have to guess what counts as a complete handoff, what quality bar applies to client delivery, or what a manager will ask about in a one-on-one.
This guide gives you the pieces to make that practical. It covers role scorecards, KPI and OKR decision rules, a meeting cadence with clear jobs, an escalation path for performance issues, and an evidence pack for fair reviews. Keep one more rule in view as you build: after performance discussions, keep a written record. Decision logs, one-on-one notes, and dated examples of work quality are what turn opinions into decisions you can explain.
Before you move on, do a quick readiness check. For each direct report, can you point to one document that shows the current expectations, who owns the next decision if priorities conflict, and the next review or one-on-one date? If any of those are missing, fix that first. Early ratings without written expectations or a scheduled follow-up can become guesswork.
Build the mental model before you set targets#
Set your decision system before you set targets. If expectations, evidence, and approval paths are not defined first, KPI and OKR discussions usually become inconsistent.
| Term | Definition | Manager use |
|---|---|---|
| Role scorecard | Written definition of what good performance looks like in a role | Evaluate outcomes, not visibility or personal style |
| KPI | Recurring operating signal | Decide whether coaching, staffing, or priorities need to change |
| OKR | Time-bound improvement goal with a clear progress signal | Track planned change work, not replace day-to-day performance evaluation |
Start with one shared operating page that covers expectations, decision points, evidence standards, and accountability.
Use these plain-language terms so everyone applies them the same way:
- A role scorecard is your written definition of what good performance looks like in a role. Managers use it to evaluate outcomes, not visibility or personal style.
- A KPI is a recurring operating signal. Managers use it to decide whether coaching, staffing, or priorities need to change.
- An OKR is a time-bound improvement goal with a clear progress signal. Managers use it to track planned change work, not to replace day-to-day performance evaluation.
Add governance before rollout: define who can initiate escalation, who approves rating changes, where decisions are logged, and how calibration disagreements are reviewed. Owners can vary by team, but the rules should be explicit and consistent.
If your team works across borders, pause for a legal and policy mapping step before implementation. Use a placeholder such as [local HR policy and jurisdiction review required before implementation] until each location is mapped.
Run short, regular plan reviews for ongoing work, and keep formal evaluation checkpoints separate for higher-impact decisions. Keep issues in coaching while expectations are clear and progress is documented; move to correction when coaching is not resolving the issue or risk is expanding.
Quick self-check before moving to scorecards and targets: can you point to each person's current scorecard, evidence source, next check-in, escalation entry point, and rating approver? If not, finish that setup first.
Set role scorecards that match agency delivery reality#
Set scorecards to evaluate outcomes and work quality, not activity signals. In remote teams, performance is judged by what gets delivered and how reliably people contribute, not by online presence or visible busyness.
Use criteria that cover what clients receive, how well the work holds up, and how dependable collaboration is across handoffs. This keeps one strength from masking a meaningful gap in another area.
Each scorecard line needs a written standard that is specific, measurable, realistic, and clear. Tie each line to named evidence sources, not manager memory, using records you already produce during delivery (for example, delivery records, quality-review notes, handoff documentation, client feedback summaries, and one-on-one commitments). If the evidence source is unclear, rewrite the line before rollout.
A quick test helps: if a line reads like "handles client delivery reliably," it is too vague for appraisal. Rewrite it so a manager can verify it from records, then confirm the result could trigger a real coaching, staffing, or priority decision.
| Tool | Use this for | Not this |
|---|---|---|
| Role scorecard | Rating performance against written criteria | Watching weekly movement only |
| KPI | Trend monitoring on a recurring measure | Full appraisal by itself |
| Dashboard | One-page highlight view of key metrics | Detailed evidence pack for ratings |
Keep this boundary clear. KPI reporting and dashboards are useful for trend visibility, but they are not sufficient on their own for full performance decisions.
Run a calibration check before the cycle starts#
Before the review cycle opens, give the same sample evidence to two managers and compare likely ratings. If disagreement is likely, tighten the wording, clarify the evidence rule, or split blended criteria before formal reviews begin.
Use a simple verification step#
For every scorecard line, confirm four checks:
- the expectation is written in specific appraisal language
- the evidence source is named
- two managers would likely interpret it similarly
- a high or low result would trigger a concrete decision
If a line fails any check, fix it before the cycle starts.
Choose KPIs and OKRs that prevent vanity reporting#
Use KPIs and OKRs only when they drive a decision, not just a dashboard update. If a metric will not change coaching, staffing, priorities, or process, it is likely noise.
Keep the roles separate: KPIs track current operating performance, and OKRs are for intentional change. When you treat them as the same thing, ownership blurs and accountability weakens.
| Signal type | Primary job | Time horizon | Decision use |
|---|---|---|---|
| KPI | Monitor ongoing operational or tactical performance | Near-term delivery control | Correct drift, unblock work, coach, or reallocate effort |
| OKR | Move performance toward a strategic outcome | Longer planning/change cycle | Check whether the change effort is working or needs adjustment |
| Activity signal | Add context on effort or work patterns | Supporting context | Use to interpret outcomes, quality, or handoff reliability, not as a standalone rating signal |
Define ownership and response rules before launch#
Before adding any KPI or OKR, document the owner, review cadence, and what action you will take if the signal improves, declines, or stalls. This keeps metrics from becoming passive reporting lines.
Then verify data dependencies. If a metric depends on QA notes, ticket records, or client feedback, make sure those inputs are consistently captured and reviewed on the same cadence. Clean-looking metrics built on patchy inputs still produce weak decisions.
Map each metric back to the role scorecard#
Run a metric-to-scorecard check before each cycle. Every dashboard line should map to one scorecard criterion, one likely coaching or staffing decision, and one follow-up record (for example, a one-on-one note, corrective action, or priority change). If you cannot complete that chain, remove or rewrite the metric.
For trend notes, require context tags such as scope change, staffing shift, dependency blocker, or process fix. That gives managers a fast way to separate real movement from noise before they act.
This pairs well with our guide on A Guide to Salary Bands and Compensation for a Global Remote Team.
Install a meeting cadence that actually drives decisions#
Once your metrics have owners and response rules, stop using meetings for narration. Use live time for decisions and discussions that are faster in real time. If there is no decision to make, post the update asynchronously.
This discipline protects focus. Microsoft's 2025 Work Trend Index reports workers are interrupted every 2 minutes during core work hours, adding up to 275 interruptions a day, with 60% of meetings ad hoc.
Give each meeting one decision job#
Do not force execution risk review, coaching, and formal evaluation into one recurring call. Keep the same three-meeting structure, and assign each one a clear decision owner.
| Meeting type | Use when | Do not use when | Required pre-read | Decision artifact |
|---|---|---|---|---|
| Weekly check-in | You need a real-time decision on delivery risk, priority conflict, staffing tradeoffs, or a blocker | The update is broadcast-only and no tradeoff needs judgment | Async status update with KPI/OKR movement, blocker, requested decision, and owner confirmation | Decision, owner, due date, and proof signal for the next cycle |
| One-on-one | You need coaching, feedback, support, or an approach decision for one person's scorecard outcomes | The topic is team status narration or a hidden formal rating conversation | Recent commitments, scorecard notes, current blocker, and support request | Commitments from both sides, follow-up date, and expected proof of progress |
| Review checkpoint | You need a formal performance discussion that informs development and other people decisions | Evidence is incomplete or the issue still belongs in regular coaching | Scorecard snapshot, KPI trend context, one-on-one notes, and closed escalation records | Written rationale tied to evidence, named final approver, and next review date |
Run the same pre-meeting sequence every cycle#
Before live time, require four written inputs:
- Status changes since the last cycle.
- Blocker framing and impact.
- Requested decision.
- Owner confirmation, plus a single final approver when approval is needed.
This keeps the meeting on tradeoffs instead of recap. It also helps resolve some blockers offline before adding another call.
Make pre-read mandatory. Atlassian's page-led meeting test reported that 85% of page-led meetings achieved their goal versus 69% of control meetings.
Judge cadence health by decision records#
Close each meeting with a lightweight decision log:
- Decision
- Owner
- Proof of progress
- Follow-up date
If options were debated, add a short tradeoff note so the team does not rehash the same decision later. Treat missing decision artifacts as your primary cadence warning signal; attendance alone cannot prove your rhythm is working. After this decision hygiene is stable, tighten async norms in your communication policy for a remote team, then use Gruv tools as a low-friction next step for operational consistency.
Decide when to use asynchronous updates versus live meetings#
Default to async, and escalate to live only when you need real-time judgment, fast back-and-forth clarification, or an immediate decision. This keeps routine updates from turning into interruptions while still giving urgent or complex issues the attention they need.
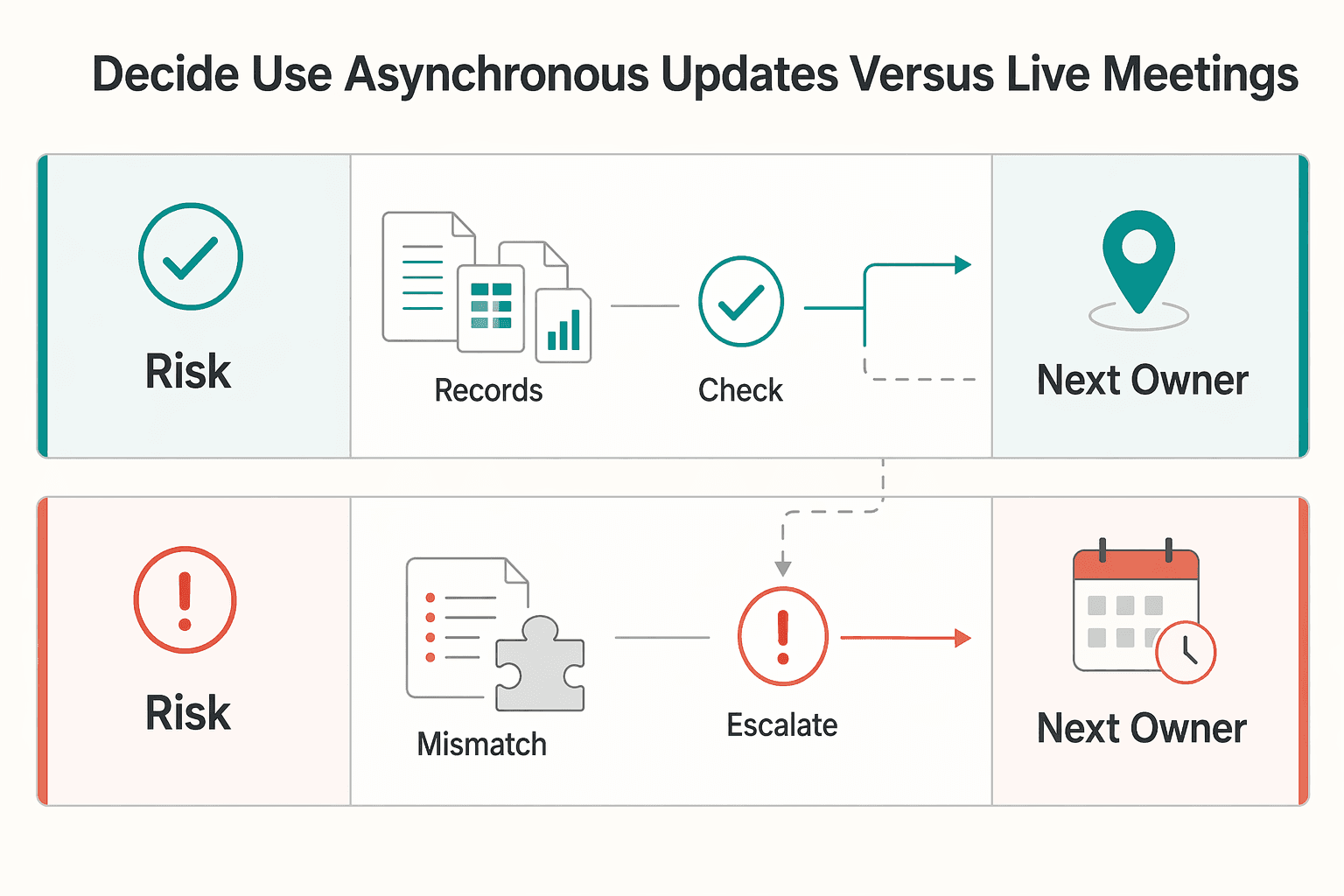
Use one routing rule in daily operations: if a written update makes the status, risk, owner, and next step clear, stay async. If the issue stays unresolved in writing, escalate.
| Use async when | Switch to 1:1 when | Switch to team meeting when | Required written output after escalation |
|---|---|---|---|
| The update is routine status, handoff detail, or a low-risk flag, and no immediate back-and-forth is needed | The blocker is concentrated with one person, or you need direct coaching/support to restore progress | Multiple owners are involved, tradeoffs are unresolved, priorities conflict, clarification threads keep looping, or client-impact risk is rising | Post a short decision record: decision, owner, due date, dependencies, proof of progress, next checkpoint |
| The next owner and next checkpoint are already clear in writing | A repeated blocker still has no clear owner and accountability needs to be set directly | Timing, staffing, scope, quality, or client commitments require a shared decision in real time | Post a brief loop-back summary in the async channel so the team can execute without reopening the same debate |
Keep escalation triggers observable, not personality-based. Strong triggers look like: repeated blocker without an owner, unresolved tradeoff after async clarification, circular clarification thread, or rising client-impact risk.
Enforce one async update format#
Before booking live time, require each async update to include:
- current status
- primary risk
- next owner
- decision request (if any)
- next checkpoint
After every live escalation, close the loop in writing. Decisions and details are easy to lose without notes, so require a decision record, then post a two- to three-sentence summary back in the async channel to protect focus time and prevent repeat debate. This also keeps your remote work practices from drifting into meeting sprawl.
Related reading: Performance Reviews for Remote Employees When You Work as a Contractor.
Execute the first 90 days in clear order#
Run the first 90 days as a 30-60-90 plan with clear gates, not a loose trial period. In each phase, document priorities, practical goals, and success metrics before you add new targets or extra reporting.
A 30-60-90 plan gives you a structured roadmap for the first three months, but the detail should match your context. Build it with the manager who will review the work, and keep KPI tracking explicit from day one.
| Phase | Objective | Manager action | Team member action | Evidence to capture | Checkpoint decision |
|---|---|---|---|---|---|
| Days 1-30 setup | Turn role expectations into a working plan | Define high-level priorities, practical goals, and success metrics together; confirm KPI tracking | Clarify unclear terms, restate goals in plain language, and confirm ownership | Current 30-60-90 plan, agreed priorities, measurable goals, initial metrics, scheduled check-ins | Do not advance until both of you can explain what success looks like and how progress will be measured |
| Days 31-60 pressure test | Test the plan under real delivery conditions | Review progress, check whether KPIs are useful for decisions, and tighten vague goals | Track progress, raise blockers early, and flag where goals or metrics are unclear | KPI trend notes, blocker log, check-in notes, updated goals where needed | Do not advance until blockers have clear owners and metrics are usable for coaching or priority calls |
| Days 61-90 outcome review | Compare outcomes to the plan and set the next cycle | Review outcomes against goals, close open gaps, and document next expectations | Bring evidence of completed work, unresolved issues, and next-step goals | Outcome summary, goal-by-go review, open issues list, next-cycle expectations | Do not advance until outcomes are documented and next-cycle expectations are explicit |
The common breakdown is delay: when concerns are left until a much later review point, issues build and become harder to resolve cleanly. Before you move forward, confirm three things: your documentation is consistent, blockers were resolved or clearly carried, and next-cycle expectations are written down.
Handle performance problems early with explicit escalation paths#
Act as soon as you can show a pattern in outcomes, behavior, or team feedback. Pick the escalation tier, document it, and write the next checkpoint so the case does not drift into memory-based judgment.
Use the records from your first 90 days (notes, scorecards, check-ins) to classify the issue: coaching, formal correction, or calibration.
| Tier | Trigger pattern | Immediate manager move | Documentation minimum | Stay at tier or move up |
|---|---|---|---|---|
| Early coaching | First pattern of concern in outcomes, behavior, or team feedback (not a one-off). | Hold a private discussion, name the concern, explain impact, restate the expected result or behavior, and set a checkpoint. | Dated issue summary, evidence artifact, impact note, expected change, checkpoint date. Use recurring 1:1 agendas, async updates, and documented standups where available. | Stay if the next checkpoint shows clear correction. Move up if the pattern repeats, expectations remain disputed, or impact spreads. |
| Formal correction | Repeated pattern after coaching, or a concern affecting delivery quality across work. | Hold a private concern discussion and open a written Performance Improvement Plan with SMART goals, timelines, and support resources. | Coaching record, dated evidence trend, impact note, written plan, support offered, review date or review window, and success criteria tied to outcome-based KPIs where relevant. | Stay if progress is visible and records are current. Move up if progress stalls, evidence is inconsistent across managers, or impact extends beyond one manager's lane. |
| Calibration review | Cross-team impact, stalled correction, or cases where managers could reach different outcomes from similar facts. | Bring the case to calibration, and separate evidence-quality review from outcome decision. | Full case packet: coaching notes, PIP record, trend evidence, manager notes, completeness check, draft rationale. | Decide only after evidence-quality and process-consistency checks pass. If the packet is weak, return it for completion before any rating or staffing decision. |
Use trigger definitions managers can apply the same way#
Define triggers operationally, not emotionally. "First pattern" means you can point to more than one dated signal (for example, scorecard movement, 1:1 behavior notes, or repeated team feedback). "Repeated pattern" means the coaching checkpoint did not resolve the issue. "Cross-team impact" means the issue now affects other people, other accounts, or decisions outside one manager's direct scope.
If one manager escalates early and another waits for review season on similar facts, you create visibility bias. Keep one rule: if a concern is not tied to written evidence, it is not ready for escalation.
Write the correction plan so both sides can review the same thing#
Your correction plan should remove ambiguity, not just increase pressure. Keep it short and reviewable:
| Plan element | What to include |
|---|---|
| Concern statement | Linked to dated evidence |
| SMART goal or goals | SMART goal or goals |
| Timeline or review window | Review window to confirm before the plan starts |
| Support resources and manager commitments | Support resources and manager commitments |
| Checkpoint date or dates | Checkpoint date or dates |
| Success evidence | Tied to outcomes, not superficial activity like hours logged or email volume |
If a plan says "improve communication" without a proof standard, rewrite it before the plan starts.
Calibrate the evidence before you calibrate the outcome#
Use calibration to enforce consistency and equity, not to rubber-stamp decisions. First check evidence quality: dated artifacts, clear impact, expected change, and checkpoint history.
Then make outcome decisions. Add a process-consistency check: if a similar case elsewhere would require stronger notes, fuller 1:1 records, or clearer impact, align the documentation standard first.
Manage time zone friction without lowering standards#
Keep standards constant across regions, and make routing explicit: use overlap time for ambiguity and decisions, and use async updates for routine execution and evidence.
Use one written communication rule plus a decision log so work does not depend on everyone being online together. Define when a call is required versus when a written update is sufficient, and keep that rule consistent across teams. When updates stay trapped in meetings, decisions slow down; when response speed becomes the main signal, teams drift toward always-on behavior instead of reliable delivery.
| Scenario | Required channel | Escalation trigger | Mandatory decision artifact |
|---|---|---|---|
| Planned execution with stable scope | Standardized async update | Move to live overlap when ownership, acceptance criteria, or blocker resolution is still unclear in writing | Written handoff note in the shared record |
| Priority conflict, scope change, or client-risk tradeoff | Live overlap discussion | Escalate when written updates show competing priorities or unclear decision rights | Decision log entry with owner, decision, and next checkpoint |
| Cross-time-zone dependency blocked | Start async, then move to live overlap if still unresolved | Escalate when the next owner cannot proceed from the written handoff | Updated decision log plus revised handoff |
| Repeated coordination defect affecting review evidence | Manager review discussion | Escalate when the same coordination defect repeats across handoffs | Dated manager note tied to pattern and corrective action |
For performance scoring, evaluate delivery reliability and handoff quality first, then use responsiveness as a secondary signal unless a role has explicit coverage expectations. Fast chat replies should not outweigh missed commitments, unclear ownership, or handoffs that create rework.
Use a consistent handoff checklist and require receiver confirmation in the same shared record before work is treated as transferred. If coordination defects repeat, log them as process signals first so you can fix the workflow before assigning individual blame.
Before judging individual performance, run a short bias-control loop:
- Check for chat-visibility bias by comparing visible reply activity against delivery reliability and handoff quality.
- Rebalance scorecard emphasis if visibility is outranking dependable execution.
- Correct coordination standards and manager behavior first when the same handoff defects repeat.
This keeps time-zone fairness tied to evidence, not online presence.
Build an evidence pack for fair reviews and low-surprise operations#
Build one evidence pack per person, and only score claims you can trace to a dated record with a clear owner. Separate what can affect a rating from what only adds context.
Use two buckets:
- Rated evidence: records that can directly support a score or review statement.
- Background context: useful explanation that stays out of scoring unless you can link it to an official record.
This keeps reviews grounded in documented work and development. Keep a written record of review discussions and share it with the employee afterward.
| Evidence item | What to include | Evidence owner | Source system | Rating use |
|---|---|---|---|---|
| Role scorecard snapshot | Current cycle expectations, measured outcomes, accepted criteria | Manager or role owner | Scorecard or appraisal document | Primary evidence for role expectations and outcome rating |
| KPI trend notes | Delivery/quality trend direction, plus anomaly explanation | Metric owner or manager | Reporting dashboard or dated status record | Primary evidence when trends support or weaken reliability claims |
| OKR progress summary | Objective status, key-result movement, blockers removed, decision dates | Objective owner | OKR tracker or review record | Secondary evidence for change initiatives and stretch work |
| One-on-one summary | Coaching points, commitments, follow-up results, dates discussed | Manager | Written one-on-one record | Primary evidence for development, support, and patterns over time |
| Closed escalation records | Trigger, action taken, owner, close status, repeated or resolved outcome | Manager or escalation owner | Escalation log or written review record | Primary evidence when concerns were formally raised and tracked |
Run a pre-review quality gate#
Before calibration, check the pack quickly:
| Quality gate | What to check |
|---|---|
| Completeness | Required artifacts are present |
| Date/owner linkage | Each artifact shows when it was created and by whom |
| Trend explanation | KPI/OKR notes explain movement, not just the latest value |
| Escalation status clarity | Concerns are clearly marked as resolved, repeated, or open |
If any gate fails, fix the pack before scoring. Consistent standards and factual detail make rating decisions clearer and more defensible.
Set an evidence hierarchy#
Use written, dated operational records as primary evidence. Keep screenshots, chat fragments, and side-channel notes as secondary unless they are linked back to the official record used for the decision.
If a rating is challenged, verify it against the underlying operational evidence.
Before each cycle, validate your review templates with HR/legal for each operating location so language stays job-related and consistent with business necessity. Recheck this regularly where guidance is changeable, including UK employment-record guidance.
End with a traceability pass: map every draft rating claim to a dated artifact in the project record. If a claim cannot be mapped, remove it from scoring and keep it as discussion context until verified.
For a step-by-step walkthrough, see How to Set Up Workers' Compensation Insurance for a Remote Team.
Use manager scripts that improve clarity and trust#
Use scripts as a consistency system for managers, not a personality script. In remote teams, review surprises usually come from misaligned signals, so your goal is to make performance positioning clear before formal ratings.
Use one house structure in every conversation: facts -> impact -> next action, then close with continue, correct, or escalate. This keeps your language consistent across manager styles and makes each message easier to verify later.
| Conversation moment | When to use it | Script pattern to use | Minimum evidence standard |
|---|---|---|---|
| Routine one-on-one feedback | A pattern is emerging, but you are still in coaching mode | "Here are the facts I observed. Here is the impact on delivery or quality. Here is the next action before our checkpoint. Decision today: continue or correct." | At least one dated, traceable example from your scorecard, KPI/OKR notes, one-on-one record, or escalation log |
| Mid-cycle performance positioning | You need to clarify current standing before review close | "Here is your current standing against the scorecard. Here is the evidence trend behind that position. Here is what must continue or change before formal review." | Multiple dated artifacts with trend context, not a single incident |
| Formal correction conversation | Coaching did not resolve the issue, or risk is increasing | "Here are the documented facts to date. Here is the impact. Here is the required change, support offered, and checkpoint date. Decision today: escalate." | Complete documented pattern, prior coaching notes, and any required policy step or form verified before finalizing |
Use language that can be checked later, not language that only sounds supportive.
| Vague language | Clear language |
|---|---|
| "You need to be more early." | "In the last two handoffs, the blocker field was blank, which delayed the next owner. Starting now, complete all handoff fields and flag blockers in the agreed channel before end of day. We will check the next two handoffs." |
| "Communication has been off." | "On the date the revision occurred, the client revision was not logged in the project record, so QA used the older scope. Use the update template for every client change. We will review this at the next one-on-one." |
| "You are doing fine, keep going." | "Your QA defect notes were complete for the last three cycles, and rework dropped. Continue that standard through the next cycle." |
Use this record standard in one-on-ones and review prep so every manager logs decisions the same way:
- date, conversation type, manager name
- observed behavior or outcome
- concrete example tied to a source record
- impact on team, delivery, or quality
- expected next action
- support offered
- checkpoint date
- close decision: continue, correct, or escalate
- policy-required form/approval wording to verify before finalizing
If policy requires a specific form or approval, verify it first and then log the conversation with the same structure.
Conclusion#
Treat remote team performance management as an operating discipline, not a manager preference. You get fairer calls and less review-cycle drama when expectations are explicit, trust is protected, and every rating can be traced to written evidence instead of recollection from a busy week.
Your closeout sequence is straightforward. First, align expectations in writing through role scorecards, KPI ownership, and clear acceptance criteria. Next, lock the habits that keep the process honest: run one-on-ones alongside formal reviews, keep a decision log after meetings, and send clear handoff messages at sign-off when work crosses time zones. Even a one-hour schedule difference can hurt communication, so score reliability by handoff quality and commitments met, not by who replies fastest.
Then make documentation non-optional. Acas guidance is clear that performance discussions should be recorded and shared with the employee, and formal reviews should sit alongside regular feedback. Before any calibration or correction step, check the evidence pack: current scorecard snapshot, dated one-on-one notes, KPI or OKR trend context if relevant, and closed escalation records. If a statement cannot be tied to a dated artifact with an owner and context, keep it out of scoring. If coaching fails, move through the published escalation path, consider a formal improvement plan, and document each checkpoint before any disciplinary step.
Start small, then expand. A pilot with one team lets you test cadence discipline, handoff templates, and review packets on a small scale. Scaling first usually just spreads inconsistent manager behavior faster. If you need to confirm what your process should look like in a specific country, remember that EU employment rules are implemented nationally and U.S. teams may face both federal and state requirements. Want help turning that into a compliant operating setup? Talk to Gruv.
Frequently Asked Questions
How do you measure remote team performance without micromanaging?
Measure outcomes, quality, and collaboration reliability, not constant online presence. If you start tracking remote workers, treat privacy as a real tradeoff and keep the boundary clear: use only the minimum signals needed to explain a decision without breaching privacy.
What you do next: Check your scorecards and remove any measure that depends more on presence than on a dated result or quality signal.
Which KPIs should an IT agency review weekly versus monthly?
There is no fixed weekly-versus-monthly rule in this grounding. Use a faster rhythm when a rise, drop, or flat trend should change coaching or delivery priorities now, and use a slower rhythm when you need broader pattern context.
What you do next: Label each KPI with its owner, review rhythm, and the action you will take for up, down, or flat movement.
How often should one-on-ones and formal performance reviews happen?
Run one-on-ones on a regular cadence so people are not guessing where they stand. Remote employees can feel out of the loop, and managers can miss context if they mostly see people on video calls. This grounding supports regular check-ins, but it does not set one fixed interval for formal reviews.
What you do next: Make sure every person has a scheduled one-on-one cadence and clearly documented review expectations.
What belongs in a performance evidence pack before calibration?
Keep artifacts you can verify quickly: dated scorecard snapshots, KPI trend logs, and dated one-on-one notes. If a rating statement cannot be traced to a dated artifact with clear ownership and context, treat it as background only and leave it out of scoring.
What you do next: Do a completeness check before calibration and stop any packet that relies on unverified anecdotes.
How should managers handle time-zone differences without lowering standards?
This grounding does not define specific time-zone performance standards. Keep expectations explicit, apply the same outcome standards across locations, and use regular check-ins to catch misalignment early.
What you do next: Review team expectations and check-in coverage so distributed teammates stay aligned and in the loop.
What mistakes show up most often in remote team performance management, and how do you correct them?
The usual failures are unclear metrics, weak feedback loops, and assumptions that people will volunteer problems on their own, even though burnout, isolation, and distractions are common in remote work. Correct that by asking targeted questions in one-on-ones, documenting clear next steps, and tightening expectations when the same issue repeats.
What you do next: Audit your last three manager notes and rewrite any vague line so it states the fact, the impact, and the next checkpoint.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
- cbp.gov/sites/default/files/2024-08/usbp-strategy_05...trusted
- dol.gov/general/aboutdol/majorlawstrusted
- eeoc.gov/employers/recordkeeping-requirementstrusted
- eeoc.gov/employers/small-business/5-im-conducting-per...trusted
- fema.gov/sites/default/files/2020-07/Continuity-Risk-...trusted
- library.hbs.edu/working-knowledge/global-talent-local-obstac...trusted
- opm.gov/policy-data-oversight/performance-management...trusted
- opm.gov/telework/tmo-and-coordinators/performance-ma...trusted
Educational content only. Not legal, tax, or financial advice.
Related Posts

The Best Digital Nomad Cities for Slow Travel in 2026
If you want a city that still works after the first exciting week, judge it like a place to live, not a place to visit. Location-independent work keeps growing in 2026, but that does not make every popular city a good base. This list is for remote professionals planning a longer stay and weighing the legal and practical choices that still matter once daily life takes over.

How to Set Up a Limited Company in Ireland
Work in two tracks and keep them separate: complete CRO formation first, then handle post-setup registrations. That order reduces duplicate edits and missed follow-ups.

The Freelance Payment Penalty: A Modeled Audit of Platform Fees, FX Spreads, and Payout Delays
The money rarely disappears through a single, easy-to-spot fee. The real loss is stacked. A marketplace takes its commission, a processor adds a charge for international cards, a bank or payment company converts the currency at a spread, a platform holds the funds before release, and a wire sheds a little to intermediaries on the way in. Each layer looks defensible on its own, but the worker feels the combined result as a smaller deposit and a later payday.